2019 г.
Вглядываясь в бездну: оценка схем управления параллелизмом на процессоре с тысячью ядер
Сияньяо Ю, Джордж Безерра, Эндрю Павло, Сринивас Девадас, Майкл Стоунбрейкер
Перевод: С.Д. Кузнецов
Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores
Xiangyao Yu, George Bezerra, Srinivas Devadas, Michael Stonebraker, MIT CSAIL, Andrew Pavlo, Carnegie Mellon University
Аннотация
Компьютерные архитектуры приближаются к эпохе, в которой будут доминировать машины с десятками или даже сотнями ядер в одном чипе. Этот невиданный внутрипроцессорный параллелизм порождает новое измерение масштабируемости, на которое не рассчитаны современные системы управления базами данных (СУБД). В частности, при росте числа ядер чрезвычайно усложняется проблема управления параллелизмом. При наличии сотен параллельных потоков управления сложность координации конкурентного доступа к данным, вероятно, приведет к уменьшению выгоды от возрастающего числа ядер.
Чтобы лучше понять, насколько сегодняшние СУБД пригодны для будущих процессорных архитектур, мы произвели оценку методов управления параллелизмом для рабочих нагрузок оперативного управления транзакциями (on-line transaction processing, OLTP) на многоядерных чипах. Мы реализовали семь алгоритмов управления параллелизмом для СУБД с хранением баз данных в основной памяти и с использованием компьютерного моделирования (computer simulation) масштабировали свою систему до 1024 ядер. В каждом случае мы выявляли наиболее существенные ограничивающие факторы, не зависящие от конкретной реализации СУБД, и установили, что даже самые современные СУБД подвержены этим ограничениям. Мы пришли к выводу, что для использования будущих многоядерных чипов следует не пытаться пошаговым образом улучшать существующие решения, а полностью пересмотреть архитектуру СУБД, которая должна строиться с нуля и быть тесно связанной с аппаратурой.
1. Введение
Эпоха экспоненциального однопоточного повышения производительности завершилась. Жесткие ограничения энергопотребления и проблемы сложности заставили разработчиков чипов перейти от одноядерных к многоядерным архитектурам. Тактовая частота процессоров возрастала в течение десятилетий, но теперь этот рост прекратился. Агрессивные суперскалярные процессоры, изменяющие порядок выполнения команд, теперь уступают место простым ядрам, последовательно выполняющим команды [1]. Мы вступаем в эпоху многоядерных машин с большим числом этих крошечных маломощных ядер в одном чипе. Если не появится какая-то новая прорывная технология, то при наличии текущих ограничений энергопотребления и неэффективности однопоточной обработки увеличение числа ядер является единственным способом, с помощью которого архитекторы могут увеличить вычислительную мощность компьютеров. Это означает, что параллелизм на уровне команд и однопоточная производительность уступят место массивному параллелизму на уровне потоков управления.
Поскольку закон Мура продолжает действовать, можно ожидать, что число ядер в одном чипе будет продолжать расти экспоненциально. Скоро мы будем иметь сотни, возможно, тысячи ядер в одном чипе. Масштабируемость одноузловой СУБД с использованием общей памяти (shared-memory DBMS) в многоядерную эпоху становится все более важной. Но если сегодняшняя технология СУБД не адаптируется к этой будущей реальности, то вся компьютерная мощность будет впустую тратиться на преодоление узких мест, и дополнительные ядра станут бесполезными.
В этой статье мы взглянем на это страшное будущее и посмотрим, что произойдет с обработкой транзакций на процессоре с тысячей ядер. Вместо того, чтобы рассматривать все возможные проблемы масштабируемости, мы ограничимся областью управления параллелизмом. При наличии сотен параллельных потоков управления сложность координации конкурентного доступа к данным станет фактором, ограничивающим масштабируемость, и, вероятно, уменьшит выгоду от увеличения числа ядер. Поэтому мы поставили перед собой цель всесторонне изучить масштабируемость транзакционных СУБД на основе одного наиболее важного их компонента.
Мы реализовали семь алгоритмов управления параллелизмом в СУБД с хранением баз данных в основной памяти и использовали высокопроизводительный распределенный симулятор центрального процессора для масштабирования системы до 1000 ядер. Реализация системы с нуля позволила нам избежать искусственных узких мест существующих СУБД и понять более фундаментальные проблемы алгоритмов. В предыдущих исследованиях масштабируемости использовались существующие СУБД [24, 26, 32], но многие унаследованные компоненты этих систем не были ориентированы на использование многоядерных процессоров. Насколько нам известно, оценка нескольких алгоритмов управления параллелизмом в одной СУБД в настолько крупном масштабе не проводилась.
Наш анализ показывает, что все алгоритмы не масштабируются при увеличении числа ядер. В каждом случае мы выявляем основные ограничивающие факторы, не зависящие от реализации СУБД, и утверждаем, что даже самым современным системам свойственны эти ограничения. Мы приходим к выводу, что для решения этой проблемы масштабируемости необходимы новые подходы к управлению параллелизмом, тесно связанные с многоядерными архитектурами. Прежде чем добавлять большее число ядер, разработчикам архитектур компьютеров нужно будет обеспечить аппаратные решения проблем узких мест СУБД, которые не решаются программным путем.
Основной вклад этой статьи:
- всесторонняя оценка масштабируемости семи схем управления параллелизмом;
- первая оценка транзакционной СУБД на компьютере с 1000 ядрами;
- выявление узких мест в схемах управления параллелизмом, не связанных с особенностями реализации.
Оставшаяся часть этой статьи организована следующим образом. В разд. 2 мы начинаем с обзора схем управления параллелизмом, использованных в нашем исследовании. В разд. 3 описываются компоненты исследования. В разд. 4 и 5 приводятся результаты нашего анализа, а в разд. 6 – обсуждение результатов. Наконец, в разд. 7 обозреваются родственные работы, и в разд. 8 обсуждаются направления будущих исследований.
2. Схемы управления параллелизмом
Транзакционные СУБД поддерживают часть приложения, взаимодействующего с конечным пользователем (end-user). Конечные пользователи взаимодействуют с интерфейсной частью приложения (front-end application), передавая ей запросы на выполнение некоторых функций (например, зарегистрировать место на рейсе). Приложение обрабатывает эти запросы и затем выполняет транзакции в СУБД. Такими пользователями могут быть люди, использующие свой персональный компьютер или мобильное устройство, или другая компьютерная программа, потенциально выполняемая где-то еще в мире.
Транзакцией в контексте этих систем является выполнение последовательности из одной или большего числа операций (например, SQL-запросов) над совместно используемой базой данных для выполнения некоторой функции более высокого уровня [17]. Транзакция – это базовая единица изменения базы данных: частичные транзакции не допускаются, и результат воздействия группы транзакций на состояние базы данных эквивалентен результату некоторого последовательного выполнения всех транзакций. Транзакциям в современных рабочих нагрузках OLTP свойственны три основные характеристики: (1) они недолговечны (т.е. нет задержек по вине пользователей); (2) они затрагивают небольшое подмножество данных с использованием индексного поиска (index look-ups) (т.е. отсутствуют полные просмотры таблиц или крупные соединения); (3) они повторяются (т.е. выполняются те же запросы с другими входными данными) [38].
Предполагается, что транзакционная СУБД поддерживает для каждой выполняемой транзакции четыре свойства: (1) атомарность (atomicity), (2) согласованность (consistency), (3) изоляцию (isolation) и (4) долговечность (durability). Эти общепринятые понятия совместно обозначаются аббревиатурой ACID [20]. Управление параллелизмом позволяет конечным пользователям обращаться к базе данных в мультипрограммном режиме, сохраняя при этот иллюзию, что каждый из них выполняет свою транзакцию в одиночку в выделенной для этого систем [3]. По сути, это обеспечивает в системе гарантии атомарности и изолированности.
Теперь мы опишем различные схемы управления параллелизмом, которые исследовались при выполнении нашей многоядерной оценки. При этом мы следуем канонической категоризации, согласно которой любая схема управления параллелизмом является вариантом либо двухфазного протокола синхронизационных блокировок (two-phase locking), либо протокола упорядочивания по временным меткам (timestamp ordering) [3]. В табл. 1 приводится сводка этих различных схем.
Табл. 1. Схемы управления параллелизмом, оцениваемые в этой статье
| 2PL
| DL_DETECT
| 2PL с выявление дедлоков
|
| NO_WAIT
| 2PL с предотвращение дедлоков за счет отсутствия ожидания
|
| WAIT_DIE
| 2PL с предотвращение дедлоков за счет аварийного завершения молодых транзакций
|
| T/O
| TIMESTAMP
| Базовый алгоритм T/O
|
| MVCC
| Многоверсионный алгоритм T/O
|
| OCC
| Оптимистическое управление параллелизмом
|
| H-STORE
| T/O с блокировками на уровне разделов
|
2.1 Двухфазные блокировки
Двухфазный протокол синхронизационных блокировок (Two-Phase Locking, 2PL), вероятно, являлся первым корректным методом, обеспечивающим корректное выполнение параллельных транзакций в системах баз данных [6, 12]. В соответствии с этой схемой транзакции должны запрашивать блокировки данного элемента базы данных до того, как им будет разрешено выполнять операции чтения или записи над этим элементом. Транзакция должна запросить блокировку по чтению (read lock) до того, как ей будет разрешено читать данный элемент, и, аналогично, она должна запросить блокировку по записи (write lock), чтобы изменять этот элемент. СУБД поддерживает блокировки либо для каждого кортежа, либо на более высоком логическом уровне (например, таблиц или разделов) [14].
Владение блокировками регулируется двумя правилами: (1) разные транзакции не могут одновременно владеть конфликтующими блокировками, и (2) если транзакция передает владение блокировкой другой транзакции, она никогда не может получить дополнительных блокировок [3]. Блокировка элемента по чтению конфликтует с блокировкой того же элемента по записи. Аналогично, блокировка элемента по записи конфликтует с блокировкой того же элемента по записи или по чтению.
На первой фазе 2PL, называемой фазой роста (growing phase), транзакции разрешается запрашивать столько блокировок, сколько ей требуется, без освобождения блокировок [12]. Когда транзакция освобождает какую-либо блокировку, она входит во вторую фазу, называемую фазой спада (shrinking phase); с этого момента ей запрещается получение дополнительных блокировок. Когда транзакция завершается (фиксацией (committing) или принудительным прерыванием (aborting)), все оставшиеся блокировки автоматически освобождаются и переходят в распоряжение координатора.
2PL считается пессимистическим подходом, поскольку в нем предполагается, что транзакции будут конфликтовать, и поэтому им нужно запрашивать блокировки, чтобы избежать этой проблемы. Если транзакция не может получить блокировку требуемого элемента, она вынуждается ждать, пока эта блокировка не станет доступной. Если это ожидание является неконтролируемым (т.е. время ожидания не определено), СУБД может подвернуться синхронизационным тупикам, дедлокам (deadlock) [3]. Поэтому основным различием между разными вариантами 2PL является то, как они обрабатывают дедлоки и какие предпринимают действия при обнаружении тупика. Опишем теперь различные варианты 2PL, которые мы реализовали в своей оценочной среде, противопоставляя их на основе этих двух деталей.
