Безопасность программного обеспечения компьютерных систем.
Казарин О.В.
www.cryptography.ru
ГЛАВА 2. ОБЕСПЕЧЕНИЕ ТЕХНОЛОГИЧЕСКОЙ БЕЗОПАСНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
2.1. ФОРМАЛЬНЫЕ МЕТОДЫ ДОКАЗАТЕЛЬСТВА ПРАВИЛЬНОСТИ
ПРОГРАММ И ИХ СПЕЦИФИКАЦИЙ
Традиционные методы анализа ПО связаны с доказательством правильности программ (верификация программ). Начало этому направлению было положено работами П. Наура и Р. Флойда, в которых сформулирована идея приписывания точке программы так называемого индуктивного, или промежуточного утверждения и указана возможность доказательства частичной правильности программы (то есть соответствия друг другу ее предусловия и постусловия), построенного на установлении согласованности индуктивных утверждений.
Фундаментальный вклад в теорию верификации внес Ч. Хоор, высказавший идеи проведения доказательства частичной правильности программы в виде вывода в некоторой логической системе, а Э. Дейкстра ввел понятие слабейшего предусловия, позволяющее одновременно как соответствие друг другу предусловия и постусловия, так и завершимость. Методы доказательства правильности программ принесли определенную пользу программированию. Было отмечено, что эти методы указывают способ рассуждения о ходе выполнения программ, дают удобную систему комментирования программ и устанавливают взаимосвязи между конструкциями языков программирования и их семантикой. Если принять более широкое толкование термина "анализ программ", подразумевая доказательство разнообразных свойств программ или доказательство теорем о программах, то ценность методов анализа станет более ясной. В частности можно исследовать характер изменения выходных значений программы, количество операций при выполнении программы, наличие зацикливаний, незадействованных участков программы. Таким образом, в некоторых частных случаях методы верификации могут применяться и для доказуемого обнаружения программных дефектов.
Формальное доказательство в виде вывода в некоторой логической системе вполне надежно, но сами доказательства оказываются очень длинными и часто необозримыми. Рассмотрим следующий фрагмент программы.
integer r, dd;
r:=a; dd:=d;
while dd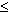 r do dd:=2*dd;
while dd
r do dd:=2*dd;
while dd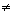 d do dd:=2*dd;
begin dd:=dd/2;
if ddr do r:=r-dd;
end.
d do dd:=2*dd;
begin dd:=dd/2;
if ddr do r:=r-dd;
end.
Должно соблюдаться условие, что целые константы a и d удовлетворяют отношениям a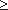 d и d>0.
d и d>0.
Рассмотрим последовательность значений, заданную выражениями для:
i=0 ddi=d
i>0 ddi=2*ddi-1.
Далее с помощью обычных математических приемов можно вывести, что:
ddn=d*2n (2.1.1)
Кроме того, поскольку d>0, можно сделать вывод, что для любого конечного значения r отношение ddr>r будет выполняться при некотором конечном значении k; первый цикл завершается при dd=d*2k. Решая уравнение di=2*di-1 относительно di-1, получаем di-1=di/2, что позволяет утверждать, что второй цикл тоже завершится. По окончании первого цикла dd=ddk и поэтому выполняется соотношение
0 r < dd (2.1.2)
Это соотношение сохраняется при выполнении повторяемого оператора второго заголовка. После завершения повторений (в соответствии с заголовком while ddd do) мы получаем dd=d. Отсюда и из соотношения (2) следует, что
0 r < d (2.1.3)
Далее мы доказываем, что после начала работы программы всегда выполняется отношение:
dd 0(mod d) (2.1.4)
0(mod d) (2.1.4)
Это следует, например, из того, что возможные значения dd имеют вид (см. (1)) d*2i при 0 i k.
Следующая задача состоит в том, чтобы показать, что после присваивания r начального значения всегда выполняется отношение
ar(mod d) (2.1.5)
Оно выполняется после начальных присваиваний.
Повторяемый оператор первого заголовка (dd:=2*dd) сохраняет отношение (2.1.5), и поэтому весь первый цикл сохраняет отношение (2.1.5).
Повторяемый оператор из второго цикла состоит из двух операторов. Первый (dd:=2*dd) сохраняет инвариантность (2.1.5); второй тоже сохраняет отношение (2.1.5), так как он либо не изменяет значение r, либо уменьшает r на текущее dd, а эта операция в силу (2.1.4) также сохраняет справедливость отношения (2.1.5). Таким образом, весь повторяемый оператор второго цикла сохраняет отношение (2.1.5).
Объединяя отношения (2.1.3) и (2.1.5), получаем, что окончательное значение r удовлетворяет условиям 0 r < d и ar(mod d), то есть r - наименьший неотрицательный остаток от деления a на d.
И хотя методы доказательства правильности программ существенно ограничены для практического использования, тем не менее есть области, где данные методы могут найти прикладное значение. Следующий пример характеризует это.
Большинство известных алгоритмов электронной цифровой подписи в качестве основной алгоритмической операции используют дискретное возведение в степень. Стойкость соответствующих криптографических схем основывается (как правило, гипотетически) или на сложности извлечения корней в поле GF(n), n - произведение двух больших простых чисел, или на трудности вычисления дискретных логарифмов в поле GF(p), p - большое простое число. Чтобы противостоять известным на данный момент методам решения этих задач операнды должны иметь длину порядка 512 или 1024 битов. Понятно, что выполнение вычислений над операндами повышенной разрядности (еще будет употребляться термин "операнды многократной точности" по аналогии с операндами однократной и двукратной точности) требует высокого быстродействия рабочих алгоритмов криптографических схем.
Представление чисел
Пусть
A, N, e - три целых положительных числа многократной точности, причем
A < N. Тогда для любого
e при вычислении
Ae(mod
N)
C, результат редукции C
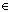
{1,N-1}. Если
e представить
n-разрядным двоичным вектором, то всю операцию возведения в степень можно свести к чередованию операций вида
A*B modulo
N и
B*B modulo
N, где 0 < B < N-1. Таким образом, во всех дальнейших рассуждениях
e будет представляться только как двоичная строка. Кроме того, числа
A, B, N, а также
P - частичное произведение и
S - текущий результат будут представляться n-битовыми двоичными векторами, например,
N[1,n], где
N[1] и
N[n] - младший и старший биты N соответственно.
Алгоритм использует вычислительную систему с фиксированной длиной слова, то есть A, B, N, P и S будут также рассматриваться как векторы A[1,m], B[1,m], N[1,m], P[1,m'] и S[1,m'], где каждый элемент вектора (элемент одномерного массива) есть цифра r-ичной системы счисления, m'=m+h, величина h будет изменяться в зависимости от вида алгоритма. Основание r такой системы будет ограничено длиной машинного слова λ и цифры такой системы имеют вид 0,1,...,r-1 (r выбирается как целое положительное основание с неотрицательной базой). При этом n и m связаны соотношением n=s*m, где s=log2r (в дальнейших рассуждениях log - логарифм по основанию 2). Наиболее целесообразно выбрать основание r=2λ как наиболее экономное представление чисел в машине, ибо при r < 2λ на представление чисел уходит больше памяти. Например, широко принятое на практике представление десятичных чисел в двоично-десятичном коде требует на 20 % большего объема памяти, чем двоичное представление тех же чисел.
Тем не менее, иногда полезно представлять ситуацию, когда r=10 или r=10k, например, при отладке программ.
Следует также обратить внимание на тот факт, что при выполнении арифметических операций над числами многократной точности, например, по классическим алгоритмам Кнута, основание r следует уменьшать, чтобы не возникло переполнение разрядной сетки. Так, для операции сложения уменьшение выполняется до r=2λ-1, для умножения - до r=2λ/2. Однако если архитектурой вычислительной системы предусмотрен флаг переноса или хранение промежуточного результата с двойной точностью, то можно возвращаться к основанию r=2λ.
Алгоритм A*B modulo N - алгоритм выполнения
операции модулярного умножения
Операнды многократной точности для данного алгоритма представляются в виде одномерного массива целых чисел. Для знака можно зарезервировать элемент с нулевым индексом. Особенности представления чисел при организации взаимодействия алгоритма с другими рабочими программами, при организации ввода-вывода и т.д. рассматриваются, например, в работе. В алгоритме использован известный вычислительный метод "разделяй и властвуй" и реализован способ вычисления "цифра-за-цифрой". Прямое умножение не следует делать по нескольким причинам: во-первых, произведение A*B требует в два раза больше памяти, чем при методе "цифра-за-цифрой"; во-вторых, умножение двух многоразрядных чисел труднее организовать, чем умножение числа многократной точности на число однократной точности. Так, в работе приводятся расчеты на супер-ЭВМ "CRAY-2" для 100-разрядных десятичных чисел: модулярное умножение методом "цифра-за-цифрой" выполняется примерно на 10% быстрее, чем прямое умножение и следующая за ним модульная редукция. Алгоритм модулярного умножения (алгоритм P) приведен на рис.2.1, а на рис.2.2 представлен псевдокод процедуры ADDK.
Так как B[i] [0,...,2 λ/2-1], то проверку "if B[i]<>0" в алгоритме P можно не вводить потому, что вероятность того, что B[i] будет равняться 0 пренебрежимо мала, если значение λ не достаточно малым. Ошибка затем все равно будет алгоритмом обнаружена. Проверка
"if p_short-k*n_short>n_short DIV 2"
позволяет представлять k числом однократной точности и работать с наи-меньшими абсолютными остатками в каждой итерации. Значение операнда Pi на каждом шаге итерации должно быть ограничено величиной N.
Теорема 2.1. Пусть Pi - частичное произведение P в конце i-той итерации (т.е. в конце i-того цикла FOR алгоритма P). Тогда для любого i (i=[1,...,n]) abs(Pi)<N, rm-1 N rm.
Доказательство теоремы 2.1. Доказательство теоремы проведем методом индукции.
Если k=abs(p_short) DIV n_short, где DIV - целочисленное деление, то
p_short=(k+δ)*n_short, (2.1.6)
где k - целое, 0 k < r-1 и 0 δ < 1.
Проверка "if p_short-k*n_short>n_short DIV 2" есть ни что иное, как проверка
δ > 0.5 (2.1.7)
На i-том шаге алгоритм вычисляет:
P'=Pi-1*r+A*B[i] (2.1.8)
Возможны два варианта:
Вариант 1. Если k=0, т.е. n_short>abs(p_short) (см. алгоритм), то суммирование при помощи процедуры ADDK не производится и утверждение теоремы выполняется, т.е. abs(Pi) < N .
Вариант 2. Если k > 0, т.е.
n_short < abs(p_short) (2.1.9)
Здесь также возможны два варианта:
Вариант A:
p_short < 0 (2.1.10)
Из (2.1.9) и (2.1.10) следует P'<-N и так как Pi=-P'+k*N (см. алгоритм), то согласно (2.1.7)
Pi= δ*N, если δ 0.5 (2.1.11)
и так как Pi=-P'+(k+1)*N, то
Pi=-(1-δ)*N, если δ > 0.5 (2.1.12)
Алгоритм P
m_shifts:=0;
while n[m_shifts]=0 do
begin
shift_left(N and A);
m_shifts:=m_shifts+1;
end;
m:=m_shifts;
reset(P);
n_short:=N[m];
for i:=n downto 1 do
begin
shift_left(P);
{сдвиг на 1 элемент влево или
умножение P*r}
if b<>0 then
addk(A*B[i],{to}P);
let p_short represent the 2 high
assimilated digits of P;
k:=abs(p_short) div n_short;
if p_short-k*n_short > n_short div 2 then
k:=k+1;
if k>0 then
begin
if p_short < 0 then
addk(k*N,{to} P)
else
addk(-k*N,{to} P);
end;
end;{for}
right shift P, N by m_shifts;
if P < 0 then
P:=P+N;
write(P); {P - результат}
Рис. 2.1. Псевдокод алгоритма модулярного умножения A*B modulo N
Алгоритм ADDK
carry:=0;
for i:=1 to m do
begin
t:=P[i]+k*N[i]+carry;
P[i]:=t mod r;
carry:=t div r;
end;
P[m+1]:=carry;
write(P); {P - результат}
Рис.2.2. Псевдокод алгоритма вычисления P+k*N
(процедура ADDK)
Вариант B:
p_short>0 (2.1.13)
Из (2.1.9) и (2.1.13) следует P'>N и так как Pi=P'-k*N, то согласно (2.1.7)
Pi=-δ *N, если δ 0.5 (2.1.14)
и так как Pi=P'-(k+1)*N, то
Pi=(1-δ)*N, если δ > 0.5 (2.1.15)
Во всех случаях (2.1.11), (2.1.12), (2.1.14) и (2.1.15), так как 0 δ < 1, то abs(Pi) < N.
Теорема доказана
.
Примечание. Для чего нужна проверка (2.1.7)
"if p_short-k*n_short>n_short DIV 2" ?
Пусть в конце каждой итерации P принимает максимально возможное значение Pi-1=N-1, а N, A и B[i] заведомо тоже велики: N=rn+1-1, A=rn+1-2, B[i]=r-1. Тогда на i-том шаге согласно (2.1.8):
Pi'=(rn+1-2)*r+(rn+1-2)*(r-1)=2*rn+2-rn+1-4*r+2(2.1.16)
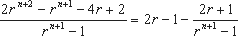 (2.1.17)
(2.1.17)
При достаточно большом m, если не введена проверка (2.1.6), то k < 2*r-1, по условию же 0< k < r -1. И из (2.1.16) и (2.1.17) видно, что P придется представлять m+2 разрядами (что определяется слагаемым 2*rn+2), по условию же m+1. Если же ввести проверку (2.1.7), то даже при δ=0,5 т.е.
Pi-1=(N-1)/2 и с учетом того, что если неравенство (2.1.7) выполняется, то Pi меняет знак на противоположный (сравн. (2.1.11), (2.1.12), (2.1.14) и (2.1.15)), из (2.1.6) и (2.1.7) получим, что 0 k < (1/2)*r-1, что удовлетворяет наложенному на k условию, и для представление P достаточно m+1 разряда.
В алгоритме P используется также известный метод, когда для получения частного от деления двух многоразрядных чисел, используются только старшие цифры этих чисел (см., например, алгоритм D в работе [36, стр.291-295]). Чем больше основание системы счисления r, тем ниже вероятность того, что пробное частное k от деления первых цифр больших чисел не будет соответствовать действительному частному.
Методы доказательства правильности программ могут быть применены для анализа безопасности ПО при существенных ограничениях на размеры и сложность создаваемых программ. Поэтому в частных случаях они могут оказаться более эффективными, чем другие известные методы анализа программ, которые исследуются в следующих разделах данной работы.
2.2. МЕТОДЫ И СРЕДСТВА АНАЛИЗА БЕЗОПАСНОСТИ
ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Широко известны различные средства программного обеспечения обнаружения элементов РПС - от простейших антивирусных программ-сканеров до сложных отладчиков и дизассемблеров - анализаторов и именно на базе этих средств и выработался набор методов, которыми осуществляется анализ безопасности ПО.
Авторы работ [17,45] предлагают разделить методы, используемые для анализа и оценки безопасности ПО, на две категории: контрольно-испытательные и логико-аналитические (см. рис.2.3). В основу данного разделения положены принципиальные различия в точке зрения на исследуемый объект (программу). Контрольно-испытательные методы анализа рассматривают РПС через призму фиксации факта нарушения безопасного состояния системы, а логико-аналитические - через призму доказательства наличия отношения эквивалентности между моделью исследуемой программы и моделью РПС.
В такой классификации тип используемых для анализа средств не принимается во внимание - в этом ее преимущество по сравнению, например, с разделением на статический и динамический анализ.
Комплексная система исследования безопасности ПО должна вклю-чать как контрольно-испытательные, так и логико-аналитические методы анализа, используя преимущества каждого их них. С методической точки зрения логико-аналитические методы выглядят более предпочтительными, т.к. позволяют оценить надежность полученных результатов и проследить последовательность (путем обратных рассуждений) их получения. Однако эти методы пока еще мало развиты и, несомненно, более трудоемки, чем контрольно-испытательные.
2.2.1. Контрольно-испытательные методы анализа
безопасности программного обеспечения
Контрольно-испытательные методы - это методы, в которых критерием безопасности программы служит факт регистрации в ходе тестирования программы нарушения требований по безопасности, предъявляемых в системе предполагаемого применения исследуемой программы [17]. Тестирование может проводиться с помощью тестовых запусков, исполнения в виртуальной программной среде, с помощью символического выполнения программы, ее интерпретации и другими методами.
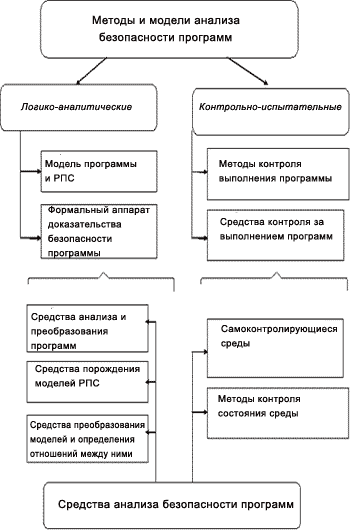
Рис. 2.3. Методы и средства анализа безопасности ПО
Контрольно-испытательные методы делятся на те, в которых контролируется процесс выполнения программы и те, в которых отслеживаются изменения в операционной среде, к которым приводит запуск программы. Эти методы наиболее распространены, так как они не требуют формального анализа, позволяют использовать имеющиеся технические и программные средства и быстро ведут к созданию готовых методик. В качестве примера - можно привести методику пробного запуска в специальной среде с фиксацией попыток нарушения систем защиты и разграничения доступа. Рассмотрим формальную постановку задачи анализа безопасности ПО для решения ее с помощью контрольно-испытательных методов.
Пусть задано множество ограничений на функционирование программы, определяющих ее соответствие требованиям по безопасности в системе предполагаемой эксплуатации. Эти ограничения задаются в виде множества предикатов С={ci(a1,a2,...am)|i=1,...,N} зависящих от множества аргументов A={ai|i=1,...,M}.
Это множество состоит из двух подмножеств:
-
подмножества ограничений на использование ресурсов аппаратуры и операционной системы, например оперативной памяти, процессорного времени, ресурсов ОС, возможностей интерфейса и других ресурсов;
-
подмножества ограничений, регламентирующих доступ к объектам, содержащим данные (информацию), то есть областям памяти, файлам и т.д.
Для доказательства того, что исследуемая программа удовлетворяет требованиям по безопасности, предъявляемым на предполагаемом объекте эксплуатации, необходимо доказать, что программа не нарушает ни одного из условий, входящих в С. Для этого необходимо определить множество параметров P={pi|i=1,...,K}, контролируемых при тестовых запусках программы. Параметры, входящие в это множество определяются используемыми системами тестирования. Множество контролируемых параметров должно быть выбрано таким образом, что по множеству измеренных значений параметров Р можно было получить множество значений аргументов А.
После проведения Т испытаний по вектору полученных значений параметров Pi,i=1,...,T можно построить вектор значений аргументов Ai, i=1,...,T.
Тогда задача анализа безопасности формализуется следующим образом.
Программа не содержит РПС, если для любого ее испытания i=1,...,T множество предикатов C={cj(a1i,a2i...aMi)|j=1,...,N} истинно.
Очевидно, что результат выполнения программы зависит от входных данных, окружения и т.д., поэтому при ограничении ресурсов, необходимых для проведения испытаний, контрольно-испытательные методы не ограничиваются тестовыми запусками и применяют механизмы экстраполяции результатов испытаний, включают в себя методы символического тестирования и другие методы, заимствованные из достаточно проработанной теории верификации (тестирования правильности) программы.
Рассмотрим схему анализа безопасности программы контрольно-испытательным методом (рис.2.4).
Контрольно-испытательные методы анализа безопасности начинаются с определения набора контролируемых параметров среды или программы. Необходимо отметить, что этот набор параметров будет зависеть от используемого аппаратного и программного обеспечения (от операционной системы) и исследуемой программы. Затем необходимо составить программу испытаний, осуществить их и проверить требования к безопасности, предъявляемые к данной программе в предполагаемой среде эксплуатации, на запротоколированных действиях программы и изменениях в операционной среде, а также используя методы экстраполяции результатов и стохастические методы.
Очевидно, что наибольшую трудность здесь представляет определение набора критичных с точки зрения безопасности параметров программы и операционной среды. Они очень сильно зависят от специфики операционной системы и определяются путем экспертных оценок. Кроме того в условиях ограниченных объемов испытаний, заключение о выполнении или невыполнении требований безопасности как правило будет носить вероятностный характер.
2.2.2. Логико-аналитические методы
контроля безопасности программ
При проведении анализа безопасности с помощью логико-аналитических методов (см. рис.2.5) строится модель программы и формально доказывается эквивалентность модели исследуемой программы и модели РПС. В простейшем случае в качестве модели программы может выступать ее битовый образ, в качестве моделей вирусов множество их сигнатур, а доказательство эквивалентности состоит в поиске сигнатур вирусов в программе. Более сложные методы используют формальные модели, основанные на совокупности признаков, свойственных той или иной группе РПС.
Формальная постановка задачи анализа безопасности логико-аналитическими методами может быть сформулирована следующим образом.
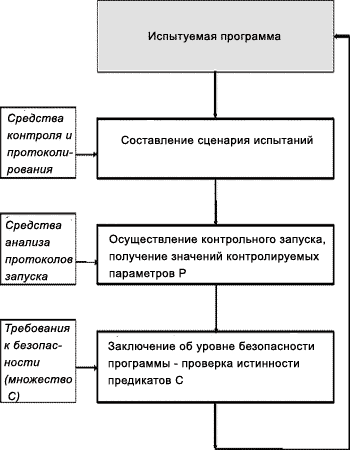
Рис.2.4. Схема анализа безопасности ПО с помощью контрольно-испытательных методов
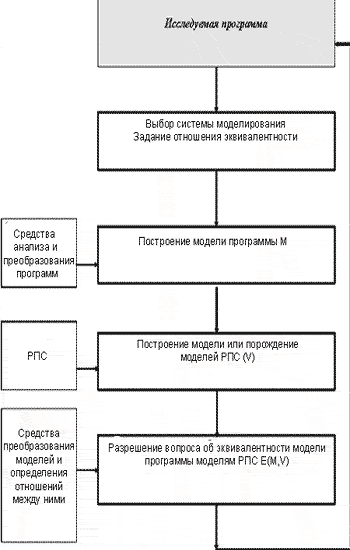
Рис. 2.5. Схема анализа безопасности ПО с помощью
логико-аналитических методов
Выбирается некоторая система моделирования программ, представленная множеством моделей всех программ - Z. В выбранной системе исследуемая программа представляется своей моделью М, принадлежащей множеству Z. Должно быть задано множество моделей РПС V={vi|i=1,...,N}, полученное либо путем построения моделей всех известных РПС, либо путем порождения множества моделей всех возможных (в рамках данной модели) РПС. Множество V является подмножеством множества Z. Кроме того, должно быть задано отношение эквивалентности определяющее наличие РПС в модели программы, обозначим его Е(x,y). Это отношение выражает тождественность программы x и РПС y, где x - модель программы, y - модель РПС, и y принадлежит множеству V.
Тогда задача анализа безопасности сводится к доказательству того, что модель исследуемой программы М принадлежит отношению E(M,v), где v принадлежит множеству V.
Для проведения логико-аналитического анализа безопасности про-граммы необходимо, во-первых, выбрать способ представления и получения моделей программы и РПС. После этого необходимо построить модель исследуемой программы и попытаться доказать ее принадлежность к отношению эквивалентности, задающему множество РПС.
