2009 г.
Query-by-Example: язык баз данных
М.М. Злуф
Источник: журнал Системы Управления Базами Данных # 3/1996, издательский дом «Открытые системы»
Новая редакция: Сергей Кузнецов, 2009 г.
Оригинал: M. M. Zloof. Query-by-Example: a data base language. IBM Systems Journal, Vol.16, # 4, 1977.
Содержание
Выборка
Вставки, удаления, модификации
Создание таблицы
Заключение
Приложение
Благодарности
Литература
Обсуждается высокоуровневый язык управления базами данных, предоставляющий
пользователю удобный и унифицированный интерфейс для формирования запросов,
обновления, определения и контроля базы данных.
Чтобы выполнить некоторую операцию с базой данных, пользователь строит пример соответствующего
решения в схематических таблицах, которые можно ассоциировать с реальными
таблицами в базе данных. В настоящее время система используется в экспериментальном режиме
в нескольких приложениях.
Query-by-Example [1-4] – высокоуровневый язык управления базами данных,
предоставляющий удобный и унифицированный стиль для построения запросов,
обновления, определения и контроля базы данных. Согласно философии Query-by-Example,
от пользователя требуется весьма скромные знания для начала работы, и сводится
к минимуму количество концепций, которые он должен изучить для понимания
и использования всего языка. Синтаксис языка прост, но тем не менее он
охватывает широкий спектр сложных транзакций. Это достигается за счет использования
одних и тех же операций для извлечения, манипулирования, определения и контроля (насколько это возможно).
Операции языка имитируют, насколько возможно, ручное манипулирование
таблицами, сохраняя тем самым простоту, симметричность и нейтральность
реляционной модели [5,6]. Формулировка транзакции должна следовать мыслительному
процессу пользователя, предоставляя тем самым свободу при построении такой формулировки.
Система должна динамически создавать и уничтожать таблицы базы данных,
она должна также предоставлять пользователю возможности динамического определения
операторов контроля доступа и средств безопасности.
Архитектура языка Query-by-Example направлена на удовлетворение сформулированных требований. Результаты различных психологических исследований
показывают, что для инструктирования непрограммистов требуется менее трех
часов, после чего они могут формулировать довольно сложные запросы. Без применения Query-by-Example для формулировки аналогичных запросов от пользователя потребовалось бы знание исчисления предикатов
первого порядка. Другими непроцедурными языками в этой области являются
SEQUEL [8] и QUEL [9].
Первая реализация Query-by-Example была выполнена Нибуром (K.E. Niebuhr) и Смитом (S.E.
Smith) [11]. В настоящее время язык в экспериментальном режиме используется в различных
приложениях, среди которых управление библиотечными файлами, ресурсами
компьютеров, файлами патентов, почтовыми файлами и платежными счетами.
Формальные синтаксис и семантика, обоснование полноты, спецификации авторизации и целостности
приведены в работе [12].
В следующих разделах на основе иллюстративных примеров выборки, манипулирования
и определения показываются возможности Query-by-Example.
Выборка
Часть языка, связанная с запросами, иллюстрируется примерами над следующими
таблицами:
- EMP (NAME, SAL, MGR, DEPT),
- SALES (DEPT, ITEM),
- SUPPLY (ITEM, SUPPLIER),
- TYPE (ITEM, COLOR, SIZE),
где таблица EMP определяет имя, зарплату, руководителя и отдел каждого
служащего, таблица SALES содержит список товаров, продаваемых каждым отделом,
таблица SUPPLY хранит список товаров, поставляемых каждым поставщиком,
и таблица TYPE описывает цвет и размер каждого товара. Содержимое примерной базы данных и результаты запросов, демонстрируемых в примерах, приведены в
Приложении.
В Query-by-Example фундаментальными являются две основные концепции.
Программирование производится внутри двумерных схематических таблиц.
Это делается путем заполнения соответствующих полей таблицы в примере решения.
Кроме того, проводится различие между константным элементом (constant element) и элементом
примера (example element). Элементы примера (переменные) подчеркиваются, а постоянные
элементы – нет.
Используя две эти концепции, пользователь может сформулировать широкий
спектр запросов. Рассмотрим, например, таблицу TYPE, которая содержит в
качестве заголовков столбцов ITEM, COLOR и SIZE. Допустим, пользователь
хочет сформулировать следующий запрос: "Вывести информацию обо всех зеленых товарах".
Изначально пользователю на экране предлагается схематическая таблица, как показано на рис. 1.
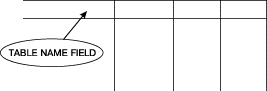
Рис. 1. Схематическая таблица
Пользователь вводит в поле имени таблицы имя таблицы, к которой будет адресоваться запрос: в данном случае имя таблицы – TYPE. Затем можно либо
ввести заголовки столбцов, либо позволить системе сделать это автоматически.
(Эта операция объясняется далее.) После этого пользователь формулирует
запрос, осуществляя ввод, показанный на рис. 2. Здесь P. означает <напечатать>,
и указывает на желаемый вывод. Элемент ROD, являющийся элементом примера
(переменной), подчеркнут и представляет пример возможного ответа. GREEN
(ЗЕЛЕНЫЙ) – это константный элемент, определяющий требуемое условие запроса; он не подчеркивается.