2PL с выявлением дедлоков (DL_DETECT): СУБД отслеживает граф ожидания (waits-for graph) транзакций и проверяет наличие в нем циклов (т.е. дедлоков) [19]. Если дедлок обнаруживается, система должна выбрать транзакцию для аварийного завершения и последующего перезапуска, чтобы разорвать цикл. На практике для выявления циклов используется централизованный детектор дедлоков. Детектор выбирает транзакцию для аварийного завершения на основе уже используемого ей объема ресурсов (например, числа удерживаемых ей блокировок) для минимизации стоимости перезапуска транзакции [3].
2PL с предотвращением дедлоков за счет отсутствия ожидания (NO_WAIT): В отличие от подхода с обнаружением дедлоков, в котором СУБД рассчитывает найти тупики после их возникновения, данный подход является более осторожным: транзакция аварийно прерывается, как только у системы возникает подозрение, что поведение этой транзакции может привести к дедлоку [3]. Если запрос блокировки не удовлетворяется, планировщик немедленно аварийно прерывает запросившую транзакцию (т.е. не позволяет ей ждать удовлетворения запроса блокировки).
2PL с ожиданием и предотвращением дедлоков (WAIT_DIE): Это невытесняющий вариант схемы NO_WAIT, в котором транзакции разрешается ждать транзакцию, которая удерживает требуемую блокировку, если первая транзакция старше второй. Если запрашивающая блокировку транзакция младше, то она аварийно завершается (отсюда термин «dies» – умирает) и запускается заново [3]. Каждая транзакция получает временную метку до начала выполнения, и порядок временных меток гарантирует невозможность дедлоков.
2.2 Упорядочивание по временным меткам
Схемы управлению параллелизмом с упорядочиванием транзакций по их временным меткам (Timestamp Ordering, T/O) априорно производят сериализационный порядок транзакций, а затем СУБД поддерживает этот порядок. Каждой транзакции перед началом ее выполнения назначается уникальная, монотонно возрастающая временная метка. Эта временная метка используется СУБД для обработки конфликтующих операций в должном порядке (например, операций чтения и записи или двух отдельных операций записи над одним и тем же элементом) [3].
Опишем теперь схемы T/O, реализованные в нашем испытательном стенде. Основными различиями этих схем являются (1) уровень гранулярности, на котором СУБД проверяет наличие конфликтов (на уровне кортежей или на уровне разделов), и (2) время проверки наличия этих конфликтов (во время выполнения или в конце транзакции).
Базовая схема T/O (TIMESTAMP): Каждый раз, когда некоторая транзакция читает или изменяет некоторый кортеж в базе данных, СУБД сравнивает временную метку этой транзакции с временной меткой последней транзакции, которая читала или писала тот же самый кортеж. Для каждой операции чтения или записи СУБД отвергает запрос на выполнение операции, если временная метка соответствующей транзакции оказывается меньше временной метки транзакции, которая последней выполняла операцию записи над данным кортежем. Аналогично, операция записи отвергается, если временная метка соответствующей транзакции оказывается меньше временной метки транзакции, которая последней читала данный кортеж. При использовании схемы TIMESTAMP операция чтения кортежа создает его локальную копию, чтобы обеспечить повторяемость чтения (поскольку кортеж не защищен блокировкой). При аварийном завершении транзакции она получает новую временную метку и перезапускается. Это соответствует алгоритму «basic T/O», описанному в [3], но в нашей реализации используется децентрализованный планировщик.
Многоверсионное управление параллелизмом (MVCC): При использовании схемы MVCC каждая операция записи кортежа создает в базе данных его новую версию [4, 5]. Каждая версия помечается временной меткой транзакции, которая эту версию создала. В СУБД поддерживается внутренний список всех версий каждого элемента. При выполнении операции чтения СУБД определяет, к какой версии кортежа из этого списка будет обращаться соответствующая транзакция. Это обеспечивает сериализуемый порядок выполнения всех операций. Одним из преимуществ MVCC является то, что СУБД не отвергает опоздавшие операции. Другими словами, СУБД не отвергает операцию чтения из-за того, что затрагиваемый ей элемент уже перезаписан другой транзакцией [5].
Оптимистическое управление параллелизмом (Optimistic Concurrency Control, OCC): СУБД отслеживает наборы чтения/записи каждой транзакции и сохраняет все ее операции записи в частном рабочем пространстве транзакции [28]. При фиксации транзакции система определяет, перекрывается ли набор чтения этой транзакции с набором записи какой-либо другой параллельно выполняемой транзакции. Если такое перекрытие отсутствует, СУБД применяет к базе данных операции записи, собранные в рабочем пространстве транзакции; в противном случае транзакция аварийно завершается и перезапускается. Преимуществом этого подхода для СУБД с хранением баз данных в основной памяти является то, что транзакция записывает свои изменения в совместно используемую память только во время фиксации, и, следовательно, период конкуренции является коротким [42]. Современные реализации OCC включают Silo [42] и Hekaton [11, 29] от Microsoft. Реализованный нами алгоритм похож на Hekaton в том, что мы распараллеливаем фазу валидации и поэтому обеспечиваем большую масштабируемость, чем оригинальный алгоритм [28].
T/O с блокировками на уровне разделов (H-STORE): База данных разбивается на непересекающиеся участки памяти, называемые разделами. Каждый раздел защищается блокировкой, и с ним связывается однопоточный механизм выполнения (execution engine); только механизм выполнения данного раздела имеет право обращаться к данным этого раздела. Каждая транзакция должна получить блокировки всех разделов, требуемых для выполнения ее операций, до того, как начнет выполняться. Для этого требуется, чтобы СУБД до ее начала каждой транзакции знала, к каким разделам эта транзакция будет обращаться [34]. Когда от транзакции поступает соответствующий запрос, СУБД назначает ей временную метку и ставит транзакцию в очередь ожидания блокировок всех требуемых разделов. Механизмы выполнения каждого раздела удаляют из очереди самую старую (с наименьшей временной меткой) транзакцию и предоставляют ей доступ к разделу [38]. Когда-то подобный подход применялся в Smallbase [22], а в наше время он был реализован в H-Store [27].
3. Многоядерный испытательный стенд СУБД
Поскольку многоядерные чипы еще не существуют, для своего анализа мы использовали Graphite [30] – симулятор многоядерного процессора, который может масштабироваться до 1024 ядер. Что касается СУБД, мы реализовали транзакционный движок, обеспечивающий только те функциональные возможности, которые требовались для наших экспериментов. Мотивация использования собственной СУБД является двоякой. Во-первых, это позволяет нам быть уверенными в отсутствии узких мест, не связанных с управлением параллелизмом. Это позволяет нам исследовать основы каждой схемы в изоляции от помех, вызываемых работой не относящихся к делу функций. Во-вторых, использование полнофункциональной СУБД непрактично из-за значительного замедления работы в режиме симуляции (например, Graphite в среднем замедляет работу в 10000 раз). Наличие собственного движка позволило нам выполнять эксперименты за разумное время. Опишем теперь инфраструктуру симуляции, движок СУБД и рабочие нагрузки, использованные в нашем исследовании.
3.1 Симулятор и целевая архитектура
Graphite [30] – это быстрый симулятор процессоров для крупномасштабных многоядерных систем. Graphite выполняет готовые для использования Linux-приложения, создавая отдельный поток управления для каждого ядра симулируемой архитектуры. Как показано на рис. 1, каждому потоку управления приложения назначается поток симулируемого ядра, который может отображаться на различные процессы отдельных хост-машин. Для повышения производительности Graphite ослабляет потактовую точность, периодически используя механизмы синхронизации для моделирования гранулярности уровня команд. Подобно другим симуляторам процессоров, Graphite только выполняет приложения и не моделирует операционную систему.

Рис. 1. Инфраструктура симулятора Graphite – Потоки управления приложения отображаются на потоки симулируемых ядер, которые развертываются на нескольких хост-машинах
Целевая архитектура представляет собой «ячеистый» (tiled) многоядерный процессор, в котором каждая ячейка содержит энергоэффективное процессорное ядро с последовательным выполнением команд, кэш команд и данных первого уровня размером в 32 Кб, часть кэша (cache slice) второго уровня размером в 512 Кб и сетевой роутер. Эта архитектура аналогична другим коммерческим процессорам, таким как Tile64 компании Tilera (64 ядра), SCC (48 ядер) и Knights Landing (72 ядра) компании Intel [1]. Ячейки связываются высокопропускной сетью на кристалле (on-chip network) 2Dmesh, в которой каждый переход до ближайшего маршрутизатора (hop) выполняется за два такта. Тактовая частота и ячеек, и сети составляет 1 ГГц. Архитектура 64-ядерной машины схематично показана на рис. 2.
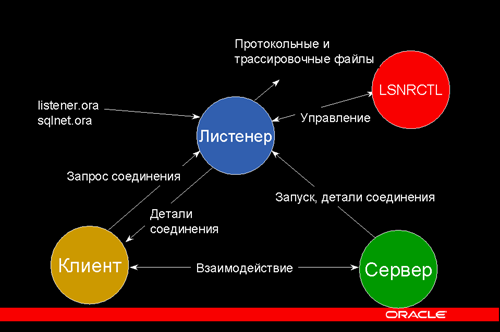
Рис. 2. Целевая архитектура – многопроцессорный процессор с ячеистым чипом с 64 ячейками и сетью на кристалле с двумерной сеткой (2D-mesh network-on-chip). Каждая ячейка содержит процессорное ядро, кэш L1 и L2 и сетевой коммутатор (SW)
Мы выбрали конфигурацию с совместным для всех ядер кэшем второго уровня, поскольку эта конструкция наиболее часто встречается в коммерческих многоядерных процессорах. В экспериментах по сравнению общих и частных кэшей L2 мы наблюдали, что наличие общих кэшей на рабочих нагрузках OLTP приводит к существенному сокращению числа обращений к основной памяти и повышению производительности из-за увеличенной емкости совокупного кэша (результаты не показаны). Поскольку части кэша L2 распределены между разными ячейками, моделируемая многоядерная система относится к архитектуре NUCA (Non-Uniform Cache Access – неоднородный доступ к кэшу), в которой задержка кэша L2 возрастает в зависимости от длины расстояния в двумерной сетке.