На основании полученных результатов можно сделать заключение о степени безопасности программы. Ключевыми понятиями здесь являются "способ представления" и "модель программы". Дело в том, что на ком-пьютерную программу можно смотреть с очень многих точек зрения - это и алгоритм, который она реализует, и последовательность команд процессора, и файл, содержащий последовательность байтов и т.д. Все эти понятия образуют иерархию моделей компьютерных программ. Можно вы-брать модель любого уровня модели и способ ее представления, необхо-димо только чтобы модель РПС и программы были заданы одним и тем же способом, с использованием понятий одного уровня. Другой серьезной проблемой является создание формальных моделей программ, или хотя бы определенных классов РПС. Механизм задания отношения между программой и РПС определяется способом представления модели. Наиболее перспективным здесь представляется использование семантических графов и объектно-ориентированных моделей.
В целом полный процесс анализа ПО включает в себя три вида анали-за:
-
лексический верификационный анализ;
-
синтаксический верификационный анализ;
-
семантический анализ программ.
Каждый из видов анализа представляет собой законченное исследование программ согласно своей специализации.
Результаты исследования могут иметь как самостоятельное значение, так и коррелироваться с результатами полного процесса анализа.
Лексический верификационный анализ предполагает поиск распознавания и классификацию различных лексем объекта исследования (программа), представленного в исполняемых кодах. При этом лексемами являются сигнатуры. В данном случае осуществляется поиск сигнатур следующих классов:
-
сигнатуры вирусов;
-
сигнатуры элементов РПС;
-
сигнатуры (лексемы) "подозрительных функций";
-
сигнатуры штатных процедур использования системных ресурсов и внешних устройств.
Поиск лексем (сигнатур) реализуется с помощью специальных про-грамм-сканеров.
Синтаксический верификационный анализ предполагает поиск, распознавание и классификацию синтаксических структур РПС, а также по-строение структурно-алгоритмической модели самой программы.
Решение задач поиска и распознавания синтаксических структур РПС имеет самостоятельное значение для верификационного анализа программ, поскольку позволяет осуществлять поиск элементов РПС, не имеющих сигнатуры. Структурно-алгоритмическая модель программы необходима для реализации следующего вида анализа - семантического.
Семантический анализ предполагает исследование программы изучения смысла составляющих ее функций (процедур) в аспекте операционной среды компьютерной системы. В отличие от предыдущих видов анализа, основанных на статическом исследовании, семантический анализ нацелен на изучение динамики программы - ее взаимодействия с окружающей средой. Процесс исследования осуществляется в виртуальной операционной среде с полным контролем действий программы и отслеживанием алгоритма ее работы по структурно-алгоритмической модели.
Семантический анализ является наиболее эффективным видом анализа, но и самым трудоемким. По этой причине методика сочетает в себе три перечисленных выше анализа. Выработанные критерии позволяют разумно сочетать различные виды анализа, существенно сокращая время исследования, не снижая его качества.
2.3. МЕТОДЫ ОБЕСПЕЧЕНИЯ НАДЕЖНОСТИ ПРОГРАММ ДЛЯ КОНТРОЛЯ ИХ ТЕХНОЛОГИЧЕСКОЙ БЕЗОПАСНОСТИ
При исследовании методов и средств оценки уровня технологической безопасности программных комплексов учитываются факторы, имеющие, как правило, чисто случайный характер. Следовательно, показатели, связанные с оцениванием безопасности ПО лучше всего выражать вероятностной мерой, а для их вычисления можно использовать вероятностные модели надежности ПО [56], которые при осуществлении замены условия правильности функционирования программ на условие их безопасности можно использовать для этих целей.
Исходные данные, определения и условия
В данном разделе будем считать, что безопасность программного обеспечения - это вероятность того, что преднамеренные программные дефекты, вызывающие критическое поведение управляемой КС, будут обнаружены при определенных условиями внешней среды и в течение заданного периода наблюдения при испытаниях.
Под определенными условиями внешней среды следует понимать описание входных данных и состояние вычислительного процесса в момент выполнения программы при испытаниях. Под заданным периодом функционирования понимается время, необходимое для выполнения поставленной задачи. Выделение определенного интервала времени целесообразно в случае систем реального времени, в которых неопределенными являются количество прогонов любой из действующих программ, состояние баз данных и моменты выполнения той или иной программы. В условиях, когда состояние программы достоверно известно в качестве периода наблюдений следует выбрать рабочий цикл или прогон. В любом случае перед каждым повторным выполнением программы необходимо либо восстанавливать состояние памяти , либо осуществлять серию последовательных прогонов, при котором последовательным образом изменяется состояние базы данных.
Интуитивное определение безопасности ПО может быть уточнено в статистическом смысле на основе следующих простых соображений:
-
машинная программа p может быть определена как описание некоторой вычислимой функции F на множестве E всех значений наборов входных данных, таких что каждый элемент Ei множества E представляет собой набор значений данных, необходимый для выполнения прогона программы: E=(Ei:i=1,2,...,N);
-
выполнение программы p приводит к получению для каждого Ei определенного значения функции F(Ei);
-
множество E определяет все возможные вычисления в программе p, то есть каждому набору входных данных Ei соответствует прогон программы p, и наоборот, каждому прогону соответствует некоторый набор входных данных Ei;
-
наличие дефектов в программе p приводит к тому, что ей на самом деле соответствует функция F', отличная от заданной функции F;
-
для некоторого Ei отклонение выхода F'(Ei), полученного в результате выполнения программы не должно превышать уровень безопасности программного обеспечения S(Ei), то есть безопасность обеспечивается при соблюдении ограничения: F'(Ei), S(Ei). (Вопрос о том, приводит ли некоторое отклонение выхода к нарушению условия безопасности, должен решаться в каждом конкретном случае отдельно, поскольку все определяется конкретными особенностями поведения системы после нарушения ее работы)
.
Совокупность действий, включающая ввод Ei, выполнение программы p, которое заканчивается получением результата F'(Ei) называется прогоном программы p. Необходимо также отметить, что значения входных переменных, образующие Ei, не должны все одновременно подаваться на вход программ p. Таким образом, вероятность P того, что прогон программы приведет к обнаружению дефекта, равна вероятности того, что набор данных Ei, используемый в данном прогоне, принадлежит множеству Ee. Если обозначить через ne число различных наборов значений входных данных, содержащихся в Ee, то P=ne/N - есть вероятность того, что прогон программы на наборе входных данных Ei, случайно выбранном из E среди равновероятных, закончится обнаружением дефекта. При этом R=1-P - есть вероятность того, что прогон программы p на наборе входных данных Ei, случайно выбранном из E среди априорно равновероятных, приведет к получению приемлемого результата.
Однако в процесс функционирования программы выбор входных данных из E обычно осуществляется не с одинаковыми априорными вероятностями, а диктуется определенными условиями работы. Эти условия характеризуются некоторым распределением вероятностей pi, того, что будет выбран набор входных данных Ei. Распределение P может быть определено через pi с помощью величины yi, которая принимает значение 0, если прогон программы на наборе Ei заканчивается вычислением приемлемого значения функции, и значением 1, если этот прогон заканчивается обнаружением дефекта. Поэтому 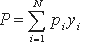 - есть вероятность того, что прогон программы на наборе входных данных Ei, выбранных случайно с распределением вероятностей pi, закончится обнаружением дефекта. При этом R=1-P есть вероятность того, что прогон программы p на наборе входных данных Ei, выбранных случайно с распределением вероятностей pi, приведет к получению приемлемого результата.
- есть вероятность того, что прогон программы на наборе входных данных Ei, выбранных случайно с распределением вероятностей pi, закончится обнаружением дефекта. При этом R=1-P есть вероятность того, что прогон программы p на наборе входных данных Ei, выбранных случайно с распределением вероятностей pi, приведет к получению приемлемого результата.
Введем также определения и обозначения, связывающие структурные характеристики программ с их безопасностью. Структурными характеристиками программы p являются множество ветвей Lj (j=1,...,n), подмножества входных наборов данных Gj, соответствующие ветвям Lj, множества сегментов Segj, из которых состоят отдельные ветви, совокупность операторов ветвления, которые обеспечивают переход от одного сегмента к другому при движении по отдельной ветви программы.
Оценка технологической безопасности программ
на базе метода Нельсона
Перед тем как перейти непосредственно к методу оценки, необходимо сделать несколько замечаний. Следует заметить, что реальные условия испытаний программ всегда существенно отличаются от тех, которые требуются для представительного измерения уровня безопасности ПО. Так, например, тестовые прогоны выполняются на входных наборах данных, выбранных не совсем случайным, а выбранных некоторым определенным образом: обычно выбор производится так, чтобы соответствующую ошибку можно было найти как можно быстрее. При этом выбор основывается на опыте и интуиции испытателей, либо осуществляется с учетом функциональных возможностей, которые должна обеспечивать программа, или возможностей соответствующих методик испытаний. Поэтому контрольные примеры, как правило, не являются представительными с точки зрения моделирования реальных условий работы программы и далее описывается процедура грубой оценки величины R, предусматривающая использование результатов испытаний и включающая следующие шаги:
- Определение множества E входных массивов.
- Выделение в E подмножеств Gj, связанных с отдельными ветвями программы.
- Определение для каждого Gj в предполагаемых условиях функционирования значений вероятности Pj.
- Определение подмножества Gj для каждого входного набора данных, используемого в контрольных примерах.
- Выявление проверенных пар и непроверенных в ходе испытаний сегментов и пар сегментов.
- Определение для каждого j величины P'=ajPj, где aj определяется в соответствии со следующими правилами [56].
-
aj=0,99, если подмножество Gj включает более одного контрольного примера;
-
aj=0,95, если подмножество Gj включает ровно один контрольный пример;
-
aj=0,90, если подмножество Gj не включает ни одного контрольного примера, но в процессе проверки программы были найдены все сегменты и все сегментные пары ветви Lj;
-
aj=0,80, если в ходе испытаний были опробованы все сегменты, но не все сегментные пары;
-
aj=0,80-0,20m, если m сегментов (1 m 4) ветви Lj не были опробованы в ходе испытаний;
-
aj=0, если более чем 4 сегмента не были опробованы в процессе испытаний.
- Вычисление грубой оценки R" осуществляется по формуле
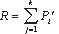 , где k представляет собой общее число ветвей программы.
, где k представляет собой общее число ветвей программы.
Приведенные выше параметры aj были определены интуитивно [56] на основе анализа теоретических результатов исследования и экспериментальных результатов тестирования различных программ. Для того, чтобы получить более точные оценки величины R необходимо провести измерения с использованием подходящего метода формирования выборки.
Оценка технологической безопасности ПО осуществляется посредством проверки условия R" S", где S" установленная нормативными документами граница безопасности ПО. Отметим также, что для систем критических приложений такая граница должна быть достаточно высокой, то есть стремится к 1.
2.4. МЕТОДЫ СОЗДАНИЯ АЛГОРИТМИЧЕСКИ БЕЗОПАСНЫХ ПРОЦЕДУР
2.4.1. Постановка задачи
Основной отличительной особенностью подхода, связанного с созданием алгоритмически безопасного ПО является то, что начало процесса обеспечения безопасности программ при их разработке можно перенести на более ранние этапы жизненного цикла программного обеспечения, например, на этапы, предшествующие этапу испытания программ, тем самым увеличив общее время на внесение в программы защитных функций. Здесь уместно процитировать слова Э.В. Дейкстра, одного из основоположников современной методологии программирования, сказанные им еще в 1972 году ([14], стр.41): "В настоящее время общепринятой техникой является составление программы, а затем ее тестирование. Однако тестирование программ может быть очень эффективным способом демонстрации наличия ошибок, но оно безнадежно неадекватно для доказательства их отсутствия... Не следует сначала писать программу, а потом доказывать ее правильность, поскольку в этом случае требование найти доказательство только увеличит тяготы бедного программиста". Эти слова как нельзя лучше подходят и к современной проблематике, связанной, в данном случае, не столько с разработкой правильных, сколько безопасных программ. Иными словами, ключом к созданию безопасного программного обеспечения является стремление защищаться от дефектов с самого начала жизненного цикла программ, а не после факта их создания.
Кроме того, следует отметить, что одно из основных достоинств методов создания алгоритмически безопасного программного обеспечения заключается в том, что данные методы позволяют защищать программное обеспечение, как на этапе разработки, так и на этапе его эксплуатации.
В то же время, необходимо сказать, что основная сложность в разработке безопасных программ указанного типа заключается в трудности нахождения эффективных алгоритмов их функционирования, которые являлись к тому же доказуемо корректными. И, предположительно, проблема неразрешимости доказательства безопасности для сложных программ при использовании методов их тестирования на этапе испытаний остается, в случае применения методов создания алгоритмически безопасного программного обеспечения, по-прежнему неразрешимой, что будет видно из дальнейших рассуждений.
Одним из главных методических вопросов создания безопасного программного обеспечения является постановка задачи (формулировка проблемы) ее разработки. Предположим, некоторому разработчику (коллективу разработчиков) предписывается разработать программу P для некоторого объекта автоматизации. При этом последствия некорректного функционирования программы таковы, что могут привести к неким "нежелательным" или даже катастрофическим последствиям для объекта автоматизации. Исходя из гипотезы, что в общем случае проблема доказательства безопасности для сложных комплексов программ является неразрешимой, неформальная качественная постановка задачи разработки указанных программ может быть тогда сформулирована следующим образом.
Постановка 1. "При некоторых условиях и ограничениях необходимо разработать программу P, которая корректно вычисляет результат почти для всех своих входных значений".
Таким образом, разработчик констатирует факт, что лишь для незначительной (возможно достаточно малой) доли входных значений программа может выдать некорректное выходное значение в результате необнаруженного программного дефекта или активизации необнаруженной программной закладки.
Понятно, что в некоторых случаях возникает определенная необходимость получения каких-либо более точных количественных оценок степени защиты созданной программы от внутренних дефектов, с целью получения определенных гарантий надежного функционирования объекта автоматизации.
При использовании контрольно-испытательных методов анализа безопасности программ, когда анализу подвергается только исполняемый код программы [17,45] можно получить (как правило, экспертным путем) либо приближенные количественные характеристики обнаружения дефектов в контролируемых программах, либо стратификационные характеристики ненарушения программой некоторых условий безопасности. В этом случае постановка 1 задачи разработки программы P принципиально не меняется. (Естественно не рассматриваются простейшие случаи, когда при тестировании возможен контроль результата программы при полном переборе всех входных значений, при всех ограничениях и допущениях и т.п.).
Постановка же задачи разработки безопасного программного обеспечения за счет алгоритмически безопасных процедур меняется с точки зрения получения точных количественных (в данном случае вероятностных) характеристик кардинальным образом.
Постановка 2. "При некоторых условиях и ограничениях необходимо разработать программу P*, которая корректно вычисляет результат для всех своих входных значений с пренебрежимо малой вероятностью ошибки".
На примере постановок 3, 4 и 5, 6 можно также проследить существенную разницу в парадигме разработки безопасных программ. Постановки 3 и 4 в отличие от постановок 1 и 2 учитывают не "содержание" наборов входных значений программы P, а их распределения вероятностей, а постановки 5 и 6 являются в некотором смысле обобщенными и учитывают заданный структурный критерий тестирования.
Постановка 3. "При некоторых условиях и ограничениях необходимо разработать программу P, которая некорректно вычисляет результат лишь для некоторого частного распределения вероятностей своих входных величин".
Постановка 4. "При некоторых условиях и ограничениях необходимо разработать программу P*, которая корректно вычисляет результат для любого распределения вероятностей своих входных величин с пренебрежимо малой вероятностью ошибки".
Постановка 5. "При некоторых условиях и ограничениях необходимо разработать программу P, которая корректно вычисляет результат почти на всех тестах полной системы тестов программы относительно заданного структурного критерия тестирования".
Постановка 6. "При некоторых условиях и ограничениях необходимо разработать программу P*, которая корректно с пренебрежимо малой вероятностью ошибки вычисляет результат на всех тестах полной системы тестов относительно заданного структурного критерия тестирования".
Одним из принципиальных условий решения задачи в постановке 2, 4 и 6 является наличие некоего свойства алгоритмической трансформации, позволяющего переходить от традиционного пути создания программ, которые будут затем проверяться на наличие дефектов, к априорно безопасным программам. К числу таких примеров можно отнести самокорректирующиеся и самотестирующиеся программы [23,26,31,33,62,63] (п.2.6.1.), обладающие свойством случайной самосводимости и программы, созданные на базе методов конфиденциальных вычислений [24,25,32] (п.2.6.2), начало изучения которых было положено в работах [61,67]. Рассмотренные до этого методы анализа безопасности ПО связаны с попытками обезопасить фактически уже разработанное программное обеспечение от действий злоумышленника. Это означает, что разработка безопасного ПО возможна за счет создания средств противодействия программным закладкам для продуктов, созданных на основе существующих информационных технологий создания программного обеспечения. То есть, только после факта разработки программ начинается верификационный анализ, тестирование или контроль их на технологическую безопасность. В этом смысле проблема обеспечения технологической безопасности программного обеспечения более близка к фундаментальной проблеме его надежности.
В то же время, данные методы создания безопасного ПО характеризуются рядом существенных недостатков, к числу которых можно отнести: невозможность перекрытия для большинства программных комплексов всего спектра тестовых наборов исходных данных; необходимость создания высоконадежных механизмов тестирования программ, например, механизмов экстраполяции результатов испытаний; существенные ресурсозатраты на проведение испытаний и т.п.
Поэтому в последнее время появилась насущная необходимость в создании новых информационных технологий разработки ПО, исходно ориентированных на создание безопасных программных продуктов относительного заданного класса. В этом случае проблема исследований сводится к разработке таких математических моделей, которые представляются адекватной формальной основой для создания методов защиты программного обеспечения на этапе его проектирования и разработки. При этом изначально предполагается, что:
-
один или несколько участников проекта являются (или, по крайней мере, могут быть) злоумышленниками;
-
в процессе эксплуатации злоумышленник может вносить в программы изменения (необязательно связанные с внедрением апостериорных программных закладок);
-
средства вычислительной техники, на которых выполняются программы, не свободны от аппаратных закладок.
Тогда, исходя из этих допущений, формулируется следующая неформальная постановка задачи: "Требуется разработать программное обеспечение таким образом, что несмотря на указанные выше "помехи" оно функционировало бы правильно". Одно из основных достоинств здесь состоит в том, что одни и те же методы позволяют защищаться от злоумышленника, действующего как на этапе разработки, так и на этапе эксплуатации программного обеспечения. Однако, это достигается за счет некоторого замедления вычислений, а также повышения затрат на разработку программного обеспечения.
В рамках указанного выше подхода на данный момент известны два направления, неформальное введение в которые дается ниже.
2.4.2. Методы создания самотестирующихся и
самокорректирующихся программ для решения вычислительных задач
Общие принципы создания двухмодульных вычислительных процедур и методология самотестирования
Пусть необходимо написать программу P для вычисления функции f так, чтобы P(x)=f(x) для всех значений x.Традиционные методы верификационного анализа и тестирования программ не позволяют убедиться с вероятностью близкой к единице в корректности результата выполнения программы, хотя бы потому, что тестовый набор входных данных, как правило, не перекрывают весь их возможный спектр. Один из методов решения данной проблемы заключается в создании так называемых самокорректирующихся и самотестирующихся программ, которые позволяют оценить вероятность некорректности результата выполнения программы, то есть, что P(x) f(x) и корректно вычислить f(x) для любых x, в том случае, если сама программа P на большинстве наборах своих входных данных (но не всех) работает корректно.
Чтобы добиться корректного результата выполнения программы P, вычисляющей функцию f, нам необходимо написать такую программу Tf, которая позволяла бы оценить вероятность того, что P(x) f(x) для любых x. Такая вероятность будет называться вероятностью ошибки выполнения программы P. При этом Tf может обращаться к P как к своей подпрограмме.
Обязательным условием для программы Tf является ее принципиальное отличие от любой корректной программы вычисления функции f, в том смысле, что время выполнения программы Tf, не учитывающее время вызовов программы P, должно быть значительно меньше, чем время выполнения любой корректной программы для вычисления f. В этом случае, вычисления согласно Tf некоторым количественным образом должны отличаться от вычислений функции f и самотестирующаяся программа может рассматриваться как независимый шаг при верификации программы P, которая предположительно вычисляет функцию f. Кроме того, желательное свойство для Tf должно заключаться в том, чтобы ее код был насколько это возможно более простым, то есть Tf должна быть эффективной в том смысле, что время выполненияTf даже с учетом времени, затраченное на вызовы P должно составлять константный мультипликативный фактор от времени выполнения P. Таким образом, самотестирование должно лишь незначительно замедлять время выполнения программы P.
Самокорректирующаяся программа это вероятностная программа Cf, которая помогает программе P скорректировать саму себя, если только P выдает корректный результат с низкой вероятностью ошибки, то есть для любого x, Cf вызывает программу P для корректного вычисления f(x), в то время как собственно сама P обладает низкой вероятностью ошибки.
Самотестирующейся/самокорректирующейся программной парой называется пара программ вида (Tf,Cf). Предположим пользователь может взять любую программу P, которая целенаправленно вычисляет f и тестирует саму себя при помощи программы Tf. Если P проходит такие тесты, тогда по любому x, пользователь может вызвать программу Cf, которая, в свою очередь, вызывает P для корректного вычисления f(x). Даже если программа P, которая вычисляет значение функции f некорректно для некоторой небольшой доли входных значений, ее в данном случае все равно можно уверенно использовать для корректного вычисления f(x) для любого x. Кроме того, если удастся в будущем написать программу P' для вычисления f, тогда некоторая пара (Tf,Cf) может использоваться для самотестирования и самокоррекции P' без какой-либо ее модификации. Таким образом, имеет смысл тратить определенное количество времени для разработки самотестирующейся/ самокорректирующейся программной пары для прикладных вычислительных функций.
Перед тем как перейти к более формальному описанию определений самотестирующихся и самокорректирующихся программ необходимо дать определение вероятностной оракульной программе (по аналогии с вероятностной оракульной машиной Тьюринга).
Вероятностная программа M является вероятностной оракульной программой, если она может вызывать другую программу, которая является исполнимой во время выполнения M. Обозначение MA означает, что M может делать вызовы программы A.
Пусть P - программа, которая предположительно вычисляет функцию f. Пусть I является объединением подмножеств In, где n принадлежит множеству натуральных чисел N и пусть Dp={Dn|n N} есть множество распределений вероятностей Dn над In. Далее, пусть err(P,f,Dn) это вероятность того, что P(x) f(x), где x выбрано случайно в соответствии с распределением Dn из подмножества In. Пусть β - есть некоторый параметр безопасности. Тогда (ε1, ε2)-самотестирующейся программой для функции f в отношении Dp с параметрами 0 ε1<ε2 1 - называется вероятностная оракульная программа Tf, которая для параметра безопасности β и любой программы P на входе n имеет следующие свойства:
- если err(P,f,Dn)ε1, тогда программа TfP выдаст на выходе ответ "норма" с вероятностью не менее 1-β .
- если err(P,f,Dn)ε2, тогда программа TfP выдаст на выходе "сбой" с вероятностью не менее 1-β .
Оракульная программа
Cf с параметром 0
ε < 1 называется ε-самокорректирующейся программой для функции
f в отношении множества распределений
Dp, которая имеет следующее свойство по входу
n,
x In и β. Если
err(P,f,Dn)ε , тогда
CfP=f(x) с вероятностью не менее 1- β.
(ε
1,ε
2,ε)-
самотестирующейся/ самокорректирующейся программной парой для функции
f называется пара вероятностных программ (
Tf,Cf) такая, что существуют константы 0
ε
1 < ε
2 ε < 1 и множество распределений
Dp при которых
Tf -есть (ε
1,ε
2)-самотестирующаяся программа для функции
f в отношении
Dp и
Cf - есть
ε-самокорректирующаяся программа для функции
f в отношении распределения
Dp.
Свойство случайной самосводимости. Пусть x In и пусть c > 1 - есть целое число. Свойство случайной самосводимости заключается в том, что существует алгоритм A1, работающий за время пропорциональное nO(1), по-средством которого функция f(x) может быть выражена через вычислимую функцию F от x, a1,...,ac и f(a1),...,f(ac) и алгоритм A2, работающий за время пропорциональное nO(1), посредством которого по данному x можно вычислить a1,...,ac, где каждое ai является случайно распределенным над In в со-ответствии с Dp.