Рис. 2. Заголовок столбцов и необходимый ввод для получения товаров зеленого
цвета
Запрос можно перефразировать следующим образом: напечатать информацию обо всех товарах
– таких как ROD, – зеленым цвета . Элемент ROD не обязательно
должен содержаться в базе данных. Поскольку элемент примера является произвольным,
пользователь может обозначить его как X, 10, 11 или WATER без изменения
смысла и результатов запроса. Позднее мы увидем, что элементы примера, используются
для установления связей между двумя или более строками одной таблицы или
разных таблица. Там, где связи не нужны, элементы примера можно опускать.
Тем самым, допустима эквивалентная формулировка запроса на основе примера, показанная
на рис. 3. Другими словами, отдельно стоящий оператор P. по умолчанию означает P."Example Element". В следующих примерах мы используем P. или P."Example Element"
произвольным образом.

Рис. 3. Альтернативная формулировка запроса для вывода зеленых деталей
После того, как пользователь сформулировал запрос, он нажимает клавишу Enter
для получения ответа. При использовании модельной базы данных, приведенной
в приложении, вывод запроса будет иметь вид, показанный на рис. 4. Выводится только столбец товаров, поскольку на рис. 3 P. было
введено только в столбец ITEM. Если бы P. было введено и в столбец
SIZE, система вывела бы и товары, и их размеры.

Рис. 4. Пример вывода на экран зеленых товаров
Когда пользователь представляет запрос (или любую другую операцию) в
схематической таблице, он осознает, что за этой схемой запроса находится реальная таблица с
теми же заголовками, что и таблица запроса, в которой содержатся реальные данные.
Другими словами, для выражения запроса он воспроизводит операцию ручного просмотра
таблиц. Если для выражения запроса пользователю требуются две или большее число
таблиц, он может образовать дополнительные пустые схемы (используя
специальные функциональные клавиши) и затем заполнить их заголовки.
Рассмотрим несколько типов запросов на иллюстративных примерах. Ответы на эти запросы приводятся в приложении.
Простая выборка. Вывести все цвета. Формулировка этого запроса
показана на рис. 5. Элемент примера WHITE может быть опущен. Дубликаты значений
цветов в этом случае выводиться не будут. (Метод вывода дубликатов приведен
в этой статье ниже.) В случае автоматического предоставления системой
заголовков столбцов, пользователь может (если это требуется) удалить неиспользуемые
столбцы. Таким образом, столбцы ITEM и SIZE можно было бы удалить.

Рис. 5. Простая выборка, см. результат запроса
Простая выборка с упорядочиванием. Вывести все цвета в алфавитном
порядке. Как показано на рис. 6, для вывода по возрастанию используется оператор AO.. Аналогично, для вывода по убыванию используется
оператор DO.. Там, где необходимы первичная и вторичная сортировки, для первичной сортировки ставится
AO(1)., а для
вторичной – AO(2)..

Рис. 6. Простая выборка с упорядочиванием, см. результат запроса
Простая выборка с множественным выводом. Вывести всю таблицу
TYPE. Эта операция показана на рис. 7. Здесь также могут быть использованы
элементы примера. Сокращенное представление этого же запроса показано на
рис. 8. Здесь оператор вывода P. применяется ко всей строке. Заметим, что
все системные операторы, такие как P., I. и AO., заканчиваются точкой.
Если таблица содержит много столбцов, пользователь может вывести все
необходимые, удалив предварительно ненужные столбцы и применив оператор
P. для всей строки, представляющей только оставшиеся столбцы.

Рис. 7. Простая выборка с множественным выводом

Рис. 8. Сокращенная простая выборка с множественным выводом
Выборка имен таблиц. Вывести список имен доступных таблиц базы
данных. Формулировка этого запроса приведена на рис. 9. Здесь оператор
вывода расположен в поле имени таблицы, запрашивая тем самым у системы
все доступные имена таблиц. Для нашей модельной базы данных результатом
этого запроса будет :
EMP
SALES
SUPPLY
TYPE
И снова элемент примера TAB является необязательным.

Рис. 9. Выборка имен таблиц
Выборка заголовков столбцов. Ранее говорилось, что вместо того, чтобы обязывать пользователя вводить
заголовки столбцов, система может сгенерировать их автоматически.
Как это делается, показано на рис. 10. В этом примере запрашиваются заголовки
столбцов таблицы TYPE. Здесь опять оператор p. применяется ко всей строке
заголовков, и в действительности, это пример является сокращенной формой
размещения нескольких операторов вывода в полях заголовков столбцов.
Автоматическая генерация заголовков столбцов полезна, поскольку она освобождает
пользователя от необходимости запоминания этих заголовков (или нахождения
их в каталоге) и за счет этого предотвращает ошибки при вводе.

Рис. 10. Выборка заголовков столбцов, см. результат запроса
Если пользователь введет в поле имени таблицы P. TAB P. (или P.P.), то система выведет каталог базы данных, т.е. имена таблиц и их соответствующие имена столбцов.
Ограниченная выборка. Вывести имена сотрудников, работающих
в отделе игрушек (toy) и получающих больше $10000. Этот запрос показан на рис.
11. Обратите внимание на условие "больше $10000".
Здесь возможно использование любого из следующих операторов сравнения:
≠, >, >=, <, <=. Если в качестве префикса не используется ни один из операторов сравнения, подразумевается оператор сравнения по равенству. Символ ≠ может
быть заменен символами ¬ или ¬=.

