Методы сортировки и поиска
С.Д. Кузнецов
- Введение
- 1. Типы и структуры данных
- 1.1. Понятие типа данных
- 1.2. Встроенные типы данных
- 1.3. Уточняемые типы данных
- 1.4. Перечисляемые типы данных
- 1.5. Конструируемые типы данных
- 1.6. Указатели
- 1.7. Динамическое распределение памяти и списки
- 1.8. Абстрактные (определяемые пользователями) типы данных
- 1.9. Типы и структуры данных, применяемые в реляционных базах данных
- 1.10. Типы и структуры данных, применяемые в объектно-реляционных базах данных
- 2. Методы внутренней сортировки
- 3. Методы внешней сортировки
- 4. Методы поиска в основной памяти
- 5. Методы поиска во внешней памяти
4. Методы поиска в основной памяти
В этой части книги будут обсуждаться структуры данных в основной памяти и методы их использования, предназначенные для поиска данных в соответствии со значениями их ключей. Эта задача является не менее распространенной в программировании, чем внутренняя сортировка данных.
Главным образом, распространены два подхода - поиск в динамических древовидных структурах и поиск в таблицах на основе хэширования. Рассмотрению разновидностей этих подходов и посвящены следующие два раздела.
Заметим, что мы намеренно выделили в отдельную часть структуры данных и методы поиска данных во внешней памяти. Несмотря на использование того же набора терминов (деревья и хэширование) поиск во внешней памяти и критерии оценки эффективности алгоритмов существенно отличаются от тех, которые применимы в случае расположения данных в основной памяти.
4.1. Методы поиска в основной памяти на основе деревьев
Понятия, связанные с деревьями, широко известны и интуитивно понятны. Тем не менее, для однозначного понимания содержимого этого раздела (и соответствующего раздела следующей части курса) мы приведем несколько не слишком формальных определений и примеров.
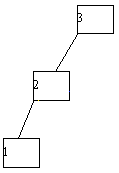
Существует несколько возможных определений дерева. Например, с точки зрения теории графов деревом часто называют неориентированный граф с выделенной вершиной (корнем), который не содержит циклов. Нас будут интересовать не произвольные графы, а только ориентированные деревья, причем с точки зрения программистов. Поэтому мы используем следующее рекурсивное определение: дерево R с базовым типом T - это либо (a) пустое дерево (не содержащее ни одной вершины), либо (b) некоторая вершина типа T (корень дерева) с конечным (возможно, нулевым) числом связанных с ней деревьев с базовым типом T (эти деревья называются поддеревьями дерева R). Из этого определения, в частности, следует, что однонаправленный список (рисунок 4.1) является деревом.
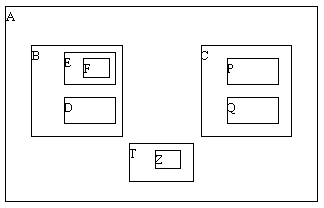
Рис. 4.1.
Деревья можно представлять по-разному (это всего лишь однородная иерархическая структура). Например, на рисунках 4.1 и 4.2 показаны два разных способа представления одного и того же дерева, у которого базовый тип содержит множество букв латинского алфавита. Сразу заметим, что графовое представление на рисунке 4.2 больше соответствует специфике программирования.
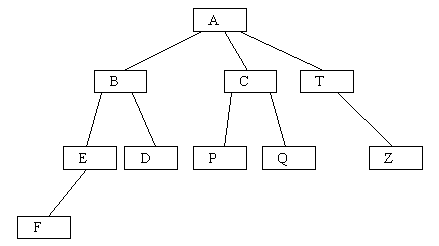
Рис.4.2.
Придерживаясь естественной для графового представления терминологии, мы будем называть связи между поддеревьями ветвями, а корень каждого поддерева - вершиной. Упорядоченным деревом называется такое, у которого ветви, исходящие из каждой вершины, упорядочены. Например, два упорядоченных дерева на рисунке 4.3 различаются.
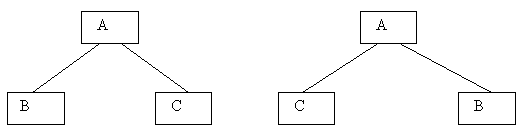
Рис.4.3.
По определению, корень дерева находится на уровне 0, а все вершины дерева, непосредственно связанные с вершиной уровня i, находятся на уровне i+1. Вершина x уровня i, непосредственно связанная с вершиной y уровня i+1, называется непосредственным предком (или родителем) вершины y. Такая вершина y соответственно называется непосредственным потомком (или сыном) вершины x. Вершина без непосредственных потомков называется листовой (или терминальной), нелистовые вершины называются внутренними. Под степенью внутренней вершины понимается число ее непосредственных потомков. Если все вершины имеют одну и ту же степень, то она полагается степенью дерева. На самом деле, всегда можно добиться того, чтобы любая вершина дерева имела одну и ту же степень путем добавления специальных вершин в тех точках, где отсутствуют поддеревья (рисунок 4.4).
Число вершин (или ветвей), которые нужно пройти от корня к вершине x, называется длиной пути к вершине x. Высотой (или глубиной) дерева будем называть максимальную из длин путей от корня до вершин дерева.
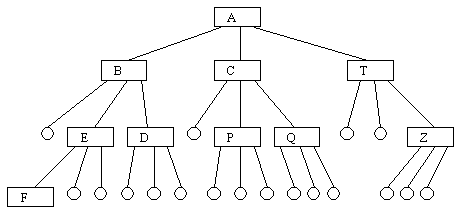
Рис. 4.4.
4.1.1. Двоичные деревья
Для организации поиска в основной памяти особое значение имеют упорядоченные двоичные (бинарные) деревья (как, например, на рисунке 4.3). В каждом таком дереве естественно определяются левое и правое поддеревья. Двоичное дерево называется идеально сбалансированным, если число вершин в его левом и правом поддеревьях отличается не более, чем на 1 (легко видеть, что при соблюдении этого условия длины пути до любой листовой вершины дерева отличаются не больше, чем на 1). Примеры идеально сбалансированных деревьев показаны на рисунке 4.5.
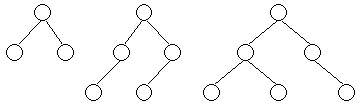
Рис. 4.5.
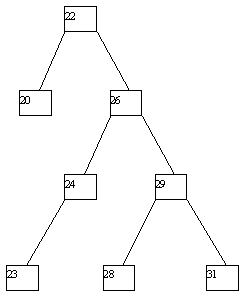
Рис. 4.6.
Двоичные деревья обычно представляются как динамические структуры (см. раздел 1.7) с базовым типом записи T, в число полей которого входят два указателя на переменные типа T.
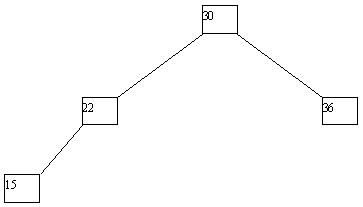
При использовании в целях поиска элементов данных по значению уникального ключа применяются двоичные деревья поиска, обладающие тем свойством, что для любой вершины дерева значение ее ключа больше значения ключа любой вершины ее левого поддерева и меньше значения ключа любой вершины правого поддерева (рисунок 4.6). Для поиска заданного ключа в дереве поиска достаточно пройти по одному пути от корня до (возможно, листовой) вершины (рисунок 4.7). Высота идеально сбалансированного двоичного дерева с n вершинами не превышает log₂ n, поэтому при поиске в таком дереве требуется не более log₂ n + 1 сравнений (рисунок 4.8).
