Миром правят встроенные системы
Обзор апрельского, 2009 г. номера журнала Computer (IEEE Computer Society, V. 42, No 4, April 2009)
В этом году темой апрельского номера является встраиваемое программное обеспечение (embedded software). Этой теме посвящены только две большие статьи, но первая из них носит обзорный характер, позволяющий взглянуть на направление встраиваемого ПО в целом. Поэтому я выделю в данном обзоре тематическую часть и начну именно с нее.
Упомянутая обзорная статья называется «Встраиваемое ПО: факты, цифры и будущее» («Embedded Software: Facts, Figures, and Future») и написана Кристофом Эбертом и Кейперсом Джонсом (Christof Ebert, Vector, Capers Jones, Software Productivity Research LLC).
Встраиваемое ПО формирует наш мир. Трудно представить повседневную жизнь без него. Примерами устройств, в которых применяется встраиваемое ПО, являются кардиостимуляторы, мобильные телефоны, бытовые электроприборы, космические аппараты, антиблокировочные системы в автомобилях и т.д. Встроенное ПО, с одной стороны, исключительно полезно, но, с другой стороны, порождает небывалые риски.
Хорошим примером того, как встроенное ПО «помогает повысить качество жизни» миллионам людей, являются кардиостимуляторы. В период 1990-2000 гг. производителями было отозвано полмиллиона этих устройств, в 40% которых были обнаружены ошибки во встроенных программах. Для человека, пользующегося кардиостимулятором, шансы того, что производитель устройства отзовет его или предупредит о наличии в нем дефекта в течение года, составляют 1 к 15. Для имплантируемых электрических дефибрилляторов сердца (более сложных устройств, которые могут произвести сильный электрошок при внезапной остановке сердца) шансы на получение предупреждения о возможном дефекте еще выше – примерно 1 к 6.
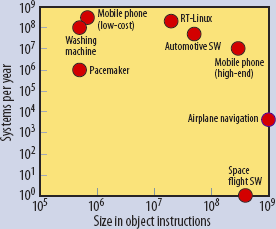
Рис. 1. Размер и применение встраиваемого ПО
Мировой рынок встроенных систем оценивается примерно в 160 миллиардов евро при ежегодном росте на 9%. На рис. 1 показаны размер и ежегодный объем производства некоторых видов встраиваемого ПО. В то время как эти данные сопоставимы с данными о крупнейших программных пакетах, таких как Microsoft Windows, встраиваемое ПО значительно сложнее из-за несвойственных другим видам ПО требований реального времени и ограничений на интерфейсы.
Сообщества встраиваемых и информационных систем склонны к существованию в почти полной взаимной изоляции. Это относится как к конференциям, так и к организационной структуре и продуктам. Разработчики встраиваемого ПО обычно не участвуют в основных компьютерных выставках и конференциях разработчиков программного обеспечения и чаще принимают участие в проблемно-ориентированных мероприятиях, таких как конференции SAE Convergence, поскольку они связывают разработку ПО с конкретными проблемами и решениями индустрии.
В данной статье авторы приводят обзор приемов и методов, влияющих на разработку встраиваемого ПО. Не погружаясь в конкретные методологии разработки, они придерживаются подхода на основе анализа количественных показателей, концентрируясь на новшествах в области разработки встраиваемого ПО.
В 2008 г. в развитых странах на каждого человека приходилось около 30 встроенных микропроцессоров со встроенным ПО, сложность которого оценивается не менее чем в 2,5 миллиона единиц функциональности (function point). По мере возрастания числа автоматических устройств и потребностей в них со стороны пользователей объем встраиваемого ПО растет на 10-20% в год в зависимости от прикладной области. Число встраиваемых микропроцессоров составляет более 98% от общего числа производимых микропроцессоров, и их суммарная мощность значительно превосходит общую мощность компьютеров, используемых в IT-индустрии.
Рис. 2. Рост сложности встраиваемых систем
На рис. 2 показана эволюция некоторых встроенных систем в терминах размера ПО, а именно, бортового ПО в космических аппаратах, телекоммуникационных систем, автомобильного встраиваемого ПО и ядра Linux, которое часто служит основой многих встроенных систем. Windows Mobile и другие встраиваемые операционные системы развиваются с не меньшей скоростью. В своей статье авторы опираются на эти компоненты, поскольку именно с ними работают.
В последние десятилетия темпы роста встраиваемого ПО ускоряются. Например, в новых автомашинах теперь имеется от 20 до 70 электронных блоков с более чем 100 миллионами команд встроенного ПО. В области автомобилестроения стоимостные качества, прежде всего, определяются встроенным ПО, в результате чего не только возрастает цена и сложность, но и повышаются риски из-за потенциальных дефектов в этом ПО. В то время как доля механических дефектов сокращается, число дефектов вызываемых электронными системами, быстро возрастает.
Но как оценить плотность дефектов встраиваемого ПО? Как оценить планы поставщиков, направленные на устранение этих дефектов? Для определения критических «горячих точек» в разработке, тестировании встраиваемого ПО и управлении соответствующими проектами требуется наличие производственных эталонных данных, в частности, об ожидаемых дефектах. Где можно получить такие исходные данные? Они могут не быть легкодоступными или могут оказаться непригодными для новых продуктов, методологий и проектов.
Хотя исследователи начинают публиковать все больше данных о стандартном ПО, это не так в области встраиваемого ПО. Публикуется много неофициальных требований к инструментальным средствам, языкам и методологиям, но опытные данные об их реальной эффективности собираются редко. Причина состоит просто в том, что встраиваемое ПО «растворяется» в окружающих его системах. Это затрудняет экспериментальные исследования.
Приводимые в статье факты и количественные показатели основаны на многолетних экспериментальных исследованиях авторов, производившихся в ходе реальных разработок встраиваемого ПО.
Вторую статью, относящуюся к тематической подборке, написали Хешам Шокри и Майк Хинчи (Hesham Shokry, Mike Hinchey, Lero—the Irish Software Engineering Research Centre). Название статьи – «Основанная на моделях верификация встраиваемого программного обеспечения» («Model-based Verification of Embedded Software»).
По мере снижения стоимости микропроцессоров и памяти возрастает распространенность приложений со встроенным ПО. В последние несколько лет возрастающие требования к функциональным возможностям приложений приводят к появлению все более крупных и сложных встроенных систем. По мере роста числа и сложности этих систем для различных аспектов встроенных приложений требуется достижение все более высокого уровня надежности и устойчивости.
Почти во всех инженерных дисциплинах для того чтобы справиться со сложностью систем используются модели. Разработчики также применяют их как повторно используемые и поддающиеся анализу артефакты, которые позволяют ликвидировать концептуальный разрыв между требованиями и реализацией целевых систем.
В индустрии ПО продолжается рост популярности технологии разработки приложений на основе моделей (model-based development, MBD) для различных прикладных областей, прежде всего, аэрокосмической области, транспорта, медицины и бытовой электроники.
Хотя MDB хорошо поддерживается коммерческими инструментальными средствами, эта технология является относительно новой и непривычной для разработчиков встраиваемого ПО. В частности, при применении MDB для разработки приложений со встроенным ПО разработчикам приходится использовать методы тестирования, отличные от традиционных. Эти методы еще не стандартизованы, но для их поддержки уже имеются мощные коммерчески доступные инструментальные средства. С использованием этих средств технология MDB будет способствовать совершенствованию встроенного ПО.
Модель – это абстрактное представление системы, в котором подчеркивается некоторый частный аспект разработки. Поскольку каждая модель создается для некоторой конкретной цели, уровень абстракции моделей одной и той же системы может сильно различаться, и для их описания могут использоваться разные языки и нотации.
Хотя в индустрии для представления львиной доли моделей, применяемых в MDB, используется UML, в своем «чистом» формате эти модели не слишком пригодны для описания и анализа сложных систем. На фазах проектирования и анализа встроенных систем управления традиционно используются другие виды моделей, основанных на математике. В этих случаях они описывают математические алгоритмы, необходимые для обработки сигналов, управляющих, например, некоторой электромеханической системой. Решение проблем разработки таких моделей и их реализации в приложениях со встроенным ПО требуется, в частности, в автомобильной промышленности.
Вне тематической подборки в апрельском номере опубликованы четыре больших статьи. Сеон Аун Хван (Seong Oun Hwang, Hongik University, Republic of Korea) представил статью «Насколько целесообразно управление цифровыми правами?» («How Viable Is Digital Rights Management?»).
Никто не станет спорить с тем, что Internet революционизировал доступ к информации и обмен ею, но обратной стороной широкого доступа к мультимедиа является нарушение прав интеллектуальной собственности и авторских прав. По мере возрастания спроса на музыку, фильмы и книги достижение требуемой степени (и даже возможности) защиты контента продолжает оставаться юридической, социокультурной и технологической проблемой. Для технологии управления цифровыми правами (rights management, DRM), направленной на защиту цифрового контента, проблема состоит в том, что требуется не отставать от возрастающих разнообразия и интенсивности спроса на доступ к контенту. Пока это не удается, частично из-за того, что старые идеи не обеспечивают должным образом интероперабельность, обещаемую покупателям контента.
Большинство используемых существующих схем DRM основано на недоверии к пользователю; считается, что использование защищенного контента должно быть ограничено. Защита прав на основе такой модели ограниченного использования вызывает проблемы интероперабельности схем DRM и затрудняет создание доверительной инфраструктуры, продолжающей при этом защищать контент.
Компьютерное сообщество должно пересмотреть существующие подходы и глубоко задуматься над способами защиты, гарантирующими, что пользователи смогут использовать приобретенный ими контент независимо от применяемого ими плеера. Потребность в этой гарантии приводит к трудным вопросам, на которые нужно ответить, чтобы сделать следующие шаги. Какая технология может обеспечить защиту прав, ассоциированных с цифровым контентом? Следует ли компьютерному сообществу хотя бы пытаться решать проблемы, связанные с DRM? Например, некоторые контент-провайдеры, в основном, онлайновые музыкальные магазины, уже предлагают пользователям возможность приобретения контента, свободного от DRM.
Чтобы ответить на эти вопросы, исследователям нужно понять, как развивалась технология DRM, в каком отношении эта технология сегодня терпит неудачу, и что требуется изменить, если продолжать считать технологию DRM целесообразной.
Автором следующей статьи – «Реальная стоимость часа работы ЦП» («The Real Cost of a CPU Hour») – является Эдвард Уокер (Edward Walker, University of Texas at Austin).
Во всем мире ширится процесс приобретения и установки кластеров IT-серверов. Эта развивающаяся тенденция частично объясняется верой общества в возможности Internet для поддержки сотрудничества, развлечений и коммуникаций; принятием в организациях IT концепции ПО как сервиса; использованием симуляции в научных исследованиях и при разработке производственной продукции.
В то же время, коммерческие компании, такие как Amazon.com, IBM и Google дают возможность любой организации и даже частным лицам покупать время в их центрах данных через онлайновые Web-службы. При наличии этих сервисов «облачных вычислений» (cloud computing) организации IT могут арендовать компьютерное время для своих вычислительных нужд вместо того чтобы покупать кластер серверов. Например, с августа 2006 г. Amazon.com предлагает Web-сервис Elastic Compute Cloud. Заплатив 10 центов за час времени ЦП, организации могут приобретать экземпляры виртуальных машин с правами суперпользователя, базирующиеся в узлах центра данных Amazon.com.
Но что означают эти 10 центов в час? Является ли эта цена справедливой? Как соотносится эта цена со стоимостью приобретения кластера? Количественные ответы на эти вопросы очень важны для ученых, активно использующих компьютеры, организаций IT и т.д.
Чтобы обеспечить пользователям возможность обоснованного выбора, требуется инструментальное средство для количественного сравнения стоимости приобретения кластера со стоимостью аренды времени ЦП на открытом конкурентном рынке. Предлагаемая автором модель вычисляет стоимость часа времени ЦП с учетом ухудшения характеристик (значимости времени ЦП). Получение этой стоимости позволяет произвести количественное сравнение затрат на аренду компьютерного времени в режиме онлайн и на приобретение кластера серверов.
Статью «Надежное распределенное хранение данных» («Reliable Distributed Storage») написали Грегори Чоклер, Рашид Гуеррау, Идит Кейдар и Марко Вуколич (Gregory Chockler, IBM Haifa Research Laboratory, Rachid Guerraoui, EPFL, Idit Keidar, Technion, Marko Vukolic, IBM Zurich Research Laboratory).
С появлением технологий сетей хранения данных (storage area network, SAN) и сетевых устройств хранения данных (network attached storage, NAS), а также при возрастающей доступности дешевых дисков все более популярными становятся распределенные системы хранения данных. В этих системах для предотвращения потери данных используется репликация, и данные хранятся в нескольких основных блоках хранения (дисках или серверах), называемых базовыми объектами. Такие системы обеспечивают высокий уровень доступности данных. Хранимые данные должны оставаться доступными при выходе из строя любого сервера или диска; иногда они способны выдержать большее число отказов.
Устойчивость системы хранения равна t, если t из n базовых объектов (серверов или дисков) могут выйти из строя без воздействия на доступность или согласованность данных. Уровень устойчивости определяет доступность сервиса. Например, если каждый сервер работоспособен 99% времени, то при хранении данных на одном сервере может быть обеспечена доступность в 99%. Если данные реплицируются на трех серверах (n = 3), и решение выдерживает выход из строя одного сервера (t = 1), то доступность достигает 99.97%.
Популярным способом борьбы с дисковыми отказами является использование избыточного массива недорогих дисков (redundant array of inexpensive disks, RAID). Кроме повышения производительности за счет распределения данных по разным дискам дискового массива, системы RAID предотвращают потерю данных при отказе дисков за счет избыточности путем зеркалирования или использования кодов, исправляющих ошибки (erasure codes). Однако система RAID обычно содержится в одном блоке, расположенном в одном физическом месте. Доступ к RAID производится на основе одного дискового контроллера, а связь с клиентами поддерживается через один сетевой интерфейс. Следовательно, дисковый массив представляет собой единое уязвимое звено.
В отличие от этого, распределенная система хранения данных эмулирует устойчивый к сбоям, совместно используемый объект хранения путем поддержки копий в нескольких местах, так что данные остаются доступными при полном выходе из строя отдельного узла системы. Эта возможность достигается при использовании дешевых дисков или персональных компьютеров для хранения базовых объектов. Исследователи обычно фокусируются на изучении объекта хранения, который поддерживает только базовые операции чтения и записи, обеспечивая доказуемые гарантии. Исследования этих объектов являются фундаментальными, поскольку они являются строительными блоками для более сложных систем хранения. Кроме того, такие объекты можно использовать для хранения файлов, что делает их интересными сами по себе.
Наконец, последняя большая статья апрельского номера называется «Поиск определительных ответов в Web с использованием поверхностных паттернов» («Searching for Definitional Answers on the Web Using Surface Patterns»). Ее авторами являются Алехандро Фигуэро, Гюнтер Ньюман и Джон Аткинсон (Alejandro Figueroa, Günter Neumann, German Research Center for Artificial Intelligence, John Atkinson, University of Concepcion).
В последние годы исследователи, разрабатывающие основанные на Web вопросно-ответные системы (question-answering system, QAS), все больше концентрируются не на простых фактографических вопросах, а на сложных вопросах, для получения ответов на которые требуется обработка информации из многочисленных источников и вывод соответствующих заключений. В одном из типов вопросов, регулярно обсуждаемых на международных форумах, таких как Text Retrieval Conference (TREC), требуется получить определение заданного термина, например, «Что такое эпилепсия?», «Кто такой Том Хэнкс?» или «Что такое WWF?».
Определительные QAS обычно извлекают из нескольких документов предложения, содержащие наиболее полную описательную информацию об искомом термине, а затем обобщают эти предложения до определений. Как правило, используются дополнительные внешние источники определений, такие как энциклопедии и словари, содержащие точные и значимые крупицы определений, которые сливаются с основным корпусом текстов. Однако для интеграции каждого конкретного ресурса требуется разработка специального адаптера. Поэтому основной проблемой разработки определительных QAS является использование Web как источника описательной информации.
В определительных QAS Web часто используется для выборки и обработки больших объемов полных документов. После этого во всех выбранных документах требуется выделить описательные предложения. Определительные вопросы часто встречаются в журналах поисковых машин, что свидетельствует о важности этого типа вопросов. Однако оценить качество QAS, отвечающей на определительные вопросы, намного труднее, чем оценить качество системы, отвечающей на фактографические вопросы, поскольку в данном случае ответы нельзя просто подразделить на «правильные» и «неправильные».
Хотя поисковые машины в Web представляют цельные фрагменты документов, сопровождаемые ссылками на соответствующие полные документы, в определительных QAS не удается воспользоваться этими фрагментами как непосредственным источником описательных фраз. Для решения этой проблемы авторы предлагают новый подход, основанный на перезаписи запросов с целью повышения вероятности извлечения из Web-фрагментов ценных частиц описательной информации путем их сопоставления с поверхностными паттернами. Кроме того, в этом подходе применяются семантический анализ на основе эталонного корпуса текстов и стратегии устранения неоднозначности выбранных слов, описывающих различные аспекты целевых понятий.