Особенности построения информационных хранилищ
Александр Стулов24.04.2003
Открытые системы, #04/2003
При реализации проектов построения хранилищ данных возникает ряд общих задач, независящих от предметной области: проектирование структуры, актуализация агрегатных значений. В статье рассмотрены возможные пути решения этих задач и способы реализации иерархических измерений.
В основе концепции хранилища данных лежат две основные идеи: интеграция разъединенных детализированных данных (описывающих некоторые конкретные факты, свойства, события и т.д.) в едином хранилище и разделение наборов данных и приложений, используемых для обработки и анализа.
В начале 80-х годов, в период бурного развития регистрирующих информационных систем, появилось осознание ограниченности их применения для анализа данных и построения систем поддержки и принятия решений. Регистрирующие системы создавались для автоматизации рутинных операций: выписки счетов, оформления договоров, проверки состояния склада и т.д., и предназначались для линейного персонала. Основными требованиями к таким системам были обеспечение транзакционности вносимых изменений и максимизация скорости, что и определило тогда выбор реляционных СУБД и модели представления данных «сущность-связь» в качестве основных технических решений при построении регистрирующих систем.
Для менеджеров и аналитиков в свою очередь требовались системы, которые бы позволяли: анализировать информацию во временном аспекте, формировать произвольные запросы к системе, обрабатывать большие объемы данных, интегрировать данные из различных регистрирующих систем. Очевидно, что регистрирующие системы не удовлетворяли ни одному из этих требований — информация в такой системе актуальна только на момент обращения к базе данных, а в следующий момент времени по тому же запросу можно получить совершенно другой результат. Интерфейс регистрирующих систем рассчитан на проведение жестко определенных операций и возможности получения результатов на нерегламентированный (ad-hoc) запрос сильно ограничены. Возможности обработки больших массивов данных также были невелики из-за настройки СУБД на выполнение коротких транзакций.
Ответом на возникшую потребность стало появление технологии хранилищ данных.
Определение и типовые архитектуры хранилищ данных
Определение понятия «хранилище данных» первым дал Уильям Инмон в своей монографии [1] — это «предметно-ориентированная, интегрированная, содержащая исторические данные, неразрушаемая совокупность данных, предназначенная для поддержки принятия управленческих решений».
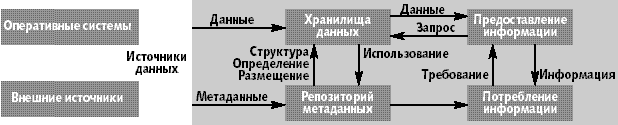
Концептуально модель хранилища данных можно представить в виде схемы [2] на рис. 1. Данные из различных источников помещаются в хранилище, а их описания — в репозиторий метаданных. Конечный пользователь, используя различные инструменты (средства визуализации, построения отчетов, статистической обработки и т.д.) и содержимое репозитория анализирует данные в хранилище. Результатом является информация в виде готовых отчетов, найденных скрытых закономерностей, каких-либо прогнозов. Так как средства работы конечного пользователя с хранилищем данных могут быть самыми разнообразными, то теоретически их выбор не должен влиять на структуру хранилища и функции его поддержания в актуальном состоянии. Физическая реализация данной концептуальной схемы может быть самой разнообразной.
|
| Рис. 1. Концептуальная модель хранилища данных |
Виртуальное хранилище данных — это система, предоставляющая интерфейсы и методы доступа к регистрирующей системе, которые эмулируют работу с данными в этой системе, как с хранилищем данных. Виртуальное хранилище данных можно организовать, создав ряд «представлений» (view) в базе данных, либо применив специальные средства доступа, например, продукты класса Desktop OLAP, к которым относятся, в частности, Business Objects, Brio Enterprise и другие [12]. Главными достоинствами такого подхода являются простота и малая стоимость реализации, единая платформа с источником информации, отсутствие сетевых соединений между источником информации и хранилищем данных.