3.2 СУБД
Мы реализовали собственную легковесную СУБД с хранением баз данных в основной памяти на основе библиотеки pthreads в расчете на использование в среде Graphite. Эта СУБД работает как один процесс с несколькими рабочими потоками управления, число которых равно числу процессорных ядер; каждый поток управления отображается на отдельное ядро. Все данные наша СУБД сохраняет в основной памяти построчным образом. В системе поддерживаются базовые индексы на основе хэш-таблиц и подключаемый менеджер блокировок, что позволяет менять разные реализации схем управления параллелизмом, описанные в разд. 2. Также допускается разделение индексов и менеджера блокировок (как это требуется при использовании схемы H-STORE) или их использование в централизованном режиме.
В нашей системе не симулируются клиентские потоки управления; вместо этого в каждом рабочем потоке содержится фиксированной длины очередь транзакций, обслуживаемых по порядку. Это сокращает накладные расходы сетевых протоколов, которые по их сути трудно воспроизвести в симуляторе. В каждой транзакции содержатся программная логика и вызовы запросов. Статистика транзакций, такая как пропускная способность, задержка и частота аварийных завершений, собирается после периода разогрева, который является достаточно продолжительным для достижения системой устойчивого состояния.
Помимо статистики времени выполнения, наша СУБД также информирует о том, сколько времени каждая транзакция проводит в разных компонентах системы [1]. Мы группируем эти измерения в шесть категорий:
ПОЛЕЗНАЯ РАБОТА (USEFUL WORK): Время, в течение которого транзакция действительно выполняет логику приложения и работает с кортежами в системе.
АВАРИЙНОЕ ЗАВЕРШЕНИЕ (ABORT): Накладные расходы из-за отката системой всех изменений, сделанных аварийно завершающейся транзакцией.
ВЫДЕЛЕНИЕ ВРЕМЕННОЙ МЕТКИ (TS ALLOCATION): Время, которое требуется системе для получения уникальной временной метки от централизованного распределителя. Для схем управления параллелизмом, требующих наличия у транзакций временных меток, накладные расходы на выделение временной метки возникают один раз для каждой транзакции.
ИНДЕКС (INDEX): Время, которое транзакция тратит на работу с хэш-индексами таблиц, включая накладные расходы на низкоуровневое защелкивание (latching) бакетов в хэш-таблицах.
ОЖИДАНИЕ (WAIT): Общий объем времени, в течение которого транзакция должна была ждать. Транзакция может ждать либо блокировки (например, при использовании 2PL), либо кортежа, значение которого еще не готово (например, при использовании T/O).
МЕНЕДЖЕР (MANAGER): Время, которое транзакция проводит в менеджере блокировок или менеджере временных меток. Это время не включает какое-либо время ожидания.
3.3 Рабочие нагрузки
Далее мы описываем два тестовых набора, которые мы реализовали в своем испытательном стенде для их анализа.
YCSB: The Yahoo! Cloud Serving Benchmark – коллекция рабочих нагрузок, типичных для крупномасштабных сервисов, создаваемых Интернет-компаниями [8]. Для всех экспериментов на основе YCSB, описываемых в этой статье, мы использовали базу данных YCSB объемом около 20 Гб, содержащую одну таблицу с 20 миллионами строк. У каждого кортежа YCSB имеется один столбец первичного ключа и 10 дополнительных столбцов, каждый из которых содержит 100 байт случайно сгенерированных символьных данных. Для первичного ключа СУБД создает один хэш-индекс.
Каждая транзакция из рабочей нагрузки YCSB по умолчанию обращается к 16 записям в базе данных. Каждое обращение – это чтение или обновление. В своей программной логике транзакция не производит каких-либо вычислений. Все запросы независимы один от другого; другими словами, входные данные одного запроса не зависят от результатов предыдущего запроса. Записи, к которым происходят обращения в YCSB, соответствуют распределению Зипфа, контролируемому параметром theta, который воздействует на уровень конкуренции в бенчмарке [18]. Если theta=0, обращения ко всем кортежам происходят с одинаковой частотой. Но если theta=0.6 или theta=0.8, к «горячему» участку из 10% кортежей базы данных обращаются 40% или 60% транзакций соответственно.
TPC-C: Этот бенчмарк в настоящее время является индустриальным стандартом для оценки производительности OLTP-систем [40]. База данных TPC-C состоит из девяти таблиц, имитирующих складское приложение обработки заказов. Для всех транзакций TPC-C обеспечивается входной параметр WAREHOUSE id, который является внешним ключом для всех таблиц, кроме ITEM. При использовании алгоритма управления параллелизма, требующего разделения данных (т.е. H-STORE), база данных TPC-C разделяется по этому WAREHOUSE id.
В нашей симуляции воспроизводятся только две (Payment и NewOrder) из пяти транзакций TPC-C. Поскольку они составляют 88% всей рабочей нагрузки TPC-C, это хорошая аппроксимация. Наша версия является «добросовестной» реализацией, хотя для рабочих потоков мы опустили «время на размышление». Каждый рабочий поток запускает следующую транзакцию без паузы; это устраняет потребность в увеличении размера базы данных при росте числа параллельно выполняемых транзакций.
3.4 Симулятор в сравнении с реальной аппаратурой
Чтобы показать, что симулятор Graphite производит результаты, сопоставимые с существующими аппаратными средствами, мы развернули свою СУБД на Intel Xeon E7-4830 и выполнили на ней рабочую нагрузку YCSB, насыщенную операциями чтения, со средним уровнем конкуренции (theta=0.6). Затем мы выполнили ту же рабочую нагрузку в среде Graphite с тем же числом ядер.
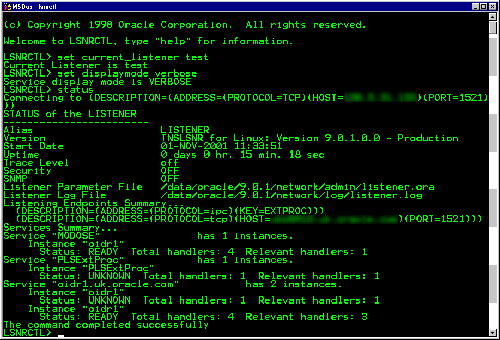
(a) Симуляция в среде Graphite (b) Реальная аппаратура
Рис. 3. Симулятор в сравнении с реальной аппаратурой – Сравнение результатов схем управления параллелизмом при их выполнении в среде Graphite и на реальном многоядерном процессоре с использованием рабочей нагрузки YCSB со средним уровнем конкуренции (theta=0.6)
Результаты на рис. 3 показывают, что все схемы управления параллелизмом демонстрируют одни и те же тенденции изменения производительности в среде Graphite и на реальном процессоре. Однако заметим, что относительное различие производительности между MVCC, TIMESTAMP и OCC на рис. 3a и 3b не одинаково. Это связано с тем, что при использовании MVCC производится большее число обращений к основной памяти, чем при использовании двух других схем, а такие обращения являются более дорогими в системах с двумя сокетами. В Graphite воспроизводится один сокет процессора, и поэтому отсутствует межсокетный трафик. Кроме того, на 32 ядрах падает производительность схем семейства T/O и схемы WAIT_DIE из-за накладных расходов на коммуникации между ядрами при назначении временных меток. Этот вопрос обсуждается в подразделе 4.3.
4. Проектные решения и оптимизации
Одной из основных проблем, решению которых посвящалось наше исследование, являлась разработка максимально масштабируемых СУБД и схем управления параллелизмом. При развертывании на машине с 1000 ядер многие второстепенные аспекты реализации становились помехой для производительности. Мы делали все возможное для оптимизации каждого алгоритма, устраняя все возможные факторы, ограничивающие масштабируемость, и сохраняя при этом основные функциональные возможности алгоритмов. Большая часть этой работы заключалась в устранении общих структур данных и разработке распределенных версий классических алгоритмов.
В этом разделе мы обсудим свой опыт разработки многоядерной транзакционной СУБД и расскажем о выборе решений для построения масштабируемой системы. Кроме того, мы выявим фундаментальные факторы, ограничивающие масштабируемость схем 2PL и T/O, и покажем, как можно смягчить эти проблемы за счет аппаратной поддержки. Подробный анализ отдельных схем представлен в разд. 5.
4.1 Общие оптимизации
Сначала обсудим оптимизации, направленные на повышение производительности СУБД при использовании всех схем управления параллелизмом.
Распределение памяти: Одно из первых ограничений, с которым мы столкнулись при попытке масштабировать СУБД к большому числу ядер, было связано с функцией malloc. Мы обнаружили, что при использовании версии функции malloc, обеспечиваемой в среде Linux по умолчанию, СУБД проводит большую часть времени в ожидании выделения памяти. Это является проблемой даже для только читающих рабочих нагрузок, потому что СУБД все равно приходится копировать читаемые записи при использовании TIMESTAMP и создавать средства поддержки внутренних метаданных для доступа к структурам данных отслеживания доступа. Мы пытались использовать оптимизированные версии malloc (TCMalloc [15], jemalloc [13]), но результаты были настолько же неутешительными.
Проблему удалось решить путем создания собственной реализации malloc. Подобно тому, как это делается в TCMalloc и jemalloc, каждому потоку управления назначается свой пул основной памяти. Отличие состоит в том, что наш распределитель памяти автоматически изменяет размеры пулов на основе рабочей нагрузки. Например, если для некоторого бенчмарка требуется выделение крупных непрерывных участков основной памяти, то для амортизации стоимости каждой операции выделения памяти размер пула увеличивается.
Таблица блокировок: Как отмечалось в предыдущих работах [26, 36], таблица блокировок в СУБД является еще одной точкой конкуренции. Вместо поддержки централизованных таблицы блокировок или менеджера временных меток мы реализовали эти структуры данных покортежным образом, и каждой транзакции требуется «защелкивать» (latch) только требуемые ей кортежи. Это улучшает масштабируемость, но увеличивает накладные расходы основной памяти, поскольку СУБД приходится поддерживать дополнительные метаданные о держателях совместных/монопольных блокировок. На практике эти метаданные (несколько байт) для крупных кортежей являются незначительными.
Мьютексы: Блокировка с использованием мьютекса – это дорогостоящая операция, для выполнения которой требуется посылка нескольких сообщений внутри чипа. Наличие центрального критического участка, защищенного мьютексом, ограничит масштабируемость любой системы (см. подраздел 4.3). Поэтому при выполнении критических работ важно избегать использования мьютексов. При применении 2PL основным узким местом является мьютекс, защищающий централизованный детектор блокировок; а при применении алгоритмов T/O мьютекс используется для назначения уникальных временных меток. В последующих разделах мы опишем разработанные нами оптимизации, которые устраняют потребность в этих мьютексах.
4.2 Масштабируемые блокировки 2PL
Далее мы опишем оптимизации для алгоритмов 2PL.
Выявление дедлоков: По отношению к DL_DETECT мы обнаружили, что алгоритм выявления дедлоков является узким местом, если несколько потоков управления конкурируют по поводу обновления графа ожидания в централизованной структуре данных. Мы решили проблему, разделив эту структуру данных между ядрами и сделав детектор дедлоков полностью свободным от блокировок. Теперь, когда некоторая транзакция хочет обновить свой граф ожидания, ее поток управления без каких-либо блокировок ставит в ее очередь все транзакции, которых ожидает данная транзакция. Этот шаг является локальным (т.е. не требующим межъядерных коммуникаций), потому что данный поток управления не производит запись в очереди других транзакций.
