Теория расширенных (постреляционных) баз данных
Модели данных
Существует целый класс бизнес задач (так называемые учетно-аналитические задачи) в которых обращение к данным удобно вести по так называемым "бизнес-объектам" - аналогам реальных документов. В Финансовой сфере примерами бизнес объектов могут служить счета-фактуры, мемориальные ордера, накладные. С информационной точки зрения бизнес объекты представляют собой наборы информации, зачастую довольно сложные, содержащие повторяющиеся элементы, но связанные в единое целое. Существует два подхода при проектировании информационной системы из таких бизнес объектов.
При первом подходе проектировщику необходимо осуществить нормализацию информации, то есть разложить данные содержащиеся в бизнес объектах на множество таблиц содержащих неделимые "атомарные" элементы информации. При этом проектировщику необходимо решить ряд проблем: установить связи между этими таблицами, при определении отношений "множество ко множеству" создать промежуточные таблицы перекрестных ссылок, установить ограничения целостности и так далее.
При проектировании системы содержащей несколько бизнес объектов проектировщик получает набор одноранговых таблиц со множеством связей которые можно легко представить в виде ER-диаграммы. Бизнес объекты как бы "размываются" на фоне таблиц поскольку таблицы не имеют иерархии. Ведь бизнес объекты иерархичны по своей сути. Например, строки товаров в счете-фактуре не могут существовать и не имеют смысла без самого счета. При обращении к бизнес объекту проектировщик определяет в операторах SQL операции "JOIN" для выборки информации из нескольких таблиц.

Рис. 1a
При втором подходе проектировщик осуществляет операции выборки/доступа к данным оперируя непосредственно над бизнес объектами. Нормализация данных производится динамически, в оперативной памяти, тогда, когда это действительно необходимо: например, когда производится группировка счетов-фактур по типу товара.
Этот подход обеспечивает максимальную эффективность при работе с бизнес объектами, но требует от СУБД поддержки сложных структур - таких как вложенные таблицы или массивы, а также возможности динамической нормализации этих структур. Таблицы в такой системе приобретают некоторую иерархию: выделяются "главные" и "вспомогательные" таблицы.

Рис. 1б
Реляционные базы данных и отношения
Большинство пользователей убеждены в том, что слово реляционный в названии реляционные базы данных относится к способности быстро строить отношения между таблицами. Действительно, наиболее сильная сторона реляционных баз данных заключается в управлении межтабличными отношениями.
В основе реляционные баз данных лежит теория отношений - математическая теория, оперирующая наборами кортежей. Можно представить кортеж как строку в таблице. В реляционной теории, набор строк в таблице выражает отношение.
Ну а как насчет управления отношениями в реляционных базах данных? Основной механизм создания отношений - объединение. Здесь возникают три главные проблемы. Во-первых, большинство людей не понимает, что из себя представляет объединение. Более того, поскольку базы данных должны быть нормализованы, то работа с реальными представлениями часто требует многочисленных объединений. Очень сложно, объяснить людям, которые далеки от технических наук, как соединить 15 или 20 таблиц для представления данных. И часто, в процессе создания объединения, результирующее представление работает неэффективно, иными словами, медленно.
Во-вторых, по определению, объединения носят временный характер. Самая сильная сторона реляционного подхода, где сложные записи разбиваются на простые таблицы, является одновременно и самой большой его слабостью. Пользователю не нужно разбираться в отношениях между различными частями БД, разработчик базы данных должен встроить их в ее структуру. Но это означало бы преобразование реляционной БД обратно в сетевую.
И, наконец, отношения всегда связаны с ограничениями целостности и другими бизнес-правилами, как то: не стирать записи пользователя, содержащие неоплаченные заказы, не оплачивать стоимость товара по несуществующим кредитным картам и т.п. Однако, не владея методом выражения межтабличных отношений, подобные правила не могут стать встроенной частью БД.
Так сложилось, что вышеупомянутая проблема означала введение всех бизнес-правил в код приложений. В некоторых реляционных БД правила бизнеса хранятся в словарях данных как "хранимые процедуры", написанные в SQL и выполняемые при внесении изменений в БД. Но наиболее простой выход из положения - связать ограничения целостности напрямую с отношениями БД.
