MapReduce и параллельные СУБД: друзья или враги?
Майкл Стоунбрейкер, Дэниэль Абади, Дэвит Девитт, Сэм Мэдден, Эрик Паулсон, Эндрю Павло и Александр Разин
Перевод: Сергей Кузнецов
4. Возможные приложения
Хотя параллельные СУБД могут справиться с той же семантической рабочей нагрузкой, что и MR, регулярно упоминаются несколько классов приложений, для которых лучше подходит модель MR, а не СУБД. Проанализируем пять таких классов приложений и обсудим преимущества использования одного вида систем перед другим видом.4.1. ETL и наборы данных, читаемые только единожды
Каноническое использование MR характеризуется следующим шаблоном из пяти операций:- чтение журнальной информации из нескольких разных источников;
- разбор и очистка журнальных данных;
- выполнение сложных преобразований (таких как связывание данных с сессиями пользователей ("sessionalization"));
- принятие решения о том, какие атрибутивные данные следует сохранить и
- загрузка информации в СУБД или другую систему хранения данных.
Эти шаги аналогичны фазам извлечения, преобразования и загрузки в системах ETL. Система MR, по сути, "стряпает" из необработанных данных полезную информацию, которая потребляется другой системой хранения. Поэтому систему MR можно считать параллельной системой ETL общего назначения.
ETL для параллельных СУБД поддерживают многие продукты, включая Ascential, Informatica, Jaspersoft и Talend. Рынок велик, поскольку почти все крупные компании используют системы ETL для загрузки больших объемов данных в хранилища данных. Одной из причин этой симбиотической взаимосвязи является очевидное различие в том, что каждый из этих классов систем обеспечивает для пользователей: СУБД не пытаются выполнять ETL, а системы ETL не пытаются поддерживать сервисы СУБД. Работа системы ETL обычно предшествует работе СУБД, поскольку на фазе загрузки данные, как правило, поступают прямо в СУБД.
4.2. Сложная аналитика
Во многих приложениях интеллектуального анализа (data mining) и кластеризации данных программе приходится производить несколько проходов по данным. Такие приложения невозможно представить в виде одиночных агрегатных SQL-запросов. Вместо этого требуется сложная программа обработки потоков данных, в которой выходные данные одной части приложения являются входными данными другой его части. MR является хорошим кандидатом для реализации таких приложений.4.3. Полуструктурированные данные
В отличие от СУБД, системам MR не требуется, чтобы пользователи определяли схемы своих данных. Поэтому такие системы легко сохраняют и обрабатывают так называемые "полуструктурированные" ("semistructured") данные. По нашему опыту, такие данные часто имеют вид пар "ключ-значение", где число атрибутов, присутствующих в записях, меняется. Этот стиль данных типичен для журналов Web-трафика, происходящих из разных источников.При использовании реляцинной СУБД единственный способ моделирования таких данных состоит в применении таблицы с большим числом атрибутов, пригодной для размещения записей нескольких типов. В каждой строке атрибуты, которые отсутствуют в сохраняемой в этой строке записи, содержат неопределенное значение (NULL). В СУБД, сохраняющих данные по строкам (row-based), работа с такими "широкими" таблицами, вообще говоря, может приводить к плохой производительности. С другой стороны, в поколоночных (column-based) СУБД эта проблема смягчается за счет чтения с диска значений только значимых атрибутов и автоматического подавления неопределенных значений [3]. Было продемонстрировано, что эти методы обеспечивают хорошую производительность при работе с наборами RDF-данных, и мы ожидаем того же при работе с более простыми данными "ключ/значение".
В той степени, в которой полуструктурированные данные соответствуют обсуждавшейся выше концепции "стряпни" данных (т.е. данные подготавливаются для загрузки во внутреннюю систему обработки данных), системы в стиле MR хорошо подходят для работы с ними. Если же набор полуструктурированных данных предназначается для использования с помощью аналитических запросов, то, по нашему мнению, лучшим решением будет параллельная СУБД с поколоночным хранением данных.
4.4. Анализ на "скорую руку" (quick-and-dirty)
Одним из досадных аспектов многих современных параллельных СУБД является то, что их трудно должным образом устанавливать и конфигурировать, поскольку пользователи часто сталкиваются с мириадами параметров настройки, которые необходимо корректно установить, чтобы добиться эффективной работы системы. По сравнению с нашим опытом установки двух коммерческих параллельных систем, установка реализации MR с открытыми исходными текстами оставила наилучшие воспоминания [17]. Мы смогли получить работающую систему MR и начать выполнять в ней запросы существенно быстрее, чем при использовании какой-либо СУБД. На самом деле, только экспертная поддержка одного из поставщиков позволила нам настроить соответствующую параллельную СУБД таким образом, чтобы выполнение запросов завершалось за минуты, а не часы или дни.После установки и правильного конфигурирования СУБД программисты должны определить схему своих данных (если она еще не существует), а затем загрузить данные в систему. В СУБД этот процесс длится значительно дольше, чем в системе MR, потому что СУБД должна разобрать и проверить в загружаемых кортежах каждый элемент данных. В отличие от этого, MR-программисты по умолчанию (а значит, чаще всего) загружают свои данные путем их простого копирования в распределенную блочную систему хранения, на которой основывается система MR.
Если программисту требуется выполнить некоторый единичный анализ текущих данных, то, очевидно, предпочтительной является модель MR со своим небольшим временем раскрутки. С другой стороны, профессиональные программисты СУБД и администраторы предпочитают тратить больше времени на обучение и подготовку системы к использованию, поскольку получаемый выигрыш в производительности окупает предварительные расходы.
4.5. Производственная эксплуатация при ограниченном бюджете
Еще одним достоинством систем MR является то, что почти все они созданы в проектах open source и доступны полностью бесплатно. СУБД и, в частности, параллельные СУБД стоят недешево. Хотя, насколько нам известно, имеются хорошие одноузловые решения с открытыми исходными текстами, надежная параллельная СУБД, поддерживаемая сообществом open source, отсутствует. Корпоративные пользователи с высоким уровнем потребностей и крупным бюджетом могут позволит себе платить за коммерческую систему и за все инструментальные средства, поддержку и обслуживание, пользователи с более умеренными бюджетом или уровнем требований считают более привлекательными системы с открытыми исходными текстами. Сообщество баз данных упускает свой шанс, не обеспечивая пользователям более совершенное параллельное решение с открытыми кодами.4.6. Мощные инструментальные средства
Системы MR являются мощными инструментальными средствами для приложений в стиле ETL и сложной аналитики. Кроме того, они популярны среди пользователей, нуждающихся в анализе данных "на скорую руку" и обладающих ограниченным бюджетом. С другой стороны, если приложению требуется эффективная обработка запросов, неважно, над полуструктурированными или строго структурированными данными, то более предпочтительны СУБД. В следующем разделе мы обсудим результаты нескольких сценариев использования, показывающие это превосходство в производительности. В число рассматриваемых задач обработки данных входят как те, которые считаются особенно подходящими для систем MR, так и более специфичные для СУБД сложные запросы.5. "Лакомые кусочки" для СУБД
Чтобы продемонстрировать соотношения показателей производительности параллельных СУБД и систем MR, мы опубликовали результаты сравнения тестовых испытаний двух параллельных СУБД и инфраструктуры MR Hadoop [17]. Мы хотели обнаружить предельную производительность кажого из подходов при их применении к областям, входящим и не входящим в их целевые пространства приложений. Мы использовали две системы баз данных: коммерческую поколоночную СУБД Vertica и СУБД-X с хранением данных по строкам (продукт одного из крупных коммерческих производителей). В состав тестового набора входила простая задача, представленная в исходной статье про MR от Google [7], а также четыре другие аналитические задачи возрастающей сложности, являющиеся, по нашему мнению, распространенными и пригодными для решения на системах обоих классов. Эксперименты проводились на кластере со 100 узлами без общих ресурсов в университете Висконсин-Мэдисон. В полном тексте статьи [17] описываются и обсуждаются результаты всех экспериментов, включая время загрузки данных. Здесь мы ограничимся сводкой наиболее интересных результатов. (Исходные коды, использованные в этом исследовании, доступны на сайте database.cs.brown.edu.)Hadoop, несомненно, является наиболее популярной общедоступной версией инфраструктуры MR (версия от Google, возможно, быстрее, но нам недоступна), а СУБД-X и Vertica являются популярными параллельными СУБД с хранением данных по строкам и столбцам соответственно.
После публикации статьи Павло и др. [17] мы продолжали настраивать все три системы. Кроме того, мы получили из сообщества Hadoop много советов по поводу способов повышения производительности. Мы все их опробовали, и результаты, представленные в этой статье (по состоянию на август 2009 г.), представляют лучшее, чего нам удалось добиться с существенной помощью экспертов по всем трем системам. На самом деле, время, потраченное нами на настройку Hadoop, теперь превосходит время, которое ушло на работу с каждой из двух других систем. Хотя, как отмечалось выше, начальная установка Hadoop оставила у нас самые хорошие воспоминания, настройка этой системы для получения максимальной производительности оказалась трудной задачей. Очевидно, что производительность является движущейся мишенью, поскольку у всех трех продуктов регулярно появляются новые релизы.
5.1. Исходная MR-задача Grep
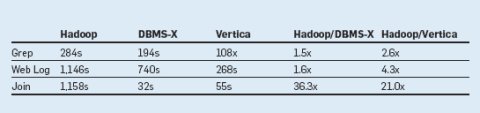
Наш первый эксперимент основывался на задаче Grep из исходной статьи про MR, в которой она описывается, как "представитель большой части реальных программ, написанных пользователями MapReduce" [7]. При решении этой задачи каждая система должна просканировать набор данных из 100-байтовых записей, производя поиск трехсимвольного шаблона. Каждая запись состоит из уникального ключа, занимающего первые 10 байт, и случайного 90-байтового значения. Шаблон поиска ищется только в последних 90 байт каждой из 10000 записей. Мы использовали набор данных объемом в один терабайт, разделенный по 100 узлам (10 гигабайт на узел). Набор данных состоит из 10 миллиардов записей, каждая из которых занимает 100 байт. Поскольку в этой задаче, по существу, требуется выполнить последовательное сканирование набора данных в поисках заданного шаблона, она позволяет простым образом измерить, насколько быстро система может просканировать крупный набор записей. При решении этой задачи невозможно с пользой применить какие-либо сортировку или индексацию, и ее легко запрограммировать как в среде MR, так и на SQL. Поэтому можно было бы ожидать более быстрого выполнения от низкоуровневой системы (такой как Hadoop), выполяняемой прямо поверх файловой системы (HDFS), чем от более тяжеловесных СУБД.Однако время выполнения, приводимое в табл. 1, показывает удивительный результат: системы баз данных оказываются почти в два раза быстрее Hadoop. Некоторые причины этого явления мы поясняем в разделе об архитектурных различиях.
Табл. 1. Результаты сравнения систем на тестовом наборе
5.2. Задача обработки Web-журналов
Вторая задача – это классическая SQL-агрегация с использованием разделаGROUP BY над таблицей посещений пользователями некоторых Web-сайтов. Такие данные типичны для журналов Web-серверов, и подобные запросы обычно используются для анализа трафика. В этом эксперименте мы использовали набор данных объемом в 2 терабайта, состоящий из 155 миллионов записей, которые были разделены по 100 узлам (20 гигабайт на узел). Каждая система должна вычислить общий объем дохода от рекламы, полученного для каждого IP-адреса, посещение которого зарегистрировано в журнале. Подобно предыдущей задаче, требуется прочитать все записи, и поэтому индексация таблицы СУБД не помогает. Можно было бы подумать, что при решении этой задачи отличится Hadoop, потому что здесь требуются прямолинейные вычисления, но результаты в табл. 1 показывает, что системы баз данных превосходят Hadoop даже в большей степени, чем при решении задачи Grep.
5.3. Задача соединения
Последняя задача, которую мы здесь обсудим, – это достаточно сложное соединение двух таблиц с применением дополнительных операций агрегации и фильтрации. Набор данных о посещениях пользователями Web-сайтов соединяется с дополнительной 100-гигабайтной таблицей значенийPageRank для 18 миллионов URL (1 гигабайт на узел). Задача соединения состоит из двух подзадач, выполняющих сложные вычисления над этими двумя наборами данных. В первой части задачи каждая система должна найти IP-адреса, для которых получен наибольший доход от рекламы в течение заданного временного промежутка посещений пользователей. После получения этих промежуточных записей системы должны вычислить среднее значение PageRank для всех страниц, посещенных в течение этого промежутка времени.
СУБД должны хорошо выполнять аналитические запросы со сложными операциями соединения (см. таблицу). СУБД-X оказалась быстрее, чем Hadoop, в 36 раз, а Vertica – в 21 раз. В общем случае, время выполнения запросов для типичных задач пользователей находится в промежутке между этими крайними значениями. В следующем разделе мы исследуем причины появления таких результатов.
6. Архитектурные различия
Различия в производительности между Hadoop и СУБД объясняются различными факторами. Прежде чем углубляться в детали, следует сказать, что эти различия происходят из особенностей реализации рассматриваемых двух классов систем, а не из какого-либо фундаментального различия в их архитектурах. Например, модель обработки MR не зависит от используемой системы хранения, так что теоретически данные можно было бы предварительно обрабатывать, индексировать, сжимать и аккуратно размещать в области хранения на фазе загрузки, как это делает СУБД. Поэтому целью нашего исследования являлось сравнение реальных различий в производительности между представительными реализациями этих двух моделей.6.1. Повторяющийся разбор записей
Одним из факторов, способствующих не слишком высокой производительности Hadoop, является то, что в конфигурации, которая применяется по умолчанию, данные сохраняются в распределенной файловой системе (HDFS) в том же текстовом формате, в котором они были образованы. Поэтому при использовании этого метода хранения обязанность разбора полей каждой записи ложится на код пользователя. Hadoop обеспечивает возможность хранения данных в файлах (SequenceFile) в виде пар "ключ/значение", но, несмотря на эту возможность, в коде пользователя требуется разбор "значения" каждой записи, если оно состоит из нескольких атрибутов. Мы обнаружили, что использование для хранения данных механизма SequenceFile без сжатия в наших испытаниях приводило к уменьшению производительности. Заметим, что именно тактика использования этого механизма без сжатия предлагалась сообществом MR для повышения производительности Hadoop.
В отличие от повторяющегося разбора записей в MR, в СУБД записи разбираются при начальной загрузке данных. Этот шаг разбора позволяет менеджеру хранения данных СУБД аккуратно разместить данные в области хранения, чтобы во время выполнения можно было непосредственно обращаться к наиболее эффективному представлению значений атрибутов. Во время выполнения никакой интерпретации кортежей параллельные СУБД не производят.
В модели MR нет ничего такого, что запрещало бы разбирать записи заранее и сохранять их в оптимизированных структурах (т.е. пойти на некоторое увеличение времени загрузки ради повышения производительности во время выполнения). Например, данные можно было бы хранить в файловой системе с использованием платформенно-независимого и расширяемого механизма компании Google Protocol Buffer, обеспечивающего сериализацию структурированных данных (эта опция не поддерживается в Hadoop). Или же можно было бы в каждом узле переместить данные из среды MR в реляционную СУБД, заменяя, тем самым, уровень хранения HGFS оптимизаированным хранилищем структурированных данных в стиле СУБД [4].
На основе подобных идей можно найти способы повышения производительности системы Hadoop. Накладные расходы на разбор данных являются проблемой, и механизм SequenceFile не обеспечивает ее эффективного решения. Эту проблему следует считать ориентиром при выборе направления будущих разработок.
6.2. Сжатие данных
Мы обнаружили, что существенный выигрыш в производительности обеспечивает включение в СУБД опции сжатия данных. Результаты тестовых испытаний показывают, что при использовании сжатия данных производительность Vertica и СУБД-X увеличивается в 2-4 раза. С другой стороны, при использовании сжатия входных данных Hadoop часто работает даже медленнее, чем без сжатия. В лучшем случае, за счет сжатия данных производительность Hadoop повышалась на 15%. Следует заметить, что в тестовых испытаниях Дина и Гемавата [7] сжатие данных не использовалось.Нам непонятно, почему эффект сжатия данных в Hadoop оказался таким незначительным. Практически во всех коммерческих хранилищах данных, основанных на SQL, сжатие данных применяется для повышения производительности. По-видимому, это связано с тем, что алгоритмы сжатия, применяемые в коммерческих СУБД, тщательно настраиваются, чтобы расходы на распаковку кортежей не перевешивали выигрыш от уменьшения объема обменов с дисками при чтении сжатых данных. Например, мы установили, что на современных процессорах стандатные Unix-реализации алгоритмов gzip и bzip оказываются слишком медленными, чтобы принести какую-то выгоду.
