Рационализация согласованности в "облаках": не платите за то, что вам не требуется
Тим Краска, Мартин Хеншель, Густаво Алонсо, Дональд Коссман
Перевод: Сергей Кузнецов
6. Реализация
В этом разделе описывается реализация рационализации согласованности поверх Simple Storage Service (S3) компании Amazon. Реализация основана на архитектуре и протоколах, представленных в [7]. В системе, описанной в [7], уже обеспечиваются разные уровни согласованности поверх Amazon S3, и имеется коммерческий вариант этой системы под названием Sausalito [1]. В конце раздела также приводятся краткие соображения относительно возможности реализации рационализации согласованности на других платформах, таких как PNUTS компании Yahoo.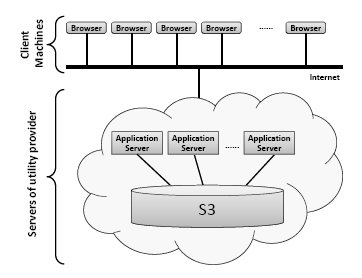
Рис. 1. Архитектура
6.1. Архитектура
На рис. 1 показана общая архитектура, которую мы позаимствовали из [7, 1]. Клиенты подключаются через Internet к одному из серверов приложений. Серверы приложений работают в "облачной" среде поверх службы виртуальных машин Amazon Elastic Computing Cloud (EC2). Кроме того, в этой архитектуре в одной системе объединяются серверы баз данных и приложений, а для постоянного хранения данных используется Amazon Simple Storage Service. Следовательно, страницы данных хранятся в S3, и данные выбираются прямо из сервера приложений аналогично тому, как если бы имелась база данных с общими дисками. Чтобы координировать записи в S3, на каждом сервере приложений поддерживает набор протоколов. Протоколы, представленные в [7], разработаны в многоуровневом стиле, и на каждом уровне повышается уровень согласованности. В качестве индексной структуры используется B-дерево, которое также сохраняется в S3.Мы использовали протоколы, описанные в [7], и построили над ними протоколы для сессионной согласованности и сериализуемости. Кроме того, мы усовершенствовали механизм журнализации, введя средства логической журнализации. Чтобы обеспечить гарантии адаптивной согласованности, мы реализовали управление необходимыми метаданными, политики и компонент, собирающий и обрабатывающий требуемую темпоральную статистику.
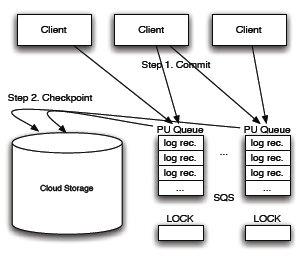
Рис. 2. Базовый протокол
6.2. Реализация протоколов
Основная идея, направленная на достижение более высокого уровня согласованности поверх S3, состоит во временной буферизации обновлений страниц в очередях, показанных на шаге 1 на рис. 2. Очереди, используемые на первом шаге, называются очередями отложенных обновлений (pending update queue, PU-очередь). По истечении некоторого интервала времени один из серверов монопольным образом сливает обновления, буферизованные в PU-очереди, с соответствующей страницей S3, предварительно запрашивая для этой очереди блокировку. Это называется операцией контрольной точки (checkpointing, шаг 2 на рис. 2).6.2.1. Сессионная согласованность
В [7] уже обсуждался протокол, обеспечивающий монотонность по чтению собственных записей (read-your-writes monotonicity). Идея состоит в том, чтобы для каждой страницы, которую сервер в прошлом кэшировал, сохранялась временная метка последней фиксации. Если сервер получает от S3 старую версию страницы (старше версии, которую сервер видел ранее), он выявляет это и читает страницу из S3 заново.Сессионную согласованность обеспечивает перенаправление в течение сессии всех запросов от одного клиента к одному и тому же серверу. В нашей реализации такая маршрутизация производится на основе использования идентификаторов сессий и соответствующей переадресации запроса.
До постановки сообщений в очереди в них включаются векторные часы (vector clocks), которые проверяются вместе с ограничениями целостности во время выполнения операции контрольной точки для выявления и, при необходимости, устранения конфликтов.
6.2.2. Сериализуемость
Для обеспечения сериализуемости, требуемой для данных категории A, мы реализовали двухфазный протокол блокировок (two-phase locking protocol, 2PL). 2PL особенно устойчив к высокой частоте возникновения конфликтов и поэтому хорошо подходит в ситуациях, в которых конфликты ожидаются. Чтобы обеспечить права монопольного доступа, требуемые 2PL, мы реализовали службу блокировок. Чтобы всегда видеть наиболее последнее по времени состояние записей, мы были вынуждены реализовать усовершенствованную службу очередей, обеспечивающую более высокий уровень гарантий, чем Amazon Simple Queue Service. В частности, любое сообщение в любое время можно изъять из очереди, и идентификаторы сообщений монотонно возрастают.Возрастание значений идентификаторов в нашей службе очередей позволило нам упростить протокол монотонности, представленный в [7]. Для гарантирования монотонности достаточно сохранить в странице только изменения, соответствующие сообщению с наибольшим идентификатором. Если система считывает в S3 страницу с меньшим идентификатором, мы знаем, что эта страница нуждается в обновлении. Чтобы привести страницу в актуальное состояние, из очереди выбираются все сообщения, и применяются только сообщения с идентификаторами, большими идентификатора страницы.
