Применение модельного подхода для автоматического тестирования оптимизирующих компиляторов
С.В. Зеленов, С.А. Зеленова, А.С. Косачев, А.К. Петренко
Институт Системного Программирования РАН
В статье предлагается концепция автоматизированного построения тестовых наборов и тестовых оракулов для тестирования оптимизаторов. Используется подход, основанный на генерации тестов из моделей. Основные идеи модельного подхода заключаются в следующем: 1) модельный язык неявно разбивает множество программ целевого языка на классы эквивалентности; 2) критерий тестового покрытия формулируется в терминах модельного языка; 3) в соответствии с выбранным критерием генерируется набор тестов. В работе описывается схема построения тестового оракула, который проверяет сохранение семантики программы после ее оптимизации.
- Введение
- Построение абстрактной модели
- Подход к решению задачи проверки сохранения семантики программы во время работы оптимизатора
- Создание генератора тестов
- Запуск тестов
- Практическое применение подхода
- Области применимости подхода
- Близкие работы
- Заключение
- Литература
Введение
Компиляторы [1,2,3] - это основной инструмент при создании программного обеспечения, поэтому их надежность особенно важна. Наряду с другими методами верификации и валидации для компиляторов, тестирование попрежнему остается важным элементом в семье этих методов. Необходимость автоматизации тестирования компиляторов также представляется очевидной, поскольку реальные объемы добротных наборов тестов и сложность анализа результатов весьма велики.
Подход UniTesK [4] является методологий построения надежного и качественного ПО на основе использования моделей этого ПО. UniTesK использует модельный подход в следующих целях:
- для построения критериев правильности реализации ПО,
- для построения критериев полноты и эффективности проверки качества ПО,
- для построения входных тестовых данных и процедур анализа результатов целевого ПО.
В узком смысле UniTesK предлагает рассматривать модели как инструмент для построения тестов целевого ПО. При этом процесс разработки теста и собственно тестирования распадается на следующие фазы:
- Построение абстрактной модели или спецификации поведения целевой системы.
- Извлечение тестового оракула (т.е. процедуры анализа результата целевой системы) из спецификации.
- Разбиение пространства входных данных целевой системы на домены,
- Проектирование критерия тестового покрытия в терминах абстрактной модели.
- Интеграция сгенерированных и вручную написанных компонентов тестовой системы.
-
Пропуск тестов, включающий
- анализ результатов целевой системы при помощи оракулов;
- измерение тестового покрытия в терминах модели/спецификации или в терминах реализации.
Основные достоинства этого подхода состоят в следующем:
- Спецификации и модели обычно строятся на основе функциональных требований к системе, и часто структура спецификаций следует структуре требований, что позволяет явным образом связать требования к системе с результатами тестирования и метриками тестового покрытия.
- Спецификации и модели, а значит и тесты, могут разрабатываться до завершения реализации целевой системы, что сокращает общее время разработки ПО.
- Спецификации и модели обычно компактнее и проще реализации, что упрощает ре-юз и сопровождение как самих моделей, так и тестов, которые строятся на их основе.
- Достижение исчерпывающего покрытия в соответствии с критериями, определенными на спецификациях и моделях, как правило, обеспечивает уровень покрытия реализации, сравнимый с уровнем, достигаемым при традиционном тестировании, но за счет существенно меньших трудозатрат.
Подход UniTesK прошел апробацию в проектах, свзяаннных с тестированием как действующего, так и вновь создаваемого ПО [5,6,7]. Целевое ПО в этих проектах принадлежало к различным классам систем, предоставляющих процедурный интерфейс:
- ядра операционных систем,
- телекоммуникационные протоколы,
- серверы,
- run-time поддержка компиляторов и отладчиков.
Следуя общей схеме процесса UniTesK, описанной выше, удалось полностью автоматизировать работы фаз 2, 3, 5, 6. Фаза 1 выполняется вручную, фаза 4 - полуавтоматически.
