Оптимизация запросов в системах баз данных
Матиас Ярке, Юрген Кох
Перевод - Сергей Кузнецов
Оригинал: Matthias Jarke, Jurgen Koch. Query Optimization in Database Systems. Computing Surveys, Vol. 16, No. 2, June 1984
Продолжение |
Начало |
4. ВЫЧИСЛЕНИЕ ЗАПРОСОВ
В этом разделе мы представляем методы вычисления компонентов запросов разной сложности, таких как выражения с единственной переменной, выражения с двумя переменными и выражения с многими переменными. Индивидуальные подходы можно представлять как строительные блоки общей системы вычисления запросов. Их стоимость и диапазоны применимости составляют исходные данные для последней стадии процесса оптимизации запросов, на которой генерируется оптимальный план доступа.
4.1 Выражения с одной переменной
Выражения с одной переменной описывают условия для выборки элементов из одного отношения. Наивный подход к их вычислению состоит в чтении каждого элемента отношения и проверке того, удовлетворяет ли он каждому терму выражения. Поскольку этот подход является очень дорогостоящим при наличии крупных отношений и сложных выражений, используются разнообразные методы для сокращения числа обращений к элементам и числа проверок, применяемых к прочитанным элементам.Прямой и упорядоченный доступ может обеспечиваться индексами, возможно, объединяемыми с мультисписочными структурами [Welch and Graham 1976; Yang 1977]. С концептуальной точки зрения, индекс является бинарным отношением, связывающим значения атрибутов со ссылками на элементы отношения, обычно называемыми идентификаторами кортежей (TID). Мы отличаем одномерные индексы, которые поддерживают доступ на основе одного атрибута отношения, от многомерных индексов, которые поддерживают доступ через комбинацию атрибутов. Одномерные индексы обычно реализуются на основе структур ISAM [IBM 1966] или B-деревьев [Bayer and McCreight 1972]. Обзор многомерных индексных структур приводится в [Bentley and Friedman 1979]. В число примеров входят работы [Shneiderman 1977] по комбинированным индексам, [Nievergelt et al. 1984] по грид-файлам и [Gardarin et al. 1984] по предикатным деревьям. Хотя пути доступа обычно невидимы для пользователей, сообщается об усилиях по разработке представлений на языках высокого уровня, доступных для тех программистов, которые настаивают на предельной эффективности. Такие языковые построения простираются от TID'ов [Jarke and Schmidt 1981; van de Riet et al. 1981] до абстрактных представлений полных путей доступа [Mall et al. 1984; Schmidt 1984; Tsichritzis 1976].
Число проверок, применяемых к выбранному элементу отношения во время вычисления выражения, может быть сокращено путем преобразований выражения во время выполнения. Оптимизация специального класса выражений, булевских выражений, на протяжении долгого времени является темой исследований в области конструирования компиляторов [Gries 1971]. Булевские выражения (т.е. безкванторные термы, связанные через AND/OR) являются составной частью ряда управляющих структур в языках программирования высокого уровня. Цель оптимизации булевских выражений состоит в генерации кода, который пропускает вычисление компонентов выражения, более не существенных для значения выражения в целом. Например, в операторе
IF A AND B THEN statement_l ELSE statement_2 END,
если терм A уже вычислен как "false", то вычисление терма B является избыточным, и может сразу выполняться ветвь ELSE. Если та же идея применяется для вычисления выражений с одной переменной [Gudes and Reiter 1973; Liu 1976], то запросы можно упрощать во время выполнения.
Другой подход, разработанный для совершенствования эффективности, состоит в изменении порядка вычисления индивидуальных компонентов выражения. Известно несколько алгоритмов для достижения в некоторых ситуациях оптимальных последовательностей выполнения; в некоторых из них предполагается наличие априорных вероятностей значений атрибутов [Hanani 1977], а другие работают без таких предположений [Breitbart and Reiter 1975]. Варрен [Warren 1981] применяет аналогичный метод для оптимизации программ, выраженных в логике.
4.2 Выражения с двумя переменными
Выражения с двумя переменными описывают условия для комбинации элементов из двух отношений. Вообще говоря, выражения с двумя переменными составляются из одноместных термов, ограничивающих одиночные переменные независимо одна от другой, и двухместные термы, утанавливающие связь между обоими переменными. В этом разделе мы сначала описываем базовые методы вычисления одиночного двухместного терма, соответствующего операции соединения в разд. 2.2, а затем стратегии вычисления произвольных выражений с двумя переменными.
Подходы к реализации операции соединения можно классифицировать на стратегии, зависящие от порядка, и стратегии, не зависящие от порядка [Todd 1974]. Простым методом, не зависящим от порядка доступа к элементам, является так называемый метод вложенной итерации (nested iteration) [Pecherer 1975, 1976; Selinger et al. 1979], в котором считывается каждая пара элементов отношений, и эта пара конкатенируется, если удовлетворяется условие соединения. Набросок алгоритма выглядит следующим образом:
FOR i := 1 TO N1 DO
read ith element of rel1;
FOR j := 1 TO N2 DO
read jth element of rel2;
form the join according to the join condition;
END;
END;
Пусть N1(N2) - число элементов отношения, считываемых во внешнем (внутреннем) цикле. Для вычисления двухместного терма требуется N1 + N1 * N2 обращений ко вторичной памяти, если считать, что для каждого элемента требуется обращение ко вторичной памяти.
Метод вложенной итерации может быть дополнен использованием индекса на атрибуте(ах) отношения "rel2". Вместо последовательного сканирования каждого элемента "rel2" для каждого элемента "rel1" парные элементы "rel2" выбираются напрямую [Griffeth 1978; Klug Klug 1982b]. Таким образом, требуется всего N1 + N1 * N2 * j12 обращений, где j12 - коэффициент селективности, характеризующий сокращение декартова произведения "rel1" и "rel2" в соответствии с условием соединения.
В методе вложенных блоков (nested block method) [Kim 1980] метод вложенной итерации адаптируется к среде страничной памяти. Предполагается, что в буфере основной памяти будет храниться по одной или более страниц каждого отношения, и в каждой странице содержится набор записей.
Сам алгоритм в основном идентичен алгоритму, применяемому в методе вложенной итерации, за ислючением того, что считываютмя страницы памяти, а не одиночные элементы отношений. Число обращений ко вторичной памяти, требуемых для выполнения соединения, сокращается до P1 + (P1/B1) * P2, где P1(P2) - это число страниц, занимаемых внешнем (внутренним) отношением, и B1 - это число страниц внешнего отношения, удерживаемых в буфере основной памяти. Формула показывает, что во внешнем цикле всегда выгоднее считывать меньшее отношение (т.е. делать P1 < P2). Заметим, что если одно из отношений может целиком удерживаться в буфере основной памяти, то требуется P1 + P2 обращений.
Метод слияния (merge method) [Blasgen and Eswaran 1977; Selinger et al. 1979] основывается на порядке, в котором производится доступ к элементам отношения. Оба отношения сортируются в порядке возрастания или убывания значений атрибутов соединения, и производится слияние в соответствии с условием соединения. Требуется приблизительно N1 + N2 + S1 + S2 обращений к вторичной памяти, где S1 и S2 обозначают число обращений к вторичной памяти, требуемых для сортировки обоих отношений. Если оба отношения уже отсортированы в соответствии с тем же критерием, то метод слияние выглядит наиболее эффективным методом вычисления двуместных термов [Merrett 1981; Merrett et al. 1981]. Исключениями являются те случаи, когда оба отношения достаточно малы, чтобы поместиться в основной памяти, (в этом случае предпочтительнее метод вложенных блоков), и когда одно отношение гораздо больше другого, и возможно использование индексов (в этом случае лучше работает вложенная итерация с использованием индексов).
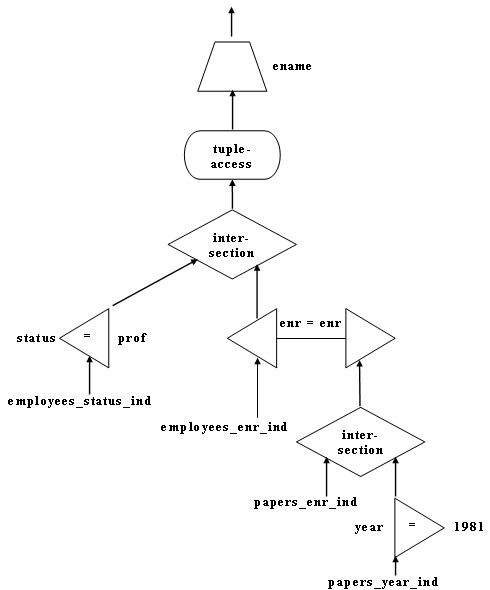
Рис 5. Граф операций, иллюстрирующий вычисление запроса из Примера 2.1.
Предполагается наличие различных индексов
Методы вычисления произвольных выражений с двумя переменными создаются на основе стратегий для выражений с одной переменной и алгоритмов вычисления двухместных термов. Они различаются способами использования и даже создания путей доступа, таких как индексы и сортировка, и порядком обработки термов. Один из таких методов иллюстрируется на рис. 5. В нем широко используются индексы. Идентификаторы кортежей, получаемые при обработке одноместных термов, и те, которые удовлетворяют условию соединения, пересекаются и затем используются для доступа к элементам отношений. Эти элементы проецируются на атрибуты, встречающиеся в двухместных термах и целевом списке. Спроецированные элементы конкатенируются и в заключение проецируются на целевой атрибут.
В [Blasgen and Eswaran 1976, Niebuhr and Smith 1976, Yao and DeJong 1978 и 1979] описываются разнообразные другие алгоритмы и приводится их систематическое сравнение в отношении эффективности. Эти результаты демонстриуют, что часто не существует априорно лучший алгоритм. Оптимизатор должен либо полагаться на эвристики, либо производить дорогостоящее сравнение стоимости многих альтернатив для каждого запроса.
Важным случаем выражений с двумя переменными являются соединения, в которых одна из участвующих переменных ("внутренняя") связана квантором существования или всеобщности. Результат такого выражения содержит только элементы одного отношения. Кроме того, доступ к другому отношению требуется только для того, чтобы установить, удовлетворяется ли условие соединения для данного значения "внешней" переменной каким-либо элементом (соответственно, всеми элементами) отношения области определения "внутренней" переменной. Сами элементы не представляют интереса. Это означает, что для вычисления квантифицированных запросов промежуточные результаты можно представлять в сжатой форме [Dayal 1983a; Jarke and Schmidt 1981]. Если в выражении с двумя переменными содержится только один соединительный терм с операцией сравнения <, d ,>, или e, то требуется только одно значение атрибута (минимальное или максимальное значение атрибута внутреннего отношения). Тем самым, квантифицированное выражение с двумя атрибутами может быть преобразовано к одноместному терму [Jarke and Koch 1983]. Кстати, аналогичное использование агрегатных функций (максимума и минимума) предлагается в контексте поддержания целостности [Bernstein et al. 1980].
4.3 Выражения с несколькими переменными
Стратегии вычисления выражений с несколькими переменными являются наиболее крупными блоками для построения общей системы обработки запросов. Существуют два основных подхода, называемые параллельной обработкой и пошаговым сокращением (stepwise reduction).Параллельная обработка компонентов запроса служит для того, чтобы избегать повторяющихся обращений к одним и тем же данным. Повторяющихся обращений к одним и тем же данным можно избежать путем одовременного вычисления нескольких компонентов запроса. В Palerno [Palermo 1972] все одноместные термы, связанные с некоторой переменной, полностью вычисляются, и все двухместные термы, в которых встречается та же переменная, частично обрабатываются одновременно путем сканирования отношения области определения этой переменной. В параллель можно вычислять даже связки через AND между термами, что еще больше сокращает размер промежуточных результатов [Jarke and Schmidt 1982]. Аналогичные подход на более высоком уровне описан в [Klug 1982b]; в этом подходе в параллель вычисляются агрегатные функции и сложные подзапросы. Стратегии планирования для параллельной обработки компонентов запросов обсуждаются Шмидтом в [Schmidt 1979].
Другим подходом, использующим преимущества параллельной обработки, являются конвейерные операции, которые могут работать с частичными результатами предыдущих операций [Smith and Chang 1975; Yao 1979]. Например, ограничение и проекция могут конвейеризоваться, так что требуется только относительно небольшой буфер для обмена данными, а не создание и последующее чтение, возможно, большого временного отношения.
Аспекты одновременного вычисления и конвейеризации объединяются в так называемом методе "обратной связи" ("feedback" method) [Clausen 1980; Rothnie 1974, 1975], в котором частичные результаты операции соединения используются для ограничения ее входных данных. То, в какой степени это можно проделать, зависит от квантификации переменных, содержащихся в соединительном терме. Например, рассмотрим выражение
[EACH rl IN rel1: ALL rel2 IN rel2 (rl.A op rel2.B)].
