СУБД с хранением данных по столбцами и по строкам: насколько они отличаются в действительности?
Дэниэль Абади, Сэмюэль Мэдден, Набил Хачем
Пересказ: Сергей Кузнецов
5.4. Скрытое соединение
Запросы к хранилищам данным, в частности, к хранилищам данных со звездообразной схемой часто имеют следующую структуру: ограничить множество кортежей в таблице фактов, используя предикаты ограничения над одной или несколькими таблицах измерений; затем выполнить некоторое агрегирование ограниченной таблицы фактов, часто с группировкой по атрибутам другой таблицы измерений. Таким образом, требуется выполнять соединения таблицы фактов и таблиц измерений для каждого предиката и каждой агрегатной группировки. Хорошим примером является Запрос 3.1 из Star Schema Benchmark.
SELECT c.nation, s.nation, d.year,
sum(lo.revenue) as revenue
FROM customer AS c, lineorder AS lo,
supplier AS s, dwdate AS d
WHERE lo.custkey = c.custkey
AND lo.suppkey = s.suppkey
AND lo.orderdate = d.datekey
AND c.region = 'ASIA'
AND s.region = 'ASIA'
AND d.year >= 1992 and d.year <= 1997
GROUP BY c.nation, s.nation, d.year
ORDER BY d.year asc, revenue desc;
Этот запрос находит величины общего дохода от заказчиков, проживающих в Азии и покупавших некоторый продукт, который поставлялся азиатским поставщиком, в период между 1992-м и 1997-м гг.. Эти величины группируются по стране заказчика, стране поставщика и году выполнения данной транзакции.
Традиционный план выполнения таких типов запросов состоит в организации конвейера соединений в порядке уменьшения селективности предикатов. Например, если c.region = ‘ASIA’ является наиболее селективным предикатом, то первым будет выполняться соединение таблиц LINEORDER и CUSTOMER по столбцу custkey, ограничивая таблицу LINEORDER таким образом, что в ней останутся только заказы от азиатских заказчиков. После выполнения этого соединения к соединенной таблице customer-order добавляется столбец nation. Эти результаты отправляются по конвейеру в операцию соединения с таблицей SUPPLIER, где применяется предикат s.region = ‘ASIA’ и выбирается s.nation. За этим следует соединение с таблицей DATE, к которой применяется предикат, ограничивающий временной период. Результаты этих соединений группируются, вычисляется агрегатная функция, и полученные кортежи сортируются в соответствии со спецификацией раздела ORDER BY.
В качестве альтернативы традиционному плану можно использовать метод отложенной материализации соединений [5]. В этом случае к столбцу c.region применяется предикат c.region = ‘ASIA’, и из ограниченной таблицы CUSTOMER извлекаются значения столбца custkey. Затем эти ключи соединяются со столбцом custkey таблицы фактов. Результатом этого соединения являются два набора позиций – один для таблицы фактов, другой для таблицы измерений. Эти наборы позиций показывают, какие пары кортежей соответствующих таблиц прошли через предикат соединения. Вообще говоря, не более чем один из этих наборов является упорядоченным списком (набор позиций внешней таблицы соединения, обычно таблицы фактов). Затем по неотсортированному набору позиций извлекаются значения из столбца c.nation, а по отсортированному списку позиций – значения других столбцов таблицы фактов (suppkey, orderdate и revenue). Аналогичные соединения выполняются с таблицами SUPPLIER и DATE.
У каждого из этих планов имеются свои недостатки. В первом (традиционном) случае конструирование кортежей до выполнения соединений сводит на нет все преимущества отложенной материализации, описанные в подразделе 5.2. Во втором случае требуется извлекать значения из таблицы размерностей не в порядке позиций, что вызывает значительные накладные расходы [5].
В качестве альтернативы этих планов авторы предлагают метод, названный ими методом скрытых соединений, который можно использовать в системах баз данных с хранением данных по столбцам для соединений внешний-ключ/первичный-ключ таблиц в базе данных со звездообразной схемой. Это соединение с отложенной материализацией, но в нем минимизируется число значений, которые требуется извлекать не в порядке позиций. Тем самым, метод устраняет оба отмеченных выше недостатка. Метод основывается на переписи соединений в предикаты на столбцах внешних ключей таблицы фактов. Эти предикаты могут вычисляться либо путем использования хэш-поиска (в этом случае моделируется хэш-соединение), либо на основе более совершенных методов, таких как метод, называемый авторами переписыванием в предикат between и обсуждаемый в п. 5.4.2.
За счет переписи соединений в виде предикатов ограничения на столбцах таблицы фактов они могут выполняться в то же время, что и другие предикаты ограничения, которые применяются к таблице фактов, и можно использовать любой алгоритм применения предикатов, описанный в предыдущей статье авторов [5]. Например, все предикаты могут применяться параллельно, а результаты – сливаться с использованием быстрых операций над битовыми строками. Или же результаты применения одного предиката могут передаваться по конвейеру в операцию применения другого предиката для сокращения числа вычислений второго предиката. Только после применения всех предикатов соответствующие кортежи извлекаются из таблиц измерений, имеющих отношение к данному запросу (это также можно делать параллельно). За счет откладывания извлечения данных из таблиц измерений минимизируется число выборок, производимых не в порядке позиций.
Метод скрытых соединений расширяет результаты предыдущих работ по повышению эффективности соединений в звездообразных схемах [17, 23] (напоминающих методы полусоединений [8]) за счет использования преимуществ колоночной организации базы данных и методов переписи предикатов, позволяющих избежать хэш-поиска.
5.4.1. Детали соединений
При использовании метода скрытых соединений соединения выполняются в три этапа. Сначала каждый предикат применяется к соответствующей таблице измерений для извлечения списка ключей таблицы измерений, удовлетворяющих данному предикату. Эти ключи используются для построения хэш-таблицы, которую можно использовать для проверки того, удовлетворяет ли предикату некоторое значение ключа (эта хэш-таблица должна легко поместиться в основной памяти, поскольку таблицы измерений обычно являются небольшими, и хэш-таблица содержит только ключи). Пример выполнения этого первого этапа для приведенного выше запроса на некоторых примерных данных показан на рис. 2.
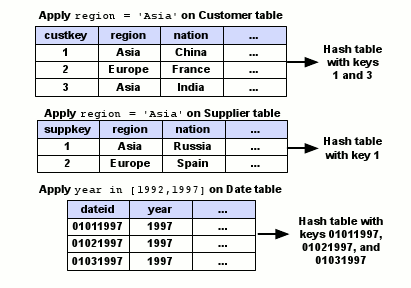
Рис. 2. Первый этап выполнения соединений, требуемых для обработки Запроса 3.1 из SSBM на некоторых примерных данных
На следующем этапе эти хэш-таблицы используются для извлечения позиций тех записей из таблицы фактов, которые удовлетворяют соответствующему предикату. Это делается путем поиска в хэш-таблице каждого значения столбца внешнего ключа таблицы фактов и создания списка всех позиций в этом столбце внешнего ключа, значения которых удовлетворяют предикату. Затем списки позиций от всех предикатов пересекаются, и генерируется список позиций P таблицы фактов, значения которых удовлетворяют всем предикатам. Пример выполнения этого второго этапа показан на рис. 3. Заметим, что список позиций может быть явным списком позиций или же битовой строкой, как показано в примере.
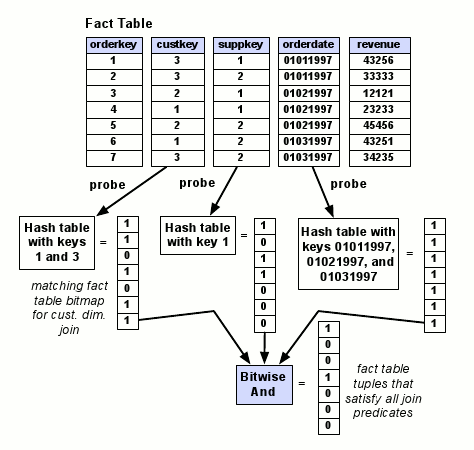
Рис. 3. Второй этап выполнения соединений, требуемых для обработки Запроса 3.1 из SSBM на некоторых примерных данных
На третьем этапе соединения используется список P позиций таблицы фактов, значения которых удовлетворяют всем предикатам. Для каждого столбца C, являющегося внешним ключом к некоторой таблице измерений, данные которой требуются для формирования результата запроса (например, ссылка на столбец этой таблицы измерений имеется в списке выборки, разделе GROUP BY или в вызове агрегатной функции), значения внешнего ключа из C выбираются с использованием P, и производится поиск в соответствующей таблице измерений. Заметим, что если ключи таблицы измерений образуют отсортированный, непрерывный список идентификаторов, начинающийся с единицы (что является распространенным случаем), то значение внешнего ключа в действительности задает позицию нужного кортежа в таблице измерений. Это означает, что требуемые столбцы таблицы измерений могут быть извлечены напрямую с использованием этого списка позиций (и это просто быстрый поиск в массиве).
Эта прямая выборка из массива (наряду с тем фактом, что таблицы размерностей обычно являются небольшими, так что столбец, в котором осуществляется поиск, часто может поместиться в кэше L2) является причиной того, что методу скрытых соединений не присущи описанные выше недостатки подходов соединений с отложенной материализацией [5], где завершающая беспорядочная выборка по списку позиций является очень дорогостоящей. Кроме того, минимизируется число значений, которые требуется выбирать, поскольку число позиций в списке P зависит от селективности всего запроса, а не только той части, которая была выполнена к моменту выборки.