Рис. 11. Ограниченная выборка, см. результат запроса
Ограниченная выборка с частичным подчеркиванием. Вывести названия
товаров зеленого цвета, начинающиеся с буквы I. Пример приведен на рис.
12. Символ I в конструкции "IKE" не подчеркнут и является
константой. Поэтому система выведет все зеленые товары, названия которых начинаются
с буквы I. Пользователь может применять частичное подчеркивание в начале,
середине или конце слова, предложения или абзаца, как в примере XPAY,
означающем слово, предложение или абзац, такие что где-то в них содержатся
буквы PA. Поскольку элементы примера могут быть пустыми, слова, предложения
и параграфы, начинающиеся или заканчивающиеся буквами PA, также удовлетворяют
этому условию.

Рис. 12. Ограниченная выборка с частичным подчеркиванием, см. результат запроса
Возможность частичного подчеркивания полезна в том случае, когда хранимыми
данными является предложение или текст, и пользователю требуется найти
все примеры, содержащие определенное слово или корень. Если, например,
необходимо найти все данные, включающие слово Texas, формулировкой запроса будет
P.XTEXASY.
Ограниченная выборка с использованием связей. Вывести все
зеленые товары, продаваемые отделом игрушек. Формулировка запроса показана на рис. 13. В
этом случае пользователь использует и таблицу TYPE, и таблицу SALES, генерируя
две пустых схематических таблицы и заполняя их заголовками и требуемыми данными. В этом примере наилучшим образом иллюстрируется важность элементов примера. Здесь один и тот же элемент примера
должен быть применен в обеих таблицах, показывая,
что если товар из примера, такой как NUT, имеет зеленый цвет, то тот же товар
продается отделом игрушек. Только если одновременно выполняются оба условия, товар считается решением. Эквивалентом при ручной обработке была бы следующая процедура:
просмотр таблицы TYPE и нахождение товара зеленого цвета, с последующим
просмотром таблицы SALES для определения того, продается ли данный товар
отделом игрушек. Поскольку в формулировке запроса нет никаких указаний на то,
как должен обрабатываться запрос, и в каком порядке должен осуществляться
просмотр таблиц, она является нейтральной и симметричной.

Рис. 13. Ограниченная выборка с использованием связей, см. результат запроса
Поняв концепцию связывания элементов примера пользователь может связывать любое число таблиц и любое число строк одной таблицы, как в следующем примере.
Элементы примера, связанные в одной таблице. Найти имена и
зарплаты сотрудников, получающих больше, чем Льюис (Lewis). Запрос показан на рис.
14. Пусть, например, зарплата Льюиса составляет S1, как тогда зовут служащих, зарплата которых больше S1? Порядок строк в примере несущественен: пользователь
не обязан каким-либо образом структурировать запрос. Вместо этого существует
возможность формулировать запрос в соответствии с особенностями мыслительного процесса конкретного пользователя.

Рис. 14. Элементы примера, связанные в одной таблице, см. результат запроса
Другим средством Query-by-Example является возможность формирования
сложного запроса путем расширения существующего простого запроса. Такое
расширение предыдущего примера путем добавления дополнительного
условия показано на рис. 15. В этом запросе требуется найти имена и зарплаты служащих, получающих больше, чем Льюис, и работающих
в отделе, продающем ручки.
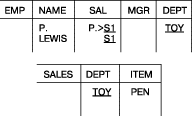
Рис. 15. Расширение примера с рис. 14, см. результат запроса
Еще один запрос может состоять в нахождении имен служащих, получающих больше, чем их менеджеры.
Его можно переформулировать следующим образом: вывести имена служащих,
менеджером которых может быть Джонс (JONES,
например), и размер зарплаты которых больше S1 (например), где S1 – зарплата Джонса. Здесь
один и тот же элемент примера используется для связи менеджера в первой
строке и имени во второй строке, и один и тот же элемент примера применяется для
сравнения зарплат. Порядок строк, конечно, вновь несущественен. После
получения ответа пользователь имеет возможность вернуться назад и модифицировать
или исправить старый запрос. Если, например, пользователь не уверен, что
последний запрос верен, т.е. что запрос был правильно сформулирован, он
может снабдить каждый элемент операторами вывода, получив при этом имена
служащих, их зарплаты и имена их руководителей в первой строке и те же
имена руководителей и их зарплаты во второй строке. Таким способом пользователь
может проверить правильность выполнения запроса.