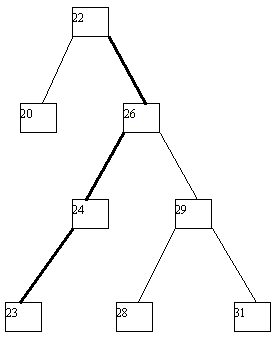
Рис. 4.7. Путь поиска ключа по значению “23”
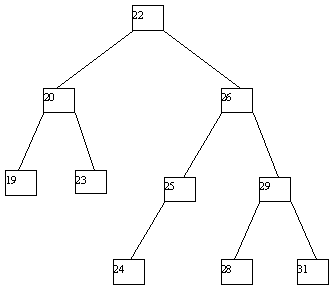
Рис. 4.8. Идеально сбалансированное двоичное дерево
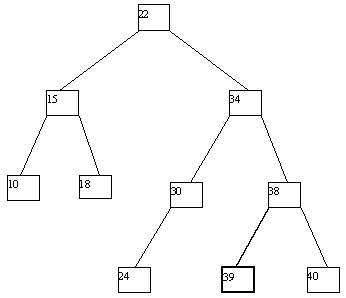
Применение деревьев как объектов с динамической структурой особенно полезно, если допускать выполнение не только операции поиска по значению ключа, но и операций включения новых и исключения существующих ключей. Если не принимать во внимание потенциальное желание поддерживать идеальную балансировку дерева, то процедуры включения и исключения ключей очень просты. Для включения в дерево вершины с новым ключом x по общим правилам поиска ищется листовая вершина, в которой находился бы этот ключ, если бы он входил в дерево. Возможны две ситуации: (a) такая вершина не существует; (b) вершина существует и уже занята, т.е. содержит некоторый ключ y. В первой ситуации создается недостающая вершина, и в нее заносится значение ключа x. Во второй ситуации после включения ключа x эта вершина в любом случае становится внутренней, причем если x > y, то ключ x заносится в новую листовую вершину - правого сына y, а если x < y - то в левую. Четыре потенциально возможных случая проиллюстрированы на рисунке 4.9.
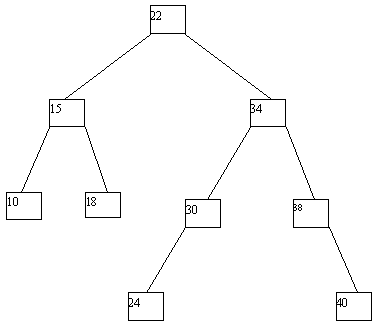
(a)
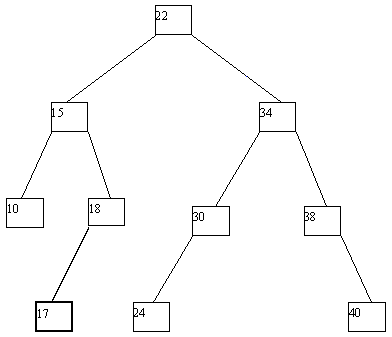
(b)
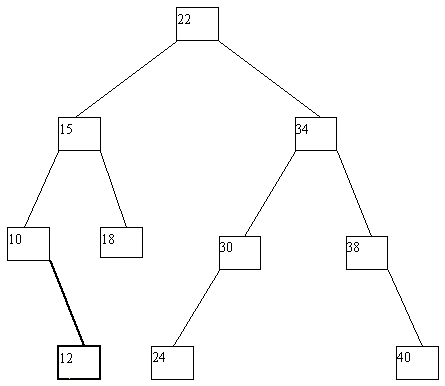
(c)
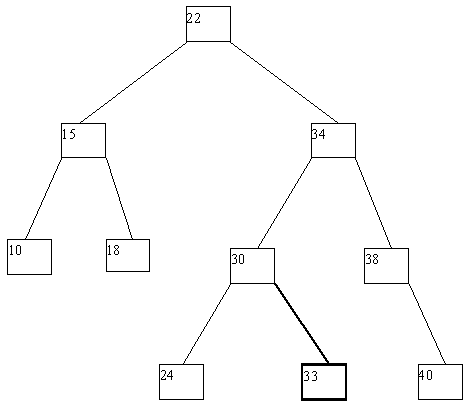
(d)
(e)
Рис. 4.9.
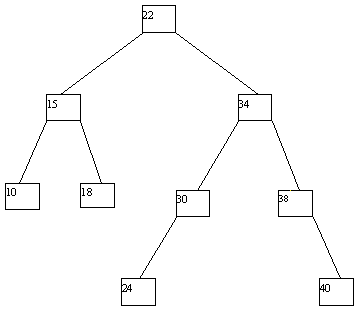
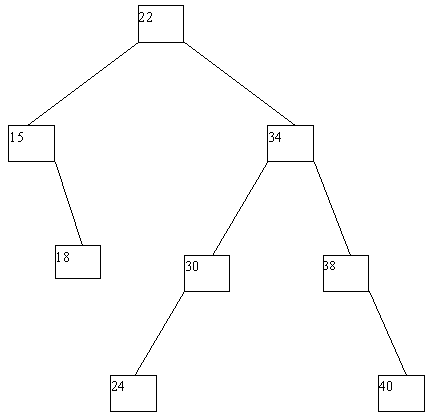
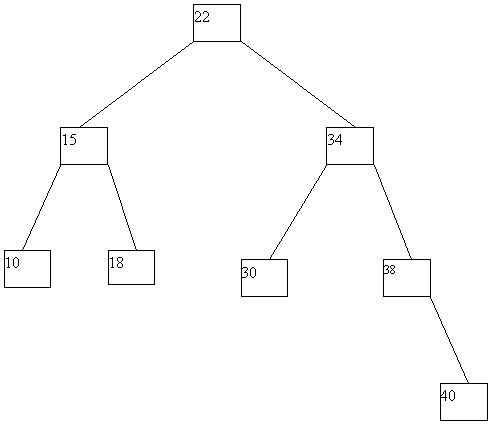
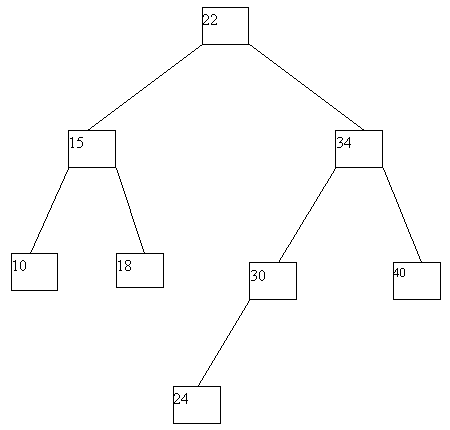
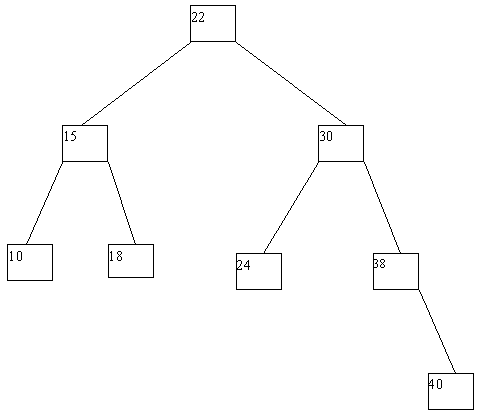
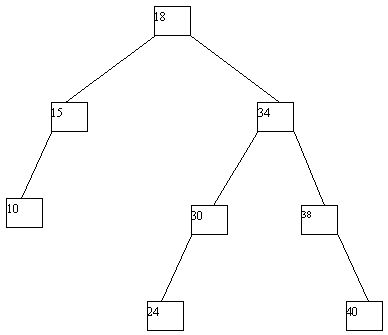
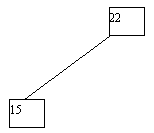
При выполнении исключения ключа из дерева также прежде всего выполняется поиск ключа. Если ключ обнаруживается, то возможны следующие случаи: (a) ключ содержится в листовой вершине, у вершины-отца которой имеются два сына; (b) ключ содержится в листовой вершине, являющей единственным сыном своего отца; (c) ключ содержится во внутренней вершине, имеющей только левого или только правого сына; (d) ключ содержится во внутренней вершине, имеющей и левого, и правого сыновей. В случае (a) соответствующая листовая вершина ликвидируется, а у ее отца остается только один сын. В случае (b) листовая вершина ликвидируется, а ее отец становится новой листовой вершиной. В случае (c) внутренняя вершина ликвидируется, и ее место занимает единственный сын (он может быть внутренней или листовой вершиной. В случае (d) внутренняя вершина ликвидируется, и заменяется на листовую или внутреннюю вершину, достигаемую по самому правому пути от левого сына внутренней вершины. Эта вершина наследует левого и правого сыновей ликвидируемой вершины. Возможные варианты иллюстрируются на рисунке 4.10.
