[Назад] [Оглавление] [Вперед]
2.2 Объектно-ориентированные базы данных в стандарте ODMG
Первый манифест формально являлся всего лишь статьей, представленной на Конференцию по объектно-ориентированным и дедуктивным базам данных группой частных лиц. Как вы могли видеть в предыдущем подразделе, требования Манифеста были скорее эмоциональными, чем явно специфицированными. В 1991 г. был образован консорциум ODMG (тогда эта аббревиатура раскрывалась как Object Database Management Group , но впоследствии приобрела более широкую трактовку – Object Data Management Group ). Консорциум ODMG тесно связан с гораздо более многочисленным консорциумом OMG (Object Management Group ), который был образован двумя годами раньше. Основной исходной целью ODMG была выработка промышленного стандарта объектно-ориентированных баз данных (общей модели). За основу была принята базовая объектная модель OMG COM (Core Object Model ). В течение более чем десятилетнего существования ODMG опубликовала три базовых версии стандарта, последняя из которых называется ODMG 3.0 [5]. 16
Забавно, что хотя ODMG (по мнению автора) вышла из OMG , в последние годы некоторые стандарты OMG опираются на объектную модель ODMG . В частности, на модель ODMG опирается спецификация языка OCL (Object Constraint Language ), являющаяся частью общей спецификации языка UML 1.4 (и UML 2.0) [7]. В этой статье мы не ставим цель провести детальное сопоставление подходов OMG и ODMG и отсылаем заинтересованных читателей к Энциклопедии Когаловского [6] и материалам сайтов этих консорциумов [7-8]. Мы ограничимся кратким изложением основных идей, содержащихся в стандарте ODMG -3.
Архитектура ODMG
Предлагаемая ODMG архитектура показана на рис. 2.1. В этой архитектуре определяются способ хранения данных и разные виды пользовательского доступа к этому “хранилищу данных”17. Единое хранилище данных доступно из языка определения данных, языка запросов и ряда языков манипулирования данными.18 На рис. 2.1 ODL означает Object Definition Language (язык определения объектов), OQL – Object Query Language (язык объектных запросов) и OML – Object Manipulation Language (язык манипулирования объектами).
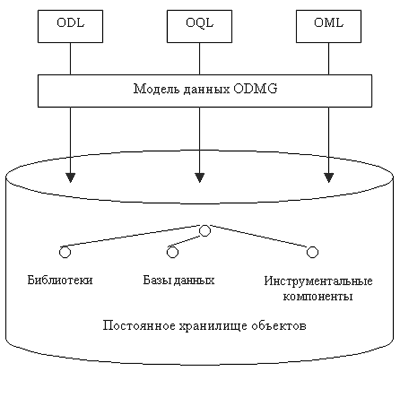
Рис. 2.1. Архитектура ODMG
Центральной в архитектуре является модель данных, представляющая организационную структуру, в которой сохраняются все данные, управляемые ООСУБД. Язык определения объектов, язык запросов и языки манипулирования разработаны таким образом, что все их возможности опираются на модель данных. Архитектура допускает существование разнообразных реализационных структур для хранения моделируемых данных, но важным требованием является то, что все программные библиотеки и все поддерживающие инструментальные средства обеспечиваются в объектно-ориентированных рамках и должны сохраняться в согласовании с данными.
Основными компонентами архитектуры являются следующие.
- Объектная модель данных. Все данные, сохраняемые ООСУБД, структуризуются в терминах конструкций модели данных. В модели данных определяется точная семантика всех понятий (более подробно см. ниже).
- Язык определения данных (ODL ). Схемы баз данных описываются в терминах языка ODL , в котором конструкции модели данных конкретизируются в форме языка определения. ODL позволяет описывать схему в виде набора интерфейсов объектных типов, что включает описание свойств типов и взаимосвязей между ними, а также имен операций и их параметров. ODL не является полным языком программирования; реализация типов должна быть выполнена на одном из языков категории OML . Кроме того, ODL является виртуальным языком в том смысле, что в стандарте ODMG не требуется его реализация в программных продуктах ООСУБД, которые считаются соответствующими стандарту. Допускается поддержка этими продуктами эквивалентных языков определения, включающих все возможности ODL , но адаптированных под особенности конкретной системы. Тем не менее, наличие спецификации языка ODL в стандарте ODMG является важным, поскольку в языке конкретизируются свойства модели данных.
- Язык объектных запросов (ODL ). Язык имеет синтаксис, похожий на синтаксис языка SQL, но опирается на семантику объектной модели ODMG . В стандарте допускается прямое использование OQL и его встраивание в один из языков категории OML .
- Языки манипулирования объектами (OML ). Для программирования реализаций операций и приложений требуется наличия объектно-ориентированного языка программирования. OML представляется собой интегрирование языка программирования с моделью ODMG ; это интегрирование производится за счет определенных в стандарте правил языкового связывания (language binding ). Дело в том, что в самих языках программирования, естественно, не поддерживается стабильность объектов. Чтобы разрешить программам на этих языках обращаться к хранимым данным, языки должны быть расширены дополнительными конструкциями или библиотечными элементами. Эту возможность и обеспечивает языковое связывание.
- Постоянноехранилище объектов. Логическая организация хранилища данных любой ООСУБД, совместимой со стандартном ODMG , должна основываться на модели данных ODMG . Физическая организация у разных ООСУБД может различаться, но в любом случае она должна обеспечивать эффективные структуры данных для хранения иерархии типов и объектов, являющихся экземплярами этих типов. Иерархия типов связана не только с данными, но и с различными библиотеками и компонентами инструментальных средств, поддерживающими разработку приложений. Так что в ООСУБД, совместимой со стандартом ODMG , хранилище представляет собой интегрированную систему, где согласованным образом сохраняются данные и программный код.
