Транзакционные параллельные СУБД: новая волна
Сергей Кузнецов
3.2 DORA: почти "shared-nothing" в среде "shared-everything"
Подход H-Store с отказом от совместного использования ресурсов лишен компромиссов: в этой архитектуре любой аппаратно поддерживаемый поток управления рассматривается как отдельный узел системы со своими собственными ресурсами. В этой бескомпромиссности кроется много плюсов: в частности, параллельная СУБД строится в виде набора полностью идентичных компонентов, каждый из которых обладает единственной активностью. Но, с другой стороны, при этом приносятся в жертву аппаратные возможности многоядерных процессоров, позволяющие на физическом уровне использовать все ресурсы компьютера в потоках управления всех ядер.В связи с этим мне кажется очень поучительным проект DORA [15], в котором разрабатывается архитектура СУБД, обладающая свойствами shared-nothing на логическом уровне, но использующая аппаратные возможности shared-everything на физическом уровне. В качестве экспериментальной аппаратной платформы в DORA использовался компьютер Sun T5220 "Niagara II". В микропроцессоре Niagara II имеется 8 ядер, в каждом из которых на аппаратном уровне поддерживается 8 потоков управления, т.е. на уровне операционной системы в компьютере имеется 64 процессора, каждому из которых доступны все остальные ресурсы системы.
Исследование [15] выполнялось не в том же контексте, что H-Store; в DORA основной упор делается на сокращение взаимодействий с центральным менеджером блокировок. Поэтому в большей части этого раздела я опишу основные идеи DORA в том виде, как они подаются авторами [15]. Однако, с моей точки зрения, между проектами H-Store и DORA имеется более глубокая связь, чем это отмечается авторами, например, [14] и [15], и на этой связи я остановлюсь в заключение подраздела.
3.2.1 Проблемы блокировок в традиционных многопоточных СУБД
Авторы [15] использовали в своем проекте транзакционную систему управления базами данных Shore-NT [33], являющуюся модифицированным вариантом системы Shore [30] с многопотоковым ядром. В Shore-NT (как и в Shore) поддерживаются все основные возможности традиционных транзакционных СУБД: ACID-транзакции с обеспечением полной изоляции на основе иерархических блокировок, управление буферным пулом, индексы на основе B-деревьев, классическое управление журнализацией и восстановлением баз данных. Каждой транзакции назначается отдельный поток управления. Как утверждается в [15], выбор пал на Shore-NT, поскольку среди всех реализаций СУБД с открытыми исходными текстами эта система лучше всего масштабируется при росте числа ядер в процессоре [34]. Однако я думаю, что не менее важную роль при этом выборе сыграло и то, что в разработке Shore-NT активно участвовали именно участники проекта DORA.С использованием Shore-NT были выполнены эксперименты, полностью подтвердившие выводы авторов [29] (которые экспериментировали с однопотоковым вариантом Shore) об отрицательном влиянии традиционных блокировок на производительность транзакционных СУБД. При традиционном назначении каждой транзакции отдельного потока управления в них приходится использовать большое число критических участков для координации доступа к совместно используемым ресурсам. Для организации критических участков в многоядерных процессорах приходится использовать защелки (latch), основанные на применении спинлоков [35], что в ряде случаев вынуждает аппаратный поток управления "зависать" при входе в критический участок.
В Shore-NT (как и большинстве других многопотоковых систем с использованием общих ресурсов) каждой логической блокировке соответствует структура данных (описатель блокировки), содержащая режим блокировки, указатель на списки удовлетворенных или ожидающих удовлетворения запросов блокировки, а также защелку. Когда некоторая транзакция пытается получить некоторую блокировку, менеджер блокировок сначала проверяет, что для этой транзакции уже удерживаются блокировки намерений для объектов более высокого уровня, и в случае потребности устанавливает требуемые блокировки (как уже упоминалось, в Shore-NT используется иерархическая схема блокировок, подробности об этой схеме см., например, в [36]). Если оказывается, что запрашиваемая блокировка транзакции не требуется, поскольку для нее уже удерживается подходящая блокировка более высокого уровня, текущий запрос сразу удовлетворяется.
