Социальные сети: новые радости и горести
Обзор августовского, 2010 г. номера журнала Computer (IEEE Computer Society, V. 43, No 8, август 2010).
Авторская редакция.
Также обзор опубликован в журнале "Открытые системы"
В этом году темой августовского номера журнала Computer является «социальный мультимедийный компьютинг» (Social Multimedia Computing) – новая область междисциплинарных исследований, в которой наводятся мосты между общественными науками и технологией мультимедиа. У тематической подборки отсутствует приглашенный редактор, и сама она включает только три статьи (честно говоря, к обозначенной теме номера полностью относится только первая из них).
Название этой статьи совпадает с темой номера, написана она Йонхоном Тианом, Тайджуном Хуаном, Джейдипом Сриваставой и Ноширом Контрактором (Yonghong Tian, Tiejun Huang, Peking University, Jaideep Srivastava, University of Minnesota, Noshir Contractor, Northwestern University).
Блоги и социальные сети становятся все более важной частью медийного контента, используемого посетителями Internet. При повсеместном наличии мобильных телефонов, цифровых фото- и видеокамер Internet преобразуется в основной канал доставки пользователям мультимедийного контента. Теперь наблюдается следующий виток эволюции, поскольку за прошедшее десятилетие появились сайты, поддерживающие социальные сети (Facebook, MySpace, Blogger, LinkedIn), и службы совместного использования контента (YouTube, Flickr, Youku), которые становятся платформами, облегчающими производство и совместное использование пользовательского контента, а также создание крупных групп единомышленников.
Гибрид технологий мультимедиа и социальных сетей, который авторы называют социальным мультимедиа, поддерживает новые типы взаимодействий пользователей. Например, в YouTube недавно появилось средство, которое позволяет пользователям откликаться на видеоролики, выложенные другими пользователями, что приводит к появлению асинхронных мультимедийных диалогов. Социальное мультимедиа также обеспечивает дополнительный контекст, облегчающий понимание мультимедийного контента. Например, агрегация данных о поведении всех пользователей, смотрящих один и тот же видеоролик (например, данных о нажатии кнопки «пауза»), может помочь выявить наиболее интересные сцены и объекты этого ролика. Очевидно, что у социального мультимедиа имеется громадный потенциал для изменения способов коммуникации и сотрудничества людей.
В последние годы быстро эволюционировала и компьютерная технология. Под влиянием роста числа приложений социальных сетей возник социальный компьютинг – новая парадигма компьютинга, предполагающая исследование общественного поведения и организационной динамики, а также управление ими для создания интеллектуальных приложений. Однако широкое распространение социального мультимедиа ставит перед социальным компьютингом новые серьезные проблемы, связанные с общественной активностью и взаимодействием в контексте мультимедиа.
Имеется много нерешенных проблем и в области собственно мультимедиа. Социальное мультимедиа может помочь усовершенствовать существующие мультимедийные приложения, и термин социальный мультимедийный компьютинг характеризует междисциплинарную область исследований и разработки приложений, опирающихся на достижения в области общественных наук и технологии мультимедиа.
Следующую статью тематической подборки – «Службы подключения к социальным сетям» («Social-Networks Connect Services») – представили Му Нам Ко, Коррелл Чек, Мохамед Шехаб и Равви Сандху (Moo Nam Ko, Gorrell P. Cheek, Mohamed Shehab, University of North Carolina at Charlotte, Ravi Sandhu, ravi.sandhu@utsa.edu , University of Texas at San Antonio).
Web-сайты, поддерживающие социальные сети, позволяют пользователям устанавливать социальные контакты с членами своей семьи, друзьями и коллегами. Пользователи также часто создают профили для хранения и совместного использования с другими пользователями разного вида контента, включая фотографии, видеоролики и сообщения. Обновление пользовательского профиля интересным контентом является формой самовыражения, способствующим привлечению к таким сайтам новых пользователей. Для содействия этому взаимодействию и обеспечения более насыщенного контента сайты социальных сетей открывают доступ к своим сетям через Web-сервисы в форме онлайновых интерфейсов прикладного программирования (application programming interface, API). Эти API позволяют сторонним разработчикам взаимодействовать с сайтом социальной сети, получать доступ к информации и мультимедийным данным, опубликованным пользователями, а также создавать социальные приложения, агрегирующие, обрабатывающие и производящие контент на основе выявляемых интересов пользователей.
Сайты социальных сетей обеспечивают многочисленные прикладные сервисы, которые могут перемешивать данные пользовательских профилей со сторонними данными. В дополнение к этому, сторонние сайты могут быстро распространять эти сервисы через сайты социальных сетей, чтобы поддерживать связь с пользователями, когда они посещают эти сайты. Кроме того, пользователи могут применять различные приложения над контентом многочисленных сторонних сайтов: пользователи обращаются к сайтам социальных сетей, на которых поддерживаются их профили; сторонние сайты выбирают эти профили, обогащают контент и возвращают его на сайты социальных сетей для потребления соответствующим пользователем и, возможно, его друзьями. Например, пользователи Facebook могут совместно с друзьями использовать музыкальные записи, создавать плей-листы и получать уведомления о концертах путем установки стороннего музыкального приложения iLike.
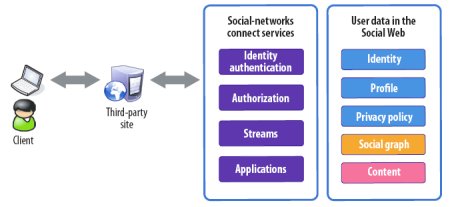
Структура сервисов подключения к социальным сетям
Компании, владеющие основными сайтами социальных сетей, начинают вводить в действие службы подключения к социальным сетям (social-networks connect service, SNCS, такие как Facebook Platform, Google Friend Connect и MySpaceID), которые еще в большей степени разрушают препятствия, ограничивающие доступ к социальным сетям. Эти SNCS дают возможность сторонним компаниям разрабатывать социальные приложения и расширять собственные службы без потребности в хостинге или построении собственной социальной сети. Эта возможность позволяет сторонним компаниям усиливать функциональные характеристики сайтов социальных сетей.
Например, сторонние компании могут использовать службы аутентификации, обеспечиваемые каким-либо сайтом социальной сети, так что от пользователя не требуется создание еще одной пары «логин-пароль» для доступа к сайту сторонней компании. Пользователи могут продолжать применять на этом сайте свою учетную запись в социальной сети и сформированный профиль. Кроме того, пользователи могут обращаться к сторонним сайтам, обогащающим контент пользовательских профилей в социальной сети, что способствует улучшению восприятия контента. Таким образом, SNCS способствуют росту числа участников социальных сетей, позволяя обеспечить более интересный контент из самых разнообразных источников.
Завершает тематическую подборку статья Фей-Ю Ванга, Дэниэла Зенга, Джеймса Хендлера, Кинпен Жанга, Жуо Фенга, Янкин Гао, Гаунпи Лэя (Fei-Yue Wang, Chinese Academy of Sciences, Daniel Zeng, Chinese Academy of Sciences and University of Arizona, James A. Hendler, Rensselaer Polytechnic Institute, Qingpeng Zhang, Zhuo Feng, Yanqing Gao, Guanpi Lai, University of Arizona, Hui Wang, National University of Defense Technology) «Исследование системы поиска во плоти человеческой: движимое толпой расширение онлайнового знания» («A Study of the Human Flesh Search Engine: Crowd-Powered Expansion of Online Knowledge»).
Концепция «поиска во плоти человеческой» (human flesh search, HFS), возникшая в Китае, в последние пять лет привела к возникновению в этой стране нового взрывоопасного Web-явления. В Китае пользователи Web повседневно применяют HFS для выявления коррумпированных правительственных чиновников и частных лиц, занимающихся незаконной или аморальной деятельностью. HFS играет и положительную роль, поддерживая социальные службы, помогающие, например, людям разыскивать родственников, потерявшихся в кризисных ситуациях.
Что же такое «поиск во плоти человеческой»? Этот термин происходит от дословного перевода исходного китайского словообразования 人肉搜索, означающего поиск, который выполняется при помощи людей (в отличие от полностью автоматического поиска, поддерживаемого, например, Google) и часто направлен на выяснение личности какого-либо человека. Более точным переводом был бы «поиск, поддерживаемый людьми» («people-powered» search). Точного определения этого термина в компьютерном контексте пока еще нет, поскольку HFS как Web-явление реального мира находится в стадии формирования. В различных блогах, на wiki-сайтах и в средствах массовой информации появляются многочисленные сомнительные толкования; поскольку они происходят из не китайских источников, то часто являются слишком узкими или чересчур конкретными. Например, в блоге сайта SearchEngineWatch.com HFS определяется, как «нахождение и порицание тех людей, которые публикуют в Web материалы, неугодные пользователям». В статье онлайнового варианта журнала Times активности HFS характеризуются, как «электронная охота за ведьмами» (digital witch hunts). Наконец, в блоге сайта guardian.co.uk HFS называют «Internet-сборищем, которое выслеживает реальных людей и публикует конфиденциальную информацию своих жертв».
Китайские источники дают более широкие определения. Например, на сайте ChinaSupertrends.com HFS определяется, как «онлайновые группы, собирающиеся на основе использования китайских электронных досок объявлений, чатов и систем мгновенной передачи сообщений для совместного решения некоторых задач».
Для эмпирического изучения HFS авторы собрали полный набор онлайновых эпизодов, относящихся к HFS, начиная с момента возникновения этого явления в 2001 г. и до 5 мая 2010 г. В стратегии сбора данных применялся как автоматический поиск в Web, так и ручные действия. К числу использованных источников относились публикации в СМИ, онлайновые форумы, блоги, видео-сайты и т.д. В общей сложности собраны данные о 404 эпизодах. Для каждого эпизода фиксировались время начала и конца HFS-активности, основные типы онлайновых и офлайновых активностей, природа события и окончательный результат. Для 211 эпизодов удалось собрать исходные потоки сообщений, которыми обменивались пользователи, а также их посты.
На основе анализа собранных данных авторы выявили две определяющие характеристики HFS. Во-первых, в большинстве HFS-эпизодов значительная часть активности происходила в режиме офлайн в виде, например, процессов накопления информации из офлайновых источников. Во-вторых, почти во всех эпизодах группы формировались на чисто добровольной основе: пользователи объединялись для обмена информацией, совместного проведения исследований и выполнения других действий в общих интересах.
С системной точки зрения системы HFS (HFS engine, HFSE) представляют собой платформы (специальные Web-сайты и онлайновые форумы), поддерживающие HFS-активности путем широковещательного распространения запросов и планов действий, обеспечения общего доступа к результатам поиска, и иногда, хотя и редко, награждающие особо активных участников.
Вне тематической подборки в августовском номере опубликованы три большие статьи. Яцек Изидоржик и Михаел Изидоржик (Jacek Izydorczyk, Michael Izydorczyk, Silesian University of Technology, Gliwice, Poland) представили статью «Масштабирование микропроцессоров: какие ограничения сохранятся?» («Microprocessor Scaling: What Limits Will Hold?»).
Законы термодинамики и квантовой механики налагают естественные ограничения на возможности разработчиков средств микроэлектроники. Эти ограничения в той или иной форме учитывались проектировщиками, начиная со времени разработки первых интегральных схем (ИС) и заканчивая современными системами на кристалле (system on a chip, SoC). Кроме того, эволюция технологии направлялась законом Мура – каждые два года стоимость ИС в два раза понижается, а число транзисторов в ИС в два раза возрастает.
Однако в последнее время люди стали подвергать сомнению применимость закона Мура и общепринятых показателей разработки. Ускорятся или замедлятся темпы развития микроэлектроники? Авторы полагают, что возможности технологии, если оценивать их числом бит, обрабатываемых с одну секунду, в расчете на квадратный сантиметр полезной площади кристалла, в следующие четыре десятилетия будут возрастать экспоненциально. Первые 20 лет будут посвящены поиску новых материалов, устройств и схем, позволяющих повысить энергоэффективность обработки данных, но в следующие за ними десятилетия необходимо будет сконцентрироваться на разработке новых парадигм проектирования, позволяющих, в частности, создавать надежные и предсказуемые системы на основе ненадежных компонентов. К концу этого сорокалетнего периода можно ожидать появления средств энергоэффективной аналоговой обработки, что позволит создавать вычислительные машины с архитектурой, схожей с нервной системой человека.
Исследования авторов и результаты других экспериментов приводят к тому выводу, что возможности будущей технологии будут зависеть не от размера интегрированных устройств, а от способности ИС отводить рассеваемое тепло. Поэтому авторы видят две основных проблемы: как сократить объем потребляемой энергии и как отводить тепло из ИС. Для поиска ответов на эти вопросы в статье анализируются закон Мура, ограничения развития технологии микроэлектроники, законы термодинамики и теория информации.
Авторы приходят к оптимистическим выводам относительно перспектив дальнейшего масштабирования микропроцессоров и возможности сохранения действия закона Мура. Хотя в ближайшее время трудно ожидать появления революционных решений для сокращения потребления энергии и отвода тепла, постоянные небольшие совершенствования современной технологии CMOS (complementary metal-oxide semiconductor, комплементарный металло-оксидный полупроводник) являются настолько очевидными, что нельзя уверенно говорить о реальных ограничениях этой технологии.
Авторами статьи «Практический распределенный компьютер на основе использования Ibis» («Real-World Distributed Computer with Ibis») являются 13 исследователей из Амстердамского Свободного университета. Первым в списке авторов числится Генри Бал (Henri E. Bal, Vrije Universiteit, Amsterdam, the Netherlands).
В последние два десятилетия наблюдается гигантский прогресс в применении высокопроизводительных и распределенных компьютерных систем в науке и индустрии. К наиболее широко используемым системам относятся вычислительные кластеры, крупномасштабные grid-системы. В последнее время большой популярностью пользуются вычислительные «облака» и мобильные системы. В последние несколько лет исследователи активно изучают такие системы с целью обеспечения прозрачных и эффективных возможностей компьютинга в мировом масштабе.
К сожалению, текущая практика показывает, что пока эта цель остается недостижимой. Например, сегодняшние grid-системы используются для выполнения крупномодульных программ с изменяющимися параметрами или программ, основанных на архитектуре «master-worker». Использование grid для выполнения более сложных приложений обычно ограничивается упрощенными схемами планирования, выбирающими для выполнения приложения какой-либо один узел. Эта ситуация плачевна, поскольку многие научные и производственные приложения могли бы получить выигрыш от использования распределенных компьютерных ресурсов. Эффективному выполнению намного более широкого класса приложений способствуют достижения в области оптоволоконных компьютерных сетей. Кроме того, исследователи не обращают достаточного внимания на проблему, которая может возникнуть при совместном использовании нескольких разобщенных систем для выполнения единого распределенного вычисления. В то же время, подобный сценарий вполне вероятен, поскольку у научных пользователей имеется доступ к весьма разнообразным системам.
По сути, каждый кластер, grid и каждая «облачная» вычислительная среда обеспечивают четко определенные политики доступа, полную связность и простой доступ ко всем своим ресурсам. Такие системы часто являются в основном однородными, предоставляя в каждом узле одну и ту же конфигурацию программного (и даже аппаратного) обеспечения. Однако при объединении нескольких систем образуется распределенная система, являющаяся разнородной по составу программного и аппаратного обеспечения, а также и по производительности своих компонентов. Это приводит к возникновению проблем интероперабельности. Также вероятно и возникновение коммуникационных проблем по причине наличия брандмауеров, разных способов трансляции сетевых адресов, или просто из-за того, что эффективные коммуникации становятся невозможными, поскольку ресурсы слишком разнесены географически. Кроме того, системы часто объединяются динамически, и во время работы системы могут добавляться, исчезать или даже выходить из строя вычислительные ресурсы.
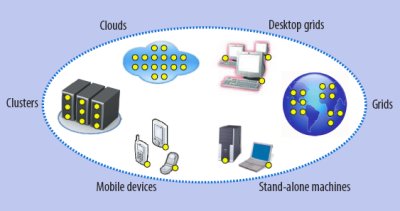
Практическая распределенная система «в худшем случае», состоящая из кластеров, grid’ов, «облаков», а также включающая grid’вы десктопов, отдельные машины и мобильные устройства. Кластеры, grid’ы и «облака» являются хорошо организованными подсистемами с собственным промежуточным программным обеспечением, программными интерфейсами, политиками доступа и механизмами защиты.
Заранее непредусмотренный набор вычислительных ресурсов, общающихся посредством некоторого сетевого соединения, образует практическую распределенную систему. Известно, что создание приложений для таких систем затруднительно, поскольку программисты должны учитывать возможность проблем, упомянутых ранее. Настолько же затруднительно и развертывание приложений, поскольку в каждом компоненте системы имеются свое промежуточное программное обеспечение и политики доступа.
Применение высокопроизводительного распределенного компьютинга можно упростить, если суметь абстрагироваться от этих сложностей за счет наличия одной программной системы, пригодной для использования в любой распределенной системе. По существу, такая система должна обеспечивать две логически независимых подсистемы: систему программирования, обладающую функциональными возможностями, которые традиционно ассоциируются с языками программирования и коммуникационными библиотеками, и систему развертывания, обладающую функциональными возможностями, которые ассоциируются с операционными системами. Система программирования должна позволять разрабатывать приложения, являющиеся не только эффективными, но и устойчивыми к сбоям. В ней должна поддерживаться модель программирования, поддерживающая отказоустойчивость и пластичность (возможность выдерживать динамическое появление и исчезновение машин), а также автоматически разрешающая любые проблемы связности. Система развертывания должна облегчать развертывание приложений и управление ими независимо от того, где они выполняются. Она также должна обеспечивать возможности распределенного управления файлами, аутентификации пользователей, управления ресурсами и взаимодействия разных систем промежуточного программного обеспечения.
Чтобы соответствовать потребностям разных пользователей, от разработчиков прикладного и системного программного обеспечения до пользователей приложений, такая система должна иметь многоуровневую архитектуру. Интерфейсы программирования должны определяться на разных уровнях, каждый из которых соответствует потребностям определенной категории пользователей.
Исследователи во всем мире активно изучают средства и механизмы высокопроизводительных и распределенных вычислений, но ни одна из существующих программных систем не обеспечивает полный спектр требуемых возможностей. Проект Ibis направлен на устранение этого изъяна, обеспечивая интегрированную систему, основанную на простой, ориентированной на пользователей философии: практические распределенные приложения должны разрабатываться и компилироваться на локальной рабочей станции, а потом развертываться в некоторой распределенной системе.
В Ibis используется технология виртуальных машин Java, что позволяет приложениям выполняться в неоднородной среде. Архитектура Ibis основывается на подходе «двух подсистем». Система программирования поддерживает ряд моделей программирования, опирающихся для одну и ту же коммуникационную библиотеку. Система развертывания состоит из графического пользовательского интерфейса и библиотеки для развертывания приложений и управления ими. Программные средства Ibis можно бесплатно скачать с сайта www.cs.vu.nl/ibis.
Последнюю большую статью номера написали Симон Потегис Цварт, Дерек Гроен, Стефан Харфст, Томоаки Ишияма, Кей Хираки, Кейго Нитадори, Юричиро Макино, Стефен МакМиллан и Паола Гроссо (Simon Portegies Zwart, Derek Groen, Stefan Harfst, Leiden University, The Netherlands, Tomoaki Ishiyama, Kei Hiraki, University of Tokyo, Keigo Nitadori, RIKEN, Japan, Junichiro Makino, National Astronomical Observatory of Japan, Stephen McMillan, Drexel University, Paola Grosso, University of Amsterdam). Статья называется «Моделирование Вселенной с использованием межконтинентального Grid’а» («Simulating the Universe on an Intercontinental Grid»).
Пониманию Вселенной учеными мешает неясная природа ее крупнейшей составляющей – холодной темной материи (cold dark matter). Наблюдения за крупными структурами обеспечивают некоторое представление о сути этого явления, в частности, понимание поведения темной материи. Например, исследователям известно, что Млечный путь и другие галактики быстро вращаются, и что темная материя удерживает звезды от выброса за пределы галактики. Известно, что на темную материю воздействует гравитация, и что между этими частицами отсутствует электромагнитное взаимодействие.
Хотя подобные наблюдения продолжаются, они обеспечивают лишь ограниченную информацию. Поэтому для более глубокого изучения темной материи ученые опираются на моделирование, и результаты моделирования используются для лучшего понимания наблюдений и обеспечения возможности предсказаний. Возможность моделирования Вселенной в целом (пока) отсутствует, и поэтому в моделях охватывается только некоторый сектор Вселенной, и для расширения этого сектора до бесконечности используются периодические граничные условия.
В последнее десятилетие эти модели стали достаточно эффективными и обеспечили значительный прогресс в исследованиях. Большая часть моделей концентрируется на образовании и эволюции наблюдаемой суперструктуры Вселенной: галактик, кластеров и темной материи. В соответствии с моделью Λ Cold Dark Matter (где Λ обозначает темную энергию), возраст Вселенной составляет 13,7 миллиардов лет, и она включает примерно 4% барионной материи (звезд и газа), около 23% небарионной (холодной темной) материи и 73% темной энергии.
Точная природа темной материи остается загадкой. Наиболее перспективная гипотеза состоит в том, что темная материя – это скопление слабо взаимодействующих массивных частиц. Сторонники этой гипотезы считают, что вся Вселенная заполнена некоторой мелкоструктурной субстанцией, которая ведет себя подобно гравитационной среде и никаким другим образом не наблюдается. Действие гравитационной силы изменяется обратно пропорционально квадрату расстояния, и поскольку охватываемая масса изменяется пропорционально кубу расстояния, при увеличении масштабов гравитационная сила становится доминирующей. При отсутствии защитных механизмов все объекты подвержены гравитационным взаимодействиям независимо от разделяющего их расстояния.
Популярным методом моделирования темной материи является моделирование гравитационного взаимодействия N тел, когда каждая моделируемая частица представляет текучее тело, состоящее из частиц темной материи. Однако такое моделирование может быть очень ресурсоемким, что делает проблематичным получение значительных результатов. Например, для крупномасштабного моделирования гравитационного взаимодействия N тел на одном суперкомпьютере может потребоваться несколько месяцев.
Эта административная проблема и наличие возрастающего интереса к проблеме распределения ресурсов в крупномасштабном научном компьютинге побудили авторов к выполнению исследования применимости вычислительного grid’а для имитационного моделирования космологической задачи гравитационного взаимодействия N тел. Известно, что использование распределенных ресурсов более рентабельно, если время вычислений растет быстрее времени коммуникаций, и именно так обстояли дела в данном случае. Используемый grid, называемый авторами CosmoGrid, состоит из двух суперкомпьютеров: IBM Power6 в Национальном академическом суперкомпьютерном центре Нидерландов (SARA) в Амстердаме и Cray XT4 в Центре вычислительной астрофизики Японской национальной астрономической обсерватории в Токио. Цель создания этого grid’а заключалась в исследовании возможности эффективного использования большого числа процессоров, когда их разделяют полпланеты. Если бы авторам удалось выполнить моделирование с использованием суперкомпьютеров, находящихся на большом расстоянии один от другого, можно было бы расширять созданную виртуальную организацию, добавляя в нее большее число суперкомпьютеров.
Моделирование было начато в мае 2009 года и завершено примерно через 14 месяцев. Хотя авторам пришлось столкнуться со многими управленческими, политическими и техническими проблемами, им удалось переписать код реализации известного алгоритма моделирования treePM (particle-mesh) таким образом, что эффективность моделирования повысилась на 90% по сравнению с моделированием на одном суперкомпьютере. Эти результаты подтверждают возможность использования grid’ов для высокопроизводительных вычислений.
Хочу обратить внимание читателей на еще один материал августовского номера – заметку Энтони Клива, Тома Менса и Жана-Люка Эно (Anthony Cleve, INRIA Lille-Nord Europe, Tom Mens, University of Mons, Belgium, Jean-Luc Hainaut, University of Namur, Belgium) «Data-Intensive System Evolution»(«Эволюция систем, насыщенных данными»). В этой заметке не описываются какие-либо новые идеи, и она посвящена очень практической теме – проблеме эволюции того, что мы всегда называли приложением базы данных. И особенно приятно, что эта заметка написана в «рабоче-крестьянской»" манере, без каких-либо умствований с применением термина model-driven development и иже с ним (хотя речь, по существу, идет именно об этом). Мне показалось, что эту заметку с удовольствием прочитают многие отечественные практики приложений баз данных, и что она может навести на, возможно, интересные мысли студентов и аспирантов, ищущих темы для самостоятельных исследований. Поэтому я перевел ее на русский язык целиком.