Предположим, что соединительный терм вычисляется методов вложенной итерации. Пусть при проверке некоторого элемента rl обнаруживается, что терм "rl.A op rel2.B" вычисляется в false для некоторого rel2 с rel2.B = c1. Поскольку rel2 связана квантором существования, rl отвергается, и к выражению выборки может быть добавлен исключающий фильтр
[EACH rl IN rel1: NOT (rl.A op cl) AND ALL rel2 IN rel2 (rl.A op rel2.B)],
поскольку одно и то же значение rel2 вызвало бы отклонение всех элементов rl из "rel2", которые не удовлетворяют первому терму. С другой стороны, если rl с rel1.A = c2 проходит проверку, к предикату выборки можно добавить фильтр "истинности":
[EACH rl IN rel1: rl.A op c2 OR NOT (rl.A op cl) AND ...].
Оба фильтра впоследствии могут обновляться для усиления ограничений.
Второй подход к вычислению выражения с несколькими переменными обосновывается посредством следующего примера:
Пример 4.1. На рис. 6 показан объектный граф, представляющий выражение
[<d.dname> OF
EACH d IN departments:
SOME e IN employees(e.status = professor
AND
e.city = d.city)
AND
SOME l IN lectures (l.daytime > 8 pm
AND
l.dname = d.dname)]
Выражения, подобные приведенному в Примере 4.1, называются древовидными выражениями [Goodman and Shmueli 1982; Shmueli 1981], поскольку ассоциированный с ними граф является деревом. Стандартный подход к вычислению такого выражения состоял бы в формировании соединения всех трех отношений, ограничении промежуточного результата в соответствии с одноместными термами и заключительной проекции на атрибуты, указанные в целевом списке. Как показано во вводном примере (разд. 1.2, стратегия 2), этот метод выполняется довольно плохо. Это еще более проблематично в распределенной среде, где каждое отношение располагается в своем узле, и нужно передавать из узла в узел отношения целиком. Более того, отношение в целевом узле может быть временно расширенным для формирования соединения, хотя окончательный результат представляет всего лишь его горизонтальное и вертикальное подмножество.
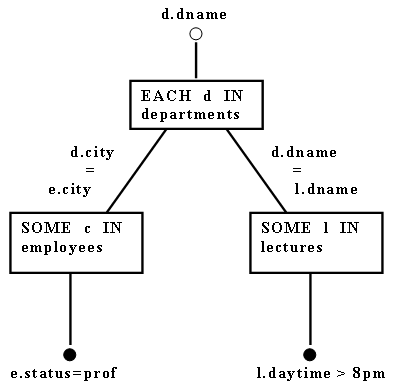
Рис. 6. Объектный граф для Примера 4.1
В [Bernstein and Chiu 1981, Bernstein et al. 1981 и Bernstein and Goodman 1981a, 1981b, 1981c] предлагается пошаговое сокращение древовидных выражений (со свободными перемеными и переменными, связанными квантором существования). Это метод часто превосходит по производительности описанный выше простой подход, как в децентрализованных, так и централизованных средах. Он основывается на модифицированной операции соединения, и в нем используется так называемая операция полусоединения.
Полусоединение отношения "rel1" с отношением "rel2" равняется соединению этих отношений, спроецированному на атрибуты отношения "rel1":
semijoin(rel1, A op B, rel2)
= proj(join(rel1, A op B, rel2), attributes rel1)).
Таким образом, эта операция формирует "половину соединения". Основные премущества полусоединения над соединением состоят в следующем: (1) для его вычисления требуется передача только списка значений атрибутов соединения вместо отношения целиком, и (2) оно обладает эффектом "сокращения", поскольку результат semijoin(rel1, A op B, rel2) всегда является подмножеством rel1, тогда как соединение в худшем случае может производить декартово произведение. Как обсуждалось в разд 4.2, в терминах реляционного исчисления полусоединение соответствует выражению с двумя переменными, где одна переменная связана квантором существования.
Простейшее вычисление древовидного выражения средствами пошагового сокращения можно описать следующим образом. Начиная с листьев дерева запроса, представляющего выражение, выполняется по одному полусоединению на каждую дугу в порядке обхода дерева в ширину от листьев к корню. Таким образом, выражение, содержащее одну свободную переменную и n-1 переменных, связанных квантором существования, может быть полностью обработано за n-1 полусоединение.
Если все переменные являются свободными, должна выполняться дополнительная последовательность полусоединений в обратном порядке. В централизованной среде этот вид стратегии полусоединений уступает операции соединения слиянием. Объединенной с параллельным вычислением кванторов. Даже в распределенной системе простая последовательность "снизу-вверх/сверху-вниз" часто оказывается менее эффективной, чем последовательность "с середины" (middle-out), которая начинается с полусоединений с очень сильным сокращением [Chiu and Ho 1980; Chiu et al. 1981].
В стратегиях вычисления древовидных выражений, содержащих и кванторы существования, и кванторы всеобщности, необходимо учитывать порядок, в котором кванторы появляются в выражении. Пошаговое сокращение возможно только в тех случаях, когда обработка дуг в дереве запросов (в ширину, от листьев к корню) соответствует порядку кванторов в выражении (слева направо).
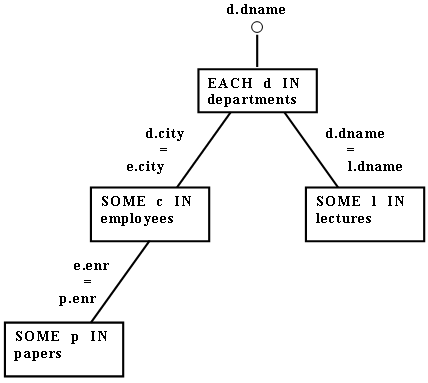
Рис. 7. Объектный граф для Примера 4.2
[(d.dname) OF
EACH d IN departments:
ALL p IN papers
SOME e IN employees
(p.enr = e.enr AND e.city = d.city)
AND
SOME 1 IN lectures (1.dname = d.dname)]
Обработка этого дерева в порядке обхода в ширину от листьев к корню привела бы к получению значения выражения
[<d.dname> OF
EACH d IN departments:
SOME e IN employees
ALL p IN papers
(p.enr = e.enr AND e.city = d.city)
AND
SOME l IN lectures (l.dname = d.dname)],
которое не является эквивалентным исходному выражению.
Кванторы существования и всеобщности нельзя менять местами без изменения смысла выражения за исключением случаев, в которых применимы правила Q1-Q4 из таб. 1. В выражениях, содержащих только один тип кванторов, допускается произвольное изменение последовательности переменных в соответствии с правилами преобразования Q5 и Q6. Ярке и Кох [Jarke and Koch 1983] описывают направленный, так называемый "квант-граф" (quant graph), который поддержиавает применение этих правил.
Циклические выражения являются дополнением древовидных выражений по отношению ко всему множеству выражений. Хотя мы приводили некоторые исключения в разд. 3.3, в общем случае циклические выражения не могут быть полностью сокращены посредством полусоединений [Bernstein and Goodman 1981a, 1981b; Goodman and Shmueli 1982].
Пример 4.3. Рассмотрим запрос: "Названия отделов, в которых предлагаются лекции после 8 часов вечера, читаемые профессорами, проживающими в том же городе, где находится отдел". Соответствующие выражение реляционного исчисления и граф запроса показаны на рис. 8.
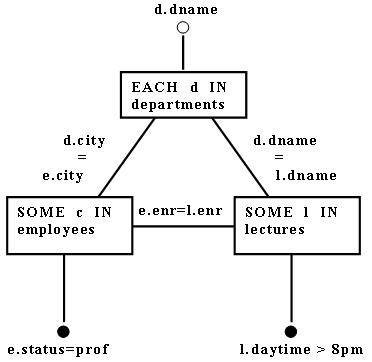
Рис 8. Циклическое выражение исчисления и соответствующий ему объектный граф
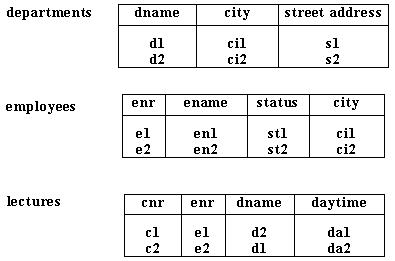
Рис 9. Некоторое возможное состояние базы данных
Если база даных находится в состоянии, показанном на рис. 9, никакая последовательность полусоединений (соответствующих дугам графа запроса с рис. 8) не произведет правильного результата (пустое отношение). Причина состоит в том, что в методе полусоединений в каждый момент времени рассматривается только одна дуга, и за счет этого теряются ограничительные условия, введенные на основе эффекта обратной связи цикла:
[(d.dname) OF
EACH d IN departments:
SOME e IN employees
(e.status = professor
AND
SOME l IN lectures
(l.daytime > 8 pm
AND
d.dname = l.dname AND l.enr = e.enr
AND e.city = d.city))]
В [Kambayashi et al. 1982] предлагается обобщить применимость метода полусоединений к циклическим выражениям. Общая идея состоит в преобразовании циклического графа запроса в дерево путем добавления соответствующих термов к дугам графа. На рис. 10 демонстрируется этот метод, примененный к циклическому выражению из Примера 4.3.
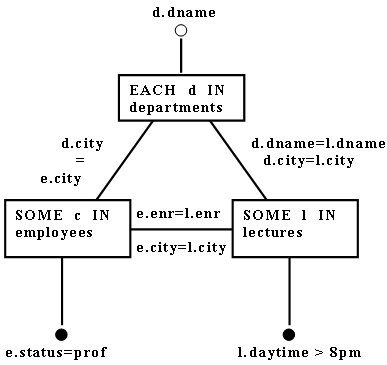
Рис 10. Дополненный объектный граф для Примера 4.3
Дополнительные термы "d.city = 1.city" и "l.city = e.city" влекут условие "d.city = e.city" по транзитивности. Таким образом, результирующий граф эквивалентен "цепочному" запросу (chain query), частной форме древовидного запроса. Заметим, что это добавление новых термов, по существу, соответствует добавлению в схему отношения "lectures" атрибута "city" (инициализированного неопределенным значением).
Затем дерево запроса обрабатывается пошаговым сокращением с выполнением обобщенного полусоединения для каждой дуги (с учетом заново введенного атрибута). Число пересылок данных сокращается за счет использования специальных методов сжатия.
Методы эффективной реализации операций, подобные представленным в этом разделе, являются кандидатами на роль компонентов аппаратуры специализированных машин баз данных. Однако в таких компонентах часто допускается параллелизм и, следовательно, требуются несколько иные алгоритмы соединений и полусоединений [Bitton et al. 1983; Maekawa 1982; Missikoff and Scholl 1983; Valduriez 1982; Valduriez and Gardarin 1984]. Краткий обзор аппаратных подходов к оптимизации запросов представлен в разд. 6.3.
5. ПЛАНЫ ДОСТУПА
В предыдущем разделе мы имели дело с методами эффективного вычисления компонентов запросов, которые можно использовать, как строительные блоки общего алгоритма выполнения запроса. Для завершающего шага нашего каркаса выполнения запросов требуется объединение этих блоков в эффективную процедуру выполнения произвольного стандартизированного, упрощенного и улучшенного выражения. К сожалению, работа в этой области еще не завершена.На вход такой процедуры поступают логически предобработанный запрос (как описывалось в разд. 3), существующие структуры хранения и пути доступа и стоимостная модель. На выходе появляется оптимальный (или, по крайней мере) эвристически "хороший") план доступа. Процедура состоит из следующих шагов:
- Сгенерировать все разумные логические планы доступа для выполнения запроса. Логический план доступа описывает последовательность операций или промежуточных результатов, ведущих от существующих отношений к окончательному результату запроса.
- Пополнить логические планы доступа деталями физического представления данных (порядки сортировки, существование физических путей доступа, статистическая информация).
- Выбрать наиболее дешевый план путем применения модели стоимости доступа и обработки.
В этом разделе мы обозреваем генерацию путей доступа, стоимостных моделей для их оценки и проблему выбора наиболее дешевого плана. На качество окончательного плана сильно влияют существующие структуры хранения и пути доступа, которые обычно невозможно оптимизировать для одного непредвиденного запроса. Поэтому в разд. 5.4 мы кратко рассматриваем одновременную оптимизацию нескольких запросов.
5.1 Генерация планов доступа
Планы доступа описывают последовательности операций (представленные графами операций) или промежуточных результатов (объектные графы), ведущие от существующих данных к результату запроса. Оптимизатор запросов должен генерировать достаточно обильный набор планов, чтобы в нем содержался оптимальный план, и достаточно умеренный, чтобы удержать накладные расходы на приемлемом уровне.Два предельных подхода демонстрируются в [Smith and Chang 1975 и Yao 1979]. Смит и Чанг используют жесткий набор "автоматически программирующих" правил преобразования запросов, похожих на те, которые обуждались в разд. 3. Их процедура генерирует ровно один план, не обязательно оптимальный. Метод Яо генерирует все недоминируемые планы доступа, возможные в данной физической среде. Хотя этот подход может быть пригодным в контексте запросов с двумя переменными, он становится недопустимо дорогостоящим для более сложных запросов.
В других подходах ищется компромисс между эвристическим выбором и детальной генерацией альтернативных планов доступа. Например, в System R [Chamberlin et al. 1981; Selinger et al. 1979] применяется эвристическая процедура, основанная на концепции вложенных блоков SQL. На более нижнем уровне генерируются и сравниваются планы выполнения для каждого блока запроса. На верхнем уровне определяется последовательность выполнения блоков запроса. В [Kim 1982] отмечается, что зависящей от пользователя блочной структуре запроса уделяется слишком много внимания, и предлагается ввести в обработку SQL-запросов шаги стандартизации.