Однако недостатков гораздо больше. Создавая виртуальное хранилище данных создается не хранилище как таковое, а иллюзия его существования. Структура хранения и само хранение не претерпевают изменений, и остаются проблемы: производительности, трансформации данных, интеграции данных с другими источниками, отсутствие истории, чистоты данных, зависимость от доступности и структуры основной базы данных.
Двухуровневая архитектура хранилища данных подразумевает построение витрин данных (data mart) без создания центрального хранилища, при этом информация поступает из регистрирующих систем и ограничена конкретной предметной областью. При построении витрин используются основные принципы построения хранилищ данных, поэтому их можно считать хранилищами данных в миниатюре. Плюсы: простота и малая стоимость реализации; высокая производительность за счет физического разделения регистрирующих и аналитических систем, выделения загрузки и трансформации данных в отдельный процесс, оптимизированной под анализ структурой хранения данных; поддержка истории; возможность добавления метаданных.
Построение полноценного корпоративного хранилища данных обычно выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных — внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции. Во-первых, он является источником аналитической информации для оперативного управления и, во-вторых, здесь подготавливаются данные для последующей загрузки в центральное хранилище. Под подготовкой данных понимают их преобразование и проведение определенных проверок. Наличие оперативного склада данных просто необходимо при различном регламенте поступления информации из источников. Третий уровень представляет собой набор предметно-ориентированных витрин данных, источником информации для которых является центральное хранилище данных. Именно с витринами данных и работает большинство конечных пользователей.
Проектирование структуры реляционного хранилища данных
Хранилища строятся на основе многомерной модели данных, подразумевающей выделение отдельных измерений (время, география, клиент, счет) и фактов (объем продаж, доход, количество товара) с их анализом по выбранным измерениям. Многомерная модель данных физически может быть реализована как в многомерных, так и в реляционных СУБД. В последнем случае она выполняется по схеме «звезда» или «снежинка». Данные схемы предполагают выделение таблиц фактов и таблиц измерений. Каждая таблица фактов содержит детальные данные и внешние ключи на таблицы измерений.
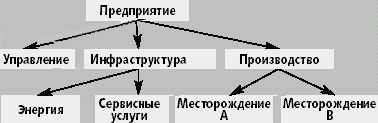
Теория построения многомерной модели данных и ее воплощение в реляционной структуре известна [3, 10, 12], однако информации по проблеме представления иерархий очень мало. В качестве примера измерения, широко применяющегося при анализе деятельности предприятия и имеющего иерархическую структуру, можно привести справочник статей затрат (рис 2).
|
| Рис. 2. Модель иерархического справочника. |
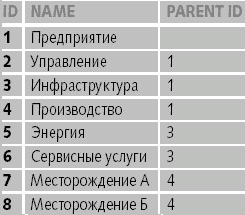
|
| Таблица 1. Представление иерархий с помощью рекурсивной связи |
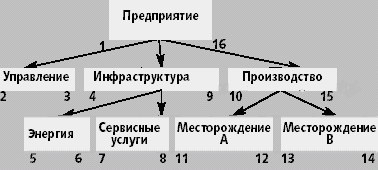
Метод, предложенный Джо Селко [4], основан на теории множеств — все узлы дерева проходятся в прямом порядке [5] и для каждого узла заполняются два значения (cм. нумерацию узлов на рис. 3).
|
| Рис. 3. Нумерация левой и правой границ узлов дерева |
Сначала заполняется левая граница и лишь затем правая — при движении обратно от потомков к родителям. При такой нумерации узлов каждый родитель содержит потомков, левая и правая граница которых лежит в интервале между левой и правой границей родителя. Аналогично все родители потомка имеют левую границу, которая меньше левой границы потомка и правую, большую правой границы потомка. Следовательно, сумму затрат для конкретного места возникновения затрат и всех его составляющих можно получить одним запросом. Например, для получения затрат по инфраструктуре можно выполнить следующий SQL-запрос:
select sum(fact_table.cost)
from fact_table, dimension_table D1, dimension_table D2
where fact_table.dimension_id = D2.id
and D2.left >= D1.left
and D2.right <= D1.right
and D1.name = «Инфраструктура»
Для простоты работы с таким справочником кроме полей left, right стоит добавить еще два поля: «Level» — уровень узла в дереве, «Is_leaf» — флаг, показывающий является ли узел листом в дереве или нет. Таким образом, мы получаем таблицу «dimension_table» (таблица 2), которая позволяет хранить дерево любой глубины вложенности и размерности и выбирать потомков и родителей с помощью одного запроса.