(a)
(b)
(c)
(d)
(e)
(f)
Рис. 4.10. Исключение ключа из двоичного дерева
Поддержка дерева поиска в идеально сбалансированном состоянии требует существенного усложнения (с соответствующим увеличением накладных расходов) операций включения и исключения ключей. Кроме того, как показано в книге Вирта, при равномерном распределении значений включаемых и исключаемых ключей использование идеально сбалансированных деревьев поиска дает выигрыш не более 30% (имеется в виду число сравнений, требующихся при поиске). Поэтому на практике идеально сбалансированные деревья поиска используются крайне редко.
4.1.2. Сбалансированные двоичные деревья
Как видно из содержимого предыдущего подраздела, идеально сбалансированные деревья представляют, в большей степени, чисто теоретический интерес, поскольку поддержание идеальной сбалансированности требует слишком больших накладных расходов. В 1962 г. советские математики Адельсон-Вельский и Ландис предложили менее строгое определение сбалансированности деревьев, которое в достаточной степени обеспечивает возможности использования сбалансированных деревьев при существенно меньших расходах на поддержание сбалансированности. Такие деревья принято называть АВЛ-деревьями (в соответствии с именами их первооткрывателей).
По определению, двоичное дерево называется сбалансированным (или АВЛ) деревом в том и только в том случае, когда высоты двух поддеревьев каждой из вершин дерева отличаются не более, чем на единицу. При использовании деревьев, соответствующих этому определению, обеспечивается простая процедура балансировки при том, что средняя длина поиска составляет O(log n), т.е. практически не отличается от длины поиска в идеально сбалансированных деревьях. Как доказали Адельсон-Вельский и Ландис, глубина АВЛ-дерева не более чем на 45% превышает глубину аналогичного идеально сбалансированного дерева.
Чтобы понять, как устроены "самые плохие" АВЛ-деревья, попробуем построить сбалансированное дерево с высотой h, содержащее минимальное число вершин. Обозначим такое дерево через Th. Понятно, что T0 - это пустое дерево, а T1 - дерево с одной вершиной. Дерево Th строится путем добавления к корню двух поддеревьев типа T(h-1). Одно из таких поддеревьев должно иметь высоту h-1, а другое может иметь глубину h-2. Такие "плохо" сбалансированные деревья называются деревьями Фибоначчи (поскольку принцип их построения напоминает принцип построения чисел Фибоначчи) и определяются рекурсивно следующим образом:
- (a) пустое дерево есть дерево Фибоначчи высоты 0;
- (b) единственная вершина есть дерево Фибоначчи высоты 1;
- (c) если T(h-1) и T(h-2) являются деревьями Фибоначчи высотой h-1 и h-2 соответственно, а x - новый корень дерева, то Th = <T(h-1), x, T(h-2)> есть дерево Фибоначчи высотой h;
- (d) другие деревья Фибоначчи не существуют.
Примеры деревьев Фибоначчи высотой 2, 3 и 4 показаны на рисунке 4.11.
(а) Дерево Фибоначчи высотой 2
(b) Дерево Фибоначчи высотой 3

( c ) Дерево Фибоначчи высотой 4
Рис. 4.11. Примеры деревьев Фибоначчи
Число вершин в дереве Th определяется из следующего рекуррентного соотношения:
N0 = 0; N1 = 1; Nh = N(h-1) +1 + N(h-2)
Эти числа определяют число вершин в АВЛ-дереве в худшем случае.
Рассмотрим, как можно поддерживать балансировку АВЛ-дерева при выполнении операций включения и исключения ключей. Начнем с операции включения. Пусть рассматриваемое дерево состоит из корневой вершины r и левого (L) и правого (R) поддеревьев. Будем обозначать через hl высоту L, а через hr - высоту R. Для определенности будем считать, что новый ключ включается в поддерево L. Если высота L не изменяется, то не изменяются и соотношения между высотой L и R, и свойства АВЛ-дерева сохраняются. Если же при включении в поддерево L высота этого поддерева увеличивается на 1, то возможны следующие три случая:
- (a) если hl = hr, то после добавления вершины L и R станут разной высоты, но свойство сбалансированности сохранится;
- (b) если hl < hr, то после добавления новой вершины L и R станут равной высоты, т.е. сбалансированность общего дерева даже улучшится;
- (c) если hl > hr, то после включения ключа критерий сбалансированности нарушится, и потребуется перестройка дерева.
Имеет смысл рассмотреть две разные ситуации. В первой ситуации новая вершина добавляется к левому поддереву L, во второй - к правому поддереву. Правила восстановления балансировки показаны на рисунке 4.12 и проиллюстрированы примерами на рисунке 4.13.
(a)
(b)
(c)
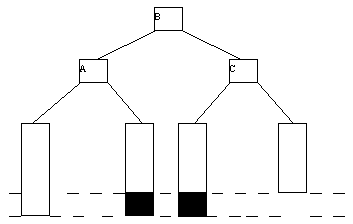
(d)
Рис. 4.12.
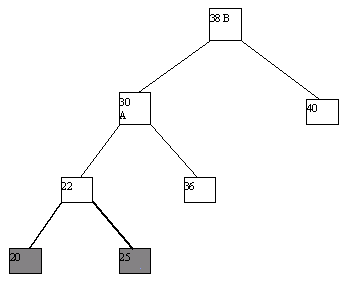
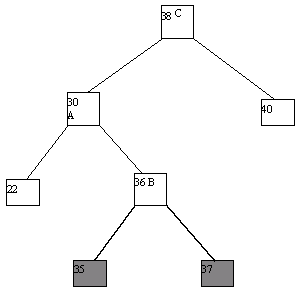
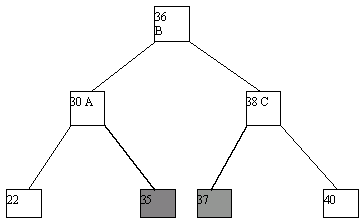
(a)

(b)
(c)
(d)
Рис. 4.13.
Как кажется, в данном случае рисунки лучше проясняют суть явления, чем текст и тем более компьютерная программа. Действия, которые требуются для балансировки, авторы механизма назвали "поворотами". Действительно, если внимательно посмотреть на то, что происходит с деревом, это действительно напоминает его повороты относительно выбранной вершины.
При исключении вершин из АВЛ-дерева также возможна его не слишком сложная балансировка. Мы не будем приводить описание требующихся процедур, а проиллюстрируем их на нескольких последовательных примерах (рисунок 4.14).
