Базы данных. Вводный курс
Сергей Кузнецов1.4. Потребности информационных систем
Удовлетворяют ли рассмотренные выше базовые возможности файловых систем потребности информационных систем? Типовая информационная система, главным образом, ориентирована на хранение, выбор и модификацию данных соответствующей прикладной области. Структура таких данных зачастую очень сложна, и, хотя структуры данных различны в разных информационных системах, между ними часто бывает много общего.
На начальном этапе использования вычислительной техники для построения информационных систем проблемы структуризации данных решались индивидуально в каждой информационной системе. Производились необходимые надстройки над файловыми системами (библиотеки программ), подобно тому, как это делается в компиляторах, редакторах и т. д. (рис. 1.4).

Рис. 1.4. Примитивная схема структуризации данных в информационной системе
Но поскольку информационные системы требуют сложных структур данных, эти дополнительные индивидуальные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить общую часть информационных систем, ответственную за управление сложно структурированными данными, явилось, на мой взгляд, первой побудительной причиной создания СУБД. Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ (рис. 1.5), реализующей над стандартной базовой файловой системой более сложные методы хранения данных.
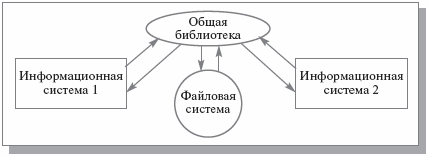
Рис. 1.5. Две информационные системы с общей библиотекой
Поясним это на примере. Предположим, что требуется реализовать простую информационную систему, поддерживающую учет служащих некоторой организации. Система должна выполнять следующие действия:
- выдавать списки служащих по отделам;
- поддерживать возможность перевода служащего из одного отдела в другой;
- обеспечивать средства поддержки приема на работу новых служащих и увольнения работающих служащих.
Кроме того, для каждого отдела должна поддерживаться возможность получения:
- имени руководителя отдела;
- общей численности отдела;
- общей суммы зарплаты служащих отдела, среднего размера зарплаты и т. д.
Для каждого служащего должна поддерживаться возможность получения:
- номера удостоверения по полному имени служащего (для простоты допустим, что имена всех служащих различны);
- полного имени по номеру удостоверения;
- информации о соответствии служащего занимаемой должности и о размере его зарплаты.
1.4.1. Структуры данных
Предположим, что мы решили основывать эту информационную систему на файловой системе и пользоваться одним файлом СЛУЖАЩИЕ, расширив базовые возможности файловой системы за счет специальной библиотеки функций. Поскольку минимальной информационной единицей в нашем случае является служащий, в этом файле должна содержаться одна запись для каждого служащего. Чтобы можно было удовлетворить указанные выше требования, запись о служащем должна иметь следующие поля:
- полное имя служащего (
СЛУ_ИМЯ); - номер его удостоверения (
СЛУ_НОМЕР); - данные о соответствии служащего занимаемой должности (
СЛУ_СТАТ; для простоты «да» или «нет»); - размер зарплаты (
СЛУ_ЗАРП); - номер отдела (
СЛУ_ОТД_НОМЕР).
Поскольку мы решили ограничиться одним файлом СЛУЖАЩИЕ, та же запись должна содержать имя руководителя отдела (СЛУ_ОТД_РУК). (Иначе было бы невозможно, например, получить имя руководителя отдела с известным номером.)
Чтобы информационная система могла эффективно выполнять свои базовые функции, необходимо обеспечить многоключевой доступ к файлу СЛУЖАЩИЕ по уникальным ключам (ключ называется уникальным, если его значения гарантированно различны во всех записях файла) СЛУ_ИМЯ и СЛУ_НОМЕР. Очевидно, что в противном случае для выполнения наиболее часто используемых операций получения данных о конкретном служащем понадобится последовательный просмотр в среднем половины записей файла. Кроме того, должна обеспечиваться возможность эффективного выбора всех записей с общим значением СЛУ_ОТД_НОМЕР, т. е. доступ по неуникальному ключу. Если не поддерживать специальный механизм доступа, то для получения данных об отделе в целом в общем случае потребуется полный просмотр файла. Требуемая общая структура файла СЛУЖАЩИЕ показана на рис. 1.6. Но даже в этом случае, чтобы получить численность отдела или общий размер зарплаты, система должна будет выбрать все записи о служащих указанного отдела и посчитать соответствующие общие значения.