Метод создания самотестирующейся расчетной программы
с эффективным тестирующим модулем
В качестве расчетной программы рассматривается любая программа, решающая задачу получения значения некоторой вычислимой функции. При этом под верификацией расчетной программы понимается процесс доказательства того, что программа будет получать на некотором входе истинные значения исследуемой функции. Иными словами, верификация расчетной программы направлена на доказательство отсутствия преднамеренных и (или) непреднамеренных программных дефектов в верифици-руемой программе.
В данном случае предлагается метод создания самотестирующихся программ для верификации расчетных программных модулей [33]. Данный метод не требует вычисления эталонных значений и является независимым от используемого при написании расчетной программы языка программи-рования, что существенно повышает оперативность исследования программы и точность оценки вероятности отсутствия в ней программных де-фектов. Следует в то же время отметить, что предположительно предлагаемый метод можно использовать для программ, вычисляющих функции особого вида, а именно функции, обладающие свойством случайной само-сводимости.
Пусть для функции Y = f (X) существует пара функций (gc, hc)Y таких, что:
Y = gc (f (a1), ..., f (ac)),
X = hc (a1, ..., ac).
Легко увидеть, что если значения ai выбраны из In в соответствии с распределением Dp, тогда пара функций (gc, hc)Y обеспечивает выполнение для функции Y = f (X) свойства случайной самосводимости. Пару функций (gc, hc)Y будем называть ST-парой функций для функции Y = f (X).
Метод верификации расчетных программ на основе
ST-пары функций.
Предположим, что на ST-пару функций можно наложить некоторую совокупность ограничений на сложность программной реализации и время выполнения. В этом случае, пусть длина кода программ, реализующих функции gc и hc , и время их выполнения составляет константный мультип-ликативный фактор от длины кода и времени выполнения программы P.
Предлагаемый метод верификации расчетной программы P на основе ST-пары функций для некоторого входного значения вектора X* заключа-ется в выполнении следующего алгоритма. (Всюду далее, если осуществ-ляется случайный выбор значений, этот выбор выполняется в соответствии с распределением вероятностей Dp).
Алгоритм ST
Определить множество A*={a1*,...,ac*} такое, что X*=hc{a1*,...,ac*} , где a1*,...,ac* выбраны случайно из входного подмножества In.
Вызвать программу P для вычисления значения Y0*=f(X*)
Вызвать c раз программу P для вычисления множества значений {f(a1*),...,f(ac*)}
Определить значения Y1*=gc{f(a1*) ,...,f(ac*)}
Если Y0*=Y1* , то принимается решение, что программа P корректна на множестве значений входных параметров {X*,a1*,...,ac*} в противном случае данная программа является некорректной.
Таким образом, данный метод не требует вычисления эталонных значений и за одну итерацию позволяет верифицировать корректность программы P на (n+1) значении входных параметров. При этом время верификации можно оценить как 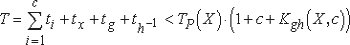 где ti и tx - время выполнения программы P при входных значениях ai и X* соответственно;
где ti и tx - время выполнения программы P при входных значениях ai и X* соответственно;
tg и th-1 - время определения значения функции gc и множества A* соответственно:
TP (X) - временная (не асимптотическая) сложность выполнения программы P;
Kgh (X, c)- коэффициент временной сложности программной реализации функции gc и определения A* по отношению ко временной сложности программы P (по предположению он составляет константный мульти-пликативный фактор от TP (X), а его значение меньше 1). Для традиционного вышеуказанного метода тестирования время выполнения и сравнения полученного результата с эталонным значением составляет:
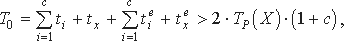
где tie и txe - время определения эталонных значений функции Y = f (X) при значениях ai и X* соответственно (в общем случае, не может быть меньше времени выполнения программы).
Следовательно, относительный выигрыш по оперативности предложенного метода верификации (по отношению к методу тестирования программ на основе ее эталонных значений):
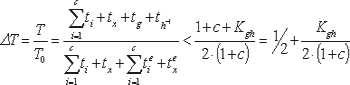
Так как, коэффициент Kgh < 1, а c 2, то получаем относительный вы-игрыш по оперативности испытания расчетных программ указанного типа (обладающих свойством случайной самосводимости) более чем в 1.5 раза.
Исследования процесса верификации расчетных программ
В качестве примера работоспособности предложенного метода рассмотрим верификацию программы вычисления функции дискретного возведения в степень:
y = fAM (x) = Ax modulo M.
Выбор данной функции обусловлен тем, что она является одной из основных функций в различных теоретико-числовых конструкциях, например, в схемах электронной цифровой подписи, системах открытого распределения ключей и т.п. Это, в свою очередь, демонстрирует возможность применения предложенного метода при исследовании расчетных программ, решающих конкретные прикладные задачи. Кроме того, очевидно, что данная функция обладает свойством случайной самосводимо-сти, а исходя из результатов работы [62] можно показать, что для данной функции существует (1/288, 1/8)-самотестирующаяся программа.
Для экспериментальных исследований была выбрана программа EXP из библиотеки базовых криптографических функций CRYPTOOLS [33], которая реализует функцию дискретного возведения в степень (размерность переменных и констант не превышает 64 байтов). Была разработана интегрированная оболочка для проведения верификации, включающая ин-терфейс с пользователем и программные процедуры, реализующие некоторую совокупность проверочных тестов. Экспериментальные исследования состояли из определения временных характеристик процесса верифи-кации на основе использования ST-пары функций и определения возмож-ности обнаружения предложенным методом преднамеренно внесенных программных ошибок.
Для этого были определены следующие ST-пары функций:
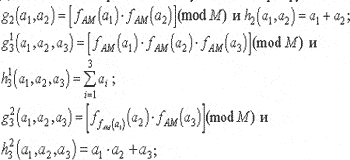
В процессе исследований менялась используемая ST-пара функций и варьировалась размерность параметров A, M и аргумента X. Результаты экспериментов полностью подтвердили приведенные выше временные за-висимости (технические результаты исследований авторы в данной работе опускают).
Исследование возможности обнаружения предложенным методом преднамеренно внесенных ошибок заключалось в написании программы EXPZ. Спецификация для программ EXP и EXPZ одна и та же, отличие же заключается в том, что программа EXPZ содержит программную закладку деструктивного характера. Преднамеренно внесенная закладка при иссле-дованиях гарантировала сбой работы программы вычисления значения функции y = fAM (x) = Ax modulo M (то есть обеспечивала получение непра-ильного значения функции) примерно на каждой восьмой части входных значений экспоненты x.
Было проведено свыше 2000 экспериментов [33]. Все входные значения, на которых произошел сбой программы, были обнаружены, что в дальнейшем подтвердилось проверочными тестами, основанными на использовании малой теоремы Ферма и теореме Эйлера. Этот факт, в свою очередь, экспериментально показал, что программа, реализующая алгоритм ST, является (1/8,1/288)-самотестирующейся программой.
Таким образом, предложенный метод позволяет в значительной степени сократить время испытания расчетных программ на предмет выявления непреднамеренных и преднамеренных программных дефектов. При этом по результатам испытаний можно получить количественные оценки вероятности наличия программных дефектов в верифицируемой расчетной программе. Однако, разработка формальных методов получения ST-пары функций для заданной расчетной программы, а также разработка методик ее испытания с помощью рассмотренного алгоритма требуют дальнейших теоретических и прикладных исследований.
Метод создания самокорректирующейся процедуры вычисления
теоретико - числовой функции дискретного экспоненцирования
Обозначения и определения для функции дискретного возведения в степень вида gxmoduloM. Пусть In=Zq представляет собой множество {1,...,q}, где q= φ(M) - значение функции Эйлера для модуля M, а Z*M - множество вычетов по модулю M, где n= |log2M|. Пусть распределение Dp есть равномерное распределение вероятностей. Тогда равновероятный случайный выбор элемента a из множества Ω будет обозначаться как aRΩ . Оракульной программой, в данном случае, является программа вы-числения функции gxmoduloM, по отношению к исследуемым самотестирующейся и самокорректирующейся программам.
Алгоритм Axmodulo N можно вычислить многими способами [34,64], один из наиболее общеизвестных и применяемых, - это алгоритм, основанный на считывании индекса (значения степени) слева направо. Этот метод достаточно прост и нагляден, история его восходит еще к 200 г. до н.э. Пусть x[1,...,n] - двоичное представление положительного числа x и A, B и N - положительные целые числа в r-ичной системе счисления, тогда псевдокод алгоритма Axmodulo N, реализованного программой Exp(') имеет следующий вид.
Псевдокод алгоритма AxmoduloN
Program Exp(x,N,A,R); {вход x,N,A, выход R}
begin
B:=1;
for i:=1 to n do
begin
B:=(B*B)modN;
if [i]=1 then B:=(A*B)modN;
end;
R:=B;
end.
Из описания алгоритма видно, что число обращений к операции вида
(A*B)modulo
N будет log
x+ β(x), где β(x) число единиц в двоичном представлении операнда
x или вес Хэмминга
x.
Построение самотестирующейся/самокорректирующейся программной пары для функции дискретного экспоненцирования.
Сначала рассмотрим следующие 4 алгоритма (см. рис.2.6 - 2.9). Для доказательства полноты и безопасности указанной пары доказывается сле-дующая теорема.
Теорема 2.2. Пара программ S_K_exp(x,M,q,g,β) и S_T_exp(x,M,q,g,β) является (1/288,1/8,1/8)-самокорректирующейся/ самотестирующейся про-граммной парой для функции gxmoduloM, с входными значениями, выбранными случайно и равновероятно из множества In.
Для доказательства теоремы необходимо доказать следующие две леммы.
Лемма 2.1. Программа S_K_exp(M,q,g,β) является (1/8)-самокорректирующейся программой для вычисления функции gxmoduloM в отношении равномерного распределения Dn.
Доказательство. Полнота программы S_K(') означает, что если оракульная программа P(x), обозначаемая как Exp(') выполняется корректно, то и самокорректирующаяся программа S_K(') будет выполняться кор-ректно. В данном случае полнота программы очевидна. Если P(x) коррект-но вычислима, то из 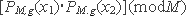 следует, что
следует, что
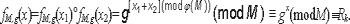

Рис. 2.6. Псевдокод алгоритма S_K_exp

Рис. 2.7. Псевдокод алгоритма S_T_exp
Program L_T(n,R); {вход g,M,q, выход Rl}
begin
x1:=random(q);
x2:=random(q);
x:=(x1+x2)modq;
Exp(g,x1,M,R1);
Exp(g,x2,M,R2);
Exp(g,x,M,R);
if R1 R2=R then Rl:=1
else Rl:=0;
end.
Рис. 2.8. Псевдокод алгоритма теста линейной состоятельности L_T
Program N_T(n,R); {вход g,M,q, выход Re}
begin
x1:=random(q);
x2:=(x1+1)modq;
Exp(g,x1,M,R1);
Exp(g,x2,M,R2);
if R1 g=R2 then Re:=1
else Re:=0;
end.
Рис. 2.9. Псевдокод алгоритма теста единичной состоятельности N_T
Для доказательства безопасности сначала необходимо отметить, что так как x1 RZq, то и x2 имеет равномерное распределение вероятностей над Zq. Так как вероятность ошибки ε 1/8, то в одном цикле вероят-ность Prob[Rk=fM,g(x)] 3/4. Чтобы вероятность корректного ответа была не менее чем 1- β, исходя из оценки Чернова [62], необходимо выполнить не менее 12ln(1/β ) циклов
Лемма 2.2. Программа S_T_exp(n,M,q,g,β) является (1/288,1/8)-самотестирующейся программой, которая контролирует результат вычисления значения функции gxmoduloM с любым модулем M.
Доказательство. Полнота теста линейной состоятельности доказыва-ется аналогично доказательству полноты в лемме й, где x1,x2 RZq. Полнота теста единичной состоятельности вытекает исходя из следующего очевид-ного факта. Корректное выполнение теста [PM,g(x1)'PM.g(1)](mod M) соответствует вычислению функции:
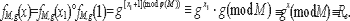
Для доказательства условия самотестируемости необходимо отметить, что так как и в лемме 1 для того, чтобы вероятность корректных ответов Rl и Re в обоих тестах была не более 1-β достаточно выполнить тест линейной состоятельности 576ln(4/β) раз и тест единичной состоятельности 32ln(4/β) раз.
Можно показать, основываясь на теоретико - групповых рассуждени-ях, что возможно обобщение программы S_T(') и для других групп (алгоритмы данной программы основываются на вычислениях в мультипликативной группе вычетов над конечным полем). То есть для всех yG, P(y)G*, где G* -представляет собой любую группу, кроме групп G**. К группам последнего вида относятся бесконечные группы, не имеющие конечных подгрупп за исключением {О`}, где О` - тождество группы. Таким образом, можно показать (при использовании в вышеуказанных алгорит-мах параметров с их независимым, равновероятным и случайным выбо-ром), что программа вида S_T(') является (ε/36,ε)-самотестирующейся программой. Отсюда следует доказательство утверждения леммы
Исходя из определения самотестирующейся/ самокорректирующейся программной пары и основываясь на результатах доказательств лемм 1 и 2, очевидным образом следует доказательство теоремы 1.
Замечания. Как видно из псевдокода алгоритма Axmodulo N в нем используется операция ABmodulo N. Используя ту же технику доказательств, как и для функции дискретного возведения в степень, можно построить (1/576,1/36,1/36)-самокорректирующуюся/ самотестирующуюся программ-ную пару для вычисления функции модулярного умножения. Это справед-ливо исходя из следующих соображений. Вычисление функции fM(ab)=fM((a1+a2)(b1+b2)) следует из корректного выполнения программы с 4-х кратным вызовом оракульной программы P(a,b), то есть:
[PM(a1,b1)+PM(a1,b2)+PM(a2,b1)+PM(a2,b2)](mod M).
Алгоритм вычисления Axmodulo N выполняется для c=2. Однако, декомпозиция x, как следует из свойства самосводимости функции Axmodulo N, может осуществляться на большее число слагаемых. Хотя это приведет к гораздо большему количеству вызовов оракульной программы, но в то же время позволит значительно снизить вероятность ошибки.
Применение самотестирующихся и самокорректирующихся программ
Применение самотестирующихся, самокорректирующихся программ и их сочетаний возможно в самых различных областях вычислительной математики, а, следовательно, в самых разнообразных областях человече-ской деятельности, где широко применяются вычислительные методы. К ним относятся такие направления как цифровая обработка сигналов (а, следовательно, решение проблем в системах распознавания изображений, голоса, в радио- и гидроакустике), а также методы математического моделирования процессов изменения народонаселения, экономических процессов, процессов изменения погоды и т.п. Идеи самотестирования могут найти самое широкое применение в системах защиты информации, например, в системах открытого распределения ключей, в криптосистемах с открытым ключом, в схемах идентификации пользователей вычислительных систем и аутентификации данных, где базовые вычислительные алгоритмы обладают некоторыми алгоритмическими свойствами, например, свойством случайной самосводимости, описанным выше.
Активными исследованиями в области создания самотестирующихся и самокорректирующихся программ в вычислительной математике ученые и практики начали заниматься с начала 90-х годов. В этот период были разработаны самотестирующиеся программы для ряда теоретико-числовых и теоретико-групповых задач, для решения задач с матрицами, полиномами, линейными уравнениями, рекуррентными соотношениями и аппроксимирующими функциями.
Основная идея использования идей самотестирования в криптографии заключается в неформальном девизе "Защитить самих защитников". Так как криптографические методы используются для высокоуровневого обеспечения конфиденциальности и целостности информации, собственно программно-техническая реализация этих методов должна быть свободна от программных и/или аппаратных дефектов. Таким образом, самотестирование и самокоррекция программ может эффективно применяться в совре-менных системах защиты информации от несанкционированного доступа.
К другим направлениям в теории и практике самотестирования можно отнести построение псевдослучайных генераторов, в котором центральным звеном является конструкция, которую можно рассматривать как самокорректирующую программу для решения задачи, эквивалентной проблеме дискретных логарифмов, а также разработку самотестирующихся программ для параллельных вычислений, где используется идея самотестирования для построения схемы константной глубины для проверки мажоритарных функций.
2.4.3. Создание безопасного программного обеспечения на базе методов теории конфиденциальных вычислений
Постановка задачи
Задачу конфиденциальных вычислений, которая решается посредством многостороннего интерактивного протокола можно описать в следующей постановке. Имеется n участников протокола или n процессоров вычислительной системы, соединенных сетью связи. Изначально каждому процессору известна своя "часть" некоторого входного значения x. Требуется вычислить f(x), f - некоторая известная всем участникам вычислимая функция, таким образом, чтобы выполнились следующие требования:
-корректности, когда значение f(x) должно быть вычислено правильно, даже если некоторая ограниченная часть участников произвольным образом отклоняется от предписанных протоколом действий;
-конфиденциальности, когда в результате выполнения протокола не один из участников не получает никакой дополнительной информации о начальных значениях других участников (кроме той, которая содержится в вычисленном значении функции).
Можно представить следующий сценарий использования этой модели для разработки безопасного программного обеспечения. Имеется некоторый процесс, для управления которым необходимо вычислить функцию f. При этом последствия вычисления неправильного значения таковы, что представляется целесообразным пойти на дополнительные затраты, связанные с созданием сети из n процессоров и распределенного алгоритма для вычисления f. В системе имеется еще один абсолютно надежный участник, который имеет доступ к секретному значению x и имеет возможность выделить каждому участнику свою "долю" x. Название протоколы "конфиденциальное вычисление функции" отражает тот факт, что требование конфиденциальности является основным, то есть значение x не должно попасть в руки злоумышленника.
Общие замечания по проблематике конфиденциальных вычислений
Задача конфиденциального вычисления была впервые сформулирована А.Яо для случая с двумя участниками в 1982 г. В 1987 г. О. Голдрайх, С. Микали и А. Вигдерсон показали, как безопасно вычислить любую функцию, аргументы которой распределены среди участников в вычисли-тельной установке (то есть в конструкции, где потенциальный противник ограничен в действиях вероятностным полиномиальным временем). В их работе рассматривалась синхронная сеть связи из n участников, где каналы связи небезопасны и стороны, также как и противник, ограниченны в сво-их действиях вероятностным полиномиальным временем. В своей модели вычислений они показали, что в предположении существования односто-ронних функций с секретом можно построить многосторонний протокол (с n участниками) конфиденциальных вычислений любой функции в присут-ствие пассивных противников (т.е., противников, которым позволено толь-ко "прослушивать" коммуникации). Для некоторых типов противников (для византийских сбоев) авторы привели протокол для конфиденциально-го вычисления любой функции, где ( n/2 -1) участников протокола явля-ются нечестными (или ( n/2 -1)-протокол конфиденциальных вычислений).
В дальнейшем изучались многосторонние протоколы конфиденциаль-ных вычислений в модели с защищенными каналами. Было показано, что если противник пассивный, то существует ( n/2 -1)-протокол для конфиденциального вычисления любой функции. Если противник активный (т.е., противник, которому позволено вмешиваться в процесс вычислений), тогда любая функция может быть вычислена посредством ( n/3 -1)-протокола конфиденциальных вычислений. Эти протоколы являются безопасными в присутствие неадаптивных противников (т.е., противников, действующих в схеме вычислений, в которой множество участников независимо, но фиксировано).
В последнее время исследуются вычисления для случая активных противников, ограниченных в работе вероятностным полиномиальным временем, где часть участников вычислений может быть "подкуплена" противником и многосторонние конфиденциальные вычисления при наличии незащищенных каналов и с вычислительно неограниченным против-ником, а также исследовались многосторонние конфиденциальные вычисления с нечестным большинством участников при наличии защищенных каналов. Кроме того, изучаются многосторонние протоколы конфиденциальных вычислений при наличии защищенных каналов и динамического противника (т.е., противника, который может "подкупать" различных участников в разные моменты времени). В фундаментальной работе [67] предложены определения для многосторонних конфиденциальных вычис-лений при наличии защищенных каналов и в присутствии адаптивных про-тивников.
В работе [61], авторы начали комплексные исследования асинхронных конфиденциальных вычислений. Они рассмотрели полностью асинхрон-ную сеть (т.е., сеть, где не существует глобальных системных часов), в ко-торой стороны соединены защищенными каналами связи. Автор привел первый асинхронный протокол византийских соглашений с оптимальной устойчивостью, где противник может "подкупать" n/3 -1 из n участников вычислений.
Определение односторонней функции, описание используемых
примитивов, схем и протоколов
В качестве одного из основных математических объектов в данной работе используются односторонние функции, то есть вычислимые функции, для которых не существует эффективных алгоритмов инвертирова-ния. Необходимо отметить, что односторонняя функция - гипотетический объект, поэтому называть конкретные функции односторонними матема-тически некорректно. Впервые такую гипотетическую конструкцию для конкретного криптографического приложения, - открытого распределения ключей, предложили У. Диффи и М. Хеллман в 1976 г. (см, например, оп-ределения в работе [6]). Они показали, что вычисление степеней в мульти-пликативной группе вычетов над конечным полем является простой зада-чей с точки зрения состава необходимых вычислений, в то время как из-влечение дискретных логарифмов над этим полем - предположительно сложная вычислительная задача.
Неформально говоря, для двух независимых множеств X и Y функция f:X- > Y называется односторонней, если для каждого x X можно легко вычислить f(x), в то время как почти для всех y Y вычислительно трудно по-лучить такой x X, что f(x)=y, при условии , что такой x существует.
Далее приводится формальное определение односторонней функции в терминах теории сложности вычислений. Для этого введем следующее обозначение. Пусть a RM обозначает, что элемент a случайно, с равномерным распределением вероятностей и независимо от других событий выбран из всех элементов множества M.
Функция f называется односторонней, если существует полиномиальная машина Тьюринга T, которая на любом входе x 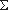 вычисляет f(x) и для любого полиномиального алгоритма A справедливо следующее.
вычисляет f(x) и для любого полиномиального алгоритма A справедливо следующее.
Пусть x R n и слово y=f(x) подано на вход алгоритма A. Тогда для любого полинома p и для всех достаточно больших n вероятность Prob(f(A(y))=y)<1/p(n).
Вероятность берется по выбору значения x из n и, если A - это веро-ятностная машина Тьюринга, - по вырабатываемым ею случайным величинам.
(n,t)-Пороговые схемы. Используемая в данном разделе (n,t)-пороговая схема, известная как схема разделения секрета Шамира, - это протокол между n+1 участниками, в котором один из участников, именуемый дилер - Д, распределяет частичную информацию (доли) о секрете между n участниками так, что:
-
любая группа из менее чем t участников не может получить любую информацию о секрете;
-
любая группа из не менее чем t участников может вычислить сек-рет за полиномиальное время.
Пусть секрет s - элемент поля F. Чтобы распределить s среди участни-ков P1,...,Pn, (где n< |F| ) дилер выбирает полином f F[x] степени не более t-1, удовлетворяющий f(0)=s. Участник Pi получает si=f(xi) как свою долю секрета s, где xi F\{0} - общедоступная информация для Pi (xi xj для i j).
Вследствие того, что существует один и только один полином степени не менее k-1, удовлетворяющий f(xi)=si для k значений i, схема Шамира удовлетворяет определению (n,t)-пороговых схем. Любые t участников могут найти значение f по формуле:
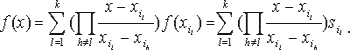
Следовательно
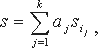
где a1,...,ak получаются из
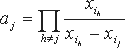
Таким образом, каждый ai является ненулевым и может быть легко вычислен из общедоступной информации.