Аналогичный компромисс был выбран в INGRES [Youssefi and Wong 1979]. Поход эвристической декомпозиции преобразует подход к набору подзапросов, каждый из которых содержит не более двух переменных. Для каждого из этих подзапросов производится более детальный анализ его оптимальной реализации.
Исчерпывающая процедура генерации планов доступа для решения конъюнктивных запрросов без кванторов всеобщности и агрегатов предложена в [Rosenthal and Reiner 1982]. Расширенное представление в виде объектного графа используется для моделирования стратегий вычисления, в которых применяются вспомогательные структуры прямого доступа. Чтобы избежать генерации чрезмерного числа стратегий, генерация планов доступа перекрывается с шагом выбора. Не создаются стратегии, противоречащие другим процедурам.
5.2 Анализ стоимости планов доступа
Выбор физических планов доступа определяется эвристическими правилами или основывается на стоимостной модели структур хранения и операций доступа [Merrett 1977]. В этом разделе обозреваются стоимостные модели и их интеграция в процедуры оптимизации.Хотя несколько исследователей анализируют требования к рабочей памяти [Kim 1982; Lang et al. 1977; Sacco and Schkolnick 1982] или затраты ЦП [Gotlieb 1975; Selinger et al. 1979], большинство стоимостных моделей основывается на числе обращений к вторичной памяти. Для данной операции на эту величину влияет размер операндов, используемые структуры доступа и размер буферов основной памяти.
В начале вычисления операндами являются существующие структуры данных известного размера, такие как отношения и индексы. Однако на более поздних стадиях большинство операндов является результатами предшествующих операций, и стоимостная модель должна оценивать их размер с использованием информации об исходных структурах данных и селективности операций, уже выполненных над ними. Хотя ведется много работ, пока отсутствуют общепринятые формулы для оценки размера промежуточных результатов. Отчасти это является следствием недостаточного понимания допустимого соотношения объема используемой информации и точностью результата.
Вообще говоря, чем более органичительными являются предположения о данных, тем меньше требуется параметров для вычисления размера результатов операций. Например, в [Demolombe 1980] описывается рекурсивная процедура оценки размера результата вычисления безкванторного выражения исчисления, для которой должны быть известны пять типов параметров, если доступны достаточно детальные статистические данные о базе данных. Однако при более ограничительных предположениях требуются только три из из них. В оценках размеров, приведенных в [Selinger et al. 1979], используется только информация, уже существующая в базе данных, но делается много предположений о данных и запросе [Astrahan et al. 1980]. В другой предельной точке Яо [Yao 1979] предполагает (неявно), что известны детальные данные о селективности; ничего не говорится о том, каким образом эти данные получаются. (Однако см. [Yao 1977b] на предмет модели стоимости доступа.)
В последние годы исследователи осознают потребность в тщательной формулировке и критическом анализе всех используемых предположений о характеристиках баз данных для генерации формально обоснованной системы параметров, которая позволяет
- вычислять оценку размера результата для каждой возможной операции и
- вычислять значения параметров промежуточных результатов для дальнейших операций.
В таких методах состояние базы данных во время выполнения представляется как случайный процесс, генерующий элементы отношения из декартова произведения доменов атрибутов под управлением некоторым распределением вероятности (которое обычно предполагается равномерным), а также общими правилами (например, функциональными зависимостями) схемы базы данных [Gelenbe and Gardy 1982; Richard 1981]. Из этих предположений выводятся параметры, значения которых должны быть известны для вычисления размера любого промежуточного результата сложных операций. Например, в [Richard 1981] демонстрируется, что достаточно знать размер всех проектов в базе данных, если распределения значений атрибутов являются равномерными и независимыми (даже если атрибуты определены на одном и том же домене).
В [Christodoulakis 1981, 1983 и Montgomery et al. 1983] приводится критический анализ таких предположений и показывается, что они ведут к предубеждению против структур прямого доступа в планах выборки. Однако пока не опубликованы какие-либо формулы с более общими предположениями и без чрезмерных требований данных.
Окончательной мерой стоимости является число обращений к вторичной памяти, а не размеры промежуточных результатов. В большом числе исследований оценивалась взаимосвязь между этит величинами [Cardenas 1975; Chan and Niamir 1982; Cheung 1982b; Luk 1983; Whang et al. 1983; Yao 1977a; Yu et al. 1978]. По существу, она зависит от используемых физических структур хранения и пропорции элементов, к которым происходит обращение.
Предположим сначала, что требуется доступ ко всем элементам операнда размером N. Тогда оптимальным числом обращений к вторичной памяти будет N/B, где B - коэффициент блокирования операнда. Этого можно достичь, только если элементы хранятся плотно, и с самого начала известно, на каких физических записях они располагаются. В качестве контрпримера, для так называемого "сегментного сканирования" в System R требуется доступ к надмножеству требуемых страниц, чтобы найти все элементы отношения [Selinger et al. 1979]. Если требуется читать элементы в некотором предопределенном порядке, они должны храниться не только плотно, но также и отсортированными в данном порядке.
Если используется прямой доступ к подмножеству элементов, то число обращений к вторичной памяти, требуемых для выборки n из N элементов будет зависеть от кластеризации элементов в физических блоках. В большинстве упоминавшихся выше моделей предполагается случайное размещение записей по блокам, что в некотором смысле соответствует худшему случаю [Christodoulakis 1981]. Оптимальная кластеризация может сократить число страниц, к которым требуется совершить обращение, до n/B.
В заключение заметим, что традиционные предположения о распределениях атрибутов и размещении элементов ведут к завышению стоимости, и поэтому оценки стоимости препятствуют использованию структур прямого доступа. С другой стороны, для более совершенные методов требуется больше статистической информации о базе данных. Вопрос о том, как сохранять такую информацию, к сегодняшнему дню еще не решен полностью.
5.3 Выбор путей доступа
Как оценки стоимости используются при оптимизации запросов? Как отмечалось в разд. 5.2, имеются эвристические процедуры, в которых они вообще не используются. В других подходах эвристическое сокращение выбора объединяется с перечислительной (enumerative) минимизацией стоимости в "конце игры" [Youssefi and Wong 1979]. Эксперименты показывают, что эффективность баз данных может существенно улучшить комбинаторный анализ [Epstein and Stonebraker 1980].Имеются два способа использования оценок стоимости в процессе выбора. Во-первых, стоимость каждого альтернативного плана доступа можно определить полностью [Blasgen and Eswaran 1976; Yao 1979]. Преимуществом этого подхода является реалистичный способ применения методов, подобных параллелизму и обратной связи. С другой стороны, высоки расходы на оптимизацию.
Во-вторых, стоимость стратегий можно вычислять инкрементально в параллель с их генерацией. Этот подход позволяет параллельно оценивать полное семейство стратегий с общими компонентами, что существенно сокращает расходы на оптимизацию. Например, в методе, предложенном в [Rosenthal and Reiner 1982], сохраняется только стоимость минимального способа получения промежуточного результата, и отвергается любой другой метод, распознаваемый как неоптимальный.
Расширением этого второго подхода является динамическая процедура оптимизации запросов, которая происходит из того наблюдения, что в каждый момент времени требуется принятие решение только по поводу выполнения следующей операции. Чтобы гаранировать общую оптимальность, должны оцениваться только последствия этого решения на оставшуюся часть вычисления. У динамической процедуры имеются реальные данные обо всех ее операндах, включая промежуточные результаты. Эта информация может также использоваться для обновления оценок оставшихся шагов. У динамического метода имеются два недостатка: его стоимость и опасность ошибки в локальном оптимуме, если не применять заглядывания вперед. Однако при аккуратном использовании этот метод может сократить оценки стоимости для запросов, в которых размер реальных промежуточных результатов отличается оцененных размеров.
5.4 Поддержка нескольких запросов
Все рассмотренные до сих пор процедуры вычисления запросов концентрировались на оптимизации выполнения одиночного запроса. В [Chesnais et al. 1983] исследуется также влияние на производительность параллельного доступа к базе данных нескольких пользователей. Однако стратегии оптимизации запросов могут могут даже выходить за пределы простого параллелизма за счет разделения (sharing) стоимости выполнения общих операций между несколькими запросами. Кроме того, стратегия, оптимизирующая одновременное выполнение нескольких запросов, может учитывать возможность инвестиций в дополнительные пути доступа, создание которых не было бы целесообразно по соображениям стоимости для одиночного запроса. Немногие подходв к оптимизации нескольких запросов можно разбить на три группы в соответствием со временем, когда принимаются решения:- одновременная оптимизация пакетных запросов,
- выбор индексов и
- физическое проектирование базы данных.
Из набора запросов, поставляемых одним или несколькими примерно в одно и то же время, для более эффективной обработки может быть образован пакет [Shneiderman and Goodman 1976]. Методы пакетной обработки аналогичны тем, которые описывались в разд. 4.3 и предсназначались для вычисления переменных со многими переменными. Прежде всего, при вычислении запросов могут использваться результаты общих подвыражений [Grant and Minker 1981; Jarke 1984], и, если при вычислении разных подвыражений требуются обращения к одной и той же физической странице данных, то можно сделать это за одно обращение к вторичной памяти. Во-вторых, могут обеспечиваться временные физические пути доступа, такие как сортировка, хэширование или индексы, стоимость которых окупается для пакета в целом. Наконец, результаты некоторых запросов могут быть сохранены для обработки последующими запросами [Finkelstein 1982; Hevner and Yao 1981]. Как кажется, в этой области пока отсутствует согласованная теория. В [Kim 1981, 1984 и Jarke 1984] описываются языковые конструкции и предварительные архитектуры, и ряд выполняемых проектов рассматривается в [IEEE 1982].
Многие примеры в этой статье демонстрируют важность использования индексов для обеспечения эффективности алгоритмов вычисления запросов. С этой точки зрения, индексы редко причиняют вред, но они наиболее полезны, если очень селективны и поддерживают доступ к атрибутам, часто встречающимся в запросах [Gilles and Schuster 1975]. Однако при выборе индекса необходимо учитывать изменяющие транзакции, посколько наряду с изменением базовых данных они должны изменять и индексы. Проблема выбора индексов описана в нескольких обзорах [Batory 1982] и учебных статьях [March 1983; Putkonen 1979; Schkolnick 1975; Severance and Carlis 1977]. Выбор и поддержка более общих индексов, поддерживающих пользовательские представления, исследовалась в [Roussopoulos 1982a, 1982b]. Использование конструкция языка высокого уровня для расширения понятий представления обсуждается в [Jarke 1984 и Schmidt 1984].
Наконец, оптимизация запросов влияет на физическое проектирование базы данных. Однако долговременная оптимизация является лишь одним аспектов физического проектирования баз данных (см., например, [Carlis et al. 1981, Carlson and Kaplan 1976, Schkolnick 1982 и Teorey and Fry 1982). Важные проектные стратегии, влияющие на эффективность обработки запросов, включают горизонтальную кластеризацию элементов отношений по значениям атрибутов [Salton 1978] и вертикальное разделение атрибутов в соответствии с частотой совместных обращений [Hammer and Niamir 1979].
6. НЕСТАНДАРТНАЯ ОПТИМИЗАЦИЯ ЗАПРОСОВ
Мы описывали оптимизацию запросов в каркасе запросов реляционного исчисления в централизованных системах баз данных. Хотя этот подход покрывает большую часть работы, выполненной в данной области, некоторые проблемы обработки запросов выходят за пределы каркаса, поскольку сложность запросов превышает пределы реляционной полноты, или из-за структуры используемой физической базы данных. Не обещая полноты, в следующих разделах мы приведем краткий обзор некоторых важных разработое. За дальнейшими деталями рекомендуется обращаться к указанной литературе.6.1 Запросы более высокого уровня
Запросы, выражаемые на реляционно полном языке, выбирают из базы данных элементы отношения (или множества элементов), которые могут быть описаны предикатом реляционного исчисления. Хотя это метод достаточен для большинства бизнес-приложений, ориентированных на транзакции, для некоторых других приложений могут требоваться более сложные объекты данных и более мощные предикаты запросов. Эти требования могут характеризоваться как расширения языков, которые приводят к языкам, более мощным, чем реляционно полные языки. В этом разделе мы обращаемся к методам оптимизации для таких расширений.В системах иерархических и сетевых баз данных поддерживаются объекты данных, которые являются более сложными, чем плоские записи, и поэтому в них содержатся пути доступа, несущие информацию (information-bearing) [Astrahan and Ghosh 1974]. Поэтому для реляционных интерфейсов к таким системам требуется эффективная трансляция реляционных запросов в навигационные программы доступа. (Также изучается и обратная проблема - преобразование программ из сетевого кода к реляционным запросам [Katz and Wong 1982].) Описано несколько подходов: интерпретационный, трансляционный и обрабатывающий представления.