Рис. 16. Две связи в одной и той же таблице, см. результат запроса
Выборка с использованием отрицания. Вывести все отделы, в которых продается некоторый товар
товар, не поставляемый компанией Pencraft. Этот запрос показан на рис. 17.
Здесь использован оператор отрицания (¬) для всего выражения
запроса в таблице SUPPLY. Этот запрос может быть перефразирован следующим образом: вывести
названия отделов, продающих товары INK, такие что PENCRAFT не поставляет
товары INK. Другими словами, система должна просматривать пары (INK,
PENCRAFT) по всей таблице, и название соответствующего отдела выводится
только в том случае, если такой пары не находится. Этот запрос отличается
от того, который обсуждается в следующем абзаце.
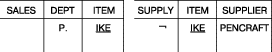
Рис. 17. Выборка с использованием отрицания, см. результат запроса
Выборка с использованием отрицания. Вывести все отделы, котрые продают товары,
поставляемые поставщиком, отличающимся от компании Pencraft. Этот запрос
проиллюстрирован на рис. 18. В этом примере система извлекает данные таблицы
SUPPLY для поставщиков, отличающихся от Pencraft, и затем выбирает соответствующие
отделы. Обратите внимание, что пара (INK, PENCRAFT) также может существовать.
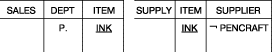
Рис. 18. Выборка с использованием отрицания, см. результат запроса
Выборка связанных данных из нескольких таблиц. Вывести названия
всех отделов вместе с названиями их поставщиков. Поскольку результатом вывода является новая
таблица, пользователь должен сгенерировать третью схематическую таблицу и заполнить
его элементами примеров из двух существующих таблиц, удовлетворяющими условиям запроса.
Так как эта таблица создается пользователем – и, следовательно, не содержит
хранимых данных – он может заполнить поля заголовков столбцов или оставить
их пустыми. Это показано на рис.19.
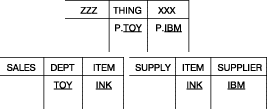
Рис. 19. Выборка связанных данных из нескольких таблиц, см. результат запроса
Использование ZZZ, THING и XXX в качестве заголовков иллюстрирует тот
факт, что пользователь может выбирать свои собственные заголовки. В результирующую
таблицу из двух других таблиц передаются только связанные элементы
TOY
и IBM. Наличие элемента INK в обеих таблицах SALES и SUPPLY
означает, что TOY – это отдел, в который товар INK поставляется поставщиком IBM. Порядок таблиц не является существененным, т.е. результирующая таблица
не обязательно должна отображаться первой.
Если пользователь не сгенерирует третью таблицу, а снабдит префиксом
P. элементы TOY и IBM в двух исходных таблицах, то в результате появятся
две отдельные таблицы, одна из которых будет содержать отделы, а другая
– поставщиков. Тогда связь между отделами и их поставщиками будет утеряна.
Рассмотрим следующую таблицу: EMP1 (NAME, SAL, COMMISSION).
Арифметические операции. Для каждого служащего вывести его имя
и зарплату плюс комиссионное вознаграждение. Здесь пользователь вновь создает выводную
таблицу и выполняет в ней требуемую арифметическую операцию, как показано
на рис. 20. В этом случае пользователь создает таблицу OUTPUT и определяет
заголовок EARNING. Арифметическое выражение (S1 + S2) суммирует
зарплату и комиссионное вознаграждение каждого служащего. В таблице допускается любое арифметическое выражение.

Рис. 20. Арифметические операции, см. результат запроса
Выборка с использованием блока условий. В Query-by-Example имеются
два двухмерных объекта. Первый из них – это уже обсуждавшаяся схематическая таблица. Второй объект
– это блок условий (condition box), представляющий собой блок с заголовком CONDITIONS.
Пустой блок условий может быть отображен по желанию пользователя в любое
время. Блок условий используется для выражения одного или нескольких требуемых
условий, которые трудно выразить в таблице.
Представление запроса "вывести имена служащих, зарплата которых больше суммы зарплат
служащих Джонса (Jones) и Нельсона (Nelson)" показано на рис. 21. Конечно,
это простое условие можно было бы выразить путем замены S1 на >(S2 + S3)
в первой строке таблицы EMP.
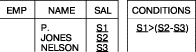
Рис. 21. Использование блока условий, см. результат запроса
Знак равенства в блоке условий является условием сравнения по равенству, и его не
следует путать с оператором присваивания. Операторы присваивания подразумевают
процедурность, а Query-by-Example – язык непроцедурный. Поэтому операторы
присваивания не допускаются. Выражение "W=M+N",
например, может быть сформулировано как "M+N=W"
или "M=W-N". Выражение "M=M+1"
всегда является ложным. Разные условия в блоке условий вводятся на разных
строках, но должны выполняться одновременно, т.е. над результатами разных
условий выполняется логическая операция AND.
Выборка с использованием AND и OR. В Query-by-Example операции
AND и OR выражаются неявно. В большинстве приведенных примеров мы задавали
операцию AND над условиями, либо размещая более двух условий
на одной и той же строке (ограниченная выборка), либо связывая разные строки с помощью
элемента примера (ограниченная выборка с использованием связей). Запросы,
приведенные на рис. 22 и 23, демонстрируют неявное использование операций
AND и OR. На рис. 24 и 25 эти запросы переформулируются
с использованием блока условий.
Вывести имена служащих, зарплата которых составляет от $10000 до $15000
и не равна $13000. Этот запрос показан на рис. 22. Применение элемента
примера JONES во всех трех строках приводит к тому, что для слухащего
JONES для этих трех условий выполняется операция AND.

Рис. 22. Неявная операция AND, см. результат запроса
Вывести имена служащих, зарплата которых составляет $10000, $13000
или $16000. Этот запрос проиллюстрирован на рис. 23. В различных строках
используются разные элементы примера, поэтому эти три строчки выражают
независимые запросы. Результатом является объединение трех множеств ответов.
(В этом примере нельзя применить оператор P. без указания
элемента примера.)

Рис. 23. Неявная операция OR, см. результат запроса
Переформулировка запросов с операциями AND и OR с использованием блока условий.
Рис. 24 иллюстрирует формулировку условия с применением операции AND в блоке условий.
Рис. 25 показывает формулировку условия с применением операции OR.
Для представления операции AND используется амперсенд (&), а символ | представляет операцию OR.

Рис. 24. Операция AND в блоке условий

Рис. 25. Операция OR в блоке условий
Пользователь может также указать операции AND и OR между упорядоченными парами
значений, как в следующем примере. Вывести имена сотрудников,
зарплата и отдел которых являются либо парой ($10000, Toy), либо парой ($20000,
Hardware). Зарплаты и отделы являются упорядоченными парами, и между этими парами может присутствовать OR, как показано на рис.26.