Проверяемая схема разделения секрета. Пусть имеется n участников вычислений и t* (значение t* не более порогового значения t) из них могут отклоняться от предписанных протоколом действий. Один из участников назначается дилером Д, которому (и только ему) становится известен секрет (секретная информация) s. На первом этапе дилер вне зависимости от действий нечестных участников осуществляет привязку к уникальному параметру u. Идентификатор дилера известен всем абонентам системы. На втором этапе осуществляется открытие (восстановление) секрета s всеми честными участниками системы. И если дилер Д - честный, то s=u.
Проверяемая схема разделения секрета ПРС представляет собой пару многосторонних протоколов (РзПр,ВсПр), - а именно протокола разделения секрета и проверки правильности разделения РзПр и протокола восстановления и проверки правильности восстановления секрета ВсПр, при реализации которых выполняются следующие условия безопасности.
Условие полноты. Для любого s, любой константы c>0 и для достаточно больших n вероятность
Prob((n,t,t*)РзПр=(Да,s) t* < t & Д - честный)>1-n-c.
Условие верифицируемости. Для всех возможных эффективных алгоритмов Прот, любой константы c>0 и для достаточно больших n вероятность
Prob((t*,(Да,u))ВсПр=(s=u)| (n,t,t*)РзПр=(Да,u)& t* < t & Д - честный)<n-c.
Условие неразличимости. Для секрета s* RS вероятность
Prob(s*=s |(n,t,t*)РзПр=(Да,s*) & Д - честный)< 1/ |S| .
Свойство полноты означает, что если дилер Д честный и количество нечестных абонентов не больше t, тогда при любом выполнении протокола РзПр завершится корректно с вероятностью близкой к 1. Свойство верифицируемости означает, что все честные абоненты выдают в конце протокола ВсПр значение u, а если Д - честный, тогда все честные абоненты восстановят секрет s=u. Свойство неразличимости говорит о том, что при произвольном выполнении протокола РзПр со случайно выбранным секретом s*, любой алгоритм Прот не может найти s*=s лучше, чем простым угадыванием.
Широковещательный примитив (Br-субпротокол). Введем следующее определение. Протокол называется t-устойчивым широковещательным протоколом, если он инициализирован специальным участником (дилером Д), имеющим вход m (сообщение, предназначенное для распространения) и для каждого входа и коалиции нечестных участников (числом не более t) выполняются условия.
Условие завершения. Если дилер Д - честный, то все честные участники обязательно завершат протокол. Кроме того, если любой честный участник завершит протокол, то все честные участники обязательно завершат протокол.
Условие корректности. Если честные участники завершат протокол, то они сделают это с общим выходом m*. Кроме того, если дилер честный, тогда m*=m.
Необходимо подчеркнуть, что свойство завершения является более слабым, чем свойство завершения в византийских соглашений. Для Br-протокола не требуется, чтобы несбоящие процессоры завершали протокол, в том случае, если дилер нечестен.
Br-протокол
Код для дилера (по входу m):
- Послать сообщение (сбщ,m) всем процессорам и завершить протокол с выходом m.
Код для процессоров:
- После получения первых сообщений (сбщ,m) или (эхо,m), послать (эхо,m) ко всем процессорам и завершить протокол с выходом m.
Предложение 2.1. Br-протокол является t-усточивым широковещательным протоколом для противников, которые могут приостанавливать отправку сообщений.
Доказательство. Если дилер честен, то все несбоящие процессоры получают сообщение (сбщ,m) и, таким образом, завершают протокол с выходом m. Если несбоящий процессор завершил протокол с выходом m, то он посылает сообщение (эхо,m) ко всем другим процессорам и, таким образом, каждый несбоящий процессор завершит протокол с выходом m.
Ниже описывается 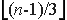 -устойчивый широковещательный протокол, который именуется BB. В протоколе принимается, что идентификатор дилера содержится в параметре m.
-устойчивый широковещательный протокол, который именуется BB. В протоколе принимается, что идентификатор дилера содержится в параметре m.
Протокол BB
Код для дилера (по входу m):
- Послать сообщение (сбщ,m) ко всем процессорам.
Код для процессора Pi:
- После получения сообщения (сбщ,m`), послать сообщение (эхо,m`) ко всем процессорам.
- После получения n-1 сообщений (сбщ,m` ), которые согласованы со значением m` послать сообщение (гот,m` ) ко всем процессорам.
- После получения t+1 сообщений (гот,m` ), которые согласованы со значением m` , послать (гот,m` ) ко всем процессорам.
- После получения n-1 сообщений (сбщ,m` ), которые согласованы со значением m , послать сообщение (OK,m` ) ко всем процессорам и принять m` как распространяемое сообщение.
Протокол византийского соглашения (BA-субпротокол). Введем следующее определение. При византийских соглашениях для любого начального входа xi, i [1,...,n] участника i и некоторого параметра d (соглашения) должны быть выполнены следующие условия.
Условие завершения. Все честные участники вычислений в конце протокола принимают значение d.
Условие корректности. Если существует значение x такое, что для честных участников xi=x, тогда d=x.
Обобщенные модели вычислений для сети синхронно и асинхронно
взаимодействующих процессоров
Принимаемая модель создания программного обеспечения на базе методов конфиденциального вычисления функции позволяет единообразно трактовать как ошибки, возникающие, например, в результате сбоев технических средств, так и ошибки, возникающие за счет привнесения в вычислительный процесс преднамеренных программных дефектов. Следует отметить, что протоколы конфиденциального вычисления функции относятся к протоколам, которые предназначены, прежде всего, для защиты процесса вычислений от действия "разумного" злоумышленника, то есть от злоумышленника, который всегда выбирает наихудшую для нас стратегию.
В модели вводится дополнительный параметр t, t < n, - максимальное число участников, которые могут отклоняться от предписанных протоколом действий, то есть максимальное число злоумышленников. Поскольку злоумышленники могут действовать заодно, обычно предполагается, что против протокола действует один злоумышленник, который может захва-тить и контролировать любые t из n процессоров по своему выбору.
Модель сбоев и модель противника
Рассматривается сеть взаимодействующих процессоров. Некоторые процессоры могут "сбоить". При сбоях, приводящих к останову (FS-сбоях), сбоящий процессор может приостановить в некоторый момент времени отправку своих сообщений. В то же время предполагается, что сбоящие процессоры продолжают получение сообщений и могут выдавать "некую информацию" в свои выходные каналы. При Византийских сбоях (By-сбоях) процессоры могут произвольным образом сотрудничать друг с другом с целью получения необходимой для них информации или с целью нарушения процесса вычислений. При By-сбоях сбоящие процессоры могут объединять свои входы и изменять их. В то же время это должно происходить при условии невозможности изучения любой информации о входах несбоящих процессоров.
Сбои могут быть статическими и динамическими. При статических сбоях множество сбоящих процессоров фиксировано в начале и процессе вычислений, при динамических - множество сбоящих процессоров может меняться, как может меняться и характер самих сбоев. Сбоящие процессоры будут также называться нечестными участниками вычислений, в противоположность честным участникам, которые выполняют предписанные вычисления.
Противника можно представлять как некий универсальный процессор, действия которого заключаются в стремлении "сделать" процессоры сети сбоящими ("подкупить" их).
По аналогии со сбоями противник может быть динамическим и статическим. Статическим противником является противник, который "сотрудничает" с фиксированным количеством сбоящих процессоров ("подкупленных" противником). При действиях динамического противника количество сбоящих процессоров может меняться (в том числе непредсказуемым образом).
Кроме того, противник может быть активным и пассивным, а также с априорными и апостериорными протокольными и раундовыми действиями. Пассивный противник не может изменять сообщения, циркулируемые в сети. Активный противник может знать все о внутренней конфигурации сети, может читать и изменять все сообщения сбоящих процессоров и может выбирать сообщения, которые будут посылать сбоящие процессоры при вычислениях. Активный динамический противник может в начале каждого раунда "подкупить" несколько новых процессоров. Таким образом, он может изучить информацию, получаемую ими в текущем раунде, и принять решение "подкупить" ли ему новый процессор, или нет. Такой противник может собирать и изменять все сообщения от сбоящих процессоров к несбоящим. В то же время гарантируется, что все сообщения (в том числе, между честными процессорами) будут доставлены адресатам в конце текущего раунда. Действия аналогичного характера активный противник может выполнить не только в течение раунда (в его начале и конце), но и до начала выполнения протокола и после его завершения.
Противник называется t-противником, если он сотрудничает с t процессорами.
Модель взаимодействия
Взаимодействие процессоров может осуществляться посредством конфиденциальных и открытых каналов связи. Каждые два процессора могут быть иметь симплексное, полудуплексное или дуплексное соединение. При этом каждое из соединений, в зависимости от решаемой задачи, в некоторый промежуток времени, может быть либо конфиденциальным, либо открытым.
Кроме того, может существовать широковещательный канал связи, то есть канал, посредством которого один из процессоров может одновременно распространить свое сообщение всем другим процессорам вычисли-тельной системы. Такой канал еще называется каналом с общей шиной.
Взаимодействие в сети характеризуется трафиком T, который может представлять собой совокупность сообщений, полученных участниками вычислений в r-том раунде в установленной модели взаимодействия.
Синхронная модель вычислений
Рассматривается сеть процессоров, функционирование которой синхронизируется общими часами (синхронизатором). Каждое локальное (внутреннее) вычисление соответствует одному моменту времени (одному такту часов). В данной модели отрезок времени между i и i+1 тактами называется раундом при синхронных вычислениях. За один раунд протокола каждый процессор может получать сообщения от любого другого процессора, выполнять локальные (внутренние) вычисления и посылать сообщения всем другим процессорам сети. Имеется входная лента "только-для-чтения", которая первоначально содержит строку Λ (k) (например вида 1k), при этом k является параметром безопасности системы. Каждый процессор имеет ленту случайных значений, конфиденциальную рабочую ленту "только-для-чтения" (первоначально содержащую строку Λ), конфиденциальную входную ленту "только-для-чтения" (первоначально содержащую строку xi), конфиденциальную выходную ленту "только-для-записи" (первоначально содержащую строку Λ) и несколько коммуникационных лент. Между каждой парой процессоров i и j существует конфиденциальный канал связи, посредством которого i посылает безопасным способом сообщение процессору j. Данный канал (коммуникационная лента) исключает запись для i и исключает чтение для j. Каждый процессор i имеет также широковещательный канал, представляющий собой ленту, исключающую запись для i и являющийся каналом "только-для-чтения" для всех остальных процессоров сети.
Предполагается, что в раунде r для каждого процессора i существует однозначно определенное сообщение (возможно пустое), которое распространяет процессор i в этом раунде и для каждой пары процессоров i и j существует единственное сообщение, которое i может безопасным образом послать j в данном раунде. Все каналы являются помеченными так, что каждый получатель сообщения может идентифицировать его отправителя.
Процессор i запускает программу πi, совокупность которых, реализует распределенный алгоритм П. Протоколом работы сети называется n-элементный кортеж P=( π1, π2,.., πn). Протокол называется t-устойчивым, если t процессоров являются сбоящими во время выполнения протокола. Историей процессора i являются: содержание его конфиденциального и общего входа, все распространяемые им сообщения, все сообщения, полученные i по конфиденциальным каналам связи, и все случайные параметрами, сгенерированные процессором i во время работы сети.
Идеальный и реальный сценарии
Для доказуемо конфиденциального вычисления вводятся понятия идеального и реального сценария [10]. В идеальном сценарии дополнительно вводится достоверный процессор (TP-процессор). Процессоры конфиденциально посылают свои входы ТР-процессору, который вычисляет необходимый результат (выход) и также конфиденциально посылает его обратно процессорам сети. Противник может манипулировать с этим результатом (вычислить или изменить его) следующим образом. До начала вычислений он может подкупить один из процессоров и изучить его секретный вход. Основываясь на этой информации, противник может подкупить второй процессор и изучить его секретный вход. Это продолжается до тех пор пока противник не получит всю необходимую для него информацию. Далее у противника есть два основных пути. Он может изменить входы нечестных процессоров. После чего те, вместе с корректными входами честных процессоров, направляют свои новые измененные входы ТР-процессору. По получению от последнего выходов (значения вычисленной функции) противник может приступить к изучению выхода каждого нече-стного процессора. Второй путь заключается в последовательном изучении входов и выходов процессоров, подключая их всякий раз к числу нечестных. В данном случае рассматривается противник, который не только может изучать входы нечестных процессоров, но и менять их, изучать по полученному значению функции входы честных процессоров.
В реальном сценарии не существует ТР-процессора, и все участники вычислений моделируют его поведение посредством выполнения многостороннего интерактивного протокола.
Грубо говоря, считается, что вычисления в действительности (в реальном сценарии) безопасны, если эти вычисления "эквивалентны" вычислениям в идеальном сценарии. Точное определение (формальное определение) понятия эквивалентности в этом контексте является одной из основных проблем в теории конфиденциальных вычислений.
Асинхронная модель вычислений
В данном подразделе рассматривается полностью асинхронная сеть из n процессоров, которые соединены открытыми или конфиденциальными каналами. При этом не существует единых глобальных часов. Любое сообщение в сети может быть задержано независимым образом. В то же время считается, что каждое посланное сообщение обязательно будет получено адресатом. Вопрос о переупорядочивании сообщений не исследуется.
Вычисления в асинхронной модели рассматривается как последовательность шагов. На каждом шаге активизируется один из процессоров. При этом активизация процессора происходит по получении им сообщения. После чего он выполняет внутренние вычисления и возможно выдает сообщения в свои выходные каналы. Порядок шагов определяется Планировщиком (D), неограниченным в вычислительной мощности. Каналы, являющиеся конфиденциальными или открытыми, рассматриваются как частные планировщики (PDj). Информация, известная частному планировщику, есть не что иное как сообщения, посланные от источника сообщений их адресату. В данной модели вычислений каждый их шах рассматривается как раунд при асинхронных вычислениях. Идеальный и реальный сценарии в асинхронной модели
Сценарий в асинхронной модели с ТР-участником заключается в добавлении ТР-процессора в существующую асинхронную сеть при наличии t потенциальных сбоев (сбоящих процессоров). При этом честные процессоры, также как и ТР-процессор не могут ожидать наличия более, чем n-t входов для вычислений с целью получения их выхода, так как t процессоров (сбоящие процессоры) могут никогда не присоединиться к вычислениям.
Асинхронный ТР-сценарий
В начале вычислений процессоры посылают свои входы ТР-процессору. В то же время, существует планировщик D, который доставляет сообщения участников некоторому базовому подмножеству процессоров, мощностью не меньше n-t, обозначаемому как C и являющемуся независимым от входов честных процессоров. ТР-процессор по получению входов - аргументов функции (возможно некорректных) из множества C, предопределенно оценивает значение вычисляемой функции, основываясь на C и входах участников из С. (Здесь для корректности может использоваться следующее предопределенное оценивание: установить входы из C в 0 и вычислить данную функцию). Затем ТР-процессор посылает значение оценочной функции обратно участникам совместно с базовым множеством С. Наконец честные процессоры вычислений выдают то, что они получили от ТР-участника. Нечестные участники выдают значение некоторой независимой функции, информацию о которой они "собирали" в процессе вычислений. Эта информация может состоять из их собственных входов, слу-чайных значений, используемых при вычислениях и значения оценочной функции.
Так же как и в синхронной модели, вычисления в реальной асинхронной модели безопасны, если эти вычисления "эквивалентны" вычислениям в ТР-сценарии.
Далее в соответствии с работой [61] сделаем попытку формализовать понятия полноты и безопасности протокола асинхронных конфиденциальных вычислений.
Безопасность асинхронных вычислений
Для удобства мы унифицируем коалицию нечестных процессоров и планировщика. Это не увеличит мощность противника в ТР-сценарии, так как и нечестные участники, и планировщик имеют неограниченную вычислительную мощность.
Для вектора  =x1,...,x2 и множества
=x1,...,x2 и множества 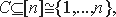 , пусть C определяет вектор , спроектированный на индексы из C. Для подмножества B
, пусть C определяет вектор , спроектированный на индексы из C. Для подмножества B 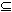 [n] и вектора |B| -vector
[n] и вектора |B| -vector 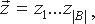 , пусть
, пусть  определяет вектор, полученный из подстановкой входов из B соответствующими входами из
определяет вектор, полученный из подстановкой входов из B соответствующими входами из  . Используя эти определения, можно определить оценочную функцию f с базовым множеством C [n] как
. Используя эти определения, можно определить оценочную функцию f с базовым множеством C [n] как 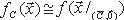
Пусть A - область возможных входов процессоров и пусть R - область случайных входов. ТР-противник это кортеж А=(B,h,c,O), где B [n] - множество нечестных участников, h:A|B| x R - > A |B| -функция подстановки входов, с:A |B| x R -> {C [n] | |C| n-t} - функция выбора базового множест-ва и O:A |B| x R x A - > {0,1}* - функция выхода для нечестных процессоров.
Функции h и O представляют собой программы нечестных процессо-ров, а функция c - комбинацию планировщика и программ нечестных участников вычислений.
Пусть f:An - > A для некоторой области A. Выход функции вычисления f в ТР-сценарии по входу и с ТР-противником А=(B,h,c,O) - это n-vector τ(,A) = τ1(,A)...τn(,A) случайных переменных, удовлетворяющих для каждого 1 i n:
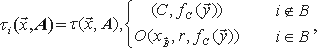
где r объединенный случайный вход нечестных процессоров, C= (B,r) и 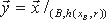
Акцентируем внимание на то, что выход сбоящих процессоров и вы-ход несбоящих процессоров вычисляется на одном и том же значении слу-чайного входа r.
Далее формализуем понятие вычисления "в реальной жизни".
- Пусть B=(B,β) - коалиция нечестных процессоров, где B
 [n] - множество нечестных процессоров и β - их совместная стратегия.
[n] - множество нечестных процессоров и β - их совместная стратегия.
- Пусть πi(,B,D) определяет выход процессора Pi после выполнения протокола πi по входу , с планировщиком D и коалиции B. Пусть также π (,B,D)= π1(,B,D)... πn(,B,D).
Кроме того, пусть f:An - > A для некоторой области A и пусть π - протокол для n процессоров. Будем говорить, что π безопасно t-вычисляет функцию f в асинхронной модели для каждого частного планировщика PD и каждой коалиции B с не более, чем из t нечестных процессоров, если выполняются следующие условия.
Условие завершения (условие полноты). По всем входам все честные процессоры завершают протокол с вероятностью 1.
Условие безопасности. Существует ТР-противник A такой, что для каждого входа векторы τ(,A) и π(,B,D) идентично распределены (эквивалентны).
Конфиденциальное вычисление функции
Общие положения. Для некоторых задач, решаемых в рамках методо-логии конфиденциальных вычислений, достаточно введения определения конфиденциального вычисления функции [67].
Пусть в сети N, состоящей из n процессоров P1,P2,...,Pn со своими секретными входами x1,x2,...,xn, необходимо корректно (т.е. даже при наличии t сбоящих процессоров) вычислить значение функции (y1,y2,...,yn)=f(x1,x2,...,xn) без разглашения информации о секретных аргументах функции, кроме той, информации, которая содержится в вычисленном значении функции.
По аналогии с идеальным и реальным сценариями, приведенными выше, можно ввести понятия "реальное и идеальное вычисление функции f" [67].
Пусть множество входов и выходов обозначается как X и Y соответственно, размерности этих множеств |X| =X и |Y| = μ . Множество случайных параметров, используемых всеми процессорами сети, обозначается через R, размерность - |R| = v. Кроме того, через W обозначим рабочее пространство параметров сети. Через T(r) обозначается трафик в r-раунде, через ti(r) - трафик для процессора i в r-том раунде, r0 и rk - инициализирующий и последний раунды протокола соответственно и r* - заданный неким произ-вольным образом раунд выполнения протокола P.
Пусть функцию f можно представить как композицию d функций (функций от двух аргументов-векторов) 
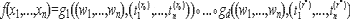
Аргументы функции gη являются рабочими параметрами w1,...,wn уча-стников протокола с трафиком (t1,...,tn) в r раунде. Значения данной функции gη являются аргументами (рабочими параметрами протокола с трафи-ком (t1,...,tn) в r+1 раунде) для функции gη+1.
Из определения следует, что функция f:(Xn RnW)- > Y, где - декартово произведение множеств, реализует:
RnW)- > Y, где - декартово произведение множеств, реализует:
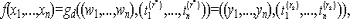
Введем понятие моделирующего устройства M. Здесь можно проследить некоторые аналогии с моделирующей машиной в интерактивных сис-темах доказательств с нулевым разглашением (см., например, [27,29]).
Пусть рΘПрот - распределение вероятностей над множеством историй (трафика Т и случайных параметров) нечестных участников во время выполнения протокола Р.
Моделирующее устройство, взаимодействующее с нечестными участниками, осуществляет свое функционирование в рамках идеального сценария. Моделирующее устройство М создает распределение вероятностей параметров взаимодействия иΘПрот между М и нечестными участниками.
Протокол P конфиденциально вычисляет функцию f(x), если выпол-няются следующие условия:
align="justify"Условие корректности. Для всех несбоящих процессоров Pi функция
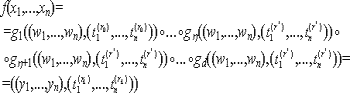
вычисляется с вероятностью ошибки близкой к 0.
Условие конфиденциальности. Для заданной тройки (x,r,w)(Xn RnW) распределения рΘПрот и иΘПрот являются статистически не различимыми.
Функция f, удовлетворяющая условиям предыдущего определения называется конфиденциально вычислимой.
Проверяемые схемы разделения секрета как
конфиденциальное вычисление функции
Для вышеприведенной проверяемой схемы ПРС и обобщенных моделей противника, сбоев, взаимодействия и вычислений синтезируем схему разделения секрета, которая являлась бы работоспособной в протоколах конфиденциальных вычислений.
Рассматривается полностью синхронная сеть взаимодействующих процессоров в условиях проявления By-сбоев. Противник представляется как активный динамический t-противник. Взаимодействие процессоров может осуществляться посредством конфиденциальных каналов связи. Кроме того, существует широковещательный канал связи.
Схема проверяемого разделения секрета, рассматриваемая как схема конфиденциального вычисления функции, значение которой является распределенный среди процессоров проверенный на корректность и затем восстанавливаемый секрет, обозначается как ПРСК.
Пусть сеть N состоит из n процессоров P1,P2,...,Pn-1,Pn, где Pn - дилер Д сети N. Множество секретов обозначается через S, размерность этого мно-жества |S| =l. Множество случайных параметров, используемых всеми процессорами сети, обозначается через R, размерность |R| = v. Через W обозначается рабочее пространство параметров сети.
Требуется вычислить посредством выполнения протокола P=(РзПр,ВсПр) функцию f(x), где f - представляется в виде композиции двух функций g o h. Пусть функция g:(SnRnW) - > W, а функция h:W - > S.
Проверяемая схема разделения секрета ПРСК называется t-устойчивой, если протокол разделения секрета и проверки правильности разделения РзПр и протокол восстановления секрета ВсПр являются t-устойчивыми. Функция f является конфиденциально вычислимой, если конфиденциально вычислимы функции g и h.
t-Устойчивая верифицируемая схема разделения секрета ПРСК - есть пара протоколов РзПр и ВсПр, при реализации которых выполняются следующие условия.
Условие полноты. Пусть событие A1 заключается в выполнении тождества
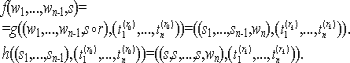
Тогда для любой константы c>0 и для достаточно больших n вероятность Prob(A1)>1-n-c.
Условие корректности. Пусть событие A2 заключается в выполнении тождества
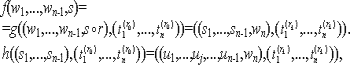
где uj=s для j G и G - разрешенная коалиция участников.
Тогда для любой константы c>0, достаточно больших n, для границы t*< t и любого алгоритма Прот вероятность Prob(A2)-c.
Условие конфиденциальности.
Функция 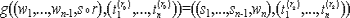 -
-
конфиденциально вычислима.
Функция 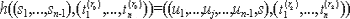 - конфиденциально вычислима.
- конфиденциально вычислима.
Свойство полноты означает, что если все участники протоколов РзПр и ВсПр следуют предопределенным вычислениям, тогда любая коалиция несбоящих процессоров может восстановить секрет s. Свойство корректности означает, что при действиях t-противника Прот, любая разрешенная коалиция из n процессоров сети может корректно разделить, проверить и восстановить секрет. Свойство конфиденциальности вытекает из свойства конфиденциальности функции.
Схема ПРСК
Предлагаемая схема ПРСК, является (n/3-1)-устойчивой и использует схему разделения секрета Шамира.
Пусть n=3t+4 и все вычисления выполняются по модулю большого простого числа p>n. Из теории кодов с исправлением ошибок известно, что если вычисляем полином f степени t+1 в
n-1различных точках i, где i=1,...,n-1, тогда по данной последовательности si=f(i), можно восстановить коэффициенты полинома за время, ограниченное некоторым полиномом, даже если t элементов в последовательности произвольно изменены. Это вариант кода Рида-Соломона, известный как код Берлекампа-Велча. Пусть далее K - параметр безопасности и K/n означает [K/n] .
Протокол РзПр
- Дилер Д выбирает случайный полином f0(x) степени t+1 с единственным условием: f0(0)=s - его секрет. Затем он посылает процессору Pi его долю si=f0(i). Кроме того, он выбирает 2К случайных полиномов f1,...,f2K степени t+1 и посылает процессору Pi значения fj(i) для каждого j=1,...,2К.
- Каждый процессор Pi распространяет (посредством широко-вещательного канала) K/n случайных битов α(i-1)K/n+j, для j=1,...,K/n.
- Дилер Д распространяет полиномы gj=fj+ αjf0 для всех j=1,...,K.
- Процессор Pi проверяет, удовлетворяют ли его значения полиномам, распространяемым дилером. Если он обнаруживает ошибку, он ее декларирует для всех. Если более чем t процессоров сообщают об этом, тогда дилер считается нечестным и все процессоры принимают по умолчанию значение нуля как секрет дилера Д.
- Если менее чем t процессоров сообщили об ошибке, дилер распространяет значения, который он посылал в первом раунде тем процессорам, которые сообщали об ошибке дилера.
- Каждый процессор Pi распространяет K/n случайных битов β(i-1)K/n+j для j=1,...,K/n.
- Дилер Д распространяет полиномы hj=fK+j+ βjf0 для всех j=1,...,K.
- Процессор Pi проверяет, удовлетворяют ли значения, которые он имеет, полиномам, распространяемым дилером Д в 5-м раунде. Если он находит ошибку, он декларирует об этом всем процессорам сети. Если более чем t процессоров сообщают об ошибке, тогда дилер нечестный и все процессоры принимают по умолчанию значение нуля как секрет дилера Д.
Протокол ВсПр
- Каждый процессор Pi выбирает случайный многочлен hi степени t+1 такой, что hi(0)=si - его собственная входная доля секрета. Он посылает процессору Pj значение hi(j).
- Каждый процессор Pi выбирает случайные полиномы pi(x), qi,1(x),...,qi,2K(x) степени t+1 со свободным членом 0 и посылает участнику Pj значения pi(j), qi,1(j),...,qi,2K(j).
- Каждый процессор Pi распространяет K случайных битов
γl,(i-1)K/n+m для l=1,...,n и m=K/n.
- Каждый процессор распространяет следующие полиномы rj=qi,j+ γi,jpi для каждого j=1,...,K.
- Каждый процессор Pi проверяет, что информация процессора Pl, посланная ему в 1-м раунде, соответствует тому, что Pl распространяет в 3-м раунде. Если имеется ошибка или Pl распространяет полином с ненулевым свободным членом, процессор Pi распространяет сообщение badl. Если более чем t процессоров распространяют badl, процессор Pl исключается из сети и все другие процессоры принимают как 0 долю процессора Pl. В противном случае, Pl распространяет информацию, которую он посылал в раунде 1 процессорам, распро-странявшим сообщение badl.
- Каждый процессор Pi распространяет K случайных битов
δl,(i-1)K/n+m для l=1,...,n и m=1,...,K/n.
- Каждый процессор Pi распространяет следующие полиномы rj=qi,K+j+ δi,jpi для каждый j=1,...,K.
- Каждый процессор Pi проверяет, что информация, посланная процессором Pl, в 1-м раунде и распространенная в 5-м раунде, соответствует полиномам процессора Pl, распространенным в 7-м раунде. Если имеется ошибка или Pl распространил полином с ненулевым свободным членом процессор Pi распространяет badlr. Если более чем t процессоров распространили badl, тогда Pl - нечестен и все процессоры принимают его долю, равную 0.
- Каждый процессор Pl распределяет всем другим процессорам следующее значение si+p1(i)+p2(i)+...+p(i), затем интерполирует полином F(x)=f0(x)+p1(x)+p2(x)+...+pn(x) c использованием алгоритма с исправлением ошибок Берлекампа-Велча. Секрет будет равен s=F(0)=f(0).
Заметим, что если дилер Д честен, в конце протокола ВсПр противник, даже зная секрет s и t долей "подкупленных" процессоров, ничего не узнает о долях секрета честных процессоров, так как полином имеет степень t+1 и ему необходимо для интерполяции t +2 точки.
Доказательство безопасности схемы проверяемого
разделения секрета
Теорема 2.3. Схема ПРСК является (n/3-1)-устойчивой.
Доказательство. Пусть
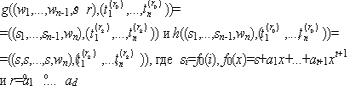
(то есть полином, созданный, с использованием случайного параметра r дилера Д).
При рассмотрении протокола РзПр напомним, что ti - трафик процессора Pi. Ясно, что для всех процессоров Pi, in, функция входа всегда возвращает пустую строку Ii(ti)=ε, так как процессоры не вносят никакие входы в процессе вычисления функции g. Для дилера Д, Д=Pn+1, функция входа немного сложнее. Пусть mi - сообщение, который дилер распространяет процессору Pi в 5-м раунде, если Pi сообщил об ошибке в 4-м раунде или сообщение, которое дилер послал процессору Pi в 1-м раунде, если Pi не заявлял об ошибке. Тогда ID(tD)=f(0), где f=BW(m1,...,mn) - полином степени t+1, следующий из интерполяции Берлекампа-Велча. Функция выхода более простая: Oi(ti)=mi, где mD=ε.
При рассмотрении протокола ВсПр, определим вход и выход функции g. Функция входа Ii для процессора Pi определена как следующая: пусть mi,j - сообщение, посланное процессором Pi процессору Pj в 1-м раунде; Ii(ti)=hi(0), где hi=BW(mi,1,...,mi,n) - многочлен степени t+1, следующий из интерполяции Берлекампа-Велча. Если такого полинома не существует, то Ii(ti)=0. Функция выхода следующая: пусть Mi - сообщение, распространяемая процессором Pi в раунде 9; Oi(ti)=F(0)=s, где F=BW(M1,...,Mn) - полином степени t+1, следующий из интерполяции Берлекампа-Велча.
Далее для доказательства теоремы необходимо доказать выполнения условий полноты, корректности и конфиденциальности.
Полнота. Если дилер Д - честный, исходя из свойств схемы ПРСК, любой несбоящий процессор может восстановить секрет s с вероятностью 1, так как посредством определенных выше функций g и h
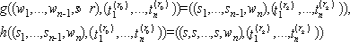
реализуется
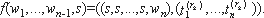
Корректность. Для доказательства теоремы необходимо доказать следующие две леммы.
Лемма 2.3. Пусть функция g имеет вид
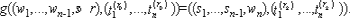
Тогда g корректно вычисляет доли секрета s1,...,sn-1.
Доказательство. Сначала мы должны доказать, что для всех несбоящих процессоров Pi, значение Ii(ti) равно корректному входу. Если дилер Д - честный, то mi=f(i), где f - многочлен степени t+1 со свободным членом s (секретом). Таким образом, ID(tD)=s - если дилер честный. Второе условие корректности состоит в том, что с высокой вероятностью должно выполняться O(t)=g(I(t)). В нашем случае это означает, что с высокой вероятностью значения mi, находящиеся у несбоящих процессоров, должны предназначаться для единственного полинома степени t+1. Это справедливо с вероятностью 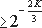 , где не менее
, где не менее 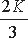 битов выбраны действительно случайно несбоящими процессорами в раундах 2 и 6. Каждый бит представляет запрос, на который нечестный дилер, распределивший "плохие" доли, должен будет ответить правильно в следующем раунде только с вероятностью 1/2 (то есть, если он предскажет правильно значение бита). Следовательно, это и есть граница для вероятности ошибки
битов выбраны действительно случайно несбоящими процессорами в раундах 2 и 6. Каждый бит представляет запрос, на который нечестный дилер, распределивший "плохие" доли, должен будет ответить правильно в следующем раунде только с вероятностью 1/2 (то есть, если он предскажет правильно значение бита). Следовательно, это и есть граница для вероятности ошибки
Лемма 2.4. Пусть функция h имеет вид
Тогда h корректно восстанавливает секрет s.
Доказательство. Понятно, что для всех несбоящих процессоров Ii(ti)=si - корректная доля входа. В этом случае необходимо проверить, что с высокой вероятностью O(t)=h(I,t), а это означает, что необходимо доказать, что
Это равенство не выполняется, если:
-
любой сбоящий процессор Pl "преуспевает" в получении случайного "мусора" вместо значений pl(j) в раунде 2 (в этом случае, сообщения Mi не будут интерполировать полином);
-
процессор Pi распределяет pl(j) в раунде 2 и использует полином со свободным членом, отличным от нуля (в этом случае, Mi восстановит другой секрет).
Так как мы уже знаем, что Pl "преуспевает" в любом из двух описанных случаев с вероятностью 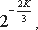 , то, следовательно, имеется не более, чем n/3 сбоящих процессоров и вероятность того, что протокол вычисляет неправильный выход не более, чем n/3(), что для достаточного большого K, является экспоненциально малым.
, то, следовательно, имеется не более, чем n/3 сбоящих процессоров и вероятность того, что протокол вычисляет неправильный выход не более, чем n/3(), что для достаточного большого K, является экспоненциально малым.
Конфиденциальность. Для доказательства теоремы необходимо доказать следующие две леммы.
Лемма 2.5. Пусть функция g имеет вид
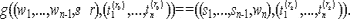
Тогда g конфиденциально вычислима в отношение долей секрета s1,...,sn-1.
Доказательство. Доказательство условия конфиденциальности для функции g заключается в описании работы моделирующего устройства М, которое взаимодействует со сбоящими процессорами (в том числе с нечестным дилером) и создает "почти" такое же распределение вероятностей, которое возникает у сбоящих процессоров во время реального выполнения протокола РзПр.
Необходимо рассмотреть два случая.
Случай A: Дилер нечестен до начала 1-ого раунда. Моделирующее устройство будет следовать только командам процессоров с единственным исключением, что оно будет "передавать" их в какое-либо время противнику в случае "сговора". Так как процессоры не сотрудничают по любому входу, то это сводит моделирование к работе схемы проверяемого разделения секрета с нечестным дилером. Так что моделирование будет неразличимо с точки зрения противника.
Случай B: Дилер честен до начала 1-ого раунда. Моделирующее устройство в 1-м раунде будет создавать случайный "ложный" секрет s' и распределять его процессорам в соответствии с командами протокола с полиномом f'. Если дилер честен в течение всего протокола, тогда он будет выполняться с точки зрения противника как обычный протокол проверяемого разделения секрета с честным дилером. Если дилер нечестен после
1-ого раунда противник и моделирующее устройство получит из оракула истинный вход s дилера. В этом случае моделирующее устройство передает управление от дилера к противнику и меняет полином, используемый для разделения на новый многочлен f" такой, что f"(0)=s и f"(i)=f'(i) для всех процессоров Pi, которые были "подкуплены" противником. Изменения моделирующего устройства в соответствии со случайным полиномом fi, используемым для доказательств с нулевым разглашением (см, например, [6,27,29]) делает их совместимыми с любым широковещательным каналом. Моделирующее устройство может всегда сделать это, так как противник имеет не более t точек полинома степени t+1. Далее моделирующее устройство использует полином f" для работы несбоящих процессоров, все еще находящихся под его управлением. Можно утверждать, что для противника эти вычисления не отличимы от реальных вычислений. Единственный момент, отличающийся от реальных вычислений, - это тот факт, что доли секрета, которые противник получает до того, как дилер становится нечестным, созданы с использованием другого полинома. Но благодаря свойствам полиномов - это не является проблемой для моделирующего устройства, в том случае, если дилер нечестен.
Лемма 2.6. Пусть функция h имеет вид
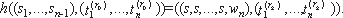
Тогда h конфиденциально вычислима в отношение секрета s.
Доказательство. Работа моделирующего устройства M сводится к следующему.
Описание работы моделирующего устройства M
1. В раунде 1 M моделирует процессор Pi, выбирая случайный полином h'i степени t+1 и посылает h'i(j) к Pj. В этом месте моделирующему устройству позволено получить из оракула выход функции, так что M будет изучать истинный секрет s. Если такой процессор является "подкупленным" противником Прот в конце этого раунда (или в следующих раундах), то и M, и Прот узнают истинную долю sl и M должен изменить полином h'l в соответствии с тем, что h'l(0)=sl, но без изменения значения в точках, уже известных противнику. Моделирующее устройство M может всегда cделать это, потому что противник имеет не более t точек полинома степени t+1.
2-8. В течение раундов 2-8 моделирующее устройство полностью следует явно командам процессоров. Так как все что делают процессоры в этих раундах полностью случайно и нет влияния на их входы, M будет всегда способен создать неразличимые распределения.
9. Моделирующее устройство M выбирает полином g степени t+1 такой, что g(0)=s и затем для каждого процессора Pi, устройство M распространяет g(i)+pi(i)+...+pn(i), где pj - полином, распределенный процессором Pj в течение раундов 2-8 моделирования. Интерполяция Рида-Соломона этих значений даст как результат секрет s. Если процессор Pl является сбоящим в конце этого раунда, тогда и M, и Прот узнают из оракула истинную долю входа sl. Если slg(l), тогда M только изменит значение pl в точке l так, чтобы сделать полную сумму соответствующей такой широковещательной передаче.
Моделирование неотличимо от реального выполнения с точки зрения противника. Фактически, в раундах 2-8 все сообщения случайны и не связаны с входом, так что моделирующее устройство может легко играть роль несбоящих процессоров. В раунде 1 противник просматривает не более t долей реального входа несбоящих процессоров. В соответствии со свойствами схемы разделения секрета Шамира, эти доли полностью случайны и, таким образом, могут моделироваться даже без знания реального входа (как и в случае с моделирующим устройством). В раунде 9 реальная доля распространена "скрытым образом" как случайный "мусор", а это позволит моделирующему устройству распространять сообщение несбоящих процессоров с необходимым распределением даже без знания реального входа.
С доказательством лемм 2.2 - 2.5 доказательство теоремы 2.3 следует считать законченным.
Здесь уместно сделать следующее замечание. Схемы (протоколы) конфиденциальных вычислений являются чрезвычайно сложным объектом исследований. Как видно из сказанного выше, даже описание и доказательство безопасности одного из базовых примитивов в протоколах конфиденциального вычисления функции, - схемы проверяемого разделения секрета являются чрезвычайно громоздкими и сложными. Демонстрация собственно протоколов конфиденциальных вычислений, решающих те или иные теоретические или прикладные задачи, выходит за рамки настоящей работы.
RL-прототип модели синхронных
конфиденциальных вычислений
Зададимся вопросом "Существует ли реальный вычислительный аналог представленной модели синхронных конфиденциальных вычислений ?". Такой вопрос важен и с прикладной, и с содержательной точки зрения.
Рассмотрим многопроцессорную суперЭВМ семейства S-1 на базе сверхбыстродействующих процессоров MARK IIA (MARK V). Такую вычислительную систему назовем RL-прототипом (real-life) модели синхронных конфиденциальных вычислений в реальном сценарии.
Проект семейства систем высокой производительности для военных и научных применений (семейства S-1) является в США частью общей программы развития передовых направлений в области числовой обработки информации. Исходя из целей программы, можно сделать вывод о возможности применения указанной вычислительной системы в автоматизированных системах критических приложений. Поэтому требования высокой надежности и безопасности программного обеспечения систем являются обязательными.
В указанной многопроцессорной системе используются специально разработанные однопроцессорные машины, образующие семейство, то есть имеющие однотипную архитектуру. В систему может входить до 16 однопроцессорных ЭВМ, сравнимых по производительности с наиболее мощными из существующих суперЭВМ. В дополнение к обычному универсальному оборудованию процессоры семейства S-1 оснащены специализированными устройствами, позволяющими выполнять высокоскоростные вычисления в тех прикладных областях, где планируется использование данной многопроцессорной системы. К таким операциям относятся вычисления функций синуса, косинуса, возведения в степень, логарифмирования, операции быстрого преобразования Фурье и фильтрации, операции умножения над матрицами и транспонирования.
Системы семейства S-1 предоставляют в распоряжение пользователя большую сегментированную память с виртуальной адресацией в несколько миллиардов 9-разрядных байтов. Процессоры соединены между собой с помощью матричного переключателя, который обеспечивает прямую связь каждого процессора с каждым блоком памяти (см. рис.2.10). При обращениях к той или иной ячейке памяти процессоры всегда получают последнее записанное в ней значение. Команды выполняются в последовательности: "чтение - операция - запись". С целью повышения быстродействия памяти в составе каждого процессора имеются две кэш-памяти: первая - объемом 64 Кбайт для хранения данных, вторая - объемом 16 Кбайт (с перспективой наращивания). В обоих типах кэш-памяти длина набора составляет 4, а длина строки 64 байта.
В операционной системе Amber, предназначенной для вычислительных систем семейства S-1, предусмотрена программа планировщик, который на нижнем уровне архитектуры системы обеспечивает эффективный механизм оперативного планирования заданий на одном процессоре. Основным правилом планирования здесь является назначения в порядке очереди. На уровне такого одноприоритетного планирования каждое задание выполняется до тех пор, пока не возникает необходимость ожидания какого-либо внешнего события или не истечет выделенный квант процессорного времени. Планировщик высокого уровня осуществляет более сложное планирование, в основу которого положена некоторая общая стратегия. Результатом его работы являются соответствующим образом измененные параметры планировщика нижнего уровня: приоритеты заданий или размеры квантов времени.
Рис. 2.10. RL-прототип модели синхронных
конфиденциальных вычислений
Одной из важнейших особенностей многопроцессорной системы семейства S-1 является наличие общей памяти большой емкости, позволяющей осуществлять широкомасштабный обмен данными между заданиями. Если два задания работают с одним и тем же сегментом памяти, они пользуются его единственной физической копией, в то время как другие области пространства адресов остаются в их собственном владении. Таким образом, задания оказываются защищенными от неосторожных попыток изменить их внутренне состояние. Между двумя заданиями можно установить жесткий режим чтения-записи, когда одному заданию разрешаются операции чтения-записи, а другому только операции чтения из данного сегмента.
Операционная система Amber имеет большие возможности для реконфигурации системы в случае возникновения сбоев (внештатных ситуаций). Если требуется вывести из конфигурации процессор, выполнение на нем приостанавливается и производится их перераспределение на другие процессоры. Когда процессор или память вводятся в рабочую конфигурацию, они становятся обычными ресурсами системы и загружаются по мере необходимости.
Таким образом, можно проследить широкий круг аналогий между моделью конфиденциальных вычислений и ее вычислительным прототипом. В этом случае центральный коммутатор совместно с устройствами памяти можно рассматривать и как широковещательный канал, и как набор конфиденциальных каналов связи между процессорами. Конфиденциальность каналов может рассматриваться в том случае, если существует возможность предотвратить несанкционированный доступ к блокам памяти или хранить и передавать данные в зашифрованном виде. Привязка во времени многопроцессорной системы S-1 осуществляется посредством устройства синхронизации. Параметром безопасности системы может являться длина строки (64-256 Кбайт).
Вычислительная система типа S-1 позволяет осуществлять разработку прототипов распределенных вычислительных систем и исследование характеристик многосторонних протоколов различного типа, как криптографического характера, так и нет. К такой разновидности распределенных вычислений можно отнести следующие протоколы, имеющие, в том числе, и прикладное значение.
- Протоколы византийского соглашения (определение дано выше).
- Протоколы разделения секрета (определение дано выше).
- Протоколы электронного голосования. В таком протоколе должно быть обеспечено три основных условия:
- обеспечения правильности подачи и подсчета голосов;
- обеспечения тайного голосования избирателей;
- обеспечения невозможности срыва выборов или искажения их результатов.
- Протоколы выработки общей случайной строки. Протокол позволяет безопасным образом группе участников, часть из которых являются нечестными, выработать с равномерным распределением вероятностей общую для всех случайную строку. Такой протокол является часто используемым вычислительным примитивом для построения более сложных протоколов распределенных вычислений.
Методы конфиденциальных вычислений могут позволить для многопроцессорных систем проектировать высокозащищенную программно-аппаратную среду для использования в автоматизированных системах критически уязвимых объектов информатизации.
2.4.4. Криптопрограммирование
Криптопрограммирование посредством использования
инкрементальных алгоритмов
Одним из основных инструментов методологии криптопрограммирования являются инкрементальные алгоритмы. Цель инкрементальной криптографии заключается в разработке криптографических алгоритмов обработки электронных данных, обладающих следующим принципиальным свойством. Если алгоритм применяется к электронным данным D для достижения каких-либо их защитных свойств, то применение инкрементального алгоритма к данным D, подвергнувшихся модификации - D`, должно осуществляться быстрее, чем необходимость заново обработать данный документ. В тех приложениях, когда указанные алгоритмы являются, например, алгоритмами шифрования электронных документов или их цифровой подписи, требование повышения эффективности инкрементальных алгоритмов является крайне желательным. Один из основных методов применения инкрементальных алгоритмов заключается в использовании их аутентификационных признаков для антивирусной защиты.
При обработке электронных документов инкрементальными алгоритмами рассматриваются такие операции обработки данных как "вставка" и "стирание" для символьных строк или "cut" - "вырезание и помещение в буфер" и "paste" - "извлечение из буфера и вставка" для текста. Основная задача здесь заключается в разработке эффективных инкрементальных алгоритмов для схем цифровой подписи и схем аутентификации сообщений, поддерживающих вышеупомянутые операции по модификации электронных данных. Такие алгоритмы должны обладать основным качественным свойством, а именно свойством "защиты от вмешательства", что, таким образом, и делает их применимыми для защиты программ от вирусов и других разрушающих программных средств.
Основные криптографические примитивы, такие как шифрование и цифровая подпись имеют фундаментальную теоретическую базу. Во многих работах (см., например, обзор в работе [28]) были даны базовые определения их криптографической стойкости, основанные на обобщенных теоретико-сложностных и теоретико-информационных предположениях. Главная проблема, которая остается и затрудняет использование на практике многих доказуемо стойких теоретических криптоконструкций, заключается в их пространственно-временной неэффективности. Инкрементальность, в этом смысле, является новой мерой эффективности, которая является вполне приемлемой во многих алгоритмических приложениях.
Пусть далее рассматривается процессор, защищенный от физического вмешательства, который имеет ограниченное количество безопасной локальной памяти. Необходимо получить доступ к файлам, находящихся на удаленных (возможно небезопасных) носителях, например, хост-станциях или www-серверах. Компьютерный вирус может атаковать удаленную станцию, и исследовать и изменять содержание удаленной информационной среды (но при этом он не имеет доступа к безопасной локальной памяти процессора). Для защиты файлов от таких вирусов, процессор вычисляет для каждого файла аутентификационный признак, как функцию от самого файла и ключа, который хранится в безопасной локальной памяти.