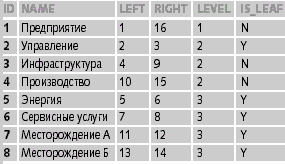
|
| Таблица 2. Представление иерархий с помощью левой и правой границ |
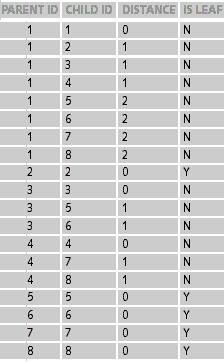
|
| Таблица 3. Структура и содержание вспомогательной таблицы |
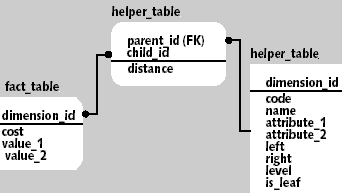
|
| Рис. 4. Модель иерархического справочника с вспомогательной таблицей |
Например, для того, чтобы посчитать сумму затрат, возникающих в местах, находящихся по иерархии на один уровень ниже «Инфраструктуры», необходимо выполнить следующий SQL-запрос:
select sum(fact_table.cost)
from fact_table, dimension_table, helper_table
where fact_table.dimension_id = helper_table.child_id
and dimension_table.dimension_id = helper_table.parent_id
and dimension_table.name = «Инфраструктура»
and helper_table.distance = 1
Проблема проектирования иерархических справочников еще более усложняется когда измерение может иметь несколько альтернативных иерархий и становится совсем трудноразрешимой при необходимости поддерживать историю изменения таблицы измерения.
Проблема медленно меняющихся измерений интересна сама по себе, без усложнения ее иерархичностью классификаторов. В литературе она в большинстве случаев рассматривается в контексте «факт — медленно меняющееся измерение» [7]. Такая задача, действительно, решается относительно просто путем добавления в таблицу измерения даты начала и окончания действия записи. Изменение записи в справочнике приводит к «закрытию» старой записи и добавлению новой.
Возвращаясь к примеру справочника статей затрат, пользователь, желающий получить информацию по актуальной статье затрат на какую-либо конкретную дату, должен включить ее в условие SQL-запроса. Предположим, что справочник статей затрат связан со справочником счетов бухгалтерского учета. Один или несколько бухгалтерских счетов представляют собой статью затрат. Как должно отразиться на справочнике счетов бухгалтерского учета изменение какого-либо атрибута статьи затрат? С одной стороны, с точки зрения плана счетов, изменение атрибута не приводит к изменению сущности статьи затрат и бухгалтерские проводки через план счетов должны относиться на ту же статью. С другой стороны, в справочнике статей затрат появилась новая запись, которая должна быть каким-то образом связана со справочником счетов. Данная проблема может быть решена с помощью разделения таблицы измерений на две — содержащую актуальную информацию и содержащую историю изменения сущности. Этот подход также позволяет решить проблему иерархического измерения с необходимостью поддержания истории изменения записей в нем (рис. 5).
Таблица «dimension_actual» представляет собой таблицу измерений с первичным ключом dimension_id, содержащую корректные атрибуты измерения на сегодняшний день. С ней связана через внешний ключ dimension_id историческая таблица «dimension_history», в которой находится история изменения записей, определяемая датами начала/окончания действия записи (поля date_start, date_end). Актуальная на сегодняшний день запись также присутствует в ней с открытой датой окончания действия. Таблица фактов «fact_table» связана с таблицей измерений через вспомогательную таблицу «helper_table», которая отражает иерархическую структуру измерения.