Рис. 26. Операция OR над упорядоченными парами, см. результат запроса
Заметим, что с использованием концепций элемента примера,
константного элемента, оператора вывода и применением этих конструкций в
схематических таблицах и блоках условий пользователь может выражать весьма
сложные запросы, включающие широкий спектр операций над реляционными
базами данных, таких как проекции, выборки, соединения, проекции соединений,
объединение, разность, пересечение и арифметические операции.
В языке Query-by-Example имеются шесть встроенных фунций:
CNT. (count), SUM., AVG. (average), MAX. (maximum), MIN. (minimum) и
UN. (unique). Функция UN. может быть присоединена к функциям CNT.,
SUM. или AVG.. Например, CNT. UN. означает, что число только различных значений. Следующие примеры иллюстрируют применение
этих функций.
Выборка с использованием встроенных функций и оператора ALL.. Подсчитать общее число служащих. Этот запрос показан на рис.
27. Выражение ALL.JONES представляет собой мультимножество (множество,
содержащее дубликаты) всех имен в таблице EMP, и функция CNT. осуществляет
подсчет числа элементов этого множества. Здесь снова можно использовать
конструкцию P.CNT.ALL., опуская элемент примера JONES.

Рис. 27. Использование функции CNT, см. результат запроса
Подсчитать общее количество отделов в таблице SALES. Этот запрос проиллюстрирован
на рис. 28. Поскольку в столбце DEPT существуют дубликаты отделов (столбец
DEPT не является ключом), для удаления дубликатов присоединяется функция
UN.. Функция ALL. не удаляет дубликаты автоматически, так как она порождает
мультимножество. Заметим, что в случае использования конструкции
P.ALL.TOY будет получен список всех отделов с их дубликатами.

Рис. 28. Использование функций CNT. и UN., см. результат запроса
Ограниченная выборка с использованием встроенных функций.
Вывести сумму зарплат в отделе игрушек. Этот запрос показан на рис. 29. Конструкция
ALL.S1 порождает мультимножество всех зарплат, соответствующих TOY, т.е. мультимножество всех зарплат отдела игрушек. Таким образом, если
зарплата каждого из пятидесяти служащих составляет $12000, при суммировании
эта сумма будет учтена пятьдесят раз.

Рис. 29. Ограниченная выборка с использованием встроенных функций, см. результат запроса
Выборка с группированием. Для каждого отдела вывести его название
и сумму зарплат всех служащих. Этот запрос показан на рис. 30. Группирование
задается путем двойного подчеркивания TOY для явного указания
оператора group-by. Этот запрос может быть перефразирован следующим образом:
для каждого отдела TOY (например) просуммировать зарплаты всех его сотрудников.

Рис. 30. Выборка с группированием, см. результат запроса
Вывести отделы, в которых работает более трех сотрудников. Этот запрос показан на рис. 31. Встроенные функции применимы только к выражениям, значениями которых являются множества,
поэтому необходимо использовать оператора ALL. или выражение-множество,
заключенное в скобки. Поэтому, например, при попытке использования вызова CNT.INK вызникнет
сообщение об ошибке.

Рис. 31. Условие на множество товаров, см. результат запроса
Выборка с использованием ALL., включающая "связи множеств"
Вывести названия отделов, продающих, по крайней мере, все товары зеленого
цвета. Этот запрос показан на рис. 32. Значением выражения ALL.INK в таблице TYPE
является мультимножество (т.е. множество, содержащее дубликаты)
всех зеленых товаров. Строки таблицы SALES означают, что производится
поиск отделов (таких как TOY), продающих это множество товаров и,
может быть, что-нибудь еще. Звездочка означает, что могут существовать
дополнительные товары, не входящие в это множество.

Рис. 32. Выборка, включающая "связи множеств", см. результат запроса
Вывести названия отделов, таких что все продаваемые ими товары имеют зеленый цвет. Запрос показан на рис. 33. В этом примере конструкция
ALL.INK таблицы SALES представляет собой мультимножество всех товаров,
продаваемых отделом TOY. Звездочка в таблице TYPE означает, что,
несмотря на то, что товары ALL.INK должны быть зеленого цвета, могут
существовать другие товары зеленого цвета.
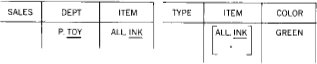
Рис. 33. Выборка, включающая "связи множеств", см. результат запроса
Вывести названия отделов, продающих все товары зеленого цвета и ничего
больше. Запрос показан на рис. 34. Здесь множества в обеих таблицах совпадают.
Это означает, что не существует дополнительных товаров, не являющихся зелеными,
и не существует других товаров зеленого цвета, продаваемых другими отделами.

Рис. 34. Выборка, включающая "связи множеств", см. результат запроса
Вывести названия отделов, продающих все те товары, что и отдел аппаратуры (Hardware),
и, может быть, что-то еще. Исключить из этого списка сам отдел аппаратуры .
Запрос показан на рис. 35.
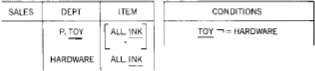
Рис. 35. Выборка с использованием блока условий, включающая "связи множеств", см. результат запроса
Несмотря на то что простая связь может быть выражена путем использования
одного элемента примера в двух или более строках, в связи множеств необходимо
различать равенство множеств и вхождение одного множества в другое.
Первое достигается указанием идентичных связей множеств, как показано на
рис. 34, второе – использованием звездочки.
В общем случае скобочное выражение может содержать одно или более множеств,
а также произвольное количество единичных элементов примера и константных
элементов. В него также может входить или не входить единичная звездочка.
Например, допустимым является следующее скобочное выражение:

В то же время выражение
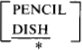
не является правильным, поскольку оно не содержит множества.
Вставки, удаления, модификации
Вставки (I.), удаления (D.), модификации (U.) выполняются в том же стиле,
что и операции выборки. Основное различие заключается в использовании операторов
I., D. и U. вместо P., который употребляется в выражениях запросов. Этот
раздел состоит из двух частей: простые вставки, удаления
и модификации; операции, зависящие от запроса. Термин "простая"
относится к операции, включающей только константные элементы.
Простая вставка. Вставить в таблицу служащих нового служащего
отдела игрушек по имени Джонс (Jones) зарплата которого составляет $10000, а менеджером является Генри (Henry). Эта операция показана на рис. 36. Так же, как оператор
P., когда он используется для целой строки, оператор I. применяется ко всей строке. Пустое поле при выполнении вставки интерпретируется как null-значение с тем ограничением, что не допускается ввод null-значений в поля первичного ключа; на рис. 36 это поле NAME. Такое ограничение согласуется с реляционной моделью
[5, 6] в том отношении, что поле первичного ключа должно однозначно идентифицировать
запись (кортеж). (Спецификация поля первичного ключа показана ниже на рис.
45.)

Рис. 36. Простая вставка
Простое удаление. Удалить информацию обо всех служащих отдела
игрушек. Эта операция показана на рис. 37. В этом случае удаляются
все записи, которые содержат значение TOY в поле DEPT. Разумеется, допускается
заполнение полей NAME, SAL, MGR элементами примера.

Рис. 37. Простое удаление
Простая модификация. Установить в качестве нового значения зарплаты Генри (Henry) $50000. Эта операция показана на рис. 38. Query-by-Example
не позволяет изменять поле(я) первичного ключа. В примере на рис. 38 новое
значение зарплаты Генри устанавливается независимо от прежнего значения
этого поля. Поле(я) первичного ключа должно(ы) обязательно специфицироваться
для обеспечения уникальности. Пустое поле означает, что никакая модификация
не требуется. Если требуется изменить содержимое поля на null-значение, то
следует ввести слово NULL или специальный определяемый пользователем
символ; способ определения такого символа описан ниже.

Рис. 38. Простая модификация
Вставка, зависящая от выборки. Вставить в таблицу служащих нового
сотрудника отдела игрушек c именем Генри (Henry), менеджером которого является Ли (Lee), а зарплата
такая же, как у служащего с именем Льюис (Lewis). Эта операция представлена
на рис. 39. Это пример вставки, зависящей от выборки, поскольку система
должна сначала произвести произвести запрос к базе данных для нахождения зарплаты Льюиса, а затем
скопировать полученное значение для Генри. Хотя последовательность строк при формулировании операции несущественна,
в ней присутствует неявное упорядочение выполнения – вставку нельзя завершить
до выполнения запроса.

Рис. 39. Вставка, зависящая от выборки
Удаление, зависящее от выборки. Удалить всех служащих, работающих
в отделе продажи ручек. Эта операция показана на рис.
40. Заполнение поля NAME, SAL, MGR элементами примера здесь не требуется, хотя и не запрещается.
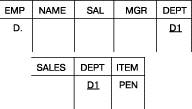
Рис. 40. Удаление, зависящее от выборки
Модификации, зависящие от выборки. Часто требуется модифицировать некоторое поле на основе его предыдущего значения. Это делается неявным образом. Пример: повысить зарплаты служащих отдела игрушек на 10
процентов. Эта операция показана на рис. 41. Выражение в
поле SAL в строке, содержащей U. задает новое значение
зарплаты; вторая строка специфицирует выборку прежнего значения. Операцию
можно переформулировать следующим образом: выбрать запись со значением
TOY в поле DEPT, найти значение поля зарплаты S1 и изменить его
на новое, равное 1,1*S1.

Рис. 41. Модификации, зависящие от выборки
Поскольку результатом выборки из отношения (таблицы) также является некоторое отношение (таблица), то пользователь может оперировать непосредственно с такой таблицей.
Например, получив результат выборки всех служащих отдела игрушек, он может
удалить любую запись, поставив напротив нее символ операции D. и нажав
клавишу ENTER.
Создание таблицы
Создание таблицы в языке Query-by-Example выполняется в том же стиле,
что и описанные ранее операции. Таблица определяется при помощи схематических таблиц
с константными элементами и элементами примера. Пользователю предоставляются
средства для создания новых таблиц и расширения существующих, для определения
моментальных снимков (snapshot), представляющих собой выборки данных из нескольких таблиц,
выполненные в определенные моменты времени, или динамических представлений (view) данных,
выбираемых из множества таблиц. Все эти операции выполняются
неявно, без использования специальных ключевых слов, как это было в более
ранних версиях языка [2].
Создание новой таблицы. На рис. 42 продемонстрировано создание
таблицы с именем EMP и столбцами NAME, SAL, MGR, DEPT. Начиная с пустой схематической таблицы (как при формулировании запроса), пользователь заполняет заголовки
именами полей. Оператор I. справа от EMP относится ко всей строке заголовков
столбцов.

