СУБД с хранением данных по столбцами и по строкам: насколько они отличаются в действительности?
Дэниэль Абади, Сэмюэль Мэдден, Набил Хачем
Пересказ: Сергей Кузнецов
6.3. Производительность C-Store
Беглый взгляд на среднее время выполнения запросов SSBM (около 4 секунд) в C-Store сразу позволяет понять, что эта система работает быстрее не только колоночных хранилищ, моделируемых в строчном хранилище (от 80 до 220 секунд), то также и наилучших для строчного хранилища сценариев, когда запросы известны заранее, и в строчном хранилище созданы материализованные представления, подогнанные под планы выполнения запросов (10.2 секунд). Эту разницу в производительности можно частично объяснить безо всяких экспериментов – в колоночных хранилищах отсутствуют покортежные накладные расходы, и не требуются соединения столбцов (это более подробно объясняется в п. 6.3.1). Однако это наблюдение не объясняет причину того, что колоночное хранилище оказывается быстрее варианта с материализованными представлениями (случая CS Row-MV из подраздела 6.1), в котором имеется аналогичный объем ввода-вывода, и в обеих системах не требуется соединение столбцов одной и той же таблицы. Чтобы понять, откуда взялась эта разница в производительности, авторы выполнили ряд дополнительных экспериментов с использованием колоночного хранилища, из которого последовательно удалялись специфические для этой организации оптимизации до тех пор, пока колоночное хранилище не начало моделировать строчное хранилище. Таким образом, удалось исследовать влияние этих разнообразных оптимизаций на эффективность обработки запросов. Эти результаты представлены в п. 6.3.2.
6.3.1. Покортежные накладные расходы и стоимость соединений
В современных колоночных хранилищах явно не сохраняются идентификаторы записей (или первичные ключи), требуемые для соединения столбцов одной и той же таблицы. Вместо этого для реконструкции кортежей используются неявные позиции значений в столбцах (i-тое значение из каждого столбца принадлежит i-тому кортежу таблицы). Кроме того, заголовки кортежей хранятся в собственных отдельных столбцах, так что к ним возможен доступ отдельно от реальных значений столбцов. Следовательно, столбец в колоночном хранилище содержит только соответствующие данные, а не заголовок кортежа, идентификатор записи и данные, как это происходит в вертикально разделенном строчном хранилище.
В колоночном хранилище файлы данных хранятся в порядке позиций (i-тое значение всегда располагается за (i-1)-м значением), в то время как порядок в файлах данных многих строчных хранилищ (даже кластеризованных по некотором атрибуту) гарантируется только при доступе через некоторый индекс. Очевидно, что это приводит к предпочтительности использования для реконструкции кортежей в колоночном хранилище соединения со слиянием (без сортировки). В строчном хранилище слияние на основе индексов является медленным способом реконструкции кортежей, поскольку итерирование отсортированного файла должно производиться через индекс, что может приводить к дополнительному передвижению дисковых головок при переходе от одного листа индекса к другому.
Следует заметить, что ни одно из упомянутых выше различий не является фундаментальным. Нет причин, по которым в строчном хранилище нельзя было бы отдельно хранить заголовки кортежей, использовать виртуальные идентификаторы записей для соединения данных и поддерживать файлы данных в позиционном порядке. Приведенное наблюдение всего лишь выделяет некоторые важные реализационные соображения, которые были бы уместны при желании построить строчное хранилище, успешно моделирующее колоночное хранилище.
6.3.2. Анализ преимуществ колоночных хранилищ
Как говорилось в разд. 5, все три оптимизации, ориентированные на системы с хранением данных по столбцам, существенно повышают производительность соответствующих систем баз данных. Это сжатие, отложенная материализация и итерация по блокам. Кроме того, авторы расширили возможности C-Store методом скрытых соединений, который, как они ожидали, также будет способствовать повышению производительности. По-видимому, именно эти оптимизации являются причиной показанного на рис. 5 различия в производительности между колоночным хранилищем и вариантом строчного хранилища с материализованными представлениями, для которого имелся такой же объем ввода-вывода, что и для колоночного хранилища. Чтобы проверить это предположение, авторы последовательно удаляли оптимизации из базового варианта C-Store и после каждого шага измеряли производительность.
Удалить сжатие из C-Store было просто, поскольку в C-Store имеется специальный флаг, управляющий включением и отключением этого режима. Удалить метод скрытого соединения было тоже просто, потому что это новая операция, включенная в систему самими авторами. Для удаления отложенной материализации авторам пришлось вручную кодировать планы запросов, чтобы кортежи конструировались в начале выполнения плана. Удалить итерацию по блокам оказалось несколько труднее, чем перечисленные три оптимизации. В C-Store доступ к данным возможен через два интерфейса: «getNext» и «asArray». При применении первого метода требуется вызов функции для каждого очередного значения, в то время как во втором случае возвращается указатель на массив, который можно итерировать напрямую. Для операций, используемых в планах запросов SSBM и производящих доступ к блокам через интерфейс «asArray», авторы написали их альтернативные версии с использованием «getNext». Это привело только к существенному замедлению выполнения операций ограничения.
На рис. 7(a) показаны детальные (для каждого запроса) результаты последовательного удаления этих оптимизаций из C-Store; на рис. 7(b) эти результаты усреднены по всем запросам SSBM. Блочная обработка может повысить производительность на 5-50% в зависимости от того, было ли уже удалено сжатие (если сжатие удалено, то выигрыш во времени процессора не так существенен, поскольку основным фактором производительности становится ввод-вывод). В других системах, таких как MonetDB/X100, более тщательно оптимизированных для обработки данных блоками [9], можно было бы ожидать большей деградации производительности при удалении этой оптимизации.
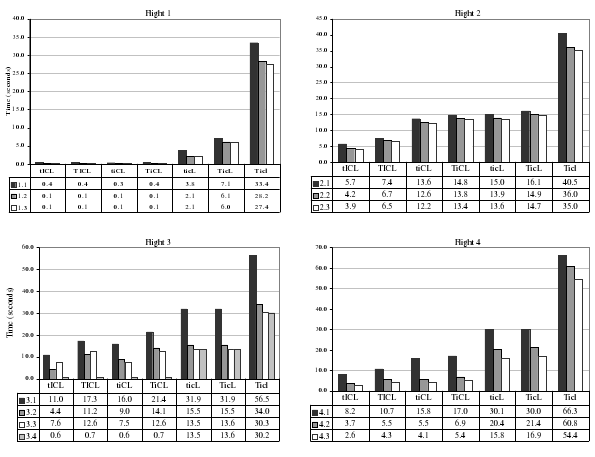
Рис. 7(a). Показатели производительности C-Store для каждого звена запросов при удалении различных оптимизаций. Используемые четыре буквы показывают конфигурацию C-Store: T – покортежная обработка, t – блочная обработка, I – скрытые соединения разрешены, i – скрытые соединения запрещены, C – сжатие разрешено, c – сжатие запрещено, L – отложенная материализация разрешена, l – отложенная материализация запрещена.
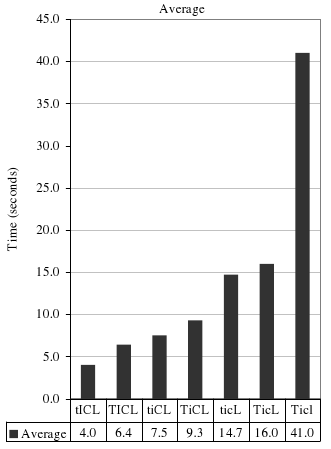
Рис. 7(b). Усредненные показатели производительности C-Store для всех запросов.
Скрытое соединение повышает производительность на 50-75%. Поскольку в C-Store используется аналогичный метод «отложенной материализации соединений», это различие в производительности в большей степени обязано оптимизации «переписи в предикат between». В SSBM имеется много случаев, в которых можно применить эту оптимизацию. В таблице SUPPLIER столбцы region, nation и city являются атрибутами с повышающимся уровнем детализации, что, как говорилось в подразделе 5.4, приводит к выработке непрерывных позиционных множеств при применении атрибута сравнения по равенству к любому из этих столбцов. Аналогичные столбцы region, nation и city имеются и в таблице CUSTOMER. В таблице PART атрибутами с повышающимся уровнем детализации являются mfgr, category и brand1. Наконец, в таблице DATE такими атрибутами являются year, yearmonth и date. В каждом запросе SSBM содержится не менее одного соединения (во всех запросах, кроме первого, содержится больше одного соединения), и для каждого запроса, по крайней мере, одно соединение производится с таблицей измерений, для которой имеется предикат на одном из этих специальных типов атрибутов. Следовательно, оптимизацию «перепись в предикат between» можно было использовать не менее одного раза для каждого запроса.
Понятно, что наиболее существенными оптимизациями являются сжатие и отложенная материализация. Сжатие повышает производительность в среднем в два раза. Однако, как отмечалось в разд. 5, авторы не поддерживают избыточного хранения таблицы фактов с несколькими порядками сортировки для получения полного преимущества от сжатия (отсортирован только один столбец – orderdate, и два столбца – quantity и discount – вторично отсортированы). Столбцы таблицы фактов, используемые в запросах SSBM, не очень хорошо сжимаются, если они не упорядочены, поскольку они являются либо ключами (и их множество обладает большой мощностью), либо случайными значениями. Первое звено запросов, в котором имеется доступ ко всем трем упорядоченным столбцам, демонстрирует преимущество по производительности, получаемое при использовании в запросах сильно сжатых столбцов.
В этом случае сжатие приводит к повышению производительности на порядок. Так происходит из-за того, что последовательности значений в этих упорядоченных столбцах могут быть продольно закодированы (run length encoded, RLE). Продольное кодирование не только обеспечивает хороший коэффициент сжатия и, тем самым, сокращает накладные расходы ввода-вывода, но также и позволяет очень просто выполнять операции над сжатыми данными (например, предикат или агрегатную функцию можно применить сразу ко всей последовательности). Первично отсортированный столбец orderdate содержит всего 2405 уникальных значений, и поэтому средняя длина последовательности для этого столбца составляет 25000. Для его хранения требуется менее 64 килобайт дискового пространства.
Другой существенной оптимизацией является отложенная материализация. Эта оптимизация удалялась последней, поскольку в процессе конструирования кортежей данные требуется распаковывать, и ранняя материализация приводит к выполнению, ориентированному на строки, что препятствует применению скрытых соединений. Отложенная материализация обеспечивает почти трехкратное повышение производительности. Так происходит, прежде всего, из-за селективных предикатов в некоторых запросах SSBM. Чем более селективен предикат, тем расточительнее конструировать кортежи в начале выполнения плана запроса, поскольку большинство этих кортежей немедленно отфильтруется.
Заметим, что после удаления всех оптимизаций колоночное хранилище ведет себя подобно строчному хранилищу. Столбцы немедленно «сшиваются» и обрабатываются после этого так же, как в строчном хранилище. Поэтому можно было бы ожидать, что колоночное хранилище будет выполнять запросы подобно строчному хранилищу с материализованными представлениями, поскольку требования к вводу-выводу и обработка запросов у них аналогичны – единственным различием является необходимость конструирования кортежей в начале выполнения плана запроса в колоночном хранилище. В подразделе 6.1 авторы предостерегали против прямых сравнений с System X, но при сравнении этих показателей со случаем CS Row-MV с рис. 5 можно видеть, насколько дорогостоящим может быть конструирование кортежей. Это согласуется с предыдущими результатами авторов.
6.3.3. Следствия эффективности соединений
При профилировании кода авторы заметили, что в случае базового варианта C-Store основная часть команд выполняется на ранних стадиях плана (применение предикатов), и что использование метода скрытых соединений делает выполнение соединений осносительно дешевым. Для дальнейшего анализа этого наблюдения была создана денормализованая версия таблицы фактов, в которой таблица фактов и ее таблицы измерений были заранее соединены, так что вместо внешнего ключа к таблице измерений таблица фактов содержала все значения таблицы измерений, повторяющиеся для каждой записи таблицы фактов (например, вся информация о заказчике содержится к каждом кортеже таблицы фактов, соответствующем заказу, который сделал этот заказчик). Понятно, что в строчном хранилище эта полная денормализация была бы более пагубной с точки зрения производительности, поскольку привела бы к существенному расширению таблицы. Однако можно было бы ожидать, что это ускорит выполнение запросов в колоночном хранилище, поскольку нужно было бы считывать только столбцы, имеющие отношение к запросу, и можно было бы избежать выполнения соединений.
К своему удивлению, авторы обнаружили, что часто эти ожидания не оправдываются. На рис. 8 сравнивается производительность варианта C-Store с использованием скрытых соединений, обсуждавшегося в предыдущем пункте, с производительностью на том же рабочем наборе трех вариантов единой денормализованной таблицы, для которой соединения были выполнены заранее. В первом случае в денормализованную таблицу включались без изменения полные строки, такие как названия регионов и стран. В этом случае производительность оказалась в пять раз ниже производительности базового варианта. Это связано с тем, что скрытое соединение преобразует предикаты на атрибутах таблицы измерений в предикаты на значениях внешнего ключа таблицы фактов. Когда таблица денормализуется, предикаты применяются к реальному атрибуту символьных строк таблицы фактов. В обоих случаях применение предиката является доминирующим шагом. Однако предикат на целочисленном внешнем ключе может вычисляться быстрее предиката на атрибуте со значениями-строками символов, поскольку целочисленный атрибут короче.
Конечно, атрибуты типа символьных строк можно было бы легко перекодировать по словарю в целые числа до денормализации. Когда авторы проделали это (случай «PJ, Int C» на рис. 8), разница в производительности между базовым и денормализованным вариантами стала гораздо меньше. Тем не менее, для довольно многих запросов базовый вариант по-прежнему работал быстрее. Для этого имеются две причины. Во-первых, в некоторых запросах SSBM присутствуют два предиката на одной таблице измерений. Метод скрытых соединений может обобщить результат этого двойного применения предиката как один предикат на атрибуте внешнего ключа таблицы фактов. Однако в денормализованном варианте предикаты должны полностью применяться к обоим столбцам таблицы фактов (напомним, что в хранилищах данных таблица фактов, вообще говоря, гораздо крупнее таблиц измерений, и поэтому применение предикатов к таблице фактов обходится намного дороже, чем их применение к таблице измерений).
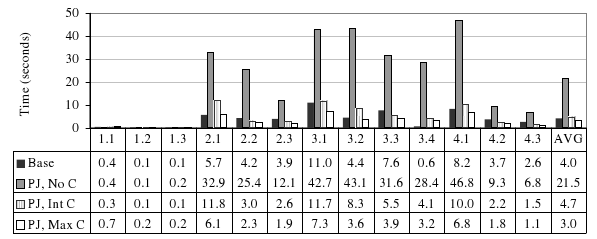
Рис. 8. Сравнение производительности основного варианта C-Store с исходной схемой базы данных SSBM с той же C-Store с денормализованным вариантом схемы. Денормализованные столбцы могут быть несжатыми («PJ, No C»), сжатыми по словарю в целые числа («PJ, Int C») или предельно сжатыми («PJ, Max C»).
Во-вторых, во многих запросах имеются предикат на одном атрибуте таблицы измерений и группировка по другому атрибуту той же таблицы измерений. При использовании скрытого соединения для этого требуется одна итерация по столбцу внешнего ключа для применения предиката и еще одна итерация (после применения всех предикатов из всех таблиц и выполнения пересечения) для извлечения атрибута группировки. Но, поскольку в C-Store используется конвейерное исполнение, ко времени второго доступа блоки значений столбца внешнего ключа останутся в основной памяти. В денормализованном случае столбец предиката и столбец группировки являются разными столбцами таблицы фактов, и по ним обоим требуется производить итерирование, что удваивает объем требуемого ввода-вывода.
В действительности, многие столбцы таблиц измерений базы данных SSBM содержат достаточно мало значений, и их можно сжать до размеров, меньших размеров целочисленных внешних ключей. При использовании в S-Store полного сжатия метод денормализации оказался полезным в большем числе случаев (что показано на рис. 8 как случай «PJ, Max C»).
У этих результатов имеются интересные следствия. Денормализация в течение долгого времени использовалась в системах баз данных для повышения эффективности выполнения запросов за счет уменьшения числа соединений во время исполнения. Вообще говоря, школа мудрости учит нас, что при денормализации за эффективность выполнения запросов приходится платить расширением таблицы и повышением уровня избыточности данных (увеличением размера таблицы на диске и повышением риска появления аномалий обновлений). Можно было бы ожидать, что этот компромисс будет более благоприятным для колоночного хранилища (и денормализация будет использоваться более часто), поскольку при использовании схемы хранения по столбцам перестает быть проблемой один из недостатков денормализации – расширение таблицы. Однако результаты авторов показывают нечто противоположное: денормализация не слишком полезна в колоночных хранилищах (по крайней мере, при использовании звездообразных схем). Это объясняется тем, что скрытые соединения выполняются настолько хорошо, что сокращение числа соединений путем денормализации не дает существенного выигрыша. На самом деле, похоже, что денормализация полезна только в тех случаях, когда атрибуты таблицы измерений, включаемые в таблицу фактов, отсортированы (либо вторично отсортированы) или могут быть сильно сжаты.
7. Заключение
В этой статье сравнивается производительность C-Store и нескольких вариантов коммерческого строчного хранилища на тестовом наборе хранилищ данных SSBM. Авторы показали, что попытки эмулировать физическую схему колоночного хранилища в строчном хранилище на основе методов вертикального разделения и доступа только к индексам не приводят к хорошей производительности. Авторы объясняют это высокой стоимостью реконструкции кортежей, а также высокими покортежными накладными расходами в узких вертикально разделенных таблицах. Проанализированы причины, по которым колоночное хранилище может настолько эффективно обрабатывать данные, ориентированные на хранение в столбцах. Обнаружено, что отложенная материализация повышает производительность в три раза, сжатие – в среднем почти в два раза (и на десятичный порядок на запросах, обращающихся к отсортированным данным). Также предложен новый метод соединения, названный скрытым соединением, который позволяет повысить производительность еще на 50%.
Авторы не утверждают, что моделировать колоночное хранилище в строчном хранилище невозможно. Они говорят лишь о том, что подобные варианты организации данных показывают плохую производительность при использовании сегодняшних строчных хранилищ (в экспериментах авторов использовался один из последних релизов System X). Для успешного моделирования колоночного хранилища потребуются существенные усовершенствования базовой системы, такие как введение виртуальные идентификаторы кортежей, сокращение покортежных накладных расходов, использование продольного кодирования для нескольких кортежей и применение некоторых ориентированных на столбцы методов выполнения запросов: выполнение операций прямо над сжатыми данными, блочная обработка, скрытые соединения и отложенная материализация. Некоторые из этих усовершенствований реализованы или намечены к реализации в различных строчных хранилищах [12, 13, 20, 24]. Однако построение полного строчного хранилища, которое может работать как колоночное хранилище на соответствующих рабочих нагрузках, представляется авторам интересной исследовательской проблемой.
8. Благодарности
Авторы благодарны Ставросу Харизопулосу (Stavros Harizopoulos) за его комментарии к этой статье и Национальному научному фонду (NSF) за финансирование данного исследования по грантам 0704424 и 0325525.
9. Оценка повторяемости результатов
Все рисунки, содержащие числовые показатели, полученные на основе экспериментов с прототипом C-Store (рис. 7a, рис. 7b и рис. 8), проверены комитетом по проверке повторяемости результатов SIGMOD. Авторы благодарны Иоанне Манолеску и комитету по проверке повторяемости результатов за их отзывы.