OLTP в Зазеркалье
Ставрос Харизопулос, Дэниэль Абади, Сэмюэль Мэдден, Майкл Стоунбрейкер
Пересказ: Сергей Кузнецов
1. Введение
Современные системы баз данных общего назначения, ориентированные на OLTP, обладают стандартным набором характерных черт: коллекцией структур данных на диске для хранения таблиц, включающей неупорядоченные файлы и B-деревья; поддержкой параллельного выполнения нескольких запросов и операций обновления базы данных на основе блокировок; восстановлением на основе журнала и наличием эффективного менеджера буферов основной памяти. Эти средства были разработаны для поддержки обработки транзакций в 1970-е и 1980-е гг., когда объем баз данных OLTP во много раз превосходил размеры доступной основной памяти, и компьютеры, поддерживающие эти базы данных, стоили сотни тысяч, если не миллионы долларов.
Сегодня имеется совсем другая ситуация. Во-первых, современные процессоры являются очень быстрыми, так что время вычислений для многих транзакций категории OLTP измеряется микросекундами. За несколько тысяч долларов можно купить систему с гигабайтами основной памяти. Кроме того, организации нередко владеют сетевыми кластерами, включающими много рабочих станций, общий объем памяти которых измеряется сотнями гигабайт, и этого хватает для хранения в основной памяти многих баз данных OLTP.
Во-вторых, развитие Internet и появление разнообразных приложений, для которых требуется обработка больших объемов данных, приводит к повышению интереса к системам, похожим на системы баз данных, но не поддерживающим полный набор возможностей стандартной системы баз данных. Конференции по тематике операционных систем и сетей заполнены докладами с предложениями архитектур систем хранения данных, «похожих на системы баз данных», в которых поддерживаются различные формы целостности, надежности, параллелизма, репликации и поддержки запросов [DG04, CDG+06, GBH+00, SMK+01].
Эта возрастающая потребность в службах, подобных службам баз данных, в сочетании с существенным повышением производительности и снижением стоимости аппаратуры наводит на мысль о ряде интересных альтернативных систем, которые можно построить таким образом, чтобы они обладали не тем набором характерных черт, которые имеются у стандартных серверов баз данных OLTP.
1.1 Альтернативные архитектуры СУБД
Очевидно, что оптимизация систем баз данных категории OLTP на основе использования основной памяти является хорошей идеей, если соответствующие базы данных помещаются в основную память. Но возможен и ряд других вариантов организации систем баз данных, например:
- Системы баз данных без журнализации. Такие системы баз данных либо могут не нуждаться в восстановлении баз данных, либо могут производить восстановление на основе данных, хранимых в других узлах кластера (как это предлагалось в системах Harp [LGG+91], Harbor [LM06] и C-Store [SAB+05]).
- Однопотоковые системы баз данных. Хотя режим многопотоковой обработки традиционно являлся важным в системах баз данных OLTP для скрытия времени ожидания, возникающего из-за медленного выполнения записи на диск, он гораздо менее важен для систем, которые размещают базы данных целиком в основной памяти. Однопотоковая реализация в некоторых случаях может оказаться вполне достаточной, особенно, если она обеспечивает хорошую производительность. Конечно, требуется какой-либо способ получения преимуществ от наличия в одном процессоре нескольких ядер, но современные достижения в технологии виртуальных машин обеспечивают возможность придать этим ядрам вид отдельных процессорных узлов без слишком больших накладных расходов [BDR97], что делает однопотоковые реализации вполне пригодными.
- Системы баз данных без поддержки транзакций. Во многих системах поддержка транзакций не требуется. В частности, в распределенных Internet-приложениях транзакционной согласованности часто предпочитается конечная согласованность [Bre00, DHJ+07]. В других случаях могут быть приемлемыми легковесные формы транзакций, например, такие, в которых все чтения должны быть произведены до первой записи [AMS+07, SMA+07].
На самом деле, в сообществе баз данных имеется несколько предложений по построению систем баз данных со всеми этими характеристиками или некоторыми из них [WSA97, SMA+07]. Однако открытым остается вопрос, как будут работать эти разные конфигурации, если их действительно построить? Это и есть центральный вопрос данной статьи.