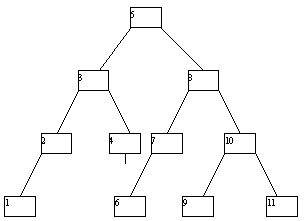
(a)
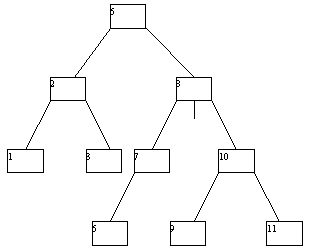
(b)
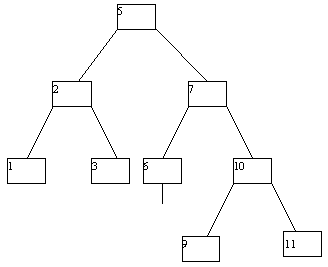
(c)
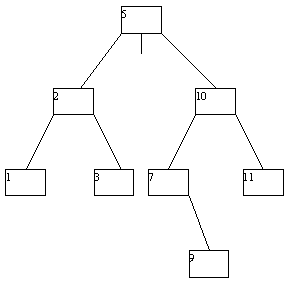
(d)
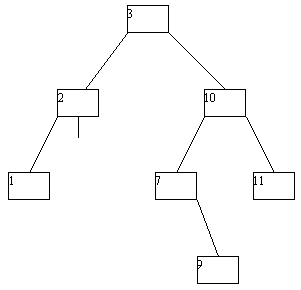
(e)
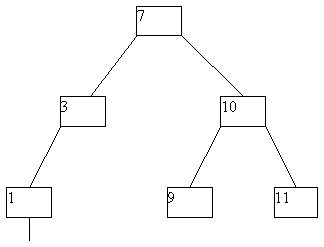
(f)
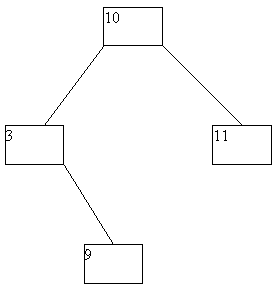
(g)
Рис. 4.14.
Известно, что оценкой стоимости поиска в АВЛ-дереве, а также выполнения операций включения и исключения ключей является O(log n), т.е. эти деревья при поиске ведут себя почти так же хорошо, как и идеально сбалансированные деревья, а поддержка балансировки при включениях и исключениях обходится гораздо дешевле.
4.1.3. Деревья оптимального поиска
В приводившихся выше рассуждениях по поводу организации деревьев поиска предполагалось, что вероятность поиска любого возможного ключа одна и та же, т.е. распределена равномерно. Но встречаются ситуации, в которых можно получить информацию о вероятности обращений к отдельным ключам. Обычно в таких случаях дерево поиска строится один раз, имеет неизменяемую структуру, в него не включаются новые ключи, и из него не исключаются существующие ключи. Примером соответствующего приложения является сканер компилятора, одной из задач которого является определение принадлежности очередного идентификатора к набору ключевых слов языка программирования. На основе сбора статистики при многочисленной компиляции программ можно получить достаточно точную информацию о частотах поиска по отдельным ключам.
Пусть дерево поиска содержит n вершин, и обозначим через pi вероятность обращения к i-той вершине, содержащей ключ ki. Сумма всех pi, естественно, равна 1. Постараемся теперь организовать дерево поиска таким образом, чтобы обеспечить минимальность общего числа шагов поиска, подсчитанного для достаточно большого количества обращений. Будем считать, что корень дерева имеет высоту 1 (а не 0, как раньше), и определим взвешенную длину пути дерева как сумму pi*hi (1<=i<=n), где hi - длина пути от корня до i-той вершины. Требуется построить дерево поиска с минимальной взвешенной длиной пути.
В качестве примера рассмотрим возможности построения дерева поиска для трех ключей 1, 2, 3 с вероятностями обращения к ним 1/7, 2/7 и 4/7 соответственно (рисунок 4.15).
Посчитаем взвешенную длину пути для каждого случая. В случае (a) взвешенная длина пути P(a) = 1*4/7 + 2*2/7 + 3*1/7 = 11/7. Аналогичные подсчеты дают результаты P(b)=12/7; P(c)=12/7; P(d)=15/7; P(e)=17/7. Следовательно, оптимальным в интересующем нас смысле оказалось не идеально сбалансированное дерево (c), а вырожденное дерево (a).
На практике приходится решать несколько более общую задачу, а именно, при построении дерева учитывать вероятности неудачного поиска, т.е. поиска ключа, не включенного в дерево. В частности, при реализации сканера желательно уметь эффективно распознавать идентификаторы, которые не являются ключевыми словами. Можно считать, что поиск по ключу, отсутствующему в дереве, приводит к обращению к "специальной" вершине, включенной между реальными вершинами с меньшим и большим значениями ключа соответственно. Если известна вероятность qj обращения к специальной j-той вершине, то к общей средней взвешенной длине пути дерева необходимо добавить сумму qj*ej для всех специальных вершин, где ej - высота j-той специальной вершины.
(a)
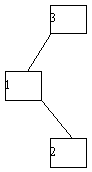
(b)
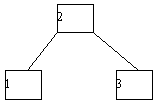
(c)
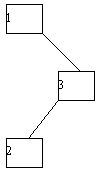
(d)

(e)
Рис. 4.15.
При построении дерева оптимального поиска вместо значений pi и qj обычно используют полученные статистически значения числа обращений к соответствующим вершинам. Процедура построения дерева оптимального поиска достаточно сложна и опирается на тот факт, что любое поддерево дерева оптимального поиска также обладает свойством оптимальности. Поэтому известный алгоритм строит дерево "снизу-вверх", т.е. от листьев к корню. Сложность этого алгоритма и расходы по памяти составляют O(n2). Имеется эвристический алгоритм, дающий дерево, близкое к оптимальному, со сложностью O(n*log n) и расходами памяти - O(n).
4.1.4. Деревья цифрового поиска
Методы цифрового поиска достаточно громоздки и плохо иллюстрируются. Поэтому мы кратко остановимся на наиболее простом механизме - бинарном дереве цифрового поиска. Как и в деревьях, обсуждавшихся в предыдущих разделах, в каждой вершине такого дерева хранится полный ключ, но переход по левой или правой ветви происходит не путем сравнения ключа-аргумента со значением ключа, хранящегося в вершине, а на основе значения очередного бита аргумента.
Поиск начинается от корня дерева. Если содержащийся в корневой вершине ключ не совпадает с аргументом поиска, то анализируется самый левый бит аргумента. Если он равен 0, происходит переход по левой ветви, если 1 - по правой. Если не обнаруживается совпадение ключа с аргументом поиска, то анализируется следующий бит аргумента и т.д., пока либо не будут проверены все биты аргумента, или мы не наткнемся на вершину с отсутствующей левой или правой ссылкой.
На рисунке 4.16 показан пример дерева цифрового поиска для некоторых заглавных букв латинского алфавита. Считается, что буквы кодируются в соответствии с кодовым набором ASCII, а для их представления и поиска используются 5 младших бит кода. Например, код буквы A равен 41(16), а представляться A будет как последовательность бит 00001.
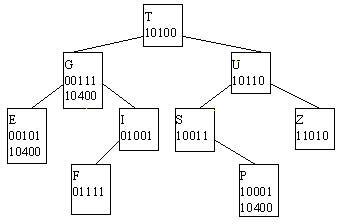
Рис. 4.16.
4.2. Методы хэширования для поиска в основной памяти
Если в предыдущем разделе речь шла о поиске необходимой информации по заданному ключу путем прямого сравнения значения аргумента с искомым ключом, то этот раздел посвящен принципиально (до некоторой степени) другому подходу к поиску. Общая идея подхода заключается в том, чтобы с помощью применения к заданному аргументу поиска x заранее определенной функции f(Ч) (хэш-функции, иногда называемой по-русски функцией расстановки) получить значение f(x), которое наилучшим образом характеризовало бы положение искомого ключа в основной или внешней памяти. В этом разделе мы сосредоточимся на такого рода методах поиска данных в основной памяти.
Замечание по поводу терминологии. В течение многих лет в сообществе российских программистов обсуждался вопрос применения русскоязычной терминологии, относящейся к хэшированию. Кроме упомянутого выше термина "расстановка", предлагалось использовать "русский" термин "рандомизация". Поскольку, как видно, для этого подхода нет подходящего названия на русском языке, мы будем использовать транслитерацию английского термина "hashing" - хэширование.
4.2.1. Совершенное хэширование
Под термином совершенное хэширование понимается техника, которая позволяет строить статические массивы, содержащие записи, индекс доступа к которым по заданному ключу однозначно производит заданная хэш-функция. Идея состоит в том, чтобы по заданному набору ключей произвести хэш-функцию, которая преобразует значение ключа в соответствующий индекс массива записей и при этом оставляет незанятым максимальное число элементов массива (если удается занять все элементы массива, функция называется абсолютно совершенной).
