Оценочная оптимизация для магии: алгебра и реализация
Правин Сешарди (Praveen Seshadri, Univ. of Wisconsin, Madison)
Джозеф Хеллерстейн (Joseph M. Hellerstein, Univ. of California, Berkeley)
Хамид Пирамеш (Hamid Pirahesh, IBM Almaden Research Ctr.)
Клифф Леюнг (T. Y. Cliff Leung, IBM Santa Teresa Lab.)
Раджу Рамакришнан (Raghu Ramakrishnan, Univ. of Wisconsin, Madison)
Дивеш Сривастава (Divesh Srivastava, AT&T Research)
Питер Стюки (Peter J. Stuckey, Univ. of Melbourne)
С. Сударшан (S. Sudarshan, IIT, Bombay)
SIGMOD Conference 1996: 435-446
Перевод: Сергей Кузнецов
3. Магические множества и оптимизация соединений
В этом разделе мы опишем, каким образом выбор вариантов перезаписи на основе магических множеств можно рассматривать как часть фазы оптимизации соединений оптимизатора запросов.
3.1 Букварь по оптимизации соединений
Оптимизатор запросов определяет эффективный порядок, в котором следует производить соединения N отношений, и метод, используемый для каждого соединения. Поскольку операция соединения ассоциативна и коммутативна, имеется обширное пространство из O((2(N-1))!/(N-1)!) возможных порядков соединений [GHK92]. Поскольку это пространство недопустимо обширно для целей анализа даже для небольших значений N, в большинстве практических алгоритмов оптимизации соединений [SAC+79, IK84, KBZ86] анализируются ограниченные области этого пространства. У всех алгоритмов имеется одна общая черта: на каждом шаге в них рассматриваются различные двухместные соединения, и для каждого соединения анализируется стоимость применения различных методов соединения.
3.2 Упорядочение соединений и SIPS
Разъясним теперь соответствие между перезаписью на основе магических множеств и упорядочением соединений. Рассмотрим исходный запрос на рис. 1. На рис. 1 графически изображены шесть возможных вариантов порядка соединений Emp E, Dept D и DepAvgSal V; предикаты выборки для краткости опущены.
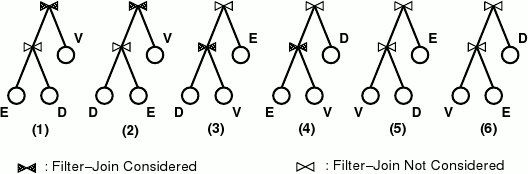
Рис. 4. Некоторые возможные порядки соединений
Сначала рассмотрим планы 1 и 2; результат соединения E и D используется как внешнее отношение в завершающем соединении с представлением V (последнее соединение на рисунке затенено, поскольку эта операция представляет интерес). Как это связано с перезаписью на основе магических множеств? В примере 2 соединение E и D используется как таблица PartialResult, из которой материализуется магическое множество для представления V. Имеется соответствие между составным внешним отношением в плане соединения и таблицей PartialResult, используемой в магической перезаписи. Следовательно, планы 1 и 2 «соответствуют» этому конкретному варианту перезаписи на основе магических множеств. Аналогично, план 3 «соответствует» перезаписи на основе магических множеств, в которой в качестве таблицы PartialResult используется только отношение Dept D. План 4 «соответствует» перезаписи, в которой которой в качестве таблицы PartialResult используется только отношение Emp E. Наконец, планы 5 и 6 «соответствуют» исходному запросу (т.е. перезапись на основе магических множеств не производится).
Мы используем это соответствие для исследования экспоненциального пространство выбора SIPS для перезаписи на основе магических множеств. Мы предлагаем включить анализ вариантов перезаписи на основе магических множеств в оптимизацию соединений путем моделирования магической перезаписи как метода соединения, допуская, тем самым, внедрение нашего подхода в любой оценочный алгоритм оптимизации соединений без существенного изменения кода оптимизатора. Основным изменением оптимизатора является добавление нового метода соединения, и это воздействует на сложность оптимизации только через константный множитель.