Интерпретационные модели (например, [Zaniolo 1979]) прямо интерпретируют реляционные запросы как последовательность покортежных операций в серевой базе данных. Аналогично, прямые трансляционные методы (например, [Vassiliou and Lochovsky 1980]) часто не обращаются к оптимизации; такие методы могут приводить к весьма неэффективному коду. Даял со своими сотрудниками [Dayal et al. 1981; Dayal and Goodman 1982] и Грей [Gray 1981, 1984] разработали стратегии оптимизации запросов для сетевых баз данных. В качестве альтернативы, можно представлять сетевые структуры как реляционные представления с особыми ограничениями целостности [Rosenthal and Reiner 1984]. Таким образом, для компиляции эффективных навигационных программ, работающих над сетевой базой данных, можно использовать существующие средства оптимизации представлений.
Приложения из областей CAD/CAM и обработки текстов обычно работают с даже более сложнымиобъектами, составленными их элементов разных отношений. С исользованием нескольких представления данных можно определить структуры поверх традиционной реляционной (или сетевой) базы данных, которые позволяют обращаться к объекту целиком или к его части [Johnston et al. 1983]. Другой подход заключается в расширении реляционной модели отношениями, не находящимися в первой нормальной форме [Lamersdorf 1984; Schek and Pistor 1982]. В таких расширениях доступ к подструктурам поддерживается специальными индексными схемами или использованием механизмов поиска по шаблону, аналогичных тем, которые используются в информационном поиске [Davis and Kunii 1982]. В [Dayal 1983b] исследуется родственная проблема ответа на запросы в обобщенной иерархии, в которой учитывается тот факт, что объекты данных наследуют свойства от более общих объектов.
Запросы реляционного исчисления выбирают наборы данных в том виде, как они поступают из базы данных, в них не поддерживаются генерация и абстрагирование от хранимых данных к более сложным объектам данных языка запросов. К области обработки статистических запросов относятся группировка и суммаризация элементов одного отношения по некоторым так называемым категорийным атрибутам. Для поддержки таких приложений в некоторых языках запросов предлагается ограниченный набор встроенных агрегатных функций. Агрегатные функции могут быть определены как расширения как реляционного исчисления [Klug 1982a], так и реляционной алгебры [Ozsoyoglu and Ozsoyoglu 1983] и могут вычисляться с использованием вложенной итерации с использованием индексов, описанной в разд. 4 [Klug 1982b]. Однако многие статистические базы данных характеризуются высокой избыточностью и большим числом неопределенных значений. Поэтому данные должны сжиматься и храниться способом, отличным от стандартных реляционных баз данных. Обзор этих вопросов можно найти в [Shoshani 1982]. Для обработки запросов в таких базах данных изобретаются специальное программное обеспечение [Eggers and Shoshani 1980] и аппаратура [Bancilhon et al. 1982; Hawthorn 1982]. В [Walker 1980] обсуждается использование небольших абстрактных баз данных в системах поддержки решений.
Для приложения баз данных искусственного интеллекта , в особенности экспертных систем [Nau1983] и пользовательских интерфейсов на естественных языках [Marburger and Nebel 1983; Sagalowicz 1977] требуются интерфейсы, выполняемые над "сырыми" данными, поступающими из базы данных [Buneman 1979; Chang 1979; Minker 1975, 1978]. Хотя части такого механизма вывода могут обеспечиваться традиционными механизмами представлений с некоторой дополнительной оптимизацией [Jarke et al. 1984; Ott 1977; Ott and Horlaender 1982; Paige 1982], более сложные запросы - например, использование рекурсии - должны обрабатываться другим образом.
Ряд возможных архитектур для сопряжения экспертных систем с СУБД представлен в [Jarke and Vassiliou 1984]. Обращение к экспертной системе обычно транслируется в последовательность связанных вызовов базы данных. В число методов оптимизации входит объединение нескольких покортежных вызовов базы данных в операции, ориентированные на множества [Kunifuji and Yokota 1982; Vassiliou et al. 1984], упрощение таких запросов на выборку [Grishman 1978; Jarke et al. 1984; Reiter 1978], переупорядочивание условий, которые требуется проверять [Warren 1981] и разделение промежуточных результатов [Grant and Minker 1981], что особенно полезно при выполнении рекурсивных вызовов базы данных [Chang 1978; Henschen and Naqvi 1984; Kellogg 1982; Minker and Nicolas 1983]. Средством, часто предлагаемым в этом контексте, является язык логического програмирования Prolog [Kowalski 1981]. В [Parsaye 1983] предлагаются расширения к Prolog, специально разработанные для управдения базами данных и знаний.
Языковые расширения, представленные в этом разделе, теоретически можно различать по их выразительной мощности и трудности вычислений. В [Chandra and Harel 1982a, 1982b] анализируется несколько классов языков запросов более высокого уровня, такие как (в порядке возрастания мощности языков и вычислительной сложности) запросы с использованием реляционного исчисления первого порядка, запросы с использованием дизъюнктов Хорна, запросы с фиксированной точкой, запросы второго порядка и общие вычисляемые запросы. Пользователь традиционного языка запрсов может достичь мощности этих языков высокого уровня путем использования конструкций универсального языка программирования в языке программирования баз данных [Schmidt 1984]. Недостаток этого решения, в дополнение к возрастающим усилиям по программированию, сосотоит в том, что ответственность за эффективную реализацию переходит от системы управления данными к пользователю.
6.2 Распределенные базы данных
В распределенной базе данных фрагменты одной логической базы данных (как ее видят пользователи) размещаются в нескольких физических базах данных, каждая из которых доступна из отдельного компьютера. Базы данных могут распределяться для повышения доступности данных (за счет репликации данных [Andler et al. 1982]), повышения удобства доступа для ниболее частых пользователей (путем локального сохранения данных [Wong 1983]) и увеличения скорости выполнения запросов (за счет параллельной обработки фрагментов) [Su and Mikkilineni 1982; Wong and Katz 1983]). В число примеров распределенных систем баз данных входят Distributed INGRES [Stonebraker and Neuhold 1977], POREL [Neuhold and Biller 1977], SIRIUS [Esculier and Clorieux 1979], VDN [Munz 1979], SDD-1 [Bernstein et al. 1981] и R* [Williams et al. 1982].Тот факт, что данные физически распределены и могут реплицироваться, сильно влияет на проектирование баз данных [Chen and Akoka 1980], управление параллельным доступом (concurrency control) [Bernstein and Goodman 1981c] и обработку запросов. В [Rothnie and Goodman 1977] приводится обзор основных исследовательских проблем.
Если данные являются распределенными, стоимость пересылки данных становится переменной, а не константой проблемы оптимизации запросов. Поскольку имеется тенденция к преобладанию стоимости коммуникаций над стоимостью локальной обработки, для оптимизации запросов требуется совершенно другая целевая функция - минимизация коммуникационных задержек, часто представляемая объемом данных, передаваемых из одного узла в другой.
Основное решение, влияющее на передачу данных, касается выбора узла(ов), в которых выполняются вычисления. Общая стратегия состоит в том, чтобы распределять выполнение запроса, а не собирать все данные, чтобы выполнять запрос в одном узле (например, в том, на который поступил запрос). Преимущества этого подхода выразительно продемонстрированы в [Tanenbaum 1981] b Gavish and Segev 1982]. Внутри этой общей стратегии наиболее важными тактическими целями являются максимальное сокращение объема данных, подлежащих передаче для локальной обработки [Forker 1982] и выбор сайта(ов), в которых выполняются глобальные операции (см., например, [Bernstein et al. 1981 и Ceri and Pelagatti 1982]). Если данные реплицируются, имеется возможность выбора копии, использование которой минимизирует пересылку данных [Ullman 1982; Williams et al. 1982].
Разработано большое число стратегий распределенной обработки запросов. На выбор между такими стратегиями влияют несколько факторов.
6.2.1 Соотношение между стоимостями коммникаций и локальной обработки
Если коммуникационные каналы является относительно медленными, стоимость коммуникаций обычно преобладает над стоимость распределенной обработки к такой степени, что прочие расходы становятся принебрежимо малыми. В некоторых более теоретических моделях (например, [Apers et al. 1983, Hevner 1979 и Muthuswamy and Kerschberg [1983]) расходы на локальную обработку полностью игнорируются. На практике [Bernstein et al. 1981; Smith et al. 1981] будет использоваться двухуровневая процедура оптимизации, которая сначала планирует глобальную стратегию, а затем разрабатывет оптимальный план выполнения подзапросов для каждого локального узла.При возрастании скорости коммуникаций стоимость локальной обработки должна приниматься во внимание [Chu and Hurley 1982; Gouda and Dayal 1981]: теперь произвольный объем локальной препроцессорной обработки не может быть оправдан сокращением объема передачи данных между узлами. В [Kerschberg et al. 1982] описывается эксперимент с сетью из двух компьютеров, показывающий относительную важность локальной обработки. Конечно, одновременная минимизация объемов передачи данных и локальной обработки значительно увеличивает число альтернатив, подлежащих сравнению, поскольку проблему больше нельзя декомпозировать в иерархию независимых подпроблем.
6.2.2 Структура сети
На сложность обработки запросов оказывает влияние топология компьютерной сети, в которой реализуется распределенная база данных. В сети с произвольной маршрутизацией сообщений играют важную роль задержки организации очередей (queuing delay) в промежуточных узлах [Muthuswamy and Kerschberg 1983; Tanenbaum 1981]. Однако их можно рассматривать только в контексте оптимизации всего сетевого трафика. Чтобы избежать этого усложенения, во многих алгоритмах оптимизации (например, [Hevner and Yao 1979]) предполагается полностью связная сеть с независящими от узлов коммуникационными задежками. Другой простой структурой является звезднообразная компьютерная сеть [Kerschberg et al. 1982], в которой основной центральный процессор связывается с несколькими (обычно менее крупыми) локальными процессорами.Структура сети может быть однородной (т.е. состоять из процессоров одного типа) или разнородной. Для однородной сети (одинаковая скорость процессоров, независящая от процессоров линейная стоимость коммуникаций) в [Chu and Hurley 1982] доказан ряд теорем, применение которых ограничивает пространство поиска оптимального решения. Например, показано, что при этих предположениях глобально оптимальна локальная предобработка одноместных операций (ограничение, проекция). Даже внутри однородной компьютерной сети может существовать неоднородная распределенная база данных, если локальные базы данных основываются на разных моделях данных или СУБД [Chan et al. 1983; Smith et al. 1981].
6.2.3 Стратегия распределения данных
Отношение может быть физически разделено горизонтально (множество кортежей разделяется на подмножества в соответствии с паттерном локальных обращений), вертикально (множество атрибутов разделяется в соответсвии с особенностями различных приложений в разных местах) или на произвольные фрагменты с наличием перекрытия между ними или без перекрытия [Mahmoud et al. 1979].В [Gavish and Segev 1983] описывается алгоритм оптимизации набора операций в горизонтально разделенной реляционной базе данных. Доказана вычислительная трудность проблемы и разработаны эвртистики для ее решения. В [Ullman 1982] описывается использование "сторожевых условий" ("guard conditions") для упрощения запросов в горизонтально разделенных базах данных путем определения значимых фрагментов. Работа с неразъединенными фрагментами только что началась [Maier and Ullman 1983].
Основное внимание в существующей литературе уделяется вертикально распределенным базам данным. В этом случае ограничение и проецирование могут выполняться локально; исследования концентрируются на оптимальной реализации и планирования соединений и других операций над несколькими отношениями. Основным средством, используемым в этом контексте, является операция полусоединения, описанная в разд. 4.3. Как обсуждалось, древовидные запросы можно полностью решить с использованием полусоединений. Для частного случая цепочных запросов существует эффективный алгоритм, вычисляющий оптимальное расписание полусоединений при известном коэффициенте сокращения каждого полусоединения [Chiu et al. 1981]. Аналогичные алгоритмы для общих древовидных запросов приводятся в [Chiu and Ho 1980 и Gouda and Dayal 1981]. Однако по причине вычислительной сложности точных методов обычно предпочитают использовать эвристические процедуры Bernstein et al. 1981; Chang 1982; Cheung 1982a; Yu and Chang 1983].
В некоторых ранних алгоритмах полусоединения не использовались. В [Wong 1977] использовалась процедура поиска экстремума для инкрементального совершенствования начального решения, обрабатывающего весь запрос в одном узле. В [Epstein et al. 1978] представлена модель для раздельной минимизации времени обработки или сетевого трафика для каждой операции в запросе. Не гарантируется глобальная оптимальность. Оптимизационный алгоритм в R* (распределенный вариант System R [Williams et al. 1982]) производит исчерпывающий поиск комбинаций из нескольких альтернативных стратегий соединения для запросов с несколькими соединениями. В пределах просранства поиска и ограничений оценок данных находится оптимальное решение [Daniels 1982; Daniels et al. 1982; Ng 1982; Selinger and Adiba 1970].
Как и в централизованном случае, многие алгоритмы распределенного выполнения запросов подвергаются критике либо за предположение о практичности использования слишком больших объемов статистической информации, либо за использование нереалистичных упрощений. В [Muthuswamy and Kerschberg 1983] описывается процедура получения детальной статистики база данных путем наблюдения за использованием базы данных. Вычислительная сложность проблемы оптимизации распределенных запросов приводит к тем же явлениям, которые мы наблюдали для централизованных запросов. Одна группа ислледователей занимается поиском оптимальных решений в частных случаях, в то время как другая использует общие эвристики, чтобы иметь возможность отвечать на все запросы. При наличии планов реализации распределенной СУБД проблема состоит в объединении обоих подходов однородным образом. В [Yu and Chang 1983] приводится хороший пример такой исчерпывающей стратегии, которая включает эффективную работу с фрагментами, репликацию данных и динамические планы доступа (при этом избегаются упомянутые выше ошибки статистических оценок).
