Анализ текстовых документов для извлечения тематически сгруппированных ключевых терминов
Мария Гринева, Максим Гринев, Дмитрий Лизоркин
Труды Института системного программирования РАН
3. Метод извлечения ключевых терминов
Метод состоит из следующих пяти шагов: 1) извлечение терминов-кандидатов; 2) разрешение лексической многозначности терминов; 3) построение семантического графа; 4) обнаружение сообществ в семантическом графе; 5) выбор подходящих сообществ.
3.1. Извлечение терминов-кандидатов
Целью этого шага является извлечение всех терминов документа и подготовка для каждого термина набора статей Википедии, который потенциально могут описывать его значение.
Мы разбираем исходный документ на лексемы, выделяя все возможные N-граммы. Для каждой N-граммы мы строим ее морфологические вариации. Далее для каждой из вариации производится поиск по всем заголовкам статей Википедии. Таким образом, для каждой N-граммы мы получаем набор статей Википедии, которые могут описывать ее значение.
Построение различных морфологических форм слов позволяет нам расширить поиск по заголовкам статьей Википедии и, таким образом, находить соответствующие статьи для большей порции терминов. Например, слова drinks, drinking и drink могут быть связаны с двумя статьями Википедии: Drink и Drinking.
3.2. Разрешение лексической многозначности терминов
На данном шаге для каждой N-граммы мы должны выбрать наиболее подходящую статью Википедии из набора статей, который был построен для нее на предыдущем шаге.
Многозначность слов – распространенное явление естественного языка. Например, слово «платформа» может означать железнодорожную платформу, или платформу программного обеспечения, а также платформу, как часть обуви.
Правильное значение многозначного слова может быть установлено при помощи контекста, в котором это слово упоминается. Задача разрешения лексической многозначности слова представляет собой автоматический выбор наиболее подходящего значения слова (в нашем случае – наиболее подходящей статьи Википедии) при упоминании его в некотором контексте.
Существует ряд работ по разрешению лексической неоднозначности терминов с использованием Википедии [21, 8, 18, 10, 11]. Для экспериментов, обсуждаемых в данной работе, был реализован метод, предложенный Д. Турдаковым и П. Велиховым в работе [21]. В [21] авторы используют страницы для многозначных терминов и перенаправляющие страницы Википедии. С использованием таких страниц Википедии строится набор возможных значений термина. Далее наиболее подходящее значение выбирается при помощи знаний о семантической близости терминов: для каждого возможного значения термина вычисляется степень его семан-тической близости с контекстом. В итоге выбирается то значение термина, степень семантической близости с контекстом которого было наибольшим.
Распространенной проблемой традиционных методов извлечения ключевых терминов является наличие абсурдных фраз в результате, таких как, например, "using", "electric cars are". Использование Википедии как контролирующего тезауруса позволяет нам избежать данной проблемы: все ключевые термины, полученные в результате работы нашего метода, являются осмысленными фразами.
Результатом работы данного шага является список терминов, в котором каждый термин соотнесен с одной соответствующей статьей Википедии, описывающей его значение.
3.3. Построение семантического графа
На данном шаге по списку терминов, полученном на предыдущем шаге, мы строим семантический граф.
Семантический граф представляет собой взвешенный граф, вершинами которого являются термины документа, наличие ребра между двумя вершинами означает тот факт, что термины семантически связаны между собой, вес ребра является численным значением семантической близости двух терминов, которые соединяет данное ребро.
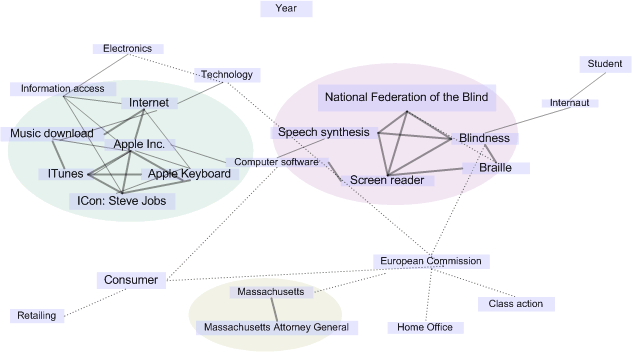
Рис. 1. Пример семантического графа, построенного по новостной статье «Apple to Make ITunes More Accessible For the Blind»
Рис. 1 демонстрирует пример семантического графа, построенного из новостной статьи «Apple to Make ITunes More Accessible For the Blind». В статье говорится о том, что главный прокурор штата Массачусетс и Национальная Федерация Слепых достигли соглашения с корпорацией Apple Inc., следуя которому Apple сделает доступным свой музыкальный Интернет-сервис ITunes для слепых пользователей посредством технологии screen-reading. На рис. 1 можно видеть, что термины, релевантные Apple Inc. и Blindness, образуют два доминантных сообщества, а термины Student, Retailing и Year оказались на периферии и слабо связаны с остальным графом.