3.3 Перезапись на основе магических множеств как метод соединения
Мы определяем Filter-Join отношений R и S следующим образом:
Определение 3.1 (R Filter-Join S) R называется внешним отношением, а S – внутренним отношением метода Filter-Join. Создается надмножество (без дубликатов) значений атрибута соединения R и используется как фильтр для ограничения кортежей S, к которым производится доступ. Ограниченное отношение из кортежей S затем соединяется с отношением R (с использованием любого другого доступного алгоритма соединения).
Этот метод соединения похож на хорошо известную операцию полусоединения [BGW+81], и эта схожесть используется в разд. 7 при моделировании магических множеств с использованием операции Θ-полусоединения. Важным отличием является то, что полусоединения обычно применяются к хранимым отношениям, в то время как перезапись на основе магических множеств работает с представлениями.
Предположим, что оптимизатор запросов, дополненный возможностью рассмотрения Filterjoin как метода соединения, вызывается для обработки запроса с соединением N отношений. На некоторой промежуточной стадии оптимизатор оценивает стоимость некоторого соединения. Внешнее соединение является составным отношением вида (R1 ⊳⊲ R2 ⊳⊲ … ⊳⊲ R(k-1)), и внутренним является одиночное отношение Rk, для которого можно применить перезапись на основе магических множеств (т.е. Rk является представлением). Наименьшее фильтрующее множество будет происходить из проекции (без дубликатов) всего составного внешнего отношения. Менее ограничительные фильтрующие множества могли бы создаваться путем использования в качестве PartialResult соединения любого подмножества таблиц составного внешнего отношения. После того как сделан конкретный выбор PartialResult, само фильтрующее множество может быть представлено точно или с некоторыми потерями (т.е. взамен может использоваться некоторое надмножество фильтрующего множества) путем опускания некоторых атрибутов соединения.3
Имеется много различных вариантов выбора для PartialResult и для фильтрующего множества. Как мы показали в Примере 2, фильтрующее множество используется для ограничения внутреннего отношения путем добавления этого множества в раздел FROM внутреннего блока запроса. Даже после выбора некоторого PartialResult и некоторого фильтрующего множества модифицированная версия внутреннего реляционного представления (LimitedDepAvgSal на рис. 2) нуждается в планировании. Ясно, что если эти варианты выбора исследуются для каждого возможного соединения, включающего Rk, то мы проанализируем все возможные комбинации SIPS. Однако мы не склонны к тому, чтобы подвергать риску сложность оптимизатора ради оптимизирующей перезаписи на основе магических множеств. Из этого следует, что если мы предлагаем анализировать возможные варианты выбора для каждого Filterjoin, то это должно делаться за константное время. Поэтому наша следующая задача состоит в сокращении пространства поиска до некоторых приемлемых размеров.
3.4 Ограничение пространства поиска
Пространство опций для одного конкретного Filterjoin является обширным по трем причинам:
- Имеется много возможных вариантов выбора для PartialResult. Вообще говоря, если составное внешнее отношение образуется путем соединения (k-1)-го отношения, то любое подмножество из 2(k-1)-1 непустых подмножеств множества этих отношений могло бы использоваться в качестве основы PartialResult.
- При наличии конкретного PartialResult имеется много возможных вариантов выбора для фильтрующего множества. Вообще говоря, если имеется m атрибутов соединения, то любое подмножество из 2m-1 непустых подмножеств множества этих атрибутов могло бы использоваться в качестве основы фильтрующего множества. Кроме того, могло бы иметься несколько возможных реализаций фильтрующего множества (например, как отношение или как фильтр Блюма).
- При наличии конкретного фильтрующего множества имеется обширное пространство возможных планов для внутреннего реляционного представления, модифицированного путем добавления фильтрующего множества.
