СУБД с хранением данных по столбцами и по строкам: насколько они отличаются в действительности?
Дэниэль Абади, Сэмюэль Мэдден, Набил Хачем
Пересказ: Сергей Кузнецов
2. Предыдущие работы
В этом разделе авторы приводят краткий обзор предыдущих родственных работ, в которых сравнивалась производительность колоночных и строчных хранилищ. Хотя идея вертикального разделения таблиц базы данных для повышения производительности была популярна в течение долгого времени [1, 7, 16], разработка современных систем баз данных, ориентированных на хранение данных по столбцам, и методов векторизованного выполнения запросов началась с проектов MonetDB [10] и MonetDB/X100 [9]. Эти проекты показали, что системы, ориентированные на хранение по столбцам, благодаря более эффективному использованию процессора и кэша (в дополнение к сокращенному объему ввода-вывода), могут на тестовых наборах типа TPC-H значительно превосходить в производительности коммерческие и доступные в исходных кодах СУБД. Однако в исследованиях, связанных с MonetDB, не предпринимались попытки оценить, какую производительность могли бы показать строчные хранилища при использовании методов, ориентированных на работу со столбцами, и, насколько это известно авторам данной статьи, оптимизации, применяемые в MonetDB, никогда не оценивались в том же контексте, как оптимизация C-Store для выполнения операций напрямую над сжатыми данными.
В другой недавней системе с хранением данных по столбцам применяется подход «треснувшего заркала» (fractured mirror) [21]. Здесь используется гибридная схема с поддержкой и строчного, и колоночного хранилищ. В строчном хранилище, главным образом, обрабатываются обновления базы данных, а над колоночным хранилищем выполняются операции чтения. Фоновый процесс переносит измененные данные из строчного хранилища в колоночное. В этом проекте также исследовалось несколько представлений данных для поддержки стратегии полного вертикального разделения в строчном хранилище (Shore). Авторы пришли к выводу, что существенной проблемой являются накладные расходы на поддержку кортежей, и что для сокращения времени реконструкции кортежей разумно производить упреждающее чтение с диска крупных блоков колоночных данных.
C-Store – это более молодая СУБД, поддерживающая хранение данных в столбцах. В ней поддерживаются многие возможности, присутствующие в MonetDB/X100, а также используются оптимизации для выполнения операций прямо над сжатыми данными [4]. Как и в случае двух ранее упоминавшихся проектов, проект C-Store показывает, что колоночное хранилище может существенно превзойти по производительности строчное хранилище на рабочих нагрузках хранилищ данных, но и в этом проекте раньше не исследовались возможные варианты организации физических схем баз данных с хранением по строкам. В данной статье авторы анализируют производительность C-Store, отмечая, как различные оптимизации, предложенные в литературе (например, [4, 5]), способствуют общей производительности системы по сравнению со строчным хранилищем на полном тестовом наборе хранилищ данных. Это также не делалось в предыдущих работах, посвященных C-Store.
В [14] Харизопулос и др. сравнивают производительность строчного и колоночного хранилищ, построенных с нуля, изучая простые планы, в соответствии с которыми данные последовательно считываются с диска, и немедленно реконструируются кортежи («ранняя материализация»). Эта работа демонстрирует, что в тщательно управляемой среде с использованием простых планов колоночные хранилища превосходят по производительности строчные хранилища в пропорции, зависящей от доли столбцов таблицы, считываемых с диска. Но в этой работе не обсуждались ни оптимизации, позволяющие повысить производительность строчных хранилищ, ни развитые методы повышения производительности колоночных хранилищ.
В [13] Хальверсон и др. описывают реализацию колоночного хранилища в Shore и сравнивают исходную (основанную на хранении данных по строкам) версию Shore с вариантом системы, в котором использовалось вертикальное разделение таблиц. В этой работе предлагается оптимизация, называемая «супертаблицами» («super tuples»), которая позволяет избежать дублирования информации о заголовках таблиц и приводит к группировке кортежей в блоки. В результате сокращаются накладные расходы на поддержку полностью разделенной схемы, и на использованных авторами тестовых наборах система вертикально разделенных баз данных успешно конкурирует по производительности с колоночным хранилищем. Авторы приходят к выводу, что оптимизации, подобные введению «супертаблиц», потребуются в строчных хранилищах при их использовании для эмуляции колоночных хранилищ. Однако в этой статье не исследуются преимущества многих последних оптимизаций колоночных хранилищ, включая различные методы сжатия и отложенную материализацию.
3. Тестовый набор Star Schema Benchmark
В этой работе для сравнения производительности C-Store и коммерческого строчного хранилища используется тестовый набор Star Schema Benchmark (SSBM) [18, 19].