Вырожденный пример абсолютно совершенной хэш-функции приведен на рисунке 4.17, где ключами являются коды заглавных букв латинского алфавита (в кодировке ASCII), а хэш-функция отрезает от кода буквы младшие пять бит.
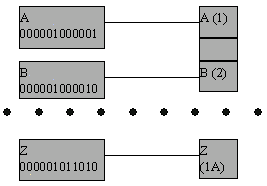
Рис. 4.17.
В более сложных случаях для построения совершенной хэш-функции используются специальные программы (основанные на эмпирических алгоритмах), которые по заданному набору ключей генерируют функции отображения ключей в индексы массивов хранимых записей. Вообще говоря, выработанная совершенная хэш-функция не гарантирует, что все элементы массива будут заполнены записями, соответствующими значениям ключей. Более того, при добавлении хотя бы одного нового ключа к ранее заданному набору потребуется генерация новой хэш-функции и соответствующая ей перестановка элементов массива записей.
Прием совершенного хэширования дает превосходные результаты при задании известного заранее не очень большого набора ключей, но не помогает в случае необходимости динамического включения или исключения записей.
4.2.2. Коллизии при хэшировании и способы их разрешения
Хэширование может обеспечить хорошие результаты и в том случае, когда набор ключей заранее неизвестен. В этом случае не приходится говорить о генерации совершенной хэш-функции. Даже если известен диапазон значений ключей, то в лучшем случае применение совершенного хэширования потребует наличия в памяти массива с размером, равным мощности множества ключей. Кроме того, неизвестны выполняемые в разумное время алгоритмы генерации совершенной хэш-функции для множества ключей большой мощности.
Распространенным методом является использование эмпирически подобранной хэш-функции, которая (a) по значению ключа производит значение индекса в границах массива и (b) равномерно распределяет ключи по элементам массива. Если ORD(k) обозначает порядковый номер ключа k в упорядоченном множестве допустимых ключей, а N - число элементов в массиве записей, то одной из наиболее естественных хэш-функций является H(k) = ORD(k) MOD N, т.е. взятие остатка от деления порядкового номера ключа на число элементов массива. Такая функция выполняется очень быстро, если N является степенью числа 2. Для числовых ключей функция обеспечивает достаточную равномерность распределения ключей в массиве.
Однако если ключом является последовательность символов (что чаще всего и бывает), то при применении такой функции возникает большая вероятность выработки одного и того же значения для ключей, отличающихся небольшим числом символов. Ситуацию несколько облегчает использование в качестве N простого числа. Вычисление функции становится более сложным, но вероятность выработки одного значения для разных ключей уменьшается.
Используются и более сложные способы вычисления хэш-функции основанные, например, на вырезке поднабора бит из битового представления ключа или вычислении квадратичного выражения от ORD(k). Но в любом случае с ненулевой вероятностью хэш-функция может выдать одно значение для разных значений ключа. Такая ситуация называется коллизией ключей и проявляется в том, что при попытке занести в хэш-таблицу запись с новым ключом мы наталкиваемся на то, что требуемый элемент массива уже занят. Одним из выходов (к которому рано или поздно, может быть, придется прибегнуть) является увеличение размера массива, образование новой хэш-функции и расстановка заново всех занятых элементов массива. Но поскольку возникновение коллизии может являться флуктуацией, до поры до времени обычно пытаются разрешать эту ситуацию другими способами. Традиционно принято различать методы прямой адресации (ключ, появление которого вызвало коллизию, помещается в один из свободных элементов хэш-таблицы) и методы цепочек (записи, для ключей которых выработано одинаковое значение хэш-функции связываются в линейный список).
4.2.3. Линейное зондирование
Самым простым способом разрешения коллизий является использование метода линейного зондирования (иногда его называют методом линейных проб). Идея состоит в том, что сталкиваясь с коллизией при включении записи, мы последовательно (циклически, с переходом через конец на начало) просматриваем массив в поиске первого незанятого элемента. Если такой элемент обнаруживается, в него и заносится включаемая запись (рисунок 4.18). Если все элементы массива заняты, то это означает, что хэш-таблица переполнена и требуется расширение массива и новая расстановка его элементов.
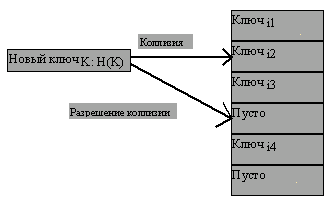
Рис. 4.18.
Если коллизия обнаруживается при поиске (т.е. следуя применяемой хэш-функции мы обращаемся по свертке ключа к элементу массива и обнаруживаем, что он занят записью с другим ключом), последовательно (циклически) просматриваются следующие элементы массива, пока не будет найдена запись с указанным ключом (рисунок 4.19), либо мы не наткнемся на свободный элемент массива. Последний вариант означает, что запись с указанным ключом в хэш-таблице отсутствует (рисунок 4.20).
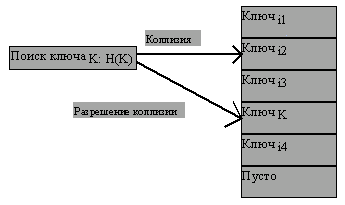
Рис. 4.19.
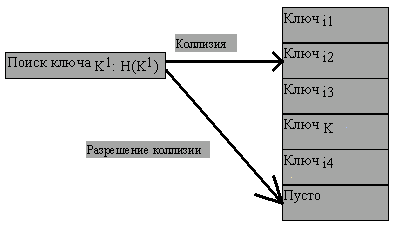
Рис. 4.20.
Достоинством метода линейного зондирования является его очевидная простота, а недостаток состоит в том, что при разрешении коллизии вторичные элементы массива (те, на которые прямо не указывает хэш-функция) имеют обыкновение сосредотачиваться вблизи первичных элементов. Заполнение массива происходит неравномерно, и увеличивается вероятность следующих коллизий.
4.2.4. Двойное хэширование
Для обеспечения равномерного распределения ключей в хэш-таблице при наличии коллизий можно применять метод двойного хэширования. Он состоит в том, что если при включении или поиска ключа в хэш-таблице возникает коллизия, то к ключу (или к комбинации ключа и текущего индекса массива) применяется вторичная хэш-функция, значение которой указывает циклическое смещение в массиве от текущего индекса к элементу, в который следует включать или в котором следует искать требуемую запись (рисунки 4.21, 4.22).
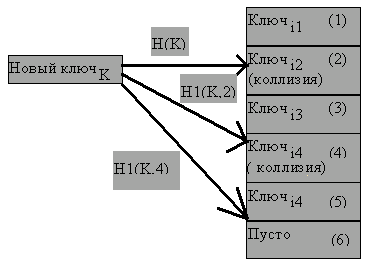
Рис. 4.21.
Поскольку метод двойного хэширования в полной форме приводит к слишком большим накладным расходам, на практике часто используется упрощенная форма этого метода, не гарантирующая равномерности записей в массиве, но обеспечивающая лучшие результаты, чем линейное зондирование. Один из способов состоит в использовании квадратичной функции при вычислении индекса следующей пробы. В этом случае последовательность вычисления индексов проб при включении или поиске записи является следующей:
h0 = H(K) ........ hi = (h0 + i^2) MOD N (i>0)
Основным недостатком метода квадратичных проб является то, что для включаемой записи может не найтись свободного элемента массива даже в том случае, когда реально около половины элементов являются свободными.
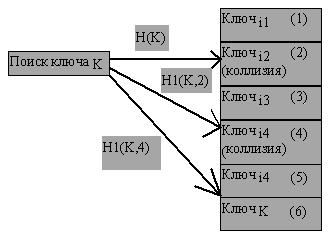
Рис. 4.22.