Пункты (1) и (2) приводят к полному диапазону SIPS, обсуждавшемуся в [BR91]. Перед лицом громадных пространств поиска мы заимствуем два хорошо известных и широко используемых метода оптимизации: (a) На пространстве поиска для Filterjoin мы применяем эвристические ограничения. Будем надеяться, что большая часть пространства поиска, отбрасываемая эвристиками, не представляет интереса. (b) Мы принимаем предположения, позволяющие нам использовать приемлемо точные «интуитивные оценки» («guesstimates») стоимости для частей пространства поиска вместо того, чтобы действительно анализировать эти части и вычислять более точные оценки.
Эвристика 1: Отношение PartialResult должно быть полным внешним отношением.
Эвристика 2: Будет рассматриваться небольшое и константное число реализаций фильтрующего множества.
Тем самым, выбор вариантов для PartialResult и фильтрующего множества может быть произведен за константное время. Наконец, мы принимаем следующее предположение, которое будет обосновано в следующем разделе.
Предположение 1: Стоимость и мощность результата Filter-join могут быть оценены за константное время.
Если предположение 1 справедливо, то порядок сложности оптимизации соединений не изменяется, хотя Filterjoin учитывается в качестве варианта. Для каждого конкретного соединения в методе Filterjoin рассматривается только одно отношение PartialResult и небольшое константное число фильтрующих множеств, и стоимость Filterjoin определяется за константное время. Весь запрос оптимизируется, и рассматривается наиболее дешевый полный план. Если он не содержит Filterjoin, то перезапись на основе магических множеств применять не следует; иначе производится перезапись с использованием SIPS, специфицируемую составным внешним отношением Filterjoin.
| JoinCostp | Стоимость выполнения соединений, требуемых для генерации PartialResult P |
| ProductionCostp | Стоимость материализации PartialResult P |
| ProjCostF | Стоимость проецирования P для генерации фильтрующего множества F |
| FilterCostRk | Стоимость генерации Rk и его ограничения с использованием фильтрующего множества |
| FinalJoinCost | Стоимость выполнения завершающего соединения внешнего отношения и Rk’ |
Таб. 1. Компоненты стоимости Filterjoin
4. Оценка стоимости и мощности
Теперь мы выведем формулу для оценки стоимости применения метода Filterjoin. Заметим, что эта оценочная формула должна вычисляться за константное время. Предположим, что в оцениваемом Filterjoin имеются (R1 ⊳⊲ R2 ⊳⊲ … ⊳⊲ R(k-1)) как внешнее отношение и Rk как внутреннее отношение. Стоимость вычисления соединения можно разбить на компоненты, показанные в таб. 1 и разъясняемые ниже. Общая стоимость Filterjoin является суммой этих компонентов.
JoinCostP + ProductionCostP + ProjCostF +
FilterCostRk + FinalJoinCost
JoinCostP: Это стоимость внешнего отношения, которая уже вычислялась как часть алгоритма оптимизации.
ProductionCostP: P требуется материализовать, поскольку это отношение используется как для генерации фильтрующего множества, так и в соединении верхнего уровня. Стоимость материализации PartialResult – это простая функция от мощности P. Поскольку эта мощность уже известна (т.е. уже оценена оптимизатором), можно вычислить стоимость материализации. Вместо того чтобы создавать временное отношение P, можно было бы вычислять повторно. Стоимость повторного вычисления P является такой же, как и JoinCostP. В качестве ProductionCostP выбирается минимум из стоимости материализации и стоимости повторного вычисления.
ProjCostF: Стоимость выполнения проецирования P (с устранением дубликатов) для генерации фильтрующего множества F зависит от мощности P. Эта стоимость также зависит от физических характеристик плана для P (например, отсортировано P или нет) и от того, можно ли совместить проецирования с генерацией P. У оптимизатора имеется вся необходимая информация для оценивания ProjCostF.
FilterCostRk: Это стоимость генерации отфильтрованной версии Rk с использованием фильтрующего множества F (пусть отфильтрованное отношение называется Rk’). Обсуждение метода вычисления стоимости и мощности Rk’ приводится после этих определений.
FinalJoinCost: Это считается просто. Мощность внешнего отношения известна. Мощность отфильтрованного внутреннего отношения только что подсчитана. Для определения наиболее дешевого способа выполнения завершающего соединения можно применить оценочные формулы других доступных методов соединения.
Заметим, что все (кроме одного) компоненты стоимости можно вычислить за константное время с использованием общеизвестных оценочных формул, уже используемых в существующих оценочных оптимизаторах. В следующем разделе показывается, как можно оценить за константное время стоимость и мощность отфильтрованного отношения Rk (FilterCostRk).
4.1 Оценивание FilterCostRk
Чтобы моделировать перезапись на основе магических множеств как Filterjoin и получать оценку его стоимости, нам не требуется явно планировать модифицированное внутреннее представление. Нам нужно всего лишь оценить мощность модифицированного представления и стоимость наилучшего плана его генерирования. На этой стадии не нужен реальный план, потому что в архитектуре оптимизации, представленной в разд. 2.2, требуется второй проход оптимизации после выполнения магической перезаписи. Размер фильтрующего воздействия фильтрующего множества (т.е. его селективность) зависит от его мощности. Поскольку точно оценить мощность проекции трудно [LNSS93], в существующих оптимизаторах принимаются некоторые предположения для оценки мощности проекции [Yao77].
Нам требуется параметризованный план для ограничения Rk, параметром которого является фильтрующее множество. Далее, нам хотелось бы иметь возможность генерировать параметризуемый план только один раз. Каждый конкретный план получается путем параметризации плана конкретным фильтрующим множеством. По экземпляру плана можно получить его стоимость и мощность результата. Поскольку параметризуемая оптимизация запросов является темой проводимого в данное время исследования [INSS92], результаты носят слишком предварительный характер, чтобы их можно было применить к нашей проблеме. Нам нужен конкретный метод для работы с параметризацией в нашем контексте. Тривиальное решение состоит в том, чтобы выполнять вложенный вызов оптимизатора при создании каждого экземпляра плана. Однако время создания каждого экземпляра должно быть небольшой константой, а поскольку Rk может сложным выражением, включающим несколько соединений, этого добиться невозможно.
Заметим, что мощность отфильтрованного внутреннего отношения Rk’ является функцией только от селективности фильтрующего множества (которая известна) и не зависит от физического размера или реализации фильтрующего множества. После того как мощность Rk’ подсчитана для нескольких значений селективности F, можно соединить полученные точки линией, определяя тем самым функцию мощности Rk’ для всех фильтрующих множеств. В действительности, в своей реализации мы решили вычислять всего две точки и производить прямую линейную интерполяцию. Выбранные точки соответствуют селективности 0 (когда мощность результата, очевидно, равняется нулю) и 1 (когда мощность результата совпадает с мощностью не модифицированного представления Rk).
Оценивание стоимости Rk’ является более сложным, потому что функции стоимости соединений могут быть нелинейными, особенно в границах размеров, когда отношение перестает помещаться в основной памяти, доступной для некоторой операции. Поэтому простая линейная интерполяция может быть неточной. Один из подходов состоит в том, чтобы определить несколько классов эквивалентности на основе размера магического множества (например, «меньше размера буфера» и «больше размера буфера») и внутри каждого класса использовать прямую линейную интерполяцию. Следует заметить, что на практике фильтрующие множества обычно бывают небольшими, поскольку содержат проекцию (без дубликатов) только на столбец соединения. Поэтому простая линейная интерполяция может выполняться удовлетворительным образом; на самом деле, в своем прототипной реализации мы использовали именно этот метод.
4.2 Пространственная сложность оптимизации
Должно быть ясно, почему пространственная сложность не является предметом этой работы. При оптимизации основного блока запроса теперь нужно попробовать применить дополнительный метод для каждого анализируемого соединения. Однако для этого не требуется сохранять какие-либо дополнительные планы. Следовательно, рассмотрение дополнительного метода соединения не изменяет порядок пространственной сложности оптимизатора. Что касается «параметризуемого» планирования сложных представлений, то при нашем подходе оптимизируется отфильтрованная версия сложного запроса для небольшого константного числа классов эквивалентности. Следовательно, и это не приводит к изменению порядка пространственной сложности.