Внедрение вируса в файл не позволяет ему заново вычислять признак, и при реализации процесса верификации признака, таким образом, обнаружится вторжение вируса. Следует обратить внимание на то, что для корректной верификации аутентификационного признака защищенный процессор должен заново подтвердить подлинность файлов. Ясно, что наиболее привлекательным способом является модернизация аутентификационного признака быстрее, чем необходимость его вычисления заново. Эта проблема особенно сложна в том случае, когда локальная память не достаточно большая для того, чтобы хранить (даже временно) фрагмент файла или когда "слишком дорого" ввести в локальную память полный файл.
Идея инкрементальных алгоритмов, состоит в том, чтобы воспользоваться какими-либо имеющимися преимуществами такой организации программно-аппаратного взаимодействия и найти способы криптографических преобразований над электронными данными D не заново, а, скорее, как получение быстродействующей функции от значений криптографических преобразований над данными из которых D был получен. Когда "изменения" не велики, инкрементальные методы могут дать большие преимущества по эффективности.
Основные элементы инкрементальной криптографии
Примитивы. Инкрементальность можно рассматривать для любого криптографического примитива. В данном случае рассматриваются два из них - цифровая подпись и шифрование. Инкрементальность далее рассматривается, как правило, для "прямых" преобразованиях, а именно для генерации подписи и шифровании, но все рассуждения будут верны и для "сопряженных" преобразований, а именно для верификации подписи и дешифрования.
Операторы модификации. Рассмотрим проблему модификации защищаемого файла в терминах применения фиксированного набора основных операций по модификации электронного документа. Например: замена блока в документе другим; вставка нового блока; удаление старого блока. Операции должны быть достаточно "мощны" для демонстрации реальных модификаций таких как: замена, вставка и удаление. Соответственно также рассматриваются операции "cut" и "paste", например, операции разбиения отдельного документа на два, а затем, вставка двух документов в один.
Инкрементальные алгоритмы. Зафиксируем базовое криптографическое преобразование T (например, цифровая подпись документа с некоторым ключом). Каждой элементарной операции модификации текста (например, вставки) будет соответствовать инкрементальный алгоритм I. На вход этого алгоритма подаются: исходный файл; значения преобразования T на нем; описание модификаций; и возможно соответствующие ключи или другие параметры. Это позволит вычислить значение T для результирующего файла. Основная проблема здесь заключается в проектировании схем обработки файлов, обладающих эффективными инкрементальными алгоритмами. Предположим, что имеется подпись σold для файла Dold и файл D'old, измененный посредством вставки в файл Dold некоторых данных. Необходимо получить подпись путем подписывания строки, состоящей из σold и описания модификаций над документом Dold. Это схема называется схемой, зависящей от истории. Могут иметься приложения, когда такие действия являются приемлемыми. В большинстве же случаев это не желательно, так как делается большое количество изменений и затраты на верификацию подписи пропорциональны числу изменений. В связи с этим размеры подписи растут со временем. Чтобы избежать таких затрат необходимо использовать схемы, свободные от истории или HF-схемы. Все нижеприведенные схемы являются схемами, свободными от истории.
Безопасность. Свойство инкрементальности вводит новые проблемы безопасности и вызывает необходимость новых определений. Рассмотрим случай схем подписи и аутентификации. Разумно предположить, что противник не только имеет доступ к предыдущим подписанным версиям фалов, но также способен выдавать команды на модификацию текста в существующих файлах и получать инкрементальные подписи для измененных файлов. Такая атака на основе выбранного сообщения для инкрементальных алгоритмов подписи может вести к "взлому" используемой схемы подписи, которая не может быть взломана при проведении противником других атак, в тех случаях, когда не используются инкрементальные алгоритмы. Кроме того, в некоторых сценариях, например, при вирусных атаках можно предположить, что противник вмешивается в содержание существующих документов и аутентификационных признаков, полученных посредством схем подписи/аутентификации. Соответственно рассматриваются два определения безопасности: базовое и более сильное понятие безопасности, когда доказывается стойкость защиты от вмешательств.
Секретность инкрементальных схем. Исходя из вышесказанного, появляется новая проблема, которая проявляется в инкрементальном сценарии, а именно - проблема секретности различных версий файлов. Предположим μ - подпись кода М и μ' является подписью слегка измененного кода M'. Тогда, наилучшим вариантом было бы получить такую подпись μ', которая давала бы как можно меньше информации, об оригинальном коде М.
Метод защиты файлов программ посредством
инкрементального алгоритма маркирования
Основные определения. Пусть АУТ(m) - обычный алгоритм аутентификации сообщений и АУТa(m)- функция маркирования сообщения m, индуцированная схемой АУТ с ключом аутентификации a. Пусть ВЕРa(m,β) - соответствующий алгоритм верификации, где β={true, false} - предикат корректности проверки.
Далее будут использоваться деревья поиска и, следовательно, необходимо напомнить, что 2-3-дерево имеет все концевые узлы (листья) на одном и том же самом уровне/высоте (как и в случае сбалансированных двоичных деревьев) и каждая внутренняя вершина имеет или 2, или З дочерних узла [2]. В данном случае 2-3-дерево подобно двоичному дереву является упорядоченным деревом и, таким образом, концевые узлы являются упорядоченными. Пусть Vh - определяет множество всех строк длины не больше h, ассоциированных очевидным способом с вершинами сбалансированного 2-3-дерева высоты h. Маркированное дерево может рассматриваться как функция Т: Vh - >{0,1}*, которая приписывает аутентификационный признак (АП) каждой вершине.
Пусть совокупный аутентификационный признак файла F получен посредством использования 2-З-дерева аутентификационных признаков каждого из блоков файла F=F[1],...,F[l] (далее такое дерево будет называться маркированным деревом). Каждая вершина w ассоциирована с меткой, которая состоит из АП (аутентифицирующих дочерние узлы) и счетчика, представляющего число узлов в поддереве с корнем w.
Алгоритм маркирования. Алгоритм создания 2-3-дерева аутентификационных признаков (алгоритм маркирования) работает следующим образом:
-
для каждого i, пусть T(w)=АУТα(F[i]), где w - i-тый концевой узел;
-
для каждого не - концевого узла w, пусть Т(w)=АУТα((L1,L2,L3),рзм), где Li - метка i-того дочернего узла w (в случае, если w имеет только два дочерних узла, то L3=γ) и рзм - число узлов в поддереве с корнем w);
-
для корня дерева Т(λ)=АУТα((L1,L2,L3),Id,счт), где Id - название документа и счт - соответствующее показание счетчика (связанное с этим документом).
Инкрементальный алгоритм маркирования. Предположим, что файл F, аутентифицированный маркированным деревом, подвергается операции замены, то есть j-тый блок файла F заменен блоком F(σ). Сначала необходимо проверить, что путь от требуемого текущего значения до корня дерева корректен. Для этого необходимо выполнить следующий алгоритм.
Пусть u0,...uh - путь из корня u0=λ к j-тому концевому узлу обозначается как uh. Тогда:
-
проверить, что ВЕРα принимает Т(λ) как корректный АП строки Т(λ)=АУТa((L1,L2,L3),Id,счт), где Id - название документа и счт - текущее значение счетчика (связанного с этим документом);
-
для i=1,...,h-1 проверить, что ВЕРα принимает Т(ui) как корректный АП строки ((L1,L2,L3),рзм), где Li - метка i-того дочернего узла w (в случае, если w имеет только два дочерних узла, то L3=γ) и рзм - число узлов в поддереве с корнем w));
-
проверить, что ВЕРα принимает Т(uh) как корректный АП блока F[j]
.
Если все эти проверки успешны, тогда совокупный АП файла F получается следующим образом:
-
установить Т(uh):=АУТ(F(σ));
-
для i=h-1,...,1 установить Т(ui):=АУТ(Т(ui1),Т(ui2),Т(ui3));
-
установить Т(λ):=АУТ((Т(ui0),Т(ui1),Т(ui1)),Id,счт+1).
Следует подчеркнуть, что значения
Т на всех других вершинах (то есть, не стоящих на пути
u0,...,uh) остаются неизменяемыми.
Следует отметить, что предлагаемая инкрементальная схема маркирования имеет дополнительное свойство, заключающееся в том, что она безопасна даже для противника который может "видеть" как отдельные аутентификационные признаки, так и все маркированное дерево и может даже "вмешиваться" в эти признаки. Для каждого файла, пользователь должен хранить в локальной безопасной памяти ключ x схемы подписи, имя файла и текущее значение счетчика. Всякий раз, когда пользователь хочет проверить целостность файла, он проверяет корректность маркированного дерева открытым образом.
Наиболее эффективным является использование инкрементального алгоритма маркирования для защиты программ, использующих постоянно обновляющие структуры данных, например, файл с исходными данными или итерационно изменяемыми переменными.
2.4.5. Защита программ и забывающее моделирование
на RAM-машинах
Основные положения
В этом разделе рассматриваются теоретические аспекты защиты программ от копирования. Эта задача защиты сводится к задаче эффективного моделирования RAM-машины (машины с произвольным доступом к памяти [2]) посредством забывающей RAM-машины. Следует заметить, что основные результаты по данной тематике (их можно получить на соответствующем личном интернетовском сайте) принадлежат О. Голдрайху и Р. Островски и эти исследования активно продолжаются в настоящее время.
Машина является забывающей, если последовательность операций доступа к ячейкам памяти эквивалентна для любых двух входов с одним и тем же временем выполнения. Например, забывающая машина Тьюринга - это машина, для которой перемещение головок по лентам является идентичным для каждого вычисления и, таким образом, перемещения не зависят от фактического входа.
Необходимо выделить следующую формулировку ключевой задачи изучения программы по особенностям ее работы. "Как можно эффективно моделировать независимую RAM-программу на вероятностной забывающей RAM-машине". В предположении, что односторонние функции существуют, далее показывается, как можно сделать некоторую схему защиты программ стойкой против полиномиально-временного противника, которому позволено изменять содержимое памяти в процессе выполнения программы в динамическом режиме.
Центральный процессор, имитирующий взаимодействие. Неформально, будем говорить, что центральный процессор имитирует взаимодействие с соответствующими зашифрованными программами, если никакой вероятностный полиномиально-временной противник не может различить следующие два случая, когда по данной зашифрованной программе как входу:
-
противник экспериментирует с оригинальным защищенным ЦП, который пытается выполнить зашифрованную программу, используя память;
-
противник экспериментирует с "поддельным" (фальсифицированным) ЦП. Взаимодействия поддельного ЦП с памятью почти идентичны тем, которые оригинальный ЦП имел бы с памятью при выполнении фиксированной фиктивной программы. Выполнение фиктивной программы не зависит по времени от числа шагов реальной программы. Не зависимо от времени поддельный ЦП (некоторым "волшебным" образом) записывает в память тот же самый выход, который подлинный ЦП написал, выполняя "реальную" программу.
При создании ЦП, который имитирует эксперименты, имеются две проблемы. Первая заключается в том, что необходимо скрывать от противника значения, сохраненные и восстановленные из памяти, и предотвращать попытки противника изменять эти значения. Это делается с использованием традиционных криптографических методов (например, методов вероятностного шифрования и аутентификации сообщений). Вторая проблема заключается в необходимости скрывать от противника последовательность адресов, к которым осуществляется доступ в процессе выполнения программы (здесь и далее это определяется как сокрытие модели доступа).
Сокрытие оригинальной модели доступа к памяти - это абсолютно новая проблема и традиционные криптографические методы здесь не применимы. Цель в таком случае состоит в том, чтобы сделать невозможным для противника получить о программе что-либо полезное из модели доступа. В этом случае ЦП не будет выполнять программу обычным способом, однако он заменяет каждый оригинальный цикл "выборки/запоминания" многими циклами "выборки/запоминания". Это будет "путать" противника и предупреждать его от "изучения" оригинальной последовательности операций доступа к памяти (в отличие от фактической последовательности). Следовательно, противник не может улучшить свои способности по восстановлению оригинальной программы.
Ценой, которую необходимо заплатить за защиту программ, таким образом, является быстродействие вычислений. Неформально говоря, затраты на защиту программ определяются как отношение числа шагов выполнения защищенной программы к числу шагов исходного кода программы. Далее показывается, что эти затраты полиномиально связаны с параметром безопасности односторонней функции, что подтверждается следующим тезисом.
Предположим, что односторонние функции существуют и пусть k - параметр безопасности функции. Тогда существует эффективный способ преобразования программ в пары, состоящие из физически защищенного ЦП с k битами внутренней защищенной памяти и соответствующей зашифрованной программы такой, что ЦП имитирует взаимодействие с зашифрованной программой, реализуемое за время, ограниченное poly(k). Кроме того, t команд оригинальной программы выполняются с использованием менее чем за tk0(1) команд зашифрованной программы, а увеличение размера внешней памяти ограничиваются коэффициентом k.
Вышеупомянутый результат доказывается посредством сведения задачи создания ЦП, который нарушает эксперименты по вмешательству, к задаче сокрытия модели доступа. По-существу, последняя задача формулируется как задача моделирования на независимой забывающей RAM-машине (см. ниже).
Моделирование на забывающих RAM-машинах
Для каждой приемлемой модели вычислений существует преобразование независимых машин в эквивалентные забывающие машины (т.е., в забывающие машины, вычисляющие ту же самую функцию). Вопрос заключается в ресурсозатратах для этих преобразований, а именно в определении времени замедления работы забывающей машины. Например, машина Тьюринга с одной лентой может моделироваться посредством забывающей машины Тьюринга с двумя лентами с логарифмическим замедлением времени выполнения. Ниже исследуется подобный процесс, но для модели вычислений с произвольным доступом к памяти (RAM-машины). Основное достоинство RAM-машины - это способность мгновенно получать доступ к произвольным ячейкам памяти. В контексте настоящей работы, приводится следующий основной неформальный результат для RAM-машины.
Пусть RAM(m) означает RAM-машину с m ячейками памяти и доступом к случайному оракулу [13]. Тогда t шагов независимой RAM(m)-программы может моделироваться за менее чем O(t(log2 t)3) шагов на забывающей RAM(m(log2 m)2).
Таким образом, можно увидеть, как провести моделирование независимой RAM-программы на забывающей RAM-машине с полилогарифмическим (от размера памяти) замедлением времени выполнения. В то же время, простой комбинаторный аргумент показывает, что любое забывающее моделирование независимой RAM-машины должно иметь среднее число Ω(lоgt) затрат. В связи с эти приводится следующий аргумент.
Пусть машина RAM(m) - определена как показано выше. Тогда каждое забывающее моделирование RAM(m)-машины должно содержать не менее max{m,(t-1)log m} операций доступа, чтобы смоделировать t шагов оригинальной программы.
Далее рассмотрим сценария наихудшего случая, в котором наблюдатель (или в данном случае противник) активно пытается получить информацию, вмешиваясь в процесс вычислений. Вопрос заключается в том, можно ли гарантировать, что воздействие противника является забывающим по входу. Неформально говоря, моделирование RAM-машины на забывающей RAM-машине является доказуемо защищенным от вмешательства, если моделирование остается забывающим (т.е. не вскрывает какой-либо информации о входе за исключением его длины) даже в случае, когда независимый "мощный" противник исследует и изменяет содержимое памяти. В связи с этим приводится следующий аргумент.
В условиях определения RAM(m)-машины t шагов независимой RAM(m)-программы могут быть промоделированы (доказуемо защищенным от вмешательства способом) менее чем за O(t(log2t)3) шагов на забывающей машине RAM(m(log2m)2).
Необходимо отметить, что вышеприведенные результаты относятся к RAM-машинам с доступом к случайному оракулу. Чтобы получить результаты для более реалистичных моделей вероятностных RAM-машин, необходимо заменить случайный оракул, используемый выше, псевдослучайной функцией. Такие функции существуют в предположении существования односторонних функций с использованием короткого действительно случайно выбранного начального значения.
Модели и определения
Далее рассматривается модель RAM как пара интерактивных машин с ограниченными ресурсами, и даются два базовых понятия: понятие защиты программ и понятие моделирования на забывающей RAM-машине.
RAM-машина как пара интерактивных машин. В данном разделе RAM-машина представляется как две интерактивные машины: центральный процессор (ЦП) и модуль памяти (МП). Задача исследований сводится изучению взаимодействия между этими машинами. Для лучшего понимания необходимо начать с определения интерактивной машины Тьюринга.
Интерактивная машина Тьюринга - многоленточная машина Тьюринга, имеющая следующие ленты:
-
входная лента "только-для-чтения";
-
выходная лента "только-для-записи";
-
рабочая лента "для-записи-и-для-чтения";
-
коммуникационная лента "только-для-чтения";
-
коммуникационная лента "только-для-записи"
.
Под ITM(c,w) обозначается машина Тьюринга с рабочей лентой длины w и коммуникационными лентами, разделенными на блоки c-битной длины, которая функционирует следующим образом. Работа ITM(c,w) на входе у начинается с копирования у в первые |y| ячеек ее рабочей ленты. В случае если |y|>w, выполнение приостанавливается немедленно. В начале каждого раунда, машина читает следующий c-битный блок с коммуникационной ленты "только-для-чтения". После некоторого внутреннего вычисления, использующего рабочую ленту, раунд завершен с записью с битов на коммуникационную ленту "только-для-записи". Работа машины может завершиться в некоторой точке с копированием префикса ее рабочей ленты на выходную ленту машины.
Теперь можно определить ЦП и МП как интерактивные машины Тьюринга, которые взаимодействуют друг с другом, а также можно ассоциировать коммуникационную ленту "только-для-чтения" ЦП с коммуникационной лентой "только-для-записи" МП и наоборот. Кроме того, и ЦП, и МП будут иметь ту же самую длину сообщений, то есть, параметр с, определенный выше. МП будет иметь рабочую ленту размером, экспоненциальным от длины сообщений, в то время как ЦП будет иметь рабочую ленту размером, линейным от длины сообщений. Каждое сообщение может содержать "адрес" на рабочей ленте МП и/или содержимое регистров ЦП.
Далее используем k как параметр, определяющий и длину сообщений, и размер рабочих лент ЦП и МП. Кроме того, длина сообщений будет равна k+2+k', а размер рабочей ленты будет равен 2kk', где k'=O(k).
Для каждого kN определим MEMk как машину IТМ(k+2+O(k),2kO(k)), работающую точно так, как определено выше. Рабочая лента разбивается на 2k слов, каждое размером O(k). После копирования входа на рабочую ленту машина MEMk является машиной, управляемой сообщениями. После получения сообщения (i,a,v), где i{0,1}2{"запомнить","выборка","стоп"}, a{0,1}k и v{0,1}O(k), машина MEMk работает следующим образом.
Если i="запоминание", тогда машина MEMk копирует значение v из текущего сообщения в число а рабочей ленты.
Если i="выборка", тогда машина MEMk посылает сообщение, состоящее из текущего числа а (рабочей ленты).
Если i="стоп", тогда машину MEMk копирует префикс рабочей ленты (как специальный символ) на выходную ленту и останавливается.
Далее, пусть для каждого kN определим CPUk как машину IТМ(k+2+O(k),O(k)), работающую точно так, как определено выше. После копирования входа на свою рабочую ленту, машина CPUk выполняет вычисления за время, ограниченное poly(k), используя рабочую ленту, и посылает сообщение, определенное в этих вычислениях. В следующих раундах CPUk - является машиной, управляемой сообщениями. После получения нового сообщения машина CPUk копирует сообщение на рабочую ленту и, основываясь на вычислениях на рабочей ленте, посылает свое сообщение. Число шагов каждого вычисления на рабочей ленте ограничено фиксированным полиномом от k.
Единственная роль входа ЦП должна заключаться в инициализации регистров ЦП, и этот вход может игнорироваться при последовательном обращении. "Внутреннее" вычисление ЦП в каждом раунде соответствует элементарным операциям над регистрами. Следовательно, число шагов, принимаемых в каждом таком вычислении является фиксированным полиномом от длины регистра (которая равна O(k)). Теперь можно определить RAM-модель вычислений, как совокупность RAMk-машин для каждого k.
Для каждого kN определим машину RAMk как пару (CPUk, MEMk), где ленты "только-для-чтения" машины CPUk совпадают с лентами "только для записи" машины MEMk, а ленты "только-для-записи" машины CPUk совпадают с лентами "только-для-чтения" машины MEMk. Вход RAMk - это пара (s,y), где s - вход (инициализация) для CPUk и у - вход для MEMk. Выход машины RAMk по входу (s,у), обозначаемый как RAMk(s,у), определен как выход MEMk(y) при взаимодействии с CPUk(s).
Для того, чтобы рассматривать RAM-машину как универсальную машину, необходимо разделить вход у машины MEMk на "программу" и "данные". То есть, вход у памяти разделен (специальным символом) на две части, названные программой (обозначенной П) и данными (обозначаемыми x).
Пусть RAMk и s фиксированы и у=(П,х). Определим выход программы П на входных данных х, обозначаемый через П(x) как RAMk(s,у). Определим время выполнения П на данных х, обозначаемое через tП(x), как сумму величины (|у|+|П(x)|) и числа раундов вычисления RAMk(s,у). Определим также размер памяти программы П для данных х, обозначаемый через sП(x) как сумму величины |у| и числа различных адресов, появляющихся в сообщениях, посланных CPUk к MEMk в течение работы RАМk(s,у).
Легко увидеть, что вышеупомянутая формализация непосредственно соответствует модели вычислений с произвольным доступом к памяти. Следовательно, "выполнение П на х" соответствует раундам обмена сообщениями при вычислении RAMk(',(П,х)). Дополнительный член |y| + |П(x)| в tП(x) поясняет время, потраченное при чтении входа и записи выхода, в то время как каждый раунд обмена сообщениями представля-ет собой единственный цикл в традиционной RAM-модели. Член |y| в sП(х) объясняет начальное пространство, взятое по входу.
Дополнения к базовой модели и вероятностные RAM-машины. Приводимые ниже результаты верны для RAM-машин, которые являются вероятностными в очень строгом смысле. А именно ЦП в этих машинах имеет доступ к случайным оракулам. Однако в предположении существования односторонних функций, случайные оракулы могут быть эффективно реализованы посредством псевдослучайных функций.
Для каждого k N определим оракульный CPUk как CPUk с двумя дополнительными лентами, названными оракульными лентами. Одна из этих лент является "только-для-чтения", а другая "только-для-записи". Всякий раз, когда машина входит в специальное состояние вызова оракула, содержимое оракульной ленты "только-для-чтения" изменяется мгновенно (т.е., за единственный шаг) и машина переходит к другому специальному состоянию. Строка, записанная на оракульной ленте "только-для-чтения" между двумя вызовами оракула называется запросом, соответствующим последнему вызову. Будем считать, что CPUk имеет доступ к функции f, если делается запрос q и оракул отвечает и изменяет содержимое оракульной ленты "только-для-чтения" на f(q). Вероятностная машина CPUk - это оракульная машина CPUk с доступом к однородно выбранной функции
f:{0,1}O(k) - > {0,1}.
Для каждого k N определим оракульную RAMk-машину как RAMk-машину, в которой машина CPUk заменена на оракульную CPUk. Скажем, что эта RAMk-машина имеет доступ к функции f, если CPUk имеет доступ к функции f и будем обозначать как RAMkf . Вероятностная RAMk-машина - это RAMk-машина, в которой CPUk заменен вероятностным CPUk. (Други-ми словами, вероятностная RAMk-машина - это оракульная RAMk-машина с доступом к однородно выбранной функции).
Повторные выполнения RAM-машины. Для решения проблемы защи-ты программ необходимо использовать повторные выполнения "одной и той же" RAM-программы на нескольких входах. Задача состоит в том, что RАМ-машина начинает следующее выполнение с рабочими лентами ЦП и МП, имеющих содержимое, идентичное их содержимому при окончании предыдущего выполнения программы.
Для каждого k N , повторные выполнения RAMk-машины на входной последовательности y1,y2,... рассматриваются как последовательность вычислений RAMk-машины, при котором первое вычисление началось с входа y1, когда рабочие ленты и СРUk, и MEMk пусты и i-тое вычисление начинается с входа уi, когда рабочая лента каждой машины (т.е., и СРUk, и MEMk) содержит ту же самую строку, которую она содержала по окончании i-1 вычисления.
