MapReduce: внутри, снаружи или сбоку от параллельных СУБД?
Сергей Кузнецов
3. MapReduce внутри параллельной СУБД
Очевидны преимущества клиент-серверных организаций СУБД: в такой архитектуре сервер баз данных поддерживает крупную базу данных, которая сохраняется в одном экземпляре и доступна большому числу приложений, выполняемых прямо на стороне клиентов или в промежуточных серверах приложений. Однако даже при использовании реляционной (или, правильнее, SQL-ориентированной) организации баз данных, когда от клиентов на сервер баз данных отправляются высокоуровневые декларативные запросы, в обратную сторону, от сервера к клиенту, пересылаются результирующие данные, вообще говоря, произвольно большого объема.Естественно, возникает вопрос: не окажется ли дешевле, чем пересылать данные с сервера на клиент для их дальнейшей обработки, переместить требуемую обработку данных на сервер, ближе к самим данным. Насколько мне известно, в явном виде идея перемещения вычислений на сторону сервера была высказана в статье Лоуренса Роува (Lawrence A. Rowe) и Майкла Стоунбрейкера (Michael R. Stonebraker) [38], хотя в более скрытой форме намеки на эту идею можно найти и в более ранних статьях М. Стоунбрейкера и др. [39-40], еще не имевших непосредственного отношения к СУБД Postgres.
С того времени, как поддержка определяемых пользователями хранимых процедур, функций и методов, типов данных и триггеров появилась во всех развитых SQL-ориентированных СУБД, соответствующие языковые средства специфицированы в стандарте языка SQL. Более того, возникла новая проблема выбора – одну и ту же функциональность приложения можно реализовать на стороне сервера, на сервере приложений и на клиенте. Однозначных методологий и рекомендаций, способствующих простому выбору, не существует. Например, очевидно, что если услугами одного сервера пользуется несколько приложений, то перегрузка сервера хранимыми процедурами и функциями, реализующими функциональность одного приложения, может нанести ущерб эффективности других приложений.
Тем не менее, во всех традиционных серверных организациях СУБД возможность переноса вычислений на сторону сервера существует и не очень сложно реализуется. Однако в параллельных СУБД (в особенности, категории sharing-nothing) дела обстоят гораздо хуже. Выполнение SQL-запросов распараллеливается автоматически оптимизитором запросов. Но оптимизатор запросов не может распараллелить определенную пользователем процедуру или функцию, если она написана не на SQL, а на одном из традиционных языков программирования (обычно с включением вызовов операторов SQL).
Конечно, технически можно было бы такие процедуры и функции вообще не распараллеливать, а выполнять в каком-либо одном узле кластера. Но тогда (а) в этом узле пришлось бы собрать все данные, требуемые для выполнения процедуры или функции, для чего потребовалась бы массовая пересылка данных по сети, и (b) это свело бы на нет все преимущества параллельных СУБД, производительность которых основывается именно на параллельном выполнении.
С другой стороны, невозможно обязать распараллеливать свои программы самих пользователей, определяющих хранимые процедуры или функции (например, на основе библиотеки MPI [41], которую принято использовать для явного параллельного программирования на основе обмена сообщениями в массивно-параллельной среде). Во-первых, это слишком сложное занятие для разработчиков приложений баз данных, которые часто вообще не являются профессиональными программистами. Во-вторых, при таком явном параллельном программировании требовалось бы явным же образом управлять распределением данных по узлам кластера.
Несмотря на эти трудности, какая-то поддержка механизма распараллеливаемых определяемых пользователями процедур и функций в параллельных аналитических системам баз данных все-таки требуется, поскольку без этого аналитики вынуждены выполнять анализ данных на клиентских рабочих станциях, постоянно пересылая на них из центрального хранилища данных данные весьма большого объема. Другого способа работы у них просто нет. И как показывает опыт двух производственных разработок, для обеспечения возможностей серверного программирования в массивно-параллельной среде систем баз данных с пользой может быть применена модель MapReduce.
Речь идет о параллельных аналитических СУБД Greenplum Database компании Greenplum [9] и nCluster компании Aster Data Systems [10]. Общим в подходах обеих компаний является то, что модель MapReduce реализуется внутри СУБД, и возможностями этих реализаций могут пользоваться разработчики аналитических приложений. Различие состоит в том, как можно пользоваться возможностями MapReduce: в Greenplum Database – наряду с SQL, а в nCluster – из SQL. Рассмотрим эти подходы подробнее.