SSBM – это тестовый набор хранилищ данных, происходящий от TPC-H. В отличие от TPC-H, в нем используется классическая звездообразная схема (являющаяся установившейся практикой организации данных в хранилищах данных). В SSBM также содержится меньшее число запросов, чем в TPC-H, и ослаблены требования к допустимым настройкам системы. Авторы выбрали этот тестовый набор, потому что его проще реализовать, чем TPC-H, и для его запуска не требовалось модифицировать C-Store (а для запуска полного тестового набора TPC-H это пришлось бы делать).
Схема. База данных SSBM состоит из одной таблицы фактов LINEORDER, в которой объединяются таблицы LINEITEM and ORDERS TPC-H. В таблице имеется 17 столбцов, содержащих информацию об отдельных заказах. Cоставной первичный ключ состоит из атрибутов ORDERKEY и LINENUMBER. Другие атрибуты таблицы LINEORDER являются внешними ключами к таблицам CUSTOMER, PART, SUPPLIER и DATE (для даты принятия заказа и даты завершения его обработки), а также таблица включает атрибуты приоритета заказа, его размера, стоимости и размера скидки. Таблицы измерений содержат информацию о соответствующих сущностях. На рис. 1 (основанном на рис. 2 из [19]) показана схема таблиц.
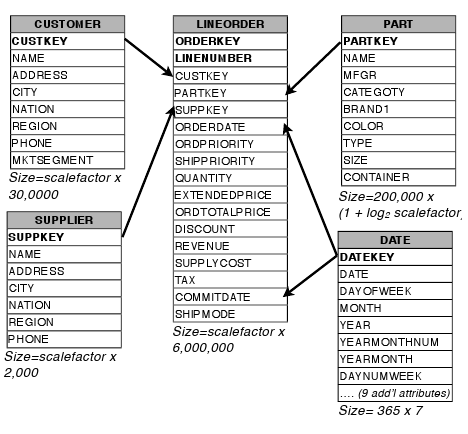
Рис. 1. Схема базы данных SSBM
Как и в TPC-H, в SSBM имеется базовый «масштабный коэффициент», который можно использовать для масштабирования размера базы данных. Размеры всех таблиц определяются относительно этого масштабного коэффициента. В работе авторов использовался масштабный коэффициент 10 (означающий, например, что в таблице LINEORDER содержалось 60000000 кортежей).
Запросы. В тестовый набор SSBM входит тринадцать запросов, разделенных на четыре категории, или «звена» (flight):
- Звено 1 состоит из трех запросов. Запросы содержат ограничения атрибута одного измерения, а также столбцов
DISCOUNTиQUANTITYтаблицыLINEORDER. Запросы определяют прирост дохода (произведение значений столбцовEXTENDEDPRICE(общая цена заказа) иDISCOUNT(скидка)), который можно было бы получить, если бы в указанном году отсутствовали различные уровни скидок для заказов с различными размерами. Селективность этих трех запросов для таблицыLINEORDERсоставляет 1.9×10−2, 6.5 × 10−4 и 7.5 × 10−5 соответственно. - Звено 2 состоит из трех запросов. Запросы содержат ограничения атрибутов двух измерений и вычисляют величины дохода для отдельных классов продуктов в отдельных регионах, сгруппированные по классам продукта и годам. Селективность этих трех запросов для таблицы
LINEORDERсоставляет 8.0×10−3, 1.6 × 10−3 и 2.0 × 10−4 соответственно. - Звено 3 состоит из четырех запросов с ограничениями на трех измерениях. Запросы вычисляют величины дохода в отдельных регионах за некоторый промежуток времени, сгруппированные по странам заказчиков, странам поставщиков и годам. Селективность этих четырех запросов для таблицы
LINEORDERсоставляет 3.4 ×10−2, 1.4 × 10−3, 5.5 × 10−4 и 7.6 × 10−7 соответственно. - Звено 4 состоит из трех запросов. Запросы содержат ограничения на столбцах трех измерений и вычисляют размеры прибыли (
REVENUE - SUPPLYCOST), сгруппированные по годам, странам и категориями для запроса 1 и по регионам и категориям для запросов 2 и 3. Селективность этих трех запросов для таблицыLINEORDERсоставляет 1.6 ×10−2, 4.5 × 10−3 и 9.1 × 10−5 соответственно.
4. Выполнение запросов в СУБД с хранением данных по строкам
В этом разделе обсуждается несколько различных методов, которые можно использовать для реализации колоночной базы данных в коммерческой СУБД, ориентированной на хранение данных по строкам (здесь и далее она называется System X). Авторы рассматривают три класса физических схем: схема с полным вертикальным разделением, схема с доступом только к индексам и схема с материализованными представлениями. Также проводится сравнение со «стандартной» физической структурой строчного хранилища с одной физической таблицей на каждое отношение.
