Определяются два вида абстракций, имеющих фундаментально важное
значение для проектирования и использования баз данных. Агрегация – это
абстракция,
которая превращает связь между объектами в некоторый агрегированный
объект.
Обобщение – это абстракция, превращающая класс объектов в родовой
объект.
Предполагается, что для всех объектов (индивидуальных, агрегатных,
родовых)
следует обеспечивать унифицированную интерпретацию в моделях реального
мира.
В качестве примитива для определения таких моделей разработан новый тип
данных, названный родовым. Модели, определяемые с помощью этого
примитива, структурируются как некоторое множество иерархий агрегации,
пересекающееся с некоторым множеством
иерархий обобщения. В точках пересечения появляются абстрактные
объекты.
Такая высокоуровневая структура обеспечивает некоторую дисциплину для
организации
реляционных баз данных. Она, в частности, дает возможность:
- интегрировать
и поддерживать важный класс представлений (view);
- обеспечивать при определенных
эволюционных изменениях стабильность данных и программ;
- значительно
легче понимать сложные модели и более естественным образом формулировать
запросы;
- использовать более семантичный подход к проектированию баз
данных;
- осуществлять дополнительную оптимизацию на более низких уровнях
реализации.
Родовой тип формализуется множеством инвариантных
свойств. Если абстракции должны сохраняться, то эти свойства должны
удовлетворяться всеми отношениями в базе данных. Предлагается
инициирующий механизм для
автоматической поддержки таких инвариантов во время выполнения операций
обновления.
Дается простое отображение иерархий агрегации/обобщения на структуры
наборов
CODASYL.
Ключевые слова и фразы: модель данных, реляционная база данных, проектирование
баз данных, агрегация, обобщение, абстракция данных, тип данных, ограничения
целостности, представление знаний.
1. Введение
Абстракция какой-либо системы представляет собой модель этой системы,
в которой намеренно опущены некоторые детали. Выбор тех деталей, которые
следует опустить, делается на основе анализа как преполагаемого приложения
этой абстракции, так и его пользователей. Цель состоит в том, чтобы дать возможность
пользователя обращать внимание на те детали системы, которые существенны
для данного приложения, а другие детали игнорировать.
В некоторых приложениях система может обладать слишком многими деталями, существенными для единственной абстракции, чтобы быть при этом интеллектуально
управляемой. Такую управляемость можно обеспечить
путем декомпозиции модели в иерархию абстракций. Иерархия позволяет вводить существенные детали управляемым
образом. Абстракции на любом заданном уровне
иерархии позволяют (временно) игнорировать многие существенные детали при
понимании абстракций на следующем более высоком уровне.
Одно из преимуществ такой "иерархии абстракций" заключается
в возможности доступа различных пользователей к модели на разных уровнях
абстракции. Так, например, если основная система является коммерческим
предприятием, пользователи-руководители могут иметь доступ
к глобальной информации, а конторские служащие – к детализированной информации.
Таким образом, единственная модель может совместно использоваться несколькими
различными пользователями без нарушения их требований к доступу. Другим
достоинством иерархии абстракций является повышенная стабильность модели
в процессе развития приложения или самой системы. Изменение некоторой детали,
игнорируемой на более высоких уровнях модели, не воздействует на
эти уровни. Конечно, некоторые изменения при этом будут распространяться
с нижнего уровня на верхний.
Отношение в реляционной схеме Кодда поддерживает две различные формы
абстракции. Мы называем эти формы абстракции "агрегацией" и "обобщением".
Агрегацией называется абстракция, в которой связь между объектами
рассматривается как объект более высокого уровня. При таком абстрагировании можно
игнорировать многие детали этой связи. Например, некоторая
связь между человеком, отелем и датой может быть абстрагирована как
объект "бронирование". Можно при этом мыслить о "бронировании",
не задумываясь о всех деталях базовой связи, например о номере
комнаты, фамилии агента по бронированию или продолжительности
бронирования.
Обобщением называется абстракция, в которой множество схожих объектов рассматривается
как некоторый родовой объект. При таком абстрагировании можно игнорировать
многие индивидуальные различия между объектами. Например, множество людей-служащих
может быть абстрагировано как родовой объект "служащий". В такой
абстракции не учитываются индивидуальные различия между служащими, например,
те факты, что служащие имеют различные фамилии, возраст и служебные
функции.
Если ввести соответствующую дисциплину структурирования, то
реляционная
схема Кодда может одновременно поддерживать как иерархии абстракций
агрегации,
так и иерархии абстракций обобщения. В предыдущей статье [4] мы
предложили
дисциплину структурирования, пригодную для абстракций агрегации. В
настоящей статье предлагается дисциплина структурирования для
абстракций обобщения,
и она интегрируется с дисциплиной, ранее предложенной для абстракций
агрегации.
Польза от такой дисциплины структурирования заключается в следующем:
- можно эффективно интегрировать и согласованным образом поддерживать абстракции (иногда называемые представлениями),
относящиеся к различным пользователям базы данных;
- при различных видах эволюционных изменений может обеспечиваться стабильность
моделей (иногда называемая независимостью данных);
- без значительной утраты интеллектуальной управляемости могут поддерживаться
сильно структурированные модели;
- может быть разработан более систематический подход к проектированию баз
данных и, в частности, процедур баз данных;
- становятся возможными более эффективные реализации, поскольку может
быть сделано больше предположений относительно структуры верхнего уровня.
В [4] мы сопоставляли примитивы для выражения абстракций агрегации,
которые обнаруживаются в языках программирования, с примитивами, требуемыми
в базах данных. Мы показали, как можно адаптировать Хоаровскую структуру декартова
произведения1)
[2], чтобы ее можно было использовать для определения реляционных
моделей. Такая адаптация приводит к некоторому пониманию роли абстракций
агрегации в базах данных. Настоящую работу можно рассматривать как
попытку адаптации к реляционным моделям структуры размеченного объединения
(discriminated union)2)
Хоара [2]. Эта адаптация, в свою очередь, приводит к пониманию роли абстракций
обобщения в базах данных.
Исследования в области баз данных касались, главным образом,
агрегации (например, для нормальных форм Кодда [1]), а обобщение при этом
в значительной мере игнорировалось. Причина заключалась, вероятно, в том,
что в простых моделях с обобщением можно обычно весьма удовлетворительно
обходиться, выбирая каждый раз специальный подход, подходящий к данному
конкретному случаю. Интересно, что исследования в области по базам знаний на основе подхода искусственного
интеллекта, напротив, в основном касались обобщения
(например, семантические сети Квиллиана [3]) в то время как агрегация совершенно
не использовалась. Объединяя агрегацию и обобщение в единую дисциплину
структурирования, мы взаимно обогащаем области баз данных и искусственного
интеллекта.
В разд. 2 разрабатывается философия представления
абстракций обобщения в реляционной схеме Кодда. Эта философия приводит
к мощной родовой (generic) структуре для определения реляционных моделей. Такая структура
описывается в разд. 3. Далее в разд.
4 исследуется, каким образом родовая структура может использоваться
для обработки различных ситуаций при моделировании. В разд. 5 обсуждаются пять свойств реляционной модели, которые должны оставаться
инвариантными во время выполнения операций обновления. Эти инвариантные свойства представляют
собой (частично) аксиоматическое определение введенной родовой структуры.
На основе семантических соображений разрабатывается набор правил для поддержки
этих инвариантов. В разд. 6 приводятся заключительные
замечания, касающиеся некоторых аспектов родовой структуры, включая
методы проектирования баз данных, техники реализации и языка доступа.
2. Абстракции обобщения
Цель этого раздела – разработка философской позиции относительно природы
и представления обобщений. Прежде всего мотивируется, почему так важно
представлять обобщения в моделях (аспектов) реального мира. Далее рассматриваются
иерархии обобщений и обсуждаются некоторые их свойства. Наконец, исследуется
представление обобщений как отношений Кодда.
Мы будем использовать термин "обобщение" в следующем смысле:
Обобщение – это абстракция, которая позволяет обобщенно представлять себе
некоторый класс индивидуальных объектов как единый именованный объект.
Обобщение является, вероятно, наиболее важным механизмом, которым мы располагаем
для концептуализации реального мира. По-видимому, оно представляет собой,
основу для овладения естественным языком – ребенок переходит от наблюдения за
конкретными собаками к модели собаки вообще. Эта абстракция позволяет нам делать прогнозы
о будущем на основе конкретных событий в прошлом – если этот огонь и этот
огонь обжег мне руку, то, вероятно, огонь вообще будет обжигать мне руку.
При проектировании баз данных для моделирования реального мира существенно,
чтобы схема базы данных обладала возможностью явного представления обобщений.
Благодаря этому будет обеспечиваться соответствие естественному языку соглашений об именовании
в модели, и пользователи получат возможность применять
обычные мысленные образы при своем взаимодействии с базой данных. В частности,
явное именование родовых объектов обеспечивает следующие возможности:
-
применение операций к родовым объектам;
- спецификацию атрибутов для
родовых объектов;
- спецификацию связей, в которых участвуют родовые объекты.
По существу, мы хотим, чтобы родовые объекты интерпретировались унифицированным
образом наряду с объектами всех других видов и обладали бы такими же возможностями.
Первая из указанных выше возможностей является достаточно ясной. Однако
для иллюстрации второй и третьей, вероятно, имеет смысл привести некоторые
примеры.
Предположим, что мы обобщаем некоторый класс индивидуальных объектов
в именованный
родовой объект. Информация, которая "резюмирует" атрибуты отдельных
объектов,
может быть присоединена в качестве атрибутов этого родового объекта.
Например,
поскольку все собаки имеют "острые зубы" и "четыре ноги",
эта информация может быть присоединена в качестве атрибута родового
объекта "собака". Эта информация могла бы быть присоединена избыточным
образом в качестве атрибутов
индивидуальных собак. Однако это затуманивает тот факт, что
эти атрибуты имеют собаки вообще, а не только упомянутые индивидуумы.
В качестве другого примера мы могли бы обобщить класс водителей грузовиков
в родовой объект "водитель грузовика". Нам может быть интересен не размер
зарплаты каждого конкретного водителя, а лишь средняя (минимальная, максимальная)
зарплата водителя грузовика вообще. Эта информация о зарплате может быть
отнесена как атрибут к родовому объекту "водитель грузовика".