В противном случае менеджер блокировок через хэш-таблицу ищет описатель требуемой блокировки (образуя его в случае отсутствия). Описатель блокировки "защелкивается", и запрос блокировки добавляется к списку запросов. Если запрос блокировки можно удовлетворить (требуемый объект не заблокирован или текущий режим его блокировки совместим с режимом запрашиваемой блокировки), то запрос помечается как удовлетворенный, защелка освобождается, и продолжается выполнение транзакции. Иначе запрос блокировки не удовлетворяется и транзакция блокируется (защелка описателя блокировки при этом освобождается).
В каждой транзакции поддерживается список полученных ей блокировок. При завершении транзакции они освобождаются в хронологическом порядке. Для освобождения очередной блокировки менеджер блокировок защелкивает ее описатель, удаляет из списка запрос освобождаемой блокировки, устанавливает новый режим блокировки и удовлетворяет все отложенные запросы блокировки, которые можно удовлетворить (активизируя соответствующие транзакции). После этого защелка описателя блокировки освобождается.
По мере роста числа активных транзакций (т.е. числа доступных потоков управления, которое, очевидно, коррелирует с числом ядер процессора) растет объем работы, требуемой для удовлетворения запросов на получение или освобождение блокировок, поскольку удлиняются списки запросов блокировок. Дополнительные обходы списков блокировок нужны для выявления синхронизационных тупиков (а все это увеличивает размер критических участков). Возникающие последствия губительны для производительности системы.
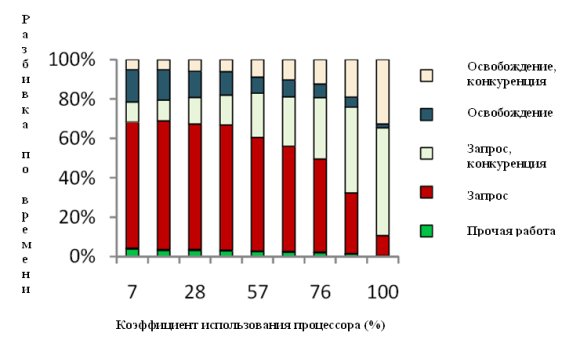
Рис. 7. Разбивка по времени работы менеджера блокировок Shore-MT при выполнении тестового набора TPC-B.
На рис. 7 показана разбивка по времени работы менеджера блокировок Shore-NT при возрастании коэффициента загрузки процессора. Как видно, при слабой загрузке системы 85% времени менеджер блокировок выполняет полезную работу. Однако по мере роста загруженности процессора растут расходы на обслуживание конкуренции потоков управления. При стопроцентной загрузке процессора 85% времени работы менеджера блокировок уходит на выполнение операций над защелками.
3.2.2 Архитектура DORA
Основные идеи DORA (Data-ORiented Architecture) состоят в следующем:- потоки управления связываются не с транзакциями, а с отдельными частями базы данных;
- система распределяет работу каждой транзакции по потокам управления в соответствии с тем, к каким данным обращается транзакция;
- при обработке запросов система по мере возможности избегает взаимодействий с централизованным менеджером блокировок.
Потоки управления (исполнители), в которых выполняются операции транзакций, связываются с данными за счет установки для каждой таблицы базы данных правила маршрутизации. Правило маршрутизации разделяет соответствующую таблицу на наборы записей (фактически, разделы) так, что каждая запись относится к одному и только одному набору. Каждый набор записей приписывается одному исполнителю, и одному исполнителю может быть приписано несколько наборов записей одной таблицы. Физический доступ к данным производится через общесистемный буферный пул, и правила маршрутизации не вызывают какого-либо физического разделения или перемещения данных. Правила маршрутизации поддерживаются во время работы системы менеджером ресурсов DORA и периодически им обновляются для балансировки нагрузки. Столбцы таблицы, используемые в соответствующем правиле маршрутизации, называются полями маршрутизации.
Для распределения работы каждой транзакции по исполнителям в DORA для каждой транзакции образуется граф потока транзакции, в котором фиксируются зависимости действий транзакции и их связь с наборами записей. Действие – это часть транзакции, заключающаяся в обращении к одной записи или небольшому набору записей одной таблицы. С каждым действием связывается идентификатор действия, который может содержать значения полей маршрутизации или быть пустым. Последовательные действия с одним идентификатором можно слить.