6.3 Машины баз данных
Использование машин баз данных мотивируется, прежде всего, целью освобождения основного компьютера общего назначения от бремени обработки баз данных, чтобы могла быть повышена общая производительность системы. Перемещения функциональность СУБД с основного компьютера на вспомогательную машину баз данных можно достичь применением программного или аппаратного подхода.В подходе software backend (обзор см., например, в [Maryanski 1980]) база данных вместе с программным обесечением СУБД перемещается на автономный компьютер общего назначения. Программный backend полностью обрабатывает каждый запрос к базе данных, позволяя основному компьютеру в параллель выполнять задачи, не связанные с базами данных. Другой привлекательной чертой этого подхода является разумная цена традиционного компьютера. Однако для приложений с очень интенсивным использованием базы данных этот подход кажется непригодным. В этих ситуациях сам вспомогательный компьютер становится узким местом системы, поскольку обладает теми же ограничениями, что и основной компьютер общего назначения. Общая производительность может быть даже хуже, чем в конфигурации с одним главным компьютером по причине требуемых дополнительных межпроцессорных коммуникаций.
В таком случае может быть выбран подход hardware backend (обзор см., например, в [Hsiao 1979 и Langdon 1979). С точки зрения оптимизации запросов аппаратный backend может быть использован для поддержки важных стратегий оптимизации, таких как ранее вычисление ограничительных операций и параллельная обработка, путем размещения аппаратной логики как можно ближе к базовым данным и разделения работы между существующими аппаратными компонентами.
Вообще говоря, аппаратный backend состоит из набора взаимодействующих сециализированных процессоров. Существует большое разнообразие архитектурных альтернатив, от ассоциирования идентичных процессоров с непересекающимися фрагментами базы данных до назначения конкретным процессорам разных функций СУБД; эти назначения могут делаться статически или динамически.
Так назывемая "клеточная логика" ("cellular logic") [Su 1979] характеризуется фрагментацией базы данных (например, размещаемой на диске) на клетки равного размера (например, дорожки диска), с каждой из которых ассоциируется специализированный процессор. Обычно у этих процессоров имеется одинаковый репертуар операций, и они подключаются к управляющему процессору, контроллирующему параллельные операции всех подчиненных процессоров. Привлекают широкое внимание различные прототипы клеточной логики, такие как CASSM [Su and Lipkovsky 1975], RAP [Ozkarahan 1982] и RARES [Lin et al. 1976].
В некоторых проектах машин баз данных также производятся эксперименты с ассоциативными матрицами [Berra and Oliver 1979]. Однако из-за своей относительно высокой стоимости и ограниченной емкости они не представляют ралистичного решения для постоянного хранения баз данных целиком. Поэтому обычно предлагается использовать ассоциативные матрицы как промежуточные устройства для относительно недорогих устройств массовой памяти.
В ряде архитектур машин баз данных применяется специализация процессоров для конкретных функций СУБД. Разработаны особые стоимостные модели [Bernadat 1983] и алгоритмы оптимизации [Valduriez and Gardarin 1984]. В DBC [Banerjee and Hsiao 1979] контроль доступа, поддержка справочников и обработка запросов выполняется разными компьютерами. В DIRECT [DeWitt 1979] поддерживается динамическое назначение процессоров для задач обработки процессов, таких как выполнение индивидуальных подзапросов, также как и в поисковом процессоре Technical University of Braunschweig [Leilich et al. 1978]. В последние годы технологии LSI и VLSI используются для тесной интеграции хранения данных и возможностей обработки запросов, а также аппаратной реализации языковых конструкций, обычно доступных в языках запросов высокого уровня [Kim et al. 1981; Menon and Hsiao 1981].
7. ЗАКЛЮЧЕНИЕ
В статье был приведен обзор методов логических преобразований и физического выполнения запросов к базам данных с использованием каркаса реляционного исчисления. Было показано, что для решения проблемы эффективной обработки запросов в традиционных централизованных и распределенных системах баз данных накоплен большой объем знаний.Исследования оптимизации запросов продолжаются оставаться активной областью. Обещающие направления включают разработку простых, но реалистичных оценок стоимости, оптимизацию запросов с дедуктивными или вычислительными возможностями и одновременную оптимизацию нескольких запросов и обновляющих транзакций. Другие интересные области, кратко затронутые в обзоре, включают оптимизацию запросов в системах баз данных, использующих более развитые пути доступа., такие как мультиатрибутные индексы или машины баз данных, и оптимизацию запросов в системах, работающих со сложными структурами данных, требуемыми для искусственного интеллекта, офисной деятельности, статистики, поддержки решений и CAD/CAM.
БЛАГОДАРНОСТИ
Работа Маттиаса Ярке частично поддерживалась совместным исследованием с IBM. Работа Юргена Коха частично поддерживалась Deutsche Forschungsgemeinschaft по гранту SCHM450/2-1 (руководитель проекта: J. W. Schmidt). Авторы признательны Иоахиму Шмидту и Арни Розенталю за многочисленные обсуждения и предложения, а также рецензентам и редакторам за полезные замечания к презентации материала.
ЛИТЕРАТУРА
- AHO, A. V., BEERI, C., AND ULLMAN, J. D. 1979a. The theory of joins in relational databases. ACM Trans. Database Syst. 4, 3 (Sept.), 297-314.
- AHO, A. V., SAGIV, Y., AND ULLMAN, J. D. 1979b. Efficient optimization of a class of relational expressions. ACM Trans. Database Syst. 4, 4 (Dec.), 435-454.
- AHO, A. V., SAGIV, Y., AND ULLMAN, J. D. 1979c. Equivalences among relational expressions. SIAM J. Comput. 8, 2, 218-246.
- ANDLER, S., DING, I., ESWARAN, K., HAUSER, C., KIM, W., MEHL, J., AND WILLIAMS, R. 1982. System D: A distributed system for availability. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 33-44.
- APERS, P. M. G., HEVNER, A. R., AND YAO, S. B. 1983. Optimization algorithms for distributed queries. IEEE Trans. So#w. Eng. SE-9, 1, 57-68.
- ASTRAHAN, M. M., AND CHAMBERLIN, D. S. 1975. Implementation of a structured English query language. Commun. ACM 18, 10 (Oct.), 580-588.
- ASTRAHAN, M. M., AND GHOSH, S. P. 1974. A search path selection algorithm for the Data Independent Accessing Model (DIAM). In Proceedings of the ACM-SIGMOD Workshop on Data Description, Access and Control (Ann Arbor, Mich., May 1-3). ACM, New York, pp. 367-388.
- ASTRAHAN, M. M., SCHKOLNICK, M., AND KIM, W. 1980. Performance of the System R access path selection algorithm. In Information Processing 80. Elsevier North-Holland, New York, pp. 487-491.
- BANCILHON, F., RICHARD, P., AND SCHOLL, M. 1982. On line processing of compacted relations. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 263-269.
- BANERJEE, J., AND HSIAO, D. K. 1979. DBC-A database computer for very large databases. IEEE Trans. Comput. C-28, 6, 414-429.
- BATORY, D. S. 1982. Index selection. In Principles of Database Design, S. B. Yao, Ed. Springer, New York.
- BAYER, R., AND MCCREIGHT, E. 1972. Organization and maintenance of large ordered indexes. Acta Inf. 1, 173-189.
- BAYER, R., ELHARDT, K., KIESSLING, W., AND KILLAR, D. 1984. Verteilte Datenbanksysteme. Inf. Spektrum 7, 1, 1-19.
- BENTLEY, J. L., AND FRIEDMAN, J. H. 1979. Data structures for range searching. ACM Comput. Surv. 11, 4 (Dec.), 397-409.
- BERNADAT, P. 1983. Decomposition et evaluation de questions dans une machine base de donnees relationnelles. These IIIme cycle, Department d'Informatique, Universite de Paris VI, Paris, France.
- BERNSTEIN, P. A., AND CHIU, D. M. W. 1981. Using semi-joins to solve relational queries. J. ACM 28, 1 (Jan.), 25-40.
- BERNSTEIN, P. A., AND GOODMAN, N. 1981a. The power of natural semijoins. SIAMJ. Comput. 10, 4, 751-771.
- BERNSTEIN, P. A., AND GOODMAN, N. 1981b. The power of inequality semijoins. Inf. Syst. 6, 4, 255-265.
- BERNSTEIN, P. A., AND GOODMAN, N. 1981c. Concurrency control in distributed database systems. ACM Comput. Surv. 13, 2 (June), 185-221.
- BERNSTEIN, P. A., BLAUSTEIN, B. T., AND CLARKE, E. M. 1980. Fast maintenance of semantic integrity assertions using redundant aggregate data. In Proceedings of the 6th International Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 126-136.
- BERNSTEIN, P. A., GOODMAN, N., WONG, E., REEVE, C. L., AND ROTHNIE, J. B., JR. 1981. Query processing in a system for distributed databases (SDD-1). A C M Trans. Database S yst. 6, 4 (Dec.), 602-625.
- BERRA, B., AND OLIVER, E. 1979. The role of associative array processors in database machine architectures. IEEE Comput. 12, 3, 53-61.
- BITTON, D., BORAL, H., DEWITT, D., AND WILKINSON, W. K. 1983. Parallel algorithms for the execution of relational database operations. ACM Trans. Database Syst. 8, 3 (Sept.), 324-353.
- BLASGEN, M. W., AND ESWARAN, K. P. 1976. On the evaluation of queries in a relational data base system. IBM Res. Rep. RJ 1745, IBM Research Laboratories, San Jose, Calif.
- BLASGEN, M. W., AND ESWARAN, K. P. 1977. Storage and access in relational databases. IBM Syst. J. 16, 363-377.
- BOLOUR, A. 1981. Optimal retrieval for small range queries. SIAM J. Comput. 10, 4, 721-741.
- BREITBART, Y., AND REITER, A. 1975. Algorithms for fast evaluation of Boolean expressions. Acta Inf. 4, 107-116.
- BRODIE, M., MYLOPOULOS, J., AND SCHMIDT, J. W., Eds. 1984. On Conceptual Modelling. Perspectives from Artificial Intelligence, Databases, and Programming Languages. Springer, New York.
- BUNEMAN, P. 1979. The problem of multiple paths in a database schema. In Proceedings of the 5th International Conference on Very Large Data Bases (Rio de Janeiro, Oct. 3-5). IEEE, New York, pp. 368-372.
- CARDENAS, A. F. 1975. Analysis and performance of inverted data base structures. Commun. ACM 18, 5 (May), 253-263.
- CARLIS, J. V., MARCH, S. T., AND DICKSON, G. W. 1981. Physical database design: A DSS approach. In Proceedings of the 2nd International Conference on Information Systems (Boston, Mass.). ACM, New York, pp. 153-172.
- CARLSON, C. R., AND KAPLAN, R. S. 1976. A generalized access path model and its application to a relational data base system. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Washington, D.C., June 2-4). ACM, New York, pp. 143-154.
- CERI, S., AND PELAGATTI, G. 1982. Allocation of operations in distributed database access. IEEE Trans. Comput. C-31, 2, 119-128.
- CHAMBERLIN, D. D., ASTRAHAN, M. M., KING, W. F., LORIE, R. A., MEHL, J. W., PRICE, T. G., SCHKOLNICK, M., SELINGER, P. G., SLUTZ, D. R., WADE, B. W., AND YOST, R. A. 1981. Support for repetitive transactions and ad hoc queries in System R. ACM Trans. Database Syst. 6, 1 (Mar.), 70-94.
- CHAN, A., AND NIAMIR, B. 1982. On estimating cost of accessing records in blocked database organizations. Comput. J. 25, 3, 368-374.
- CHAN, A., DAYAL, U., FOX, S., GOODMAN, N., RIES, D. D., AND SKEEN, D. 1983. Overview of an Ada compatible distributed database manager. In SIGMOD 83, Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 228-237.
- CHANDRA, A. K., AND HAREL, D. 1982a. Structure and complexity of relational queries. J. Comput. Syst. Sci. 25, 99-128.
- CHANDRA, A. K., AND HAREL, D. 1982b. Horn clauses and the fixpoint query hierarchy. In Proceedings of the ACM Symposium on Principles of Database Systems (Los Angeles, Calif., Mar. 29-31). ACM, New York, pp. 158-163.
- CHANDRA, A. K., AND MERLIN, P. M. 1977. Optimal implementation of conjunctive queries in relational data bases. In Proceedings of the 9th Annual ACM Symposium on Theory of Computation (Boulder, Colo., May 24). ACM, New York, pp. 77-90.
- CHANG, C. L. 1978. DEDUCE 2: Further investigations of deduction in relational databases. In Logic and Databases, H. Gallaire and J. Minker, Eds. Plenum, New York, pp. 210-236.
- CHANG, C. L. 1979. On evaluation of queries containing derived relations in a relational data base. IBM Res. Rep. RJ2667, IBM Research Laboratories, San Jose, Calif.
- CHANG, J.-M. 1982. A heuristic approach to distributed query processing. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 54-61.