Родовой объект, подобно индивидуальному, может участвовать в связях
с другими объектами. В качестве примера мы можем рассмотреть связь между "профессиями"
и примыкающими к ним "сообществами". К числе конкретных
профессий относятся "водитель грузовика", "computer
scientist" и "докторa", и все они являются родовыми
объектами. Эта связь, которая называется "принадлежность", представлена
в таблице I. Заметим, что "профессия"
– это обобщение класса, который включает "водителя грузовика",
"computer scientist" и "доктора".
Таблица I. Родовые объекты, участвующие в связи
Принадлежность:
|
Профессия
|
Сообщество *)
|
|
computer scientist
computer scientist
доктор
водитель грузовика
инженер-электрик
|
ACM
IEEE
AMA
Teamsters
IEEE
|
Исследуем теперь свойства иерархии родовых объектов. Воспользуемся
для этого конкретным примером. Предположим, что должна быть построена модель
для множества транспортных средств (vehicles), которыми владеют большие организации,
такие как правительственные учреждения или некоторая отрасль промышленности.
Эти средства очень разнотипны и включают, например, грузовики (truck),
подводные лодки (submarine), велосипеды (bicycle), вертолеты (helicopter).
На рис. 1 показан конкретный вариант декомпозиции "транспортного
средства" на родовые объекты более низкого уровня. Заметим, что
отдельные
транспортные средства при этом явно не представляются. Следует
представлять, что каждый родовой объект определяет некоторый класс
индивидуальных транспортных
средств. На рисунке видно, например, что "грузовик" (truck),
"велосипед" (bike) и автомобиль (car)
могут быть обобщены понятием "дорожное транспортное средство" (road
vehicle),
"дорожное транспортное средство" и "рельсовое транспортное средство"
(rail vehicle) – понятием
"наземное транспортное средство" (land vehicle), и, наконец, что
"наземное транспортное средство",
"воздушное транспортное средство" (air vehicle) и "водное транспортное
средство" (water vehicle) могут быть
обобщены понятием "транспортное средство".
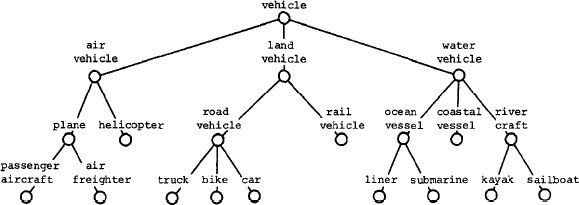
Рис. 1. Родовая иерархия транспортных средств
Пусть G – некоторый объект в родовой иерархии. Чтобы представить G как
отношение Кодда, мы должны выбрать множество атрибутов, которые являются
общими для всех индивидуумов в классе G. Например, в представление "транспортного средства"
мы можем включить атрибуты "идентификационный номер", "изготовитель",
"цена" и "вес". Эти атрибуты являются общими для всех
транспортных средств. В представление "дорожного транспортного средства"
мы можем включить все предыдущие атрибуты, а также и другие, такие как
"количество колес" и "давление в шинах". Эти атрибуты
являются общими для всех дорожных транспортных средств, однако последние
два атрибута не являются общими для всех транспортных средств. В представление
"грузовика" мы можем включить все предыдущие атрибуты и некоторые
другие, такие как "мощность двигателя в лошадиных силах" и "размер
кабины". Эти атрибуты являются общими для всех грузовиков, однако
два последних атрибута не являются общими для всех дорожных транспортных
средств.
Теперь конкретный грузовик будет являться членом каждого из классов
"транспортное средство", "дорожное транспортное средство" и "грузовик".
Однако значимые атрибуты этого грузовика будут изменяться
от класса к классу. Когда этот грузовик рассматривается как индивидуальное
транспортное средство, любые атрибуты, отличающие грузовики от других транспортных
средств, будут незначимыми. Если же данный грузовик рассматривается
как индивидуальное дорожное транспортное средство, будут незначимыми все атрибуты,
которые отличают грузовики от других дорожных транспортных средств.
В общем
случае, индивидуальный объект будет иметь тем больше значимых
атрибутов, чем ниже родовой уровень класса, в котором он предстает.
Назовем
G-атрибутами индивидуального объекта те атрибуты этого объекта, которые значимы для
класса G.
У родовой иерархии, показанной на рис. 1, имеются
две характеристики свойства, которые присущи не всем родовым иерархиям. Первая характеристика
состоит в том, что эта иерархия представляет собой дерево (т.е. никакой
родовой объект не является непосредственным потомком двух или более родовых
объектов). Вторая характеристика заключается в том, что непосредственные потомки
любого узла образуют взаимно-исключающие классы. Родовые иерархии, не обладающие
этими свойствами, показаны на рис. 2 и 3. Наш метод представления
родовых иерархий как отношений Кодда может справиться и с этими общими
формами родовой иерархии.
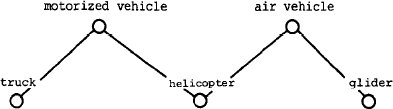
Рис. 2. Родовая иерархия, не являющаяся деревом
Рис. 3. Родовая иерархия, в которой непосредственные потомки узла не образуют взаимно-исключающие классы
Рис. 2 показывает, что объект "вертолет"
может быть обобщен двумя способами – как "моторизованное транспортное
средство" (motorized vehicle”)
либо как "воздушное транспортное средство" (air vehicle). Рис. 3
иллюстрирует декомпозицию
объекта "транспортное средство" на два различных вида родовых объектов.
Один
из этих видов связан с методом приведения транспортного средства в
движение
(ветер, человек, мотор). Другой вид связан с основной средой, через
которую или
по которой передвигается транспортное средство (воздушное пространство,
вода, земная поверхность). У некоторых этих объектов-потомков
отсутствуют
непересекающиеся классы. Например, некоторые транспортные средства и
являются
моторизованными, и передвигаются в воздухе. Следовательно, в классах
"моторизованное транспортное средство" и "воздушное транспортное
средство" содержатся некоторые общие члены.
Наш метод представления родовой иерархии требует, чтобы непосредственные
потомки любого узла разбивались на группы. Каждая группа должна содержать
родовые объекты, классы которых являются взаимно-исключающими. На практике
такое группирование обычно может быть весьма легко проделано из семантических
соображений. Например, потомки на рис. 3 могли бы
быть сгруппированы следующим образом: {транспортные средства, приводимые
в движение ветром; моторизованные транспортные средства; транспортные средства,
приводимые в движение человеком} и {воздушное транспортное средство; водное транспортное средство;
наземное транспортное средство}. Первая группа содержит взаимно-исключающие классы,
которые соответствуют альтернативным типам "системы обеспечения движения".
Вторая группа, в свою очередь, содержит взаимно-исключающие классы, которые
соответствуют различным типам "среды передвижения"3).
Назовем взаимно-исключающую группу родовых объектов с общим родителем
кластером. Будем говорить, что кластер принадлежит своему родительскому
родовому объекту. Например, мы можем говорить о двух кластерах, принадлежащих
объекту "транспортное средство" на рис. 3. У листовых узлов
в родовой иерархии отсутствуют принадлежащие им кластеры. На рис.
1 каждому родовому нелистовому объекту принадлежит в точности один
кластер. На рис. 2 у кластера, принадлежащему "моторизованному транспортному средству", и у кластера, принадлежащего
"воздушному транспортному средству", имеется общий элемент – вертолет.
Мы считаем необходимым дать каждому кластеру некоторое (осмысленное)
имя. Это имя следует выбирать таким образом, чтобы описывало родовые
объекты в данном кластере. Например, в качестве имени кластера
{транспортные средства, приводимые в движение ветром; моторизованные
транспортные
средства; транспортные средства, приводимые в движение человеком} можно
было бы использовать "категорию двигателя". Для кластера {воздушное
транспортное средство; водное транспортное средство; наземное
транспортное средство} может быть выбрано имя
"категория среды передвижения".
Опишем теперь метод представления родовой иерархии как иерархии отношений
Кодда. Для каждого родового объекта в иерархии будет создаваться одно отношение.
Пусть G – родовой объект такой, что
- I есть класс конкретных объектов,
ассоциированных с G;
- A1, ..., An
– G-атрибуты и
- C1, ..., Cm
– имена кластеров, принадлежащих G.
Тогда G представляется следующим отношением
Кодда:
|
A 1
|
...
|
A n
|
C1
|
...
|
Cm
|
...
v 1
...
|
...
...
...
|
...
v n
...
|
...
vn+1
...
|
...
...
...
|
...
vn+m
...
|
где:
- имеется один и только один кортеж для каждого индивидуума в I;
- если значением атрибута Ai индивидуума является vi, то его кортеж содержит
vi в домене Ai;
- если индивидуум включается также в родовой объект vn+j
в кластере Cj, то его кортеж содержит vn+j
в домене Cj;
- если индивидуум не включается ни в какой родовой объект в кластере
Cj, то его кортеж содержит "пусто"
(—) в домене Cj.
Таблица II. Примеры отношений Кодда для трех родовых объектов из иерархии на рис. 4
транспортное средство:
идент.
номер
|
изготовитель
|
цена
|
вес
|
категория
среды
передвижения
|
категория
двигателя
|
|
V1
|
Mazda
|
65.4
|
10.5
|
наземное
транспорт.
средство
|
мотор.
транспорт.
средство
|
|
V2
|
Schwin
|
3.5
|
0.1
|
наземное
транспорт.
средство
|
транспорт.
средство,
привод. в
движение
человеком
|
|
V3
|
Boeing
|
7,900
|
840
|
воздушное
транспорт.
средство
|
мотор.
транспорт.
средство
|
|
V4
|
Aqua Co
|
12.2
|
1.9
|
водное
транспорт.
средство
|
транспорт.
средство,
привод. в
движение
ветром
|
|
V5
|
Gyro Inc
|
650
|
150
|
воздушное
транспорт.
средство
|
мотор.
транспорт.
средство
|
моторизованное транспортное средство:
идент.