4.2.5. Использование цепочек переполнения
Это один из наиболее очевидных способов разрешения коллизий. Если по смыслу в элементах массива хранятся записи типа T, то в данном случае к записи добавляется поле типа ссылки на T. При возникновении коллизии по причине включения новой записи для нового элемента выделяется динамическая память, и он включается в конец линейного списка, который начинается от первичного элемента массива. Если коллизия возникает при поиске ключа, то список переполнения просматривается либо до момента нахождения требуемого ключа, либо до конца, что означает отсутствие искомой записи (рисунок 4.23).
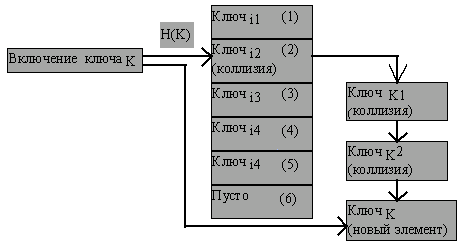
Рис. 4.23.
Метод цепочек переполнения легко реализуется, понятен, но потенциально приводит к излишним расходам памяти.
5. Методы поиска во внешней памяти
Как и в случае необходимости сортировки данных, не размещаемых целиком в основной памяти, для поиска данных во внешней памяти существует ряд методов, несколько напоминающих те, которые упоминались в предыдущей части, но сильно отличающихся по своей сути. Эти методы по названиям похожи на те, которые используются для поиска данных в основной памяти - деревья и хэширование, - но устроены совсем другим образом, чтобы минимизировать число обращений к внешней памяти.
5.1. Методы поиска во внешней памяти на основе деревьев
Базовым "древовидным" аппаратом для поиска данных во внешней памяти являются B-деревья. В основе этого механизма лежат следующие идеи. Во-первых, поскольку речь идет о структурах данных во внешней памяти, общее время доступа к которой определяется в основном не объемом последовательно расположенных данных, а временем подвода магнитных головок (см. введение в Часть 3), то выгодно получать за одно обращение к внешней памяти как можно больше информации, учитывая при этом необходимость экономного использования основной памяти. При сложившемся подходе к организации основной памяти в виде набора страниц равного размера естественно считать именно страницу единицей обмена с внешней памятью. Во-вторых, желательно обеспечить такую поисковую структуру во внешней памяти, при использовании которой поиск информации по любому ключу требует заранее известного числа обменов с внешней памятью.
5.1.1. Классические B-деревья
Механизм классических B-деревьев был предложен в 1970 г. Бэйером и Маккрейтом. B-дерево порядка n представляет собой совокупность иерархически связанных страниц внешней памяти (каждая вершина дерева - страница), обладающая следующими свойствами:
- Каждая страница содержит не более 2*n элементов (записей с ключом).
- Каждая страница, кроме корневой, содержит не менее n элементов.
- Если внутренняя (не листовая) вершина B-дерева содержит m ключей, то у нее имеется m+1 страниц-потомков.
- Все листовые страницы находятся на одном уровне.
Пример B-дерева степени 2 глубины 3 приведен на рисунке 5.1.
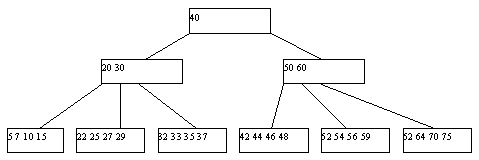
Рис. 5.1. Классическое B-дерево порядка 2
Поиск в B-дереве производится очевидным образом. Предположим, что происходит поиск ключа K. В основную память считывается корневая страница B-дерева. Предположим, что она содержит ключи k1, k2, ..., km и ссылки на страницы p0, p1, ..., pm. В ней последовательно (или с помощью какого-либо другого метода поиска в основной памяти) ищется ключ K. Если он обнаруживается, поиск завершен. Иначе возможны три ситуации:
- Если в считанной странице обнаруживается пара ключей ki и k(i+1) такая, что ki < K < k(i+1), то поиск продолжается на странице pi.
- Если обнаруживается, что K > km, то поиск продолжается на странице pm.
- Если обнаруживается, что K < k1, то поиск продолжается на странице p0.
Для внутренних страниц поиск продолжается аналогичным образом, пока либо не будет найден ключ K, либо мы не дойдем до листовой страницы. Если ключ не находится и в листовой странице, значит ключ K в B-дереве отсутствует.
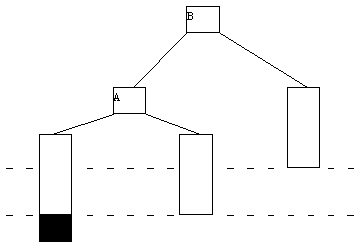
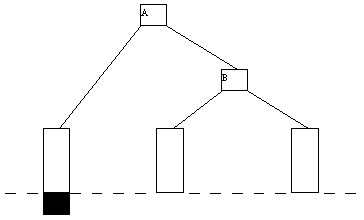
Включение нового ключа K в B-дерево выполняется следующим образом. По описанным раньше правилам производится поиск ключа K. Поскольку этот ключ в дереве отсутствует, найти его не удастся, и поиск закончится в некоторой листовой странице A. Далее возможны два случая. Если A содержит менее 2*n ключей, то ключ K просто помещается на свое место, определяемое порядком сортировки ключей в странице A. Если же страница A уже заполнена, то работает процедура расщепления. Заводится новая страница C. Ключи из страницы A (берутся 2*n-1 ключей) + ключ K поровну распределяются между A и C, а средний ключ вместе со ссылкой на страницу C переносится в непосредственно родительскую страницу B. Конечно, страница B может оказаться переполненной, рекурсивно сработает процедура расщепления и т.д., вообще говоря, до корня дерева. Если расщепляется корень, то образуется новая корневая вершина, и высота дерева увеличивается на единицу. Одношаговое включение ключа с расщеплением страницы показано на рисунке 5.2.
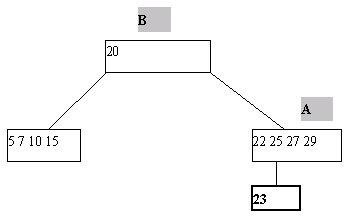
(a) Попытка вставить ключ 23 в уже заполненную страницу
(b) Выполнение включения ключа 23 путем расщепления страницы A
Рис. 5.2. Пример включения ключа в B-дерево
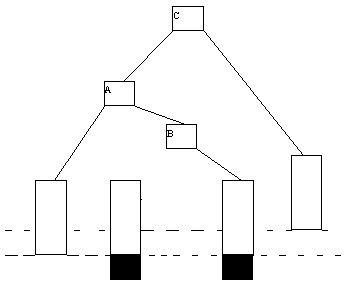
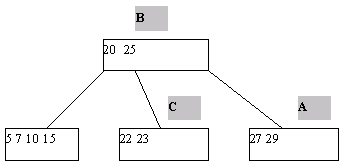
Процедура исключения ключа из классического B-дерева более сложна. Приходится различать два случая - удаление ключа из листовой страницы и удаления ключа из внутренней страницы B-дерева. В первом случае удаление производится просто: ключ просто исключается из списка ключей. При удалении ключа во втором случае для сохранения корректной структуры B-дерева его необходимо заменить на минимальный ключ листовой страницы, к которой ведет последовательность ссылок, начиная от правой ссылки от ключа K (это минимальный содержащийся в дереве ключ, значение которого больше значения K). Тем самым, этот ключ будет изъят из листовой страницы (рисунок 5.3).
(a) Начальный вид B-дерева
(b) B-дерево после удаления ключа 25
Рис. 5.3. Пример исключения ключа из B-дерева
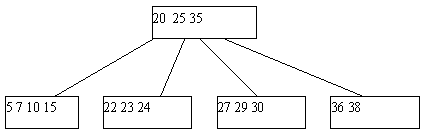
Поскольку в любом случае в одной из листовых страниц число ключей уменьшается на единицу, может нарушиться то требование, что любая, кроме корневой, страница B-дерева должна содержать не меньше n ключей. Если это действительно случается, начинает работать процедура переливания ключей. Берется одна из соседних листовых страниц (с общей страницей-предком); ключи, содержащиеся в этих страницах, а также средний ключ страницы-предка поровну распределяются между листовыми страницами, и новый средний ключ заменяет тот, который был заимствован у страницы-предка (рисунок 5.4).
