Выполнение транзакций, ориентированное на данные
Иппократис Пандис, Райан Джонсон, Никос Харадавеллас и Анастасия Айламаки
Перевод: Сергей Кузнецов
5. Оценка производительности
Для сравнения прототипа DORA c системой Shore-MT (называемой далее "базовой системой") мы используем один из наиболее параллельных многоядерных процессоров, доступных на рынке. Имеющиеся производительность и масштабируемость Shore-MT привели к тому, что эта система одной из первых столкнулась с проблемой конкуренции. По мере роста уровня аппаратного параллелизма и решения в системах обработки транзакций других проблем масштабируемости этим системам, скорее всего, тоже придется встретиться с проблемой конкуренции в менеджере блокировок.Наша оценка затрагивает три области. Во-первых, мы оцениваем, насколько эффективно DORA сокращает число взаимодействий с централизованным менеджером блокировок, и как это воздействует на производительность (подраздел 5.2). Затем мы количественно оцениваем, насколько хорошо в DORA используется внутритранзакционный параллелизм (подраздел 5.3). И, наконец, мы складываем все вместе и сравниваем пиковую производительность, достигаемую DORA и Shore-MT при использовании некоторого идеального механизма контроля доступа (подраздел 5.4).
5.1. Экспериментальные среда и рабочие нагрузки
Аппаратура: Мы выполняли все свои эксперименты на машине Sun T5220 "Niagara II", сконфигурированной с 32 гигабайтами основной памяти и функционирующей под управлением Sun Solaris 10. В чипе Sun Niagara II содержится 8 ядер, каждое из которых может поддерживать 8 аппаратных контекстов, что в целом образует 64 процессора, "видимых операционной системой". В каждом ядре имеется два исполнительных конвейера (execution pipeline), что позволяет одновременно обрабатывать команды из любых двух потоков управления. Таким образом, процессор может выполнять до 16 команд за один аппаратный цикл, используя много доступных контекстов для перекрытия задержек в каком-либо одном потоке управления.Подсистема ввода-вывода: При выполнении рабочих нагрузок OLTP на процессоре Sun Niagara II обе системы способны продемонстрировать высокую производительнось. Требования к подсистеме ввода-вывода возрастают с ростом пропускной способности из-за потребности в выталкивании на диск модифицированных страниц и записи данных в журнал. Если операции ввода-вывода генерируются произвольным образом, то для удовлетворения этого требования могут понадобиться сотни или даже тысячи дисков. Из-за ограниченного бюджета проекта, а также из-за того, что нас интересовало поведение систем при использовании большого числа аппаратных контекстов, мы сохраняли базу данных и журнал в файловой системе в основной памяти. Это решение позволило нам нагрузить центральный процессор, при том, что задействуются все пути выполнения кода менеджера хранения данных. Предварительные эксперименты с использованием высокопроизводительного твердотельного накопителя показывают, что относительное поведение систем остается тем же самым.
Рабочие нагрузки: Мы использовали транзакции из трех тестовых наборов OLTP: Network Database Benchmark или TM-1 [19] компании Nokia, TPC-C [20] и TPC-B [1]. Аналитические рабочие нагрузки типа тестового набора TPC-H приводят к тому, что значительная часть работы выполняется вне менеджера хранения данных, и такие транзакции оказывают небольшое давление на менеджер блокировок. Поэтому для этого исследования такие рабочие нагрузки неинтересны.
TM-1 состоит из семи транзакций, оперирующих с четырьмя таблицами, выполняя различные операции, которые свойственны мобильным сетям. Три транзакции выполняют только чтения, а четвертая обновляет базу данных. Все транзакции являются исключительно короткими, хотя при их выполнении задействуются все пути выполнения кода типичной системы обработки транзакций. Каждая транзакция обращается только к 1-4 записям, и они должны выполняться с небольшой задержкой даже при высоком уровне нагрузки. Мы использовали базу данных с пятью миллионами подписчиков (примерно 7,5 гигабайт). В TPC-C моделируется база данных розничного магазина. Этот тестовый набор состоит из пяти транзакций, поддерживающих заказы клиентов от их создания до доставки и оплаты покупок. Мы использовали набор данных со 150 складами (около 20 гигабайт) и буферный пул в 4 гигабайта. При наличии 150 складов можно поддерживать достаточное число параллельных запросов, чтобы загрузить машину, но при этом база данных остается достаточно небольшой, помещаясь в файловой системе в основной памяти. В TPC-B моделируется банк, в котором пользователи заносят деньги на свои счета и снимают их. Мы использовали набор данных TPC-B со 100 банковскими отделениями (примерно 2 гигабайта).
Для каждого прогона тестовый набор порождает некоторое число клиентов, и они начинают подавать запросы на образование транзакций. Хотя клиенты выполняются на той же машине, что и система, они добавляют лишь небольшие накладные расходы (<3%). Мы повторяли измерения несколько раз, и измеренное относительное среднеквадратическое отклонение составило меньше 5%. Мы применяли опции наивысшей оптимизации в компиляторе Sun CC v5.10. В измерениях, для которых требовалось прифилирование, применялись инструментальные средства из набора Sun Studio 12. Средства профилировки порождали некоторые накладные расходы (∼15%), но относительное поведение обеих систем оставалось неизменным.
5.2. Устранение конкуренции в менеджере блокировок
Во-первых, мы исследовали влияние конкуренции в менеджере блокировок в базовой системе и прототипе DORA при использовании в них возрастающего числа аппаратных ресурсов. В этом эксперимента рабочая нагрузка генерировалась клиентами, непрерывно запрашивающими выполнение транзакции GetSubscriberData из тестового набора TM1.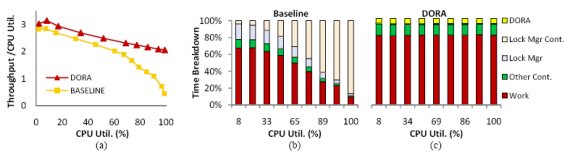
Рис. 1. DORA в сравнении с традиционной системой при рабочей нагрузке, состоящей из транзакций GetSubscriberData тестового набора TM1: (a) пропускная способность в соответствии с коэффициентом использования процессора при возрастании этого коэффициента; (b) распределение времени традиционной системы; (c) распределение времени прототипа DORA.
Результаты показаны на рис. 1. На самом левом рисунке показана пропускная способность в соответствии с коэффициентом использования процессора при возрастании этого коэффициента. На двух других диаграммах показано разделение времени каждой из двух систем. Можно видеть, что конкуренция в менеджере блокировок становится узким местом базовой системы, отбирая более 85% от общего времени выполнения. В отличие от этого, в DORA конкуренция в менеджере блокировок устраняется. Как можно заметить, накладные расходы механизма DORA невелики, намного меньше тех, которые возникают при работе централизованного менеджера блокировок даже при отсутствии конкуренции. Важно заметить, что GetSubscriberData – это только читающая транзакция. И, тем не менее, базовая система испытывает серьезные трудности из-за конкуренции внутри менеджера блокировок. Это объясняется тем, что потоки управления конкурируют даже в тех случаях, когда им требуется получить одну и ту же блокировку в совместимых режимах.
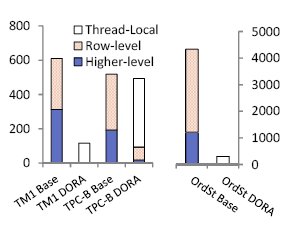
Рис. 5. Блокировки, запрошенные 100 транзакциями в базовой системе и в DORA при трех рабочих нагрузках.
Далее мы численым образом оценивали, насколько эффективно DORA сокращает число взаимодействий с централизованным менеджером блокировок, и как это влияет на производительность. Мы измеряли число блокировок, запрашиваемых в базовой системе и в DORA. Мы инструментировали код для сбора данных о числе и типе запрашиваемых блокировок. На рис. 5 показано число блокировок, запрошенных 100 транзакциями при выполнении обеими системами транзакций из тестовых наборов TM1 и TPC-B, а также транзакции OrderStatus из TPC-C. Блокировки разбиваются на три типа: блокировки уровня записей, блокировки центрального менеджера блокировок, не являющиеся блокировками уровня записей (на рисунке они обозначены как "higher level"), и локальные блокировки DORA.
При типичной рабочей нагрузке OLTP конкуренция за блокировки уровня записей имеет ограниченный характер, поскольку имеется очень большое число записей, доступ к которым происходит случайным образом. Но по мере продвижения вверх по иерархии блокировок можно ожидать возрастания уровня конкуренции. Например, каждой транзакции требуется получить блокировки намерений на уровне таблиц. На рис. 5 показано, что в DORA имеются лишь минимальные взаимодействия с централизованным менеджером блокировок. При выполнении тестового набора TPC-B в DORA запрашивается блокировка не уровня записей из-за управления областью хранения данных (выделения новой области страниц).
Рис. 5 позволяет составить некоторое представление о поведении этих трех рабочих нагрузок. TM1 состоит из исключительно кратковременных транзакций. Для их выполнения в традиционной системе запрашивается столько же блокировок более высокого уровня, сколько и блокировок уровня записей. В TPC-B число блокировок уровня записей в два раза больше числа блокировок более высокого уровня. Следовательно, можно ожидать, что при выполнении тестового набора TPC-B конкуренция в менеджере блокировок традиционной системы должна быть меньше, чем при выполнении тестового набора TM1. При выполнении транзакций OrderStatus традиционная система должна масштабироваться еще лучше, поскольку в них число блокировок уровня записей еще больше числа блокировок более высокого уровня.
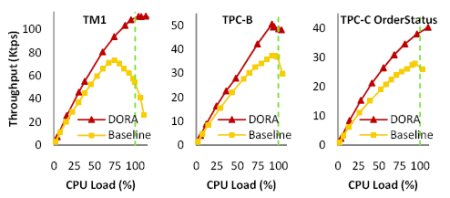
Рис. 6. Производительность базовой системы и DORA при возрастании загрузки системы при выполнении транзакций тестовых наборов TM1 и TPC-B, а также транзакций OrderStatus из TPC-C.
Рис. 6 подтверждает эти ожидания. Мы представляем диаграммы производительности обеих систем при трех рабочих нагрузках. На оси абцисс показана предлагаемая загрузка процессора. Предлагаемая загрузка процессора вычисляется путем сложения измеряемого времени использования процессора и времени, которое потоки управления тратят на ожидание ресурса процессора в очереди потоков управления, готовых к выполнению. Мы видим, что базовой системе свойственны проблемы масштабируемости, наиболее серьезные в случае TM1. С другой стороны, производительность DORA масштабируется настолько хорошо, насколько это позволяют аппаратные ресурсы.
Когда предлагаемая загрузка процессора превышает 100%, производительность традиционной системы на всех трех рабочих нагрузках резко падает. Это происходит из-за того, что операционной системе приходится вытеснять потоки управления с процессора, и в некоторых случаях это происходит в середине конфликтных критических участков. С другой стороны, производительность DORA остается высокой; это еще раз доказывает, что в DORA число конфликтных критических участков уменьшается.
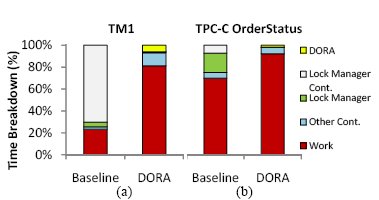
Рис. 2. Распределение времени традиционной системы обработки транзакций и прототипа DORA при полном использовании всех 64 аппаратных контекстов чипа Sun Niagara II при пропуске (a) тестового набора TM1 и (b) транзакций OrderStatus тестового набора TPC-C.
Рис. 2 показывает детальное распределение времени обеих систем при стопроцентном использовании процессора для рабочих нагрузок TM1 и OrderStatus тестового набора TPC-C. DORA превосходит по производительности базовую систему на рабочих нарузках OLTP независимо от того, имеются или нет конфликты в менеджере блокировок базовой системы.5.3. Внутритранзакционный параллелизм
В DORA внутритранзакционный параллелизм используется не только в качестве механизма снижения давления на конкурентный менеджер блокировок, но также и для сокращения времени ответа, когда рабочая нагрузка не перегружает доступную аппаратуру. Например, внутритранзакционный параллелизм оказывается полезным для приложений, демонстрирующих ограниченный межтразакционный параллелизм из-за высокого уровня конкуренции за логические блокировки, или для организаций, которые просто недоиспользуют имеющуюся у них процессорную мощность.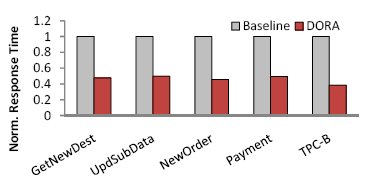
Рис. 7. Время ответа для простых транзакций. В DORA используется внутритранзакционный параллелизм, свойственный многим транзакциям.
В эксперименте, результаты которого показаны на рис. 7, мы сравнивали среднее время ответа на запрос в базовой системе и в DORA, достигаемой в ситуации, когда от одного клиента поступают запросы на образование транзакций с внутренним параллелизмом из трех рабочих нагрузок, и журнал располагается в файловой системе в основной памяти. В DORA используется доступный внутритранзакционный параллелизм и достигается меньшее время ответа. Например, транзакции NewOrder из тестового набора TPC-C выполняются в среде DORA на 60% быстрее.
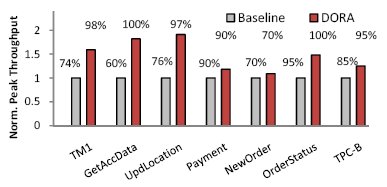
Рис. 8. Сравнение максимальной пропускной способности DORA и базовой системы на заданных рабочих нагрузках. Пиковая пропускная способность достигается при разных коэфициентах использования процессора.
5.4. Максимальная пропускная способность
Контроль доступа (admission control) может ограничивать число выполняемых транзакций, что, в свою очередь, ограничивает уровень конкуренции внутри менеджера блокировок системы. При должной настройке контроль доступа позволяет системе достичь предельно возможной пропускной способности, даже если это означает недоиспользуемость ресурсов машины. На рис. 8 приведены результаты сравнения максимальной пропускной способности базовой системы и DORA при использовании идеального контроля доступа. Для каждой системы и рабочей нагрузки показан коэффициент использования процессора, при котором достигается максимальная пропускная способность. DORA достигает более высокой максимальной пропускной способности на всех исследованных нами рабочих нагрузках, и эта пиковая пропускная способности достигается на пределе возможностей аппаратуры.Для транзакций из тестовых наборов TPC-C и TPC-B DORA демонстрирует менее значительные преимущества. Это объясняется двумя причинами. Во-первых, этим транзакциям свойственна меньшая конкуренция внутри менеджера блокировок, что лишает DORA основного ее преимущества над базовой системой. Во-вторых, некоторые из этих транзакций (такие как NewOrder и Payment из TPC-C и TPC-B) оказывают сильное давление на менеджер журнала, который становится новым узким местом.