- CHEN, P. P. S., AND AKOKA, J. 1980. Optimal design of distributed information systems. IEEE Trans. Comput. C-29, 12, 1068-1080.
- CHESNAIS, A., GELENBE, E., AND MITRANI, I. 1983. On the modeling of parallel access to shared data. Commun. ACM 26, 3 (Mar.), 196-202.
- CHEUNG, T.-Y. 1982a. A method for equijoin queries in distributed relational databases. IEEE Trans. Comput. C-31, 8, 746-751.
- C,EUNO, T.-Y. 1982b. Estimating block accesses and number of records in file management. Commun. ACM 25, 7 (July), 484-487.
- CHIU, D. M., AND HO, Y. C. 1980. A methodology for interpreting tree queries into optimal semijoin expressions. In Proceedings of the ACM SIGMOD International Conference on Management of Data (Santa Monica, Calif., May 14-16). ACM, New York, pp. 169-178.
- CHIU, D. M., BERNSTEIN, P. A., AND HO, Y. C. 1981. Optimizing chain queries in a distributed database system. Tech. Rep. TR-01-81, Computer Science Dept., Harvard University, Cambridge, Mass.
- CHRISTODOULAKIS, S. 1981. Estimating selectivities in data bases. Tech. Rep. CSRG-136, Computer Science Dept., University of Toronto, Toronto, Canada.
- CHRISTODOULAKIS, S. 1983. Estimating block transfers and join sizes. In SIGMOD 83, Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York. pp. 40-54.
- CHU, W. W., AND HURLEY, P. 1982. Optimal query processing for distributed database systems. IEEE Trans. Comput. C-31, 9, 835-850.
- CLAUSEN, S. E. 1980. Optimizing the evaluation of calculus expressions in a relational database system. Inf. Syst. 5, 1, 41-54.
- CODD, E. F. 1971. A database sublanguage founded on the relational calculus. In Proceedings of the ACM-SIGFIDET Workshop, Data Description, Access, and Control (San Diego, Calif., Nov. 11-12). ACM, New York, pp. 35-68.
- CODD, E. F. 1972. Relational completeness of data base sublanguages. In Courant Computer Science Symposia No. 6: Data Base Systems. Prentice-Hall, New York, pp. 67-101.
- DANIELS, D. 1982. Query compilation in a distributed database system. IBM Res. Rep. RJ3423, IBM Research Laboratories, San Jose, Calif.
- DANIELS, D., SELINGER, S., HAAS, L., LINDSAY, B., MOHAN, C., WALKER, A., AND WILMS, P. 1982. An introduction to distributed query compilation in R*. In Proceedings of the 2nd Symposium on Distributed Databases (Berlin, FRG). Elsevier North-Holland, New York.
- DAVIS, H. W., AND WINSLOW, L. E. 1982. Computational power in query languages. SIAM J. Comput. 11, 3, 547-554.
- DAVIS, L. S., AND KUN[1, T. L. 1982. Pattern databases. In Data Base Design Techniques II, S. B. Yao and T. L. Kunii, Eds. Springer, New York, pp. 357-399.
- DAYAL, U. 1983a. Evaluating queries with quantitiers: A horticultural approach. In Proceedings of the ACM Symposium on Principles of Database Systems {Atlanta, Ga.). ACM, New York, pp. 125-136.
- DAYAL, U. 1983b. Processing queries over generalization hierarchies in a multi-database system. In Proceedings of the 9th International Conference on Very Large Data Bases (Florence, Italy). VLDB Endowment, Saratoga, Calif., pp. 342-353.
- DAYAL, U., AND GOODMAN, N. 1982. Query optimization for CODASYL database systems. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 138-150.
- DAYAL, U., GOODMAN, N., LANDERS, T. A., OLSON, K., SMITH, J. M., AND YEDWAB, L. 1981. Local query optimization in Multibase--A system for heterogeneous distributed databases. Tech. Rep. 145 CCA-81-11, Computer Corporation of America, Cambridge, Mass.
- DEMOLOMBE, R. 1980. Estimation of the number of tuples satisfying a query expressed in predicate calculus language. In Proceedings of the 6th Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 55-63.
- DEWITT, D. J. 1979. Query execution in DIRECT. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Boston, Mass., May 30-June 1). ACM, New York, pp. 13-22.
- DOWNEY, P. J., SETHI, R., AND TARJAN, R. E. 1980. Variations on the common subexpression problem. J. ACM 27, 4 (Oct.), 758-771.
- EGGERS, S. J., AND SHOSHANI, A. 1980. Efficient access of compressed data. In Proceedings of the 6th International Conference on Very Large Data Bases {Montreal, Oct. 1-3). IEEE, New York, pp. 205-211.
- EPSTEIN, R., AND STONEBRAKER, M. 1980. Analysis of distributed data base processing strategies. In Proceedings of the 6th International Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 92-101.
- EPSTEIN, a., STONEBRAKER, M., AND WONG, E. 1978. Distributed query processing in a relational data base system. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Austin, Tex., May 31-June 2). ACM, New York, pp. 169-180.
- ESCULIER, C., AND CLORIEUX, A. M. 1979. The SIRIUS-DELTA distributed DBMS. In Proceedings of the International Conference on Entity-Relationship Approach, P. Chen, Ed. Elsevier North-Holland, New York, pp.. 543-551.
- ESWARAN, K. P., GRAY, J. N., LORIE, R. A., AND TRAIOER, I. L. 1976. The notions of consistency and predicate locks in a database system. Commun. ACM 19, 11 (Nov.), 624-633.
- FINKELSTEIN, S. 1982. Common expression analysis in database applications. In Proceedings of the ACM-SIGMOD International Conference on Management of Data {Orlando, Fla., June 2-4). ACM, New York, pp. 235-245.
- FORKER, H. J. 1982. Algebraical and operational methods for the optimization of query processing in distributed relational database management systems. In Proceedings of the 2nd International Symposium on Distributed Databases (Berlin, FRG). Elsevier North-Holland, New York, pp. 39-59.
- GARDARIN, G., VALDURIEZ, P., AND VIEMONT, Y. 1984. Predicate trees: An approach to optimize relational query operations. In Proceedings of the IEEE COMPDEC Conference (Los Angeles, Calif.). IEEE, New York.
- GAVISH, B., AND SEGEV, A. 1982. Query optimization in distributed computer systems. In Management of Distributed Data Processing, J. Akoka, Ed. Elsevier North-Holland, New York, pp. 233-252.
- GAVlSH, B., AND SEGEV, A. 1983. Set query optimization in horizontally partitioned distributed databases. Working Paper QM8304, Graduate School of Management, University of Rochester, Rochester, N.Y.
- GELENBE, E., AND GARDY, D. 1982. The size of projections of relations satisfying a functional dependency. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 325-333.
- GILLES, J. H., AND SCHUSTER, S. A. 1975. Query execution and index selection for relational data bases. Tech. Rep. CSRG-53, Computer Science Dept., University of Toronto, Toronto, Ontario.
- GOODMAN, N., AND SHMUELI, O. 1980. Nonreducible database states for cyclic queries. Tech. Rep. TR-15-80, Computer Science Dept., Harvard University, Cambridge, Mass.
- GOODMAN, N., AND SHMUELI, O. 1982. Tree queries: A simple class of relational queries. ACM Trans. Database Syst. 7, 4 (Dec.), 653-677.
- GOTLIEB, L. R. 1975. Computing joins of relations. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (San Jose, Calif., May 14-16). ACM, New York, pp. 55-63.
- GOUDA, M. G., AND DAYAL, U. 1981. Optimal semijoin schedules for query processing in local distributed database systems. In Proceedings of the ACM-SIGMOD International Conference on Management o/Data (Ann Arbor, Mich., Apr. 29-May 1). ACM, New York, pp. 164-175.
- GRANT, J., AND MINKER, J. 1981. Optimization in deductive and conventional relational database systems. In Advances in Database Theory, H. Gallaire, J. Minker, and J.-M. Nicolas, Eds. Plenum, New York, pp. 195-234.
- GRAY, P. M. D. 1981. Use of automatic programming and simulation to facilitate operations on CODASYL databases. In Database, M. P. Atkinson, Ed. Pergamon Infotech, London, pp. 315-369.
- GRAY, P. M. D. 1984. Implementing the join operation on CODASYL DBMS. In Databases: Role and Structure, P. M. Stocker, Ed. Cambridge University Press, Cambridge, England.
- GRIES, D. 1971. Compiler Construction for Digital Computers. Wiley, New York.
- GRIFFETH, N. D. 1978. Nonprocedural query processing for databases with access paths. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Austin, Tex., May 31-June 2). ACM, New York, pp. 160-168.
- GRIFFITHS, P. G., AND WADE, B. W. 1976. An authorization mechanism for a relational database system. ACM Trans. Database Syst. 1, 3 (Sept.), 242-255.
- GRISHMAN, R. 1978. The simplification of retrieval requests generated by question-answering systems. In Proceedings of the 4th International Conference on Very Large Data Bases (West Berlin, FRG, Sept. 13-15). IEEE, New York, pp. 400-406.
- GUDES, E., AND REITER, A. 1973. On evaluating Boolean expressions. Softw. Pract. Exper. 3, 345-350.
- HALL, P. A. V. 1974. Common subexpression identification in general algebraic systems. Tech. Rep. UKSC 0060, IBM UK Scientific Center, Peterlee, England.
- HALL, P. A. V. 1976. Optimization of single expressions in a relational data base system. IBM J. Res. Devel. 20, 3, 244-257.
- HAMMER, M., AND NIAMIR, B. 1979. A heuristic approach to attribute partitioning. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Boston, Mass., May 30-June 1). ACM, New York, pp. 93-101.
- HAMMER, M., AND ZDONIK, S. B., JR. 1980. Knowledge-based query processing. In Proceedings of the 6th International Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 137-147.
- HANANI, M. Z. 1977. An optimal evaluation of Boolean expressions in an online query system. Commun. ACM 20, 5 (May), 344-347.
- HAWTHORN, P. 1982. Microprocessor assisted tuple access, decompression, and assembly for statistical database systems. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 223-233.
- HENSCHEN, L. J., AND NAQVI, S. A. 1984. On compiling queries in reeursive first-order databases. J. ACM 31, 1 (Jan.), 47-85.
- HEVNER, A. R. 1979. The optimization of query processing on distributed database systems. Ph.D. dissertation, Computer Science Dept., Purdue University, West Lafayette, Ind.
- HEVNER, A. R., AND YAO, S. B. 1979. Query processing on a distributed database. IEEE Trans. Softw. Eng. SE-5, 3, 177-187.
- HEVNER, A. R., AND YAO, S. B. 1981. Transaction optimization on a distributed database system. Tech. Rep. HR-81-257, Honeywell Corporate Computer Center, Bloomington, Minn.
- HSlAO, D. K. 1979. Database machines are coming, database machines are coming. IEEE Comput. 12, 3, 7-9.
- IBM CORPORATION 1966. Introduction to IBM direct-access storage devices and organization methods. Programming manual GC 20-1649-06,
- IEEE 1982. Special issue on query optimization. IEEE Database Eng. 5, 3 (Sept.).
- JARKE, M. 1984. Common subexpression isolation in multiple query optimization. In Query Processing in Database Systems, W. Kim, D. Reiner, and D. Batory, Eds. Springer, New York.
- JARKE, M., AND KOCH, J. 1983. Range nesting: A fast method to evaluate quantified queries. In SIGMOD 83, Proceedings of Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 196-206.
- JARKE, M., AND SCHMIDT, J. W. 1981. Evaluation of first-order relational expressions. Tech. Rep. 78, Fachbereich Informatik, Universitaet Hamburg, Hamburg, FRG.
- JARKE, M., AND SCHMIDT, J. W. 1982. Query processing strategies in the PASCAL/R relational database management system. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 256-264.
- JARKE, M., AND VASSILIOU, Y. 1984. Coupling expert systems with database management systems. In Artificial Intelligence Applications for Business, W. Reitman, Ed. Ablex, Norwood, N.J., pp. 65-85.
- JARKE, M., CLIFFORD, J., AND VASS1LIOU, Y. 1984. An optimizing Prolog front-end to a relational query system. In SIGMOD 84, Proceedings of Annual Meeting (Boston, Mass., June 18-21). ACM, New York, pp. 296-306.
- JOHNSON, D. S., AND KLUG, A. 1982. Testing containment of conjunctive queries under functional and inclusion dependencies. In Proceedings of the ACM Symposium on Principles of Database Systems (Los Angeles, Calif., Mar. 29-31). ACM, New York, pp. 164-169.
- JOHNSON, D. S., AND KLUG, A. 1983. Optimizing conjunctive queries that contain untyped variables. SIAM J. Comput. 12, 4, 616-640.
- JOHNSTON, H. R., SCHWEITZER, J. E., AND WARKENTINE, E. R. 1983. A DBMS facility for handling structured engineering entities. In Proceedings of the Database Week Engineering Design Applications Conference (San Jose, Calif.). ACM, New York, pp. 3-12.
- KAMBAYASH1, Y., AND YOSHIKAWA, M. 1983. Query processing utilizing dependencies and horizontal decomposition. In SIGMOD 83 Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 55-67.
- KAMBAYASHI, Y., YOSHIKAWA, M., AND YAJIMA, S. 1982. Query processing for distributed databases using generalized semi-joins. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 151-160.