номер
|
изготовитель
|
цена
|
вес
|
мощность
в л.с.
|
запас
горючего
|
категория
мотора
|
|
V1
|
Mazda
|
65.4
|
10.5
|
150
|
300
|
роторное
траспорт.
средство
|
|
V3
|
Boeing
|
7,900
|
840
|
9600
|
2600
|
реактив.
транспорт.
средство
|
|
V5
|
Gyro Inc
|
650
|
150
|
1500
|
2000
|
роторное
траспорт.
средство
|
воздушное транспортное средство:
идент.
номер
|
изготовитель
|
цена
|
вес
|
максим.
высота
|
пробег
при взлете
|
категория
подъем.
механизма
|
|
V3
|
Boeing
|
7,900
|
840
|
30
|
1000
|
самолет
|
|
V5
|
Gyro Inc
|
650
|
150
|
5.6
|
0
|
вертолет
|
В таблице II иллюстрируется, как могут выглядеть отношения Кодда (в некоторый
момент времени) для родовых объектов "транспортное средство", "моторизованное
транспортное средство" и "воздушное транспортное средство", представленных на рис. 4. Заметим, что одним из последствий применения такого метода представления является
появление имен отношений как значений в некоторых доменах. Например, домены
"категория среды передвижения" и "категория мотора"
в отношении "транспортное средство" в качестве значений имеют имена отношений.
Это позволяет нам использовать реляционные операции Кодда для манипулирования родовыми объектами.
Как мы увидем в разд. 4, это позволяет нам
также использовать унифицированный метод для представления связей, в которых
принимают участие родовые или индивидуальные объекты.
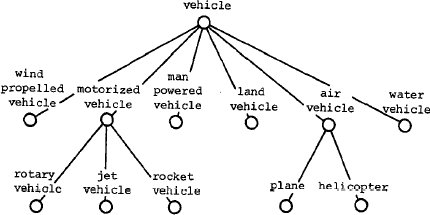
Рис. 4. Родовая иерархия транспортных средств
Будем называть домен в отношении, который содержит имя некоторого подчиненного
отношения, доменом образа (image domain) этого потомка. Например,
домен "категория среды передвижения" в отношении "транспортное средство"
является доменом образа для отношений-потомков "наземное транспортное средство",
"воздушное транспортное средство" и "водное транспортное средство". Существует
взаимно-однозначное соответствие между кластерами в родовой иерархии и
доменами образов в их реляционном представлении.
Заметим, что в таблице II все домены в "транспортном средстве", за
исключением доменов образов, наследуются его отношениями-потомками
"моторизованное
транспортное средство" и "воздушное транспортное средство". Хотя это
наследование
доменов часто может быть присущим реляционным моделям, мы не настаиваем
на том, что оно обязательно должно иметь место. Это позволяет
представлять
абстракции обобщения способом, наиболее подходящим для их пользователей.
Ясно, что значительная часть информации в реляционной иерархии является
избыточной. Это вполне приемлемо при условии, если существует некоторый
метод реализации иерархии отношений таким образом, чтобы:
- на дублирование данных не затрачивалось дополнительное пространство
памяти;
- могла поддерживаться согласованность избыточной информации.
Этот
вопрос обсуждается далее в
разд. 6.
3. Родовая структура
Опишем теперь примитив структурирования для спецификации обобщений
в реляционных моделях. В [4] мы ввели типы collection (коллекция)
и aggregate (агрегат), после чего объявили отношение R следующим образом:
var R: collection of aggregate [keylist]
s1: {key} R1
...
sn: {key} Rn
end
В этом объявлении "список ключей" (keylist) содержит селекторы для ключевых
доменов R. Заключение ключевого слова "key" (ключ) в
фигурные скобки показывает, что оно не всегда обязано присутствовать. Теперь
R может фактически рассматриваться как имя родового объекта. Для того чтобы
определить позицию родового объекта R в родовой иерархии, нам необходимо
лишь специфицировать его потомков в этой иерархии. Это дает возможность
полагать, что структура, показанная на рис. 5, является уместной для
определения отношений Кодда.
var R: generic
sk1 = (R11, ..., R1p1);
...
skm = (Rm1, ..., Rmpm)
of
aggregate [keylist]
s1: {key} R1;
...
sn: {key} Rn
end
где:
- Ri (1≤ i ≤ n) является либо родовым идентификатором
(и в этом случае должно указываться "key"),
либо идентификатором некоторого типа
(и в этом случае "key" не должно указываться);
- "список ключей" (keylist) – это последовательность
si (1≤ i ≤ n), разделенных запятыми;
- Rij (i = 1, 1 ≤ j ≤ p1; ...; i = m, 1 ≤ j ≤ pm)
представляет собой родовой идентификатор с теми же
самыми ключевыми доменами, что и у R;
- каждое ski (1 ≤ i ≤ m) является тем же самым, что и
некоторое sj (1 ≤ j ≤ n);
- если ski является тем же самым, что и sj, то
тип "{key} Rj" является множеством {Ri1, ..., Ripi}.
Рис. 5. Родовая структура
Мы используем термин родовой (generic), а не менее точный
термин коллекция (collection) с тем, чтобы указать, что определяeтся
родовой объект. Родовая структура одновременно специфицирует две абстракции:
- R как агрегацию связи между объектами от R1
до Rn и
- R как обобщение
класса, содержащего объекты от R11 до Rmpm.
Домены с селекторами от s
k1 до s
km являются доменами образов. Если никакие домены образов не специфицированы,
то
родовая структура является в точности тем же, что и структура
коллекции из
[4].
Прежде чем перейти к обсуждению пяти синтаксических требований к родовой
структуре, определим три отношения на основе таблицы II. Эти определения
показаны на рис. 6. Заметим, что в определении отношения "транспортное средство",
его родовые потомки перечислены после зарезервированного слова "generic",
а агрегированные потомки – после зарезервированного слова "aggregate".
Родовые потомки группируются в кластеры, и каждый кластер ассоциируется
с селектором соответствующего ему домена образов. В данном случае домены
образов имеют селекторы MC и PC.
var vehicle:
generic
MC = (land vehicle, air vehicle, water vehicle);
PC = (motorized vehicle, man powered vehicle, wind propelled vehicle)
of
aggregate [ID#]
ID#: identification number;
M: manufacturer;
P: price;
W: weight;
MC: medium category;
PC: propulsion category
end
var motorized vehicle:
generic
MTC = (rotary vehicle, jet vehicle, rocket vehicle)
of
aggregate [ID#]
ID#: identification number;
M: manufacturer;
P: price;
W: weight;
HP: horsepower;
FC: fuel capacity
MTC: motor category
end
var air vehicle:
generic
LC = (plane, helicopter)
of
aggregate [ID#]
ID#: identification number;
M: manufacturer;
P: price;
W: weight;
MA: maximum altitude;
TD: takeoff distance;;
LC: lift category
end
Рис. 6. Определение отношений из таблицы II
Мы не будем обсуждать два первых синтаксических требования в связи с
рис. 5, поскольку они поясняются в [4]. Требование (iii) сводится к
тому,
чтобы каждый родовой потомок R объявлялся где-либо как полноправный
родовой
объект. На рис. 6 это иллюстрируется объявлениями "моторизованного
транспортного средства" и "воздушного транспортного средства". Более
того, все эти
объекты-потомки должны иметь тот же самый ключевой домен, что и R. Это
требование позволяет ссылаться на объекты-индивидуумы унифицированным
образом
независимо от того, в какой родовой класс они входят. Иногда полезным
исключением
из этого правила является то обстоятельство, что если ski
входит в ключ R, то оно не обязательно должно появляться в ключе какого-либо
Rij (1 ≤ j ≤ pi).
Если бы оно все-таки появлялось, этот домен имел бы одно и то же значение
для каждого индивидуума в Rij.
Предположим, например, что на рис. 6 PC было бы объявлено как входящее
в ключ
объекта "транспортное средство". Если мы после этого добавили бы
"категорию
мотора" как новый домен в отношение "моторизованное транспортное
средство", то, чтобы удовлетворить требование (iii), этот домен должен
был бы иметь одно
и то же значение ("моторизованное транспортное средство") для каждого
индивидуума.
Требованию (iv) обеспечивает, чтобы каждый специфицированный
кластер ассоциировался с конкретным доменом (образов). Требование (v)
обеспечивает, чтобы каждый домен образов мог действительно допускать
в качестве значений родовые идентификаторы, перечисленные в
ассоциированном
с ним кластере. Например, в определении объекта "транспортное средство"
на
рис. 6 тип "категория среды перемещения" должен где-то определяться как
множество идентификаторов, "наземное транспортное средство",
"воздушное транспортное средство" и "водное транспортное средство".
Если определение отношения удовлетворяет этим пяти синтаксическим требованиям,
то это не дает гарантии, что данное определение специфицирует осмысленную
абстракцию агрегации и осмысленную абстракцию обобщения. Рассмотрим теперь,
какие дополнительные требования необходимы, чтобы специфицировались
осмысленные абстракции. Эти требования должны быть семантическими и каким-либо
образом связанными с нашим интуитивным пониманием реального мира.
Поскольку базы данных обычно предназначаются для моделирования реального
мира, как мы его понимаем, мы можем с уверенностью потребовать, чтобы все
имена объектов в определении отношения были именами существительными естественного
языка. Эти существительные впоследствии обеспечивают мост между нашим интуитивным
пониманием реального мира и задаваемым его отражением в определении отношения.
Если существительные естественного языка не используются, любое обсуждение
осмысленности определения отношения представляется спорным.
Если предположить, что R, каждое Ri
и каждое Rij (на рис. 5) являются существительными
естественного языка, необходимы пять семантических условий, чтобы
определение отношения специфицировало агрегацию и обобщение.
- Каждый R-индивидуум должен определять некоторый уникальный Ri-индивидуум.
- Никакие два R-индивидуума не определяют одно и то же множество Ri-индивидуумов
для всех Ri, селекторы которых принадлежат
"списку ключей".
- Каждый Rij-индивидуум должен также
быть R-индивидуумом.
- Каждый R-индивидуум, классифицируемый как Rij,
должен также быть Rij-индивидуумом.
- Никакой Rij-индивидуум не является
также Rik-индивидуумом при j ≠ k.
Под R-индивидуумом (Ri- или Rij-индивидуумом)
мы понимаем некоторый экземпляр родового объекта R (Ri или Rij) в том виде, как он появляется
в реальном мире.
Первые два условия являются необходимыми для абстракции агрегации и
обсуждаются в [1]. Остальные три условия являются необходимыми для абстракции
обобщения. Условие (iii) обеспечивает, чтобы Rij являлось подклассом R и, таким образом, чтобы Rij
могло быть обобщено до R. Например, в таблице II моторизованные транспортные
средства V1, V3 и V5 являются также транспортными средствами. Условие (iv)
обеспечивает, чтобы Rij содержало все R-индивидуумы,
классифицированные как относящиеся к Rij.
Например, в таблице II "моторизованное транспортное
средство" содержит
все транспортные средства, классифицированные таким образом в "транспортном
средстве".
Условие (v) обеспечивает, чтобы кластеры содержали взаимно-исключающие
классы.
Будем говорить, что отношение является правильно определенным (well-defined),
если его определение удовлетворяет пяти приведенным выше семантическим
требованиям.
4. Моделирование с помощью родовой структуры
Задача этого раздела – показать, как абстракции агрегации и обобщения
используются в разработке моделей реального мира. Когда агрегация и обобщение
применяются раздельно, они могут моделировать только относительно простые
ситуации. Однако, применяя их вместе, мы увидим, что может быть определено
мощное множество моделей. Опишем сначала графическое представление для
определений отношений. Такая нотация делает модели значительно более легкими
для визуализации.
Эта нотация основана на том наблюдении, что агрегация и обобщение являются
независимыми действиями. Если задан конкретный объект, обобщения этого
объекта могут рассматриваться независимо от связей, в которых этот объект
принимает участие. Благодаря этому напрашивается графическая нотация, в
которой обобщение и агрегация представляются ортогонально. Мы выбрали для
представления агрегации плоскость страницы, а для представления обобщения
– плоскость, перпендикулярную странице. Родовая структура, показанная на
рис. 5, представлена графически на рис.7.
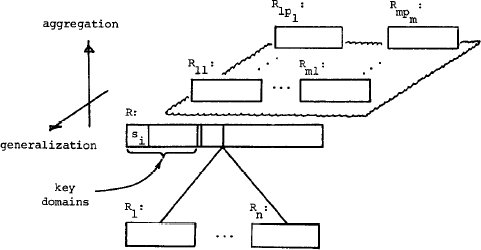
Рис. 7. Графическое представление родовой структуры
Агрегированные объекты верхнего уровня будут при этом показываться вверху
страницы, а объекты более низких уровней – ниже, к концу страницы. Таким
образом, агрегация показывается вверх по странице. Родовые объекты верхних
уровней будут показываться (в имитируемом таким образом трехмерном пространстве)
на поверхности страницы, а родовые объекты более низких уровней – ниже
поверхности. Обобщение, следовательно, показывается вне страницы.
Предположим, что мы должны моделировать "служащих" (employee)
некоторой
компании. Допустим также, что в этой компании в некоторый момент
времени
имеется три различных типа служащих – водители грузовиков (trucker),
секретари (secretary) и
инженеры (engineer). Должна поддерживаться информация о каждом
отдельном служащем – хотя в зависимости от типа служащих необходимы
различные виды информации.
Кроме того, должна поддерживаться информация о каждом родовом типе
служащих.
Более конкретно, предположим, что атрибуты "идентификационный номер служащего" (employee ID#),
"фамилия" (name), "возраст" (age) и "тип служащего" (employee type) являются
важными для всех отдельных служащих. Необходимые дополнительные атрибуты
для каждого типа служащих приведены в следующей таблице.
|
тип служащего
|
дополнительные атрибуты
|
водитель грузовика
(trucker)
|
идентификатор транспортного средства (vehicle ID#)
номер лицензии (number of license) |
секретарь
(secretary) |
cкорость печатания (typing speed) |
| инженер (engineer) |
высшая ученая степень (highest degree),
тип (механик, электрик и т.д.) (type (mech, elec))
|
Для каждого родового типа служащих должны регистрироваться следующие
атрибуты: количество служащих (size), количество вакантных должностей
(vacancie), нанимающее агентство (agency).
Построим теперь реляционную модель,**)
удовлетворяющую перечисленным выше требованиям. Поскольку наиболее абстрактным
объектом, который должен быть представлен, является "employee",
начальная модель содержит в точности этот объект. Это показано на рис. 8.
Следующий шаг заключается в декомпозиции этого объекта как в плоскости
агрегации, так и в плоскости обобщения. Предположим, что мы решаем сначала
произвести декомпозицию в плоскости обобщения. В этой плоскости компонентами
"employee" являются родовые объекты "trucker",
"secretary" и "engineer". Эти три объекта образуют единственный
кластер. После этого модель приобретает вид, представленный на рис. 9.

Рис. 8. Начальная модель для объекта "Служащий"
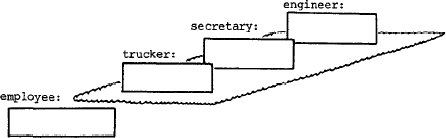
Рис. 9.Декомпозиция объекта "Служащий" в плоскости обобщения
Теперь декомпозируем объект "employee" в плоскости агрегации.
Имеется четыре атрибута служащих, которые должны регистрироваться: "employee ID#", "name", "age" и "employee type".
Поэтому мы включаем эти четыре атрибута как компоненты "employee".
Полученный результат показан на рис.10. За исключением "employee type",
данные компоненты объекта "employee" являются примитивными
объектами, т.е. каждый из них мыслится как единое целое. Однако объект
"employee type" имеет несколько важных компонентов, соответствующих
атрибутам "typename", "size", "vacancies"
и "agency". Все эти компоненты – примитивны. Полученная модель
представлена на рис.10.
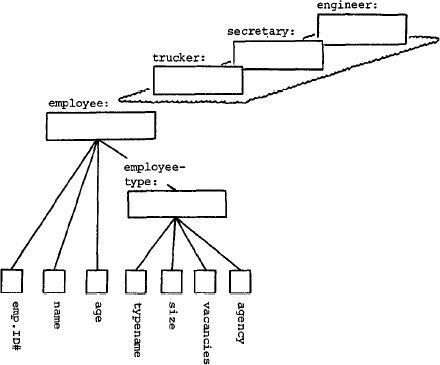
Рис. 10. Декомпозиция объекта "employee" в плоскости агрегации
Теперь мы можем продолжить разрабатывать модель, декомпозируя любой объект (который
еще не был декомпозирован) в любой плоскости. Поскольку для нас не представляют
интерес какие-либо подтипы "employee type", этот объект не декомпозируется
в плоскости обобщения. По подобным же причинам мы не декомпозируем объекты
"trucker", "secretary" и "engineer"
в плоскости обобщения. Однако каждый из этих трех объектов должен быть
декомпозирован на (примитивные) объекты в плоскости агрегации. Эти декомпозиции
включены на рис.11. Чтобы избежать загромождения рисунка, мы не провели до конца линии,
связывающие каждый объект "employee ID#", "name"
и "age" с каждым из объектов "trucker", "secretary" и "engineer". В заключение мы можем выбрать
для каждого объекта селекторы и ключи. И тогда получается реляционная модель, представленная
на рис. 11.
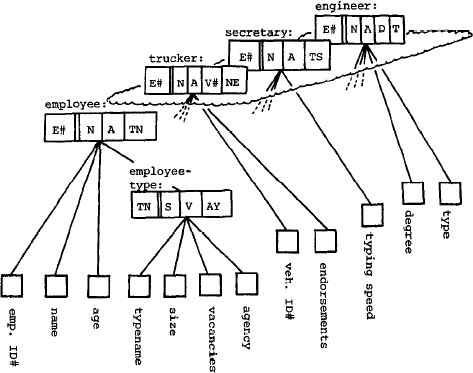
Рис. 11. Реляционная модель для объекта "employee"
Определения отношений "employee" и "employee type"
даются на рис.12. Заметим, что в отношении "employee type" содержатся
детальные сведения о "trucker", "secretary" и "engineer", когда они
полагаются родовыми объектами.
Отношение "employee" отсылает к этим детальным сведениям через домен
образов
(т.е. домен с селектором "TN"). Это позволяет для каждого отдельного
служащего ссылаться на все родовые свойства подкласса служащих, к
которому
он относится.
var employee:
generic
TN = (trucker, txoretary, engineer)
of
aggregate [E#]
E#: employee ID#;
N: name;
А: age;
TN: key employee-type
end
var employee-type:
generic of
aggregate [TN]
TN: typename;
N: size;
А: vacancies;
TN: agency
end
Рис. 12. Определение для объектов "employee" и "employee-type"
с рис. 11
В общем случае отношение R может иметь в плоскости
обобщения несколько принадлежаших ему кластеров. Для каждого кластера C
будет существовать соответствующее
отношение, на которое ссылается R в плоскости агрегации. Это отношение
будет описывать атрибуты (если они имеются) родовых объектов в C. Можно
следующим образом резюмировать это общее свойство реляционных
моделей: атрибуты родовых компонентов абстрактного объекта R определяются
в отношениях, которые являются агрегатными компонентами R.
Рассмотрим теперь моделирование различных дополнительных аспектов реального
мира, относящихся к служащим. В качестве первого аспекта предположим, что
должны моделироваться "профсоюзы" (trade union), объединяющие различные типы
служащих. Будем считать значимыми следующие атрибуты профсоюза: его
название (name), адрес (address) и руководитель (senior officer). На рис. 13 объект "trade union" показан
в плоскости агрегации объекта "employee", а плоскость обобщения
опущена (см. рис. 10).
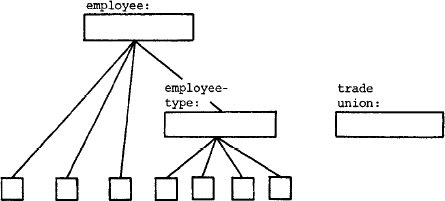
Рис. 13. Объект "trade union", включенный в плоскость агрегации объекта "employee"
Для нас представляет также интерес "принадлежность" (affiliation) к
профсоюзам
типов служащих (employee-type). Поэтому мы образуем абстрактный объект
"affiliation"
как агрегацию "employee-type" и "trade union". Предположим,
что важным атрибутом принадлежности является лицо, уполномоченное
выступать от имени
членов профсоюза конкретного типа служащих. Следовательно, в качестве
дополнительного компонента объекта "affiliation" должен быть включен
соответствующий объект, скажем, "представитель" (spokesman).
После того, как это будет сделано, модель приобретет вид, показанный на
рис.14.
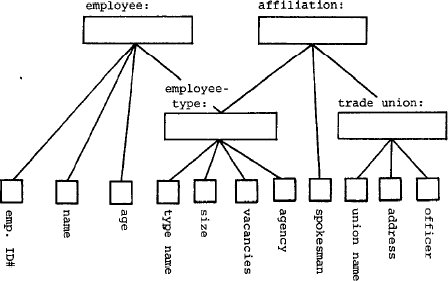
Рис. 14. Объект "affiliation", включенный рис. 13
Выбрав соответствующим образом селекторы и ключи, получаем следующее определение
"affiliation":
var affiliation:
generic of
agregate [TN, UN]
TN: key employee-type;
UN: key trade union;
S: spokesman
end
Это определение специфицирует связь между родовыми объектами.
Мы рассмотрим
далее некоторые связи на плоскости обобщения объекта "employee"
(рис. 10). Предположим, что компания, где работают
служащие (employee), владеет парком транспортных средств (vehicle), в том числе, легковыми автомобилями (car)
и грузовиками (truck). Мы будем моделировать связь между служащими и транспортными
средствами, определяющую использование служащими транспортных средств.
В частности, грузовики используются водителями грузовиков (trucker) для перевозки
материалов, а легковые автомобили используются инженерами (engineer) для визитов на
удаленные участки. Никакого другого (официального) использования транспортных
средств не предусматривается. Представление "employee" и "vehicle"
в плоскости обобщения показано на рис. 15.
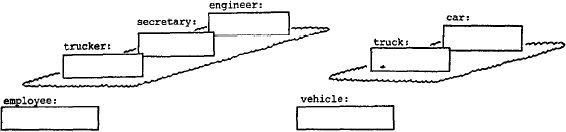
Рис. 15. Декомпозиция объектов "employee" и "vehicle"
в плоскости обобщения
Имеется два способа моделирования этой связи между служащими и транспортными
средствами. Один способ состоит в том, чтобы абстрагировать единственную связь между "employee"
и "vehicle" как агрегированный объект, скажем, "поездка" (trip).
К сожалению, такой подход является слишком общим для того, чтобы позволить в полной
мере выразить имеющуюся в виду связь. Оказалось бы, что любой служащий может
бы взять для поездки любое транспортное средство, например, могло бы получиться,
что секретарь ведет грузовик. Кроме того, в этом случае не существует не различаются
поездки, связанные с доставкой материалов, и поездки инженеров
на участки. Очень вероятно, что в зависимости от вида поездки существенны разные ее атрибуты.
Второй способ моделирования требуемой связи между служащими и транспортными
средствами состоит в том, чтобы декомпозировать ее в плоскости обобщения на две связи
– одна между "trucker" и "truck",
а другая между "engineer" и "car".
Первая связь может быть абстрагирована как агрегированный объект "перевозка" (haulage),
а вторая – как "визит" (visit). Эти объекты показаны на рис. 16.
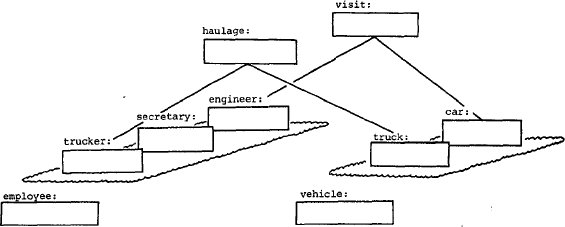
Рис. 16. Объекты "haulage" и "visit", включенные в рис. 15
Главное достоинство этого второго подхода заключается в том, что
такая модель является более точным представлением реальности. Благодаря
этому модель становится более понятной, а тем самым и в меньшей мере
провоцирующей
ошибочные доступ и манипулирование. Более того, эта модель выражает
ограничения,
налагаемые на объекты "haulage" и "visit" в реальном мире, а именно,
то, что "haulage" должен связывать водителей
грузовиков с грузовиками, а "visit" – инженеров с легковыми
автомобилями.
Если эти ограничения поддерживаются во время выполнения операций
обновления, то можно избежать возникновения
некоторых проблем целостности (например, поблем с секретарями, которые
водят грузовики). Другое достоинство заключается в том, что за счет
ограничения области действия связей "haulage" и "visit"
явными подмножествами "employee" и "vehicle"
расширяются возможности оптимизации операций выборки на более
низком уровне реализации.
Рассмотрим теперь другой пример связи в плоскости обобщения объекта
"employee". Предположим, что должно моделироваться назначение
секретарей инженеров. Самый непосредственный способ моделирования этой
связи – абстрагировать объект, скажем, "назначение" (assignment), как агрегацию
объектов "secretary" и "engineer". Объект "assignment"
показан справа на рис. 17. Хотя это отношение могло бы моделироваться как
агрегация "employee" и "employee", такой путь
привел бы к порождению излишней двусмысленности.
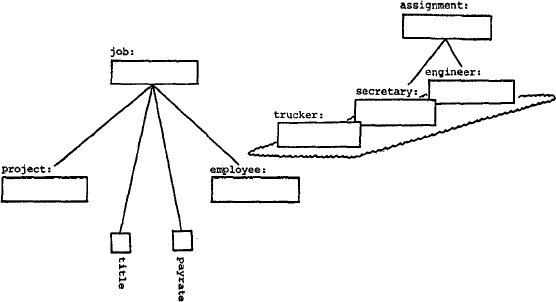
Рис. 17. Объекты "assignment" и "job", включенные в рис. 16
Все три рассмотренные связи ("haulage", "visit" и
"assignment") обладают тем свойством, что в них принимают участие
служащие некоторых, но не всех типов. Проанализируем теперь связь, в которой
принимают участие служащие всех типов. Рассмотрим связь между служащими (employee)
и проектами (project), которая идентифицирует работы (job), выполняемые служащими в проектах.
Предполагается, что данный служащий может выполнять одновременно
работы в нескольких проектах, но не несколько работ в одном и том же
проекте. Эта связь лучше всего моделируется путем агрегации объектов "employee"
и "project" в абстрактный объект, скажем, "job".
Могут быть введены другие атрибуты "job", такие как "название" (title)
и "ставка" (payrate). Объект "job" показан на рис. 17.
Определение объекта "job" с соответствующим выбором селекторов
и ключа приводится ниже:
var job:
generic of
aggregate [E#, P#]
E#: key employee;
P#: key project;
T: title;
PR: payrate
end
Здесь выбран ключ "E#, P#", поскольку, в соответствии с указанным
выше ограничением, работы находятся во взаимно-однозначном соответствии
с парами служащий-проект. В этом определении предполагается, что
никакая декомпозиция "Работы" в плоскости обобщения не представляет
интереса.
Теперь предположим, что некоторых пользователей модели интересуют
отдельные типы работ. Допустим, что среди проектов имеется проект,
связанный
с разработкой модемов, и другой, предусматривающий модернизацию
принтеров.
Некоторые пользователи могут пожелать рассматривать "работу в модемном
проекте" (modern project job) и "работу в принтерном проекте" (printer
project job) как родовые объекты.
На рис.18 показано, как выглядит модель после включения в нее этих
объектов как потомков "job" в плоскости обобщения.
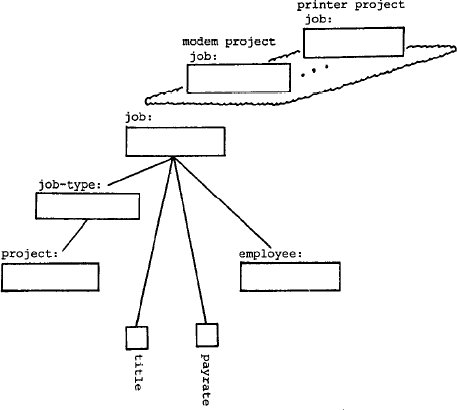
Рис. 18. Результат декомпозиции объекта "job"в плоскости обобщения.
Проанализируем теперь, почему рис. 18 выражает соответствующую
структуру.
Во-первых, поскольку мы декомпозируем работу на родовые объекты (в
плоскости
обобщения), должен быть введен (в плоскости агрегации) новый объект,
который
является обобщением этих объектов (рассматриваемых как индивидуумы).
Это
следует из требования родовой структуры, заключающегося в том, что у
каждого
кластера имеется свой собственный домен образов. Этот новый объект
называется
"тип работы" (job-type) и является компонентом объекта "job". Объект
"job-type" сам может декомпозироваться на свои объекты-атрибуты.
Во-вторых, заметим, что каждый тип работы является абстракцией всех
работ, относящихся к определенному проекту. Поэтому одним из атрибутов
типа работы должен быть проект, к которому относятся все его работы. Соответственно,
на рис.18 "project" показан как атрибут
"job-type". Объект "project" больше не является непосредственным компонентом объекта "job", как это было на рис. 17.
Теперь он является косвенным компонентом этого объекта через посредство "job-type".
Определения объектов "job" и "job-type" приводятся
ниже:
var job:
generic
TN = (modemproject job, ... , printer project job)
of
aggregate [E#, TN]
E#: key employee;
T: title;
PR: payrate;
TN: key job-type
end
var job-type:
generic of
aggregate [TN]
TN: typename;
P#: key project;
AP: average payrate
end
Заметим, что "job" представляет
собой пример отношения, в котором ключ содержит домен образов.
Введение "job-type" иллюстрирует вид реструктуризации,
которая часто может стать необходимой по мере эволюционирования
приложения модели. В первоначальном приложении пользователей может
интересовать общий класс объектов C. В процессе эволюции приложения
некоторым пользователям может стать интересна только подкатегория
C-объектов, у которых значением атрибута A является некоторое v1,
а другим пользователи может стать интересна подкатегория
со значением атрибута A, равным v2. Эти
подкатегории C относительно атрибута A должны быть далее представлены как
кластер в плоскости обобщения C. На рис. 18 этот
кластер {modem project job, ... , printer project job} представляет
подкатегоризацию "job" по отношению к "project".