Не первая нормальная форма NF2
Важным аспектом традиционной реляционной модели данных является тот факт, что элементы данных, которые хранятся на пересечении строк и столбцов таблицы, должны быть неделимы и единственны. Это значит, что данные не могут быть развернуты в процессе дальнейшей обработки. Такое правило было заложено в основу реляционной алгебры при ее разработке как математической модели данных. Дальнейшие исследования показали, что существует ряд случаев, когда ограничения классической реляционной модели существенно мешают эффективной реализации приложений
При том, что таблицы, строки и колонки так удобно отражают наше мышление, почему же они стали самоограничивающими для более крупных приложений? В основе проблемы лежат три вопроса:
- работа с полями переменной длины и группами записей;
- управление отношениями между таблицами и полями;
- и отражение подлинно семантического содержания реальных структур, которые будут моделированы базой данных.
Основной принцип реляционной модели - устранять повторяющиеся поля и группы с помощью процесса, который называется нормализацией. Так как нормализация - это простой процесс, результат часто заключается в отображении единичных файлов в реляционных таблицах. Результат как непрост в понимании, так и неэффективен в обработке.
Опыт разработки прикладных информационных систем показал, что отказ от этой установки ведет к качественно полезному расширению модели данных. Если допустить, что значение данных может само состоять из подзначений, то в результате возникает понятие многозначного поля. Проще всего рассматривать набор многозначных полей в таблице как самостоятельную вложенную (nested) таблицу.
При условии, что вложенная таблица удовлетворяет общим критериям (например имеет уникальный ключ), естественным образом происходит расширение операторов реляционной алгебры. Такая модель данных была названа постреляционной.
Многие методологии проектирования данных позволяют определять многозначные поля и затем удалять в процессе нормализации. При этом таблицы преобразуются в первую нормальную форму или 1NF. Однако удаление многозначных полей не всегда способствует улучшению прикладных программ. В случаях, когда обычная форма доступа к полю подразумевает обращение ко всем его значениям, базе данных 1NF придется проделать операцию соединения (Join) каждый раз, когда нужно получить соответствующие значения, хранящиеся в другой таблице. Совершенно очевидно, что в подобной ситуации хранение значений физически в многозначных полях может обеспечить более эффективный доступ к информации.
На рис. 2 наглядно продемонстрированы преимущества хранения данных в базах uniVerse, относящихся к непервой нормальной форме, перед более громоздким хранением в базах данных первой нормальной формы. Пример представляет хранение части данных такого типичного документа, как накладная.

Рис. 2a. Представление данных в 1-й нормальной форме (1NF)
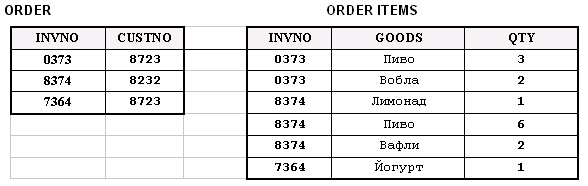
Рис. 2б. Дальнейшая нормализация (2NF)
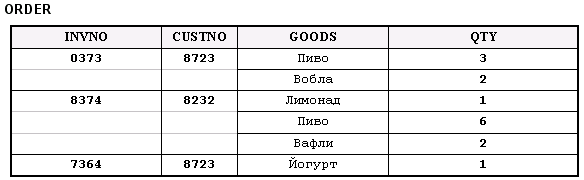
Рис. 2в. Структура хранения данных в uniVerse NFNF (NF2)
Рисунок 2. Структуры хранения данных с многозначными полями в uniVerse и в традиционных системах. Так как в uniVerse можно создавать многозначные поля переменной длины, все заказы могут храниться в одной таблице. При этом для хранения нужно меньше места и при обработке не требуется объединять данные, что повышает эффективность хранения данных
О таблицах, содержащих многозначные поля, говорят, что они находятся в непервой нормальной форме, или NF2 (Non First Normal Form). Как было замечено ранее, при условии, что используемые поля подчиняются определенным правилам, позволяющим обращаться с ними, как с таблицами, встроенными в другие таблицы, форма NF2 не нарушает принципы реляционной алгебры. Более того, такая информация полностью доступна, так как расширенные операторы, которые работают с таблицами NF2, позволяют извлекать встроенные таблицы и рассматривать данные как информацию, поступившую из таблиц 1NF. И все же во многих случаях форма 1NF будет скорее исключением, а не правилом. В большинстве случаев гораздо более эффективно осуществлять доступ к многозначным полям одновременно с остальными данными, зная, что их всегда можно извлечь и рассматривать как отдельную таблицу в тех случаях, когда это может понадобиться.