В процессе выявления дедлока поток управления ищет циклы в частичном графе ожидания, построенном путем только чтения очередей соответствующих потоков управления без блокировки этих очередей. Хотя этот подход может не обнаружить дедлок сразу после его появления, поток-детектор гарантированно найдет его на следующих проходах [5].
Перегрузка блокировок (Lock Thrashing): Даже при оптимизации выявления дедлоков схема DL_DETECT не масштабируется из-за перегрузки блокировок. Это случается, когда транзакция удерживает свои блокировки до своей фиксации, блокируя все другие параллельно выполняемые транзакции, которые пытаются получить эти блокировки. Ситуация становится проблемой при наличии высокого уровня конкуренции и большого числа параллельно выполняемых транзакций, и поэтому она является основным узким местом всех схем категории 2PL.
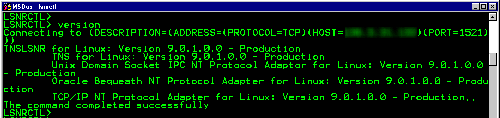
Рис. 4. Перегрузка блокировок – Результаты для рабочей нагрузки YCSB с большим числом операций записи при использовании схемы DL_DETECT без выявления дедлоков. Каждая транзакция получает блокировки в порядке возрастания первичного ключа.
Для демонстрации влияния перегрузки блокировок мы выполнили рабочую нагрузку YCSB с большим числом операций записи (смесь 50/50% операций чтения и записи) с использованием варианта DL_DETECT, в котором транзакции получают блокировки в порядке возрастания значений первичного ключа. Хотя этот подход непрактичен для всех рабочих нагрузок, он устраняет потребность в выявлении тупиков и позволяет нам лучше наблюдать за эффектами перегрузки блокировок. На рис. 4 иллюстрируется пропускная способность транзакций как функция от числа ядер для разных уровней конкуренции. При отсутствии в рабочей нагрузке скашивания (theta=0) конкуренция за блокировки является низкой, и пропускная способность масштабируется почти линейно. Однако при возрастании уровня конкуренции начинает проявляться перегрузка. При среднем уровне конкуренции (theta=0.6) максимальная пропускная способность достигается при наличии нескольких сотен ядер, а потом уменьшается из-за перегрузки. При наивысшем уровне конкуренции (theta=0.8) пик пропускной способности СУБД достигается на 16 ядрах и после этого не масштабируется. Результаты симуляции показывают, что почти все время выполнения тратится на ожидание блокировок. Следовательно, перегрузка блокировок является важнейшим узким местом подходов на основе блокировок, ограничивающим масштабируемость в сценариях с высоким уровнем конкуренции.
Ожидание по сравнению с аварийным завершением: Проблему перегрузки в DL_DETECT можно решить, аварийно завершая некоторые транзакции для уменьшения числа активных транзакций в любой момент времени. В идеале это позволяет поддерживать наибольшую пропускную способность системы, показанную на рис. 4. Мы добавили в СУБД тайм-аут, побуждающий систему аварийно завершать и перезапускать любую транзакцию, которая ожидает блокировку в течение времени, большего этого порогового значения. Заметим, что, если значение тайм-аута равно нулю, данный алгоритм эквивалентен NO_WAIT.
Мы пропускали одну и ту же рабочую нагрузку YCSB с высоким уровнем конкуренции с разными значениями тайм-аута на 64-ядерном процессоре. Для СУБД со схемой DL_DETECT и значением тайм-аута от 0 до 100 мксек измерялись пропускная способность и частота аварийных завершений.

Рис. 5. Ожидание по сравнению с аварийным завершением – Результаты для DL_DETECT при изменении значения тайм-аута на рабочей нагрузке YCSB с высоким уровнем конкуренции (theta=0.8) на 64 ядрах
Результаты на рис. 5 показывают, что если у процессора имеется небольшое число ядер, то лучше использовать короткие тайм-ауты. Это указывает на потребность в компромиссе между пропускной способностью и частотой аварийных завершений. При малом значении тайм-аута частота аварийных завершений велика, что приводит к сокращению числа активных транзакций и смягчению проблемы перегрузки блокировок. При больших значениях тайм-аута частота аварийных завершений уменьшается, но повышается уровень перегрузки. В своих экспериментах мы оценивали DL_DETECT со значением тайм-аута до 100 мксек. На практике выбор порогового значения следует основывать на характеристиках рабочей нагрузки приложений.
4.3 Масштабируемое упорядочивание по временным меткам
В заключение раздела мы обсудим свои оптимизации для улучшения масштабируемости алгоритмов, основанных на T/O.
Назначение временных меток: Все алгоритмы класса T/O, принимают решение об упорядочивании транзакций на основе присвоенных им временных меток. Поэтому СУБД должна гарантировать, чтобы каждая временная метка назначалась только одной транзакции. Примитивный подход, удовлетворяющий этому требованию, состоит в использовании мьютекса в критическом участке распределителя временных меток, но это приводит к плохой производительности. Другим распространенным решением является использование атомарной операции сложения для увеличения значения глобальной логической временной метки. Для реализации такого подхода требуется меньшее число команд, и поэтому критический участок в СУБД блокируется на более короткий промежуток времени, чем при использовании мьютекса. Но, как мы покажем, такой подход тоже непригоден при использовании процессор с 1000 ядрами. Теперь мы обсудим три альтернативы назначения временных меток: (1) атомарное сложение в пакетном режиме [42], (2) часы процессора (CPU clocks) и (3) аппаратные счетчики.
В подходе пакетного атомарного сложения СУБД использует для выделения временных меток ту же атомарную команду сложения, но менеджер временных меток в ответ на каждый запрос возвращает пакет из нескольких временных меток. Этот метод был впервые предложен при разработке СУБД Silo [42].
Для генерации временной метки с использованием часов в каждом рабочем потоке читаются показания локальных часов в соответствующем ядре, и затем эти данные конкатенируются с идентификатором потока. Этот подход обеспечивает хорошую масштабируемость, если все часы синхронизованы. В распределенных системах синхронизация достигается с использованием программных протоколов [31] или внешних часов [9]. Однако в многоядерных процессорах это вызывает большие накладные расходы, и поэтому требуется аппаратная поддержка. К июлю 2014 г. только в процессорах Intel поддерживалась синхронизация часов между ядрами.
Наконец, третий подход состоит в использовании эффективного встроенного аппаратного счетчика. Этот счетчика физически располагается в центре процессора, так что среднее расстояние до каждого ядра минимизируется. В настоящее время эта возможность не поддерживается ни в одном процессоре. Поэтому мы реализовали счетчик в Graphite, где запрос временной метки посылается по внутрикристальной сети для атомарного увеличения значения счетчика за один такт.
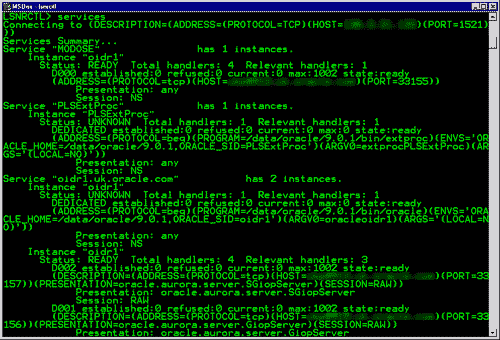
Рис. 6. Микробенчмарк методов назначения временных меток – Измерения пропускной способности для разных методов назначения временных меток
Для определения максимальной скорости, с которой СУБД может назначать временные метки при использовании разных методов, мы выполнили микробенчмарк, в котором потоки управления непрерывно запрашивают временные метки. Пропускная способность в зависимости от числа ядер показана на рис. 6. Прежде всего, заметим, что выделение временных меток с использованием мьютекса показало наихудшую пропускную способность с примерно миллионом временных меток в секунду (ts/s) на 1024 ядрах. Метод атомарного сложения показал максимальную скорость в 30 миллионов ts/s на небольшом числе ядер, но пропускная способность снижается до 8 миллионов ts/s при увеличении числа ядер. Это объясняется тем, что для каждой временной метки при отложенной записи в кэш (writing back) и последующей инвалидации соответствующих строк кэша, содержащих устаревшие данные, требуется трафик обеспечения когерентности кэша. Для этого нужен цикл обмена сообщениями внутри чипа или примерно 100 тактов для процессора с 1024 ядрами, что в конечном итоге приводит к максимальной пропускной способности в 10 миллионов ts/s при тактовой частоте в 1 ГГц. Помогает пакетное выделение временных меток, но при наличии конкуренции возникают проблемы с производительностью (см. ниже). Решения на основе аппаратуры позволяют масштабироваться при росте числа ядер. Поскольку при применении подхода с аппаратным счетчиком для увеличения значения временной метки требуется всего один такт, при использовании этого метода удается достичь максимальной пропускной способности в миллиард ts/s. Увеличение производительности связано с отсутствием потребности в трафике когерентности кэшей, поскольку дополнительная операция выполняется в удаленном режиме. Подход на основе часов обеспечивает идеальную (т.е. линейную) масштабируемость, потому что это решение является полностью децентрализованным.
Рис. 7. Выделение временных меток – Пропускная способность на рабочей нагрузке YCSB с использованием TIMESTAMP с разными методами назначения временных меток
Мы также тестировали в СУБД разные схемы назначения временных меток, чтобы увидеть, как они работают на реальных рабочих нагрузках. В этом эксперименте выполнялась рабочая нагрузка YCSB с большим числом операций записи с двумя уровнями конкуренции и с использованием схемы TIMESTAMP. Как показывает рис. 7a, при отсутствии конкуренции относительная производительность методов назначения временных меток совпадает с той, которая показана на рис. 6. Однако при наличии конкуренции кривые на рис. 7b значительно отличаются от кривых на рис. 6. Во-первых, значительно хуже пропускная способность СУБД при использовании пакетного атомарного сложения. Это объясняется тем, что при перезапуске транзакции из-за обнаружения конфликта она перезапускается в том же рабочем потоке, и ей назначается следующая временная метка из последнего пакета. Но эта временная метка все равно будет меньше той, которая назначена транзакции, вызвавшей аварийное завершение данной транзакции, и поэтому эта транзакция будет продолжать перезапускаться, пока поток не прочитает новый пакет временных меток. Метод не пакетного атомарного сложения работает так же хорошо, как и подходы на основе часов и аппаратного счетчика. В связи с этим в экспериментах, описываемых далее в этой статье, в СУБД для выделения временных отметок использовалось не пакетное атомарное сложение, потому что другие подходы требуют специализированной аппаратной поддержки, которая в настоящее время доступна не во всех процессорах.