Рис. 42. Создание заголовков столбцов новой таблицы
Для спецификации типов данных, размеров, доменов, ключей и т.д. используются атрибуты строк (ключевые слова). Для упрощения работы
пользователя эти атрибуты подсоединяются ко всем схематическим таблицам, и пользователю не нужно
вставлять их самому. Например, он может запросить имена атрибутов, как
это показано на рис. 43. Данная операция создает новую таблицу и затем
выполняет вывод всех атрибутов строк в системе. Результат этого оператора
показан на рис. 44. Пользователь затем определяет атрибуты таблицы, заполняя соответствующие
строки схематической таблицы, как показано на рис. 45. Поскольку атрибуты строк уже встроены в эту таблицу, вводить I. справа от них не требуется, но это и не повредит.
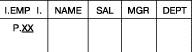
Рис. 43. Выборка имен атрибутов строк
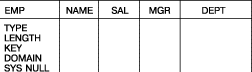
Рис. 44. Отображение имен атрибутов строк
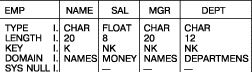
Рис. 45. Определения атрибутов
Ниже приведены описания атрибутов строк для таблиц.
- TYPE задает тип элемента данных, например, CHAR, FLOAT, FIXED и т.д.
- LENGTH задает длину соответстующего поля. (По умолчанию ширина равна длине заголовка
столбца.)
- KEY специфицирует поля, которые должны считаться
полями первичного ключа. (K обозначает Key – ключ, NK означает NonKey –
не ключ.) Как уже говорилось, поля первичного ключа не могут содержать null-значения,
а также значения-дубликаты. Для полей, специфицированных как ключевые,
гарантируется поддержка этих ограничений. Система также не позволяет изменять
значения этих полей.
- DOMAIN задает имя домена, т.е. множества значений, из которого берутся значения элементой данных. Например, данные столбцов NAME и MGR
берутся из домена NAMES. Спецификация атрибута DOMAIN полезна в тех случаях,
когда нужно знать, какие столбцы принадлежат к одному и тому же домену.
Для этого не всегда оказываются достаточными имена столбцов. Например, столбцы NAME
и MGR в таблице EMP определены на одном и том же домене. Следовательно, элементы
NAME и MGR могут быть связаны.
- SYSNULL (System Null) задает необязательный символ, обозначающий системное
null-значение. В данном примере используется символ "–".
Задав значения всех или части атрибутов из примера на рис.
45, пользователь может в той же самой схематической таблице ввести данные. Вставив
данные, можно через ту же схематическую таблицу формулировать запросы, относящиеся как к каталогу определения
данных, так и к самим данным.
Расширение таблицы. Владелец таблицы может расширить ее определение в той же манере, как при создании новой таблицы. Например, можно добавить к таблице EMP столбец COMMISSION. Сначала пользователь
запрашивает из таблицы EMP все данные, относящиеся к атрибутам строк (рис. 46). Результатом
этого запроса будет полный каталог таблицы, как он был определен ранее.
Затем пользователь вставляет имя нового столбца и новые значения значения
атрибутов, как показано на рис. 47. Если в данной таблице уже присутствуют данные, то считается, что в существующих строках столбец COMMISSION содержит null-значения до тех пор, пока
пользователь не модифицирует таблицу.
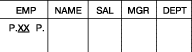
Рис. 46. Выборка данных, касающихся атрибутов строк
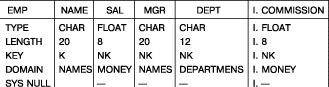
Рис. 47. Определение нового столбца в таблице
Модификация каталога таблицы. Оператор U. изменяет каталог таблицы
– будь то заголовки или спецификации атрибутов – подобно тому, как при помощи оператора
I. осуществляется вставка. Например, если нужно изменить имя таблицы с
EMP на EMP1, то указать U. перед именем таблицы оператор и ввести
новое имя поверх старого. Нажатие клавиши ENTER приведет к изменению имени таблицы.
Удаление информации из каталога таблицы и ликвидация таблицы. Оператор D. используется для удаления элементов каталога точно так же, как и для удаления обычных
данных. Например, поместив оператор D. в запись, содержащую спецификации ключевых/неключевых
полей, вы удалите эти спецификации.
Чтобы уничтожить столбец таблицы, достаточно указать D. перед
его именем. Фактически, это является сокращенным способом
удаления всех данных столбца, а затем и имени столбца. Аналогично,
указание оператора D. перед именем таблицы является сокращенным способом удаления всех строк таблицы, информации каталога, заголовков столбцов
и имени таблицы.
Создание моментального снимка (snapshot). Ранее мы показали, как можно получить новую таблицу,
состоящую из данных других таблиц. Эта таблица отображалась на экране,
но не сохранялась системой. Пользователь может сохранить такую таблицу,
создав для нее заголовок (как при создании новой таблицы).
Воспроизведем пример, показанный на рис. 19,
но сохраним результирующую таблицу под именем SS, определив заголовки ее
столбцов: DEPT и SUPPLIER. Это показано на рис. 48.
Таблица SS является моментальным снимком данных, хранившихся в исходных таблицах
в момент его создания. Поскольку теперь это новая таблица в нашей базе
данных, то по отношению к ней можно выполнять операции вставки, удаления,
модификации.

Рис. 48. Создание моментального снимка
Создание представления (view). Часто возникает потребность создать одну
таблицу на основе нескольких других, в которой бы динамически отражались
изменения данных из исходных таблиц. Такая таблица называется представлением;
в представлении отображаются все изменения, производимые в таблицах, из
которых оно получено. Чтобы создать представление, нужно
указать перед именем таблицы ключевое слово VIEW, что отличает эту операцию его от создания
моментального снимка.
Воспроизведем предыдущий пример, но вместо моментального снимка создадим представление с
именем ST, как показано на рис. 49. Данные представления физически не хранятся
в базе данных. В системе хранятся лишь указатели его на исходные составные
части, а данные материализуются лишь тогда, когда пользователь адресует запрос к этому представлению.