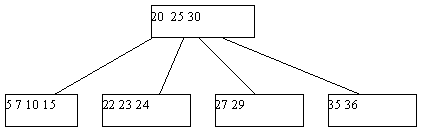
Рис. 5.4. Результат удаления ключа 38 из B-дерева с рисунка 5.3
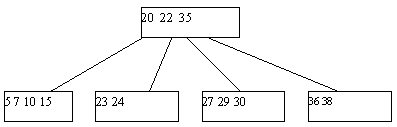
Может оказаться, что ни одна из соседних страниц непригодна для переливания, поскольку содержат по n ключей. Тогда выполняется процедура слияния соседних листовых страниц. К 2*n-1 ключам соседних листовых страниц добавляется средний ключ из страницы-предка (из страницы-предка он изымается), и все эти ключи формируют новое содержимое исходной листовой страницы. Поскольку в странице-предке число ключей уменьшилось на единицу, может оказаться, что число элементов в ней стало меньше n, и тогда на этом уровне выполняется процедура переливания, а возможно, и слияния. Так может продолжаться до внутренних страниц, находящихся непосредственно под корнем B-дерева. Если таких страниц всего две, и они сливаются, то единственная общая страница образует новый корень. Высота дерева уменьшается на единицу, но по-прежнему длина пути до любого листа одна и та же. Пример удаления ключа со слиянием листовых страниц показан на рисунке 5.5.
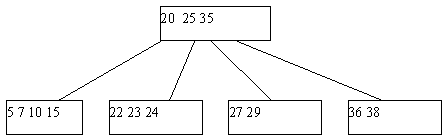
(a) Начальный вид B-дерева
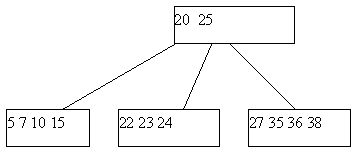
(b) B-дерево после удаления ключа 29
Рис. 5.5. Пример удаления ключа из B-дерева со слиянием листовых страниц
5.1.2. B+-деревья
Схема организации классических B-деревьев проста и элегантна, но не очень хороша для практического использования. Прежде всего это связано с тем, что в большинстве практических применений необходимо хранить во внешней памяти не только ключи, но и записи. Поскольку в B-дереве элементы располагаются и во внутренних, и в листовых страницах, а размер записи может быть достаточно большим, внутренние страницы не могут содержать слишком много элементов, по причине дерево может быть довольно глубоким. Поэтому для доступа к ключам и записям, находящимся на нижних уровнях дерева, может потребоваться много обменов с внешней памятью. Во-вторых, на практике часто встречается потребность хранения и поиска ключей и записей переменного размера. Поэтому тот критерий, что в каждой странице B-дерева содержится не меньше n и не больше 2*n ключей, становится неприменимым.
Широкое практическое применение получила модификация механизма B-деревьев, которую принято называть B+-деревьями. Эти деревья похожи на обычные B-деревья. Они тоже сильно ветвистые, и длина пути от корня к любой листовой странице одна и та же. Но структура внутренних и листовых страниц различна. Внутренние страницы устроены так же, как у B-дерева, но в них хранятся только ключи (без записей) и ссылки на страницы-потомки. В листовых страницах хранятся все ключи, содержащиеся в дереве, вместе с записями, причем этот список упорядочен по возрастанию значения ключа (рисунок 5.6).
Поиск ключа всегда доходит до листовой страницы. Аналогично операции включения и исключения тоже начинаются с листовой страницы. Для применения переливания, расщепления и слияния используются критерии, основанные на уровне заполненности соответствующей страницы. Для более экономного и сбалансированного использования внешней памяти при реализации B+-деревьев иногда используют технику слияния трех соседних страниц в две и расщепления двух соседних страниц в три. Хотя B+-деревья хранят избыточную информацию (один ключ может храниться в двух страницах), они, очевидно, обладают меньшей глубиной, чем классические B-деревья, а для поиска любого ключа требуется одно и то же число обменов с внешней памятью.

(a) Структура внутренней страницы B+-дерева

(b) Структура листовой страницы B+-дерева
Рис. 5.6. Структуры страниц B+-дерева
Дополнительной полезной оптимизацией B+-деревьев является связывание листовых страниц в одно- или двунаправленный список. Это позволяет просматривать списки записей для заданного диапазона значений ключей с лишь одним прохождением дерева от корня к листу.
5.1.3. Разновидности B+-деревьев для организации индексов в базах данных
B+-деревья наиболее интенсивно используются для организации индексов в базах данных. В основном это определяется двумя свойствами этих деревьев: предсказуемостью числа обменов с внешней памятью для поиска любого ключа и тем, что это число обменов по причине сильной ветвистости деревьев не слишком велико при индексировании даже очень больших таблиц.
При использовании B+-деревьев для организации индексов каждая запись содержит упорядоченный список идентификаторов строк таблицы, включающих соответствующее значение ключа. Дополнительную сложность вызывает возможность организации индексов по нескольким столбцам таблицы (так называемых "составных" индексов). В этом случае в B+-дереве может появиться очень много избыточной информации по причине наличия в разных составных ключах общих подключей. Имеется ряд технических приемов сжатия индексов с составными ключами, улучшающих использование внешней памяти, но, естественно, замедляющих выполнение операций включения и исключения.
5.1.4. R-деревья и их использование для организации индексов в пространственных базах данных
Коротко рассмотрим еще одно расширение механизма B-деревьев, используемое главным образом для организации индексов в пространственных базах данных, - R-деревья. Подобно B+-деревьям, R-дерево представляет собой ветвистую сбалансированную древовидную структуру с разной организацией внутренних и листовых страниц.
Но информация, хранящаяся в R-дереве несколько отличается от той, которая содержится в B-деревьях. В дополнение к находящимся в листовых страницах идентификаторам пространственных объектов, в R-деревьях хранится информация о границах индексируемого объекта. В случае двумерного пространства сохраняются горизонтальные и вертикальные координаты нижнего левого и верхнего правого углов наименьшего прямоугольника, содержащего индексируемый объект. Пример простого R-дерева, содержащего информацию о шести пространственных объектах, приведен на рисунке 5.7.
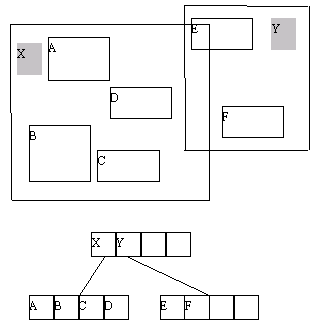
Рис. 5.7. Простое R-дерево для представления шести пространственных объектов
5.2. Методы хэширования для поиска во внешней памяти
Идея доступа к данным на основе хэширования настолько привлекательна (потенциальная возможность за одно обращение к памяти получить требуемые данные), что от нее невозможно отказаться при работе с данными во внешней памяти. Исходная идея кажется очевидной: если при управлении данными на основе хэширования в основной памяти хэш-функция вырабатывает адрес требуемого элемента, то при обращении к внешней памяти необходимо генерировать номер блока дискового пространства, в котором находится запрашиваемый элемент данных. Основная проблема относится к коллизиям. Если при работе в основной памяти потенциально возникающими потребностями дополнительного поиска информации при возникновении коллизий можно, вообще говоря, пренебречь (поскольку время доступа к основной памяти мало), то при использовании внешней памяти любое дополнительное обращение вызывает существенные накладные расходы. Основные методы хэширования для поиска информации во внешней памяти направлены на решение именно этой задачи. Заметим, что автором и первооткрывателем большинства идей хэширования во внешней памяти является Витольд Литвин.
