HadoopDB: архитектурный гибрид технологий MapReduce и СУБД для аналитических рабочих нагрузок
Азза Абузейд, Камил Байда-Павликовски, Дэниэль Абади, Ави Зильбершац, Александр Разин
Перевод: Сергей Кузнецов
6.3. Сводка описанных результатов
При отсутствии отказов или фоновых процессов производительность HadoopDB может приблизиться к производительности параллельных систем баз данных. Имеется несколько причин, по которым HadoopDB не достигает тех же или лучших результатов, чем параллельные системы: (1) в PostreSQL не поддерживается поколоночное хранение таблиц; (2) оценки производительности СУБД-X являются излишне оптимистичными (примерно на 15% лучше реальных показателей); (3) в PostgreSQL не использовалось сжатие данных; (4) имеются некоторые накладные расходы на поддержку взимодействия между Hadoop и PostgreSQL, возрастающие при увеличении числа чанков. Мы надеемся, что часть этих накладных расходов в будущем удастся устранить.HadoopDB неизменно превосходит по производительности Hadoop (за исключение задачи агрегации с использованием UDF, для которой мы не учитывали время слияния данных для Hadoop).
Хотя время загрузки HadoopDB почти в 10 раз больше, чем у Hadoop, эти расходы амортизируются существенно более высокой производительностью выполнения запросов над загруженными данными. Для некоторых задач, таких как задача соединения, десятикратное повышение стоимости загрузки сразу влечет десятикратный же выигрыш в производительности.
7. Отказоустойчивость и неоднородная среда
Как отмечалось в разд. 3, в крупных кластерах без совместно используемых ресурсов высока вероятность отказа или замедления отдельных узлов. При выполнении экспериментов, описываемых в этой статье, в среде EC2 мы часто сталкивались и с отказами узлов, и с замедлением их работы (вот примеры уведомлений, которые нам случалось получать: "4:12 PM PDT (Pacific Daylight Time): "Мы изучаем локальную проблему в зоне US-EAST. Из-за этого небольшое число экземпляров в настоящее время недоступно для использования. Мы работаем над восстановлением их работоспособости." или "Сегодня, начиная с 11:30 PM PDT, мы будем производить техническое обслуживание частей сети Amazon EC2. Целью работ является сведение к минимуму вероятности воздействия на экземпляры Amazon EC2, но, возможно, в течение короткого времени, пока соответствующие изменения вступят в силу, некоторым пользователям придется столкнуться с более частой потерей пакетов.").В параллельных системах баз данных время обработки запросов обычно определяется временем, которое затрачивается на выполнение своей части задачи наиболее медленным узлом. В отличие от этого, в MapReduce любая задача может быть запланирована для выполнения на любом узле при условии, что он свободен, и на него передаются или в нем уже имеются требуемые входные данные. Кроме того, в Hadoop поддерживается избыточное выполнение задач, выполняемых на "отстающих" узлах, чтобы сократить влияние медленных услов на общее время выполнения запроса.
Отказоустойчивость в Hadoop достигается путем перезапуска в других узлах задач, которые выполнялись на отказавших узлах. JobTracker получает периодические контрольные сообщения от компонентов TaskTracker. Если некоторый TaskTracker не общается с JobTracker в течение некотрого предустановленного периода времени (срока жизни (expiry interval), JobTracker считает, что соответствующий узел отказал и переназначает все задачи Map/Reduce этого узла другим узлам TaskTracker. Этот подход отличается от подхода, применяемого в большинстве параллельных систем баз данных, в которых при отказе какого-либо узла обработка незавершенных запросов аварийным образом завершается и начинается заново (с использованием вместо отказавшего узла узла-реплики).
За счет наследования от Hadoop средств планирования и отслеживания заданий HadoopDB обладает аналогичными свойствами отказоустойчивости и эффективной работы при наличии "отстающих" узлов.
Для проверки эффективности HadoopDB в сравнении с Hadoop и Vertica в средах, подверженных отказам и неоднородности, мы выполняли запрос с агрегацией 2000 групп (см. п. 6.2.4) на 10-узловом кластере, и в каждой системе поддерживали по две реплики данных. В Hadoop и HadoopDB срок жизни TaskTracker устанавливался в 60 секунд. В этих экспериментах использовались следующие установки.