Распределенная валидация: В оригинальном алгоритме OCC в конце фазы чтения имеется критический участок, в котором для выявления конфликтов набор чтения валидируемой транзакции сравнивается с наборами записи предыдущих транзакций. Этот шаг является коротким, но, как отмечалось выше, любой защищенный мьютексом критический участок серьезно ухудшает масштабируемость. Мы решаем эту проблему путем использования покортежной валидации, разбивающей эту проверку на более мелкие операции. Это похоже на подход, использованный в Hekaton [29], но наше решение проще, поскольку поддерживается только одна версия каждого кортежа.
Локальные разделы: Мы оптимизировали исходный протокол H-Store для использования преимуществ наличия общей памяти. Поскольку все рабочие потоки управления СУБД выполняются в одном процессе, мы разрешаем многораздельным транзакциям напрямую обращаться к кортежам удаленных разделов вместо того, чтобы посылать запросы, обрабатываемые рабочими потоками удаленных разделов. Это обеспечивает более простую реализацию, которая работает быстрее, чем при использовании межпроцессных комуникаций. При применении этого подхода данные физически не разделяются, поскольку внутри чипа коммуникационные задержки не велики. Доступ к только читаемым таблицам производится всеми потоками без репликации, что сокращает расходы основной памяти. Наконец, мы используем те же, что описаны выше, оптимизации для распределения временных меток, чтобы избежать обязательного времени ожидания для учета возможности рассинхронизации часов [38].
5. Экспериментальный анализ
Представим теперь результаты своего анализа разных схем управления параллелизмом. Наши эксперименты группируются в две категории: оценки (1) масштабируемости и (2) чувствительности. В экспериментах первой категории мы хотим определить, насколько хорошо работают схемы при возрастании числа ядер. Число ядер масштабируется до 1024 при сохранении параметров рабочей нагрузки. В экспериментах с чувствительностью мы изменяли один параметр рабочей нагрузки (например, коэффициент скашивания доступа транзакций к кортежам). Мы информируем об общей симулируемой пропускной способности СУБД, а также о времени, которое каждый рабочий поток проводит в различных частях системы, перечисленных в подразделе 3.2.
Начнем с пространного анализа рабочей нагрузки YCSB. Природа этой рабочей нагрузки позволяет изменять ее параметры и создавать различные сценарии, которые по-разному нагружают схемы управления параллелизмом. Затем мы анализируем рабочую нагрузку TPC-C, где мы изменяем число складов и исследуем влияние этого на пропускную способность алгоритмов. В начальных экспериментах не участвует схема H-STORE. Она привлекается только в подразделе 5.5 при анализе эффектов разделения базы данных.
5.1 Только читающая рабочая нагрузка
В первом эксперименте по анализу масштабируемость мы выполняли рабочую нагрузку YCSB, состоящую из только читающих транзакций с равномерным распределением обращений к кортежам. В каждой транзакции выполняются 16 отдельных операций чтения кортежей. Это обеспечивает исходные данные для каждой схемы управления параллелизмом до перехода к более сложным организациям рабочей нагрузки.

Рис. 8. Только читающая рабочая нагрузка – Результаты только читающей рабочей нагрузки YCSB
В идеально масштабируемой СУБД пропускная способность должна линейно возрастать при увеличении числа ядер. Однако это не относится к схемам T/O, результаты использования которых представлены на рис. 8a. Разбивка общего времени по компонентам на рис. 8b показывает, что при большом числе ядер узким местом является выделение временных меток. ОСС сталкивается с этой проблемой даже раньше, поскольку для этой схемы требуется назначать каждой транзакции временные метки по два раза (в начале транзакции и перед фазой валидации). И OCC, и TIMESTAMP показывают производительность хуже, чем другие алгоритмы, независимо от числа ядер. Эти алгоритмы теряют время на копирование кортежей при выполнении операций чтения, в том время как другие алгоритмы читают кортежи прямо на месте их хранения.
5.2 Рабочая нагрузка с большим числом операций записи
Только читающая рабочая нагрузка представляет собой оптимистический (и не реалистический) сценарий, поскольку не приводит к конфликтам по данным. Но даже если внести в рабочую нагрузку операции записи, при большом размере набора данных вероятность одновременного доступа двух транзакций к одному и тому же кортежу невелика. В действительности в приложениях OLTP распределение доступа к кортежам редко бывает равномерным. Более часто этому распределению свойственно скашивание Зипфа, когда доступ к одним кортежам более вероятен, чем к другим. Это может быть связано со скашиванием частоты использования элементов базы данных или с темпоральной локальностью (к новым кортежам обращения происходят более часто). В результате конкуренция за доступ к данным возрастает: транзакции конкурируют за доступ к одним и тем же данным.
Мы выполняли рабочую нагрузку YCSB с большим числом операций записи, включающую транзакции, каждая из которых обращалась к 16 кортежам. В каждой транзакции с вероятностью 50% каждое из обращений к кортежу приводит к его модификации. Величина скашивания в рабочей нагрузке определяется параметром theta (см. подраздел 3.3). В паттернах доступа транзакций к кортежам мы использовали средний и высокий уровни конкуренции.

Рис. 9. Рабочая нагрузка с большим числом операций записи (средний уровень конкуренции) – Результаты для рабочей нагрузки YCSB со средним уровнем конкуренции (theta=0.6)
Результаты экспериментов со средним уровнем конкуренции на рис. 9 показывают, что NO_WAIT и WAIT_DIE являются единственным схемами семейства 2PL, которые масштабируются при числе ядер, большим 512. NO_WAIT масштабируется лучше, чем WAIT_DIE. Что касается DL_DETECT, то рис. 9b показывает, что СУБД при использовании этой схемы проводит большую часть времени в ожидании. При росте числа ядер за пределами 256 DL_DETECT тормозится из-за перегрузки блокировок. Наиболее масштабируемой схемой является NO_WAIT, поскольку это ожидание устраняются. Однако заметим, что при использовании и NO_WAIT, и WAIT_DIE высока частота аварийного завершения транзакций. В наших экспериментах это не является проблемой, поскольку перезапуск транзакции не порождает существенных накладных расходов; время отката транзакции немного меньше времени, требуемого для повторного выполнения ее запросов. Но в действительности для рабочих нагрузок, в которых требуются откаты изменений в нескольких таблицах, индексах и материализованных представлениях, издержки могут быть большими.
Результаты, представленные на рис. 9a, также показывают, что алгоритмы категории T/O в целом работают хорошо. И TIMESTAMP, и MVCC позволяют совмещать выполнение операций и сокращать время ожидания. MVCC работает немного лучше, поскольку сохраняет несколько версий кортежей и поэтому может выполнять запросы на чтение кортежей даже более старых транзакций. OCC так хорошо не работает, потому что тратит большую часть времени на аварийное завершение транзакций; накладные расходы выше, поскольку каждая транзакция должна дойти до конца до разрешения конфликта.

Рис. 10. Рабочая нагрузка с большим числом операций записи (высокий уровень конкуренции) – Результаты для рабочей нагрузки YCSB со высоким уровнем конкуренции (theta=0.8)
Как показано на рис. 10, при наличии высокого уровня конкуренции производительность всех алгоритмов значительно ухудшается. Кривые на рис. 10a показывают, что почти все схемы не могут масштабироваться более, чем к 64 ядрам. После этой точки пропускная способность СУБД перестает возрастать, и возрастание числа ядер не дает выигрыша в производительности. Поначалу NO_WAIT превосходит все остальные схемы, но затем уступает им из-за перегрузки блокировок (см. рис. 4). Как ни странно, на 1024 ядрах лучше всего работает OCC. Это связано с тем, что, хотя большое число транзакций конфликтует, и почти все они должны быть аварийно завершены на этапе валидации, одной транзакции всегда разрешается фиксироваться. Диаграммы на рис. 10b демонстрируют, что СУБД при использовании всех схем тратит большую часть времени на аварийное завершение транзакций.

Рис. 11. Рабочая нагрузка с большим числом операций записи (изменяемый уровень конкуренции) – Результаты для рабочей нагрузки YCSB на 64 ядрах при изменяемом уровне конкуренции
Чтобы лучше понять, когда схемы управления параллелизмом перестают масштабироваться при росте числа ядер, мы фиксировали число ядер (64) и выполнили анализ чувствительности схем при росте значения параметра скашивания (theta). Результаты на рис. 11 показывают, что при значениях theta, меньших 0.6, конкуренция мало влияет на производительность. Но при возрастании значения theta наблюдается резкое падение пропускной способности, приближающейся к нулю при значениях theta, больших 0.8, т.е. все алгоритмы не масштабируются.
5.3 Размер рабочего набора
Другим факторов, влияющим на масштабируемость, является число кортежей, к которым обращается транзакция. При возрастании размера рабочего набора транзакции увеличивается вероятность обращения к тем же данным со стороны другой транзакции. Для алгоритмов типа 2PL это приводит к увеличению интервала времени, в течение которого блокировки удерживаются транзакцией. Однако при использовании T/O удлинение транзакций может снизить уровень конкуренции при выделении временных меток. В описываемом эксперименте мы изменяли число кортежей, к которым обращаются транзакции в рабочей нагрузке YCSB с большим числом операций записи. Поскольку большая пропускная способность достигается при наличии коротких транзакций, мы измеряли не число завершенных транзакций, а число кортежей, к которым происходят обращения в течение секунды. Использовались среднее значение параметра скашивания (theta=0.6) и фиксированное число ядер (512).

Рис. 12. Размер рабочего набора – Число кортежей, к которым происходит обращение в одном ядре при изменении числа запросов (theta=0.6)
Результаты, представленные на рис. 12, показывают, что при наличии коротких транзакций имеется низкий уровень конкуренции за блокировки. В этом сценарии лучшую производительность демонстрируют DL_DETECT и NO_WAIT, потому что дедлоков и аварийных завершений мало. Но по мере возрастания размеров рабочего набора производительность DL_DETECT ухудшается из-за накладных расходов, связанных с перегрузкой блокировок. При использовании алгоритмов класса T/O и схемы WAIT_DIE производительность на рабочей нагрузке с короткими транзакциями является низкой, потому что СУБД проводит большую часть времени на назначение временных меток. Но при удлинении транзакций расходы на выделение временных меток амортизируются. Хуже всего работает OCC, поскольку каждой транзакции назначаются две временные метки.
На рис. 12b показано разбиение времени выполнения транзакций по компонентам СУБД для транзакций длины один. Мы снова видим, что при использовании схем T/O большая часть времени тратится на выделение временных меток. Как показывают рис. 8b и 9b, при удлинении транзакций выделение временных меток перестает быть узким местом. Результаты на рис. 12 также демонстрируют, что алгоритмы на основе T/O более устойчивы к конкуренции, чем DL_DETECT.