Важно отметить тот факт, что термины – ошибки, возникшие при разрешении лексической многозначности терминов, проведенного на втором шаге, оказываются периферийными или даже изолированными вершинами графа, и не примыкают к доминантным сообществам.
3.4. Обнаружение сообществ в семантическом графе
Целью данного шага является автоматическое обнаружение сообществ в построенном семантическом графе. Для решения этой задачи мы применяем алгоритм Гирвана-Ньюмана. В результате работы алгоритма исходный граф разбивается на подграфы, которые представляют собой тематические сообщества терминов.
Для оценки качества разбиения некоторого графа на сообщества авторы [15] предложили использовать меру модулярности (modularity) графа. Модулярность графа является свойством графа и некоторого его разбиения на подграфы. Она является мерой того, насколько данное разбиение качественно в том смысле, что существует много ребер, лежащих внутри сообществ, и мало ребер, лежащих вне сообществ (соединяющих сообщества между собой). На практике значение модулярности, лежащее в диапазоне от 0.3 до 0.7, означает, что сеть имеет вполне различимую структуру с сообществами, и применение алгоритма обнаружения сообществ имеет смысл.
Мы отметили, что семантические графы, построенные из текстовых документов (таких как, например, новостная статья, или научная статья), имеют значение модулярности от 0.3 до 0.5.
3.5. Выбор подходящих сообществ
На данном шаге из всех сообществ необходимо выбрать те, которые содержат ключевые термины. Мы ранжируем все сообщества таким образом, чтобы сообщества с высокими рангами содержали важные термины (ключевые термины), а сообщества с низкими рангами – незначимые термины, а также ошибки разрешения лексической многозначности терминов, которые могут возникнуть на втором шаге работы нашего метода.
Ранжирование основано на использовании плотности и информативности сообщества. Плотностью сообщества является сумма весов ребер, соединяющих вершины этого сообщества.
Экспериментируя с традиционными подходами, мы обнаружили, что использование меры tf.idf терминов помогает улучшить ранжирование сообществ. Tf.idf дает большие коэффициенты терминам, соответствующим именованным сущностям (например, Apple Inc., Steve Jobs, Braille), а терминам, соответствующим общим понятиям (таким как, например, Consumer, Year, Student) дает низкие коэффициенты. Мы считаем tf.idf для терминов, используя Википедию так, как описано в работе [8]. Под информативностью сообщества мы понимаем сумму tf.idf-терминов, входящих в это сообщество, деленную на количество терминов сообщества.
В итоге, мы считаем ранг сообщества, как плотность сообщества, умноженная на его информативность, и сортирует сообщества по убыванию их рангов.
Приложение, использующее наш метод для извлечения ключевых слов, может использовать любое количество сообществ с наивысшими рангами, однако, на практике имеет смысл использовать 1-3 сообщества с наивысшими рангами.
4. Экспериментальная оценка
В этом разделе мы обсудим экспериментальные оценки предложенного метода. Поскольку не существуют стандартных бенчмарков для измерения качества извлеченных из текстов ключевых терминов, мы провели эксперименты с привлечением ручного труда, то есть полнота и точность извлеченных ключевых слов оценивались людьми – участниками эксперимента.
Мы собрали 30 блог-постов из следующих блогов технической тематики: «Geeking with Greg», автор Грег Линден, DBMS2, автор Курт Монаш, Stanford Infoblog, авторы – члены группы Stanford Infolab. В эксперименте приняли участие пять человек из отдела информационных систем ИСП РАН. Каждый участник должен был прочитать каждый блог-пост и выбрать в нем от 5 до 10 ключевых терминов. Каждый ключевой термин должен присутствовать в блог-посте, и для него должно быть найдено соответствующая статья в Википедии. Участники также были проинструктированы выбирать ключевые слова так, чтобы они покрывали все основные темы блог-поста. В итоге для каждого блог-поста мы выбрали такие ключевые термины, которые были выделены, по крайней мере, двумя участниками эксперимента. Названия перенаправляющих статей Википедии и название статей, на которые идет перенаправление, по сути, представляют собой синонимы, и мы в нашем эксперименте считали их одним термином.