3.1. Greenplum – MapReduce наравне с SQL
Сначала немного поговорим об общей философии компании Greenplum, приведшей ее, в частности, к идее поддержки технологии MapReduce наряду с технологией SQL. По мнению идеологов Greenplum и основных архитекторов Greenplum Database [28], возрастающий уровень востребованности хранилищ данных и оперативного анализа данных, возможность и целесообразность использования требуемых аппаратных средств в масштабах отдельных подразделений компаний приводят к потребности пересмотра "ортодоксального" подхода к организации хранилищ данных.3.1.1. MAD Skills: новый подход к организации хранилищ данных и аналитике
Предлагается и реализуется новый подход к анализу данных, который идеологи (и маркетологи!) компании связывают с аббревиатурой MAD. Здесь, конечно, имеется интересная игра слов, которую трудно выразить на русском языке. С одной стороны, mad применительно к технологии означает, что эта технология слегка безумна и уж во всяком случае не ортодоксальна. С другой стороны, mad skills означает блестящие способности, а значит, предлагаемая технология, по мнению ее творцов, обладает новыми полезнейшими качествами. Но в Greenplum MAD – это еще и аббревиатура от magnetic, agile и deep.
- Magnetic (магнетичность) применительно к хранилищу данных означает, что оно должно быть "притягательным" по отношению к новым источникам данных, появляющимся в организации. Данные из новых источников должны легко и просто включаться в хранилище данных с пользой для аналитиков. В отличие от этого, при использовании традиционного ("ортодоксального") подхода к организации хранилища данных, для подключения нового источника данных требуется разработка и применение соответствующей процедуры ETL, а возможно, и изменение схемы хранилища данных, в результате чего подключение нового источника данных часто затягивается на месяца, а иногда и вовсе кончается ничем.
Agile (гибкость) – это предоставляемая аналитикам возможность простым образом и в быстром темпе воспринимать, классифицировать, производить и перерабатывать данные. Для этого требуется база данных, логическая и физическая структура и содержание которой могут постоянно и быстро изменяться. В отличие от этого, традиционным хранилищам данных свойственна жесткость, связанная с потребностью долгосрочного тщательного проектирования и планирования.
Deep (основательность) означает, что аналитикам должны предоставляться средства выполнения произвольно сложных статистических алгоритмов над всеми данными, находящимися в хранилище данных, без потребности во взятии образцов или выборок. Хранилище данных должно служить как основательным репозиторием данных, так и средой, поддерживающей выполнение сложных алгоритмов.
Я не буду больше распространяться здесь про MAD-аналитику (более развернутое обсуждение см. в [28], а остановлюсь только на том аспекте, который привел к реализации системы с поддержкой интерфейсов и SQL, и MapReduce. Как считают разработчики Greenplum Database хозяевами будущего мира анализа данных должны стать аналитики. Фактически, на это направлены все аспекты MAD-аналитики. В частности, это означает всяческую поддержку написания и использования в среде хранилища данных разнообразных аналитических алгоритмов.
Как отмечалось в подразделе 1.1, параллельная СУБД Greenplum Database делалась на основе СУБД PostgreSQL, являющейся законной наследницей Postgres. Помимо своих прочих достоинств, Postgres была первой расширяемой СУБД (этот аспект системы впервые явно подчеркивался в [42]). Пользователи Postgres могли определять собственные процедуры и функции, типы данных и даже методы доступа к структурам внешней памяти. Эти возможности расширений системы были переняты и развиты в PostgreSQL. Наряду с традиционным в Postgres языком C, для программирования серверных расширений в PostgreSQL можно использовать, в частности, популярные скриптовые языки Perl и Python [43].
В Greenplum Database на основе этих возможностей расширений системы обеспечена расширенная среда, позволяющая на уровне языка SQL оперировать такими математическими объектами, как векторы, функции и функционалы. Пользователи могут определять собственные статистические алгоритмы и в полуавтоматическом режиме распараллеливать их выполнение по данным в массивно-параллельной среде (что часто является очень нетривиальной задачей). Однако в любом случае при использовании такого подхода к анализу данных пользователям-аналитикам приходится иметь дело с декларативным языком SQL, а как считают идеологи Greenplum, для многих аналитиков и статистиков SQL-программирование является обременительным и неудобным.