- KATZ, R. H., AND WONG, E. 1982. Decompiling CODASYL DML into relational queries. ACM Trans. Database Syst. 7, 1 (Mar.), 1-23.
- KELLOGG, C. 1982. A practical amalgam of knowledge and data base technology. In Proceedings of the National Conference on Artificial Intelligence (Pittsburgh, Pa.). AAAI, Menlo Park, Calif.
- KERSCHBERG, L., TING, P. D., AND YAO, S. B. 1982. Query optimization in star computer networks. ACM Trans. Database Syst. 7, 4 (Dec.), 678-711.
- K1M, W. 1980. A new way to compute the product and join of relations. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Santa Monica, {Calif., May 14-16). ACM, New York, pp. 179-187.
- KIM, W. 1981. Query optimization for relational database systems. IBM Res. Rep. RJ3081, IBM Research Laboratories, San Jose, Calif.
- KIM, W. 1982. On optimizing an SQL-like nested query. ACM Trans. Database Syst. 7, 3 (Sept.), pp. 443-469.
- KIM, W. 1984. Global optimization of relational queries: A first step. In Query Processing in Database Systems, W. Kim, D. Reiner, and D. Batory, Eds. Springer, New York.
- KIM, W., KUCK, D. J., AND GARSKI, D. 1981. A bit-serial/tuple-parallel relational query processor. IBM Res. Rep. RJ3194, IBM Research Laboratories, San Jose, Calif.
- KING, J. J. 1979. Exploring the use of domain knowledge for query processing efficiency. Tech. Rep. STAN-CS-79-781, Computer Science Dept., Stanford University, Stanford, Calif.
- KING, J. J. 1981. QUIST: A system for semantic query optimization in relational databases. In Proceedings of the 7th International Conference on Very Large Data Bases (Cannes, Sept. 9-11). IEEE, New York, pp. 510-517.
- KLUG, A. 1980. Calculating constraints on relational expressions. ACM Trans. Database Syst. 5, 3 (Sept.), 260-290.
- KLUG, A. 1982a. Equivalence of relational algebra and relational calculus query languages having aggregate functions. J. ACM 29, 3 (July), 699-717.
- KLUG, A. 1982b. Access paths in the "ABE" statistical query facility. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 161-173.
- KLUG, A. 1983. Locking expressions for increased database concurrency. J. ACM 30, 1 (Jan.), 36-54.
- KOCH, J., SCHMIDT, J. W., AND WUNDERLICH, V. 1981. Type derivation for first-order relational expressions. Tech. Rep. no. 79, Fachbereich Informatik, Universit~it Hamburg, Hamburg, FRG.
- KOWALSKI, R. 1981. Logic as a database language. Unpublished manuscript, Computer Science Dept., Imperial College, London.
- KUNIFUJI, S., AND YOKOTA, H. 1982. Prolog and relational databases for Fifth Generation Computer Systems. In Proceedings of the Workshop on Logical Bases for Data Bases (Toulouse, France). ONERA-CERT, Toulouse, France.
- LAMERSDORF, W. 1984. Recursive data models for non-conventional database applications. In Proceedings of the IEEE COMPDEC Conference (Los Angeles, Calif.). IEEE, New York.
- LANG, T., WOOD, C., AND FERNANDEZ, I. B. 1977. Database buffer paging in virtual storage systems. ACM Trans. Database Syst. 2, 4 (Dec.), 339-351.
- LANGDON, G. G. 1979. Database machines: an introduction. IEEE Trans. Comput. C-28, 6, 381-383.
- LEILICH, H.-O., STIEGE, G., AND ZEIDLER, H. C. 1978. A search processor for data base management systems. In Proceedings of the 4th International Conference on Very Large Data Bases (West Berlin, FRG, Sept. 13-15). IEEE, New York, pp. 280-287.
- LIN, C. S., SMITH, V. C. P., AND SMITH, J. M. 1976. The design of a rotating associative memory for relational database applications. ACM Trans. Database Syst. 1, 1 (Mar.), 53-65.
- LIU, J. W. S. 1976. Algorithms for parsing search queries in systems with inverted file organizations. ACM Trans. Database Syst. 1, 4 (Dec.), 299-316.
- LUK, W. S. 1983. On estimating block accesses in database organizations. Commun. ACM 26, 11 (Nov.), 945-947.
- MAEKAWA, M. 1982. Parallel join and sorting algorithms. In Data Base Design Techniques II, S. B. Yao and T. L. Kunii, Eds. Springer, New York, pp. 266-296.
- MAHMOUD, S. A., RIORDON, J. S., AND TOTH, K. C. 1979. Database partitioning and query processing. In Proceedings of the IFIP Working Conference on Database Architecture. Elsevier NorthHolland, New York, pp. 3-21.
- MAIER, D. 1983. The Theory of Relational Databases. Computer Science Press, Rockville, Md.
- MAIER, D., AND ULLMAN, J. D. 1983. Fragments of relations. In SIGMOD 83, Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 15-22.
- MAIER, D., AND WARREN, D. S. 1981. Incorporating computed relations in relational databases. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Ann Arbor, Mich., Apr. 29-May 1). ACM, New York, pp. 176-187.
- MAKINOUCHI, A., TEZUKA, M., KITAKAMI, H., AND ADACHI, S. 1981. The optimization strategy for query evaluation in RDB/V1. In Proceedings of the 7th International Conference on Very Large Data Bases (Cannes, Sept. 9-11). IEEE, New York, pp. 518-529.
- MALL, M., REIMER, M., AND SCHMIDT, J. W. 1984. Data selection, sharing and access control in a relational scenario. In On Conceptual Modeling. Perspectives from Artificial Intelligence, Databases, and Programming Languages, M. Brodie, J. Mylopoulos, and J. W. Schmidt, Eds. Springer, New York, pp. 411-436.
- MARBURGER, H., AND NEBEL, B. 1983. Natuerlichsprachlicher Datenbankzugang mit HAMANS: Syntaktische Korespondenz, natuerlichsprachliche Quantifizierung und semantisches Modell des Diskursbereichs. In Sprachen fuer Datenbanken, J. W. Schmidt, Ed. Springer-Verlag, Berlin, pp. 26-41.
- MARCH, S. T. 1983. A mathematical programming approach to the selection of access paths for large multiuser data bases. Decision Sci. 14, 4, 564-587.
- MARYANSKI, F. J. 1980. Backend database systems. ACM Comput. Surv. 12, 1 (Mar.), 3-25.
- MENON, M. J., AND HSIAO, D. K. 1981. Design and analysis of a relational join operation for VLSI. In Proceedings of the 7th International Conference on Very Large Data Bases (Cannes, Sept. 9-11). IEEE, New York, pp. 44-55.
- MERRETT, T. H. 1977. Database cost analysis: A top-down approach. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Toronto, Canada, Aug. 3-5). ACM, New York, pp. 135-143.
- MERRETT, T. H. 1981. Why sort-merge gives the best implementation of the natural join. SIGMOD Rec. 13, 2, 39-51.
- MERRETT, T. H., KAMBAYASHI, Y., AND YASUURA, H. 1981. Scheduling of page-fetches in join operations. In Proceedings of the 7th International Conference on Very Large Data Bases (Cannes, Sept. 9-11). IEEE, New York, pp. 488-498.
- MINKER, J. 1975. Performing inferences over relation data bases. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (San Jose, Calif., May 14-16). ACM, New York, pp. 79-91.
- MINKER, J. 1978. Search str~ttegy and selection function for an inferential relational system. ACM Trans. Database Syst. 3, 1 (Mar.), 1-31.
- MINKER, J., AND NICOLAS, J.-M. 1983. On recursive axioms in deductive databases. Inf. Syst. 8, 1, 1-13.
- MISSIKOFF, M., AND SCHOLL, M. 1983. Relational queries in domain based DBMS. In SIGMOD 83, Proceedings o/Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 219-227.
- MONTGOMERY, A. I., D'SoUzA, D. J., AND LEE, S. B. 1983. The cost of relational algebraic operations in skewed data: Estimates and experiments. In Information Processing 83. Elsevier North-Holland, New York, pp. 235-241.
- MUNZ, R. R. 1979. Gross architecture of the distributed database system. VDN. In Proceedings of the IFIP Working Conference on Database Architecture. Elsevier North-Holland, New York, pp. 23-34.
- MUNZ, R. R., SCHNEIDER, H.-J., AND STEYER, F. 1979. Application of sub-predicate tests in database systems. In Proceedings of the 5th International Conference on Very Large Data Bases (Rio de Janeiro, Oct. 3-5). IEEE, New York, pp. 426-435.
- MUTHUSWAMY, B., AND KERSCHEERG, L. 1983. Distributed query optimization using detailed database statistics. Unpublished manuscript, Computer Science Dept., University of South Carolina.
- NAU, D. 1983. Expert computer systems. IEEE Comput. 16, 2 (Feb.), 63-85.
- NEUHOLD, E. J., AND BILLER, H. 1977. POREL: A distributed data base on an inhomogeneous computer network. In Proceedings of the 3rcl International Conference on Very Large Data Bases (Tokyo, Oct. 6-8). IEEE, New York, pp. 380-395.
- NG, P. 1982. Distributed compilation and recompilation of distributed queries. IBM Res. Rep. RJ3375, IBM Research Laboratories, San Jose, Calif.
- NIEBUHR, K. E., AND SMITH, S. E. 1976. N-aryjoins for processing Query by Example. IBM Tech. Disclosure Bull. 19, 6, 2377-2381.
- NIEBUHR, K. E., SCHOLZ, K. W., AND SMITH, S. E. 1976. Algorithm for processing Query by Example. IBM Tech. Disclosure Bull. 19, 2, 736-741.
- NIEVERGELT, J., H1NTERBERGER, H., AND SEVCIK, K. C. 1984. The grid file: An adaptable, symmetric multikey file structure. ACM Trans. Database Syst. 9, 1 (Mar.), 38-71.
- NILSSON, N. 1982. Principles of Artificial InteUigence. Springer, New York.
- OTT, N. 1977. Interpretation of questions with quantifiers and negation in the USL system. IBM Tech. Rep. TR-77.10.005, IBM Scientific Center, Heidelberg, FRG.
- OTT, N., AND HORLAENDER, K. 1982. Removing redundant join operations in queries involving views. IBM Tech. Rep. TR-82.03.003, IBM Scientific Center, Heidelberg, FRG.
- OZKARAHAN, E. A. 1982. Database machine/computer based distributed databases. In Proceedings of the 2nd International Symposium on Distributed Databases (Berlin, FRG). Elsevier North-Holland, New York, pp. 61-80.
- OZSOYOGLU, M. Z., AND OZSOYOGLU, G. 1983. An extension of relational algebra for summary tables. In Proceedings of the 2nd Statistical Database Workshop (Berkeley, Calif.). University of California, Berkeley.
- OZSOYOGLU, M., AND YU, C. T. 1980. On identifying a class of database queries that can be processed efficiently. In Proceedings of the IEEE COMPSAC Conference. IEEE, New York, pp. 453-461.
- PAIGE, R. 1982. Applications of finite differencing to database integrity control and query/transaction optimization. In Proceedings of the Workshop on Logical Bases for Data Bases (Toulouse, France). ONERA-CERT, Toulouse, France.
- PALERMO, F. P. 1972. A data base search problem. In Proceedings of the 4th Symposium on Computer and Information Science (Miami Beach, Fla.). AFIPS Press, Reston, Va., pp. 67-101.
- PARSAYE, K. 1983. Database management, knowledge base management, and expert system development in PROLOG. In Proceedings of the Database Week Conference on Engineering Applications of Databases (San Jose, Calif.). ACM, New York, pp. 159-178.
- PECHERER, R. M. 1975. Efficient evaluation of expressions in a relational algebra. In Proceedings of the ACM Pacific 75 Conference (San Francisco, Calif., May 14-16). ACM, New York, pp. 44-49.
- PECHERER, R. M. 1976. Efficient exploration of product spaces. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Washington, D.C., June 2-4). ACM, New York, pp. 169-177.
- PIROTTE, A. 1979. Findamental and secondary issues in the design of non-procedural relational languages. In Proceedings of the 5th International Conference on Very Large Data Bases (Rio de Janeiro, Oct. 3-5). IEEE, New York, pp. 239-250.
- PUTKONEN, A. 1979. On the selection of the access path in inverted database organizations. Inf. Syst. 4, 4, 219-225.
- REIMER, M. 1983. Solving the phantom problem by predicative optimistic concurrency control. In Proceedings of the 9th International Conference on Very Large Data Bases (Florence, Italy). VLDB Endowment, Saratoga, Calif., pp. 81-88.
- RELIER, R. 1978. Deductive question-answering on relational data bases. In Logic and Databases, H. Gallaire and J. Minker, Eds: Plenum, New York, pp. 149-178.
- RICHARD, P. 1981. Evaluation of the size of a query expressed in relational algebra. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Ann Arbor, Mich., Apr. 29-May 1). ACM, New York, pp. 155-163.
- ROSENKRANTZ, D. J., AND HUNT, H. B. III. 1980. Processing conjunctive predicates and queries. In Proceedings of the 6th International Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 64-72.