Таким образом, мы видим, что при реализации даже такой простой информационной системы на базе файловой системы возникают следующие затруднения:
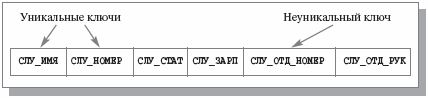
Рис. 1.6. Структура файла СЛУЖАЩИЕ на уровне приложения (случай одного файла)
- требуется создание достаточно сложной надстройки для многоключевого доступа к файлам;
- возникает существенная избыточность данных (для каждого служащего повторяется имя руководителя его отдела);
- требуется выполнение массовой выборки и вычислений для получения суммарной информации об отделах.
Кроме того, если в ходе эксплуатации системы потребуется, например, обеспечить операцию выдачи списков служащих, получающих указанную зарплату, то либо придется при выполнении каждой такой операции полностью просматривать файл, либо нужно будет реструктурировать файл СЛУЖАЩИЕ, объявляя ключевым и поле СЛУ_ЗАРП.
Для улучшения ситуации можно было бы поддерживать два многоключевых файла: СЛУЖАЩИЕ и ОТДЕЛЫ. Первый файл должен был бы содержать поля СЛУ_ИМЯ, СЛУ_НОМЕР, СЛУ_СТАТ, СЛУ_ЗАРП и СЛУ_ОТД_НОМЕР, а второй – ОТД_НОМЕР, ОТД_РУК (номер удостоверения служащего, являющегося руководителем отдела), ОТД_СЛУ_ЗАРП (общий размер зарплаты служащих данного отдела) и ОТД_РАЗМЕР (общее число служащих в отделе). Структура этих файлов показана на рис. 1.7.
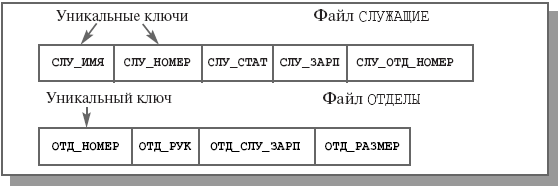
Рис. 1.7. Структура файла СЛУЖАЩИЕ и ОТДЕЛЫ на уровне приложения (случай двух файлов)
Введение этих двух файлов позволило бы преодолеть большинство неудобств, перечисленных в предыдущем абзаце. Каждый из файлов содержал бы только не дублируемую информацию, не возникала бы необходимость в динамических вычислениях суммарной информации по отделам. Но заметим, что при таком переходе наша информационная система должна обладать некоторыми новыми особенностями, сближающими ее с СУБД.
1.4.2. Целостность данных
Теперь система должна «знать», что она работает с двумя информационно связанными файлами (это шаг в сторону схемы базы данных), должна иметь информацию о структуре и смысле каждого поля. Например, системе должно быть известно, что у полей СЛУ_ОТД_НОМЕР в файле СЛУЖАЩИЕ и ОТД_НОМЕР в файле ОТДЕЛЫ один и тот же смысл – номер отдела.