Вообще, если появляется необходимость ввести в существующей модели подкатегоризацию
некоторого объекта O по отношению к атрибуту A, то требуется следующая реструктуризация:
- определить новый объект S, который
абстрагирует класс подкатегорий;
- заместить в O домен, который ссылается
на A, доменом, который ссылается на S;
- если ключ O содержит селектор
для A, заменить его селектором для S и
- вставить в S домен, который
ссылается на A.
5. Реляционные инварианты
Рассмотрим сначала свойства отношений, которые должны оставаться инвариантными
во время выполнения операций обновления. Далее мы по очереди исследуем каждую операцию
и рассмотрим методы обеспечения инвариантности этих свойств. Операциями
обновления, которые мы рассматриваем здесь, являются:
- insert (вставить) – эта операция выполняется, когда становится
интересен новый индивидуальный объект;
- delete (удалить) – эта операция выполняется, когда существующий
индивидуальный объект перестает быть интересным; и
- modify (модифицировать) – эта операция выполняется, когда заданные
элементы некоторого существующего объекта становятся субъектом изменений.
В разд. 3 мы сформулировали условия, которые должны
удовлетворяться объектами реального мира, указанными в определении отношения,
чтобы это определение выражало абстракции. Если некоторый объект
R определяется в терминах агрегатных компонентов Ri
и родовых компонентов Rij,
то такими условиями являются следующие:
- каждый R-индивидуум должен определять некоторый уникальный Ri-индивидуум;
- никакие два R-индивидуума не определяют одно и то же множество Ri-индивидуумов
для всех Ri, селекторы которых входят в "список ключей";
- каждый Rij-индивидуум должен также
быть R-индивидуумом;
- каждый R-индивидуум, классифицируемый как Rij,
должен также быть Rij-индивидуумом;
- никакой Rij-индивидуум не является
также Rik-индивидуумом при j ≠ k.
Важно, чтобы отношения и кортежи, которые представляют эти объекты реального
мира в некоторый момент времени, удовлетворяли соответствующему множеству
условий. Благодаря этому такие отношения в точности представляют абстрактную
структуру реального мира. При формулировке этих условий полезны следующие
определения.
Пусть t – некоторый кортеж Rij.
Образ предка (parent image) t – это некоторый кортеж t' из R, для которого:
- t и t' имеют одни и те же значения во всех общих доменах и
- t'.ski имеет значение
"Rij".
С семантической точки
зрения, кортеж и его образ предка совместно описывают один и тот же индивидуум
реального мира; однако образ предок находится на более высоком уровне
обобщения.
4)
Если t' – образ предка t, то мы говорим, что t –
образ потомка (child image) t'.
Для представления абстракций мы можем теперь сформулировать ограничения на
отношение вместе с его агрегатными и родовыми компонентами:
- для каждого R-кортежа t, если t.si
не есть "пусто", то в случае, когда Ri
– родовой идентификатор, t.si является
ключом некоторого Ri-кортежа, а в случае,
когда Ri – идентификатор некоторого типа,
t.si имеет тип Ri;
- никакие два различных R-кортежа не могут иметь один и тот же ключ;
- каждый Rij-кортеж имеет образ предка
в R;
- для каждого R-кортежа t, если t.sk
не есть "пусто" и имеет значение Rij,
то R имеет образ потомка в Rij;
- никакой R-кортеж не может иметь одновременно образы потомка в
Rij и в Rik
при j ≠ k.
Эти пять условий мы называем реляционными инвариантами (relational invariant).5)
Они являются трансформацией пяти предыдущих условий в соответствии с методом
представления родовых объектов как отношений. Имеется одно небольшое исключение,
связанное с инвариантами (i) и (iv). Дело в том, что на практике необходимо
допускать в некоторых доменах значения "пусто", которые означают
"неизвестно" или "безразлично". Инварианты (i) и (iv)
предусматривают существование такой возможности.
Реляционные инварианты могут рассматриваться как ограничения, налагаемые
на отношения с тем, чтобы они представляли "абстрактные объекты".
Эти инварианты должны удовлетворяться каждым отношением в реляционной модели,
безотносительно к виду абстрактного объекта, который представляет данное
отношение. Помимо этого, каждое отношение должно обычно удовлетворять множеству
инвариантов (часто называемых "ограничениями целостности"), характерных
только для этого отношения. Подобного рода инварианты ограничивают отношение
таким образом, чтобы оно представляло конкретный вид абстрактных объектов.
Поскольку реляционные инварианты применяются к каждому отношению, они являются
наиболее фундаментальной формой ограничений целостности.
Обычно пользователи не взаимодействует с базой данных на уровне примитивных
операций обновления insert, delete и modify. В большинстве
случаев эти примитивы используются для конструирования операций обновления
более высокого уровня, называемых транзакциями. Понятие транзакции позволяет
иным образом характеризовать различия между реляционными инвариантами и
специальными ограничениями целостности. Реляционные инварианты должны удовлетворяться
до и после каждой инициированной пользователем операции обновления. Специальные же
ограничения целостности должны удовлетворяться только до и
после каждой транзакции.
Обсудим теперь поддержку реляционных инвариантов
во время выполнения операций обновления. Мы предполагаем при этом, что имеет место
идеальная ситуация, в которой:
- модель корректно абстрагирует структуру реального
мира во время обновления;
- информация для обновления точно отражает
атрибуты индивидуумов реального мира;
- все пользователи имеют полные
полномочия доступа ко всем отношениям.
Такая идеализированная ситуация
позволяет нам игнорировать самостоятельные проблемы специальных
ограничений целостности и управления доступом. Мы утверждаем, что эти
проблемы более лучше пытаться решать
после разработки методов поддержки
реляционных инвариантов.
В дальнейшем обсуждении будут полезны вводимые ниже аббревиатуры. Рассмотрим
реляционную модель M, которая, наряду с прочим, содержит отношение R. Будем
говорить, что относительно R некоторое отношение является:
- paR, если оно является предком (parent) в плоскости агрегации (aggregation) отношения
R;
- caR, если оно является потомком (child) в плоскости агрегации (aggregation) отношения
R;
- pgR, если оно является предком (parent) в плоскости обобщения (generalization) отношения
R;
- cgR, если оно является потомком (child) в плоскости обобщения (generalization) отношения
R.
На рис.19 показано, как отношение "связывается" со своими отношениями
paR, caR, pgR и cgR.
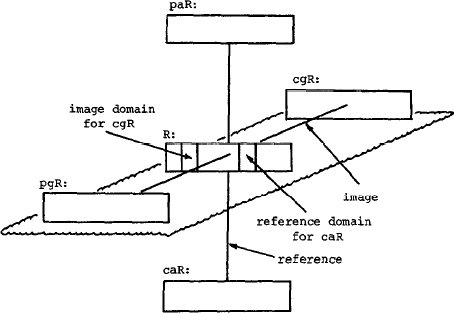
Рис. 19. Отношение R и его отношения paR, caR, pgR и cgR
В таблице III приведена сводка методов поддержки реляционных
инвариантов
при выполнении операций обновления. Каждый тип операции обновления
(insert, delete, modify) рассматривается в отдельной части таблицы. При
этом в каждой
части таблицы указывается воздействие на все пять инвариантов,
оказываемое
выполнением соответствующей операции обновления над кортежом t с ключом
k в отношении R.
Таблица III. Поддержка реляционных инвариантов при выполнении операций обновления
INSERT
|
Инвариант
|
Возможные нарушения после вставки
|
Метод коррекции нарушения
|
|
i)
|
t ссылается на несуществующий кортеж в некотором caR-отношении R'
|
вставить в R' кортеж с соответствующими значениями ключа и значениями "пусто", где это уместно
|
|
ii)
|
t появляется в R дважды
|
удалить один из экземпляров t
|
|
iii)
|
t не имеет образа-предка в некотором
pgR-отношении R'
|
если кортеж с ключом k уже существует в R', то модифицировать этот кортеж так, чтобы он стал образом предка t, иначе вставить образ предка
в R' (используя "пусто" там, где значения неизвестны)
|
|
iv)
|
t не имеет требуемого образа потомка в некотором cgR-отношении R'
|
вставить образ потомка в R' (используя "пусто" там, где значения неизвестны)
|
|
v)
|
нет
|
|
DELETE
|
Инвариант
|
Возможные нарушения после вставки
|
Метод коррекции нарушения
|
|
(i)
|
кортеж в некотором paR-отношении
ссылается на несуществующий R-кортеж
|
a) модифицировать этот кортеж так, чтобы
ссылка была замещена значением "пусто" (это возможно, если только ссылка не является частью ключа кортежей)
b) удалить этот кортеж
|
|
(ii)
|
нет
|
|
|
(iii)
|
у кортежа в некотором cgR-отношении отсутствует образ предка в R
|
удалить этот кортеж
|
|
(iv)
|
кортеж в некотором pgR-отношении не имеет требуемого образа потомка в R
|
a) модифицировать этот кортеж, замещая
его значение в домене образов значением
"пусто" (это возможно только тогда, когда
домен образов не является частью ключа
данного кортежа
b) удалить этот кортеж
|
|
(v)
|
нет
|
|
MODIFY
|
Инвариант
|
Возможные нарушения после вставки
|
Метод коррекции нарушения
|
|
(i)
|
t ссылается на несуществующий кортеж в некотором caR-отношении R'
|
вставить в R' кортеж с соответствующими значениями ключа и значениями "пусто" там, где это уместно
|
|
(i)
|
(обновление ключевого домена)
кортеж в некотором paR-отношении
ссылается на несуществующий R-кортеж
|
модифицировать кортеж так, чтобы он
ссылался на t
|
|
(ii)
|
нет
|
|
|
(iii)
|
t не имеет образа предка в некотором pgR-отношении R'
|
модифицировать старый образ предка t так,
чтобы он стал (новым) образом предка
|
|
(iii)
|
кортеж в некотором cgR-отношении R'
не имеет образа предка в R
|
если модифицируется домен образов для R', то удалить этот кортеж, иначе
модифицировать этот кортеж так, чтобы
t стал его образом предка
|
|
(iv)
|
t не имеет требуемого образа потомка
в некотором cgR-отношении R'
|
если изменяется домен образов для R', то вставить образ потомка в R' (используя "пусто" там,
где неизвестны значения), иначе
модифицировать старый образ потомка t в R' так, чтобы он стал (новым) образом потомка t
|
|
(iv)
|
Кортеж в некотором pgR-отношении не имеет требуемого образа потомка в R
|
модифицировать кортеж так, чтобы t стал
его образом потомка
|
|
(v)
|
нет
|
|
Предполагается, что реляционные инварианты удовлетворяются перед выполнением операций
обновления. Каждая часть таблицы показывает, каким образом могут быть нарушены
инварианты в результате операции обновления, а также какие действия можно
предпринять для устранения каждого нарушения. Эти действия всегда сводятся
к выполнению операции обновления над одним или несколькими отношениями
paR, caR, pgR или cgR. Они, в свою очередь, могут вызвать другие нарушения и,
следовательно, выполнение операций обновления над другими отношениями. Таким образом,
единственная инициированная пользователем операция обновления может инициировать
дополнительные операции обновления, которые распространяются как в плоскости
агрегации, так и в плоскости обобщения.