В качестве альтернативы аналитическому SQL-программированию в Greenplum Database обеспечивается полноправная реализация MapReduce, в которой обеспечивается доступ ко всем данным, сохраняемым в хранилище данных. При использовании MapReduce аналитики пишут собственный понятный для них процедурный код (можно использовать те же Perl и Python) и понимают, как будет выполняться их алгоритм в массивно-параллельной среде, поскольку это выполнение опирается на простую модель MapReduce.
3.1.2. Реализация MapReduce в Greenplum Database
Для иллюстрации общей организации Greenplum Database воспользуемся рис. 1, позаимствованным из [44].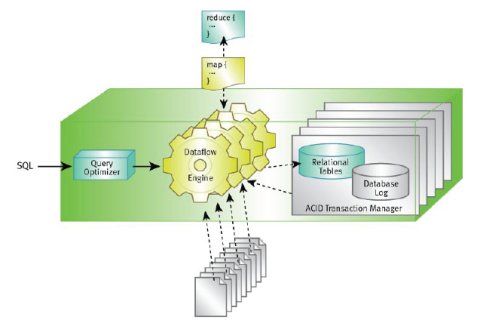
Рис. 1. Общая организация Greenplum Database
Как показывает этот рисунок, ядром системы является процессор потоков данных (Dataflow Engine). С его разработки началась реализация Greenplum Database, причем основные цели состояли в том, чтобы (a) заменить соответствующий компонент ядра PostgreSQL, чтобы обеспечить массивно-параллельное выполнение запросов и (b) обеспечить базовые функциональные возможности, требуемые для поддержки модели MapReduce. В результате SQL-ориентированная СУБД и MapReduce работают с общим ядром, поддерживающим массивно-параллельную обработку данных, и механизмы SQL и MapReduce обладают интероперабельностью.
Как отмечалось выше, функции Map и Reduce в среде Greenplum Database можно программировать на популярных скриптовых языках Python и Perl. В результате оказывается возможным использовать развитые программные средства с открытыми кодами, содержащиеся в репозиториях Python Package Index (PyPi) [45] и Comprehensive Perl Archive Network (CPAN) [46]. В составе этих репозиториев находятся средства анализа неструктурированного текста, статистические инструментальные средства, анализаторы форматов HTML и XML и многие другие программные средства, потенциально полезные аналитикам.
В среде Greenplum Database приложениям MapReduce обеспечивается доступ к данным, хранящимся в файлах, предоставляемым Web-сайтами и даже генерируемым командами операционной системы. Доступ к таким данным не влечет накладных расходов, ассоциируемых с использованием СУБД: блокировок, журнализации, фиксации транзакций и т.д. С другой стороны, эффективный доступ к данным, хранимым в базе данных, поддерживается за счет выполнения MR-программ в ядре Greenplum Database. Это позволяет избежать расходов на пересылку данных.
Архитектура Greenplum Database с равноправной поддержкой SQL и MapReduce позволяет смешивать стили программирования, делать MR-программы видимыми для SQL-запросов и наоборот. Например, можно выполнять MR-программы над таблицами базы данных. Для этого всего лишь требуется указать MapReduce, что входные данные программы должны браться из таблицы. Поскольку таблицы баз данных Greenplum Database хранятся разделенными между несколькими узлами кластера, первая фаза MAP выполняется внутри ядра СУБД прямо над этими разделами.
Как и в автономных реализациях MapReduce, результаты выполнения MR-программ могут сохраняться в файловой системе. Но настолько же просто сохранить результирующие данные в базе данных с обеспечением транзакционной долговечности хранения этих данных (см. компонент ACID Transaction Manager на рис. 1). В дальнейшем эти данные могут анализироваться, например, с применением SQL-запросов. Запись результирующих данных в таблицы происходит параллельным образом и не вызывает лишних накладных расходов.
Поскольку источником входных данных для MR-программы может служить любая таблица базы данных Greenplum, в частности, в качестве такой таблицы можно использовать представление базы данных, определенное средствами SQL. И наоборот, MR-программу можно зарегистрировать в базе данных как представление, к которому можно адресовать SQL-запросы. В этом случае MR-задание выполняется "на лету" во время обработки SQL-запроса, и результрующие данные в конвейерном режиме передаются прямо в план выполнения запроса.