Важный момент, с которым часто приходится сталкиваться разработчику хранилища данных, связан с агрегатными значениями. Этот класс задач условно можно разделить на два подкласса. Первый рассматривает задачи создания и поддержания агрегатов по имеющимся детальным данным и широко освещен в литературе [8, 11, 12]. Второй связан с тем, что источники данных для хранилища предоставляют собой не детальные значения, а уже некоторый набор агрегированных данных. Такая ситуация типична при создании хранилищ для управляющих компаний и государственных контролирующих органов, собирающих множество отчетных форм.
Крайним случаем такого подхода является модель, которую условно можно назвать «показатель-значение». Суть ее состоит в том, что собирается большой набор показателей, характеризующих финансово-хозяйственную деятельность предприятия. Эти показатели могут быть как связанными между собой функционально, так и нет, могут отражать одни и те же величины, но с разной степенью детализации и т.д. При попытке представить такие данные в виде многомерной модели разработчик сталкивается со значительными проблемами и очень часто идет по пути создания не хранилища данных, а хранилища форм. Типичное хранилище форм строится на основе трех измерений — экономические показатели, время, отчетные формы; таблицы фактов — значения экономических показателей и вспомогательных таблиц, описывающих, как показатели и их значения расположены в отчетных формах. При анализе таких данных аналитик будет испытывать значительные трудности, связанные главным образом с тем, что показатели различных форм нельзя сравнивать между собой. Единственное, что ему остается — это отслеживание изменений показателей одной формы во времени.
Заключение
При реализации проектов по построению хранилищ данных возникает ряд общих задач, независящих от предметной области: проектирование структуры иерархических измерений; проектирование структуры медленно меняющихся измерений; проектирование и актуализация агрегатных значений.В статье были рассмотрены возможные решения этих задач, приведены способы реализации иерархических измерений с помощью введения дополнительных атрибутов, а также с помощью введения дополнительной таблицы. Однако во всех рассмотренных задачах существуют нерешенные вопросы. В частности, сложным для реализации является случай иерархических измерений с необходимостью поддержания истории изменений, которые имеют связи с какими-либо другими справочниками. В статью не вошли также вопросы, касающиеся методов очистки данных [9].
Литература
- Joerg Reinschmidt, Allison Francoise, Business Intelligence Certification Guide. IBM Red Books.
- W. Inmon, Building the Data Warehouse. John Willey & Sons, New York, 1992.
- Э. Спирли, Корпоративные хранилища данных. Планирование, разработка, реализация. Том. 1: Пер. с англ. - М.: "Вильямс", 2001.
- Celko, Trees in SQL: Intelligent Enterprise, 2000, October 20.
- Д. Кнут, Искусство программирования, том 1. Основные алгоритмы, 3-е изд.: - М.: "Вильямс", 2000.
- Ralph Kimball, Help for Hierarchies. DBMS, 1998 September.
- Ralph Kimball, Slowly Changing Dimensions. DBMS, 1996 April.
- В. Дюк, А. Самойленко, Data mining: учебный курс. - СПб: Питер, 2001.
- Erhard Rahm, Hong Hai Do, Data Cleaning: Problems and Current Approaches. IEEE Data Engineering Bulletin, 23(4): 2000.
- Ralph Kimball, The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses. John Willey & Sons, New York, 1996.
- Maria Sueli Almeida, Missao Ishikawa, Joerg Reinschmidt, Torsten Roeber, Getting Started with Data Warehouse and Business Intelligence. IBM Red Books.
- Nigel Pendse, OLAP Architectures: The OLAP Report, http://www.olapreport.com/Architectures.htm#top.
Александр Стулов (alexs@sendmail.ru) — ведущий специалист компании Sovtex — BI Partner (Москва)
Описанный подход позволяет, во-первых, хранить и работать с измерением как с несбалансированным деревом, во-вторых, быстро выполнять запросы, для которых не важна история изменения измерения (не участвует таблица, содержащая историю), в-третьих, позволяет отслеживать историю изменения измерения и, наконец, разделяет отражение истории и иерархии, что значительно упрощает сопровождение измерения.