Сначала мы поясним несколько пунктов в таблице
III, а затем мы проанализируем некоторые важные свойства инициируемых
операций. Как обычно в реляционных моделях, мы предполагаем, что ни для
какого кортежа не допускается значение "пусто" ни в одном из
ключевых доменов. Нарушение этого условия должно быть единственной причиной,
по которой отвергается "корректная" операция обновления.
Единственным случаем, когда инвариант (ii) может быть нарушен корректной
операцией обновления, является вставка кортежа-дубликата. При этом корректирующим
действием служит просто удаление одного из дубликатов. Инвариант (v) никогда
не может быть нарушен при заданных нами предположениях корректности. Наконец,
инварианты (i), (iii) и (iv) могут быть нарушены любым корректным обновлением.
В каждом случае корректирующее действие соответствует абстракнотной структуре
реляционных моделей. Рассмотрим несколько примеров.
Предположим, что мы нарушаем инвариант (i), вставляя кортеж t. Это означает,
что t должен ссылаться на несуществующий кортеж в некотором отношении R'.
Для устранения такого нарушения мы должны вставить подходящий кортеж (например,
t') в R'. Не располагая какой-либо другой входной информацией, мы знаем
единственную подробность относительно t' – его ключ, который входит
в t. Следовательно, в неключевые домены t' должны быть вставлены значения
"пусто". С семантической точки зрения, эффект этого корректирующего
действия состоит в том, чтобы ввести абстрактный объект t', о котором известно,
что он находится в связи с t.
Допустим теперь, что мы нарушаем инвариант (iii), удаляя кортеж t. Это
означает, что кортеж t', который был образом потомка t, больше
не имеет образа предка в R. Чтобы устранить это нарушение, мы должны удалить
кортеж t'. Такое корректирующее действие отражает семантическое требование,
состоящее в том, что объект, который не появляется в некотором классе на
верхнем уровне обобщения, не может появиться в каком-либо классе на более
низком уровне обобщения.
Предположим, наконец, что мы нарушаем инвариант (iv), модифицируя кортеж
t. Имеются два случая, когда может иметь место такое нарушение. Первый
случай возникает, когда после модификации t имеет некоторое значение, например,
R', в каком-либо домене образов, скажем, в домене d, и t еще не имеет никакого
образа потомка в R'. В этом случае корректирующее действие зависит от того,
изменялся ли d при выполнении данной операции модификации. Если d не изменялся,
то должен быть модифицирован старый образ-потомок t в R' так, чтобы сделать
его новым образом потомка. Вся требуемая для этого информация уже имеется
в t. Если же d изменялся, то в R' должен быть вставлен образ потомка. Ключ
этого образа потомка содержится в t, однако, в каждый домен, значение которого
не содержится в t, должно быть помещено значение "пусто".
Второй случай, когда может иметь место нарушение, возникает, если старый
образ предка t (например, t') больше не имеет образа потомка в R. В этом
случае корректирующее действие сводится к модификации t' таким образом,
чтобы он снова стал образом-предком t. Во всех случаях корректирующие действия
отражают семантическое требование, в соответствии с которым детали абстрактного
объекта должны быть согласованы независимо от того, каков уровень обобщения
класса, в котором он появляется.
Анализируя таблицу III, можно обнаружить, что существует
два метода коррекции нарушений инвариантов (i) и (iv), возникающих вследствие
операции удаления. Каждый из этих методов семантически соответствует определенным
ситуациям. Рассмотрим сначала инвариант (i). Допустим, что имеется абстрактный
объект x, агрегатным компонентом которого является некоторый объект y.
Возникает вопрос, должен ли удаляться x, если удаляется y. Представляется,
что ответ зависит от контекста.
Предположим, например, что у некоторого автомобиля имеются "радиоприемник"
и "кузов", представляющие собой два его агрегатных компонента.
Если повреждается радиоприемник, то обычно считается, что автомобиль по-прежнему существует.
Однако, если разрушен кузов, то и автомобиль обычно также считается разрушенным.
Поскольку на подобные вопросы относительно удаления можно отвечать только
в рамках семантики более высокого уровня, необходимо оставить открытым решение
вопроса о том, как поддерживать инвариант (i). Когда проектируются транзакции,
программист может выбрать, какая альтернатива в наибольшей мере соответствует
тем ограничениям целостности, которые он желает поддерживать.
Аналогичные соображения применимы к инварианту (iv). Пусть мы имеем
общий
класс объектов x, который включает все объекты из более специального
класса
y. Вопрос состоит в том, следует ли удалять объект из x, когда он
удаляется
из y. Допустим, например, что некоторый объект прекращает быть
автомобилем Форд. Поскольку изменение изготовителя – не слишком
осмысленное действие,
естественно предположить, что объект вообще перестает быть
"автомобилем". С другой стороны, допустим, что некоторый объект
прекратил
быть "красным автомобилем". Поскольку достаточно легко перекрасить
красный автомобиль в голубой цвет, можно предположить, что этот объект
по-прежнему остается "автомобилем". Следовательно, решение о том,
как следует поддерживать инвариант (iv) при операциях удаления, должно
приниматься
на более высоком уровне моделирования.
Из предыдущего обсуждения должно быть ясно, что процедуры поддержки
инвариантов в таблице III предназначены для того,
чтобы отражать абстрактную структуру реального мира. Поэтому, в принципе,
безотносительно к тому, какая реляционная модель рассматривается, запускаемые
последовательности операций обновления должны отражать "естественные"
побочные эффекты первоначального определенного пользователем обновления.
Если же, однако, мы игнорируем свою интерпретацию реального мира и рассматриваем
этот вопрос формально, то вовсе не легко проверить, что последовательности
запускаемых обновлений будут обязательно вести себя правильно.
С концептуальной точки зрения, инициируемые операции обновления одновременно
распространяются несколькими путями. Что произойдет, если какие-либо два
из этих путей пересекаются? Может ли одно инициируемое обновление аннулировать
результаты работы другого? Является ли итоговый результат определенной
пользователем операции обновления независимым от порядка, в котором выполнялись
запускаемые операции обновления? Может ли последовательность запускаемых
обновлений стать циклической? Если инициируемое обновление является неприемлемым
(в связи с тем, что были бы нарушены инварианты (ii) или (v)), то должен быть
произведен откат последовательности запускаемых обновлений, и должно быть
отвергнуто первоначальное обновление. Каким образом можно узнать, что никакое
"корректное" определенное пользователем обновление не будет отвергнуто
по этой причине?
Нам хотелось бы потребовать, чтобы любая процедура поддержки инвариантов
обладала, по крайней мере, следующими тремя свойствами:
- распространение запускаемых обновлений должно в конечном счете завершаться;
- общий эффект после завершения распространения не должен зависить от порядка,
в котором выполняются запускаемые обновления;
- "корректное" определяемое пользователем обновление может отвергаться
в единственном случае, когда оно требует поместить значение "пусто"
в какой-либо ключевой домен.
Назовем эти свойства завершаемостью (termination), детермнированностью (determinancy)
и пластичностью (compliancy). Мы предполагаем, что процедуры поддержки
инвариантов, приведенные в таблице III, обладают всеми
этими тремя свойствами.
6. Заключительные замечания
Обсудим в этом разделе несколько аспектов родовой структуры, в том числе,
методы проектирования баз данных, технику реализации и языки запросов.
Мы начнем с методов проектирования баз данных – сначала обсуждение будет концентрироваться на
"нормальных формах", и затем будет перенесено на методологию
проектирования.
В разд. 3 мы определили, что отношение является правильно определенным,
если оно удовлетворяет пяти реляционным инвариантам. Кодд [1] и другие авторы предложили несколько нормальных форм как некоторое понятие
"хорошего" отношения. Какова связь между правильно определенным
отношением и отношением в нормальной форме?
По существу, нормальные формы являются попыткой формализовать понятие
"базисного агрегатного объекта" в терминах понятия функциональной
зависимости. Эти нормальные формы не предназначены для того, чтобы иметь
дело со свойствами обобщения. Если задан агрегатный
объект, нормальные формы полезны в решении вопроса, является ли этот объект
базисным (т.е. для этого объекта не имеется никаких других объектов, встроенных
в него). Однако в настоящее время нормальные формы не позволяют охарактеризовать,
что такое агрегатный (или не агрегатный) объект.
С интуитивной точки зрения, агрегатный объект – это нечто, что мы можем
именовать существительным (или именным словосочетанием) и,
вероятно, рассматривать как единое целое. Требуя, чтобы отношения были
именованными, агрегатная структура фиксирует этот аспект агрегатного объекта.
В нормальных формах именование не учитывается явным образом, и в результате отношения
в нормальной форме могут быть не именуемыми действенным образом
(не считая сентенционного описания). Так, например, отношение R на
рис. 20 удовлетворяет (мы полагаем) требованиям всех известных из публикаций
нормальных форм. Однако это отношение не представляет собой агрегатный
объект, поскольку оно, очевидно, не имеет какого-либо имени, удовлетворяющего
семантическим критериям правильно определенного объекта.
R (мужчина, стоимость недвижимости, женщина, стоимость недвижимости)
Кортеж принадлежит R, если и только если
x обладает какой-либо долей недвижимости стоимостью y,
z обладает какой-либо долей недвижимости стоимостью w, и
y > w.
(Предполагается, что и мужчины, и женщины,
могут обладать несколькими долями недвижимости.)
Рис. 20. Отношение в нормальной форме, которое не является именуемым действенным образом
С другой стороны, хотя агрегатная структура является более сильной попыткой
фиксации понятия "агрегатного объекта", она не фиксирует
понятия "базисный". Мы полагаем поэтому, что "правильно
определенное отношение" и "отношение в нормальной форме"
являются взаимно-дополняющими друг друга критериями для использования при
проектировании баз данных. В том случае, если были обнаружены правильно
определенные отношения, их внутренняя структура зависимостей может быть
проверена по критериям нормальных форм. Если правильно определенное отношение
не находится в нормальной форме, может быть целесообразной (или не целесообразной)
дальнейшая декомпозиция этого отношения.
В работе [4] была предложена методология проектирования баз данных,
которая приводит к агрегатным объектам, а затем – к правильно определенным
отношениям. Эта методология не рассматривает, однако, декомпозицию в плоскости
обобщения (т.е., неявно предполагались одноуровневые родовые иерархии).
Тем не менее, она может быть расширена очевидным образом с тем, чтобы рассматривать
декомпозицию в обоих плоскостях. Может быть, наиболее выгодно осуществлять
декомпозицию в плоскости обобщения прежде, чем проводить декомпозицию в
плоскости агрегации. Причина заключается в том, что каждый кластер, вводимый
в плоскости обобщения, требует вставки некоторого нового объекта в плоскости
агрегации.
Следует теперь сделать несколько комментариев относительно техники реализации
реляционных моделей на более низких уровнях. В такой реализации необходимо
рассматривать два фактора:
- как представляется структура отношения и
- каким образом поддерживаются реляционные инварианты.
Одно из соображений,
принимаемых во внимание при выборе представления структуры, – экономия
пространства памяти за счет исключения избыточной информации. Такая информация
возникает как в плоскости агрегации, так и в плоскости обобщения. В плоскости
агрегации она появляется в результате повторения значений ключа вверх по
иерархии. В плоскости обобщения она появляется, когда значения ключевых
или неключевых атрибутов повторяются вверх по иерархии. Одним из следствий
удовлетворения реляционных инвариантов является обеспечение согласованности
всей избыточной информации. Следовательно, при максимально возможном исключении
избыточной информации реляционные инварианты будут поддерживаться наиболее
эффективным образом.
Предварительные исследования показывают, что реляционные модели могут
представляться без какой-либо избыточности в терминах структур наборов
DBTG (Database Task Group)***). Для
плоскости агрегации каждая иерархическая ветвь становится отдельным типом
набора с отношением более высокого уровня в качестве типа члена и отношением
более низкого уровня в качестве типа владельца. Каждый экземпляр набора
содержит в качестве членов все кортежи, которые ссылаются на кортеж-владелец.
В плоскости обобщения каждая совокупность иерархических ветвей, исходящих
из заданного отношения, становится отдельным типом набора. Отношение более
высокого уровня представляет тип владельца, а все подчиненные ему отношения
– типы членов. Каждый экземпляр набора содержит в качестве членов все образы-потомки
данного кортежа-владельца. Большинство реляционных инвариантов, как нам
кажется, может поддерживаться с помощью возможностей языка определения
данных DBTG. Этот вопрос, однако, еще полностью не решен.
Обсудим, наконец, некоторые вопросы, связанные с языками доступа для
реляционных моделей. Когда мы начинали наше исследование обобщения и его
представления в реляционных моделях, мы предполагали, что язык запросов
высшего порядка был бы существенным для операций над богатой иерархической
структурой. Казалось, что помимо переменных первого порядка, определенных
на отношениях первого порядка (т.е. отношений индивидуумов), для оперирования
отношениями высших порядков (т.е., отношений отношений и т.д.) были бы
необходимы переменные высших порядков.
Однако мы недооценили мощь абстракции. Наша мотивация родовых структур
заключалась в обеспечении унифицированной интерпретации всех видов объектов
– индивидуальных, агрегатных и родовых. Это означает, что отношения высших
порядков структурно идентичны отношениям первого порядка. В результате
язык запросов первого порядка оказывается адекватным для всех реляционных
моделей, безотносительно к тому, как много уровней обобщения они содержат.
По существу, навязывая соответствующую дисциплину структурирования, мы
способны эксплуатировать богатство, которое уже подразумевалось в
первоначальной работе Кодда.
Несмотря на тот факт, что язык первого порядка может быть адекватен
для запросов, существуют серьезные причины разработки примитивов высших
порядков для программирования приложений. Рассмотрим следующий запрос,
связанный с реляционной моделью, представленной на рис.11:
"Выяснить, какой тип имеет служащий E5, а затем извлечь его
запись из множества записей этого типа служащих."
Этот запрос можно удобно выразить в двух частях, как показано ниже:
Часть 1:
R ← RESTRICT (employee to E# = E5);
S ← PROJECT (R on TN);
RETRIEVE S;
Часть 2 (в предположении, что ответ на Часть 1 – "trucker"):
T ← RESTRICT (trucker to E# = E5);
RETRIEVE T;
Первая часть возвращает тип служащего E5, например, "trucker",
а вторая часть извлекает запись E5 из множества записей типа "trucker". В этом случае пользователь должен формулировать вторую
часть, исходя из информации, полученной в первой части.
Если бы этот запрос реализовался как прикладная программа, пользователя
можно было бы "заменить" приведенным ниже оператором case:
READ X;
R ← RESTRICT (employee to E# = X);
S ← PROJECT (R on TN);
T ← case S of
trucker: RESTRICT (trucker to E# = X);
secretary: RESTRICT (secretary to E# = X);
engineer: RESTRICT (engineer: to E# = X)
end
RETRIEVE T;
Проблема с использованием оператора case состоит в том, программа становится
зависимой от родовых компонентов "employee" в один из моментов
времени. Если нанимают служащего нового типа (скажем, "cторожа" (guard)),
то программа не будет работать, когда будет введен номер служащего-сторожа.
Эта "зависимость от времени" может быть устранена с помощью
оператора более высокого порядка, который мы назовем SPECIFY. При заданном имени
отношения оператор SPECIFY будет возвращать отношение с таким именем. Теперь
можно переписать программу так, как показано ниже.
READ X;
R ← RESTRICT (employee to E# = X);
S ← PROJECT (R on TN);
T ← SPECIFY S;
U ← RESTRICT (T to X);
RETRIEVE U;
Новая программа независима от родовых компонентов "employee"
в любой момент времени.
Введение примитивов более высокого порядка может, таким образом, повысить стабильность
программ при эволюционировании базы данных в соответствии с реальным
миром. Не ясно, какие другие операторы высших порядков полезны наряду с
SPECIFY. Насколько нам известно, эти аспекты программирования приложений
должны еще быть исследованы.
Благодарности
Мы благодарны за замечания Р.В.Тейлору (R.W. Taylor) и анонимным рецензентам ранней
версии этой работы.
Ссылки и библиография
1. Codd, E.F. Further normalization of the data base relational model.
In Courant Computer. Science Symposium 6: Data Base Systems, Prentice-Hall,
Englewood Cliffs, N.J., May 1971, pp. 33-64.
2. Hoare, C.A.R. Notes on data structuring. In APIC Studies in Data
Processing. No. 8: Structured Programming, Academic Press, New York, 1972,
pp. 83-174.
3. Quillian, M.R. Semantic memory. In Semantic Information Processing,
M.I.T. Press, Cambridge, Mass., 1968, pp. 227-268.
4. Smith, J.M., and Smith , D.C.P. Database abstractions: Aggregation.
Commun. ACM, 20, June 1977, pp. 405-413.
*) Приведенные
в таблице аббревиатуры представляют названия профессиональных обществ:
ACM – Association for Computing Machinary – Ассоциация по вычислительной
технике, крупная международная организация , объединяющая специалистов
во всех областях информатики. Ряд секций ее групп по интересам (SIG) работает
в России.
IEEE CS – The Institute of Electrical and Electronics Engineers,
Inc., Computer Society – Институт инженеров в области электротехники и
электроники, крупная международная организация , объединяющая профессионалов
в области информатики.
AMA – American Medical Association – Американская Ассоциация медицинских
работников.
**) Здесь и
далее авторы используют понятие "реляционная модель", в соответствии
с ранней (структурной) трактовкой понятия "модели данных". -
Примеч. пер.
***) Авторы
имеют в виду Рабочую группу по базам данных КОДАСИЛ (CODASYL Data Base
Task Group), опубликовавшую в 1969 году целостную концепцию систем управления
базами данных сетевой структуры, включающую, в частности, первоначальную
версию соответствующей модели данных, а также спецификации основанных на
этой модели данных, а также спецификации основанных на этой модели языковых
средств определения данных и манипулирования данными. В литературе, однако,
чаще всего цитируется отчет DBTG 1971 года, содержащий следующую, значительно
более продвинутую версию ее предложений. (См. Язык описания данных КОДАСИЛ.
/Пер. с англ. – М.: Статистика, 1981.) – Прим. перев.
1)
Похожа на структуру записи в Паскале.
2) Похожа на структуру
записи с вариантами в Паскале.
3) Если представляли
бы интерес транспортные средства-амфибии, то был бы включен родовой объект
"amphibious vehicle”" как альтернатива "air vehicle",
"water vehicle" и "land vehicle".
4) Кортеж может
иметь несколько образов предков, хотя каждый из них должен принадлежать
различным отношениям. Для примера можно обратиться к иерархии на
рис. 2.
5) Эти инварианты
могут использоваться как аксиомы для спецификации семантики (в стиле Хоара
[2]) родовой структуры. К этим пяти инвариантам необходимы дополнительно
и другие аксиомы.