5.4 Смесь операций чтения/записи
Еще одним важным фактором управления параллелизмом является смешивание операций чтения и записи. Увеличение числа записей приводит к повышению уровня конкуренции, что по-разному влияет на алгоритмы. В этом эксперименте мы использовали YCSB на конфигурации с 64 ядрами и изменяли процентное соотношение операций чтения и записи в каждой транзакции. В каждой транзакции выполнялось 16 запросов при большом значении параметра скашивания (theta=0.8).

Рис. 13. Смесь операций чтения и записи – Результаты YCSB при изменении доли операций чтения на высоком уровне конкуренции
Результаты на рис. 13 показывают, что все алгоритмы обеспечивают лучшую пропускную способность при наличии большего числа операций чтения. Когда все операции являются операциями чтения, результаты соответствуют результатам для только читающих транзакций на рис. 8a. TIMESTAMP и OCC не работают хорошо, поскольку копируют кортежи для чтения. MVCC отличается наилучшими показателями производительности при небольшом числе операций записи. Это также является примером сценария, в котором наиболее эффективной оказывается поддержка чтений без блокировок за счет наличия нескольких версий; операции чтения обращаются к корректным версиям кортежей и не вынуждаются ожидать завершения пишущих транзакций. В этом состоит ключевое отличие от схемы TIMESTAMP, в которой опоздавшие запросы отвергаются, а соответствующие транзакции аварийно завершаются.
5.5 Разделение базы данных
До этого момента в своем анализе мы предполагали, что вся база данных хранится в одном разделе основной памяти и что все рабочие потоки могут получить доступ к любому кортежу. Однако при использовании схемы H-STORE СУБД для увеличения масштабируемости расщепляет базу данных на непересекающиеся поднаборы данных [38]. Этот подход позволяет достичь хорошей производительности, только если базу данных удается разделить таким образом, чтобы большинству транзакций требовалось обращаться к данным только одного раздела [34]. Если рабочая нагрузка содержит многораздельные транзакции, H-STORE не работает хорошо из-за использования грубой схемы блокировок. Также имеет значение, к какому числу разделов обращаются транзакции; например, H-STORE будет работать плохо даже при небольшом количестве многораздельных транзакций, если они будут обращаться к данным всех разделов. Чтобы исследовать эти проблемы в многоядерной среде, мы сначала сравниваем H-STORE с шестью другими схемами в идеальных условиях. Затем мы анализируем производительность этой схемы при наличии многораздельных транзакций.
В каждом тесте мы разделяли базу данных YCSB на то же число разделов, что и число используемых ядер. Поскольку в базе данных YCSB содержится всего одна таблица, для разделения кортежей использовалась простая стратегия хэширования по значениям первичного ключа, так что в каждом разделе хранилось примерно одинаковое число кортежей. В тестах использовалась рабочая нагрузка с большим числом операций записи. В каждой транзакции выполнялись 16 запросов с использованием индексного поиска без скашивания (theta=0.0). Также предполагалось, что СУБД до начала выполнения каждой транзакции известно, какой раздел назначен этой транзакции.

Рис. 14. Разделение базы данных – Результаты для только читающей рабочей нагрузки на разделенной базе данных YCSB. Транзакции обращаются к кортежам базы данных на основе равномерного распределения.
В первом эксперименте мы выполняли рабочую нагрузку, включающую только однораздельные транзакции. Результаты на рис. 14 показывают, что в средах с числом ядер до 800 H-STORE превосходит по производительности все другие схемы. Поскольку схема H-STORE специально разрабатывалась в расчете на получение преимуществ от разделения базы данных, накладные расходы этой схемы на блокировки значительно меньше, чем у других схем. Но поскольку схеме H-STORE также требуется назначение временных меток для планирования, ей свойственны те же узкие места, что и другим схемам на основе T/O. В результате при большем числе ядер производительность алгоритма деградирует. Для других схем разделение базы данных не оказывает существенного влияния на пропускную способность. Однако можно было бы переработать их реализации, чтобы обеспечить использование преимуществ от разделения [36].

Рис. 15. Многораздельные транзакции – Анализ чувствительности схемы H-STORE для рабочих нагрузок YCSB с многораздельными транзакциями
Затем мы изменили драйвер YCSB, чтобы можно было варьировать долю многораздельных транзакций в рабочей нагрузке, и развернули СУБД на 64-ядерном процессоре. Результаты на рис. 15a иллюстрируют два важных аспекта схемы H-STORE. Во-первых, нет разницы в производительности в зависимости от наличия или отсутствия в рабочей нагрузке пишущих транзакций. Это связано с особенностями схемы блокировок H-STORE. Во-вторых, производительность СУБД падает при возрастании в рабочей нагрузке числа многораздельных транзакций, поскольку при этом уменьшается уровень параллелизма в системе [34, 42].
Наконец, мы выполняли YCSB с 10% многораздельных транзакций и изменяемым число разделов, к которым они обращаются. Пропускная способность СУБД для однораздельных транзакций на рис. 15b так же деградирует из-за выделения временных меток, как и на рис. 14. Поэтому же поэтому пропускная способность системы для рабочих нагрузок с одним и двумя разделами сходится при достижении 1000 ядер. При наличии транзакций, обращающихся в четырем или большему числу разделов, СУБД не масштабируется из-за уменьшения уровня параллелизма и увеличения межъядерных коммуникационных расходов.
5.6 TPC-C
В заключение экспериментов мы проанализировали производительность всех алгоритмов управления параллелизмом на основе бенчмарка TPC-C. Транзакции в TPC-C являются более сложными, чем в YCSB, и представляют большой класс приложений OLTP. Например, они обращаются к нескольким таблицам на основе паттерна «чтение-модификация-запись», и выходные данные некоторых запросов используются в той же транзакции в качестве входных данных последующих запросов. Кроме того, транзакции TPC-C могут аварийно завершаться при наличии некоторых условий в логике программы, а не только из-за того, что СУБД выявляет наличие конфликта.
В каждом тесте рабочая нагрузка включает 50% транзакций NewOrder и 50% транзакций Payment. Эти транзакции составляют 88% смеси TPC-C, используемой по умолчанию, и представляют наибольший интерес с точки зрения сложности. Для поддержки других транзакций потребовались бы дополнительные возможности СУБД, такие как защелки на B-деревьях для синхронизации параллельных обновлений. Это добавило бы в систему дополнительные накладные расходы, и мы отложили рассмотрение проблемы масштабируемости индексов при использовании многоядерных процессоров на будущее.
Размер баз данных TPC-C обычно измеряется числом складов (warehouse). Почти для всех таблиц базы данных склад является корневой сущностью. Мы следуем спецификации TPC-C, в которой задано, что примерно 10% транзакций NewOrder и примерно 15% транзакций Payment обращаются к «удаленному» складу. Для схем, основанных на разделении базы данных (в частности, для H-STORE), каждый раздел включает все данные, относящиеся к одному складу [38]. Это означает, что транзакции над удаленными складами будут обращаться к нескольким разделам.
Сначала мы выполняли рабочую нагрузку TPC-C на базе данных с 4 складами со 100 Мб данных на склад (всего 0.4 Гб). Это позволяет оценить алгоритмы в случае, когда рабочих потоков больше, чем складов. Затем вы выполнили ту же рабочую нагрузку на базе данных с 1024 складами. Из-за ограничений по основной памяти при использовании симулятора Graphite мы уменьшили размер базы данных до 16Мб данных на склад (всего 26 Гб). Это не влияет на измерения, потому что число кортежей, к которым обращается каждая транзакция, не зависит от размеров базы данных.



Рис. 15. TPC-C (4 склада) – Результаты для рабочей нагрузки TPC-C на 256 ядрах
5.6.1 Четыре склада
Результаты на рис. 16 показывают, что на TPC-C все схемы не масштабируются, если число складов меньше числа ядер. При использовании H-Store СУБД не может использовать дополнительные ядра из-за своей схемы с разделением; дополнительные рабочие потоки по существу простаивают. Что касается других схем, то результаты рис. 16c показывают, что они могут масштабироваться до 64 ядер на транзакции NewOrder. TIMESTAMP, MVCC и OCC масштабируются хуже других схем из-за высокой частоты аварийных завершений. DL_DETECT не масштабируется из-за перегрузки блокировок и дедлоков. Но результаты на рис. 16b показывают, что ни одна схема не масштабируется для транзакции Payment. Причина состоит в том, что каждая транзакция Payment обновляет одно поле склада (W_YTD). Это означает, что каждая транзакция должна либо (1) получить монопольную блокировку соответствующего кортежа (DL_DETECT), либо запросить предварительную запись в это поле (алгоритмы, основанные на T/O). Если число рабочих потоков превышает число складов, обновление таблицы складов становится узким местом.
В целом, основной проблемой для этих двух видов транзакций является конкуренция за обновление таблицы WAREHOUSE. Каждая транзакция Payment обновляет соответствующую запись таблицы складов, и каждая NewOrder читает ее. Для алгоритмов на основе 2PL эти операции чтения и записи блокируют одна другую. Два алгоритма на основе T/O (TIMESTAMP и MVCC) превосходят по производительности другие схемы, потому что их при их использовании операции записи не блокируются чтениями. Это устраняет проблему блокировки транзакций, возникающую при применении 2PL. В результате транзакции NewOrder выполняются параллельно с транзакциями Payment.



Рис. 16. TPC-C (1024 склада) – Результаты для рабочей нагрузки TPC-C на 1024 ядрах
5.6.2 1024 склада
Затем мы выполняли рабочую нагрузку TPC-C с 1024 складами на процессоре с числом ядер до 1024. Как мы видим на рис. 17 ни одна из схем не масштабируется. Результаты показывают, что, в отличие от п. 5.6.1, пропускная способность СУБД ограничивается транзакциями NewOrder. Причины для каждой из схем свои.
Почти для всех схем основным узким местом являются накладные расходы на поддержку блокировок и защелок, которые используются даже при отсутствии конкуренции. Например, транзакция NewOrder читает кортежи из только читаемой таблицы ITEM, и при использовании схем 2PL каждое такое обращение порождает совместную блокировку. При наличии большого числа параллельных транзакций становится большим размер заблокированных метаданных и, следовательно, их обновление занимает больше времени. При использовании OCC такие блокировки не устанавливаются во время выполнения транзакции, но на фазе валидации защелкиваются все кортежи, к которым происходит обращение. Для длинных транзакций, таких как NewOrder, получение таких защелок становится проблемой. Хотя блокировки отсутствуют и при использовании MVCC, в этом случае каждый запрос на чтение порождает новую историческую запись, что увеличивает трафик обращений к основной памяти. И все эти действия избыточны с технической точки зрения, потому что таблица ITEM никогда не обновляется.
Результаты на рис. 17b показывают, что, если число складов не меньше числа рабочих потоков, узкое место в транзакции Payment устраняется. Это приводит к повышению пропускной способности всех схем. Однако для схем T/O при большом числе ядер пропускная способность становится слишком большой, и поэтому они тормозятся выделением временных меток. В результате они не могут достичь производительности выше примерно 10 миллионов txn/s. Это тот же сценарий, что и на рис. 12a, в котором для коротких транзакций 2PL превосходит по производительности T/O.
H-STORE в целом работает лучше всех других схем, поскольку с пользой применяет разделение базы данных даже при наличии примерно 12% многораздельных транзакций в рабочей нагрузке. Это подтверждает результаты предыдущих исследований, которые показывают, что H-STORE работает лучше других подходов, если менее 20% транзакций из рабочей нагрузки являются многораздельными [34, 42]. Однако на 1024 ядрах H-STORE ограничивается накладными расходами на выделение временных меток.
6. Обсуждение
Обсудим теперь результаты, описанные в предыдущих разделах, и решения, которые могут помочь избежать отмеченных выше проблем масштабируемости в многоядерных СУБД.
Табл. 2. Сводка узких мест схем управления параллелизмом, оцененных в разд. 5
| 2PL
| DL_DETECT
| Масштабируется при низком уровне конкуренции. Схема подвержена перегрузке блокировок
|
| NO_WAIT
| Отсутствует централизованный предмет конкуренции. Высокий уровень масштабируемости. Очень высокая частота аварийных завершений транзакций
|
| WAIT_DIE
| Присущи перегрузка блокировок. Узкое место – выделение временных меток
|
| T/O
| TIMESTAMP
| Большие накладные расходы на локальное копирование данных. Записи без блокировок. Узкое место – выделение временных меток
|
| MVCC
| Хорошо поддерживает рабочую нагрузку с большим числом операций записи. Чтения и записи без блокировок. Узкое место – выделение временных меток
|
| OCC
| Большие накладные расходы на локальное копирование данных. Высокая стоимость аварийных завершений. Узкое место – выделение временных меток
|
| H-STORE
| Наилучший алгоритм для разделенных рабочих нагрузок. Плохо работает при наличии многораздельных транзакций. Узкое место – выделение временных меток
|
6.1 Узкие места СУБД
Наши эксперименты показывают, что все семь схем управления параллелизмом не масштабируются до большого числа ядер, но по разным причинам и в разных условиях. В табл. 2 обобщены результаты экспериментов с этими схемами. В частности, мы установили несколько факторов, ограничивающих масштабируемость: (1) перегрузка блокировок, (2) вытесняющие аварийные завершения, (3) дедлоки, (4) выделение временных меток и (5) копирование в основной памяти.
Перегрузка блокировок возможна при использовании любого алгоритма, основанного на ожидании. Как отмечалось в подразделе 4.2, перегрузка ослабляется путем упреждающего аварийного завершения. При этом возникает компромисс между аварийными завершениями и производительностью. В целом, результаты подраздела 5.2 показывают, что для рабочих нагрузок с высоким уровнем конкуренции схема с предотвращением тупиков за счет отсутствия ожидания (NO_WAIT) работает намного лучше, чем схема с обнаружением дедлоков (DL_DETECT).
Хотя ни одна схема управления параллелизмом не показывает наилучшую производительность на всех рабочих нагрузках, при наличии определенных условий одна схема может превосходить по производительности все другие схемы. Следовательно, можно комбинировать два или большее число классов алгоритмов в одной СУБД и переключаться с одного на другой в зависимости от рабочей нагрузки. Например, в СУБД может использоваться схема DL_DETECT для рабочих нагрузок с низким уровнем конкуренции, но она может переключиться на NO_WAIT или алгоритмы на основе T/O, если транзакции выполняются слишком долго из-за перегрузки блокировок. Возможны и гибридные подходы, подобные DL_DETECT + MVCC, который применяется в MySQL: для только читающих транзакций используется многоверсионность, а для всех остальных – 2PL.
Эти результаты также дают понять, что для преодоления некоторых из этих узких мест требуется новая аппаратная поддержка. Например, во всех схемах класса T/O при наличии высокой пропускной способности имеется узкое место выделения меток времени. Использование атомарного сложения при большом числе ядер вынуждает рабочие потоки посылать внутри чипа много сообщений для модификации значения временных меток. В подразделе 4.3 мы показали, что лучше всего работают методы часов и аппаратного счетчика без недостатков, свойственных методу пакетирования. Поэтому мы считаем, что подобную аппаратную поддержку следует включить в архитектуру будущих процессоров. Мы также видели, что в некоторых схемах к замедлению могут приводить проблемы с основной памятью. Одним из способов решения этой проблемы является добавление в архитектуру процессора аппаратного ускорителя для поддержки копирования содержимого памяти в фоновом режиме. Это устранило бы потребность в загрузке данных с применением конвейера процессора. В подразделе 4.1 мы также показали, что еще одним узким местом является malloc и что мы смогли преодолеть эту проблему, создав собственную реализацию malloc, динамически изменяющую размер пула. Но при наличии большого числа ядер этими пулами становится слишком трудно управлять в глобальном контроллере основной памяти. Мы полагаем, что в будущих процессорах потребуется перейти к использованию децентрализованных или иерархических контроллеров памяти для обеспечения более быстрого выделения памяти.
6.2 Многоядерные или многоузловые системы?
Утверждается, что распределенные системы могут масштабироваться в большей степени, чем одноузловые СУБД [38]. Это совершенно верно, если число ядер в процессоре невелико и объем основной памяти узла ограничен. Но при переходе к многоузловой архитектуре СУБД возникает новый фактор ограничения производительности – распределенные транзакции [3]. Поскольку такие транзакции могут обращаться к данным, не сохраняемым в одном и том же узле, СУБД должна использовать атомарный протокол фиксации, такой как двухфазный протокол фиксации [16]. При использовании таких протоколов затраты на координацию препятствуют масштабируемости распределенных СУБД, поскольку сетевые коммуникации между узлами являются медленными. В отличие от этого, коммуникации между потоками в среде с общей основной памятью происходят намного быстрее. Это означает, что один многоядерный узел с большим объемом основной памяти может превзойти распределенную СУБД для всех приложений OLTP, кроме, может быть, самых крупных.
Возможно, для многоузловой СУБД требуются два уровня абстракции: реализация без использования общих ресурсов между узлами (shared-nothing) и многопотоковая СУБД с общей памяти внутри одного чипа. Эта иерархия распространена в высокопроизводительных вычислительных приложениях (high-performance computing). Требуется дальнейшие исследования для изучения жизнеспособности и проблем такого иерархического управления параллелизмом в транзакционных.
7. Родственные работы
Одной из первых работ, в которых описывается анализ аппаратной среды СУБД, выполняющей рабочую нагрузку OLTP, была статья [39]. Главным образом, в ней анализировались мультипроцессорные системы, в частности, способы назначения процессов на процессоры для обхода узких мест пропускной способности. В другой работе [37] измерялось время простоя процессора из-за отсутствия в кэше требуемых данных. Это исследование было позже расширено в [2] и сравнительно недавно в [41, 35].
За исключением H-STORE [14, 22, 38, 43] и OCC [28], все остальные схемы управления параллелизмом, реализованные в нашем испытательном стенде, почерпнуты из основополагающих обзоров Бернштейна и др. [3, 5]. В последние годы предпринималось несколько попыток устранения недостатков этих классических реализаций [11, 24, 32, 42]. В других работах предлагались независимые менеджеры блокировок, предназначенные для обеспечения большей масштабируемости многоядерных процессоров [36, 26]. Опишем эти системы более подробно и обсудим, почему они, вероятно, не смогут обеспечить масштабируемость будущих многоядерных архитектур.
Shore-MT [24] – это многопотоковая версия Shore [7], в которой используется схема выявления дедлоков, подобная DL_DETECT. Многие усовершенствования Shore-MT связаны с устранением в системе узких мест, связанных не с управлением параллелизмом, а, например, с журнализацией [25]. На рабочих нагрузках с высоким уровнем конкуренции системе свойственен тот же ограничивающий фактор перегрузки блокировок, что и DL_DETECT.
DORA – это движок OLTP, построенный на основе Shore-MT [32]. Вместо того, чтобы назначать потокам управления транзакции, как принято в традиционной архитектуре СУБД, в DORA потоки управления назначаются разделам базы данных. Когда транзакции требуется доступ к данным в некотором разделе, описатель этой транзакции посылается соответствующему потоку, после чего она ожидает своей очереди на обработку. Это похоже на модель разделения данных в H-STORE за исключением того, что в DORA внутри раздела поддерживаются блокировки уровня записи (а не одна блокировка на каждый раздел) [33]. Мы изучали возможность реализации подхода DORA в своей СУБД, но обнаружили, что его трудно позаимствовать, не выполнив отдельную реализацию системы.
Авторы Silo [42] также отмечали, что в схеме OCC основными узкими местами являются глобальные критические участки. Для преодоления этой проблемы они использовали децентрализованную фазу валидации на основе временных меток, получаемых с помощью пакетного атомарного сложения. Но как мы показали в подразделе 4.3, при наличии большого числа ядер для амортизации стоимости централизованного выделения временных меток СУБД должна использовать крупные пакеты. Это, в свою очередь, приводит к увеличению задержек системы при наличии высокого уровня конкуренции.
Hekaton [11] – это расширение Microsoft SQL Server, позволяющее хранить некоторые таблицы базы данных в основной памяти. В нем используется вариант MVCC со структурами данных, не требующими блокировок [29]. Администратор базы данных определяет некоторые таблицы как таблицы в основной памяти, к которым затем происходят обращения совместно с обращениями к обычным таблицам, хранимым на дисках. Как и во всех алгоритмах на основе T/O, рассмотренных в нашей статье, основным ограничением Hekaton является выделение временных меток.
В централизованном менеджере блокировок VLL для устранения узким мест, связанных с конкуренцией, применяется 2PL с блокировками на уровне кортежей [36]. Схема является оптимизированной версией DL_DETECT, порождающей при низком уровне конкуренции значительно меньшие накладные расходы, чем наша реализация. В VLL это достигается путем разделения базы данных на непересекающиеся поднаборы данных. Как и при использовании схемы H-STORE, этот метод работает хорошо только в тех случаях, когда рабочая нагрузка является разделяемой. При работе внутри каждого раздела все равно имеется критический участок, что ограничивает масштабируемость на рабочих нагрузках с высоким уровнем конкуренции.
В работе [26] отмечается, что основным фактором, ограничивающим масштабируемость MySQL, является конкуренция на защелки. Авторы устраняют эту конкуренцию путем замены паттерна синхронизации «атомарная запись после чтения» (atomic-write-after-read) на схему «чтение после записи» (read-after-write). Они также предлагают для улучшения масштабируемости заранее устанавливать и освобождать партии блокировок. Однако эта схема все равно основана на централизованном выявлении дедлоков и поэтому плохо работает при наличии конкуренции. Кроме того, в предложенной реализации используются глобальные барьеры (global barrier), что проблематично при большом числе ядер.