4.3 Как исчезает сложность?
Хотя имеется экспоненциальное число возможных вариантов перезаписи, мы ухитряемся произвести поиск наилучшего плана за два вызова оптимизатора: один – для нахождения наилучшей SIPS, а другой – для оптимизации запроса, перезаписанного на основе этой SIPS. Важно понимать, как исчезает исходная сложность; здесь нет никакой магии! В разд. 3.4 накладываются некоторые ограничения на исследуемое пространство поиска. Например, для примера из разд. 2 не будет оцениваться стоимость следующего варианта магической перезаписи: Dept используется как таблица PartialResult, и отфильтрованная версия представления LimitedDepAvgSal сначала соединяется с Emp, а потом с Dept. Другой используемый метод состоял в получении «хорошей оценки» стоимости параметризуемых планов вместо их явного вычисления. Хотя наши оценки являются, несомненно, приблизительными, это существенно лучше полного отсутствия оценок (а именно таково текущее состояние дел с алгоритмами, подобными магическим множествам). Коротко говоря, мы утверждаем, что, весьма вероятно, использование этих методов улучшит результаты сегодняшних оптимизаторов запросов. Реализация в системе баз данных DB2 C/S V2 эмпирически подтверждает верность этого утверждения.
5. Реализация в DB2 C/S V2
Реализация алгоритма, представленного в предыдущих разделах, требуется для ответа на следующие вопросы: (1) Насколько возможно внедрить такой алгоритм в реальную систему баз данных? (2) Действительно ли алгоритм находит хорошие планы (т.е. работает ли он так, как ожидалось)?
5.1 Осуществимость
Мы прототипировали предложенную оценочную оптимизацию на внутренней версии IBM системы баз данных DB2 C/S V2. Хотя в оптимизаторе запросов поддерживаются различные стратегии поиска, мы сосредоточились на стратегии, в которой используется общеизвестный алгоритм оптимизации методом динамического программирования «слева-вглубь». Выбрав полностью зрелую систему, мы были вынуждены столкнуться со всеми практическими ограничениями, существующими в реальной СУБД. Один из нас работал на DB2 C/S V2 над созданием прототипа перезаписи но основе магических множеств. Несмотря на исходное отсутствие знакомства с кодом оптимизатора, модификации и измерения производительности были завершены за три месяца. Хотя требовались изменения во многих частях оптимизатора, реальное число строк добавленного кода на C++ составило меньше 1000. Мы полагаем, что это подтверждает возможность добавления метода Filterjoin к существующим оптимизаторам.
5.2 Эффективность
Мы изучали эффективность нашего алгоритма, используя контролируемые эксперименты, подробно описываемые в следующем разделе. Основное заключение состоит в том, что результаты вполне отвечают нашим ожиданиям. Оценочная оптимизация предотвращает использование перезаписи на основе магических множеств, когда этого делать не следует, и позволяет выбрать один из лучших вариантов, когда перезапись на основе магических множеств целесообразно применять. Более того, эти положительные результаты получены без изменения порядка сложности оптимизации.
5.3 Практический опыт
Мы обнаружили, что перезапись на основе магических множеств действует на оптимизатор запросов как «нагрузочные испытания» («stresstest»). Это связано с тем, что в данном методе используются общие подвыражения, проецирование с удалением дубликатов, временные отношения и другие элементы, которые обычно применяются только в сложных запросах поддержки принятия решений. Поэтому, наряду с тем, что оценка стоимости для перезаписи на основе магических множеств определенно осмысленна на логическом уровне, важно, чтобы оптимизатор правильно моделировал конструкции, используемые при перезаписи.
3 Другим способом введения избыточности является использования фильтра Блюма (Bloom filter) [Blo70] для реализации фильтрующего множества.