Перенос опыта и инструментов UniTesK на тестирование компиляторов вскрыл ряд проблем. В этой статье мы опишем применение этого подхода к тестированию оптимизирующих модулей в компиляторах.
Главная проблема здесь заключается в том, что нет эффективного способа создавать для оптимизатора такие спецификации, из которых можно было бы извлекать эффективные оракулы. Поэтому в предлагаемом подходе мы используем лишь следующие фазы процесса UniTesK:
- Построение абстрактной модели входных данных целевой системы.
- Проектирование критерия тестового покрытия в терминах абстрактной модели.
- Интеграция сгенерированных и вручную написанных компонентов тестовой системы.
-
Пропуск тестов, включающий
- анализ результатов целевой системы при помощи оракулов;
- измерение тестового покрытия в терминах модели/спецификации или в терминах реализации.
В рамках предлагаемого подхода оракул проверяет только сохранение семантики программы во время оптимизации. Для этого в качестве тестовых воздействий на оптимизатор берутся такие программы, семантика которых полностью представляется их трассой. Такое свойство тестов позволяет свести задачу проверки сохранения семантики к сравнению трассы с некоторой эталонной трассой.
Итак, суть подхода такова:
-
Построить для тестируемого оптимизатора представительное множество тестовых воздействий следующим образом:
- построить абстрактную модель входных данных оптимизатора;
- в терминах абстрактной модели сформулировать критерий покрытия этих входных данных;
- перебрать соответствующие тестовые воздействия;
-
Протестировать оптимизатор следующим образом:
- пропустить тесты через компилятор при активированном тестируемом оптимизаторе;
- вынести вердикт относительно сохранения семантики тестов после оптимизации.
В следующих разделах статьи описываются детали процесса тестирования оптимизаторов в соответствии с предлагаемым подходом. В конце приводятся экспериментальные данные по применению методологии, обсуждаются область применимости и ограничения этого подхода и приводится обзор близких работ.
Предварительный вариант настоящей статьи был доложен на международном семинаре ``Понимание программ''[20].
Построение абстрактной модели
Модель строится на основе абстрактного описания алгоритма оптимизации.
Алгоритм оптимизации формулируется с использованием терминов, обозначающих сущности некоторого подходящего абстрактного представления программы, такого как граф потока управления, граф потока данных, таблица символов и пр. Оптимизатор для осуществления своих трансформаций ищет сочетания сущностей абстрактного представления программы, которые удовлетворяют некоторым шаблонам (например, наличие в программе циклов, наличие в теле цикла конструкций с определенными свойствами, наличие в процедуре общих подвыражений, наличие между инструкциями зависимости данных некоторого вида и пр.). При этом могут учитываться сущности лишь части терминов. Для построения модели мы будем рассматривать только те термины, которые именуют сущности, задействованные хотя бы в одном шаблоне.
Итак, в результате анализа алгоритма выделяются термины и шаблоны, используемые в алгоритме. Далее на основании этой информации описывается множество модельных строительных блоков:
- каждому термину соответствует свой вид модельного строительного блока;
- строительные блоки могут связываться между собой чтобы иметь возможность образовывать структуры, соответствующие шаблонам.
Пример: Weak-Zero SIV Subscripts analyzer. Рассмотрим анализатор, собирающий информацию о некотором виде зависимости данных для последующего использования этой информации в различных оптимизаторах. А именно, рассмотрим Weak-Zero SIV Subscripts analyzer (см., например, [3]).
Термин subscript используется для обозначения пары выражений, использующихся в паре обращений в теле цикла к одному (возможно, многомерному) массиву и стоящих на одной и той же позиции в ндексах. Subscript называется SIV (single index variable), если на соответствующей индексируемой позиции используется ровно одна индексная переменная. SIV subscript, зависящий от индукционной переменной i, называется слабо-нулевым (weak-zero), если он имеет вид <ai+c1, c2>, где a, c1, c2 - константы и a≠0.