1.2 Измерение накладных расходов OLTP
Для поиска ответа на этот вопрос авторы воспользовались современной системой баз данных с открытыми исходными кодами (Shore) и провели ее испытание на подмножестве тестового набора TPC-C. Исходная реализация, выполняемая на современной настольной машине, показывала результат примерно в 640 транзакций в секунду (transactions per second, TPS). Затем эта реализация модифицировалась путем удаления из системы различных возможностей по одной за раз, и всякий раз полученный вариант системы испытывался на том же подмножестве TPC-C. Это делалось до тех пор, пока от системы не осталось крошечное ядро, содержащее код обработки запросов, на котором удалось достичь скорости в 12700 TPS. Это ядро является однопотоковой системой баз данных в основной памяти, не поддерживающей блокировки и восстановление. В ходе этой декомпозиции авторам удалось выделить четыре основных компонента, удаление которых привело к существенному повышению пропускной способности системы:
Журнализация. Сборка журнальных записей и отслеживание всех изменений в структурах базы данных уменьшает производительность. От журнализации можно отказаться, если не требуется восстанавливаемость баз данных, или если восстанавливаемость обеспечивается другими средствами (например, на основе других узлов сети).
Блокировки. Традиционная двухфазная схема блокировок требует существенных накладных расходов, поскольку весь доступ к структурам базы данных управляется отдельной сущностью – менеджером блокировок.
Защелки (latching). В многопотоковых системах баз данных для многих структур данных должны срабатывать кратковременные блокировки (защелки, latch) до того, как к ним станет возможен доступ. Устранение этой потребности и переход к однопотоковому подходу значительно влияет на производительность.
Управление буферами. В системе баз данных с хранением данных в основной памяти не требуется доступ к дисковым страницам через буферный пул, в результате чего устраняется уровень косвенности при доступе к любой записи.
1.3 Результаты
На рис. 1 показано, как эти модификации влияют на итоговую производительность Shore (измеряемую числом выполненных команд центрального процессора на транзакцию New Order из TPC-C). Как можно видеть, каждая из этих подсистем занимает от 10 до 35% общего объема работы системы (1.73 миллиона команд, соответствующих общей высоте рисунка).
«Оптимизации, произведенные вручную» здесь представляют набор оптимизаций, которые были внесены в код авторами и направлены, прежде всего, на улучшение эффективности пакета для работы с B-деревьями. Реальные команды, обрабатывающие данный запрос и называемые на рисунке «полезной работой», – это команды минимальной реализации, выполненной авторами поверх вручную закодированного пакета поддержки B-деревьев в основной памяти. Число команд минимальной реализации при выполнении запроса составляет около одной шестидесятой от общего числа выполненных команд исходной системы. Белый прямоугольник под «buffer manager» представляет версию Shore после того, как из системы было удалено все, что было возможно, – в ней все еще выполняются транзакции, но используется около 1/15-ой от числа команд исходной системы, или в четыре раза больше числа команд полезной работы. Дополнительный выигрыш, обеспечиваемый минимальной реализацией, объясняется глубиной стека вызовов в Shore и тем фактом, что авторы не смогли полностью избавиться в Shore от всего наследия транзакций и менеджера буферов.
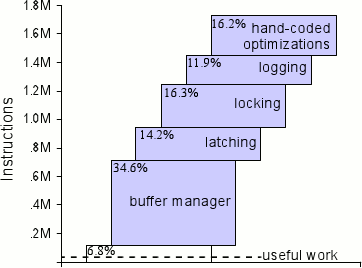
Рис. 1. Анализ выполнения команд в разных подсистемах СУБД для транзакции New Order из TPC-C. Верхняя часть столбиковой диаграммы соответствует производительности исходной системы Shore при поддержке всей базы данных в основной памяти и отсутствии конкуренции между потоками. Нижняя пунктирная линия – это полезная работа, измеренная путем выполнения той же транзакции на ядре без накладных расходов
1.4 Вклад авторов и организация статьи
Основными достижениями этой статьи являются:
- анализ того, на что уходит время при работе современной системы баз данных;
- тщательное измерение производительности различных облегченных вариантов такой системы;
- использование этих измерений для обсуждения производительности разных систем управления базами данных – например, систем без поддержки транзакций или журналов, – которые можно было бы построить.
Оставшаяся часть статьи организована следующим образом. В разд. 2 обсуждаются средства поддержки OLTP, которые скоро могут стать (или уже становятся) неупотребительными. В разд. 3 приводится обзор СУБД Shore как стартовой точки исследования авторов и описывается производившаяся ими декомпозиция. В разд. 4 описываются эксперименты авторов над Shore. Затем в разд. 5 полученные результаты используются для обсуждения их последствий для будущих СУБД и рассуждений по поводу производительности некоторой гипотетической системы управления базами данных. В разд. 6 рассматриваются дополнительные родственные исследования, и разд. 7 содержит заключение.