Модель данных СУБД uniVerse фирмы Ardent поддерживает ассоциированные многозначные поля, которые часто называют множественными группами. То есть вы можете связать несколько столбцов с множественными значениями в единое целое, называемое ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации, в такой же связи находятся все вторые значения столбцов и т.д.
Многозначные поля и ассоциации не могут вкладываться друг в друга. Расширение синтаксиса SQL позволяет осуществлять доступ к множественным полям как расширение реляционной модели, но, конечно, можно применять также стандартные и другой язык запросов uniVerse - RetrieVe. В целом многозначность полей является очень полезным свойством при создании коммерческих приложений, где информация нередко представлена в виде списков предметов.
Модель данных uniVerse представляет собой расширенную форму реляционной модели данных, которая допускает использование данных в форме NF2. В этой модели все данные хранятся в форме таблиц, как и в обычной реляционной базе данных. Единственное отличие заключается в том, что таблицы NF2 могут содержать вложенные таблицы.
Как и в большинстве реляционных баз данных, таблицы описаны в словарях, содержащих логические описания, которые представляют столбцы таблиц. Можно сказать, что реляционные и постреляционные СУБД различаются только способами хранения и индексирования данных, во всем остальном - это одно и то же.
Обычно компании автоматически выбирают реляционную модель, не давая себе труда поискать более производительный способ обработки данных. Как только они начинают анализировать свои проблемы, выясняется, что эффективность постреляционной технологии в управлении большими массивами быстро изменяющейся информации, например в бизнес-приложениях, гораздо выше.
Кроме того, uniVerse не требует, чтобы данные в поле были определенной длины или чтобы количество полей в записи было фиксировано. Это означает, что все данные и таблицы отличает большая гибкость относительно размера и их можно легко видоизменять.
Вложенные таблицы
Использование вложенных таблиц полностью отражает основную задачу реляционной модели - обеспечение пользователя простой логической структурой данных. Фактически, вложенные таблицы еще более упрощают логическое предcтавление данных и являются естественным расширением реляционной модели. Расширение реляционной базы данных предлагаемое фирмой Ardent позволяет использовать вложенные таблицы как атрибуты со множественными значениями и связанные группы таких атрибутов. Для создания таблицы показанной на рис 2в в может быть использовано следующее SQL предложение:
CREATE TABLE ORDER
(INVNO INT NOT NULL PRIMARY KEY,
CUSTNO INT,
GOODS CHAR(25) MULTIVALUED NOT NULL,
QTY INT MULTIVALUED,
ASSOC PHONES (GOODS, QTY));
В данном случае атрибуты со множественными значениями определяются словом MULTIVALUED, а связанные группы - словом ASSOC. Конечно, если необходимо представление данных в первой нормальной форме, Ardent предоставляет механизм для динамической нормализации данных (в процессе запросов). Для данной цели в SQL синтаксис расширен ключевым словом UNNEST.
Вложенные реляционные отношения
Как описано выше, определение отношений связано с необходимостью поддержки целостности данных. В случае использования вложенных таблиц, определение отношений становятся более неявным чем явным и ограничения целостности в них осуществляются автоматически, без дополнительных определений. Действительно, в данной модели нет необходимости хранить внешние ключи во вложенной и в основной таблице поскольку фактически одна таблица является частью другой и при выборке записей из основной таблицы, автоматически выбираются данные из вложенной.
Так же обстоят дела и с ссылочными ограничениями целостности - при удалении записи основной таблицы, естественно, удаляются все вложенные в эту запись таблицы. Кроме того появляется целый ряд дополнительных преимуществ. Так возможность хранить во вложенной таблице множество внешних ключей избавляет от необходимости использовать и поддерживать таблицы перекрестных ссылок в отношениях множество ко множеству, что дает неоспоримые преимущества на выборках из больших массивов данных.
Содержание |
Вперед



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС