Управление параллелизмом с низкими накладными расходами для разделенных баз данных в основной памяти
Эван Джонс, Дэниэль Абади и Сэмуэль Мэдден
Перевод: Сергей Кузнецов
6. Аналитическая модель
Для улучшения своего понимания схем управления параллелизмом мы проанализировали ожидаемые результаты экспериментов из подраздела 5.1 с использованием нескольких разделов. Наша модель предсказывает производительность трех схем на основе всего нескольких параметров (что может оказаться полезным, например, для планировщика запросов) и позволяет исследовать чувствительность этих схем к характеристикам рабочей нагрузки (например, объем расходов ресурсов процессора на выполнение одной транзакции или величина сетевой задержки). Для упрощения анализа мы игонируем репликацию.Пусть база данных состоит из двух разделов P1 и P2, а работая нагрузка – из двух транзакций. Первая транзакция – однораздельная, обращающаяся к данным либо из P1, либо из P2, причем раздел выбирается случайным образом. Вторая транзакция – многораздельная, обращающаяся к данным из обоих разделов. Зависимости по данным отсутствуют, так что требуется только один цикл коммуникаций. Другими словами, координатор просто посылает в каждый из разделов по односу фрагменту транзакции, ожидает ответа, а затем посылает свое решение о фиксации или аварийном завершении. Каждая многораздельная транзакция обращается в каждом разделе к данным одного и того же объема, но общий объем данным, к которым она обращается, такой же, что и любой однораздельной транзакции. Чтобы обеспечить максимальные преимущества для схемы с синхронизационными блокировками, мы считаем, что транзакции никогда не конфликтуют. Нас интересует пропускная способности системы при росте доли f многораздельных транзакций в рабочей нагрузке.
6.1. Блокирование
Начнем с анализа схемы блокирования. Пусть однораздельная транзакция выполняется в одном разделе tsp секунд, а многораздельная транзакция – tmp секунд в обоих разделах, включая время, требующееся на двухфазную фиксацию. Если выполняется всего N транзакций, то имеется N × f многораздельных транзакций и 1/2 × N × (1-f) однораздельных транзакций. Сомножитель 1/2 появляется из-за того, что однораздельные транзакции поровну распределены между двумя разделами. Поэтому время, требуемое для выполнения всех транзакций, и пропускная способность системы выражаются следующими формулами:время = N × f × tmp + ((N × (1-f)) / 2) × tsp
пропускная способность = N / время = 2 / (2 × f × tmp + (1-f) × tsp)
Фактически, время выполнения N транзакций является взвешенным средним между временем выполнения рабочей нагрузки из только однораздельных транзакций и временем выполнения рабочей нагрузки из только многораздельных транзакций. При возрастании f пропускная способность будет уменьшаться от 2 / tsp до 1 / tmp. Поскольку tmp > tsp, пропускная способность будет быстро падать даже при небольшой доли многораздельных транзакций.
6.2. Спекулятивная схема
Сначала рассмотрим локальную спекулятивную схему, описанную в п. 4.2.1. Для спекуляции нам требуется знать время простоя процесса каждого раздела в течение выполнения многораздельной транзакции. Если время процессора, требующееся для выполнения многораздельной транзакции в одном разделе, равно tmpN, то величина сетевой задержки tmpN равняется tmp - tmpC. Поскольку мы можем совместить выполнение следующей многораздельной транзакции с периодом ожидания ответа от сети, предельное время при выполнении рабочей нагрузки из только многораздельных транзакций tmpL вычисляется как max(tmpN, tmpC), а время простоя процессора tmpI – как max(tmpN, tmpC) - tmpC.Предположим, что для спекулятивного выполнения однораздельной транзакции требуется время tspS. За время простоя, возникающее при выполнении многораздельной транзакциии, в каждом разделе можно выполнить не более tmpI / tspS однораздельных транзакций. При выполнении в системе N × f многораздельных транзакций в каждом разделе выполняется N × (1- f) / 2 однораздельных транзакций. Следовательно, в среднем каждая многораздельная транзакция отделяется (1- f) / 2 × f однораздельными транзакциями. Поэтому для каждой многораздельной транзакции число однораздельных транзакций, которые можно спекулятивно выполнить в каждом разделе, задается следующей формулой:
Nhidden = min ((1- f) / (2 × f), tmpI / tspS)
Тем самым, время выполнения N и результирующая пропускная способность вычисляются следующим образом:
время = N × f × tmpL + (N × (1- f) - 2 × N × f × Nhidden) × (tsp / 2)
пропускная способность = 2 / (2 × f × tmpL + ((1- f) - 2 × f × Nhidden) × tsp)
В нашем конкретном случае tmpN > tmpC, и поэтому мы можем упростить формулы:
Nhidden = min ((1- f) / (2 × f), (tmp - 2 × tmpC) / tspS)
пропускная способность = 2 / (2 × f × (tmp - tmpC) + ((1- f) - 2 × f × Nhidden) × tsp)
Разные значения функции min соответствуют двум разным поведениям системы. Если (1- f) / (2 × f) ≥ tmpI / tspS, то время простоя полностью используется. В противном случае в системе отсутствует нужное число однораздельных транзакций, чтобы можно было полностью скрыть сетевые задержки, и пропускная способность будет быстро падать после того, как значение f превзойдет tspS / (2 × tmpI + tspS).
6.2.1. Спекулятивное выполнение многораздельных транзакций
В соответствии с п. 4.2.2 эту модель можно расширить, включив в нее возможность спекулятивного выполнения многораздельных транзакций. В ранее описанном выводе формулы для времени выполнения предполагалось, что одна многораздельная транзакция выполняется tmpL секунд, включая время ожидания ответа от сети. Если допустить спекулятивное выполнение многораздельных транзакций, то это ограничение снимается. Вместо этого мы должны подсчитать время процессора, требуемое для выполнения многораздельных транзакций и спекулятивного и не спекулятивного выполнения однораздельных транзакций. В предыдущей модели подсчитывалось число спекулятивных однораздельных транзакций для одной многораздельной транзакции – Nhidden. Мы можем подсчитать время для многраздельных транзакций и спекулятивных однораздельных транзакций как tperiod = tmpC + Nhidden × tspS. Это время заменяет tmpL в предыдущей модели, и пропускная способность вычисляется по следующей формуле:пропускная способность = 2 / (2 × f × tperiod + ((1- f) - 2 × f × Nhidden) × tsp)
6.3. Синхронизационные блокировки
Поскольку в рассматриваемой рабочей нагрузке отсутствуют конфликтующие транзакции, синхронизационные блокировки не приводят к задержкам. Однако необходимо учитывать накладные расходы на отслеживание блокировок. Определим l как долю дополнительного времени, требуемого при выполнении транзакций с использованием синхронизационных блокировок. Поскольку при применении этой схемы всегда нужны буфера отката, время выполнения однораздельных транзакций составляет tspS. Кроме того, нужно учитывать время, требуемое для двухфазной фиксации, так что время выполнения многораздельных транзакций равняется tspS. Время выполнения N транзакций и пропускная способность вычисляются по следующим формулам:время = N × f × l × tmpC + ((N × (1- f)) / 2) × l × tspS
пропускная способность = N / время = 2 / (2 × f × l × tmpC + (1- f) × l × tspS)
6.4. Экспериментальная валидация
Мы измерили параметры модели для своей реализации. Значения приведены в табл. 2. На рис. 10 показаны аналитическая модель с использованием этих параметров, а также измерения, полученные для нашей системы без репликации. Можно заметить, что графики относительно близки. Это означает, что модель разумным образом аппроксимирует поведение реальной системы. Эти результаты также показывают, что спекулятивное выполнение многораздельных транзакций приводит к значительному повышению производительности, если такие транзакции составляют значительную часть рабочей нагрузки.| Переменная | Измеренное значение | Описание |
| tsp | 64 миллисекунды | Время не спекулятивного выполнения однораздельной транзакции |
| tspS | 73 миллисекунды | Время спекулятивного выполнения однораздельной транзакции |
| tmp | 211 миллисекунд | Время выполнения многораздельной транзакции, включая обработку двухфазной фиксации |
| tmpC | 55 миллисекунд | Процессорное время выполнения многораздельной транзакции |
| tmpN | 40 миллисекунд | Сетевая задержка при выполнении многораздельной транзакции |
| l | 13,2% | Накладные расходы синхронизационных блокировок. Доля дополнительного времени выполнения |
Табл. 2. Переменные аналитической модели
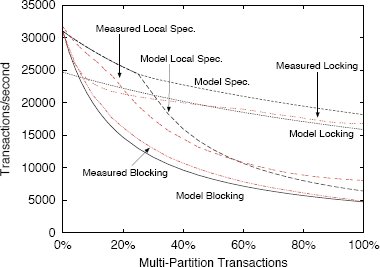
Рис. 10. Модельная пропускная способность
7. Родственные работы
В большинстве распределенных систем баз данных (например, [9], [6], [19]) для обработки параллельных запросов используется некоторая разновидность двухфазных синхронизационных блокировок, которые в соответствии с нашими результатами лучше всего подходят при наличии рабочих загрузок с малым числом конфликтов. Другие схемы, такие как упорядочение по временным меткам, позволяют избежать синхронизационных тупиков, допуская при этом параллельное выполнение транзакций. Для поддержки таких схем требуется поддержка наборов чтения/записи, защелок и откатов.Похоже, что Гарсиа-Молина (Garcia-Molina), Липтон (Lipton) и Вальдес (Valdes) первыми предложили подход к использованию основной памяти большого объема для устранения управления параллелизмом [11-12]. Этот метод использовался в некоторых ранних системах управления базами данных в основной памяти [16]. Шаша (Shasha) и др. в [27] представили механизм исполнения запросов к базам данных, похожий на нашу разработку. Они также отмечали, что схема, похожая на нашу блокировочную схему, может обеспечить существенный выигрыш в производительности при наличии рабочих нагрузок обработки транзакций. Однако их исследование выполнялось в контексте дисковых систем баз данных, требующих журналирования, и они не исследовали спекулятивную схему и схему с синхронизационными блокировками при наличии однопотокового выполнения. Вместо этого они позволяли пользователям указывать, какие транзакции конфликтуют. В системе промежуточного программного обеспечения (middleware) Sprint данные разделяются по нескольким экзмплярам коммерческой системы управления базами данных в основной памяти [7]. Транзакции должны заранее классифицироваться на однораздельные и многораздельные. В отличие от нашей схемы, журналы транзакций пишутся на диск, и используется традиционное управление параллелизмом, обеспечиваемое в используемой СУБД.
Одним из вариантов двухфазной фиксации, похожим на нашу работу, является OPT [13]. В этом протоколе допускает "заимствование" транзакциями незафиксированных ("грязных") данных некоторой транзакции, находящейся на фазе подготовки к фиксации. Хотя в этой работе предполагается использование синхронизационных блокировок, она очень похожа на нашу схему "локального спекулятивного выполнения". Однако в OPT спекулятивно выполняется только одна транзакция, в то время как при применении нашего спекулятивного управления параллелизмом спекулятивно выполняется много транзакций, и может совмещаться двухфазная фиксация многораздельных транзакций с одним и тем же координатором. Редди (Reddy) и Кицурегава (Kitsuregawa) предлагали спекулятивные синхронизационные блокировки, когда транзакция обрабатывает версии "до" и "после" изменяемых элементов данных [15]. Во время фиксации путем отслеживания зависимостей по данным между транзакциями выбирается и применяется корректный вариант выполнения. В этом подходе предполагается, что имеются обильные вычислительные ресурсы. В нашей среде возможности процессоров ограничены, и поэтому наше управление параллелизмом всегда действует на версии данных "после", а также не производит отслеживание зависимостей на мелкоструктурном уровне.
В [3] отмечалось, что синхронизационные блокировки плохо подходят для рабочих нагрузок с большим числом конфликтов, и рекомендовалось использовать в этих случаях оптимистическое управление параллелизмом. Мы придерживаемся близких к этому взглядов, хотя наши предварительные результаты, связанные с OCC, показывают, что в наших условиях этот подход не помогает, поскольку требуется дорогостоящая поддержка наборов чтения/записи. Мы считаем, что в условиях частых конфликтов более эффективно разделение данных и спекулятивное выполнение транзакций.
Разделение данных – это хорошо изученная проблема систем баз данных (среди прочего, см. [18], [24], [8], [17], [10]). В предыдущих исследованиях отмечалось, что разделение данных может эффективно повысить уровень масштабирования систем баз данных за счет распараллеливания ввода-вывода [17] или связывания с каждым разделом отдельного обработчика в кластере [18]. В отличие от этого, нас интересует разделение данных как средство освобождения от потребности в управлении параллелизмом.
H-Store [26] представляет собой инфраструктуру для системы, использующей разделение данных и однопотоковое выполнение для упрощения управления параллелизмом. Мы развиваем эту работу, предлагая несколько схем управления параллелизмом в системах разделенных баз данных в основной памяти и приходя к выводу, что спекулятивная схема часто превосходит по производительности комбинированную схему блокирования и OCC, описанную в статье про H-Store.
В предыдущих исследования по измерению накладных расходов синхронизационных блокировок, синхронизации на основе защелок, многопотоковой обработки и управления параллелизмом в Shore [14] было показано, что накладные расходы всех этих подсистем являются значительными. В данной статье эти результаты расширяются демонстрацией того, что при наличии рабочих нагрузок с частыми конфликтами может оказаться предпочительной некоторая разновидность управления параллелизмом, и что в некоторых случаях предпочтительными могут стать даже синхронизационные блокировки и многопотоковое выполнение.
8. Заключение
В этой статье описываются результаты исследования влияния схем управления параллелизмом с низкими накладными расходами на производительность систем разделенных баз данных в основной памяти. Мы обнаружили, что спекулятивное управление параллелизмом, при котором фаза фиксации ранее выполнявшихся транзакций совмещается с выполнением более поздних транзакций, хорошо работает при рабочих нагрузках, включающих однораздельные и многораздельные транзакции, когда аварийное завершение транзакций происходит редко, и лишь для немногих транзакций требуется несколько циклов коммуникаций. В противном случае предпочтительными является легковесные схемы с синхронизационными блокировками, допускающими более высокий уровень параллелизма. На (слегка измененном) эталонном тестовом наборе TPC-C явным победителем стала спекулятивная схема управления параллелизмом, позволяющая в некоторых случаях добиться производительности, в два раза превышающей производительность схемы с синхронизационными блокировками. Наши результаты особенно уместны для систем, в которых разделение данных используется для достижения параллелизма, поскольку в статье показано, что рабочую нагрузку, не разделенную должным образом, можно выполнять без накладных расходов, свойственных управлению параллелизмом на основе синхронизационных блокировок.9. Благодарности
Эта работа поддерживалась грантами NFS IIS- 0845643 и IIS-0704424, а также канадским Советом по естественным и техническим наукам (Natural Sciences and Engineering Research Council). Все высказывания, оценки и рекомендации, высказанные в статье, отражают мнение авторов, которое не обязательно совпадает с точкой зрения National Science Foundation (NSF).10. Литература
[1] TPC benchmark C. Technical report, Transaction Processing Performance Council, February 2009. Revision 5.10.1.[2] A. Adya, R. Gruber, B. Liskov, and U. Maheshwari. Efficient optimistic concurrency control using loosely synchronized clocks. In Proc. ACM SIGMOD, 1995.
[3] R. Agrawal, M. J. Carey, and M. Livny. Concurrency control performance modeling: Alternatives and implications. ACM Trans. Database Syst., 12(4):609–654, 1987.
[4] S. Agrawal, V. Narasayya, and B. Yang. Integrating vertical and horizontal partitioning into automated physical database design. In Proc. ACM SIGMOD, 2004.
[5] P. A. Bernstein and N. Goodman. Timestamp-based algorithms for concurrency control in distributed database systems. In Proc. VLDB, 1980.
[6] H. Boral, W. Alexander, L. Clay, G. Copeland, S. Danforth, M. Franklin, B. Hart, M. Smith, and P. Valduriez. Prototyping bubba, a highly parallel database system. IEEE Trans. on Knowl. and Data Eng., 2(1):4–24, 1990.
[7] L. Camargos, F. Pedone, and M. Wieloch. Sprint: a middleware for high-performance transaction processing. SIGOPS Oper. Syst. Rev., 41(3):385–398, June 2007.
[8] S. Ceri, S. Navathe, and G. Wiederhold. Distribution design of logical database schemas. IEEE Trans. Softw. Eng., 9(4):487–504, 1983.
[9] D. J. Dewitt, S. Ghandeharizadeh, D. A. Schneider, A. Bricker, H. I. Hsiao, and R. Rasmussen. The gamma database machine project. IEEE Trans. on Knowl. and Data Eng., 2(1):44–62, 1990.
[10] G. Eadon, E. I. Chong, S. Shankar, A. Raghavan, J. Srinivasan, and S. Das. Supporting table partitioning by reference in oracle. In Proc. ACM SIGMOD, 2008.
[11] H. Garcia-Molina, R. J. Lipton, and J. Valdes. A massive memory machine. Computers, IEEE Transactions on, C-33(5):391–399, 1984.
[12] H. Garcia-Molina and K. Salem. Main memory database systems: An overview. IEEE Trans. on Knowl. and Data Eng., 4(6):509–516, 1992.
[13] R. Gupta, J. Haritsa, and K. Ramamritham. Revisiting commit processing in distributed database systems. In Proc. ACM SIGMOD, pages 486–497, New York, NY, USA, 1997. ACM.
[14] S. Harizopoulos, D. J. Abadi, S. Madden, and M. Stonebraker. OLTP through the looking glass, and what we found there. In Proc. ACM SIGMOD, pages 981–992, 2008.
Имеется перевод на русский язык: Ставрос Харизопулос, Дэниэль Абади, Сэмюэль Мэдден, Майкл Стоунбрейкер. OLTP в Зазеркалье.
[15] P. Krishna Reddy and M. Kitsuregawa. Speculative locking protocols to improve performance for distributed database systems. Knowledge and Data Engineering, IEEE Transactions on, 16(2):154–169, March 2004.
[16] K. Li and J. F. Naughton. Multiprocessor main memory transaction processing. In Proc. Databases in Parallel and Distributed Systems (DPDS), 1988.
[17] M. Livny, S. Khoshafian, and H. Boral. Multi-disk management algorithms. SIGMETRICS Perform. Eval. Rev., 15(1):69–77, 1987.
[18] M. Mehta and D. J. DeWitt. Data placement in shared-nothing parallel database systems. The VLDB Journal, 6(1):53–72, 1997.
[19] C. Mohan, B. Lindsay, and R. Obermarck. Transaction management in the R* distributed database management system. ACM Trans. Database Syst., 11(4):378–396, 1986.
[20] I. Pandis, R. Johnson, N. Hardavellas, and A. Ailamaki. Data-oriented transaction execution. In PVLDB, 2010.
[21] S. Papadomanolakis and A. Ailamaki. Autopart: Automating schema design for large scientific databases using data partitioning. In Proc. Scientific and Statistical Database Management, 2004.
[22] D. V. Pattishall. Friendster: Scaling for 1 billion queries per day. In MySQL Users Conference, April 2005.
[23] D. V. Pattishall. Federation at Flickr (doing billions of queries per day). In MySQL Conference, April 2007.
[24] D. Sacca and G. Wiederhold. Database partitioning in a cluster of processors. ACM Transactions on Database Systems, 10(1):29–56, 1985.
[25] R. Shoup and D. Pritchett. The eBay architecture. In SD Forum, November 2006.
[26] M. Stonebraker, S. Madden, D. J. Abadi,
S. Harizopoulos, N. Hachem, and P. Helland. The end of an architectural era: (it’s time for a complete rewrite). In Proc. VLDB, 2007.
Имеется перевод на русский язык: Майкл Стоунбрейкер, Сэмюэль Мэдден, Дэниэль Абади, Ставрос Харизопулос, Набил Хачем, Пат Хеллэнд. Конец архитектурной эпохи, или Наступило время полностью переписывать системы управления данными.
[27] A. Whitney, D. Shasha, and S. Apter. High volume transaction processing without concurrency control, two phase commit, SQL or C++. In Int. Workshop on High Performance Transaction Systems, 1997.
[28] D. C. Zilio. Physical Database Design Decision Algorithms and Concurrent Reorganization for Parallel Database Systems. PhD thesis, University of Toronto, 1998.