- Инструментальные средства и библиотеки. Инструментальные средства, поддерживающие, например, разработку пользовательских приложений и их графических интерфейсов, программируются на одном из OML и сохраняются как часть иерархии классов. Библиотеки функций доступа, арифметических функций и т.д. также сохраняются в иерархии типов и являются единообразно доступными из программного кода разработчика приложения. Ассортимент инструментальных средств и библиотек в стандарте не определяется.
В одной ООСУБД могут поддерживаться несколько OML . В стандарте ODMG -2 были специфицированы правила связывания для языков C ++ и Smalltalk 19. Практически завершена работа над спецификаций правил связывания для языка Java.
Введение в объектную модель ODMG
Модель ODMG является объектной моделью данных, включающей возможность описания как объектов, так и литеральных значений. На разработку модели повлиял тот факт, что она предназначена для поддержки работы с базами данных, так что особо важной является эффективность доступа к данным. Большинство других объектных моделей (см. например, матрицу объектных моделей Фрэнка Манолы [9]) ориентировано на языки программирования, расc читанных на работу со всеми данными в основной памяти. В этом случае допустимо представлять все данные как объекты. Но если требуется управлять большим объемом данных, расположенных во внешней памяти, то требуется некоторый компромисс между “чистотой” модели и требуемой эффективностью. Модель ODMG подстраивается под специфику систем баз данных следующим образом:
- Для баз данных, схем и подсхем обеспечивается набор встроенных объектных типов.
- Модель включает ряд встроенных структурных типов, позволяющих применять традиционные методы моделирования баз данных.
- Модель одновременно включает понятия объектов и литералов20.
- В модели связи между объектами отличаются от атрибутов объектов (аналогично тому, как это делается в ER -модели).
Обсудим немного более подробно два последних пункта.
Объекты и литералы
Как утверждалось в Первом манифесте, одним из важнейших отличий объектов от значений является наличие у объекта уникального идентификатора (объекты обладают свойством идентифицируемости). Накладные расходы, требуемые для обращения к объекту по его идентификатору с целью получения доступа к базовым значениям данных, могут весьма сильно замедлить работу приложений. Поэтому в модели ODMG допускается описание всех данных в терминах объектов и использование традиционного вида значений, которые в модели называются литеральными значениями. Таким образом, возраст человека может задаваться целочисленным литералом, а не объектом, имеющим свойство21 возраст. В этом случае значение возраста будет сохраняться как часть структуры данных объекта человек, а не в отдельном объекте. Это, в частности, означает, что объект может входить в состав нескольких других объектов, а литерал – нет. Схема базы данных в модели ODMG главным образом состоит из набора объектных типов, но компонентами этих типов могут быть типы литеральных значений.
Другим понятием, используемым для различения объектов и литералов, является понятие изменчивости (mutability ). Предположим, например, что данные о человеке составляют структуру <имя, возраст, адрес_проживания> . Тогда возможны два варианта хранения этих данных:
- Если человек представляется в виде объекта, то компоненты описывающей его структуры данных могут изменяться (например, может изменяться адрес), но объект (человек) остается тем же самым (поскольку объектный идентификатор не изменяется). Тем самым, объекты обладают свойством изменчивости.
- Если же данные о человеке сохраняются в виде литеральной структуры, и один из компонентов этой структуры изменяется, то вся структура трактуется как новое значение. Если данные о человеке не должны изменяться, то не может изменяться ни один элемент структуры, и она является неизменчивым литералом.22
Другими словами, объект идентифицируется своим объектным идентификатором (OID – Object Identifier ), который полностью отделен от значений компонентов объекта, а литерал полностью идентифицируется значениями своих компонентов.
Связи
В большинстве объектных систем связи неявно моделируются как свойства, значениями которых являются объекты. Например, если человек работает на некоторую компанию, то у каждого объекта-человека должно иметься свойство, которое можно назвать worksFor и значением которого является соответствующий объект-компания.23 Возникает проблема, если у объекта-компании имеется свойство, которое затрагивает множество служащих этой компании (например, employees – множество, включающее все объекты служащих данной компании). Эти два свойства являются несвязными, и поддержка их согласованности может вызывать значительную программистскую проблему.
В модели ODMG , подобно ER -модели, различаются два вида свойств – атрибуты и связи, хотя и несколько другим образом. Атрибутами называются свойства объекта, значение которых можно получить по OID объекта, но не наоборот. Значениями атрибутов могут быть и литералы, и объекты, но только тогда, когда не требуется обратная ссылка. Связи – это инверсные свойства. В этом случае значением свойства может быть только объект, поскольку литеральные значения не обладают свойствами. Поэтому возраст служащего обычно моделируется как атрибут, а компания, в которой работает служащий, – как связь.
При определении связи должна быть определена ее инверсия. В приведенном выше примере, если worksFor определяется как связь, должно быть явно указано, что инверсией является свойство employees объекта-компании, а при определении employees должна быть указана инверсия worksFor . После этого система баз данных должна поддерживать согласованность связанных данных, что позволяет сократить объем работы программистов приложений и повысить надежность их программ.24 Если в объекте-компании свойство employees не требуется, то свойство объекта-служащего employees может быть атрибутом.