5.2.1. Расширяемое хэширование
В основе подхода расширяемого хэширования (Extendible Hashing) лежит принцип использования деревьев цифрового поиска в основной памяти. В основной памяти поддерживается справочник, организованный на основе бинарного дерева цифрового поиска, ключами которого являются значения хэш-функции, а в листовых вершинах хранятся номера блоков записей во внешней памяти. В этом случае любой поиск в дереве цифрового поиска является "успешным", т.е. ведет к некоторому блоку внешней памяти. Входит ли в этот блок искомая запись, обнаруживается уже после прочтения блока в основную память.
Проблема коллизий переформулируется следующим образом. Как таковых, коллизий не существует. Может возникнуть лишь ситуация переполнения блока внешней памяти. Значение хэш-функции указывает на этот блок, но места для включения записи в нем уже нет. Эта ситуация обрабатывается так. Блок расщепляется на два, и дерево цифрового поиска переформируется соответствующим образом. Конечно, при этом может потребоваться расширение самого справочника.
Расширяемое хэширование хорошо работает в условиях динамически изменяемого набора записей в хранимом файле, но требует наличия в основной памяти справочного дерева.
5.2.2. Линейное хэширование
Идея линейного хэширования (Витольд Литвин) состоит в том, чтобы можно было обойтись без поддержания справочника в основной памяти. Основой метода является то, что для адресации блока внешней памяти всегда используются младшие биты значения хэш-функции. Если возникает потребность в расщеплении, то записи перераспределяются по блокам так, чтобы адресация осталась правильной.
5.2.3. Использование хэширования для организации индексов в базах данных
Исторически методы хэширования в базах данных использовались не очень часто. Одним из первых примеров систем, где с самого начала применялись методы хэширования, являлась Ingres. Хэширование с самого возникновения ориентировано на поиск по уникальному ключу. Наиболее распространенные методы не могут обеспечить, например, поиск записей для заданного диапазона значений ключа. Тем не менее, сегодня хэш-ориентированные структуры поддерживаются рядом СУБД; особенно полезны они в задачах поиска по точному совпадению ключа.
5.3. Дополнительные способы поддержки поиска в базах данных
Помимо B+-деревьев и хэш-индексов, в современных СУБД применяется ряд дополнительных индексных структур, оптимизирующих поиск для специфических классов запросов. Рассмотрим два наиболее важных из них.
5.3.1. Индексы соединения
Это очень простая идея. Она происходит от классической экспериментальной системы IBM System R. Если можно создавать индексы для отдельных таблиц, то почему нельзя делать индексы для нескольких таблиц? Индексировать совместно таблицы, которые требуется соединять? Обычно используют обычные B+-деревья. В поле записи этих деревьев содержится список идентификаторов записей соединяемых таблиц.
Достаточно дорогой, но очень эффективный метод поддержки соединений.
5.3.2. Индексы на основе использования битовых шкал
Битовые индексы похожи на традиционные индексы, основанные на списках идентификаторов строк (RID - Row Identifier). Но битовые индексы в некоторых случаях позволяют получить существенный выигрыш в производительности.
Начнем с определения списка RID. Каждой строке в таблице приписывается RID, который можно рассматривать как указатель на строку на диске. Обычно RID состоит из номера страницы на диске и номера позиции записи на этой странице. Набор строк с данным свойством может быть представлен как список RID этих строк. В большинстве СУБД используются 4-байтовые RID (хотя в Oracle RID имеет длину по крайней мере 6 байт). Традиционно списки RID использовались в индексах для определения набора строк, ассоциированных с каждым значением некоторого индексируемого столбца. Если предположить потребность в индексе на таблице SALES, содержащей 100 миллионов строк и включающей столбец department c 40 разными значениями, то для каждого значения этого столбца мы получим список RID, который в среднем будет соответствовать 2.5 миллионам строк.
При наличии громадного числа RID, ассоциированных с каждым значением department, трудно рассчитывать, что удастся целиком переместить список RID в основную память. Список разбивается на фрагменты по несколько сотен RID, которые могут быть помещены в последовательные листовые узлы B-дерева. Для каждого фрагмента можно хранить в B-дереве только одно значение department, так что критически остается лишь потребность в хранении 100 миллионов 4-байтовых RID.
Теперь мы готовы ввести идею битовой индексации. В таблице, для которой используется эта техника, все строки должны быть перенумерованы: 0, 1, 2, ..., N-1. Нумерация строк должна производиться в соответствии с порядком их RID (физически последовательно относительно расположения строк на диске). Требуется метод преобразования номера строки в RID и наоборот. Теперь, если имеется последовательность из N бит, установим k-тый бит в 1, если строка с номером k входит в набор строк, а в противном случае - в 0. Битовый индекс на SALES по столбцу department аналогичен тому, который основан на RID, но вместо фрагментов RID в нем используются соответствующие битовые фрагменты. Каждый битовый фрагмент будет занимать 12.5 Мб, так что вполне вероятно разместить его на последовательных страницах диска. Отношение числа битов, установленных в 1, к общей длине набора бит называется плотностью этого набора и аналогично селективности условия выборки. Фрагменты с низкой плотностью можно компрессировать. Пока же будем считать, что все фрагменты обладают высокой плотностью.
В этом случае полный битовый индекс требует на листовом уровне чуть больше 500 Мб внешней памяти, т.е. больше, чем индекс, основанный на RID. Однако, ситуация меняется, если индексируемый столбец содержит мало различных значений. Если, например, таблица SALES содержит столбец gender (пол) со всего двумя значениями M и F, то для листового уровня битового индекса потребуется всего 25 Мб, в то время как для RID-индекса по-прежнему было бы нужно иметь 400 Мб. Для индексов с менее, чем 32 значениями битовые индексы позволяют экономить память.
Однако, наиболее важным свойством неупакованных битовых индексов является не экономия памяти, а возможность существенно повысить скорость выполнения операций AND, OR, NOT и COUNT. Предположим, что имеются два битовых фрагмента B1 и B2, где B1 представляет свойство gender = 'M', а B2 - department = 'sports'. Тогда для получения битового фрагмента, соответствующего свойству B1 & B2, требуется всего лишь выполнить поразрядное логическое умножение B1 и B2.
Для выполнения операции AND над двумя списками RID требуется более сложная техника: слияние с пересечением. Нужно использовать два курсора, каждый из которых продвигается по одному из списков, и в результирующем списке остаются те RID, которые встречаются в каждом из исходных списков.
Конечно, если списки-операнды включают только по несколько десятков RID, то цикл со списками RID окажется более эффективным, чем цикл, в котором выполняется логическое умножение битовых шкал, длина каждой из которых равна общему числу строк в таблице. Но при плотности битовой шкалы большей, чем 1/100, алгоритм на основе битовых шкал работает быстрее. Аналогично обстоят дела с алгоритмами для выполнения операций OR, NOT и COUNT.
Если битовая шкала становится очень разреженной, то битовые индексы работают плохо по сравнению с RID-индексами не только в связи с нагрузкой на процессор, но и по причине большого числа обменов с внешней памятью. Для решения обеих проблем требуется какой-либо метод сжатия, который позволил бы сократить расходы внешней памяти, но в то же время позволил бы по-прежнему быстро выполнять операции AND, OR, NOT и COUNT. Один из подходов состоит в совместном использовании битовой и RID индексации: когда битовый фрагмент становится слишком разреженным, он заменяется на RID-фрагмент. В других подходах используется техника кодирования битовых шкал. В этом случае становится сложно эффективно выполнять перечисленные выше операции между сжатой и несжатой шкалами. Потребность нахождения техники сжатия, которая бы не тормозила выполнение этих операций, является наиболее важной проблемой битовой индексации.
Сегодня битовые индексы широко применяются в аналитических (OLAP) системах и колоночных СУБД (таких как ClickHouse, Vertica, Apache Druid), где преобладают запросы с фильтрацией по нескольким столбцам с невысокой кардинальностью. Разработаны эффективные методы сжатия битовых шкал (в частности, Roaring Bitmaps), позволяющие сочетать компактное хранение с быстрым выполнением логических операций.