Сравнение подходов к крупномасштабному анализу данных
Эндрю Павло, Эрик Паулсон, Александр Разин, Дэниэль Абади, Дэвид Девитт, Сэмюэль Мэдден, Майкл Стоунбрейкер
Пересказ: Сергей Кузнецов
Оригинал: Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel J. Abadi, David J. DeWitt, Samuel Madden, Michael Stonebraker. A Comparison of Approaches to Large-Scale Data Analysis. Proceedings of the 35th SIGMOD International Conference on Management of Data, 2009, Providence, Rhode Island, USA
4. Тесты для оценки производительности
В этом разделе описывается тестовый набор, состоящий из пяти задач, используемых для сравнения производительности модели MR и параллельных СУБД. Первая задача была взята прямо из исходной статьи про MapReduce [8], авторы которой объявляют ее типичной для MR. Поскольку эта задача довольно проста, были разработаны четыре дополнительных задачи, которые образуют более сложную аналитическую нагрузку, позволяющую исследовать архитектурные различия, обсуждавшиеся в предыдущем разделе. Тестовый набор выполнялся на широко известной реализации MR и на двух параллельных СУБД.
4.1. Тестовая среда
При описании деталей тестовой среды отмечаются различия в операционных характеристиках тестируемых систем анализа данных, и обсуждаются способы, использованные для обеспечения единообразия экспериментов.
4.1.1. Тестируемые системы
Hadoop: Cистема Hadoop является наиболее популярной реализацией с открытыми кодами среды MapReduce, разрабатываемой Yahoo! и Apache Software Foundation [1]. В отличие от реализации Google исходной среды MR, где использовался язык C++, ядро системы Hadoop целиком написано на языке Java. В экспериментах, описываемых в этой статье, использовалась система Hadoop версии 0.19.0, исполняемая в среде Java 1.6.0. Была установлена система с конфигурацией по умолчанию, за исключением следующих изменений, которые было решено внести для улучшения производительности, не отклоняясь от основных принципов ядра MR:
- данные хранились в блоках размеров в 256 мегабайт вместо 64 мегабайт, используемых по умолчанию;
- каждый исполнитель задач JVM запускался с максимальным размером кучи в 512 мегабайт, и DataNode/JobTracker виртуальной машины запускался с максимальным размеров кучи в 1024 мегабайт (при общем объеме основной памяти в 3,5 гигабайт на узел);
- в Hadoop была разрешена опция «rack awareness» (возможность учета физического размещения узлов при планировании задач) для обеспечения локальности данных в кластере;
- в Hadoop было разрешено повторно использовать исполнитель задач JVM, а не запускать новый процесс для каждой задачи Map/Reduce.
Кроме того, система была сконфигурирована таким образом, чтобы на каждом узле запускались два экземпляра Map и один экземпляр Reduce.
В среде Hadoop также обеспечивается некоторая реализация распределенной файловой системы Google [12]. При каждом прогоне тестов все входные и выходные файлы сохранялись в распределенной файловой системе Hadoop (Hadoop distributed file system, HDFS). Использовались параметры HDFS по умолчанию с тремя репликами каждого блока и без сжатия. Тестировались и другие конфигурации (без репликации, со сжатием на уровнях блока и записи), но было обнаружено, что в этих условиях тесты выполняются с той же или худшей скоростью (см. п. 5.1.3). После завершения прогона тестов для заданного уровня масштабирования узлов каталоги данных на каждом узле удалялись, и HDFS форматировалась заново, чтобы следующий набор вводных данных реплицировался по уздам равномерно.
Для координации активности в узлах кластера в Hadoop используются центральный трекер заданий и «главный» (master) демон HDFS. Чтобы эти демоны гарантированно не влияли на производительность узлов-обработчиков, оба эти дополнительных компонента среды выполнялись в отдельном узле кластера.
СУБД-X: Использовался последний выпуск СУБД-X – параллельной SQL-ориентированной СУБД одного из ведущих поставщиков таких систем, в которой данные хранятся в «построчном» формате. Эта система инсталлировалась в каждом узле и конфигурировалась таким образом, что для буферного пула и других временных областей использовались сегменты разделяемой памяти общим объемом в 4 гигабайта. Каждая таблица хэш-разделяется по всем узлам в соответствии со значениями своего наиболее существенного атрибута, а затем сортируется и индексируется по разным атрибутам (см. пп. 4.2.1 и 4.3.1). Как и в экспериментах с Hadoop, перед каждым следующим прогоном в СУБД-X удалялись все таблицы, и данные загружались заново, чтобы кортежи были гарантированно равномерно распределены по узлам кластера.
По умолчанию СУБД-X не сжимает данные в своей внутренней системе хранения, но обеспечивается возможность сжатия таблиц с использованием широко известной схемы, основанной на словарях. Было установлено, что при включении опции сжатия время выполнения почти всех тестов сокращается на 50%, и поэтому ниже приводятся только те результаты, которые были получены при использовании сжатия данных. Только в одном случае оказалось, что при использовании сжатия производительность системы ухудшается. Кроме того, в СУБД-X не использовались средства репликации, поскольку это не улучшило бы производительность системы и усложнило бы процесс инсталляции.
Vertica: Vertica – это параллельная СУБД, разработанная для управления крупными хранилищами данных [3]. Основным отличием Vertica от других СУБД (включая СУБД-X) является то, что эта система хранит все данные по столбцам, а не по строкам [20]. В системе используется уникальный обработчик запросов, специально разработанный для применения в среде поколоночного хранения данных. В отличие от СУБД-X, в Vertica данные сжимаются по умолчанию, поскольку исполнитель запросов может работать прямо со сжатыми данными. Поскольку при реальном применении Vertica не принято запрещать возможность сжатия данных, при получении результатов, представленных в этой статье, использовались только сжатые данные. Кроме того, в Vertica все таблицы сортируются по значениям одного или нескольких атрибутов на основе кластеризованного индекса.
Было обнаружено, что в проводившихся экспериментах вполне был достаточен буфер с размером по умолчанию в 256 мегабайт в расчете на один узел. Менеджер ресурсов Vertica отвечает за определение объема памяти, выделяемой для выполнения каждого запроса, но в данном случае система была оповещена о том, что запросы следует выполнять по одному. Поэтому на каждом узле для выполнения каждого запроса использовался максимально доступный объем памяти.
4.1.2. Конфигурация узлов
Все три системы развертывались на кластере со 100 узлами. В каждом узле имелся один процессор Intel Core 2 Duo, работавший на частоте 2,40 Ггц, с 4 гигабайтами основной памяти и двумя 250-гигабайтными дисками SATA-I. Все узлы работали под управлением ОС Red Hat Enterprise Linux 5 (версия ядра 2.6.18). По данным hdparm дисковая подсистема обеспечивала пропускную способность в 7 Гбайт/сек для кэшированного чтения (cached read) и около 74 Мбайт/сек для буферизованного чтения (buffered read). Для соединения узлов использовались коммутаторы Cisco Catalyst 3750E-48TD. В таком коммутаторе имелись порты гигабайтного Ethernet для каждого узла и внешняя коммутирующая матрица (switching fabric) с пропускной способностью в 128 Гбайт/сек [6]. На каждый коммутатор приходилось 50 узлов. Коммутаторы связывались с использованием технологии Cisco StackWise Plus, что создавало между коммутаторами кольцо с пропускной способностью в 64 Гбайт/сек. Трафик между узлами, подключенными к одному и тому же коммутатору, был полностью локальным для этого коммутатора и не влиял на трафик в кольце.
4.1.3. Выполнение тестов
Для каждой задачи тестового набора ниже описываются шаги, предпринимавшиеся для реализации соответствующей MR-программы, а также эквивалентные операторы SQL, выполнявшиеся в системах баз данных. Каждая задача выполнялась три раза, и учитывались средние результаты этих прогонов. В каждой системе задачи тестового набора выполнялись по отдельности, чтобы обеспечить их монопольный доступ к ресурсам кластера. Для измерения базовой производительности без влияния накладных расходов на координацию параллельных задач сначала каждая задача выполнялась в одном узле. Затем эта задача выполнялась на кластерах разного размера, чтобы показать, как масштабируется каждая из систем при возрастании объема обрабатываемых данных и доступных ресурсов. В статье приводятся только результаты прогонов, в которых использовались все узлы, и программное обеспечение систем функционировало корректно при исполнении тестов.
Также измерялось время, требуемое каждой системой на загрузку тестовых данных. Результаты этих измерений расщепляются на время реальной загрузки данных и на время выполнения любых дополнительных операций, выполнявшихся после загрузки данных, например, сжатие данных или построение индексов. Исходные вводные данные на каждом узле хранились на одном из двух локальных дисков.
Во всех случаях, кроме специально оговариваемых, окончательные результаты запросов, выполнявшихся на Vertica или СУБД-X, направлялись командой shell по программному каналу (pipe) в файл на диске, который не использовался СУБД. Хотя можно выполнить эквивалентную операцию и в Hadoop, проще (и более распространено) сохранять результаты MR-программы в распределенной файловой системе. Однако эта процедура не аналогична тому, как производят свои выводные данные СУБД. Вместо того чтобы сохранять результаты в выводном файле, MR-программа производит один выводной файл для каждого узла Reduce и сохраняет все эти файлы в одном каталоге. Стандартная практика разработчиков состоит в использовании этих выводных каталогов как единиц ввода для других MR-заданий. Однако если некоторый пользователь пожелает использовать эти выводные каталоги в не MR-приложениях, им приходится сначала объединить результаты в одном файле и загрузить его в локальную файловую систему.
Из-за этого различия для каждой тестовой MR-задачи выполнялась дополнительная функция Reduce, которая просто объединяла окончательный вывод в одном файле HDFS. В приводимых результатах отдельно приводится время, затраченное Hadoop на выполнение реальной задачи тестового набора, и время выполнения дополнительной операции объединения выводных данных. Эти результаты демонстрируются в виде составных прямоугольников: в нижней части показано время выполнения конкретной тестовой задачи, а в верхней – время выполнения функции Reduce, объединяющей в один файл все выводные данные программы.
4.2. Исходная MR-задача
Первой тестовой задачей является «задача Grep», взятая из исходной статьи про MapReduce, авторы которой говорят о ней как о «типичном представителе большого подмножества реальных программ, написанных пользователями MapReduce» [8]. Для решения этой задачи каждая система должна просматривать набор данных, состоящий из 100-байтных записей, и производить в них поиск по трехсимвольному шаблону. Каждая запись состоит из уникального ключа, занимающего первые 10 байт, и 90-байтного случайного значения. Искомый шаблон находится по одному разу в последних 90 байтах каждых 10000 записей.
Вводные данные сохраняются в каждом узле в плоских текстовых файлах, по одной записи в каждой строке. Для прогонов тестов на Hadoop эти файлы в неизменном виде загружались прямо в HDFS. Для загрузки данных в Vertica и СУБД-X в каждой из этих систем выполнялись проприетарные команды загрузки, и данные сохранялись с использованием следующей схемы:
CREATE TABLE Data (
key VARCHAR(10) PRIMARY KEY,
field VARCHAR(90) );
Задача Grep выполнялась с двумя разными наборами данных. Измерения в исходной статье про MapReduce основывались на обработке 1 Тбайт данных на примерно 1800 узлах, на каждый узел приходилось 5,6 миллионов записей, или примерно 535 Мбайт. В описываемом испытании для каждой системы задача Grep выполнялась на кластерах с 1, 10, 25, 50 и 100 узлами. Общее число записей, обрабатывавшихся на кластере каждого из этих размеров, составляло 5,6 миллионов × число узлов. Данные о производительности каждой из систем не только иллюстрируют то, как они масштабируется при возрастании объема данных, но также позволяют (до некоторой степени) сравнить результаты с исходной системой MR.
В то время как в первом наборе данных размер данных в расчете на один узел поддерживается таким же, как в исходном тесте MR, и изменяется только число узлов, во втором наборе данных общий его размер устанавливается таким же, как в исходном тесте MR (1 Тбайт), и эти данные поровну разделяются между меняющимся числом узлов. Эта задача позволяет сравнить, насколько хорошо масштабируется каждая система при возрастании числа доступных узлов.
Поскольку для Hadoop требуется в целом 3 Тбайт дисковой памяти, чтобы сохранять в HDFS три реплики каждого блока, пришлось запускать этот тест только на кластере с 25, 50 и 100 узлами (при наличии менее чем 25 узлов для хранения 3 Тбайт данных не хватает дисковой памяти).
4.2.1. Загрузка данных
Опишем теперь процедуры, использовавшиеся для загрузки данных из локальных файлов узлов во внутреннее представление уровня хранения каждой из систем.
Hadoop: Имеются два способа загрузки данных в распределенную файловую систему Hadoop: (1) использование файловой утилиты с интерфейсом командной строки для выгрузки в HDFS файлов, хранимых в локальной файловой системе, и (2) создание собственной программы загрузки данных, которая записывает данные с использованием внутреннего API ввода-вывода Hadoop. В данном случае не требовалось изменять вводные данные для тестовых MR-программ, и поэтому во всех узлы файлы загружались в HDFS параллельно в виде плоского текста с использованием утилиты командной строки. Хранение данных в такой манере позволяет MR-программам производить доступ к данным с использованием формата данных Hadoop TextInputFormat, в котором в каждом файле ключами являются номера строк, а соответствующие им значения – это содержимое строк. Было установлено, что этот подход приводит к более высокой эффективности как загрузки данных, так и выполнения задач, чем использование сериализованных форматов или средств сжатия данных Hadoop.