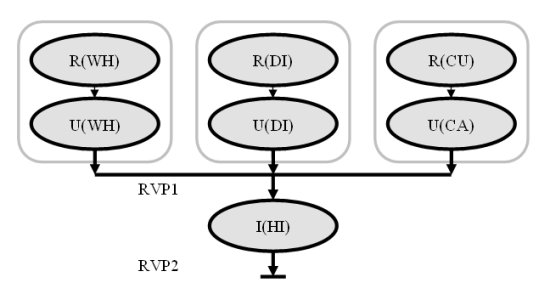
Рис. 8. Граф потока транзакции Payment из тестового набора TPC-C.
На рис. 8 показан граф потока транзакции Payment из тестового набора TPC-C. В соответствии со спецификацией TPC-C [37], транзакция Payment изменяет остаток на счете клиента (изменяет некоторую строку таблицы Customer), отражает данные о платеже в статистике продаж соответствующих склада и округа (изменяет по одной строке в таблицах Warehouse и District) и сохраняет данные о платеже в журнале истории (вставляет одну строку в таблицу History). Первичными ключами таблиц Warehouse, District и Customer являются W_ID, (D_W_ID, D_ID) и (С_W_ID, С_D_ID, С_ID) соответственно, и если полем маршрутизации для всех трех таблиц является идентификатор склада, то этот атрибут и становится идентификатором действий в группе операций в верхней части рис. 8. Поскольку пары действий чтения и изменения строки для каждой из таблиц Warehouse, District и Customer обладают одинаковыми идентификаторами, их можно слить.
Пары действий над таблицами складов, округов и клиентов, вообще говоря, можно выполнять параллельно, поскольку между ними нет зависимостей по данным. Последнее действие транзакции Payment (вставку кортежа в таблицу History) нельзя выполнять раньше, чем завершатся все три объединенные предыдущие действия. Для управления распределенными транзакциями и передачи данных между действиями, зависимыми по данным, в DORA используются разделяемые между потоками управления объекты, называемые точками рандеву (rendezvous point) (RVP). Если между действиями транзакции имеются зависимости по данным, между ними помещается RVP.
RVP разделяют транзакции на фазы: система не может одновременно выполнять действия, относящиеся к разным фазам. В каждом объекте-RVP имеется счетчик, изначально содержащий число действий, которые должны "доложить" о своем завершении. Каждый исполнитель, завершая выполнение некоторого действия, уменьшает на единицу значение счетчика соответствующей RVP. Когда значение счетчика становится нулевым, начинается новая фаза транзакции: исполнитель, обнуливший счетчик RVP, ставит действия следующей фазы в очереди соответствующим исполнителям. Исполнитель, обнуливший счетчик последней RVP в графе потока транзакции, запрашивает ее фиксацию. Аварийно завершить транзакцию и инициировать ее откат может любой исполнитель.
Итак, к одному исполнителю направляются все действия, которые должны выполняться над одним и тем же набором записей. Исполнитель отвечает за изоляцию и упорядоченность конфликтующих действий. В каждом исполнителе поддерживаются три структуры данных: очередь поступающих действий, очередь завершенных действий и локальная таблица блокировок. Действия выполняются в том порядке, в котором они поступают во входную очередь. Для устранения конфликтов между действиями в исполнителях используются локальные таблицы блокировок. В качестве объектов блокировки применяются идентификаторы действий, и блокировки могут устанавливаться только в совместном и монопольном режимах. Каждое действие, получившее требуемую локальную блокировку, продолжает выполнение без обращения к централизованному менеджеру блокировок.
Локальные блокировки, полученные каждым действием транзакции, удерживаются в соответствующих исполнителях до фиксации или аварийного завершения этой транзакции. В заключительной RVP тразакция сначала дожидается ответа от основного менеджера управления данными о заключительной фиксации или аварийном завершении транзакции. После этого все действия этой транзакции ставятся в очереди завершенных действий своих исполнителей (откат транзакции в DORA производит основная система). При обработке этих действий исполнители освобождают соответствующие локальные блокировки и удовлетворяют запросы блокировок ожидающих действий.
Одной из проблем DORA состоит в том, что оказывается невозможно обойтись локальными блокировками идентификаторов действий при выполнении операций удаления и вставки строк таблиц. Действительно, возможна ситуация, когда транзакция T1 удаляет запись в некоторой странице, а транзакция T2, действие которой выполняется в другом исполнителе, вставляет на ее место свою запись до завершения транзакции T1. Тогда, если транзакция T1 завершится аварийным образом, ее нельзя будет откатить, поскольку слот удаленной записи уже занят.