Hadoop (Hive): Репликацией данных управляла HDFS. HDFS реплицировала каждый блок данных в некотором другом узле, выбираемом случайным образом с равномерным распределением.
HadoopDB (SMS): Как описывалось в разд. 6, в каждом узле содержится двадцать гигабайтных чанков таблицы UserVisits. Каждый из этих 20 чанков реплицировался в некотором другом узле, выбираемом случайным образом.
Vertica: В Vertica репликация обеспечивается путем хранения дополнительных копий сегментов каждой таблицы. Каждая таблица хэш-разделяется между узлами, и резервная копия каждого сегмента размещается в некотором другом узле, выбираемом по правилу репликации. При сбое узла используется эта резервная копия, пока не будет заново образован утраченный сегмент.
В тестах отказоустойчивости мы прекращали работу некоторого узла после выполения 50% обработки запроса. Для Hadoop и HadoopDB это эквивалентно отказу узла в тот момент, когда было выполнено 50% работы запланированными задачами Map. Для Vertica это эквивалентно тому, что узел отказал после истечения 50% от среднего времени обработки данного запроса.
Для измерения процентного увеличения времени выполнения запроса в неоднородных средах мы замедляли работу некоторого узла путем выполнения фонового задания с большим объемом ввода-вывода. Это задание считывало значения из случайных позиций крупного файла и часто очищало кэши операционной системы. Файл находится на том же диске, на котором сохранялись данные системы.
Не было замечено какой-либо разницы в процентном замедлении HadoopDB с использованием и без использования SMS и Hadoop с использованием и без использования Hive. Поэтому мы указываем результаты для HadoopDB с использованием SMS и Hadoop с использованием Hive и, начиная с этого места, называем эти системы просто HadoopDB и Hadoop соответственно.
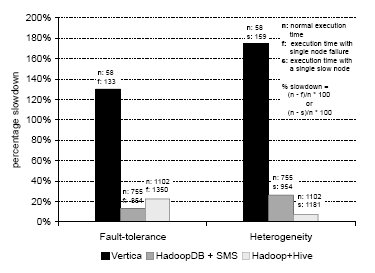
Рис. 11. Эксперименты с отказоустойчивостью и неоднородностью на кластере с 10 узлами
Результаты экспериментов показаны на рис. 11. Отказы узлов замедляли HadoopDB и Hadoop в меньшей степени, чем систему Vertica. В Vertica возрастание общего времени выполнения запроса происходит из накладных расходов на аварийное завершение выполнения запроса и его полное повторное выполнение.
В HadoopDB и Hadoop задачи, выполнявшиеся в отказавшем узле, распределялись между оставшимися узлами, содержащими реплики данных. HadoopDB несколько превосходит Hadoop по производительности. В Hadoop те узлы TaskTracker, которым придется обрабатывать блоки, не локальные для этих узлов, будут вынуждены до начала обработки их скопировать (из реплик). В HadoopDB же обработка проталкивается в реплики баз данных. Поскольку число записей, возвращаемых после обработки запроса, меньше размера исходных данных, HadoopDB не приходится сталкиваться при отказе узла с такими же сетевыми накладными расходами, что возникают у Hadoop.
В среде, в которой один из узлов является исключительно медленным, HadoopDB и Hadoop демонстрируют менее чем 30-процентное увеличение времени выполнения запроса, в то время как у Vertica это время увеличивается на 170%. Vertica ожидает, пока "отстающий" узел завершит обработку. В HadoopDB и Hadoop запускаются избыточные задачи в узлах, которые завершили выполнение своих задач. Поскольку данные разбиваются на чанки (в HadoopDB имеются гигабайтные чанки, а в Hadoop – 256-мегабайтные блоки), разные реплики необработанных блоков, назначенных "отстающему" узлу, параллельно обрабатываются несколькими узлами TaskTracker. Таким образом, задержка из-за потребности обработки этих блоков распределяется между узлами кластера.
В своих экспериментах мы обнаружили, что в планировщике задач Hadoop используется некоторое предположение, противоречащее модели HadoopDB. В Hadoop узлы TaskTracker копируют данные, не являющиеся для них локальными, из отстающих узлов или реплик. Однако HadoopDB не перемещает чанки PostgreSQL в новые узлы. Вместо этого TaskTracker избыточной задачи подключается либо к базе данных "отстающего" узла, либо к ее реплике. Если этот TaskTracker подключится к базе данных "отстающего" узла, то в этом узле потребуется параллельно обрабатывать еще один запрос, что приведет к еще большему замедлению. Поэтому та же особенность, которая приводит к немного лучшим характеристкам HadoopDB, чем у Hadoop, при продолжении работы после сбоя узла, приводит к несколько более высокому процентному замедлению работы HadoopDB при работе в неоднородных средах. Мы планируем поменять реализацию планировщика, чтобы узлы TaskTracker всегда подключались не к базам данных "отстающих" узлов, а к их репликам.
7.1. Обсуждение
Следует отметить, что хотя процентное замедление Vertica было больше, чем у Hadoop и HadoopDB, ее общее время выполнения запроса (даже при наличии отказа или медленного узла) значительно меньше, чем у этих систем. Кроме того, производительность Vertica в отсутствии сбоев на порядок выше, чем у Hadoop и HadoopDB (в основном, потому, что поколоночное хранение данных обеспечивает большой выигрыш при выполнении небольших запросов с агрегацией). Hadoop и HadoopDB могут показать такую же производительность, но на кластере, у которого число узлов на порядок больше. Следовательно, для Vertica сбои и замедление работы узлов менее вероятны, чем для Hadoop и HadoopDB. Кроме того, для поддержки 6,5-гигабайтной базы данных eBay (вероятно, крупнейшего в мире хранилища данных к июню 2009 г.) [4] используется всего лишь 96-узловой кластер без совместно используемых ресурсов. В кластерах с числом узлов меньше 100 отказы узлов возникают достаточно редко.Мы утверждаем, что в будущем станут распространенными производственные установки систем баз данных с использованием 1000-узловых кластеров, и будут не редки случаи использования 10000-узловых кластеров. Это предсказание основывается на трех наблюдаемых тенденциях. Во-первых, объем производственных данных растет быстрее, чем диктует закон Мура (см. разд. 1). Во-вторых, становится понятно, что из соображений и соотношения "цена-производительность", и (все более важного) соотношения "потребляемая энергия-производительность" использовать много дешевых, потребляющих мало энегии серверов выгоднее, чем использовать меньшее число "тяжеловесных" серверов [14]. В-третьих, как никогда ранее требуется выполнять анализ данных внутри СУБД, а не выталкивать данные для анализа во внешние системы. В перегруженных дисками архитектурах, подобных 96-узловой системе баз данных eBay, отсутствует вычислительная мощность, требуемая для поддержки аналитических рабочих нагрузок.
Поэтому в будущем нас ожидают тяжеловесные аналитические задания над базами данных, для выполнения которых понадобится больше времени и больше узлов. Вероятность отказа в этих приложениях следующего поколения будет гораздо больше, чем сегодня, и повторное выполнение всего задания после возникновения отказа будет неприемлемым (сбои могут стать настолько частыми, что долго работающие задания никогда не закончатся!). Поэтому, хотя Hadoop и HadoopDB расплачиваются падением производительности за планирование во время исполнения, рестарт на уровне блоков и частое сохранение состояния, накладные расходы на достижение стабильной отказоустойчивости станут неизбежными. Одной из особенностей системы HadoopDB является то, что она может переходить из одного конца этого спектра в другой конец. Поскольку основной единицей обработки является чанк, при снятии ограничений на размер чанка такие системы, подобно Vertica, смогут поддерживать рабочие нагрузки, для которых требуется высокая производительность и низкая отказоустойчивость, а при использовании более мелких чанков смогут обеспечивать высокий уровень отказоустойчивости (подобно Hadoop).
8. Заключение
Наши эксперименты показывают, что HadoopDB может приблизиться в отношении производительности к параллельным системам баз данных, обеспечивая при этом отказоустойчивость и возможность использования в неоднородной среде при тех же правилах лицензирования, что и Hadoop. Хотя производительность HadoopDB, вообще говоря, ниже производительности параллельных систем баз данных, во многом это объясняется тем, что в PostgreSQL таблицы хранятся не по столбцам, и тем, что в PostgreSQL не использовалось сжатие данных. Кроме того, Hadoop и Hive – это сравнительно молодые проекты с открытыми кодами. Мы ожидаем, что их следующие версии будут демонстрирорвать более высокую производительность. От этого автоматически выиграет и HadoopDB.В HadoopDB применяется некоторый гибрид подходов параллельных СУБД и Hadoop к анализу данных, позволяющий достичь производительности и эффективности параллельных систем баз данных, обеспечивая при этом масштабируемсть, отказоустойчивость и гибкость систем, основанных на MapReduce. Способность HadoopDB к прямому включению Hadoop и программного обеспечения СУБД с открытыми исходными текстами (без изменения кода) делает HadoopDB особенно пригодной для выполнения крупномасштабного анализа данных в будущих рабочих нагрузках.
9. Благодарности
Мы хотели бы поблагодарить Сергея Мельника (Sergey Melnik) и трех анонимных рецензентов за их исключительно глубокие комментарии к ранней версии этой статьи, которые мы учли при подготовке окончательного варианта. Мы также благодарны Эрику МакКоллу (Eric McCall) за помощь в использовании Vertica в среде EC2. Это исследование поддерживалось грантами NSF IIS- 0845643 и IIS-08444809.10. Литература
- Hadoop. Web Page
- HadoopDB Project. Web page
- Vertica
- D. Abadi. What is the right way to measure scale? DBMS Musings Blog
- P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neugebauer, I. Pratt, and A. Warfield. Xen and the art of virtualization. In Proc. of SOSP, 2003
- R. Chaiken, B. Jenkins, P.-A. Larson, B. Ramsey, D. Shakib, S. Weaver, and J. Zhou. Scope: Easy and efficient parallel processing of massive data sets. In Proc. of VLDB, 2008
- G. Czajkowski. Sorting 1pb with mapreduce
- J. Dean and S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In OSDI, 2004
- D. DeWitt and M. Stonebraker. MapReduce: A major step backwards. DatabaseColumn Blog.
- D. J. DeWitt, R. H. Gerber, G. Graefe, M. L. Heytens, K. B. Kumar, and M. Muralikrishna. GAMMA - A High Performance Dataflow Database Machine. In VLDB ’86, 1986
- Facebook. Hive. Web page.
- S. Fushimi, M. Kitsuregawa, and H. Tanaka. An Overview of The System Software of A Parallel Relational Database Machine. In VLDB ’86, 1986.
- Hadoop Project. Hadoop Cluster Setup. Web Page
- J. Hamilton. Cooperative expendable micro-slice servers (cems): Low cost, low power servers for internet-scale services. In Proc. of CIDR, 2009
- Hive Project. Hive SVN Repository. Accessed May 19th 2009
- J. N. Hoover. Start-Ups Bring Google’s Parallel Processing To Data Warehousing. InformationWeek, August 29th, 2008.
- S. Madden, D. DeWitt, and M. Stonebraker. Database parallelism choices greatly impact scalability. DatabaseColumn Blog
- Mayank Bawa. A $5.1M Addendum to our Series B
- C. Monash. The 1-petabyte barrier is crumbling
- C. Monash. Cloudera presents the MapReduce bull case. DBMS2 Blog
- C. Olofson. Worldwide RDBMS 2005 vendor shares. Technical Report 201692, IDC, May 2006.
- C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. Pig latin: a not-so-foreign language for data processing. In Proc. of SIGMOD, 2008.
- A. Pavlo, A. Rasin, S. Madden, M. Stonebraker, D. DeWitt, E. Paulson, L. Shrinivas, and D. J. Abadi. A Comparison of Approaches to Large Scale Data Analysis. In Proc. of SIGMOD, 2009. Русский перевод: Эндрю Павло, Эрик Паулсон, Александр Разин, Дэниэль Абади, Дэвид Девитт, Сэмюэль Мэдден, Майкл Стоунбрейкер. Сравнение подходов к крупномасштабному анализу данных
- M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, M. Cherniack, M. Ferreira, E. Lau, A. Lin, S. Madden, E. J. O’Neil, P. E. O’Neil, A. Rasin, N. Tran, and S. B. Zdonik. C-Store: A column-oriented DBMS. In VLDB, 2005.
- D. Vesset. Worldwide data warehousing tools 2005 vendor shares. Technical Report 203229, IDC, August 2006.
9 Информация: У авторов Дэниэла Абади и Александра Разина имеются небольшие пакеты акций компании Vertica, врученные им за работу в проекте C-Store – предшественнике Vertica.