Эксперименты с RAM-машиной. Рассматриваются два типа противников. Оба могут неоднократно инициировать работу RAМ-машины на входах по своему выбору. Различия между двумя типами противников состоит в их способности модифицировать коммуникационные ленты ЦП и МП в процессе вычислений. Вмешивающемуся противнику позволено как читать, так и записывать на эти ленты свою информацию (т.е., просматривать и изменять содержание взаимодействия), в то время как невмешивающемуся противнику позволено только читать эти ленты (то есть, только просматривать сообщения). В любом случае не надо позволять противнику иметь те же самые права доступа к рабочей ленте МП, так как содержимое этой ленты полностью определено начальным входом и сообщениями, посланными ЦП. Кроме того, в обоих случаях противник не имеет никакого доступа к внутренним лентам ЦП (т.е., к рабочим и оракульным лентам ЦП).
Для простоты, основное внимание будет уделяться противникам с экспоненциально ограниченным временем выполнения. Кроме того, время выполнения противника ограничено сверху 2n, где n - размер рабочей ленты ЦП. На практике противник будет ограничен по времени некоторым полиномом от длины рабочей ленты ЦП.
Невмешивающийся противник, обозначаемый как ADV является вероятностной машиной, которая на входе k и "шифрованной программе" α, которая имеет следующий доступ к оракульной RAMk-машине. Машина ADV инициирует повторные выполнения RAMk-машины на входах по своему выбору до тех пор, пока общее время выполнения не стане равным 2k. В процессе каждого из этих выполнений, машина ADV имеет доступ "только-для-чтения" к коммуникационным лентам между CPUk и MEMk.
Вмешивающийся противник определяется аналогично невмешивающемуся противнику за исключением того, что в процессе повторных вы-полнений противник имеет доступ для чтения и записи к коммуникацион-ным лентам между CPUk и МЕМk.
Преобразования, защищающие программное обеспечение
Определим компиляторы, которые по данной программе П, произво-дят пару (f,Пf), где f - случайно выбранная функция и Пf - "зашифрованная программа", которая соответствует П и f. Здесь имеется в виду оракульная RAM-машина, которая на входе (Пf,х) и при доступе к оракулу f моделирует выполнение П на данных х так, чтобы это моделирование "защищало бы" оригинальную программу П.
Далее даются определения компиляторов как набора преобразований программ в программно-оракульные пары, которые при выполнении оракульных RAM-программ являются функционально эквивалентными выполнениям оригинальных программ.
Компилятор, обозначаемый через C, является вероятностным отображением, которое по входу целочисленного параметра k и программы П для RAMk возвращает пару (f,Пf) так, чтобы
-
f:{0,1}O(k) - > {0,1} - случайно выбранная функция;
-
|Пf| =O(|П|);
Для k'=k+O(log k) существует оракульная RAMk'-машина такая, что для каждой П, каждой f и каждого x {0,1} инициируется RAMk' на входе (Пf,x) и при доступе к оракулу f обеспечивает П(x).
Оракульная RAMk'-машина отличается от RAMk-машины в том, что RAMk' имеет доступ к оракулу, в то время как RAMk нет. Понятно, что RAMk' имеет большую память, а именно RAMk'-машина состоит из 2k'=poly(k)2k слов, в то время как память RAMk состоит из 2k слов.
Компиляторы, как определено выше, преобразовывают детерминированные программы в "зашифрованные программы", которые выполняются на вероятностных RAM-машинах. Теперь непосредственно обратимся к определениям компилятора, защищающего программное обеспечение.
Оракул спецификации для программы П - это оракул, который на запрос x возвращает тройку (П(x),tП(x),sП(x)).
Отметим, что tП(x) и sП(x) обозначает время выполнения и пространственные размеры программы П на данных x. Далее даются основное определение для задачи защиты программ. В этом определении ADV может рассматриваться как вмешивающийся, так и невмешивающийся противник.
Для данного компилятора C и противника ADV, компилятор C защищает программное обеспечение против противника ADV, если существует вероятностная оракульная (в стандартном смысле) машина М, удовлетворяющая следующим условиям:
-
(М функционирует примерно за то же самое время, как и ADV): Существует полином p(') такой, что для каждой строки α время выполнения М на входе (k', |α|) (и с учетом доступа к случайному оракулу) было ограничено p(k')T, где T обозначает время выполнения ADV при экспериментировании с RAMk' на входе α.
-
(М с доступом к оракулу спецификации обеспечивает выход почти идентичный выходу ADV после экспериментирования с результатами работы компилятора): Для каждой программы П статистическое расстояние между следованием двух распределений вероятностей ограничено 2-k'.
Распределение выхода машины ADV при экспериментировании с RAMkf на входе Пf, где (f,Пf)< - C(П). Отметим, что RAMkf обозначает ин-терактивную пару (CPUk',MEMk'), где CPUk' имеет доступ к оракулу f. Распределение берется над пространством вероятностей, состоящим из всех возможных выборов функции f и всех возможных результатов выработки случайного бита ("подбрасываний монеты") машины ADV с равномерным распределением вероятностей.
Распределение выхода оракульной машины М на входе (k',O( П )) и при доступе к оракулу спецификации для П. Распределение берется над пространством вероятностей состоящим из всех возможных результатов подбрасываний монеты машины М с равномерным распределением вероятностей.
Компилятор C обеспечивает слабую защиту программ, если C защищает программы против любого невмешивающего противника. Компилятор C обеспечивает доказуемую защиту программ от вмешательства, если C защищает программы против любого вмешивающего противника.
Далее будет определяться затраты защиты программ. Необходимо напомнить, что для простоты, мы ограничиваем время выполнения программы П следующим условием: tП(x)> |П| + |x| для всех x.
Пусть C - компилятор и g:N - > N - некоторая целочисленная функция. Затраты компилятора C на большинстве аргументов g, если для каждой П, каждого x {0,1}* и каждой случайно выбранной f требуемое время выполнения RAMk' на входе (Пf,x) и при доступе к оракулу f ограничены сверху g(T)T, где T=tП(x).
Определение забывающей RAM-машины и забывающего моделирования
Необходимо начать с определения модели доступа как последовательности ячеек памяти, к которым ЦП обращается в процессе вычислений. Это определение распространяется также на оракульный ЦП.
Модель доступа, обозначаемая как Аk(y) детерминированной RAMk-машины на входе y - это последовательность (a1,...,ai,...) такая, что для каждого i, i-тое сообщение, посланное CPUk при взаимодействии с MEMk(y) имеет форму (',ai,').
При рассмотрении вероятностных RAM-машин, мы определяем случайную величину, которая для каждой возможной функции f принимает модель доступа, соответствующая вычислениям, в которых RAM-машина имеет доступ к этой функции. В связи с этим дается следующее определение.
Модель доступа, обозначаемая как 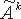 (y) вероятностной RAMk-машины на входе y - это случайная величина, которая принимает значение модели доступа машины RAMk на некотором входе y и при доступе к однородно выбранной функции f.
(y) вероятностной RAMk-машины на входе y - это случайная величина, которая принимает значение модели доступа машины RAMk на некотором входе y и при доступе к однородно выбранной функции f.
Теперь можно перейти к определению забывающей RAM-машины. Мы определяем забывающую RAM-машину как вероятностную RAM-машину, для которой распределение вероятностей последовательности ад-ресов памяти, к которым осуществляется доступ в процессе выполнения программы, зависит только от времени выполнения и не зависит от конкретного частичного входа.
Для каждого k N определим забывающую RAMk-машину как вероятностную RAMk-машину, удовлетворяющую следующему условию. Для каждых двух строк y1 и y2, если |(y1)| и |(y2)| идентично распределены, тогда также идентично распределены (y1) и (y2) .
Интуитивно, последовательность операций доступа к памяти забывающей RAMk-машины не открывает никакой информации относительно входа за исключением значения времени выполнения на этом входе.
Определения RAM-машины и забывающей RAM-машины необходимо для того, чтобы дать точное определение забывающего моделирования независимой RAM-машины посредством забывающей RAM-машины. Определение моделирования в данном случае минимально необходимое, - требуется только, чтобы обе машины вычисляли одну и ту же функцию. Кроме того, необходимо потребовать, чтобы входы, имеющие идентичное время выполнения на оригинальной RAM-машине, сохраняли бы идентичное время выполнения на забывающей RAM-машине. Для простоты, ниже представляется только определение для забывающего моделирования детерминированных RAM-машин.
Для данных машин, - вероятностной RAM'k', и RAMk вероятностная машина RAM'k' моделирует забывающим образом RAMk, если выполняются следующие условия:
-
вероятностная машина RAM'k' моделирует RAMk с вероятностью 1. Другими словами, для каждого входа y и каждого выбора оракульной функции f выход оракула RAM'k' на входе y и при доступе к оракулу f равняется выходу RAMk на входе y.
-
вероятностная машина RAM'k' - является забывающей. Необходимо подчеркнуть, что здесь рассматривается модель доступа RAM'k' на фиксированном входе и случайно выбранной оракульной функции.
Случайная величина, представляющая собой время выполнения веро-ятностной RAM'k' на входе y полностью определена текущим временем RAMk на входе y.
Следовательно, модель доступа при забывающем моделировании (которая описывается случайной величиной, определенной над выбором случайного оракула) имеет распределение, зависящее только от времени выполнения оригинальной машины. А именно, пусть (y) обозначает модель доступа при забывающем моделировании RAMk на входе y. Тогда (y1) и (y2) идентично распределены, если время выполнения RAMk на этих входах (т.е., y1 и y2) идентично.
Теперь мы обратимся к определению затрат забывающего моделирования. Для данных вероятностных машин RAM'k' и RAMk предположим, что вероятностная RAM'k' моделирует забывающим образом вычисления RAMk и путь g:N - > N - есть некоторая целочисленная функция. Тогда затраты на моделирование являются не больше g, если для каждого y требуемое время выполнения RAM'k' на входе y ограничено сверху g(T)T, где T обозначает время выполнения RAMk на входе y.
Моделирование с метками времени. В заключение этого подраздела приводится свойство некоторого RAM-моделирования. Это свойство требует, чтобы при восстановлении значения из ячеек памяти, ЦП "знает" сколько раз содержимое этих ячеек модифицировалось. То есть, для данного адреса МП a и общего числа команд (обозначенных j), выполнение всех команд ЦП "запомнить в ячейку a" может быть эффективно вычислено алгоритмом Q(j,a). Далее рассматривается только моделирование детерминированных RAM-машин.
Для данной оракульной машины RAM'k', машины RAMk предположим, что оракульная RAM'k' с доступом к оракулу f' моделирует вычисления RAM'k'. Тогда моделирование является моделированием с метками времени, если существует O(k')-временной алгоритм Q(',') такой, что выполняется следующее условие. Пусть (i,a,v) - j-тое сообщение, посланное CPU'k' (в процессе повторных выполнений RAM'k'). Тогда, число предыдущих сообщений формы ("запомнить",a,"), посланных CPU'k', равняется точно (j,a). Далее, необходимо обратить запустить алгоритм на Q(j,a) для получения номер версии(a) в раунде j.
Таким образом, чтобы "знать" номер версии любого адреса в некоторый момент времени, достаточно для ЦП сохранить счет числа шагов, которые выполняются. Подчеркнем, что ЦП не мог бы позволить себе хранить номер версии всех адресов памяти, так что проставление меток времени важно для получения доказуемой защиты программ от вмешательства.
Сведение защиты программ к забывающему
моделированию на RAM-машине
Наконец сейчас будет показано, как свести задачу защиты программ к задаче моделирования RAM-машины на забывающей RAM-машине. Эта за-дача заключается в сокрытии модели доступа, полностью игнорируя тот факт, что содержимое памяти и коммуникаций между ЦП и МП доступно для противника. Мы начинаем со сведения задачи достижения слабой за-щиты программ (т.е., защита от невмешивающихся противников) к по-строению забывающего RAM-моделирования. Далее мы сводим задачу за-щиты программ (доказуемой защиты от вмешательства) к построению за-бывающего моделирования с метками времени.
Защита программ от невмешивающихся противников. Напомним, что противник называется невмешивающимся, если все выбранные им входы инициируют выполнение программы на них и он читает содержимое памя-ти и коммуникаций между ЦП и МП при таком выполнении. Без потери общности, достаточно рассматривать противников, которые только читают коммуникационные ленты (так как содержимое ячеек памяти определено входом и коммуникациями между ЦП и МП). При использовании забы-вающего моделирования универсальной RAM-машины остается только скрыть содержимое "области значений" в сообщениях, обмениваемых ме-жду ЦП и МП. Это делается посредством шифрования, которое использует случайный оракул.
Теорема 2.1. Пусть {RAMk}kN - вероятностная RAM-машина, которая выполняет забывающее моделирование универсальной RAM-машины. Кроме того, предположим, что t шагов оригинальной RAM-машины моделируются за менее чем g(t)t шагов забывающей RAM-машины. Тогда существует компилятор, который защищает программы от невмешивающихся противников с затратами не боле O(g(t)).
Доказательство. Информация, доступная невмешивающемуся противнику состоит из сообщений, обмениваемых между ЦП и МП. Напомним, что сообщения от CPUk к MEMk имеют форму (i,a,v), где i{выборка, сохранить, стоп}, a{1,2,...,2k} и v{0,1}O(k), в то время как сообщения от MEMk до CPUk имеют форму v{0,1}O(k). При забывающем моделировании, по определению, "область адресов" (т.е., a) не вскрывает никакой информации относительно входа y=(Пf,x). Просто необходимо устранить возможность, когда "область команд" (т.е., i) обеспечивает любую информацию посредством модификации ЦП так, чтобы всегда имелся доступ к ячейкам памяти при первой выборке. Следовательно, все что осталось должно "зашифровывать" содержимое области значений (т.е., v) так, чтобы ЦП мог восстанавливать оригинальное значение. Идея состоит в том, чтобы выполнить шифрование, используя оракул, доступный ЦП.
Для шифрования CPUk содержит специальный счетчик, обозначаемый счт, инициализированный нулевым значением. Мы модифицируем RAMk добавлением случайного оракула, обозначаемого f. Понятно, что новый случайный оракул может быть объединен со случайным оракулом, используемым при забывающем моделировании. Всякий раз, когда CPUk должен сохранять значение (либо старое значение, которое только читалось, либо новое значение) в памяти MEMk, счетчик счт увеличивается и значение v шифруется посредством пары (v f(счт),счт), где обозначает поразряд-ную операцию "исключающую или". При восстановлении пары (u,j), зашифрованное значение восстанавливается посредством вычисления uf(j). Подчеркнем, что и шифрование, и дешифрование может быть легко вы-полнены, когда имеется доступ к оракулу f.
f(счт),счт), где обозначает поразряд-ную операцию "исключающую или". При восстановлении пары (u,j), зашифрованное значение восстанавливается посредством вычисления uf(j). Подчеркнем, что и шифрование, и дешифрование может быть легко вы-полнены, когда имеется доступ к оракулу f.
Компилятор C, защищающий программное обеспечение, функционирует следующим образом. На входе параметр k и программы П, состоящей из последовательности команд π1,..,πn, компилятор однороно выбирает функцию f и множества Пf=(π1 f(2k+1),2k+1),...,(πn f(2k+n),2k+n).
Так как общее время выполнения машины RAMk во всех экспериментах, инициированных противником, является не более 2k, мы никогда не используем тот же самый аргумент f для двух различных операций шифрования. Это следует из того, что шифрование (которое использует шифр "одноразовый блокнот") абсолютно безопасно (в информационно-теоретическом смысле), и следовательно, противник не получает никакой информации относительно оригинального содержания области значений.
Отметим, что на практике можно заменять случайный оракул на псевдослучайный. Следовательно, результат будет верен только для противников, ограниченных по времени некоторым полиномом. Компилятор на параметре входа k и программе П равномерно выбирает псевдослучайную функцию f. Описание f аппаратно реализовано в CPUk. Следовательно, ЦП способен вычислять f на входах длины k и poly(k)-временной противник может различать поведение этого ЦП от ЦП, описанного в доказательстве теоремы. Следовательно, любой противник, который может выполнять эксперименты по вмешательству за время, ограниченное poly(k), может быть вычислен за время, ограниченное poly(k), с доступом только к оракулу спецификаций. Подобные замечания верны и для следующей теоремы.
Теорема 2.2. Пусть {RAMk}k N - вероятностная RAM-машина, которая выполняет забывающее моделирование (с метками времени) универсальной RAM-машины. Кроме того, предположим, что t шагов оригинальной RAM-машины моделируются меньше, чем за g(t)t шагов забывающей RAM-машины. Тогда существует компилятор, который защищает программное обеспечение от вмешивающихся противников, с затратами не более O(g(t)).
Доказательство. Для защиты от противника, который может изменять содержание сообщений, обмениваемых между ЦП и МП, используются схемы аутентификации. Без потери общности, ограничимся противником, который только изменяет сообщения в направлении от МП к ЦП.
Метка аутентификации будет зависеть от значения, которое хранится в фактической ячейке памяти и от числа предыдущих запомненных команд в этой ячейке. Интуитивно, такая метка аутентификации предотвращает возможность изменять значения, заменять его значением, хранимым в дру-гой ячейке, или заменять его значением, которое было сохранено ранее в той же самой ячейке.
Центральный процессор CPUk, рассмотренный в предыдущей теореме, далее модифицируется следующим образом. Модифицированная машина CPUk имеет доступ к еще одной случайной функции, обозначаемой f. Эта функция может быть объединена с другими. В случае, если CPUk должен сохранить зашифрованное значение v в ячейке памяти он сначала определяет текущий номер версии a. Отметим, что номер версии(a) может быть вычислен CPUk в соответствии с определением моделирования с метками времени. Модифицированная машина CPUk теперь посылает сообщение (сохранить, a, (v,f(a,версия(a),v))) вместо сообщения (сохранить ,a ,v), посланного первоначально. После получения сообщения (v,t) из МП в ответ на запрос (выборка ,a ,'), модифицированная машина CPUk определяет текущее значение номера версия(a) и сравнивает t с f(a, версия(a),v). В случае, если эти два значения равны CPUk работает как и прежде. В противном случае, CPUk немедленно останавливается, предотвращая, таким образом, защиту от вмешательства. Таким образом, попытки изменить сообщения от МП к ЦП будут обнаружены с очень высокой вероятностью.
Решение задачи "Квадратного корня"
Отметим, что тривиальное решение для забывающего моделирования RAM-машины заключается в полном сканировании фактической памяти RAMk-машины для каждой виртуальной операции доступа к памяти (которая должна быть выполнена для оригинальной RAM-машины). Далее описывается первое нетривиальное решение (принадлежащее О. Голдрайху) задачи забывающего моделирования RAMk-машины посредством вероятностной RAM'k'.
Пусть заранее известен объем памяти, обозначаемый m, требуемый для соответствующей программы. Ниже мы показываем, как моделировать такую RAM-машину посредством забывающей RAM-машиной с объемом памяти m+2 таким образом, что t шагов оригинальной RAM-машины моделируются за O(t) шагов на забывающей RAM-машине.
Всякий раз, когда мы говорим о виртуальном доступе к памяти, мы подразумеваем доступ к памяти, требуемый для оригинальной RAM-машины, которая моделируется. Доступ к памяти при забывающем моделировании RAM-машины рассматривается как фактический доступ к памяти. Кроме того, без потери общности, будем понимать, что виртуальная операция доступа состоит из содержимого единственной ячейки памяти (т.е., выборка(i), сопровождаемая командами сохранить(i,') для некоторого i).
таким образом, что t шагов оригинальной RAM-машины моделируются за O(t) шагов на забывающей RAM-машине.
Всякий раз, когда мы говорим о виртуальном доступе к памяти, мы подразумеваем доступ к памяти, требуемый для оригинальной RAM-машины, которая моделируется. Доступ к памяти при забывающем моделировании RAM-машины рассматривается как фактический доступ к памяти. Кроме того, без потери общности, будем понимать, что виртуальная операция доступа состоит из содержимого единственной ячейки памяти (т.е., выборка(i), сопровождаемая командами сохранить(i,') для некоторого i).
Общее описание алгоритма "Квадратного корня". Интуитивно, чтобы полностью скрыть виртуальную модель доступа, мы должны скрыть следующее:
-
к каким виртуальным ячейкам осуществляется доступ и в каком порядке ?
-
сколько раз к конкретной виртуальной ячейке осуществляется доступ (в случае, если к ней обращались)?
В первом случае достаточно каким-либо образом "перемешать" память так, чтобы противник не знал, какой фактический адрес памяти соответствует данному виртуальному адресу. Во втором случае, мы должны убедиться, что к любой ("перемешанной") локальной памяти осуществляется доступ более одного раза. Высокоуровневые шаги моделирования следующие.
Инициализация: Первые m+ слов RAM-моделирования расположены так, чтобы содержать m виртуальных адресов (к которым оригинальная RAM-машина обращается в процессе выполнения) и "фиктивных" слов (см. рис.2.11). Оставшиеся слов распределены так, чтобы обслужить дополнительную ("краткосрочную") память (здесь и далее называемую зщт).
Моделирование шагов RAM-машины: Пока моделирование RAM-машины не остановится, выполнить. (Моделирование выполняется за периоды, каждый из которых состоит из шагов оригинальной/моделируемой машины). В каждом таком периоде выполняются следующие шаги.
Рис. 2.11. Структура данных для решения задачи "квадратного корня"
-
сканируется вся память зщт и проверяется, находится ли содержимое виртуального слова i в одном из слов памяти зщт. Подчеркнем, что здесь мы обращаемся к каждой ячейке памяти зщт в предопределенном порядке независимо от того, находится ли там виртуальное слово, которое нам надо;
-
в случае, если i-тое виртуальное слово не найдено в памяти зщт, мы восстанавливаем его из фактического слова π(i), которое является текущей ячейкой i-того виртуального слова в течение этого периода;
-
в противном случае (т.е., в случае, если i-тое виртуальное слово найдено в памяти зщт), мы получаем доступ к следующему "фиктивному слову" в перемешанной памяти (например, мы обращаемся к фактическому адресу π(m+j), где j - число шагов, моделируемых в текущем периоде);
-
в любом случае модифицируемое значение для i-той виртуальной ячейки записано (забывающим образом) в память зщт посредством сканирования заново всех слов памяти зщт
.
Модификация перемешанной памяти. В конце периода, используются значения, сохраненные в памяти зщт для модификации забывающим образом содержимого перемешанной памяти.
Перед тем как приступить к деталям реализации вышеупомянутых шагов, сделаем несколько замечаний относительно того, почему они составляют забывающее моделирование. Далее покажем, как осуществить доступ к памяти на шаге 1 фиксированным образом а, следовательно, независимо от входа и виртуальной модели доступа оригинальной RAM-машины. Различают два типа операций доступ к памяти, выполненных на шаге 2: полное сканирование памяти зщт (т.е., осуществление доступа к каждому из слов дважды на каждую виртуальную операцию доступа) и осуществление доступа к ячейкам перемешанной памяти во время каждого периода. Для каждых возможных виртуальных операций доступа, последние фактических операций доступа равномерно распределены среди всех подмножеств {1,...,m+}, где распределение вероятностей индуцировано выбором перестановки π. Таким образом, фактический доступ, выполняемый на шаге 2, не открывает никакой информации относительно виртуальных операций доступа, выполняемых в этом шаге. Легко увидеть, что шаг 3 не создает никаких новых трудностей, поскольку он может быть сделан при выполнении операций фактического доступа на шагах 1 и 2 в обратном порядке.