Объектные и литеральные типы
В модели ODMG база данных представляет собой коллекцию различимых значений (denotable values ) двух видов – объекты и литералы. Объекты обладают свойствами идентифицируемости и индивидуального существования, а литералы являются компонентами объектов. Модель данных содержит конструкции для спецификации объектных и литеральных типов. Объектные типы существуют в иерархии объектных типов; литеральные типы похожи на типы, характерные для обычных языков программирования (например, С или Pascal ). В модели ODMG не используется термин класс. Единственная классификационная конструкция называется типом, и типы описывают как объекты, так и литералы. То, что называлось классом в Первом манифесте, в ODMG называется объектным типом.
В модели поддерживается ряд литеральных типов – базовые скалярные числовые типы, символьные и булевские типы (атомарные литералы), конструируемые типы литеральных записей (структур) и коллекций. Конструируемые литеральные типы могут основываться на любом литеральном или объектном типе, но считаются неизменчивыми. Даты и время строятся как литеральные структуры. Подробнее о литеральных типах см. в следующем подразделе.
Объектный тип состоит из интерфейса и одной или нескольких реализаций.25 Интерфейс описывает внешний вид типа: какими свойствами он обладает, какие в нем доступны операции и каковы параметры у этих операций.26 В реализации определяются структуры данных, реализующие свойства, и программный код, реализующий операции. Интерфейс составляет общедоступную (public ) часть типа, а в реализации при необходимости могут вводиться дополнительные частные (private ) свойства и операции. Все объектные типы (системные или определяемые пользователем) образуют решетку (lattice ) типов, в корне которой находится предопределенный объектный тип Object . Чтобы не объяснять подробно, что такое решетка, приведем пример графа, являющегося решеткой (рис. 2.2).
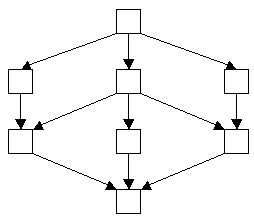
Рис. 2.2. Пример ориентированного графа, являющегося решеткой
Поскольку для определения реализации объектного типа требуется использовать один из языков OML , которые мы в этой статье не обсуждаем, ограничимся рассмотрением интерфейсной части типа. Интерфейс объектного типа состоит их следующих компонентов:
- имя;
- набор супертипов;
- имя поддерживаемого системой экстента;
- один или более ключей для ассоциативного доступа;
- набор атрибутов,каждый из которых может быть объектом или литеральным значением;
- набор связей, каждая из которых указывает на некоторый другой объект;
- набор операций.
Атрибуты и связи совместно называются свойствами, а свойства и операции совместно называются характеристиками объектного типа (или объектов данного типа).
Точно так же, как имеются атомарные и конструируемые литеральные типы, существуют атомарные и конструируемые объектные типы. В стандарте ODMG 3.0 говорится, что атомарными объектными типа являются только типы, определяемые пользователями (см. ниже).. Конструируемые объектные типы включают структурные типы и набор типов коллекций.
Язык определения объектов ODL
ODL является языком определения данных для объектной модели ODMG 27. ODL используется исключительно для описания интерфейсов типов приложения, а не для программирования реализации. Это не язык программирования, а всего лишь язык описания схем баз данных.
“Программа” на языке ODL – это набор определений типов, констант, исключительных ситуаций, интерфейсов типов и модулей. Не углубляясь в детали и не приводя синтаксических правил, остановимся на наиболее интересных (с точки зрения автора этой статьи) особенностях ODL.
Язык обеспечивает исключительно мощные возможности для определения литеральных типов. С точки зрения автора, наиболее интересны типы коллекций. Можно определить четыре разновидности типов коллекций. Типы категории set – это обычные типы множеств. Типы категории bag – эти типы мультимножеств (в значениях которых допускается наличие элементов-дубликатов). Значениями типов категории list являются упорядоченные списки значений (среди них допускаются дубликаты). Наконец, значениями типы dictionary являются множества пар <ключ, значение> , причем все ключи в этих парах должны быть различными. Определения типов имеют рекурсивную природу. Например, можно определить тип множества структур, элементами которых будут являться списки мультимножеств и т.д.
Синтаксические правила, относящиеся к определению объектных типов, требуют достаточно подробных разъяснений. К сожалению, в стандарте ODMG 3.0 этих разъяснений явно недостаточно. Поэтому дальнейший текст этого пункта является некоторым домыслом автора этой статьи, который логичен, но не обязательно соответствует истинным взглядам авторов стандарта (проверить это не представляется возможным).28
Во-первых, объектный тип можно определить с помощью двух разных синтаксических конструкций языка ODL – interface и class 29. Определение класса отличается от определения интерфейса наличием двух необязательных разделов: extends и type _ property _ list . В действительности, наиболее важным отличием класса от интерфейса является возможность наличия второго из этих разделов. В списке свойств30 могут присутствовать элементы extent и key . В спецификации модели данных ODMG 3.0 (хотя это и не отражается явно в синтаксисе ODL ) говорится, что для каждого класса может быть определен только один экстент, являющийся множеством всех объектов этого класса, которые после создания должны сохраняться в базе данных.31
Ключ – это набор свойств объектного класса, однозначно идентифицирующий состояние каждого объекта, входящего в экстент класса (это аналог возможного ключа реляционной модели данных). Для класса может быть объявлено несколько ключей, а может не быть объявлено ни одного ключа даже при наличии определения экстента. В последнем случае в экстенте класса могут существовать разные объекты с одним и тем же состоянием.32
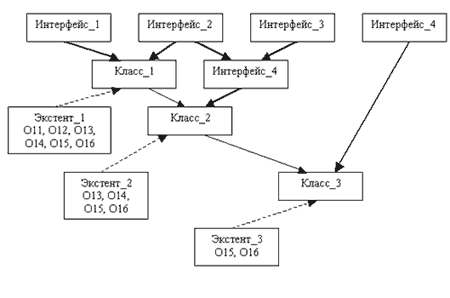
Рис. 2.3. Пример иерархии объектных типов и их экстентов
Далее, хотя и интерфейсы, и классы являются средствами определения объектных типов, между ними проводится жесткое различие. Допускается создание объектов только тех объектных типов, которые определены как классы. Объектные типы, определенные как интерфейсы, могут использоваться только для порождения новых объектных типов (интерфейсов и классов) на основании (вообще говоря) множественного наследования. Классы могут определяться на основе (вообще говоря) множественного наследования интерфейсов и одиночного наследования классов.
Механизм наследования от интерфейсов называется в ODMG наследованием IS - A, а механизм наследования от классов – extends . Прежде чем попытаться пояснить этот подход, приведем пример графа наследования интерфейсов и классов, в котором также показывается место существующих экстентов и объектов (рис. 2.3).
На рис. 2.3 “жирными” стрелками показаны связи объектных типов по наследованию IS - A . Обычные стрелки показывают связи по наследованию extends . Пунктирные стрелки соответствуют связям экстентов и соответствующих классов. Обратите внимание, что на этом рисунке у каждого из классов, входящих в иерархию, определен свой собственный экстент. Как демонстрирует рисунок, в модели ODMG поддерживается семантика включения, означающая, что экстент любого подкласса является подмножеством экстента любого своего суперкласса (прямого или косвенного). Если у некоторого подкласса свой собственный экстент не определен, то с объектами этого подкласса можно работать только через экстент какого-либо суперкласса. Стандарт не требует обязательного определения экстента. В этом случае ответственность на поддержку работы с множествами объектов ложится на прикладного программиста (для этого можно использовать типы коллекций).
Итак, при порождении подкласса путем наследования extends от некоторого суперкласса подкласс наследует экстент и набор ключей суперкласса. Как мы уже заметили, для подкласса можно определить свой собственный экстент. Что же касается возможности переопределения ключей, то в стандарте отсутствуют явные указания о возможности или невозможности этого действия. Однако очевидно, что если бы было разрешено полное переопределение набора ключей для экстента подкласса, то это противоречило бы семантике включения. По мнению автора данной статьи, по этому поводу можно трактовать ODL одним из двух способов:
(1) Если в некотором подклассе определен набор ключей, то в любом его подклассе определение ключей запрещается.
(2) Если в некотором подклассе определен набор ключей, то определение ключей в любом его подклассе приводит к расширению для этого подкласса набора ключей суперкласса.
Теперь немного поговорим о связях. Связи определяются между объектными типами. В модели ODMG поддерживаются только бинарные связи, т.е. связи между двумя типами. Связи могут быть разновидностей “один-к-одному”, “один-ко-многим” и “многие-ко-многим” в зависимости от того, сколько экземпляров соответствующего объектного типа может участвовать в связи.
Связи явно определяются путем указания путей обхода (traversal paths ). Пути обхода указываются парами, по одному пути для каждого направления обхода связи33. Например, в базе данных “служащие-отделы-проекты” служащий работает (works ) в одном отделе, а отдел состоит (consists of ) множества служащих. Тогда путь обхода consists _ of должен быть определен в объектном типе DEPT , а путь обхода works – в типе EMP . Тот факт, что пути обхода относятся к одной связи, указывается в разделе inverse обоих объявлений пути обхода. В нашем случае определения типов DEPT и EMP могли бы выглядеть следующим образом:
class DEPT {
...
relationship set <EMP>
consists_of
inverse EMP :: works
... }
class EMP {
...
relationship DEPT works
inverse DEPT :: consists_of
... }
Как видно, это связь “один-ко-многим”. Путь обходаconsists _ of ассоциирует экземпляр типа DEPT со множеством экземпляров типа EMP , а путь обхода works ассоциирует экземпляр типа EMP с экземпляром типа DEPT . Пути обхода, ведущие к коллекциям объектов, могут быть упорядоченными или неупорядоченными в зависимости от вида коллекции, указанному в объявлении пути обхода. В приведенном выше примере consists _ of является неупорядоченным путем обхода.
В ООСУБД, соответствующей стандарту ODMG , должна поддерживаться ссылочная целостность связей. Это означает, что при ликвидации любого объекта, участвующего в связи, должны ликвидироваться и все пути обхода, ведущие к этому объекту. Такой подход гарантирует, что приложения не смогут воспользоваться путями обхода, ведущими к несуществующим объектам.
Наконец, хотя это явно не отражено в синтаксисе языка ODL (по непонятным для меня причинам), наряду с набором генераторов литеральных типов коллекций set < b>t > , bag < t > , list < t > , array < t > и dictionary < t , v > поддерживается аналогичный набор генераторов объектных типов коллекций – Set < t > , Bag < t > ,List < t > , Array < t > и Dictionary < t , v > . В отличие от литералов-коллекций объекты-коллекции обладают объектными идентификаторами и свойством изменчивости. Во всех случаях требуется, чтобы все элементы коллекции были одного типа, литерального или объектного. И для литеральных, и для объектных коллекций поддерживается возможность итерации коллекции с перебором элементов коллекции либо в порядке, определяемом системой (для множеств и мультимножеств), либо в порядке, предполагаемом видом коллекции (для списков, массивов и словарей).