6. Заключение
Назначение каждой транзакции своего потока управления в традиционных системах обработки транзакций не позволяет им полностью использовать потенциал многоядерных процессоров. Результирующая конкуренция внутри менеджера блокировок становится препятствием на пути к достижению масштабируемости. В этой статье демонстрируется возможность подхода с назначением потоков управления данным устранить это узкое место и повысить как производительность, так и масштабируемость. По мере того, как многоядерные аппаратные средства будут все более ограничивать масштабируемость внутри менеджеров блокировок, а подход DORA будет набирать зрелость, ее отрыв от традиционных систем будет только возрастать.7. Благодарности
Мы сердечно благодарим Майкла Абд Эль Малека (Michael Abd El Malek), Кирияки Леванти (Kyriaki Levanti) и сотрудников лаборатории DIAS за их отзывы и техническую поддержку. Мы благодарны рецензентам PVLDB за их ценные отзывы на ранние варианты этой статьи. Эта работа частично поддерживалась исследовательской стипендией Sloan, грантами NFS CCR-0205544, IIS-0133686 и IIS-0713409, премией ESF EurYI и Swiss National Foundation.8. Литература
[1] Anon, et al. A measure of transaction processing power. Datamation, 1985.
[2] E. Bugnion, et al. Disco: running commodity operating systems on scalable multiprocessors. ACM TOCS, 15(4), 1997.
[3] M. Carey, et al. Shoring Up Persistent Applications. In Proc. SIGMOD, 1994.
[4] C. Colohan, et al. Optimistic Intra-Transaction Parallelism on Chip Multiprocessors. In Proc. VLDB, 2005.
[5] G. DeCandia, et al. Dynamo: Amazon's Highly Available Key-value Store. In Proc. SOSP, 2007.
[6] D. J. DeWitt, et al. The Gamma Database Machine Project. IEEE TKDE 2(1), 1990.
[7] H. Garcia-Molina, and K. Salem. Sagas. In Proc. SIGMOD, 1987.
[8] G. Graefe. Hierarchical locking in B-tree indexes. In Proc. BTW, 2007.
[9] S. Harizopoulos, et al. OLTP Through the Looking Glass, and What We Found There. In Proc. SIGMOD, 2008.
Перевод на русский язык: Ставрос Харизопулос, Дэниэль Абади, Сэмюэль Мэдден, Майкл Стоунбрейкер. OLTP в Зазеркалье, 2008.
[10] S. Harizopoulos, V. Shkapenyuk, and A. Ailamaki. QPipe: A Simultaneously Pipelined Relational Query Engine. In Proc. SIGMOD, 2005.
[11] P. Helland. Life Beyond Distributed Transactions: an Apostate's Opinion. In Proc. CIDR, 2007.
[12] R. Johnson, et al. A New Look at the Roles of Spinning and Blocking. In Proc. DaMoN, 2009.
[13] R. Johnson, I. Pandis, and A. Ailamaki. Improving OLTP Scalability with Speculative Lock Inheritance. In Proc. VLDB, 2009.
[14] R. Johnson, I. Pandis, N. Hardavellas, A. Ailamaki, and B. Falsafi. Shore-MT: A Scalable Storage Manager for the Multicore Era. In Proc. EDBT, 2009.
[15] E. Jones, D. Abadi, and S. Madden. Low Overhead Concurrency Control for Partitioned Main Memory Databases. In Proc. SIGMOD, 2010.
Перевод на русский язык: Эван Джонс, Дэниэль Абади и Сэмуэль Мэдден. Управление параллелизмом с низкими накладными расходами для разделенных баз данных в основной памяти, 2009.
[16] A. Joshi. Adaptive Locking Strategies in a Multi-node Data Sharing Environment. In Proc. VLDB, 1991.
[17] T. Lahiri, et al. Cache Fusion: Extending shared-disk clusters with shared caches. In Proc. VLDB, 2001.
[18] C. Mohan, et al. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging. ACM TODS 17(1), 1992.
[19] Nokia. Network Database Benchmark.
[20] Transaction Processing Performance Council. TPC - C v5.5: On-Line Transaction Processing (OLTP) Benchmark.
[21] M. Stonebraker, et al. The End of an Architectural Era (It's Time for a Complete Rewrite). In Proc. VLDB, 2007.
Перевод на русский язык: Майкл Стоунбрейкер, Сэмюэль Мэдден, Дэниэль Абади, Ставрос Харизопулос, Набил Хачем, Пат Хеллэнд. Конец архитектурной эпохи, или Наступило время полностью переписывать системы управления данными, 2007.