В других работах изучалась возможность совместной программно-аппаратной разработки для повышения производительности СУБД. Проект по созданию «бионической базы данных» (bionic database) [23] похож на нашу работу, но он фокусируется на реализации операций транзакционных СУБД в ПЛИС (программируемая логическая интегральная схема, FPGA), а не напрямую в аппаратуре процессора. Ряд работ посвящался аналитическим СУБД, и поэтому полученные в них результаты неприменимы в нашей предметной области. Например, в предлагаемом в [10] ускорителе SQL на основе использования ПЛИС данные, выбираемые из источника данных, фильтруются «на лету» при их передаче потребителю данных. Проект нацелен на поддержку OLAP-приложений за счет ускорения операций проецирования и ограничения путем использования ПЛИС. В проекте Q100 [44] предлагается специальный аппаратный сопроцессор для поддержки выполнения OLAP-запросов. Предполагается, что таблицы базы данных хранятся по столбцам, и обеспечиваются специальные аппаратные модули для каждого вида операторов SQL.
8. Планы на будущее
В представленной работе раскрыты основные узкие места алгоритмов управления параллелизмом, ограничивающие их масштабируемость при росте числа ядер. Поскольку эти узкие места неотъемлемы от имеющихся алгоритмов, по-видимому, не существуют способы обойти их программным путем. Если это действительно так, единственным подходом к решению проблемы является совместная программно-аппаратная разработка. В некоторых случаях специализированная аппаратура может значительно повысить производительность при снижении уровня энергопотребления. Мы планируем исследовать возможные модификации аппаратных средств, которые могут принести максимальный выигрыш в производительности транзакционных СУБД.
Управление параллелизмом – это всего лишь один аспект, влияющий на масштабируемость СУБД. Для построения истинно масштабируемой СУБД требуется исследовать и другие компоненты. Мы планируем исследовать реализации журнализации и индексации, а затем проанализировать возможные оптимизации этих компонентов. Мы также планируем расширить свою работу, допустив использование многоразъемных систем (multisocket system) с более чем одним многоядерным процессором.
9. Благодарности
Это исследование финансировалось (частично) Научно-техническим центром по проблеме «больших данных» компании Intel (Intel Science and Technology Center for Big Data). Мы также выражаем благодарность великому Филу Бернштейну (Phil Bernstein) за его мудрые замечания.
10. Заключение
В этой статье исследовались узкие места масштабируемости в алгоритмах управления параллелизмом для многоядерных процессоров. Мы реализовали упрощенную СУБД с хранением данных в основной памяти, в модульной архитектуре которой поддерживаются семь схем управления параллелизмом. СУБД запускалась на распределенном симуляторе процессора, обеспечивающем виртуальную среду с 1000 ядер. Наши результаты показывают, что при большом числе ядер ни один алгоритм не обеспечивает высокую производительность во всех ситуациях. Для конфигураций с небольшим числом ядер мы обнаружили, что схемы на основе 2PL хорошо работают при наличии коротких транзакций с низким уровнем конкуренции, распространенных среди рабочих нагрузок типа «ключ-значение». В свою очередь алгоритмы на основе T/O лучше работают для более длинных транзакций с более высоким уровнем конкуренции, распространенных в более сложных рабочих нагрузках OLTP. Хотя может показаться, что нет никакой надежды обеспечить масштабируемость транзакционных СУБД при наличии большого числа ядер, мы предложили несколько направлений исследований, которые планируем провести, чтобы устранить эти проблемы масштабирования.
11. Ссылки на литературу
- Intel brings supercomputing horsepower to big data analytics. http://intel.ly/18A03EM, November 2013.
- Ailamaki, D. J. DeWitt, M. D. Hill, and D. A. Wood. DBMSs on a modern processor: Where does time go? In VLDB, pages 266–277, 1999.
- P. A. Bernstein and N. Goodman. Concurrency control in distributed database systems. ACM Comput. Surv., 13(2):185–221, 1981.
- P. A. Bernstein and N. Goodman. Multiversion concurrency control - theory and algorithms. ACM Trans. Database Syst., 8(4):465–483, Dec. 1983.
- P. A. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency Control and Recovery in Database Systems, chapter 5. 1987.
- P. A. Bernstein, D. Shipman, and W. Wong. Formal aspects of serializability in database concurrency control. IEEE Transactions on Software Engineering, 5(3):203–216, 1979.
- M. J. Carey, D. J. DeWitt, M. J. Franklin, N. E. Hall, M. L. McAuliffe, J. F. Naughton, D. T. Schuh, M. H. Solomon, C. Tan, O. G. Tsatalos, et al. Shoring up persistent applications, volume 23. ACM, 1994.
- B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears. Benchmarking cloud serving systems with YCSB. In SoCC’10, pages 143–154.
- J. C. Corbett and et al. Spanner: Google’s Globally-Distributed Database. In OSDI, pages 251–264, 2012.
- C. Dennl, D. Ziener, and J. Teich. On-the-fly composition of fpga-based sql query accelerators using a partially reconfigurable module library. In FCCM, pages 45–52, 2012.
- C. Diaconu, C. Freedman, E. Ismert, P.-A. Larson, P. Mittal, R. Stonecipher, N. Verma, and M. Zwilling. Hekaton: SQL Server’s memory-optimized OLTP engine. In SIGMOD, pages 1243–1254, 2013.
- K. P. Eswaran, J. N. Gray, R. A. Lorie, and I. L. Traiger. The notions of consistency and predicate locks in a database system. Commun. ACM, 19(11):624–633, Nov. 1976.
- J. Evans. jemalloc. http://canonware.com/jemalloc.
- H. Garcia-Molina and K. Salem. Main memory database systems: An overview. IEEE Trans. on Knowl. and Data Eng., 4(6):509–516, Dec. 1992.
- S. Ghemawat and P. Menage. TCMalloc: Thread-caching malloc. http://goog-perftools.sourceforge.net/doc/tcmalloc.html.
- J. Gray. Concurrency Control and Recovery in Database Systems, chapter Notes on data base operating systems, pages 393–481. Springer-Verlag, 1978.
- J. Gray. The transaction concept: Virtues and limitations. In VLDB, pages 144–154, 1981.
- J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger. Quickly generating billion-record synthetic databases. SIGMOD, pages 243–252, 1994.
- J. N. Gray, R. A. Lorie, G. R. Putzolu, and I. L. Traiger. Modelling in data base management systems. chapter Granularity of locks and degrees of consistency in a shared data base, pages 365–393. 1976.
- T. Haerder and A. Reuter. Principles of transaction-oriented database recovery. ACM Comput. Surv., 15(4):287–317, Dec. 1983.
- S. Harizopoulos, D. J. Abadi, S. Madden, and M. Stonebraker. OLTP through the looking glass, and what we found there. In SIGMOD, pages 981–992, 2008.
- M. Heytens, S. Listgarten, M.-A. Neimat, and K. Wilkinson. Smallbase: A main-memory dbms for high-performance applications. Technical report, Hewlett-Packard Laboratories, 1995.
- R. Johnson and I. Pandis. The bionic dbms is coming, but what will it look like? In CIDR, 2013.
- R. Johnson, I. Pandis, N. Hardavellas, A. Ailamaki, and B. Falsafi. Shore-MT: a scalable storage manager for the multicore era. EDBT, pages 24–35, 2009.
- R. Johnson, I. Pandis, R. Stoica, M. Athanassoulis, and A. Ailamaki. Aether: a scalable approach to logging. Proc. VLDB Endow., 3(1-2):681–692, 2010.
- H. Jung, H. Han, A. D. Fekete, G. Heiser, and H. Y. Yeom. A scalable lock manager for multicores. In SIGMOD, pages 73–84, 2013.
- R. Kallman, H. Kimura, J. Natkins, A. Pavlo, A. Rasin, S. Zdonik, E. P. C. Jones, S. Madden, M. Stonebraker, Y. Zhang, J. Hugg, and D. J. Abadi. H-Store: A High-Performance, Distributed Main Memory Transaction Processing System. Proc. VLDB Endow., 1(2):1496–1499, 2008.
- H. T. Kung and J. T. Robinson. On optimistic methods for concurrency control. ACM Trans. Database Syst., 6(2):213–226, June 1981.
- P.-A. Larson, S. Blanas, C. Diaconu, C. Freedman, J. M. Patel, and M. Zwilling. High-performance concurrency control mechanisms for main-memory databases. VLDB, 5(4):298–309, Dec. 2011.
- J. Miller, H. Kasture, G. Kurian, C. Gruenwald, N. Beckmann, C. Celio, J. Eastep, and A. Agarwal. Graphite: A distributed parallel simulator for multicores. In HPCA, pages 1–12, 2010.
- D. L. Mills. Internet time synchronization: the network time protocol. Communications, IEEE Transactions on, 39(10):1482–1493, 1991.
- Pandis, R. Johnson, N. Hardavellas, and A. Ailamaki. Data-oriented transaction execution. Proc. VLDB Endow., 3:928–939, September 2010.
- Pandis, P. Tözün, R. Johnson, and A. Ailamaki. PLP: Page Latch-free Shared-everything OLTP. Proc. VLDB Endow., 4(10):610–621, July 2011.
- Pavlo, C. Curino, and S. Zdonik. Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems. In SIGMOD, pages 61–72, 2012.
- D. Porobic, I. Pandis, M. Branco, P. Tözün, and A. Ailamaki. OLTP on Hardware Islands. Proc. VLDB Endow., 5:1447–1458, July 2012.
- K. Ren, A. Thomson, and D. J. Abadi. Lightweight locking for main memory database systems. In VLDB, pages 145–156, 2013.
- M. Rosenblum, E. Bugnion, S. A. Herrod, E. Witchel, and A. Gupta. The impact of architectural trends on operating system performance. In SOSP, pages 285–298, 1995.
- M. Stonebraker, S. Madden, D. J. Abadi, S. Harizopoulos, N. Hachem, and P. Helland. The end of an architectural era: (it’s time for a complete rewrite). In VLDB, pages 1150–1160, 2007.
- S. S. Thakkar and M. Sweiger. Performance of an OLTP application on symmetry multiprocessor system. In ISCA, pages 228–238, 1990.
- The Transaction Processing Council. TPC-C Benchmark (Revision 5.9.0). http://www.tpc.org/tpcc/spec/tpcc_current.pdf, June 2007.
- P. Tözün, B. Gold, and A. Ailamaki. OLTP in wonderland: where do cache misses come from in major OLTP components? In DaMoN, 2013.
- S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden. Speedy transactions in multicore in-memory databases. In SOSP, 2013.
- Whitney, D. Shasha, and S. Apter. High Volume Transaction Processing Without Concurrency Control, Two Phase Commit, SQL or C++. In HPTS’97.
- L. Wu, A. Lottarini, T. K. Paine, M. A. Kim, and K. A. Ross. Q100: the architecture and design of a database processing unit. In ASPLOS, 2014.