Краткая характеристика языка запросов OQL
В кратком и неформальном описании языка мы будем по возможности строго следовать манере и последовательности изложения, принятым в стандарте ODMG 3.0, меняя только примеры.
Разработчики языка основывались на следующих основных принципах:
- OQL опирается на объектную модель ODMG.
- OQL очень близок к SQL /92. Расширения относятся к объектно-ориентированным понятиям, таким как сложные объекты, объектные идентификаторы, путевые выражения, полиморфизм, вызов операций и отложенное связывание.
- В OQL обеспечиваются высокоуровневые примитивы для работы с множествами объектов, но, кроме того, имеются настолько же эффективные примитивы для работы со структурами, списками и массивами.
- OQLявляется функциональным языком, допускающим неограниченную компонируемость операций, если операнды не выходят на пределы системы типов. Это является следствием того факта, что результат любого запроса обладает типом, принадлежащим к модели типов ODMG, и поэтому к результату запроса может быть применен новый запрос.
- OQL не является вычислительно полным языком. Он представляет собой простой язык запросов.
- Операторы языка OQL могут вызываться из любого языка программирования, для которого в стандарте ODMG определены правила связывания. И наоборот, в запросах OQL могут присутствовать вызовы операций, запрограммированных на этих языках.
- В OQL не определяются явные операции обновления, а используются вызовы операций, определенных в объектах для целей обновления.
- В OQL обеспечивается декларативный доступ к объектам. По этой причине OQL -запросы могут быть легко оптимизированы.
- Можно легко определить формальную семантику OQL.
Входные данные и результаты запросов
Как утверждается в стандарте ODMG 3.0, “OQL -запрос является функцией, вырабатывающей объект, тип которого может быть выведен на основе операций, которые участвуют в выражении запроса”. 34 Вот несколько примеров простых OQL -запросов (мы будем использовать в этих примерах определенные в предыдущем подразделе классы DEPT и EMP в предположении, что DEPARTMENTS и EMPLOYEES являются именами экстентов этих классов).
Пример 2.1. Найти даты рождения служащих, зарплата которых превышает 20000 руб.
SELECT DISTINCT E.EMP_BDATE
FROM EMPLOYEES E
WHERE E.EMP_SAL > 20000.00
Легко видеть, что этот запрос по своему виду ничем не отличается от соответствующего запроса к таблице EMP , выраженного на языке SQL . В данном случае результатом запроса будет литеральное значение типа set < date > , т.е. литеральное значение-множество, элементами которого являются значения типа date.
Пример 2.2. Найти имена и даты рождения служащих, зарплата которых превышает 20000 руб.
SELECT DISTINCT STRUCT (name: E.EMP_NAME, bdate: E.EMP_BDATE)
FROM EMPLOYEES E
WHERE E.EMP_SAL > 20000.00
Запрос снова очень похож на соответствующий запрос на языке SQL, а результатом запроса является литеральное значение-множество, элементами которого являются значения типа struct { string <20> name ; date bdate }. Наверное, для конечного пользователя языка OQL строгий вывод типа результата запроса может показаться избыточным, но для программистов приложений это свойство является очень важным.
Если предположить, что в классе EMP определена операция age , значением которой является возраст соответствующего служащего, то результатом запроса
SELECT DISTINCT STRUCT (name: E.EMP_NAME, age: E.age)
FROM EMPLOYEES E
WHERE E.EMP_SAL > 20000.00
будет литеральное значение-множество, элементами которого являются значения типа struct { string <20> name ; interval age } (пример 2.2a ).
Пример 2.3. Получить номера менеджеров отделов и тех сотрудников их отделов, зарплата которых превышает 20000 руб.
SELECT DISTINCT STRUCT ( mng: D.DEPT_MNG,
DHS: ( SELECT E
FROM D.CONSISTS_OF AS E
WHERE E.EMP_SAL > 20000.00 ) )
FROM DEPARTMENTS D
Внешне этот запрос снова похож на SQL -запрос со вложенным подзапросом, но это только внешнее сходство. Во-первых, в разделе FROM “подзапроса” мы имеем дело с переходом по связи CONSISTS _ OF от экземпляра объектного типа DEPT ко множеству экземпляров объектного типа EMP . Во-вторых, результатом запроса является литеральное значение-множество, элементами которого являются значения-структуры с двумя литеральными значениями, первое из которых есть атомарное литеральное значение типа INTEGER , а второе – литеральное значение-множество с элементами-объектами типа EMP. Более точно, результат запроса имеет тип set < struct { integer mng ; bag < EMP > DHS } >. Конечно, в “классическом” SQL такого быть не может, хотя в следующем разделе мы обсудим возможности объектно-реляционных расширений этого языка.
В OQL предполагается, что хранимые в базе данных объекты могут иметь индивидуальные имена. 35
Пример 2.4. Если, например, в базе данных сохраняется объект типа DEPT с именем main _ department, то результатом запроса
main _ department
будет являться соответствующий объект. Результатом запроса
main_department.CONSISTS_OF
будет литеральное значение-множество, состоящее из объектов типа EMP , ассоциированных через связь CONSISTS _ OF с объектом main _ department 36.
Наконец, в контексте OQL имя каждого экстента можно трактовать как имя объекта-множества. Поэтому результатом запроса
EMPLOYEES
будет литеральное множество, состоящее из всех объектов, которые содержаться в указанном экстенте.