Вертикальное разделение. Наиболее прямолинейный способ эмуляции колоночного хранения в строчном хранилище состоит в полном вертикальном разделении каждого отношения [16]. При использовании такого подхода требуется некоторый механизм соединения полей, образующих допустимую строку (в колоночных хранилищах записи обычно подбираются неявным образом за счет хранения значений столбцов в некотором порядке, но в строчном хранилище такие оптимизации невозможны). Простейший способ состоит в добавлении к каждой таблице целочисленного столбца «позиций» – часто этот способ бывает предпочтительнее использования первичного ключа, поскольку первичный ключ может быть большого размера, а иногда и составным (как в случае таблицы LINEORDER в базе данных SSBM). Для каждого столбца логической схемы создается одна физическая таблица с двумя столбцами – один столбец соответствует столбцу логической схемы, а второй – столбец позиций.
Затем запросы переписываются таким образом, чтобы при выборке нескольких столбцов из одного отношения выполнялись соединения по столбцу позиций. В System X по умолчанию для этих целей используются хэш-соединения, которые оказались дорогостоящими. По этой причине авторы экспериментировали с добавлением к каждой таблице кластеризованного индекса на столбце позиций и принуждали System X выполнять соединения через индексы, но это не улучшило производительность – дополнительные обмены с диском из-за обращения к индексам приводили к тому, что соединения выполнялись еще медленнее.
Планы с доступом только к индексам. У подхода вертикального разделения имеются две проблемы. Во-первых, требуется хранение в каждой таблице столбца позиции, что приводит к излишним затратам дисковой памяти и дополнительным обменам с диском. Во-вторых, в большинстве строчных хранилищ вместе с каждым кортежем хранится относительно крупный заголовок, что также вызывает излишние расходы дисковой памяти (в колоночных хранилищах обычно – а, возможно, даже и по определению – заголовки хранятся в отдельных столбцах во избежание этих накладных расходов).
Для преодоления этих проблем авторы пытались использовать второй подход, при котором базовые отношения хранятся в обычном строчном виде, но на каждом столбце каждой таблицы определяется дополнительный некластеризованный индекс в виде B-дерева. Планы выполнения запросов с доступом только к индексам (index-only plan), для которых требуется специальная поддержка со стороны СУБД, имеющаяся в System X, выполняются путем построения списков пар (record-id, value), удовлетворяющих предикатам, и слиянием этих списков в основной памяти, если для одной таблицы имеется несколько предикатов. Если для требуемых полей в запросе отсутствуют предикаты, то производятся полные списки пар (record-id, value) для всех значений соответствующих столбцов.
При выполнении таких планов никогда не производится доступ к реальным кортежам на диске. Хотя индексы явно хранят идентификаторы хранимых записей, каждое значение соответствующего столбца сохраняется только один раз, и обычно доступ к значениям столбцов через индексы сопровождается меньшими накладными расходами, поскольку в индексе не хранятся заголовки кортежей.
Одной из проблем этого подхода является то, что если в запросе отсутствует предикат на некотором столбце, то для выборки требуемых значений требуется последовательное сканирование индекса, которое может выполняться медленнее сканирования неупорядоченного файла (как было бы при применении подхода вертикального разделения).
Оптимизацией подхода является создание индексов с составными ключами, в которых вторичные ключи берутся из столбцов без предикатов. Например, рассмотрим запрос SELECT AVG(salary) FROM emp WHERE age>40. Если имеется составной индекс с ключом (age, salary), то ответ на этот запрос может быть получен прямо через этот индекс. Если же имеются отдельные индексы с ключами (age) и (salary), то план с доступом только к индексам будет вынужден найти все идентификаторы записей, удовлетворяющих условию age>40, а потом слить полученный список с полным списком пар (record-id, salary), построенным по индексу с ключом (salary), что будет выполняться гораздо медленнее.
В своей реализации авторы используют эту оптимизацию путем хранения первичного ключа каждой таблицы измерений в качестве вторичного ключа индексов на столбцах этой таблицы. За счет этого обеспечивается эффективный доступ к значениям первичных ключей таблиц измерений, требуемым для соединения с таблицей фактов.
Материализованные представления. В третьем подходе, рассматриваемом авторами, используются материализованные представления. При применении этого подхода для каждого звена запросов рабочей нагрузки создается оптимальный набор материализованных представлений, в котором оптимальное представление для данного звена содержит только столбцы, требуемые в запросах этого звена. В этих представлениях не выполняется соединение столбцов разных таблиц. Цель этой стратегии состоит в том, чтобы дать возможность System X производить доступ только к тем данным на диске, которые действительно требуются, избегая накладных расходов явного хранения идентификаторов записей или позиций и сохраняя заголовки кортежей только по одному для каждого кортежа. Поэтому авторы рассчитывали, что этот подход будет работать лучше первых двух подходов, хотя для его применения требуется предварительное знание рабочей нагрузки, что позволяет использовать его только в ограниченном числе ситуаций.