6.3. Конвейеризация
Во всех параллельных СУБД во время компиляции запроса создается план его выполнения, который во время выполнения запроса распределяется по соответствующим узлам. При выполнении запроса каждая операция плана должна посылать данные следующей операции, независимо от того, выполняются они в одном и том же узле или же в разных узлах, т.е. данные "проталкиваются" первой операцией во вторую операцию. Таким образом, организуется поток данных от их производителя к потребителю. Промежуточные данные никогда не записываются на диск. Возникающее в работающей системе сопротивление потока (back-pressure) заставит производителя данных приостановиться до того, как у него возникнет возможность переполнить данными потребителя. Этот метод потокового выполнения запросов отличается от подхода, используемого в MR, где производитель записывает промежуточные результаты в локальные структуры данных, а потребитель впоследствии "затягивает" к себе эти данные. Такие структуры данных часто бывают достаточно крупными, так что системе приходится записывать их на диск, что создает потенциальное узкое место. Хотя запись структур на диск представляет Hadoop удобный способ установки контрольных точек для результатов промежуточных заданийMap, что повышает отказоустойчивость, наши исследования показывают, что этот подход приводит к порождению накладных расходов, способствующих снижению производительности.
6.4. Планирование
В параллельной СУБД каждому узлу точно известно, что и когда он должен делать в соответствии с распределенным планом выполнения запроса. Поскольку операции известны заранее, система может оптимизировать план выполнения для минимизации объема пересылок данных между узлами. В отличие от этого, каждая задача в системе MR планируется, исходя из поблочной обработки данных в каждом узле. Такое планирование работы во время выполнения на уровне блоков данных является значительно более дорогостоящим, чем планирование, производимое СУБД на стадии компиляции. С другой стороны, как утверждают некоторые исследователи [4], у динамического планирования в стиле MR имеется то преимущество, что оно позволяет адаптироваться к перекосам рабочей нагрузки и различиям в производительности между узлами системы.6.5. Поколоночное хранение данных
В поколоночных СУБД (таких как Vertica) система считывает с диска значения только тех атрибутов, которые требуются для выполнения запроса. Эта ограниченная потребность в считывании данных обеспечивает существенное повышение производительности по сравнению с традиционными системами баз данных, в которых данные сохраняются на диске по строкам, и система считывает с диска значения всех атрибутов каждой записи. В СУБД-X и Hadoop/HDFS данные хранятся, по существу, по строкам, и это обеспечивает СУБД Vertica значительное преимущество в производительности над двумя другими системами при решении задачи обработки Web-журналов.6.6. Обсуждение
По-видимому, сообщество Hadoop устранит в следующем релизе проблему, связанную со сжатием данных. Кроме того, некоторые другие черты параллельных СУБД, способствующие их высокой производительности, такие как поколоночное хранение и возможность работы прямо с упакованными данными, могут быть воспроизведены в системе MR за счет использования пользовательского кода. К тому же, у других реализаций MR (таких как проприетарная реализация от Google) могут иметься совсем другие показатели производительности. Механизм планирования и модель "втягивания" данных являются базисными элементами модели отказоустойчивости MR на уровне блоков, и они вряд ли будут изменены.Между тем, СУБД обеспечивают отказоустойчивость на уровне транзакций. Исследователи СУБД часто отмечают, что при возрастании размеров баз данных и числа обрабатывающих узлов, увеличивается и потребность в отказоустойчивости на уровне более мелких элементов. СУБД без труда адаптируются к этой потребности путем пометки одной или нескольких операций в плане запроса как "операций рестарта". Система поддержки времени выполнения сохраняет результаты этих операций на диске, способствуя рестарту "на уровне операций". Можно пометить любое число операций, что позволяет настраивать гранулярность рестартов. Такой механизм легко интегрируется в эффективную среду выполнения запросов СУБД, допуская различную гранулярность рестартов. Нам известны, по крайней мере, две исследовательские группы (из Вашингтонского университета и Калифорнийского университета в Беркли), которые изучают возможности балансировки накладных расходов во время выполнения и потерь работы в результате отказов системы.
В целом, мы ожидаем, что ETL и сложная аналитика будут производиться с использованием систем MR, а для поддержки рабочих нагрузок с большим числом запросов будут применяться СУБД. Поэтому, по нашему мнению, наилучшее решение состоит в сопряжении среды MR с СУБД, чтобы в этой среде можно было выполнять сложную аналитическую обработку, и обеспечении интерфейса с СУБД для выполнения встраиваемых запросов. В HadoopDB [4], Hive [21], Aster, Greenplum, Cloudera и Vertica имеются коммерчески доступные продукты и прототипы, основанные на таком "гибридном" подходе.