Поскольку в этой статье мы фокусируемся на переключении протоколов согласованности во время выполнения, мы не будем больше говорить о реализациях 2PL, монотонности и усовершенствованных служб. Больше информации можно найти в [6].
6.3. Логическая журнализация
Чтобы обеспечить более высокий уровень параллелизма без порождения несогласованности, мы реализовали логическую журнализацию. Сообщение логического журнала содержит идентификатор модифицированной записи и код операции Op, выполненной над этой записью. Чтобы получить новое значение записи (например, при выполнении операции контрольной точки), операция Op из PU-очереди применяется к элементу данных.В протоколах, представленных в [7], используется физическая журнализация. Логические обновления устойчивы по отношению к параллельно выполняемым обновлениям, если эти операции являются коммутационными. Другими словами, никакое обновление не потеряется из-за перезаписывания, и независимо от порядка выполнения будет виден эффект всех обновлений. Однако выполнение некоммутационных операций по-прежнему может привести к несогласованности. Чтобы избежать проблем с использованием разных классов коммутационных операций (например, умножения), мы ограничились в своей реализации сложением и вычитанием. Логическая журнализация работает только для числовых значений. Для нечисловых значений (например, строк) логическая журнализация ведет себя, как физическая журнализация (т.е. для строк выигрывает последнее обновление). В нашем подходе рационализации согласованности поддерживаются оба вида значений (см. разд. 5).
6.4. Метаданные
Для каждой коллекции в нашей системе сохраняются метаданные о ее типе. Эта информация наряду с самой коллекцией сохраняется в S3. Зная коллекцию, к которой относится запись, система устанавливает, какие гарантии согласованности требуется обеспечить. Если запись относится к категории A, то система знает, что для этого элемента данных должна применяться строгая согласованность. Если элемент же данных относится к категории C, то система работает с более низким уровнем гарантий. Для этих двух категорий данных (т.е. A и C) операции проверки типа оказывается достаточно для принятия решения о выборе протокола поддержки согласованности. Для данных категории B в метаданных содержится дополнительная информация: имя политики и дополнительные параметры для нее.6.5. Компонент статистики и политики
Компонент статистики отвечает за сбор статистики во время выполнения. Статистика собирается локально. На основе этой локальной информации компонент судит о глобальном состоянии (разд. 5). Используя эти суждения, одиночный сервер может принять решение об использовании того или иного протокола (т.е. протоколов сессионной согласованности или сериализуемости). Более строгая согласованность обеспечивается только в тех случаях, когда все серверы принимают решение об использовании согласованности категории A. Таким образом, если размер окна достаточно велик, и все запросы равномерно распределены по серверам, для принятия пригодных решений не требуется какой-либо центральный сервер. Однако консолизация статистики и периодическая веерная рассылка информации о принятых решениях могут сделать систему более устойчивой. В будущем мы планируем использовать эти приемы.Для вероятностных политик требуются разные виды статистических данных. Общая политика обрабатывает записи, для которых маловероятны параллельные обновления на разных серверах с гарантиями уровня C. Поэтому для этой политики требуется информация о частоте обновлений, и для нее наиболее интересны редко обновляемые элементы данных. С другой стороны, для Динамической политики особенно интересны часто обновляемые элементы данных. Эта политика допускает частые параллельные обновления с гарантиями уровня C, пока вероятность достижения порогового значения не станет слишком высокой.
Для обеих этих политик мы сохраняем статистическую информацию прямо при записи. Для Общей политики мы сокращаем размер области памяти, требуемой для хранения статистики, за счет простой аппроксимации. Если нашей целью является достижение доли конфликтов менее 1%, то моделирование с использованием соотношения (3) из п 5.1.1 показывает, что интенсивность входного потока должна быть меньше, чем 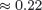 , независимо от числа серверов. Если показатель скольжения окна равен δ , то уровень сессионной согласованности можно использовать при среднем числе обновлений в течение интервала кэширования, меньшем 0.22×δ. Мы используем это свойство для сокращения числа разрядов, требуемых для хранения значения для одного кадра, и выделяем специальное значение для числа обновлений, большего того, которое помещается в выделенное число разрядов.
, независимо от числа серверов. Если показатель скольжения окна равен δ , то уровень сессионной согласованности можно использовать при среднем числе обновлений в течение интервала кэширования, меньшем 0.22×δ. Мы используем это свойство для сокращения числа разрядов, требуемых для хранения значения для одного кадра, и выделяем специальное значение для числа обновлений, большего того, которое помещается в выделенное число разрядов.