Объекты как результаты запросов
В примерах предыдущего пункта результатами запросов являлись литеральные значения, не обладающие объектными идентификаторами. Если ввести следующие определения объектных типов:
typedef Set <interval> ages;
class persinfo {
attribute string <20> n;
attribute date b; };
typedef Bag <persinfo > info;
то можно сформулировать следующие запросы.
Пример 2.5
ages ( SELECT DISTINCT E.age
FROM EMPLOYEES E
WHERE E.EMP_SAL > 20000.00 )
Окончательным результатом этого запроса является объект-множество, включающий литеральные значения типа interval . 37
Пример 2.6
info ( SELECT persinfo (n: E.EMP_NAME, b: E.EMP_BDATE)
FROM EMPLOYEES E
WHERE E.EMP_SAL > 20000.00 )
В этом примере по литеральным значениям имени и даты рождения каждого служащего, размер зарплаты которого превышает 20000 руб., конструируется объект типа persinfo , а на основе литерального мультимножества этих объектов конструируется объект-мультимножество типа info .
В совокупности результатом допустимых в OQL выражений запросов могут являться:
- коллекция объектов;
- индивидуальный объект;
- коллекция литеральных значений;
- индивидуальное литеральное значение.
Путевые выражения
Для навигации между подобъектами сложных объектов и по связям между разными объектами в OQL поддерживается специальный вид выражений, называемых путевыми (path expression ). Эти выражения определяются в так называемой точечной нотации (вместо операции “.” можно использовать и операцию “->”). Рассмотрим несколько простых примеров. Предположим, что в классах DEPT и EMP , кроме связи CONSISTS _ OF - WORKS определена еще и связь “один-к-одному” MANAGED _ BY - MANAGER _ OF :
class DEPT {
...
relationship EMP managed_by
inverse EMP :: manager_of
... }
class EMP {
...
relationship DEPT manager_of
inverse DEPT :: managed_by
... }
Пример 2.7. Для получения объекта типа EMP , соответствующего менеджеру отдела main _ department достаточно написать выражение
main_department.managed_by
Если же требуется получить имя менеджера отдела main _ department , то можно воспользоваться путевым выражением
main_department.managed_by.EMP_NAME
Пример 2.8. Получить имена всех сотрудников отдела main _ department.
Кажется, что запрос очень похож на предыдущий, и что для него годится выражение
main_department.consists_of.EMP_NAME
Но в данном случае мы имеем связь “один-ко-многим”, и хотя у каждого служащего имеется только одно имя, такие путевые выражения в OQL не допускаются. Правильной формулировкой запроса является следующая:
SELECT E.EMP_NAME
FROM main_department.consists_of AS E
Предикаты и логические операции
В спецификации OQL , как и в стандарте языка SQL , термин предикат обозначает условное выражение, которое может участвовать в запросе. Но семантика похожих на SQL конструкций языка OQL существенно отличается, что мы покажем в следующем примере.
Пример 2.9. Получить номера отделов и имена сотрудников отделов, с размером зарплаты, большим 10000 руб., работающих в отделах с числом сотрудников, большим 40 человек, и со средним размером зарплаты, большим 20000 руб.
SELECT STRUCT (DEPT_NO : D.DEPT_NO, EMP_NAME : E.EMP_NAME )
FROM DEPARTMENTS D,
D.CONSISTS_OF
E
WHERE D.DEPT_EMP_NO > 40 AND
AVG (E.EMP_SAL) > 20000.00 AND
E.EMP_SAL > 10000.00
Как следует понимать семантику выполнения данного запроса? Образуется внешний цикл по просмотру объектов экстента DEPARTMENTS . Для каждого из этих объектов по связи CONSISTS _ OF образуется коллекция (в данном случае, множество) объектов, входящих в экстент EMPLOYEES . Тем самым, выполняется неявная факторизация (группирование) экстента EMPLOYEES , в которой инвариантом группы служащих является их общий отдел. По этому поводу в списке выборки и в условии выборки (предикате) разрешается использовать как свойства инварианта группы (в нашем случае, DEPT . DEPT _ NO и DEPT . DEPT _ EMP _ NO ) и индивидуальные свойства членов групп (в нашем случае, EMP . EMP _ NAME и EMP . EMP _ SAL ), так и “агрегатные” свойства группы в целом (в нашем случае, AVG ( EMP . EMP _ SAL ) ). Для каждой группы, образуемой во внешнем цикле, оцениваются условия, характеризующие группу в целом. В просмотр внутреннего цикла допускаются только те группы, для которых результатом вычисления условий “группы” было true . За каждым элементом “отобранной” группы сохраняются свойства ее объекта-инварианта.
Как видно даже из этого примера, предикаты раздела WHERE OQL -запросов могут представлять собой произвольно сложное булевское выражение, в котором простые условия связываются логическими операциями AND, OR и NOT. Очевидно, что этот набор операций является избыточным. Тем не менее, в OQL введены две дополнительные логические операции – ANDTHEN и ORELSE . Если X и Y являются логическими выражениями, то при вычислении выражения X ANDTHEN Y выражение Y вычисляется (и определяет общий результат) в том и только в том случае, когда результатом вычисления выражения X является true . Аналогично, при вычислении выражения X ORELSE Y выражение Y вычисляется (и определяет общий результат) в том и только в том случае, когда результатом вычисления выражения X является false . Другими словами, таблицы истинности операций ANDTHEN и ORELSE полностью совпадают с таблицами истинности операций AND и OR соответственно, но предписывается порядок вычислений. Стандарт ODMG 3.0 не обеспечивает подробного обоснования для введения этих операций, однако, по нашему мнению, это как-то связано с желанием остаться в рамках двухзначной логики при возможности наличия неопределенных значений. Вот пример запроса, в предикате которого можно сравнительно осмысленно использовать операцию ANDTHEN .
Пример 2.10. Получить имена служащих и номера их отделов для служащих, работающих в отделах с фондом заработной платы, размер которого превышает 1000000 руб.
SELECT STRUCT (name: E.EMP_NAME, dept: D.DEPT_NO)
FROM EMPLOYEES E,
E.WORKS D
WHERE E.WORKS != nil andthen
D.DEPT_TOTAL_SAL > 1000000.00
38
Кратко затронем тему запросов с соединениями. Должно быть понятно, что введение механизма связей в языки ODL и OQL главным образом связано с желанием отказаться от явных естественных соединений. Тем не менее, может возникнуть потребность в явных соединениях коллекций, объекты или литералы которых связываются по значениям. Вот простой пример.
Пример 2.10. Выбрать всех служащих, у которых имеются однофамильцы.
SELECT DISTINCT E
FROM EMPLOYEES E, EMPLOYEES E1
WHERE E != E1 AND E.EMP_NAME =
E1.EMP_NAME
В результате будет образовано литеральное множество, элементами которого являются объекты типа EMP , для которых в экстенте EMPLOYEES имеется хотя бы один иной (с другим объектным идентификатором) объект, с тем же значением свойства EMP _ NAME . Понятно, что этот запрос и по виду, и по семантике выполнения является в чистом виде SQL -запросом (если заменить конструкцию E != E1 наE.EMP_NO <> E1.EMP_NO ).
Неопределенные значения
Поддержка неопределенных значений является одной из наиболее запутанных проблем современной технологии баз данных. Автору данной статьи неизвестно какое-либо удовлетворительное решение проблемы. ODMG тщательно обходит проблему неопределенных значений и пытается свести ее к проблеме неопределенных идентификаторов объектов.39 Опишем подход ODMG с минимальными комментариями.
Результатом выборки свойства объекта с пустым идентификатором является специальное значение UNDEFINED . В OQL UNDEFINED считается специальным литеральным значением, входящим во множество значений любого литерального или объектного типа.40 Правила обращения со значением UNDEFINED состоят в следующем:
- Результатом операции is _ undefined ( UNDEFINED ) является логическое значение true . Результатом операции is _ defined ( UNDEFINED ) является логическое значение false .
- Если при вычислении предиката раздела WHERE OQL -запроса получается значение UNDEFINED , то оно трактуется таким же образом, если бы результатом было значение false .
- UNDEFINED является допустимым элементом любой явно или неявно конструируемой коллекции.41
- UNDEFINED является допустимым выражением при вычислении агрегатной функции COUNT .42
- Результатом любой другой операции, включающей хотя бы один операнд со значением UNDEFINED , является UNDEFINED . 43
Пример 2.11. Найти номера отделов всех сотрудников.
SELECT E.WORKS.DEPT_NO
FROM EMPLOYEES E
Результатом запроса будет мультимножество литералов, среди которых будет содержаться значение UNDEFINED для всех сотрудников, не прикрепленных к какому-либо отделу.
Пример 2.11. Найти всех сотрудников, прикрепленных к какому-либо отделу.
SELECT E
FROM EMPLOYEES E
WHERE is_defined (E.WORKS.DEPT_NO)
Такой же результат был бы выдан при выполнении запроса
SELECT E
FROM EMPLOYEES E
WHERE E.WORKS != nil
Вызовы методов
В OQL допускается вызов метода объекта с указанием действительных параметров или без их указания (в зависимости от сигнатуры метода объекта, или класса) в любом месте запроса, если тип результата вызова метода соответствует типу ожидаемого результата запроса. Если у метода отсутствуют параметры, то нотация вызова метода в точности совпадает с нотацией выбора атрибута или перехода по связи. Если у метода имеются параметры, то их действительные значения задаются через запятую в круглых скобках. Этот гибкий синтаксис освобождает пользователя от необходимости знать, является ли свойство хранимым (атрибутом) или вычисляемым (методом).44 Однако, если в классе (или интерфейсе) содержатся одноименные атрибут и метод без параметров, то для разрешения конфликта имен в вызове метода должны содержаться круглые скобки.
В примере 2.2a мы уже показывали вариант запроса, содержащего вызов метода. В модели ODMG допускаются методы, вырабатывающие результат в виде сложных объектов или коллекций литеральных значений или объектов. Например, представим себе, что в классе EMP определена операция HIGHER _ PAID , которая для данного объекта-служащего производит множество объектов-служащих того же отдела с большим размером зарплаты. Тогда возможен следующий запрос.
Пример 2.13. Найти названия проектов, в которых участвуют сотрудники отдела 632, получающие зарплату с размером выше среднего.45
SELECT DISTINCT E.HIGHER_PAID.participate_in.PRO_NAME
FROM
EMPLOYEES AS E
WHERE E.EMP_NO = 632
Здесь мы предполагаем, что между классами EMP и PRO имеется связь “многие-к-одному” participates _ in - participants _ of (один сотрудник может принимать участие не более чем в одном проекте, но в любом проекте может участвовать произвольное число сотрудников).
Полиморфизм
Как мы отмечали ранее в этом разделе, в объектной модели ODMG поддерживается семантика включения, т.е. в экстент суперкласса входят объекты экстентов всех его подклассов. Предположим, например, что мы определили класс PROGRAMMERS как наследника класса EMP через EXTENDS . Пусть для программистов меняется семантика метода HIGHER _ PAID (высокооплачиваемым программистом считается тот, кто получает более 30000 руб. в месяц). Тогда в классе PROGRAMMERS этот метод должен быть переопределен (с сохранением сигнатуры).
Понятно, что в соответствии с семантикой включения запрос из прим. 2.13 должен распространяться на всех служащих, включая программистов. Но если текущий объект E является объектом класса PROGRAMMERS , то к нему должен применяться переопределенный вариант метода HIGHER _ PAID . Тем самым, в OQL применятся отложенное связывание объектов и методов.
Еще одна возможность, связанная с полиморфизмом и поддерживающаяся в OQL , состоит в том, что пользователь может явно указать конкретный тип подкласса объектов коллекции, а система будет проверять правильность этого указания во время выполнения запроса. Предположим, что в классе PROGRAMMERS определен дополнительный атрибут favorite _ language , значение которого характеризуют “любимый” язык программирования каждого программиста. Кроме того, пусть известно, что в отделе 632 работают только программисты. Тогда возможен следующий запрос.
Пример 2.14. Получить названия любимых языков программирования сотрудников отдела 632.
SELECT DISTINCT ((PROGRAMMERS)E).favorite_language
FROM
EMPLOYEES AS E
WHERE E.EMP_NO = 632
Если во время выполнения запроса будет обнаружено, что среди служащих отдела 632 имеются не только программисты, система зафиксирует ошибочную ситуацию.
Композиция операций
OQL является полностью функциональным языком. Если не нарушается система типов, то допускается произвольная композируемость операций. Этот подход отличается от подхода языка SQL , в котором правила композиции операций не являются ортогональными46. Наличие полной ортогональности правил композиции в OQL позволяет не ограничивать мощность выражений и облегчить общее понимание языка, сохраняя возможность использования SQL -подобного синтаксиса при формулировке наиболее простых запросов.
Среди операций, которые поддерживаются в OQL и еще не упоминались в этом разделе, содержатся “множественные” операции union , intersect и except для всех видов коллекций; операции с кванторами for all и exists ; операции сортировки и группирования (sort и group by ); агрегатные операции count , sum , min , max и avg . Мы не будем подробно обсуждать эти операции47, но приведем пример достаточно сложного запроса, в котором некоторые из операций используются.
Пример 2.15. Найти название отдела, в котором работают служащие, средняя зарплата которых меньше средней зарплаты служащих любого другого отдела (для простоты предположим, что размер средней зарплаты служащих во всех отделах различается).
Будем строить запрос по шагам с использованием конструкции языка OQL define для вычисления промежуточных результатов.
Шаг 1. Построить множество объектов-служащих, для которых известен номер отдела.
define EMPLOYEES_D ()
AS
SELECT E FROM EMPLOYEES E
WHERE E.WORKS IS NOT nil
Шаг 2. Сгруппировать служащих с известными номерами отделов по номерам отделов и вычислить размер средней зарплаты для каждого отдела.
DEFINE DEPT_AVG_SAL () AS
SELECT DEPT_NO,
AVG_SAL : avg (SELECT
X.E.EMP_SAL FROM PARTITION X )
FROM EMPLOYEES_D () E
GROUP BY DEPT_NO : E.DEPT_NO
Типомрезультатаэтогозапросаявляетсяbag < struct { integer DEPT_NO; decimal AVG_SAL } > . Операция group by расщепляет множество служащих на разделы (partitions ) в соответствии с критерием группирования (номеру отдела, в котором работает служащий). В разделе SELECT для каждого раздела вычисляется размер средней зарплаты сотрудников.
Шаг 3. Отсортировать полученное мультимножество по значениям атрибута AVG _ SAL .
DEFINE SORTED_DEPT_AVG_SAL () AS
SELECT S FROM DEPT_AVG_SAL () AS S
ORDER BY S.AVG_SAL
Типомрезультатаявляетсяlist < struct { integer DEPT_NO; decimal AVG_SAL } > .
Шаг 4. Выбрать значение атрибута DEPT _ NO из элемента списка SORTED _ DEPT _ AVG _ SAL с наименьшим значением AVG _ SAL (этот элемент стоит в списке первым).
FIRST (SORTED_DEPT_AVG_SAL ()).DEPT_NO
Если собрать запрос целиком, то мы получим следующую конструкцию:
FIRST (SELECT DEPT_NO,
AVG_SAL : avg (SELECT X.E.EMP_SAL FROM PARTITION X )
FROM (SELECT E FROM EMPLOYEES E
WHERE E.WORKS IS NOT
nil) AS E
GROUP BY DEPT_NO : E.DEPT_NO
ORDER BY AVG_SAL).DEPT_NO
Заключение к подразделу
В этом подразделе кратко и, по возможности, объективно изложены основные идеи стандарта ODMG , направленные на унификацию технологии объектно-ориентированных баз данных. Субъективная точка зрения автора этой статьи состоит в том, что стандарт ODMG 3.0 обладает рядом недостатков, среди которых следует особо выделить следующие:
- Объектная модель недостаточно обоснована. Возникает ощущение, что в модель стремились поместить свойства реализационных моделей всех коммерческих ООСУБД, существовавших к моменту написания стандарта.48
- Разделение языков определения данных (ODL ), объектных запросов (OCL ) и языков манипулирования (OML ), конечно, отражает стремление разработчиков стандарта к ортогонализации модели, но очень затрудняет ее целостное понимание.
- Язык OQL является простым с концептуальной точки зрения, но очень сложен для использования непрограммистами.
[Назад] [Оглавление] [Вперед]