Признаки индивидуальности и конфиденциальность
Обзор майского, 2009 г. номера журнала Computer (IEEE Computer Society, V. 42, No 5, May 2009).
Темой майского номера журнала является надежное управление учетной информацией (trusted identity management). Этой теме посвящены четыре больших статьи и вводная заметка приглашенных редакторов, в роли которых на этот раз выступают Петр Пачина, Энтони Рутковски, Амардео Сарма и Кенжи Такахаши (Piotr Pacyna, AGH University of Science and Technology, Anthony Rutkowski, Netmagic Associates LLC, Amardeo Sarma, NEC Laboratories Europe, Kenji Takahashi, Nippon Telegraph and Telephone Corporation). Вводная заметка называется «Надежная учетная информация для всех: к интероперабельным доверительным системам управления учетной информацией» («Trusted Identity for All: Toward Interoperable Trusted Identity Management Systems»).
Последние годы отмечены новыми вехами в развитии сетевых технологий. Распространение устройств доступа к сетям, в особенности, тех, которые связаны с беспроводными технологиями, делает использование сетей повсеместным, многообразным, создает новые возможности для бизнеса и общества. Сегодняшние сетевые платформы вносят значительный вклад в развитие сервис-ориентированной экономики. В число этих сервисов входит поддержка автоматизированных транзакций, для выполнения которых требуется безошибочный и надежный обмен информацией между участниками транзакции.
Для управления транзакциями и настройки сервисов часто используется персональная информация. Учетная информация об участнике транзакции – его имя и связанные с ним индивидуальные атрибуты, включающие биометрические данные, позволяет формировать и передавать такие данные вне пределов административных границ. Использование атрибутов, идентифицирующих конкретного индивидуума и составляющих его «цифровую личность», является неотъемлемой частью служб сетевых транзакций, в которых участвуют правительственные и коммерческие организации, а также отдельные люди. Однако при этом часто не учитывают, что для учетной информации нужны доверительные якоря (trust anchor).
В отличие от реального мира, для киберпространства характерно исчезновение границ, которые в прошлом служили естественной защитой от утечки персональной информации. Как минимум, эти границы позволяли ограничить возможности злоумышленников по нарушению конфиденциальности. Тенденция к переносу повседневной жизни и деловой активности на территорию Internet раскрывает людей в значительно большей степени, чем это было возможно когда бы то ни было раньше. Сегодня крупнейшая в мире сетевая инфраструктура, включающая значительные компоненты управления учетной информацией (identity management, IdM), поддерживает мобильную телефонию.
Доступность недорогих и легко осваиваемых технологий перехвата и интеллектуального анализа данных облегчает использование учетных данных в злонамеренных целях. В действительности, проблемы краж учетной информации уже стали одними из центральных для правительственных, общественных и коммерческих организаций. Повсеместное внедрение систем для сбора, обработки и совместного использования информации, идентифицирующей конкретных индивидуумов, для поддержки сервисов, делает всех людей уязвимыми к онлайновым кражам учетных данных, что подрывает доверие к информационным технологиям. Это приводит к расширению области исследований, затрагивающих несколько тем IdM, включая совершенствование достоверности и конфиденциальности учетной информации.
Обратной стороной проблемы конфиденциальности является то, что иногда требуется раскрытие индивидуальной информации. В настоящее время системы управления учетной информацией (identity management systems, IdMS) создаются для отдельных целей в частных пространствах компаний, в системах общественного сектора, в государственных системах. Эти системы часто являются специализированными решениям с централизованным управлением, основанными на разных предположениях и направленные на достижение разных целей. В результате между ними обычно отсутствует интероперабельность.
Многие отраслевые группы и организации по стандартизации занимаются разработкой IdMS и стандартизацией протоколов для управления надежными атрибутами, относящимися к учетной информации, которая применяется к различным типам сущностей: поставщикам услуг, клиентам, устройствам и т.д. Разрабатываются различные архитектуры, системы и технологии для управления идентификаторами и атрибутами. В основе существующих решений лежат технологии аутентификации на основе атрибутов, обработки утверждений (identity assertion) и надежного обмена «заявлениями идентификации» (identity claim).
Очевидно, что в будущем пользователям потребуются легкие, но безопасные решения, пригодные для использования в разных сценариях и контекстах. Будущие инфраструктуры IdM должны будут основываться на стандартах и поддерживать разнообразные системы, образуя глобальное пространство IdM, охватывающее множество административных областей.
Первая основная статья тематической подборки называется «Агрегация атрибутов при федеративном управлении учетной информацией» («Attribute Aggregation in Federated Identity Management») и написана Дэвидом Чедвиком и Джорджем Инманом (David W. Chadwick, George Inman, University of Kent, Canterbury).
Ни один отдельно взятый человек и ни одна отдельно взятая система не знают всех атрибутов, удостоверяющих чью-либо личность. Скорее всего, люди должны знать большинство идентифицирующих их самих признаков, но и здесь имеются ограничения. Например, они могут не знать, сколько других людей доверяет этим признакам. В любом случае, в компьютерных системах обычно сохраняется только частичная учетная информация о людях – подмножество их цифровых учетных атрибутов. Эти компьютерные системы называются поставщиками учетной информации (identity providers, IdP).
Обычно учетные атрибуты людей должны предоставляться авторитетными источниками. Хотя людям можно доверить самим указывать некоторые признаки своей индивидуальности, например, говорить о своем любимом напитке, им, конечно, нельзя разрешить самостоятельное указание всех этих признаков, таких как данных о квалификации или сведений о судимости. Таким образом, за связывание людей с разными отличительными признаками отвечают разные авторитетные источники.
При управлении доступом на основе ролей (role-based access control, RBAC) и на основе признаков (attribute-based access control, ABAC) авторизация базируется на ролях или признаках пользователей соответственно. В федеративных системах управления учетной информацией обычно применяется модель ABAC. Системы, назначающие атрибуты пользователям (IdP), отличаются и отделяются от систем, использующих эти признаки и предоставляющих доступ пользователям (поставщиков услуг, service provider, SP). Следовательно, между IdP и SP должны быть установлены доверительные отношения.
На основе этого доверия образуются федерации. Авторизация для использования федеративной службы основывается на признаках индивидуальности пользователей. Если эти признаки обеспечиваются авторитетными источниками, то SP может удостовериться в личности пользователя, даже если ему неизвестны идентификаторы его IdP. Это обуславливает появление таких систем, как Shibboleth или Windows CardSpace, позволяющих произвольному числу IdP и SP образовывать доверительные связи в федерации.
К сожалению, ограничением таких систем в настоящее время является то, что пользователи в любой сессии взаимодействия с данным SP могут выбрать только одного из своих IdP, который посылает SP утверждение об аутентификации и признаках пользователя. Поэтому авторизация может основываться только на подмножестве признаков индивидуальности пользователей. Для многих служб, основанных на Web, этого недостаточно. Требуется механизм, позволяющий пользователям агрегировать признаки, получаемые от нескольких IdP в ходе одной сессии взимодействия с SP. Предлагается концептуальная модель такого механизма, и описываются его возможные реализации.
Следующая статья представлена Полом Мэдсеном и Хироки Ито (Paul Madsen, Hiroki Itoh, NTT Advanced Technology) и названа ими «Проблемы поддержки федеративной уверенности» («Challenges to Supporting Federated Assurance»).
В федеративной модели управления учетной информацией различные задачи, ассоциированные с некоторой транзакцией над учетными данными, распределяются между участниками этой транзакции. Эта модель основывается на том предположении, что распределение задач между участниками может обеспечить пользователям удобство применения и конфиденциальность, а приложениям – эффективность.
Обычно при федеративном управлении учетной информацией некоторые признаки идентификации пользователя передаются от одного объекта другому. Объект, выдающий эти признаки, обычно называется поставщиком учетной информации (IdP), а объект, принимающий их, – проверяющей стороной (relying party, RP), или поставщиком услуг (SP). Классическим примером федеративной транзакции является однократная идентификация в Web (single sign-on, SSO), при которой пользователь, аутентифицированный на одном Web-сайте, может получить доступ к другому сайту без дополнительной аутентификации. Первый сайт (IdP) отвечает за аутентификацию пользователя, а второй (RP) – принимает решение о предоставлении доступа на основе предоставленных ему данных о пользователе.
От IdP к RP передается «статус аутентификации» пользователя, но могут передаваться и другие атрибуты его учетной информации. Между этими двумя сайтами распределяются два фундаментальных действия: IdP аутентифицирует пользователя, а RP на основе этой аутентификации его авторизует. Это распределение обязанностей позволяет, например, первому сайту взимать со второго плату за аутентификацию, а второму сайту, освободившемуся от задач аутентификации, – лучше обеспечивать свои основные сервисы.
Поскольку при федеративном управлении учетной информацией задачи, ассоциированные с данной транзакцией, распределяются между ее участниками, каждый из участников должен быть уверен в том, что другие участники выполняют свои задачи с соответствующим усердием. Например, в SSO для Web, в принципе, ничто не мешает IdP передать RP утверждение об аутентификации пользователя, который, на самом деле, не аутентифицирован. RP должна «доверять» тому, что IdP действительно аутентифицировал пользователя, и что это было сделано именно, так, как утверждает IdP.
В контексте федеративного управления учетной информацией уверенность (assurance) определяется как степень доверия, с которой RP может относиться к утверждениям некоторого IdP в связи с признаками индивидуальности пользователей. Чтобы RP могла принимать утверждения от некоторого IdP для любого нетривиального приложения, ему требуется хотя бы минимальная уверенность. Полное отсутствие уверенности означало бы полное недоверие к содержимому утверждения об учетной информации. Для IdP убедительность является необходимой характеристикой любого создаваемого им утверждения, чтобы он мог рассчитывать, что это утверждение будет принято какой-либо RP. Другими словами, RP требуется уверенность, а IdP стараются удовлетворить это требование.
Уровень уверенности, требуемой RP от федеративной транзакции над учетными данными, зависит от ресурса или приложения, к которому этот RP должен обеспечить доступ. RP будет пытаться снизить риск выполнения федеративной транзакции путем использования соответствующего уровня уверенности. Обеспечение доступа к более ценным ресурсам и приложениям влечет больший риск, и, следовательно, для этого требуется более высокий уровень уверенности. Но, в конце концов, RP сможет определить требуемый уровень уверенности для каждого ресурса. Возможная модель федеративной уверенности показана на рисунке.
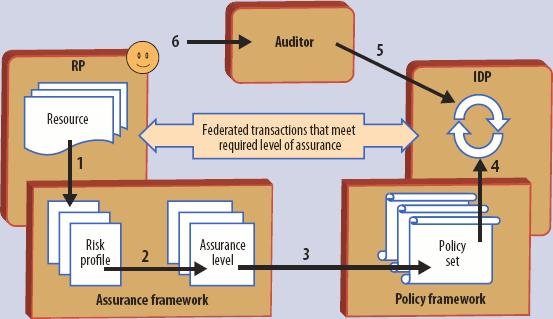
В принципе, уверенность RP, с которой она сможет или захочет отнестись к утверждению данного IdP, будет зависеть от всех процессов, технологий и методов защиты, на которых основывается IdP, и на основе которых основывается содержимое его утверждений. Тем самым, в уровне уверенности отражаются все процессы, инфраструктуры и защитные меры, реализуемые IdP для поддержки своих федеративных операций с RP. Многообразие процессов и технологий обеспечения безопасности, которые могут применяться в данном IdP, приводит к тому, что никакие два IdP, вероятно, не могут обеспечить для одной и той же RP один и тот же уровень уверенности – имеется слишком много переменных. Тем не менее, в реальных федеративных системах уровни уверенности разбиваются на классы. Об этих реализациях говорится в основной части статьи.
Статью «Интероперабельный подход к многофакторной верификации учетной информации» («An Interoperable Approach to Multifactor Identity Verification») представили Федерика Пачи, Родольфо Феррини, Андреа Муски, Кевин Стьюер и Элиза Бертино (Federica Paci, Rodolfo Ferrini, Andrea Musci, Kevin Steuer, Elisa Bertino, Purdue University).
Технологии управления цифровой учетной информацией (digital identity management, DIM) важны для обеспечения эффективного использования информации, идентифицирующей личность людей, в Internet-транзакциях. Цифровая учетная информация включает данные, уникально описывающие индивидуума, а также информацию о его взаимосвязях с другими людьми и объектами. Важным требованием является поддержка конфиденциальности этих атрибутов индивидуальности.
Другим ключевым требованием к системам DIM является интероперабельность. Однако эта среда является сложной, непрерывно изменяющейся, поскольку в индустрии и других организациях продолжают возникать новые возможности и стандарты. В число проблем интероперабельности входит использование разных признаков индивидуальности, протоколов согласования и имен атрибутов учетной информации. Проекты, подобные Concordia Project, помогают согласовать существующие спецификации и протоколы учетной информации, однако в них не затрагивается проблема неоднородности именования. Неоднородность именования возникает в системах DIM, когда различные стороны, участвующие в управлении цифровой учетной информацией (клиенты, проверяющие стороны (RP) и поставщики учетной информации (IdP)), используют разные словари для обозначения атрибутов учетной информации.
Авторы исследуют проблему неоднородности именования в контексте процесса верификации учетной информации клиентов. В этом процессе RP задает набор атрибутов учетной информации, требующихся от пользователя, от имени которого выполняется клиент, и проверяет, что данный пользователь является обладателем этих атрибутов. Пользователь является обладателем атрибутов учетной информации, если уполномочен некоторым IdP использовать эти атрибуты для получения услуг и ресурсов. В политике верификации учетной информации специфицируется такой набор атрибутов. Если клиенты и проверяющие стороны используют имена атрибутов учетной информации из разных словарей, когда некоторый клиент запрашивает ресурс или сервис от некоторой RP, то клиент может не понять, какие атрибуты учетной информации он должен предоставить.
Предлагается многофакторный протокол верификации учетной информации, поддерживающий сопоставление имен атрибутов учетной информации. При многофакторной верификации, когда клиент предоставляет некоторый атрибут, запрошенный RP, эта RP запрашивает дополнительные атрибуты для подтверждения того, что клиент действительно обладает первым атрибутом. В протоколе используется техника сопоставления имен атрибутов учетной информации на основе поисковых таблиц, справочников и отображения онтологий. Также используется криптографический протокол AgZKPK (AGgregated Zero Knowledge Proofs of Knowledge), позволяющий клиентам доказать, что они обладают несколькими атрибутами учетной информации, путем одного интерактивного доказательства. Поскольку клиенты не обязаны предоставлять эти атрибуты в открытой текстовой форме, протокол обеспечивает их конфиденциальность.
Авторами последней статьи тематической подборки – «SWIFT берется за управление учетной информацией» («A SWIFT Take on Identity Management») – являются Габриэль Лопез, Оскар Кановас, Антонио Гомез-Скармета и Жоао Гирао (Gabriel López, Óscar Cánovas, Antonio F. Gómez-Skarmeta, University of Murcia, Spain, Joao Girao, NEC Laboratories Europe).
Управление учетной информацией (IdM) является нарастающей тенденцией Web, преследующей цель упрощения управления учетной информацией с точки зрения пользователей. Кроме того, в системах IdM пытаются последовательно поддерживать конфиденциальность пользователей при доступе к различным Web-сервисам. Web оказывает IdM наиболее сильную поддержку, поскольку способствует быстрому распространению этой технологии, но из-за Web-ориентированности механизмы IdM не слишком широко используются в телекоммуникационных сетях и более традиционных службах, таких как IP-телефония и телевидение. Для интегрированного внедрения IdM в мировом масштабе требуется единая инфраструктура.
Проводимые в последнее время исследования, такие как Европейские проекты Secure Widespread Identities for Telecommunications (SWIFT) и PrimeLife, а также усилия международных организаций International Telecommunication Union (ITU) и World Wide Web Consortium (W3C) способствуют формированию более согласованного представления об IdM на разных уровнях и в разных областях. В этих подходах учитывается развитие Web, но упор делается на аспекты сетевой интеграции. В перспективе пользователи должны получить возможность повсеместно применять эту технологию при доступе к сети или прикладным службам.
Предлагается инфраструктура IdM, обеспечивающая механизмы единой регистрации (SSO) на разных уровнях для пользователей, обладающих подпиской к некоторым службам и поставщикам учетной информации. Инфраструктура обеспечивает защиту конфиденциальности, не допуская действий неавторизованных сторон с теми же идентификаторами пользователей, навязывая правила конфиденциальности разным поставщикам и поддерживая автономность пользователей при разглашении атрибутов.
Инфраструктура обеспечивает функциональные возможности по соединению существующих подписок пользователей и генерации более общей виртуальной учетной информации (virtual identity), в которой объединяются атрибуты, полученные от нескольких поставщиков. Пользователи могут создавать несколько виртуальных учетных записей, используя подмножество атрибутов, предоставляемых поставщиками учетной информации, для которых у пользователей имеется подписка. Концепция виртуальной учетной информации позволяет создавать федерации ресурсов и механизм SSO на основе нескольких IdM. Пользователи могут запрашивать доступ к нескольким службам, указывая свою учетную информацию через виртуальный идентификатор.
Вне тематической подборки опубликованы две большие статьи. Натанаэл Пауль и Эндрью Таненбаум (Nathanael Paul, Andrew S. Tanenbaum, Vrije Universiteit, Amsterdam) представили статью «Достоверное голосование: от машины к системе» («Trustworthy Voting: From Machine to System»).
После скандала с выборами президента США в штате Флорида в 2000 г. многие органы власти стали использовать для голосования электронные машины, которые не сильно отличались от персональных компьютеров с сенсорным экраном. Эти машины были настолько же ненадежными, как и системы с перфокартами. Кроме того, они делали невозможным пересчет результатов голосования, и это осложнение вынудило многие органы власти вернуться к использованию бумажных избирательных бюллетеней.
Но возврат к бумажному голосованию означает также и возврат к проблемам, которые привели к использованию электронных машин, это, по существу, шаг назад. У электронного голосования имеются реальные преимущества над использованием бумажных избирательных бюллетеней, если иметь в виду избирательную систему, а не машину для голосования. Вместо того, чтобы концентрироваться исключительно на более развитых криптографических алгоритмах, разработчикам следует представлять проблему с системной точки зрения, учитывая все ее части и добиваясь защищенности на всех уровнях. На каждом шаге разработки следует почти параноидально предусматривать возможность атак.
С учетом этих соображений в Vrije Universiteit разрабатывается избирательная система, которая практична и устойчива к взломам. В настоящее время реализуется программное обеспечение машины для голосования, и исходный код системы должен стать свободно доступным в этом году.
Наконец, последняя статья майского номера называется «Повышение надежности сетей контроллеров: CANcentrate and ReCANcentrate» («Boosting the Robustness of Controller Area Networks: CANcentrate and ReCANcentrate») и написана Мануэлем Барранчо, Джулианом Проенца и Луисом Алмейда (Manuel Barranco, Julián Proenza, University of the Balearic Islands, Luís Almeida, University of Porto).
Звездообразные топологии лучше ограничивают распространение ошибок, чем шинные топологии, позволяя получать более надежные коммуникационные системы. В некоторых приложениях это преимущество компенсирует более высокую стоимость звездообразных топологий. Например, в области локальных сетей давно произошел переход к звездообразным топологиям с использованием Ethernet, технологии, которая теперь развивается для применения в области производственной автоматизации. Аналогичный переход к звездообразным топологиям произошел в области встроенных систем, например, с использованием протоколов Time-Triggered Protocol (TTP/C) и FlexRay в автомобильных системах. Однако сети контроллеров (controller area network, CAN), которые, по-видимому, наиболее распространены в распределенных встроенных системах, все еще в основном основываются на шинной топологии.
Предлагаются две звездообразные архитектуры для CAN – симплексная звезда (CANcentrate) и звезда с реплицированием (ReCANcentrate). CANcentrate помогает повысить надежность обычных распределенных встроенных систем, а ReCANcentrate позволяет добиться той же цели в приложениях с повышенными требованиями надежности.