Для устранения возможности такого конфликта перед выполнением операций удаления и вставки записей исполнители блокируют соответствующие им идентификаторы (т.е. номер страницы и номер слота внутри страницы). Утверждается, что потребность в таких блокировках возникает сравнительно редко, но беда в том, что эта проблема совсем не техническая – это обратная сторона того, что данные разделяются между исполнителями на логическом уровне. Получается, что без централизованной синхронизации вообще нельзя вставлять в таблицы новые строки, поскольку эти операции могут выполняться параллельно разными исполнителями, и должна обеспечиваться координация распределения памяти. В DORA имеются и другие проблемы, в частности, проблема выявления тупиковых ситуаций с участием локальных и централизованных блокировок, но я не буду на них останавливаться, поскольку, на мой взгляд, эти вопросы в [15] проработаны недостаточно глубоко.
DORA реализована поверх Shore-NT с минимальными изменениями базовой системы. В частности, были блокированы средства Shore-NT собственного управления транзакциями. Транзакции программировались в виде заранее компилируемых хранимых процедур. При тестировании системы на различных тестовых наборов было установлено, что выигрыш в производительности DORA по сравнению с базовой системой достигает 4,8 раз. При неполной загрузке системы за счет внутреннего параллелизма транзакций удается добиться сокращения времени ответа на 60%.
3.2.3 DORA, H-Store и компромиссы
Одной из наиболее серьезных проблем транзакционных параллельных СУБД без использования общих ресурсов является балансировка нагрузки. Чтобы сбалансировать нагрузку, требуется изменить разделение и/или репликацию базы данных. Фактически, нужно переслать часть записей одной или нескольких таблиц из одного раздела в другой. Пересылка данных вызывает ощутимые накладные расходы (даже если вся база данных поддерживается в основной памяти), и в каждом из изменяющихся разделов необходимо должным образом изменить существующие индексы. Во время выполнения этих операций трудно продолжать поддерживать выполнение запросов, адресуемых к данным изменяемых разделов.В DORA физическая пересылка данных не требуется. Не требуется и массовое преобразование индексов, поскольку индексы поддерживаются для таблицы целиком. Менеджер ресурсов, выявив потребность в расширении раздела одного исполнителя (E1) за счет сокращения раздела другого исполнителя (E2), изменяет правило маршрутизации для данной таблицы и формирует служебную транзакцию из двух действий, разделенных RVP. Первое действие ставится в очередь входных действий E2 и приводит к тому, что E2 дожидается, пока не закончатся все транзакции, в обработке которых он участвует, принимая при этом для обработки новые действия, посылаемые в соответствии с новым правилом маршрутизации. После завершения всех действий, направленных ему в соответствии со старым правилом маршрутизации, E2 ставит в очередь E1 действие, позволяющее этому исполнителю обрабатывать действия, которые направляются ему в соответствии с новым правилом маршрутизации. (Должен признаться, что эта процедура придумана мной, поскольку в [15] она описана невразумительно. – С.К.)
Вторая проблема, с которой приходится сталкиваться системам, не использующих общих ресурсов, возникает при обработке запросов, условие выборки которых не позволяет выявить один или несколько (немного) разделов, содержащих требуемые данные. В таком случае соответствующее действие должно направляться всем исполнителям, лишь немногим из которых удастся найти то, что требуется в запросе. В DORA для выполнения таких запросов можно воспользоваться общим для таблицы "вторичным" индексом, который может помочь направить действия требуемым исполнителям. (На самом деле, с этими "общими" индексами в перспективе не все понятно. Пока DORA живет поверх Shore-NT, поддержка работы с индексами происходит "в другом мире". Но если пытаться продумать полную архитектуру с назначением потоков управления логическим разделам данных, то в ней должно найтись место и работе с индексами, а как это делать – непонятно. – С.К.)
Несмотря на наличие многих неясностей, основная идея DORA – при наличии в системе физически общих ресурсов производить разделение данных не на физическом, а на логическом уровне – кажется мне очень привлекательной. Прототип DORA рассчитан на традиционную работу с дисками, в нем поддерживаются общая система буферов и журнализация (на уровне Shore-NT) и поэтому:
- можно спокойно делить данные на логическом уровне с точностью до кортежа (все буферные страницы доступны всем потокам управления);
- в нем удается обойтись без двухфазного протокола фиксации транзакций;
- и он плохо согласуется с общими идеями H-Store.
Однако мне кажется, что возможен компромисс между архитектурами H-Store и DORA внутри одного многоядерного компьютера для поддержки баз данных в основной памяти без журнализации изменений. Для этого нужно добиться полного отсутствия потребности в централизованных блокировках. Пусть, например, каждая таблица хранится в основной памяти на основе некоторого B-дерева и кластеризуется в соответствии с его ключом (возможно, составным). Все потоки управления работают с общей виртуальной памятью, накрывающей все базу данных целиком, но каждый исполнитель получает для выполнения фрагменты транзакций, которым требуются только данные поддеревьев, приписанных к этому исполнителю. Другими словами, "верхушка" B-дерева каждой таблицы используется координатором транзакций в качестве "правила маршрутизации", а соответствующие поддеревья (определяемые диапазонами значений ключей) используются в исполнителях для доступа к кортежам. Если еще приписать каждому координатору некоторое число свободных страниц основной памяти (для обеспечения возможности автономного расширения таблиц), то при выполнении фрагментов транзакций им никогда не потребуется централизованная синхронизация.
Балансировать нагрузку в этом случае можно будет путем перераспределения поддеревьев между исполнителями, работающими с "соседними" поддеревьями. Фактически, можно легко потребовать от любого исполнителя отдать некоторую "левую" часть своего поддерева некоторой таблицы своему соседу "слева" или "правую" часть своего поддерева некоторой таблицы своему соседу "справа". По-моему, здесь сработает почти та же процедура, которая используется для балансировки нагрузки в DORA. И не потребуется никакого физического копирования данных и/или перестройки индексов, поскольку реально все данные остаются на месте.
Реплицировать, по всей видимости, придется целиком всю базу данных, поддерживаемую многоядерным компьютером. Если считать, что репликация производится для обеспечения долговечности данных и восстановления системы после отказов узлов, то трудно представить себе такой отказ, при котором перестали бы работать несколько ядер процессора, а остальные сохранили работоспособность.
Для управления прохождением транзакций в такой гибридной архитектуре можно было бы использовать любой вариант, обсуждаемый разработчиками H-Store. В зависимости от этого понадобится или не понадобится двухфазная фиксация транзакций.
Так что мне представляется, что будущее поколение ACID-транзакционных систем будет опираться на две основные параллельные архитектуры одноузловую и многоузловую. Одноузловая архитектура предполагает наличие мощного многоядерного компьютера и использование энергонезависимой внешней памяти, в которой, в частности, должен поддерживаться журнал повторного выполнения транзакций. И в этом направлении хороший фундамент закладывает DORA. Но нужно учитывать, что для достижения высокой производительности в такой архитектуре потребуется мощная параллельная система ввода-вывода, стоимость которой, вполне вероятно, будет определять стоимость системы в целом (В [15] эксперименты выполнялись с использованием файловой системы в основной памяти именно из-за отсутствия у авторов такой дорогостоящей дисковой подсистемы.)
Многоузловая архитектура строится на основе достаточно большого числа, вообще говоря, недорогих компьютеров, связанных сетью. Базы данных хранятся только в основной памяти, для обеспечения отказоустойчивости (и, следовательно, долговечности данных) используется репликация. В этом направлении хорошей основой является H-Store (и VoltDB), хотя мне кажется, что следовало бы учесть отмеченные выше возможности использования физически общих ресурсах в многоядерных узлах подобных систем.
В заключение этого раздела замечу, что, к сожалению, эти две архитектуры являются взаимоисключающими. Трудно представить компанию, которая хорошо потратилась на приобретение мощного многоядерного сервера с дорогой дисковой подсистемой, а потом решается отказаться от использования дисков и перейти к использованию многоузловой архитектуры. Трудно представить себе и ситуацию, когда сначала был выбран подход с использованием дешевых кластерных архитектур почти без дисков, а потом вдруг покупается отдельный дорогой сервер, и компания переходит к использованию одноузловой архитектуры. Так что, скорее всего, будет продолжать существовать и направление shared disks, свойственное, например, Oracle, поскольку оно позволяет достаточно эффективно использовать кластеры, построенные с использованием мощных дисковых серверов, которые до этого использовались автономно.