Кроме того, система должна учитывать, что в ряде случаев изменение данных в одном файле должно автоматически вызывать модификацию второго файла, чтобы общее содержимое файлов было согласованным. Например, если на работу принимается новый служащий, то нужно добавить запись в файл СЛУЖАЩИЕ, а также должным образом изменить поля ОТД_СЛУ_ЗАРП и ОТД_РАЗМЕР в записи файла ОТДЕЛЫ, соответствующей отделу этого служащего. Более точно, система должна руководствоваться следующими правилами:
- если в файле
СЛУЖАЩИЕсодержится запись со значением поляСЛУ_ОТД_НОМЕР, равнымn, то и в файлеОТДЕЛЫдолжна содержаться запись со значением поляОТД_НОМЕР, также равнымn; - если в файле
ОТДЕЛЫсодержится запись со значением поляОТД_РУК, равнымm, то и в файлеСЛУЖАЩИЕдолжна содержаться запись со значением поляСЛУ_НОМЕР, также равнымm; в следующих лекциях мы увидим, что правила (1) и (2) являются частными случаями общего правила ссылочной целостности: полеСЛУ_ОТД_НОМЕРсодержит «ссылки» на записи таблицыОТДЕЛЫ, и полеОТД_РУКсодержит «ссылки» на записи таблицыСЛУЖАЩИЕ; - при любом корректном состоянии информационной системы значение поля
ОТД_СЛУ_ЗАРПлюбой записиотд_kфайлаОТДЕЛЫдолжно быть равно сумме значений поляСЛУ_ЗАРПвсех тех записей файлаСЛУЖАЩИЕ, в которых значение поляСЛУ_ОТД_НОМЕРсовпадает со значением поляОТД_НОМЕРзаписиотд_k; - при любом корректном состоянии информационной системы значение поля
ОТД_РАЗМЕРлюбой записиотд_kфайлаОТДЕЛЫдолжно быть равно числу всех тех записей файлаСЛУЖАЩИЕ, в которых значение поляСЛУ_ОТД_НОМЕРсовпадает со значением поляОТД_НОМЕРзаписиотд_k; в следующих лекциях мы увидим, что правила (3) и (4) представляют собой примеры общих ограничений целостности базы данных.
Понятие согласованности, или целостности, данных является ключевым понятием баз данных. Фактически, если информационная система (даже такая простая, как в нашем примере) поддерживает согласованное хранение данных в нескольких файлах, можно говорить о том, что она поддерживает базу данных (БД). Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных (СУБД).
Уже только требование поддержания согласованности данных в нескольких файлах не позволяет при построении информационной системы обойтись библиотекой функций: такая система должна обладать некоторыми собственными данными (их принято называть метаданными), определяющими целостность данных. В нашем примере информационная система должна отдельно сохранять метаданные о структуре файлов СЛУЖАЩИЕ и ОТДЕЛЫ, а также правила, определяющие условия целостности данных в этих файлах (принято считать, что правила также составляют часть метаданных).
1.4.3. Языки запросов
Но обеспечение целостности данных – это далеко не все, что обычно требуется от СУБД. Начнем с того, что даже в нашем примере пользователю информационной системы будет не слишком просто получить, например, общую численность отдела, в котором работает Петр Иванович Сидоров. Придется сначала узнать номер отдела, в котором работает указанный служащий, а затем установить численность этого отдела. Было бы гораздо проще, если бы СУБД позволяла сформулировать такой запрос на языке, более близком пользователям. Такие языки называются языками запросов к базам данных. Например, на языке запросов SQL наш запрос можно было бы выразить в следующей форме (запрос1):
SELECT ОТД_РАЗМЕР
FROM СЛУЖАЩИЕ, ОТДЕЛЫ
WHERE СЛУ_ИМЯ = 'ПЕТР ИВАНОВИЧ СИДОРОВ' AND
СЛУ_ОТД_НОМЕР = ОТД_НОМЕР;
Это пример запроса на языке SQL с полусоединением: c одной стороны, запрос адресуется к двум файлам – СЛУЖАЩИЕ и ОТДЕЛЫ, но с другой стороны, данные выбираются только из файла ОТДЕЛЫ. Условие СЛУ_ОТД_НОМЕР = ОТД_НОМЕР всего лишь «ограничивает» интересующий нас набор записей об отделах до одной записи, если Петр Иванович Сидоров действительно работает на данном предприятии. Если же Петр Иванович Сидоров не работает на предприятии, то условие СЛУ_ИМЯ = 'ПЕТР ИВАНОВИЧ СИДОРОВ' не будет удовлетворяться ни для одной записи файла СЛУЖАЩИЕ, и поэтому запрос выдаст пустой результат.
Возможна и другая формулировка того же запроса (запрос2):
SELECT ОТД_РАЗМЕР
FROM ОТДЕЛЫ
WHERE ОТД_НОМЕР =
(SELECT СЛУ_ОТД_НОМЕР
FROM СЛУЖАЩИЕ
WHERE СЛУ_ИМЯ = 'ПЕТР ИВАНОВИЧ СИДОРОВ');
Это пример запроса на языке SQL с вложенным подзапросом. Во вложенном подзапросе выбирается значение поля СЛУ_ОТД_НОМЕР из записи файла СЛУЖАЩИЕ, в которой значение поля СЛУ_ИМЯ равняется строковой константе 'ПЕТР ИВАНОВИЧ СИДОРОВ'. Если такая запись существует, то она единственная, поскольку поле СЛУ_ИМЯ является уникальным ключом файла СЛУЖАЩИЕ. Тогда результатом выполнения подзапроса будет единственное значение – номер отдела, в котором работает Петр Иванович Сидоров. Во внешнем запросе это значение будет ключом доступа к файлу ОТДЕЛЫ, и снова будет выбрана только одна запись, поскольку поле ОТД_НОМЕР является уникальным ключом файла ОТДЕЛЫ. Если же на данном предприятии Петр Иванович Сидоров не работает, то подзапрос выдаст пустой результат, и внешний запрос тоже выдаст пустой результат.
Приведенные примеры показывают, что при формулировке запроса с использованием SQL можно не задумываться о том, как будет выполняться этот запрос. Среди метаданных базы данных будет содержаться информация о том, что поле СЛУ_ИМЯ является ключевым для файла СЛУЖАЩИЕ (т. е. по заданному значению имени служащего можно быстро найти соответствующую запись или убедиться в том, что запись с таким значением поля СЛУ_ИМЯ в файле отсутствует), а поле ОТД_НОМЕР – ключевое для файла ОТДЕЛЫ (и более того, оба ключа в соответствующих файлах являются уникальными), и система сама воспользуется этим. Можно формально доказать, что формулировки запрос1 и запрос2 эквивалентны, т. е. вне зависимости от состояния данных всегда производят один и тот же результат. Наиболее вероятным способом выполнения запроса в обеих формулировках будет выборка записи из файла СЛУЖАЩИЕ со значением поля СЛУ_ИМЯ, равным строке 'ПЕТР ИВАНОВИЧ СИДОРОВ', взятие из этой записи значения поля СЛУ_ОТД_НОМЕР и выборка из таблицы ОТДЕЛЫ записи с таким же значением поля ОТД_НОМ.
Если же, например, возникнет потребность в получении списка служащих, не соответствующих занимаемой должности, то достаточно обратиться к системе с запросом (запрос3):
SELECT СЛУ_ИМЯ, СЛУ_НОМЕР
FROM СЛУЖАЩИЕ
WHERE СЛУ_СТАТ = "НЕТ";
и система сама выполнит необходимый полный просмотр файла СЛУЖАЩИЕ, поскольку поле СЛУ_СТАТ не является ключевым, и другого способа выполнения не существует.
1.4.4. Транзакции, журнализация и многопользовательский режим
Далее, представим себе, что в первоначальной реализации информационной системы, основанной на использовании библиотек расширенных методов доступа к файлам, обрабатывается операция принятия на работу нового служащего. Следуя требованиям согласованного изменения файлов, информационная система вставляет новую запись в файл СЛУЖАЩИЕ и собирается модифицировать соответствующую запись файла ОТДЕЛЫ (или вставлять в этот файл новую запись, если служащий является первым в своем отделе), но именно в этот момент происходит (например) аварийное выключение питания компьютера.
Очевидно, что после перезапуска системы ее база данных будет находиться в рассогласованном состоянии (точно будут нарушены правила (3) и (4), а может быть, и правила (1)и (2)). Потребуется выяснить это (а для этого нужно явно проверить соответствие данных в файлах СЛУЖАЩИЕ и ОТДЕЛЫ) и привести данные в согласованное состояние. Проверку и коррекцию можно выполнить, например, следующим образом. Сгруппировать записи файла СЛУЖАЩИЕ по значениям поля СЛУ_ОТД_НОМЕР. Для каждой группы (a) проверить, существует ли в файле ОТДЕЛЫ запись, значение поля ОТД_НОМ которой равняется значению поля СЛУ_ОТД_НОМЕР записей данной группы; если такой записи в файле ОТДЕЛЫ нет, то (b) исключить группу из файла СЛУЖАЩИЕ и перейти к обработке следующей группы; иначе (c) посчитать число записей в группе и вычислить суммарное значение заработной платы; (d) обновить полученными значениями поля ОТД_РАЗМЕР и ОТД_СЛУ_ЗАРП соответствующей записи файла ОТДЕЛЫ и перейти к обработке следующей группы.
Настоящие СУБД берут такую работу на себя, поддерживая транзакционное управление и журнализацию изменений базы данных. Прикладная система не обязана заботиться о поддержке корректности состояния базы данных, хотя и должна знать, какие цепочки операций изменения данных являются допустимыми.
Представим теперь, что в информационной системе требуется обеспечить параллельную (например, многотерминальную) работу с базой данных служащих и отделов. Если опираться только на использование файлов, то для обеспечения корректности на все время модификации любого из двух файлов доступ других пользователей к этому файлу будет блокирован (вспомните возможности файловых систем в отношении синхронизации параллельного доступа, упоминавшиеся в разделе 1.3 «Файловые системы»). Таким образом, зачисление на работу Петра Ивановича Сидорова существенно затормозит получение информации о служащем Иване Сидоровиче Петрове, даже если они работают в разных отделах. Настоящие СУБД обеспечивают гораздо более тонкую синхронизацию параллельного доступа к данным.
1.4.5. СУБД как независимый системный компонент
До сих пор мы не вычленяли СУБД из состава информационной системы, имея в виду общую организацию системы, подобную той, которая показана на рис. 1.8.
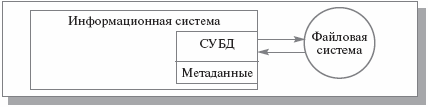
Рис. 1.8. СУБД в составе информационной системы
Здесь видны два дефекта. Во-первых, очевидно, что СУБД должна поддерживать достаточно развитую функциональность. Повторять эту функциональность в каждой информационной системе неразумно. С другой стороны, неясно, каким образом можно обеспечить готовый к использованию компонент СУБД, который можно было бы встраивать в информационные системы. Во-вторых, уже должно быть понятно, что набор файлов можно назвать базой данных только при наличии метаданных. На рис. 1.8 метаданные являются принадлежностью информационной системы, и поэтому, например, файлы СЛУЖАЩИЕ и ОТДЕЛЫ можно эффективно использовать только через нашу гипотетическую систему регистрации служащих.
Предположим, что предприятию нужна еще и информационная бухгалтерская система. Очевидно, что для ее работы также потребуются данные о служащих и отделах. При показанной выше организации системы возможны два варианта выполнения задачи, ни один из которых не является удовлетворительным.
- Внедрить бухгалтерскую систему в состав системы регистрации служащих. Но ведь, как правило, бухгалтерские системы покупаются в виде готовых и отдельных продуктов, не приспособленных к подобному «внедрению».
- Скопировать метаданные системы регистрации служащих в бухгалтерскую систему. Но метаданные (как и данные) не обязательно являются статичными. Структура базы данных может со временем изменяться, могут исчезать одни правила целостности и появляться другие. Как согласовывать копии метаданных, поддерживаемые независимыми информационными системами?
Так мы приходим к организации системы, показанной на рис. 1.9.
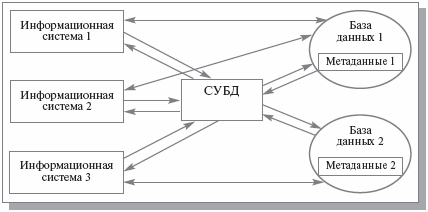
Рис. 1.9. Отдельная СУБД и базы данных с метаданными
Здесь мы видим три информационные системы, которые через одну СУБД работают с двумя разными базами данных, причем первая и вторая системы работают с общей базой данных. Это возможно, поскольку метаданные каждой базы данных содержатся в самих базах данных, и достаточно лишь указать СУБД, с какой базой данных желает работать данное приложение. Поскольку СУБД функционирует отдельно от приложений, и ее работа с базами данных регулируется метаданными, совместное использование одной базы данных двумя информационными системами не вызовет потери согласованности данных, и доступ к данным будет должным образом синхронизироваться. Заметим, что рис. 1.9 вплотную приближает нас к наиболее распространенной в последние десятилетия архитектуре «клиент-сервер». СУБД играет роль «сервера», обсуживающего нескольких «клиентов» – прикладных информационных систем.
Таким образом, СУБД решают множество проблем, которые затруднительно или вообще невозможно решить при использовании файловых систем. При этом существуют приложения, для которых вполне достаточно файлов; приложения, для которых необходимо решать, какой уровень работы с данными во внешней памяти для них требуется, и приложения, для которых, безусловно, нужны базы данных.
1.5. Заключение
Мы начали эту лекцию с рассказа об истории систем управления внешней памятью. Развитие аппаратных и программных средств управления внешней памятью диктовалось потребностями информационных систем, для построения которых требовалась возможность надежного долговременного хранения больших объемов данных, а также обеспечение достаточно быстрого доступа к этим данным.
Системы управления файлами во внешней памяти обеспечивают минимальные потребности информационных систем, предоставляя средства распределения и структуризации дисковой памяти, именования файлов, авторизации доступа и поддержки многопользовательского режима. По мере развития технологии информационных систем их потребности возрастают, выходя за пределы возможностей, обеспечиваемых файловыми системами.
Следует особо обратить внимание на то, что и сегодня основной класс устройств внешней памяти базируется на магнитных дисках с подвижными головками. Поэтому временные соотношения, приведенные в связи с рис. 1.1, по-прежнему весьма актуальны. На этих соотношениях, главным образом, базируются оптимизационные методы, применяемые в современных системах управления данными во внешней памяти.
Далее, на примере тривиальной информационной системы были показаны ситуации, в которых возможности файловых систем явно недостаточны. Более того, попытки расширения возможностей файловой системы путем включения в приложение дополнительных программных компонентов во многих случаях не приводят к успеху. В пределе такие попытки могут привести к появлению самостоятельного программного продукта, обладающего некоторыми чертами СУБД. Однако настоящие СУБД являются настолько большими и сложными программными системами, что вероятность успешного создания «самодельной» СУБД ничтожно мала.
Еще один вывод заключается в том, что при выборе технологии построения информационной системы нужно тщательно оценивать и прогнозировать ее потенциальные потребности в средствах управления данными. Конечно, любую информационную систему можно основывать на использовании промышленной, большой и мощной СУБД. Но вполне может оказаться так, что в действительности приложение будет использовать доли процентов общих возможностей СУБД. Накладные расходы (затраты на дополнительную аппаратуру, лицензирование дорогостоящего программного продукта, увеличение общего времени выполнения операций) могут оказаться неоправданными.