Рис. 49. Создание представления.
Заключение
В статье приведен обзор средств языка Query-by-Example для выполнения
выборки, манипулирования и определения данных. Одно из уникальных свойств языка
заключается в том, что для его первоначального освоения и использования
достаточно освоить лишь минимальное число основных понятий.
В отличие от англоподобных языков, где пользователь должен придерживаться
определенной фразовой структуры, в среде Query-by-Example можно ввести
любое выражение, если только оно синтаксически
корректно. Иначе говоря, поскольку элементы привязаны к схематическим таблицам, пользователь имеет возможность вводить лишь допустимые запросы. С другой стороны, в англоподобных языках ползователь может сформулировать запрос, не соответствующий фразовой структуре языка.
Поскольку порядок заполнения таблиц неважен, то формулировании операции
предоставляется множество степеней свободы.
Мы показали, как пользователь может строить запрос, постепенно доопределяя
новые условия; таким образом, можно постепенно переходить от простых запросов
к более сложным.
Операции выборки, манипулирования, определения данных выполняются единообразно,
с минимальными различиями в синтаксических правилах.
Приложение
Ниже приведено содержимое таблиц базы данных, которая использовалась в примерах этой статьи.
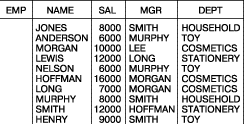
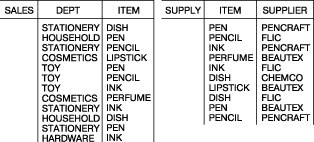

Далее следуют ответы к некоторым запросам, приведенным в тексте.

Результат запроса с рис. 5

Результат запроса с рис. 6

Результат запроса с рис. 7

Результат запроса с рис. 10

Результат запроса с
рис. 11

Результат запроса с
рис. 12

Результат запроса с
рис. 13

Результат запроса с
рис. 14

Результат запроса с
рис. 15

Результат запроса с
рис. 16

Результат запроса с
рис. 17

Результат запроса с
рис. 18

Результат запроса с
рис. 19
Запрос с рис. 20 не соответствует примерной базе данных.

Результат запроса с
рис. 21

Результат запроса с
рис. 22

Результат запроса с
рис. 23

Результат запроса с
рис. 26

Результат запроса с
рис. 27

Результат запроса с
рис. 28

Результат запроса с
рис. 29

Результат запроса с
рис. 30

Результат запроса с
рис. 31

Результат запроса с
рис. 32

Результат запроса с
рис. 33

Результат запроса с
рис. 34

Результат запроса с
рис. 35
Благодарности
Автор выражает признательность С.П. де Йонгу (S.P. deJong) и К.К. Нибуру (K.K. Nieburh) за их полезные
предложения в процессе разработки Query-by-Example. Автор также благодарен С.Е. Смиту (S.E. Smith), Р.Р. Джонсу (R.R. Jones) и Р. Дж. Берду (R.J. Byrd) за полезные обсуждения.
Литература
1. M.M. Zloof, "Query by Example", AFIPS Conference Proceedings,
National Computer Conference 44, 431-438 (1975).
2. M.M. Zloof, "Query by Example. The Invocation and Definition
of Tables and Forms", Proceedings of The International Conference
on Very Large Data Bases, Boston, Massachusetts, September 22-24, 1975,
pp. 1-24.
3. M.M. Zloof, "Query-by-Example: Operations on the Transitive
Closure", Research Report RC 5526, IBM Thomas J. Watson Research Center,
Yorktown Heights, New York, 1975.
4. M.M. Zloof, "Query-by-Example: Operation on Hierarchical
Data Bases", AFIPS Conference Proceedings, National Computer Conference
45, 845-853 (1976).
5. E.F. Codd, "A Relational Model of Data for Large Shared Data
Banks", Communications of the ACM 13, No.6, 377-387 (1970). Перевод на русский язык.
6. E.F. Codd, "Further Normalization of the Data Base Relational
Model", Courant Computer Science Symposia Vol.6, Data Base Systems,
Prentice-Hall, Inc., New York, NY (1971).
7. J.C. Thomas and J.D. Gould, "A Psychological Study of Query
by Example", Proceedings of the National Computer Conference 44, 439-445
(1975).
8. D.D. Chamberlin et al., "SEQUEL 2: A Unified Approach to
Data Definition, Manipulation and Control", IBM Journal of Research
and Development 20, 560-575 (1976). Перевод на русский язык
9. G.D. Held, M.R. Stonebraker, and E. Wang, "INGRES: A Relational
Data Base System", Proceedings of the National Computer Conference
44, (1975).
10. C.J. Date, An Introduction to Data Base Systems, Addison-Wesley
Publishing Co., Inc., Reading, MA (second edition , 1977).
11. K.E. Niebuhr, and S.E. Smith, "Implementation of Query-by-Example
on VM/370", Research Report, IBM Thomas J. Watson Research Center,
Yorktown Heights, New York, in preparation.
12. M.M. Zloof, "Query-by-Example: A Data Base Management Language",
IBM Research Report available upon request from the author, IBM Thomas
J. Watson Research Center, Yorktown Heights, New York.
13. M.M. Zloof and S.P. deJong, "The system for business automation
(SBA): Programming Language", Communications of the ACM 20, No.6,
385-396.
14. S.P. deJong and M.M. Zloof, "Application design within the
system for business automation (SBA)", Proceedings of the Twelfth
Design Automation Conference, Boston, Massachusetts, June, 1975, pp.69-76.