Пример выполнения этого третьего этапа показан на рис. 4. Заметим, что для таблицы DATE столбец ключа не является отсортированным непрерывным списком, начинающимся с единицы, так что для него требуется выполнять полное соединение (а не всего лишь позиционную выборку). Заметим также, что, поскольку это соединение вида внешний-ключ/первичный-ключ, и все предикаты уже применены, гарантируется, что в каждой таблице измерений для каждой позиции окончательного списка позиций таблицы фактов будет обнаружен один и только один результат. Это означает, что на этом третьем этапе при соединении с каждой таблицей измерений получается одно и то же число результатов, так что каждое соединение может выполняться по отдельности, и результаты могут объединяться (сшиваться) в более поздней точке плана выполнения запроса.

Рис. 4. Третий этап выполнения соединений, требуемых для обработки Запроса 3.1 из SSBM на некоторых примерных данных
5.4.2. Перезапись в предикат between
Алгоритм скрытых соединений в том виде, как он описан выше, во многом заимствует идеи полусоединения с учетом хранения данных по столбцам и хэш-соединения с отложенной материализацией. Хотя в методе скрытых соединений хэш-часть соединения выражается в виде предиката на столбце таблицы фактов, способы вычисления этого предиката и выполнения хэш-соединения (с отложенной материализацией) практически почти не различаются. Преимущество от представления соединения в виде предиката становится существенным в очень распространенном случае (для соединений в базе данных со звездообразной схемой), когда множество ключей в таблице измерений, остающееся после применения предиката, является непрерывным. В этом случае можно использовать метод, называемый авторами перезаписью в предикат between, когда предикат на таблице фактов, вычисляемый на основе хэш-поиска, переписывается в предикат between, ограничивающий внешний ключ диапазоном значений. Например, если непрерывным множеством значений ключа после применения предиката является отрезок [1000, 2000], то вместо вставки каждого из этих ключей в хэш-таблицу и проверки на основе этой хэш-таблицы каждого значения внешнего ключа таблицы фактов можно просто проверять вхождение очередного значения внешнего ключа в этот отрезок. Если эта проверка удается, соответствующий кортеж входит в результат соединения, иначе – нет. Очевидно, что предикаты between обрабатываются быстрее, поскольку для этого не требуется какой-либо поиск.
Возможность применения этой оптимизации зависит от того, непрерывны ли множества допустимых ключей таблиц измерений. Во многих случаях это свойство не выполняется. Например, при применении к неотсортированному полю предиката, задающего условие вхождения в диапазон значений, получается не непрерывное множество позиций. И даже для предикатов на отсортированных полях процесс сортировки таблицы измерений по такому атрибуту, вероятно, переупорядочит первичные ключи, так что они перестанут образовывать упорядоченное, непрерывное множество идентификаторов. Однако последнюю проблему легко преодолеть за счет использования кодирования по словарю (dictionary encoding) с целью переназначения ключей (а не сжатия). Поскольку ключи уникальны, кодирование столбца по словарю приводит к тому, что словарные ключи образуют упорядоченный, непрерывный список, начинающийся с нуля. Если столбец внешнего ключа таблицы фактов кодируется с использованием той же словарной таблицы, то можно производить перепись предиката с поиском по хэш-таблице в предикат between.
Кроме того, утверждение, что эта оптимизация работает только для предикатов на отсортированном столбце таблицы измерений, является не совсем верным. На самом деле, таблицы измерений в хранилище данных часто содержат наборы атрибутов с повышающимися уровнями детализации. Например, в таблице DATE базы данных SSBM имеются столбцы year, yearmonth и столбец полной даты date. Если таблица отсортирована по столбцу year, вторично отсортирована по столбцу yearmonth и на третьем уровне отсортирована по полной дате, то применение предиката сравнения по равенству к любому из этих трех столбцов приведет к формированию непрерывного набора результатов (или предиката проверки вхождения в диапазон значений на отсортированном столбце). Другой пример: в таблице SUPPLIER имеются столбцы region, nation, и city (в регион входит много стран, а в стране имеется много городов). Снова при сортировке слева направо применение предиката к любому из этих трех столбцов приведет к формированию непрерывного диапазона. В запросах к хранилищу данных часто используются такие столбцы, поскольку распространенной практикой OLAP является детализация данных при последовательном применении запросов (получить величину прибыли по регионам, получить величину прибыли по странам, получить величину прибыли по городам). Таким образом, перезапись в предикат between может использоваться чаще, чем может показаться сначала, и часто приводит к существенному выигрышу в производительности (что демонстрируется в следующем разделе).
Заметим, что для применения этого вида оптимизации не требуется изменять оптимизатор запросов. При вычислении предикатов над таблицами измерений можно проверить, является ли результирующее множество непрерывным. Если это так, то предикат над таблицей фактов переписывается во время выполнения.