Например, если мы предположим, что размер окна равен одному часу, показатель скольжения равен 5 минутам, и размер интервала кэширования составляет 2 минуту, то потребуется хранить значения для двенадцати кадров окна. Средняя интенсивность обновлений в расчете на кадр должна быть  . Допуская некоторое отклонение, мы можем использовать для хранения значения 4 бита, резервируя одно значение (здесь 16) для обозначения числа обновлений, большего 15. Далее такое число трактуется как бесконечность. Тогда при таком окне на каждую запись требуется 12 × 4 бит = 48 бит, что является вполне приемлемым расходом.
. Допуская некоторое отклонение, мы можем использовать для хранения значения 4 бита, резервируя одно значение (здесь 16) для обозначения числа обновлений, большего 15. Далее такое число трактуется как бесконечность. Тогда при таком окне на каждую запись требуется 12 × 4 бит = 48 бит, что является вполне приемлемым расходом.
Операции сбора статистики достаточно просты: для каждой новой операции обновления требуется увеличить на единицу счетчик текущего кадра. Кадры обновляются циклическим образом, и специальный признак указывает на то, что данные явдяются новыми. Новые записи обрабатываются специальным образом: устанавливается флаг, позволяющий избежать неправильного поведения, пока для новой записи еще не собрано достаточное количество статистической информации.
Аналогичным образом проиводится сбор статистики для Динамической политики. Основным отличием является то, что собирается сумма обновлений, а не число операций. Поэтому объем памяти для хранения статистических данных невозможно оптимизировать так, как описывалось выше. По соображениям эффективности полная статистика собирается только для наиболее часто обновляемых записей. Все остальные записи обрабатываются с использованием порогового значения, назначенного для применения по умолчанию. Собираемая статистика имеет не очень большой объем и может сохраняться в основной памяти. Например, в системе с 10000 часто обновляемых записей категории B при наличии 100 кадров в окне и использовании 32 бит для хранения суммарных значений обновлений записей потребуется всего 10000 × 100 × 32 ≈ 4 мегабайта.
Оставшиеся вычисления описываются в разд. 5. Для уменьшения погрешности оценки мы свертываем точные функции распределения, если для некоторой записи в окне выполнялось менее 30 операций обновления. В противном случае, как описывалось в разд. 5, для сокращения вычислений используется аппрокимация на основе нормального распределения. Еще одной проблемой, свойственной Динамической политике, является начало работы системы, когда какая-либо статистика отсутствует. Эта проблема разрешается за счет использования в начале работы Политики разъединения и перехода к Динамической политике после накопления достаточного объема статистической информации.
6.6. Реализационные альтернативы
Архитектура в [7, 1] основывается на предположении об использовании службы хранения данных, обеспечивающей гарантии согласованности "в конечном счете". Более высокие уровни согласованности достигаются за счет использования дополнительных служб и протоколов. В последнее время появилось несколько систем, которые сами обеспечивают гарантии согласованности более высокого уровня (например, PNUTS компании Yahoo [11]).В PNUTS поддерживается более развитый API с операциями типа Read-any, Read-latest, Test-and-set-write (required version) и т.д. С использованием этих примитивов можно реализовать сессионную согласованность прямо поверх "облачной" службы без потребности в дополнительных протоколах и очередях. Средствами такого API невозможно реализовать сериализуемость, но в PNUTS имеется операция Test-and-set-write (required version), на основе которой можно реализовать оптимистическое управления параллелизмом доступа к данным категории A. Описываемые в статье средства управления метаданными, сбора и обработки статистики и поддержки политик можно было бы легко приспособить для использования и в такой среде. Но, к сожалению, Yahoo PNUTS не является общедоступной системой. Поэтому мы не имели возможности более детально проработать реализацию и/или включить эту систему в состав своих экспериментов. Тем не менее, разработчики PNUTS утверждают, что, например, Read-any является более дешевой операцией, чем Read-latest. Следовательно, в этой системе поддерживается такой же баланс между стоимостью и согласованностью, и к PNUTS можно было бы применить рационализацию согласованности для оптимизации стоимости и производительности.
Еще одной новой системой является Microsoft SQL Data Services [20]. В этой службе в качестве базовой системы используется MS SQL Server, а сама служба основана на схемах репликации и балансировки нагрузки. За счет использования MS SQL Server система может обеспечивать строгую согласованность. Однако в этой системе имеются сильные ограничения: данные не могут распределяться по нескольким серверам, а транзакции не могут распространяться на несколько машин. Поэтому масштабируемость системы ограничена.
Рационализацию согласованности можно было бы реализовать и внутри Microsoft SQL Data Services. В частности, введение категорий A и C, а также простых стратегий типа Политики разъединения могло бы помочь повысить производительность. Однако поскольку в этом случае строгая согласованность достигается более дешевым способом (не требуется обмен сообщениями между серверами), выигрыш, скорее всего, был бы далеко не так велик, как в реальной распределенной среде, где объем данных может возрастать неограниченным образом, и данные могут распределяться между несколькими машинами.
Наконец, рационализация согласованности могла бы хорошо подойти и для традиционных распределенных систем баз данных, в частности, для кластерных решений. Если ослабление согласованности является приемлемым, рационализация согласованности может помочь уменьшить число сообщений, требуемых для обеспечения строгой согласованности. И в этом случае можно было бы прямо применить большинство компонентов нашей системы.