Метод, представленный в данной статье, был реализован по следующим архитектурным принципам. Для достижения лучшей производительности мы не вычисляли семантическую близость всех пар терминов Википедии заранее. Данные, необходимые для подсчета семантической близости терминов на лету, а именно, заголовки статей Википедии, информация о ссылках между статьями, статистическая информация о терминах были загружены в оперативную память. В итоге полученная база знаний занимала в оперативной памяти 4.5 Гбайта. База знаний была установлена на выделенном компьютере с размером оперативной памяти, равным 8 Гбайт. Клиентское приложение работали с базой знаний посредством вызовов удаленных процедур.
4.1. Оценка полноты выделенных ключевых терминов
Под полнотой мы понимаем долю ключевых слов, выделенных вручную, которые так же были выделены автоматически нашим методом:
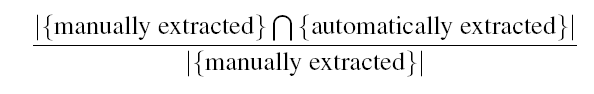
где под {manually extracted} мы понимаем множество ключевых слов, извлеченных вручную участниками эксперимента для некоторого документа, под {automatically extracted} мы понимаем множество всех ключевых терминов, автоматически извлеченных нашим методом для того же документа. Знаком |S| мы обозначаем мощность множества S, то есть количество терминов в множестве S.
Для 30 блог-постов мы имеем 180 ключевых терминов, выделенных участниками эксперимента вручную, 297 – выделенных автоматически, 127 вручную выделенных ключевых слов были также выделены автоматически. Таким образом, полнота равно 68%.
4.2. Оценка точности выделенных ключевых терминов
Мы оцениваем точность, используя ту же методологию, которой пользовались для оценки полноты. Под точностью мы понимаем долю тех слов, автоматически выделенных нашим методом, которые также были выделены вручную участниками эксперимента:
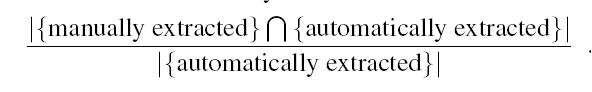
Итого, следуя показателям нашей тестовой коллекции, точность равна 41%.
4.3. Пересмотр оценки полноты и точности
С целью более качественной оценки работы метода мы также пересмотрели наши оценки полноты и точности. Важной особенностью нашего метода является факт, что он в среднем выделяет больше ключевых слов, чем человек. Более точно, наш метод обычно извлекает больше ключевых терминов, релевантных одной теме. Например, рассмотрим рис. 1. Для темы, относящейся к Apple Inc., наш метод выделяет термины: Internet, Information access, Music download, Apple Inc., ITunes, Apple Keyboard и Steve Jobs, в то время как человек обычно выделяет меньше терминов и склонен выделять имена и названия: Music download, Apple Inc., ITunes и Steve Jobs. Это означает, что, иногда метод извлекает ключевые термины с лучшим покрытием основных тем документа, чем это делает человек. Этот факт побудил нас пересмотреть оценку полноты и точности работы нашего метода.
Каждый участник эксперимента был проинструктирован пересмотреть ключевые термины, которые он сам выделил следующим образом. Для каждого блог-поста он должен был изучить ключевые термины, выделенные автоматически, и, по возможности, расширить свой набор ключевых слов, то есть дополнить его теми терминами, которые, по его мнению, относятся к главным темам документа, но не были выделены на первом этапе.
После такого пересмотра, мы получили 213 ключевых слов, выделенных вручную (вместо 180), таким образом, участники эксперимента добавили 33 новых ключевых термина, что означает, что наше предположение имело смысл, и такой пересмотр важен для полноценной оценки работы метода. В итоге, полнота равна 73% и точность – 52%.
5. Заключение
Мы предложили новый метод для извлечения ключевых терминов из текстовых документов. Одним из преимуществ нашего метода является отсутствие необходимости в предварительном обучении, поскольку метод работает над базой знаний, построенной из Википедии. Важной особенностью нашего метода является форма, в которой он выдает результат: ключевые термины, полученные из документа, сгруппированы по темам этого документа. Сгруппированные по темам ключевые термины могут значительно облегчить дальнейшую категоризацию данного документа и выведение его общей темы.
Эксперименты, проведенные с использованием ручного труда, показали, что наш метод позволяет извлекать ключевые термины с точностью и полнотой, сравнимой с теми, что дают современные существующие методы.
Мы отметили, что наш метод может быть с успехом применен для очистки сложных составных документов от неважной информации, и выделения главной темы в них. Это означает, что его интересно было бы применить для выделения ключевых терминов из Web-страниц, которые, как правило, загружены второстепенной информацией, например, меню, навигационные элементы, реклама. Это направление дальнейшей работы.