- ROSENTHAL, A., AND REINER, D. 1982. An architecture for query optimization. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 246-255.
- ROSENTHAL, A., AND REINER, D. 1984. Querying relational views of networks. In Query Processing in Database Systems, W. Kim, D. Reiner, and D. Batory, Eds. Springer, New York.
- ROTHNIE, J. B. 1974. An approach to implementing a relational data management system. In Proceedings of the ACM-SIGMOD Workshop on Data Description, Access, and Control (Ann Arbor, Mich., May 1-3). ACM, New York, pp. 277-294.
- ROTHNIE, J. B., JR. 1975. Evaluating inter-entry retrieval expressions in a relational data base management system. In Proceedings of the National Computer Conference (Anaheim, Calif., May 19-22), vol. 44. AFIPS Press, Reston, Va., pp. 417-423.
- ROTHNIE, J. B., AND GOODMAN, N. 1977. A survey of research and development in distributed database management. In Proceedings of the 3rd International Conference on Very Large Data Bases (Tokyo, Oct. 6-8). IEEE, New York, pp. 48-62.
- ROUSSOPOULOS, N. 1982a. View indexing in relational databases. ACM Trans. Database Syst. 7, 2 (June), 258-290.
- ROUSSOPOULOS, N. 1982b. The logical access path schema of a database. IEEE Trans. Softw. Eng. SE-8, 6, 563-573.
- SACCO, G. M., AND SCHKOLNICK, M. 1982. A mechanism for managing the buffer pool in a relational database system using the hot set model. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 257-262.
- SACCO, G. M., AND YAO, S. B. 1982. Query optimization in distributed database systems. In Advances in Computers, vol. 21. Academic Press, New York, pp. 225-273.
- SAGALOWlCZ, D. 1977. IDA: An intelligent data access program. In Proceedings of the 3rd International Conference on Very Large Data Bases (Tokyo, Oct. 6-8). IEEE, New York, pp. 293-302.
- SAGIV, Y. 1981. Optimization of Queries in Relational Databases. UMI Research Press, Ann Arbor, Michigan.
- SAG,V, Y. 1983. Quadratic algorithms for minimizing joins in restricted relational expressions. SIAM J. Comput. 12, 2, 316-328.
- SAGIV, Y., AND YANNAKAKIS, M. 1980. Equivalences among relational expressions with the union and difference operators. J. ACM 27, 4 (Oct.) 633-655.
- SALTON, G., AND WONG, A. 1978. Generation and search of clustered files. ACM Trans. Database Syst. 3, 4 (Dec.) 321-346.
- SCHEK, H.-J., AND PISTOR, P. 1982. Data structures for an integrated database management and information retrieval system. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 197-207.
- SCHENK, K. L., AND PINKERT, J. R. 1977. An algorithm for servicing multi-relational queries. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Toronto, Canada, Aug. 3-5}. ACM, New York, pp. 10-20.
- SCHKOLNICK, M. 1975. The optimal selection of indexes for files. Inf. Syst. 1, 4, 141-146.
- SCHKOLNICK, M. 1982. Physical database design techniques. In Data Base Design Techniques II, S. B. Yao and T. L. Kunii, Eds. Springer, New York, pp. 229-252.
- SCHMIDT, J. W. 1977. Some high level language constructs for data of type relation. ACM Trans. Database Syst. 2, 3 (Sept.), 247-261.
- SCHMIDT, J. W. 1979. Parallel processing of relations: A single-assignment approach. In Proceedings of the 5th International Conference on Very Large Data Bases (Rio de Janeiro, Oct. 3-5). IEEE, New York, pp. 398-408.
- SCHMIDT, J. W. 1984. Database programming: Language constructs and execution models. In Programmiersprachen und Programmentwicklung, U. Ammann, Ed. Springer-Verlag, Berlin, pp. 1-26.
- SELINGER, P. G., AND ADIBA, M. 1980. Access path selection in distributed database systems. IBM Res. Rep. RJ2283, IBM Research Laboratories, San Jose, Calif.
- SELINGER, P. G., ASTRAHAN, M. M., CHAMBERLIN, D. D., LORIE, R. A., AND PRICE, T. G. 1979. Access path selection in a relational database management system. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Boston, Mass., May 30-June 1). ACM, New York, pp. 23-34.
- SEVERANCE, D. G., AND CARLIS, J. V. 1977. A practical approach to selecting record access paths. ACM Comput. Surv. 9, 4 (Dec.) 259-272.
- SHMUELI, O. 1981. The fundamental role of tree schemas in relational query processing. Ph.D. thesis, Computer Science Dept., Harvard Univ., Cambridge, Mass.
- SHNEIDERMAN, B. 1977. Reduced combined indexes for efficient multiple attribute retrieval. Inf. Syst. 2, 4, 149-154.
- SHNEIDERMAN, B., AND GOODMAN, V. 1976. Batched searching of sequential and tree structured files. ACM Trans. Database Syst. I, 3 (Sept.), 268-275.
- SHOSHANI, A, 1982. Statistical database: Characteristics, problems, and some solutions. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 208-222.
- SHULTZ, R. g., AND ZINGG, R. J. 1984. Response time analysis of multiprocessor computers for database support. ACM Trans. Database Syst. 9, 1 (Mar.), 100-132.
- SMITH, J. M., AND CHANG, P. Y. W. 1975. Optimizing the performance of a relational algebra database interface. Commun. ACM 18, 10 (Oct.), 568-579.
- SMITH, J. M., BERNSTEIN, P. A., DAYAL, U., GOODMAN, N., LANDERS, T., LIN, K. W. T., AND WONG, E. 1981. MULTIBASE-Integrating heterogeneous distributed database systems. In Proceedings of the AFIPS National Computer Conference (Chicago, May 4-7), vol. 50. AFIPS Press, Reston, Va., pp. 487-499.
- SOCKUT, G. H., AND GOLDBERG, R. P. 1979. Database reorganization--Principles and practice. ACM Comput. Surv. 11, 4 (Dec.) 371-395.
- STONEBRAKER, M. 1975. Implementation of integrity constraints and views by query modification. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (San Jose, Calif., May 14-16). ACM, New York, pp. 65-78.
- STONEBRAKER, M., AND NEUHOLD, E. 1977. A distributed database version of INGRES. In Proceedings of the 2nd Berkeley Workshop on Distributed Data Management and Computer Networks (Berkeley, Calif.). University of California, Berkeley.
- STONEBRAKER, M., WONG, E., KREPS, P., AND HELD, G. 1976. The design and implementation of INGRES. ACM Trans. Database Syst. I, 3 (Sept.), 189-222.
- STROET, J. W. M., AND ENGMANN, R. 1979. Manipulation of expressions in a relational algebra. Inf. Syst. 4, 4, 195-203.
- SU, S. Y. W. 1979. Cellular-logic devices: Concepts and applications. IEEE Comput. 12, 3, 11-25.
- SU, S. Y. W., AND LIFKOVSKI, G. 1975. CASSM: A cellular system for very large databases. In Proceedings of the 1st International Conference on Very Large Data Bases (Framingham, Mass., Sept. 22-24}. ACM, New York, pp. 456-472.
- Su, S. Y. W., AND MIKKILINENI, K. P. 1982. Parallel algorithms and their implementation in MICRO-NET. In Proceedings of the 8th International Conference on Very Large Data Bases (Mexico City). VLDB Endowment, Saratoga, Calif., pp. 310-324.
- TANENBAUM, A. 1981. Computer Networks. Prentice-Hall, New York.
- TEOREY, T. J., AND FRY, J. P. 1982. Design of Database Structures. Prentice-Hall, New York.
- TODD, S. 1974. Implementing the join operator in relational data bases. IBM Scientific Center Tech. Note 15, IBM UK Scientific Center, Peterlee, England.
- TSICHRITZlS, D. 1976. LSL: A link and selector language. In Proceedings of the ACM-SIGMOD Internatiorml Conference on Management of Data (Washington, D.C., June 2-4). ACM, New York, pp. 123-133.
- ULLMAN, J. D. 1982. Principles of Database Systems. Computer Science Press, Rockville, Md.
- VALDURIEZ, P. 1982. Semi-join algorithms for multiprocessor systems. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Orlando, Fla., June 2-4). ACM, New York, pp. 225-233.
- VALDURIEZ, P., AND GARDARIN, G. 1984. Join and semijoin algorithms for a multiprocessor database machine. ACM Trans. Database Syst. 9, 1 (Mar.), 133-161.
- VAN DE RIET, R. P., WASSERMAN, A. I., KERSTEN, M. L., AND DE JONGE, W. 1981. High-level programming features for improving the efficiency of a relational database system. ACM Trans. Database Syst. 6, 3 (Sept.), 464-485.
- VASSILIOU, Y., AND JARKE, M. 1984. Query languages--A taxonomy. In Human Factors and Interactive Computer Systems, Y. Vassiliou, Ed. Ablex, Norwood, N.J.
- VASSIL|OU, Y., AND LOCHOVSKY, F. 1980. DBMS transaction translation. In Proceedings of the IEEE COMPSAC Conference. IEEE, New York, pp. 89-96.
- VASSILIOU, Y., CLIFFORD, J., AND JARKE, M. 1984. Access to specific declarative knowledge in expert systems: The impact of logic programming. Decision Support Syst. 1, 1.
- VERHOFSTAD, J. S. M. 1978. Recovery techniques for database systems. ACM Comput. Surv. 10, 2 (June), 167-195.
- WALKER, A. 1980. On retrieval from a small version of a large data base. In Proceedings of the 6th International Conference on Very Large Data Bases (Montreal, Oct. 1-3). IEEE, New York, pp. 47-54.
- WARREN, D. H. D. 1981. Efficient processing of interactive relational database queries expressed in logic. In Proceedings of the 7th International Conference on Very Large Data Bases (Cannes, Sept. 9-11). IEEE, New York, pp. 272-281.
- WELCH, J. W., AND GRAHAM, J. W. 1976. Retrieval using ordered lists in inverted and multilist files. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Washington, D.C., June 2-4). ACM, New York, pp. 21-29.
- WHANG, K.-Y., WIEDERHOLD, G., AND SAGALOWICZ, D. 1983. Estimating block accesses in database organizations: A closed noniterative formula. Commun. ACM 26, 11 (Nov.), 940-944.
- WILLIAMS, R., DANIELS, D., HAAS, L., LAPIS, G., LINDSAY, B., NG, P., OBERMARCK, R., SELINGER, P., WALKER, A., WILMS, P., AND YOST, R. 1982. R*: An overview of the architecture. In Proceedings of the International Conference on Database Systems (Jerusalem, Israel).
- WONG, E. 1977. Retrieving dispersed data from SDD-i: A system for distributed databases. In Proceedings of the Second Berkeley Workshop on Distributed Data Management and Computer Networks (Berkeley, Calif.), pp. 217-235.
- WONG, E. 1983. Dynamic rematerialization: Processing distributed queries using redundant data. IEEE Trans. Sofw. Eng. SE-9, 3, 228-232.
- WONG, E., AND KATZ, R. H. 1983. Distributing a database for parallelism. In SIGMOD 83, Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 23-29.
- WONG, E., AND YOUSSEFI, K. 1976. Decomposition--A strategy for query processing. ACM Trans. Database Syst. 1, 3 (Sept.), 223-241.
- Xu, G. D. 1983. Search control in semantic query optimization. Tech. Rep. #83-09, Computer and Information Science Dept., University of Massachusetts, Amherst, Mass.
- YANG, C.-S. 1977. Avoiding redundant accesses in unsorted multilist file organizations. Inf. Syst. 2, 4, 155-158.
- YAO, S. B. 1977a. Approximating block accesses in database organizations. Commun. ACM 20, 4 (Apr.), 260-261.
- YAO, S. B. 1977b. An attribute based model for database access cost analysis. ACM Trans. Database Syst. 2, 1 (Mar.), 45-67.
- YAO, S. B. 1979. Optimization of query evaluation algorithms. ACM Trans. Database Syst. 4, 2 (June), 133-155.
- YAO, S. B., AND DEJONG, D. 1978. Evaluation of database access paths. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Austin, Tex., May 31-June 2). ACM, New York, pp. 66-77.
- YOUSSEFI, K., AND WONG, E. 1979. Query processing in a relational database management system. In Proceedings of the 5th International Conference on Very Large Data Bases (Rio de Janeiro, Oct. 3-5). IEEE, New York, pp. 409-417.
- YU, C. T., AND CHANG, C. C. 1983. On the design of a query processing strategy in a distributed database environment. In SIGMOD 83, Proceedings of the Annual Meeting (San Jose, Calif., May 23-26). ACM, New York, pp. 30-39.
- Yu, C. T., AND OZSOYOGLU, M. 1979. An algorithm for tree query membership of a distributed query. In Proceedings of the IEEE COMPSAC Conference. IEEE, New York, pp. 306-312.
- Yu, C. T., LUK, W. S., AND SIU, M. K. 1978. On the estimation of the number of desired records with respect to a given query. ACM Trans. Database Syst. 3, 1 (Mar.), 41-56.
- ZANIOLO, C. 1979. Design of relational views over network schemas. In Proceedings of the ACM-SIGMOD International Conference on Management of Data (Boston, Mass., May 30-June 1). ACM, New York, pp. 179-190.
| Назад |