СУБД-X: Процесс загрузки в СУБД-X происходил в два этапа. Сначала в каждом узле кластера в параллель выполнялась команда SQL LOAD для чтения данных из локальной файловой системы, и их содержимое вставлялось в соответствующую таблицу базы данных. В этой команде указывалось, что локальные данные разделены некоторым специальным символом, так что не требовалось писать специальную программу для преобразования данных до их загрузки. Но, поскольку генератор тестовых данных просто создавал случайные ключи для каждой записи в каждом узле, системе было необходимо перераспределить кортежи по другим узлам кластера на основе атрибута разделения целевой таблицы. Можно было бы создать вариант генератора данных, учитывающий хэширование, что позволило бы СУБД-X просто загрузить вводные файлы в каждом узле без этого процесса перераспределения, но вряд ли это слишком сократило бы общее время загрузки.
После завершения фазы начальной загрузки выполнялась административная команда для реорганизации данных в каждом узле. Этот процесс выполнялся параллельно в каждом узле для сжатия данных, построения индексов на каждой таблице и других служебных действий.
Vertica: В Vertica также поддерживается команда SQL COPY, которая задается из одного узла, а затем координирует процесс загрузки, выполняемый параллельно в нескольких узлах кластера. В качестве входных данных команде COPY задается список узлов, для которых требуется выполнить операцию загрузки. Этот процесс аналогичен тому, который выполняется для СУБД-X: в каждом узле загрузчик системы Vertica расщепляет файлы исходных данных по некоторому разделителю, создает новый кортеж для каждой строки вводного файла и помещает этот кортеж в соответствующий узел на основе значения хэш-функции от его первичного ключа. После загрузки данных столбцы автоматически сортируются и сжимаются в соответствии с физической схемой базы данных.
Результаты и обсуждение: Результаты загрузки для наборов данных в 535 мегабайт на узел и 1 терабайт на кластер показаны на рис. 1 и 2 соответственно. Для СУБД-X разделено время двух фаз загрузки, что показано на диаграммах в виде составного прямоугольника: нижняя часть представляет время выполнения параллельной команды LOAD, а верхняя соответствует процессу реорганизации.
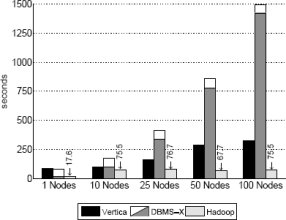
Рис. 1. Время загрузки – набор данных задачи Grep (535 мегабайт на узел)
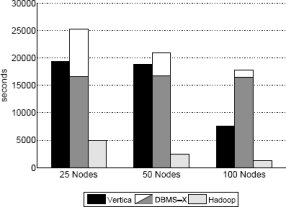
Рис. 2. Время загрузки – набор данных задачи Grep (1 терабайт на кластер)
На рис. 1 наиболее удивительна разница во времени загрузки данных в СУБД-X по сравнению с Hadoop и Vertica. Несмотря на параллельное выполнение команды LOAD в каждом узле кластера на первой фазе процесса загрузки, в действительности, данные в каждом узле загружались последовательно. Поэтому при возрастании общего объема данных пропорционально увеличивается и время загрузки. Это также объясняет то, что для набора данных в один терабайт на кластер время загрузки для СУБД-X не уменьшается при сокращении объема данных в расчете на узел. Однако выполнение сжатия и других служебных операций на данными в СУБД-X может производиться параллельно в нескольких узлах, и поэтому время выполнения второй фазы процесса загрузки сокращается вдвое при увеличении вдвое числа узлов, используемых для хранения терабайта данных. При отсутствии использования сжатия на уровне блоков или записей Hadoop явным образом превосходит и СУБД-X, и Vertica, поскольку в каждом узле происходит всего лишь копирование файла данных с локального диска в локальный экземпляр HDFS, а затем две его копии передаются в другие узлы кластера. Если бы данные загружались в Hadoop с использованием только одной копии каждого блока, то время загрузки уменьшилось бы втрое. Но, как будет показано в разд. 5, отсутствие нескольких копий часто приводит к увеличению времени выполнения заданий.
4.2.2 Выполнение задачи
Команды SQL: Поиск по шаблону для заданного поля выражается в SQL виде следующего запроса:
SELECT * FROM Data WHERE field LIKE ‘%XYZ%’;В обеих SQL-ориентированных системах отсутствовал индекс на атрибуте field, и поэтому для выполнения запроса требовался полный просмотр таблицы.
Программа MapReduce: MR-программа состоит из одной функции Map, которая получает одиночную запись, уже расщепленную в соответствующую пару «ключ/значение», и выполняет сопоставление значения с подстрокой. Если поиск подстроки успешно завершается, то функция Map просто выводит полученную пару «ключ/значение» в HDFS. Поскольку нет никакой функции Reduce, выходные данные каждого экземпляра функции Map образуют окончательный результат программы.
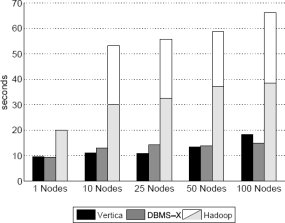
Рис. 4. Результаты задачи Grep – набор данных с 535 мегабайтами на узел
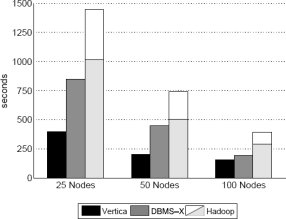
Рис. 5. Результаты задачи Grep – набор данных с 1 терабайтом на кластер
Результаты и обсуждение: Производительность всех трех систем при выполнении этой задачи показана на рис. 4 и 5. Удивительно, что на этих рисунках не согласуются относительные различия между системами. На рис. 4 две параллельные системы баз данных показывают почти одинаковую производительность, более чем в два раза превосходящую производительность Hadoop. Но на рис. 5 и СУБД-X, и Hadoop работают более чем в два раза медленнее Vertica. Причина состоит в том, что в этих двух экспериментах использовались данные существенно разного объема. Результаты, показанные на рис. 4, были получены на данных очень малого объема (535 мегабайт на узел). Это приводит к тому, что не столь уж незначительные накладные расходы на запуск Hadoop становятся фактором, ограничивающим производительность системы. Как будет показано в п. 5.1.2, для запросов с небольшим временем выполнения (меньше одной минуты) время запуска доминирует в общем времени выполнения. По наблюдениям авторов, проходит 10-25 секунд, пока все задачи Map стартуют и начинают выполняться с полной скоростью в узлах кластера. Кроме того, по мере увеличения общего числа этих задач появляются дополнительные накладные расходы для координации активности узлов центральным контроллером заданий. Эти накладные расходы незначительно возрастают при добавлении узлов к кластеру и, как показывает рис. 5, при выполнении более протяженных задач обработки данных затмеваются временем, затрачиваемым на требуемую обработку.
На приведенных диаграммах верхняя часть прямоугольников Hadoop представляет время выполнения дополнительного задания MR, объединяющего выходные данные в один файл. Поскольку эта заключительная фаза выполнялась в виде отдельного задания MapReduce, в случае, показанном на рис. 4, на нее тратилась большая часть общего времени выполнения задачи, чем в случае с рис. 5, т.к. накладные расходы на запуск снова доминировали над полезными затратами, требуемыми для выполнения завершающей фазы. Хотя задача Grep является селективной, результаты, показанные на рис. 5, демонстрируют, что для выполнения этой объединительной фазы могут потребоваться сотни секунд из-за потребности в открытии и объединении большого числа мелких выводных файлов. Каждый экземпляр Map помещает свои выводные данные в отдельный файл HDFS, и поэтому, хотя каждый файл невелик, имеется много задач Map и, следовательно, много файлов в каждом узле.
На рис. 5, на котором показаны результаты экспериментов с набором данных в один терабайт на кластер, видно, что все системы при увеличении вдвое числа узлов выполняют задачу почти вдвое быстрее. Этого и следовало ожидать, поскольку в этих экспериментах общий объем данных, распределенных по узлам, остается неизменным. Hadoop и СУБД-X демонстрируют примерно одинаковую производительность, поскольку в этих экспериментах накладные расходы на запуск Hadoop амортизируются возросшим объемом обрабатываемых данных. Однако результаты отчетливо показывают превосходство Vertica над СУБД-X и Hadoop. Авторы объясняют это активным использованием в Vertica сжатия данных (см. п. 5.1.3), которое становится более эффективным при хранении в каждом узле большего объема данных.