Зависимость между двумя обращениями к массиву существует тогда и только тогда, когда обращение к общему элементу попадает в границы цикла. Это случается только тогда, когда значение
![]()
является целым и L ≤ i0 ≤ U, где L и U соответственно нижняя и верхняя граница цикла.
Этот алгоритм использует следующие термины: SIV subscript, определяемый тремя коэффициентами a, c1 и c2; цикл, определяемый своей нижней границей L и верхней границей U. Алгоритм осуществляет поиск следующего шаблона:
![]()
Таким образом, модель состоит из следующих видов строительных блоков:
- SIV subscript, содержащий три атрибута, которые соответствуют значениям a, c1 и c2;
- Цикл, содержащий два атрибута, которые соответствуют значениям L и U, а также множество SIV subscript.
![]()
Для частного случая оптимизаций, работающих с таким абстрактным представлением, которое близко синтаксической структуре программы, можно использовать способ построения модели, основанный на идее редукции грамматик (см. [8]).
Пример: Control Flow Graph optimizer. Рассмотрим оптимизатор, который осуществляет трансформации для упрощения графа потока управления процедуры.
Термин линейный участок (basic block) обозначает последовательность инструкций, которая начинается с метки, может заканчиваться условным или безусловным переходом, и может содержать последовательность не-переходных инструкций. Линейный участок называется пустым, если в нем не содержится не-переходных инструкций.
Оптимизатор осуществляет следующие трансформации:
- если некоторый переход J1 ведет на метку L1 некоторого пустого линейного участка, который завершается безусловным переходом J2 на метку L2, то J1 трансформируется в прямую ссылку на метку L2;
- если обе ветви условного перехода J ведут на одну и ту же метку L, то J трансформируется в безусловный переход на метку L;
- если метка L некоторого линейного участка B не используется ни в каком переходе, то B удалается.
Алгоритм этой оптимизации использует такие термины: линейный участок, условный переход, безусловный переход. Алгоритм осуществляет поиск следующих шаблонов:
- переход J1 ведет на метку L1 некоторого пустого линейного участка, который завершается безусловным переходом J2 на метку L2;
- обе ветви условного перехода J ведут на одну и ту же метку L;
- метка L не используется ни в каком переходе;
Этот алгоритм использует граф потока управления в качестве абстрактного представления обрабатываемой программы. Такое представление тесно связано с синтаксической структурой программы. Редукция грамматики языка позволяет получить модель, которая состоит из следующих видов строительных блоков:
- Процедура, содержащая последовательность линейных участков;
- Линейный участок, содержащий метку, переход, а также атрибут ``пустой'';
- Метка, содержащая атрибут ``не используется'';
- Безусловный переход, содержащий ссылку на метку;
- Условный переход, содержащий ссылки на метки.
![]()
Будем называть модельной структурой граф, вершины которого - строительные блоки, а ребра - связи между строительными блоками.
Проекция предложений исходного языка в модельные структуры индуцирует разбиение множества предложений исходного языка на классы эквивалентности. Один класс эквивалентности состоит из предложений, которые имеют одинаковое модельное представление, т.е. которые неразличимы для алгоритма оптимизации. Это свойство позволяет нам выдвинуть гипотезу, согласно которой на эквивалентных предложениях оптимизатор работает одинаково. Следовательно, в желаемом тестовом наборе достаточно иметь не более одного представителя из каждого класса эквивалентности.
Поскольку множество модельных структур, т.е. множество классов эквивалентности, в общем случае бесконечно, то для создания тестового набора мы должны выбрать некоторое его конечное подмножество. Основанием для этого выбора должны служить те шаблоны, которые были выделены при анализе алгоритма оптимизации. Таким образом, критерий тестового покрытия формулируется в терминах абстрактной модели.
Пример: Критерий тестового покрытия для анализатора Weak-Zero SIV Subscripts. Напомним, что анализатор Weak-Zero SIV Subscripts осуществляет поиск следующего шаблона: L ≤ i0 ≤ U и i0 целое, где i0 определяется из соотношения
| (1) |
Сформулируем соответствующий критерий тестового покрытия в терминах модели, т.е. в терминах L, U, a, c1 и c2.
Фиксируем L, U и c1 - целые числа. Пусть a принимает значения 1 и 2. Мы хотим, чтобы i0 принимало целые значения из некоторого множества, а также какие-нибудь нецелые значения. Пусть в упомянутое множество входят целые числа, удовлетворяющие одному из следующих требований:
- i0<L, например, i0=L-1;
- i0=L;
- i0 расположено близко к L внутри интервала, задаваемого границами цикла, например, i0=L+1;
-
i0 расположено в середине интервала,
задаваемого границами цикла,
например, i0=
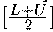 ;
;
- i0 расположено близко к U внутри интервала, задаваемого границами цикла, например, i0=U-1;
- i0=U;
- i0>U, например, i0=U+1.
Для нахождения значения c2 достаточно решить уравнение (1) относительно значений a и i0.
![]()
Подход к решению задачи проверки сохранения семантики программы во время работы оптимизатора
При тестировании важной задачей является анализ правильности работы тестируемой системы. Для случая оптимизатора такой анализ состоит из двух частей:
- проверка, что семантика программы не изменилась после работы оптимизатора;
- проверка, что были произведены все оптимизирующие трансформации.
В настоящей работе мы не касаемся проверки того, что все трансформации были сделаны. Мы здесь рассматриваем лишь необходимую часть оракула, а именно проверку сохранения семантики программы после оптимизации.
Задача проверки сохранения семантики произвольной программы при обработке ее оптимизатором равносильна задаче проверки эквивалентности двух программ. Эта задача в общем случае неразрешима. Тем не менее, для некоторых видов программ такая задача может быть решена. Например, для программ, функциональная семантика которых полностью представляется их трассой.
Напомним, что мы считаем неразличимыми для оптимизатора те программы, которым соответствуют одинаковые модельные структуры. Таким образом, можно в качестве представителей классов эквивалентности выбрать программы, функциональная семантика которых полностью представляется трассой. Для таких программ задача проверки сохранения семантики во время работы оптимизатора сводится к сравнению трассы оптимизированной программы и некоторой эталонной трассы. В качестве такого эталона мы предлагаем использовать трассу, выдаваемую неоптимизированной версией той же программы.
Пример: Инструкции для трассировки в тесте для анализатора Weak-Zero SIV Subscripts. Ниже приведен пример тестового воздействия для анализатора Weak-Zero SIV Subscripts на языке программирования C:
01: void f( int i, int* a, int* b, int* c )
02: {
03: for( i = -10; i <= 10; i++ ) {
04: a[ 31 ] = b[i];
05: c[i] = a[ 22 + 2*i ];
06: }
07: print_int_1_array( a, 2, 43 );
08: print_int_1_array( b, -10, 10 );
09: print_int_1_array( c, -10, 10 );
10: }
Строки 03-06 содержат код, построенный по модельной структуре. Строки 07-09 содержат инструкции для трассировки.
![]()
Для решения задачи проверки сохранения оптимизатором семантики необходимо иметь множество тестов и оракул.
Для построения набора тестов будем генерировать программы P, обладающие следующими свойствами:
- множество программ P является представительным для алгоритма тестируемого оптимизатора, т.е. это множество соответствует выбранному критерию тестового покрытия;
- каждая P компилируется, т.е. синтаксически и семантически корректна;
- каждая P корректно завершается за конечное время;
- каждая P содержит некоторые вычисления в тех местах, которые должны подвергаться оптимизации;
- функциональная семантика каждой P состоит в выводе информации, зависящей от всех имеющихся в программе вычислений.
Работа оракула заключается в следующем:
- каждый тест компилируется дважды - с оптимизацией и без оптимизации;
- обе откомпилированные версии запускаются на исполнение;
- полученные трассы сравниваются;
- семантика признается сохранившейся в том и только том случае, если трассы эквивалентны.
Далее в статье мы подробно рассмотрим процессы генерации и запуска тестов.
Создание генератора тестов
Будем называть тестовым воздействием единичные входные данные для тестируемого оптимизатора, т.е. программу на целевом языке. Термин ко-тестовое воздействие обозначает единичные входные данные для результата компиляции тестового воздействия, т.е. значения параметров для запуска соответствующей откомпилированной программы. Итератор ко-тестовых воздействий - это компонент, обеспечивающий перебор необходимых ко-тестовых воздействий и запуск откомпилированного тестового воздействия. Таким образом, один тест включает в себя тестовое воздействие и итератор ко-тестовых воздействий.
Для получения множества тестов для целевого оптимизатора необходимо разработать соответствующий генератор. Этот генератор должен создавать представительное множество тестовых воздействий вместе с соответствующими итераторами ко-тестовых воздействий.
Создание генератора представительного множества тестовых воздействий начинается с анализа алгоритма тестируемого оптимизатора, построения абстрактной модели и формулировки критерия тестового покрытия, как это было описано выше. После этого происходит разработка собственно генератора.
Генератор тестов состоит из двух компонентов. Первый, называемый итератор, отвечает за последовательную генерацию модельных структур. Второй компонент, называемый меппер, отвечает за отображение каждой модельной структуры в целевой язык.
Итератор должен создавать множество модельных структур в соответствии с выбранным критерием тестового покрытия.
Для данной модельной структуры S меппер должен строить соответствующий тест со следующими свойствами:
- тестовое воздействие, построенное по модельной структуре S, имеет модельное представление, совпадающее с S;
- построенный тест (т.е. тестовое воздействие и итератор ко-тестовых воздействий) является синтаксически и семантически корректным с точки зрения целевого языка;
- тестовое воздействие содержит вычисления в тех местах, которые должны подвергаться оптимизации;
- тестовое воздействие содержит инструкции для трассирования окончательных результатов вычислений;
- итератор ко-тестовых воздействий содержит инструкции для формирования всех необходимых параметров, а также инструкции для активации откомпилированного тестового воздействия (т.е. вызов соответствующей процедуры или нескольких процедур).
Если модель предполагает начилие некоторых вычислений, то для формирования трассы меппер вставляет в текст тестового воздействия печать окончательных значений всех переменных, вовлеченных в вычисления. В противном случае меппер дополнительно вставляет в текст тестового воздействия некоторые вычисления, а для формирования трассы вставляет печать окончательных результатов этих вычислений.
По окончании разработки итератора и меппера они собираются в генератор. После этого происходит генерация искомого множества тестов.
Запуск тестов
Для проверки сохранения семантики программы оптимизатором каждый тест требуется откомпилировать с оптимизацией, выполнить результат компиляции и сравнить полученную трассу с эталоном. Напомним, что мы предлагаем в качестве эталона использовать трессу неоптимизированной версии соответствующего теста.
Итак, процесс запуска тестов и анализа результатов состоит из следующих шагов:
-
Тестирование оптимизатора:
- компиляция тестов с включенной целевой оптимизацией.
-
Ко-тестирование:
- запуск результатов компиляции на выполнение;
- сохранение получившейся трассы (тестовая трасса).
-
Получеие эталона:
- компиляция теста с отключенной целевой оптимизацией;
- запуск результатов компиляции;
- сохранение получившейся трассы (эталонная трасса).
-
Запуск оракула:
- cравнение тестовой трассы с эталоном;
- вынесение вердикта о сохранении семантики теста во время оптимизации.
Тестируемый оптимизатор признается сохраняющим семантику программ в соответствии с выбранным критерием тестового покрытия тогда и только тогда, когда оракул вынес положительные вердикты для всех тестов.
Практическое применение подхода
С помощью предложенного подхода были построены тесты и протестированы ряд оптимизаторов в нескольких компиляторах для современных архитектур: GCC, Open64, Intel C/Fortran compiler.
Были разработаны генераторы для следующих оптимизаторов:
- Control Flow Graph optimization;
- Common Subexpression Elimination;
- Induction Variable optimization;
- Loop Fusion optimization;
- Loop Data Dependence analysis.
Соответствующие множества тестов генерировались для языков программирования C и Fortran.
Области применимости подхода
Предложенный подход применялся для тестирования компиляторов императивных языков программирования. В составе таких компиляторов тестировались модули, касающиеся внутрипроцедурных оптимизаций и/или анализа.
Мы полагаем, что подход применим также и к межпроцедурным оптимизациям, а также к более широкому классу языков, например, к функциональным языкам. Адаптация подхода для применения в этих областях - это задача ближайшего будущего.
Близкие работы
Формальные методы применяются для построения компиляторов и теоретического доказательства корректности их поведения. Проект Verifix [9] содержит теоретические разработки схем построения надежных компиляторов, основанных на применении серии промежуточных языков. Кроме того, имеются различные попытки реализации надежных компиляторов с использованием логических исчислений [10,11,12]. Это также чисто теоретические работы. Обычно здесь предлагается простой модельный компилятор, для него строится логическое исчисление и демонстрируется метод доказательства корректности предложенного компилятора.
В работе [13], предложены идеи построения спецификации оптимизирующих трансформаций с помощью системы перерисовки графа (Graph Rewrite Systems). Автор утверждает, что данная технология спецификации применима ко многим алгоритмам оптимизации и анализа программ. Такой подход к специфицированию трансформаций, несомненно, является очень интересным и может быть использован для построения оракулов. Однако практическое использование систем перерисовки графов требует большой технической поддержки, создание которой является отдельной сложной задачей.
Существуют также подходы к тестированию компиляторов, не использующие формальные методы. В работах [14,15,16] содержатся идеи реализации оракула, проверяющего сохранение семантики программы во время трансформаций, при отсутствии каких-либо спецификаций выполняемых оптимизаций. Следует заметить, что общим изъяном этих подходов является отсутствие способа выбора входных тестовых данных. Кроме того, подход, изложенный в [14] требует вмешательства в работу компилятора, что является неприемлемым при тестировании промышленных коммерческих продуктов.
Работа [17] описывает основанную на идеях моделирования методологию автоматического построения тестов для парсеров формальных языков. В качестве описания модели в работе используется BNF-грамматика входного языка. В работе [18] содержится методика ручного создания тестов для семантического анализатора программ по описанию модели языка.
В работе [19] описан подход к автоматизации тестирования семантического анализа и кодогенерации. Спецификации для векторных и многопроцессорных выражений языка mpC были разработаны на языке XASM. Спецификации использовались для фильтрации программ, генерируемых относительно несложным итератором, и для получения эталонных результатов. Кроме того на их основе генерировались критерии тестового покрытия и инструменты его оценки.
Итак, тестирование компиляторов является очень перспективным направлением, в этой области имеется много интересных исследований. Однако, до сих пор не предложено никакого решения, подходящего для широкого использования в промышленных процессах тестирования оптимизирующих компиляторов.
Заключение
Для автоматического получения представительных множеств тестов строились генераторы на основе абстрактного описания алгоритма оптимизации. При построении генераторов использовались инструменты и библиотеки, которые существенно облегчали процесс разработки моделей и компонентов генератора. Некоторые этапы создания генератора при этом были полностью автоматизированы.
Преимущества использования модельного подхода состоят в следующем:
- гораздо меньшая трудоемкость по сравнению с написанием тестов вручную;
- систематичность тестирования;
- легкая сопровождаемость получаемых множеств тестов;
- возможность переиспользования отдельных компонентов генератора.
Перечисленные преимущества подтверждаются результатами ряда проектов по тестированию коммерческих компиляторов.
Литература
- А. Ахо, Р. Сети, Д. Ульман. Компиляторы: принципы, технологии, инструменты // Москва-Санкт-Петербург-Киев, 2001
- S. Muchnick. Advanced Compiler Design and Implementation. Morgan Kaufmann Publishers, 1997
- R. Allen, K. Kennedy. Optimizing Compilers for Modern Architectures. Morgan Kaufmann Publishers, 2002
- I.B. Bourdonov, A.S. Kossatchev, V.V. Kuliamin, A.K. Petrenko. UniTesK Test Suite Architecture. Proc. FME'2002 conference, LNCS, 2391. Copenhagen, Denmark (2002) 77-88
- A.K. Petrenko, A.I. Vorobiev. Industrial Experience in Using Formal Methods for Software Development in Nortel Networks. Proc. Testing Computer Software (2000) 103-112
- Г.В. Ключников, А.К. Косачев, Н.В. Пакулин, А.К. Петренко, В.З. Шнитман. Применение формальных методов для тестирования реализации IPv6 // Труды Института Системного Программирования РАН, 2003 (в печати)
- A.K. Petrenko. Specification Based Testing: Towards Practice. LNCS, 2244. (2001) 287-300
- С.В. Зеленов, С.А. Зеленова, А.С. Косачев, А.К. Петренко. Генерация тестов для компиляторов и других текстовых процессоров // Программирование, Москва, 2003, том. 29, #2, 59-69
- Verifix. http://i44www.info.uni-karlsruhe.de/verifix
- J. Hannan, F. Pfenning. Compiler Verification in LF. Proc. 7th Annual IEEE Symposium on Logic in Computer Science (1992) 407-418
- M. Wand, Zh. Wang. Conditional Lambda-Theories and the Verification of Static Properties of Programs. Proc. 5th IEEE Symposium on Logic in Computer Science (1990) 321-332
- M. Wand. Compiler Correctness for Parallel Languages. Conference on Functional Programming Languages and Computer Architecture (FPCA) (1995) 120-134
- U. Assmann. Graph Rewrite Systems For Program Optimization. ACM Trans. on Programming Languages and Systems (TOPLAS), 22, No. 4 (2000) 583-637
- C. Jaramillo, R. Gupta, M.L. Soffa. Comparison Checking: An Approach to Avoid Debugging of Optimized Code. ACM SIGSOFT 7th Symposium on Foundations of Software Engineering and European Software Engineering Conference, LNCS, 1687 (1999) 268-284
- G. Necula. Translation Validation for an Optimizing Compiler. Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (2000) 83-95
- T.S. McNerney. Verifying the Correctness of Compiler Transformations on Basic Blocks using Abstract Interpretation. In Symposium on Partial Evaluation and Semantics-Based Program Manipulation (1991) 106-115
- А.В. Демаков, С.А. Зеленова, С.В. Зеленов. Тестирование парсеров текстов на формальных языках // ``Программные системы и инструменты: Тематический сборник факультета ВМиК МГУ'', Москва, 2001, вып. 2, 150-156
- А.К. Петренко и др. Тестирование компиляторов на основе формальной модели языка // Препринт института прикладной математики им. М.В Келдыша, #45, 1992
- A. Kalinov, A. Kossatchev, M. Posypkin, V. Shishkov. Using ASM Specification for automatic test suite generation for mpC parallel programming language compiler. Proc. Fourth International Workshop on Action Semantic, AS'2002, BRICS note series NS-02-8 (2002) 99-109
-
A.S. Kossatchev, A.K. Petrenko, S.V. Zelenov, S.A. Zelenova.
Application of Model-Based Approach for Automated Testing of Optimizing Compilers.
In Proceedings of the International Workshop on Program Understanding
(Novosibirsk - Altai Mauntains, Russia), July 14-16, 2003, 81-88
http://www.iis.nsk.su/psi03/workshop/