Реализация алгоритма "Квадратного корня"
Сначала, мы покажем, как выбирать и сохранять в ЦП случайную перестановку над {1,2,...,n}, используя O(log n) памяти и случайный оракул. Идея состоит в том, чтобы использовать оракул для проставления меток случайно выбранных элементов и различные целые числа из множества меток, обозначаемого Tn. Перестановка получается посредством сортировки элементов в соответствии с их метками. Если же необходимо получить вероятность коллизии ε (т.е., для нашего приложения ε=2-2k), достаточно иметь метки, выбранные случайно из множества Tn={1,2,...,n2/ε},. Пусть τ: {1,2,...,n}- > Tn - случайная функция, тривиально созданная случайным оракулом. В этом случае π(i)=k, тогда и только тогда, когда π (i) - наименьший элемент в {τ(j):1jn}. В нашем случае n=m+ , а именно n элементов состоят из m виртуальных адресов, связанных с целыми числами 1,...,m и макетов, связанных с (m+1,..., m+}.
Теперь мы имеем дело с задачей забывающей сортировки n элементов посредством меток. Определяющее условие состоит в том, что RAM-машина, которая выполняет сортировку, может хранить только фиксированное число значений одновременно. Идея состоит в том, чтобы "выполнить" сортирующую сеть Батчера, который позволяет сортировать n элементов, выполняя n|log2n| 2 сравнений. Каждое сравнение "выполняется" посредством осуществления доступа к двум соответствующим словам, чтением их содержания и записью этих значений обратно в необходимом порядке. Последовательность операций доступа к памяти, сгенерированной для этой цели фиксирована и не зависит от входа. Отметим, что забывающая RAM-машина может легко вычислять в каждой точке, какое сравнение требуется для реализации следующего. Это следует из простой структуры сети Батчера, которая является однородной относительно логарифмического пространства. Этот алгоритм будет работать, если мы сохраняем метку каждого элемента вместе с самим элементом (виртуальное слово или макет).
Далее мы точно определим, как осуществить доступ к виртуальной ячейке или к макету i. Отметим, что после шага 1 виртуальные ячейки от 1 до m (также как и макеты от m+1 до m+) сортируются согласно их меток (т.е., τ(')). Таким образом, фактический доступ в перемешанную память на шаге 2 выполняется двоичным поиском необходимой метки. А именно, предположим, что мы хотим получить доступ к элементу i {1,...,m+}. Затем, вместо того, чтобы непосредственно достичь фактической ячейки π(i), как предлагается выше, мы выполняем двоичный поиск метки π(i). Этот двоичный поиск заканчивается на фактической ячейке π(i). Помимо этого другие фактические операции доступа, выполняемые во время поиска, полностью определены π(i). Таким образом, эти дополнительные фактические операции доступа не открывают никакой информации наблюдателю (противнику).
Далее описываются две альтернативных реализации шага 3. Первый вариант - реверсия модели доступа на шаге 2. Второй вариант - полная сортировка фактической памяти (то есть, все m+2 слов, включая память зщт) дважды как описано в алгоритме. Первая сортировка выполняется в соответствии с ключом (v,σ ), где v - виртуальный адрес ( - для макетов) и σ {0,1} указывает, исходит ли это слово из памяти зщт или из перемешанной памяти. Таким образом, сортируемый список имеет виртуальные адреса, появляющиеся так, чтобы некоторые из них появляются в двойном экземпляре, один за другим (одна версия из памяти зщт, а другая из перемешанной памяти). Затем, мы сканируем этот список и для каждого виртуального адреса, появляющегося в дубликате, маркируется второе местонахождение (возникающее из перемешанной памяти) также как и макет (т.е., ). В заключение, мы снова полностью сортируем память, но на сей раз виртуальными адресами. Фактически, эта дополнительная сортировка не нужна, поскольку память будет подвергнута пересортировке когда-либо при следующем выполнении шага 1.
- для макетов) и σ {0,1} указывает, исходит ли это слово из памяти зщт или из перемешанной памяти. Таким образом, сортируемый список имеет виртуальные адреса, появляющиеся так, чтобы некоторые из них появляются в двойном экземпляре, один за другим (одна версия из памяти зщт, а другая из перемешанной памяти). Затем, мы сканируем этот список и для каждого виртуального адреса, появляющегося в дубликате, маркируется второе местонахождение (возникающее из перемешанной памяти) также как и макет (т.е., ). В заключение, мы снова полностью сортируем память, но на сей раз виртуальными адресами. Фактически, эта дополнительная сортировка не нужна, поскольку память будет подвергнута пересортировке когда-либо при следующем выполнении шага 1.
Далее следует детальное описание шага 2. Главная идея при этом моделировании состоит в том, чтобы осуществить доступ к каждой виртуальной ячейке в "перемешанной памяти" только в течение каждого шага периода. Как только "осуществиться" доступ к некоторой виртуальной ячейке, необходимо сохранить версию этой виртуальной ячейке в памяти зщт. В течение шага 2, счт содержит число виртуальных операций доступа, моделируемых в текущем периоде. Переменная счт - первоначально содержит 0 и увеличивается, пока достигнет значения . Булева переменная found будет инициироваться, если требуемое значение найдено в памяти зщт. Когда оригинальная RAM-машина осуществляет доступ к i-тому виртуальному слову, забывающая RAM-машина работает следующим образом:
-
(2a) сканирует полностью память зщт и ищет виртуальный адрес i. А именно, для j, пробегающему значения от m+ +1 до m+2, доступ к фактической ячейке памяти j переменная found устанавливается в true и сохраняется в ЦП, если виртуальный адрес i совпадает с фактической ячейкой j. (Переменная found инициализирована в значение false до этого сканирования и остается такой же, если виртуальный адрес i не был найден);
-
(2b) если found=false, тогда забывающая RAM-машина осуществляет доступ к слову с меткой π(i) и сохраняет содержимое в ЦП. Как показано выше, это реализуется посредство двоичного поиска метки π(i);
-
(2c) если found=true, тогда забывающая RAM-машина осуществляет доступ к слову с меткой π(m+счт), которое является "макетом". Это также реализуется посредством двоичного поиска метки π(m+счт);
-
(2d) просматривает полностью память зщт снова и записывает модифицируемое значение i-того виртуального слова в памяти зщт. А именно, для m+ +1 до m+2 доступ к фактической ячейке памяти j запоминается в ее модифицированном значении виртуального адреса i, если адрес j содержит старое значение виртуального адреса i (т.е., found=true), либо found=false и j - первое пустое слово в shelter-е.
-
Значение счт увеличивается на 1.
Подчеркнем, что наблюдатель не может видеть, сохранил ли ЦП значения или нет и, таким образом, не может различать выполнение шага 2b от выполнения шага 2c. Ясно, что шаги 2a и 2d имеют фиксированную модель доступа и, таким образом, не никакая информация, полезная для наблюдателя, не вскрывается.
Анализ алгоритма "Квадратного корня"
Как обсуждалось выше, последовательность фактических операций доступа к памяти забывающей RAM-машины действительно не открывает никакой информации относительно последовательности виртуальных операций доступа к памяти оригинальной RAM-машины. Это действительно так, потому что во время шагов 1, 2a, 2d и 3 фактическая модель доступа фиксирована, в то время как во время шагов 2b и 2c фактические модели доступа неразличимы и "случайны".
Теперь остается вычислить затраты на моделирование (т.е., отношение числа операций доступа, выполненных на забывающей RAM-машиной к числу оригинальных операций доступа). Далее мы вычисляем общее число фактических операций доступа, выполняемых на период (т.е., m+2 виртуальных операций доступа). Число фактических операций доступа на шаге 1 определено числом сравнений в сортирующей сети Батчера, а именно, O(mlog2m). То же самое делается на шаге 3. Что касается шага 2, каждая виртуальная операция доступа выполняется за 2 +log2(m+)=O() фактических операций доступа. Это составляет амортизационные затраты O(log2m). Фактически, вышеупомянутый выбор параметров (то есть, размер памяти зщт) не оптимален.
При использовании памяти зщт размера s, мы получаем амортизационные затраты
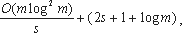
которые минимизированы установкой s=Θ(logm ).
Заключительные замечания
В данном подразделе был представлен компилятор, который трансформировал RAM-программы в эквивалентные программы, которые предотвращают попытки противника выяснить что-либо относительно этих программ при их выполнении. Перенос был выполнен на уровне команд, а именно операции доступа к памяти для каждой команды заменялись последовательностью избыточных операций доступа к памяти. Понятно, что все формулировки и результаты, показанные выше, применимы к любому другому уровню детализации выполнения программ. Например, на уровне "пролистывания" памяти это означало бы, что мы имеем дело с операциями "получить страницу" и "сохранить страницу", как с атомарными (базовыми) командами доступа. Таким образом, единственная операция "доступ к странице" заменяется последовательностью избыточных операций "доступ к странице". В целом исследуется механизм для забывающего доступа к большому количеству незащищенных ячеек памяти при использовании ограниченного защищенного участка памяти. Применение к защите программ было единственным приложением, обсужденным выше, но возможны также и другие приложения.
Одно возможное приложение - это управление распределенными базами данных в сети доверенных сайтов, связанных небезопасными каналами. Например, если в сети сайтов нет ни одного, который содержал бы полную базу данных, значит необходимо распределить всю база данных среди этих сайтов. Пользователи соединяются с сайтами так, чтобы можно было восстановить информацию из базы данных таким образом, чтобы не позволить противнику (который контролирует каналы) изучить какая часть базы данных является наиболее используемой или, вообще, узнать модель доступа любого пользователя. В данном случае не требуется скрывать факт, что запрос к базе данных был выполнен некоторым сайтом в некоторое время, - просто надо скрывать любую информацию в отношении фрагмента необходимых данных. Также принимается предположение о том, что запросы пользователей выполняются "один за другим", а не параллельно. Легко увидеть, что забывающее моделирование RAM-машины может применяться к этому приложению посредством ассоциирования сайтов с ячейками памяти. Роль центрального процессора будет играть сайт, который в текущий момент времени запрашивает данные из базы и информация о моделировании может циркулировать между сайтами забывающим способом. Отметим, что вышеупомянутое приложение отличается из традиционной задачи анализа трафика.
Другое приложение - это задача контроль структуры данных, которая следует из определений самотестирующихся программ, рассматриваемых выше. В этой конструкции желательно сохранить структуру данных при использовании малого количества достоверной памяти. Большая часть структуры данных может сохраняться в незащищенной памяти, где и надо решать задачу защиты от вмешательства противника. Цель состоит в том, как обеспечить механизм контроля целостности данных, которые необходимо сохранять посредством забывающего моделирования RAM-машиной.
2.5. ПОДХОДЫ К ЗАЩИТЕ РАЗРАБАТЫВАЕМЫХ ПРОГРАММ ОТ АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ИНСТРУМЕНТАЛЬНЫМИ СРЕДСТВАМИ ПРОГРАММНЫХ ЗАКЛАДОК
Если целью атаки является нанесение как можно большего вреда, то заманчивой целью для нарушителя, пытающегося внедрить РПС, являются программы, которые используют много различных пользователей, например, компиляторы [45]. Для того, чтобы понять, как это можно сделать рассмотрим следующую упрощенную структуру компилятора, которая дает представление об общих принципах его работы:
compile:
get (line);
translate(line);
Согласно этой структуры компилятор сначала "получает строку", а затем транслирует ее. Конечно, настоящий компилятор устроен намного сложнее, чем эта схема, но этой иллюстрации отдано предпочтение потому, что она в виде некой модели разъясняет фазы лексического анализа трансляции компилятора. Целью РПС будет поиск новых текстовых участков во входных программах, которые будут транслироваться, и вставление в эти участки различного кода. В примере, представленном ниже, компилятор ищет текстовый участок "read_pwd(p)", наличие которого в функции входа в данную компьютерную систему известно, как мы предполагаем, нападающей программе. Когда этот участок будет найден, компилятор не будет транслировать "read_pwd(p)", а вместо этого буде транслировать вставку из РПС, которая может устанавливать "лазейку", которая потом позволит злоумышленнику легко получить доступ к системе. Измененный код компилятора следующий:
compile;
get (line)
if line="readpwd(p)" then
translate (destructive means insertion);
else
translate(line);
fi;
В этом измененном коде, компилятор получает строку, ищет нужный текст, и если находит то транслирует код РПС. Код РПС может включать в себя простую проверку пароля "черного входа" (например, может признаваться правильный пароль "12345" для любого пользователя). Это особенно опасно, поскольку код источника больше не отражает того, что находится в объектном коде и просмотр кода источника (не смотря на то, что проверяется и компилятор) никогда не позволит уловить эту атаку (см рис.2.12).
Заметим, чти на рис.2.12 исходный текст или исполняемый код, включающий только те выражения, которые предлагались его разработчиком назван чистым, а код, содержащий РПС, - грязным. Далее заметим, что если компилируется атакованный компилятор и грязный исполняемы код устанавливается код в какой-либо рабочий директорий (так обычно и бывает), то компилятор с внедренным РПС может быть обнаружен, только если кто-нибудь вернется к источнику компилятора и проверит его (что редко случается). Но настоящий источник может быть восстановлен злоумышленником после компилирования грязного источника и создания грязного исполняемого компилятора. Это, вообще говоря, потом поможет восстановить настоящий исполняемый компилятор при рекомпиляции источника, но это редкий случай.
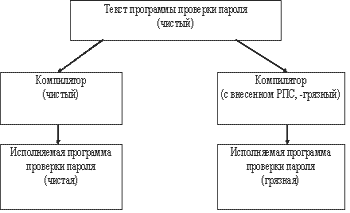
Рис.2.12. Работа компилятора с привнесенным РПС
2.6. МЕТОДЫ ИДЕНТИФИКАЦИИ ПРОГРАММ И ИХ ХАРАКТЕРИСТИК
2.6.1. Идентификация программ по внутренним
характеристикам
Обеспечение безопасности программ, когда их исходные тексты попадают в руки злоумышленников, которые стремятся привнести в код программы РПС до того как программы подвергнутся компиляции, может заключаться в использовании методов идентификации программ и их характеристик.
При установления степени подобия исходной и исследуемой программы целесообразнее всего выбрать критерий, который насколько это возможно, не зависит от маскировок, вносимых в исходный текст программ нарушителем. Для этого необходимо выбрать параметры, характеризующие собственно программу и связанные с такими ее свойствами, которые трудно изменить и которые сохраняются в машинном коде программы. К таким параметрам может относится, например, распределение операторов по тексту программы [15], которое сложно изменить нарушителю, не искажая назначения программы. Такие изменения требуют глубокого понимания текста программы и логики вносимых изменений, что сопряжено с огромной работой по преобразованию программы.
Сначала рассмотрим вопросы анализа подобия последовательностей операторов в программе, поскольку этот подход не чувствителен к поверхностной маскировке, которую мог бы попытаться внести нарушитель, изменяя некоторые атрибуты программы, например, имена переменных, нумерацию строк и т.п. Для этого необходимо написать программу - анализатор, которая будет тестировать исследуемую программу, и выделять операторы, накапливая их в файле как данные, отражающие порядок их использования. Введем для последовательности операторов программы с номером n обозначение seq n. Тогда последовательность операторов для программ 1 и 2 будет обозначаться seq1 и seq2 соответственно. Одна из характеристик последовательности операторов - частота появления отдельного оператора. Анализ последовательности операторов оказывается эффективным в тех случаях, когда нарушитель изменяет или перемещает отдельные части программы, добавляет дополнительные операторы или погружает скопированную программу в некоторый модуль. При таких манипуляциях значительные участки последовательности операторов сохраняются неизменными, так как попытка изменить их равносильна переписыванию программы с сопутствующей ой трудоемкой операцией отладки. Рассмотрим распределение частот появления операторов в программе. Если программа скопирована целиком, но при этом замаскирована, число появлений каждого оператора в копии будет аналогично числу появлений в оригинале. Нарушитель может изменить некоторые операторы и добавить новые, но в целом процент изменений в программе, вероятно, будет мал, и распределение частот появления операторов ожидается одинаковым как для копии, так и для оригинала.
В то же время, если программа (или отдельный программный модуль) включена в большую программу необходимо рассматривать другую характеристику, связанную с сохранением структуры последовательности операторов и определяемую некоторой функцией. Такое подобие структур может быть выражена как максимум взаимной корреляцией функций двух программ, положение которого зависит от размещения модуля в программе. Интересен вопрос, будет ли заимствованная программа, откомпилированная в машинный код, обеспечивать достаточное значение корреляционной функции, чтобы выделить модуль, включенный в состав программы, а также будет ли взаимная корреляционная функция машинного кода соответствовать взаимной корреляционной функции исходной программы на языке высокого уровня.
Другая характеристика программы - автокорреляционная функция, определяющая меру соответствия, с которой одни и те же последовательности операторов повторяются в самой программе. По всей видимости, корреляционная функция должна быть чувствительна к добавлению, удалению или перемещению операторов, чем гистограмма частот появления операторов в программе, поскольку при сокращении последовательности значение корреляционной может существенно уменьшаться.
2.6.2. Способы оценки подобия целевой и исследуемой программ с точки зрения наличия программных дефектов
Частоту появления операторов в программе можно изобразить в виде гистограммы. Для этого достаточно написать подпрограмму, которая будет подсчитывать каждое появление операторов в последовательности зафиксированных операторов программы. На рис.2.13 приведена гистограмма операторов для информационно - поисковой системы (ИПС) [15]; на абсциссе графика отмечено количество возможных операторов интерпретатора языка, используемого в этих текстах. Было выявлено [15], что некоторые операторы очень часто встречаются в программах различного назначения, некоторые редко, а некоторые вообще не встречаются. Для сравнения на рис.2.14 приведена гистограмма для программы редактирования текстов (РТ) [15], которая отличается от гистограммы на рис.2.13.
Повторяемость некоторых операторов делает степень подобия программ визуально видимой, особенно для программ с одинаковым функциональным назначением, поскольку целевая направленность часто определяет и выбор операторов. Глаз плохо различает относительные значения амплитуд на различных гистограммах, поэтому удобнее изображать частоту появления операторов в одной программе в зависимости от частоты появления в другой. В этом случае для программ одного вида подобия точки будут размещаться на биссектрисе первого квадранта под углом 45o . Если программы существенно различаются по частоте вхождения операторов в последовательности операторов, тогда точки будут иметь существенный разброс.
Визуальное восприятие можно выразить математически, используя понятие корреляции. Простую меру оценки подобия можно получить, подсчитывая для каждого оператора с номером n среднее значение частоты его появления Dn в каждой программе. Математически эта мера подобия An для одного оператора записывается в виде
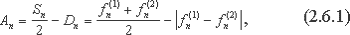
где fn(1),fn(1) - частоты появления оператора с номером n в программах 1 и 2 соответственно; Sn средняя сумма частот появления операторов с номером n в обеих программах; Dn - разность между частотами появления оператора с номером n в программах 1 и 2.
Рис.2.13. Гистограмма частоты появления операторов в программе для информационно-поисковой системы
Рис.2.13. Гистограмма частоты появления операторов в программе для редакторов текста
Мера для всей последовательности операторов получается путем суммирования по всем операторам и нормировки (чтобы снять зависимость от длины программы, сумму делят на полное число операторов в обеих программах). Такая мера подобия A(1,2) для программ 1 и 2 имеет вид:
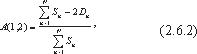
где N - число операторов в языке.
Если частота появления операторов в обеих программах одинакова, мера подобия A(1,2)=1, если операторы, присутствующие в программах, образуют пересекающие множества A(1,2)=-1. Для рассмотренных последовательностей операторов мера подобия равна A(ИПС,РТ)=-0,8. Статистическая формула для корреляции имеет вид:
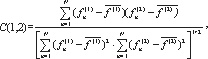
где  - средние значения частот появления всех операторов в программах 1 и 2 соответственно.
- средние значения частот появления всех операторов в программах 1 и 2 соответственно.
Значения коэффициентов корреляции, вычисленных по формуле (2.6.2) всегда находятся в пределах от 0 до 1. Если программы имеют почти один и тот же вид подобия коэффициент корреляции близок к 1, в случае вычисления коэффициента корреляции для программ ИПС и РТ коэффициент корреляции равен C(ИПС,РТ)=0,56.
Вклад в значение коэффициента корреляции частоты появления операторов зависит от популярности применения некоторых операторов в программах разного типа. Этот вклад приводит к большему значению коэффициента корреляции по сравнению с мерой подобия. Это означает, что пороговое значение коэффициента корреляции при оценке подобия программ должен быть увеличен или, наоборот, соответствующие измерения должны быть скорректированы на величину, учитывающую степень подобия программ.
Распределение частот появления операторов наиболее полезно при сравнении двух программ, поскольку не зависит от порядка следования программ. Однако оно мало пригодно, когда программа встроена в программный продукт в сочетании с другими программными модулями, частотный спектр операторов которых может его поглотить. Для выявления присутствия модулей в большой программе более удобны коэффициенты взаимной корреляции.
Взаимная корреляция может быть использована для оценки взаимосвязи операторов в различных точках программы. Сравнивая последовательности операторов двух программ, можно достаточно просто проверить взаимную корреляцию операторов по их местоположению в этих последовательностях. Каждый раз, когда в последовательностях встречаются одинаковые операторы, это событие фиксируется и их общее число суммируется. В том случае, когда одна программа короче другой, более короткая продлевается циклическим повтором. Если обе программы идентичны, отношение числа зафиксированных операторов к общему числу операторов в программе равно 1.
Прямая корреляция между элементами множества не является оптимальной мерой, поскольку фоновая корреляция, обусловленная случайностью, может оказаться очень высокой, и поэтому необходимо переходить от анализа отдельных элементов к анализу групп элементов. Улучшенную корреляцию можно получить, если рассматривать группу элементов. Поэтому при поиске в некоторой последовательности операторов совпадающих элементов следует проверять, является следующий элемент совпадающим, и если это так, то совпадение фиксируется и этот процесс продолжается до окончания сравниваемой последовательности. Если последовательность имеет длину n, объем выборки, отнесенный к первому элементу, увеличивается с 1 до n.
Расчет корреляции (которая в данном случае называется взвешенной взаимной корреляцией) продолжается путем перехода к следующему (второму) элементу последовательности. В этом случае соответствующая выборка увеличивается с 2 до n-1.
Затруднения, связанные с использованием метода простой корреляции для последовательностей машинных команд, состоят в определении длины последовательности, поскольку длина должна быть различна для разных операторов высокого уровня. Метод взвешенной корреляции, когда устанавливается высокий порог повторяемости, решает эту проблему, поскольку, если и теперь отмечаются совпадающие последовательности, то весьма вероятно, что последовательность действительно выявляет совпадающие операторы языка высокого уровня, а случайные совпадения, имеющие корреляцию ниже установленного порога, во внимание не принимаются. Выше мы предполагали, что программы обработаны одним и тем же компилятором. В то случае, когда компилятор не известен, возможно, следует провести тестирование с различными компиляторами, пока корреляция не будет выявлена.
Для анализа корреляции внутри самой программы вводится автокорреляционная функция. Для этого необходимо воспользоваться подпрограммами для определения взаимных корреляций, если в качестве двух тестовых использовать одну и ту же последовательность. Автокорреляция представляет значительный интерес, поскольку дает некоторую числовую характеристику программы. По всей вероятности автокорреляционные функции различного типа можно использовать и тестировании программ на технологическую безопасность, когда разработанную программу еще не с чем сравнивать на подобие с целью обнаружения программных дефектов.
Таким образом, программы имеют целую иерархию структур, которые могут быть выявлены, измерены и использованы в качестве характеристик последовательности данных. При этом в ходе тестирования, измерения не должны зависеть от типа данных, хотя данные, имеющие структуру программы, должны обладать специфическими параметрами, позволяющими указать меру распознавания программы. Поэтому указанные методы позволяют в определенной мере выявить те изменения в программе, которые вносятся нарушителем либо в результате преднамеренной маскировки, либо преобразованием некоторых функций программы, либо включением модуля, характеристики которого отличаются от характеристик программы, а также позволяют оценить степень обеспечения безопасности программ при внесении программных закладок.
Оглавление Вперед



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС