Наиболее строгое решение содержится в языках линии Паскаль. В определении всего структурного типа или его завершающей части можно явно указать специальное поле перечисляемого типа (дискриминант), значения которого являются метками соответствующих вариантов типа записи. Для корректного использования переменных такого типа требуется заносить в поле дискриминанта актуальное значение при изменении интерпретации переменной и руководствоваться значением дискриминанта при доступе к содержимому переменной. Вот пример определения типа записи с вариантами в языке Паскаль:
type person = record lname, fname: alfa;
birthday: date;
marstatus: (single, married);
case sex: (male, female) of
male: (weight: real;
bearded: boolean);
female: (size: array[1..3] of integer)
end
(Считается, что типы данных alfa и date уже определены.) После определения переменной типа person в любой момент можно обращаться и к полям weight и bearded, и к элементам массива size, но корректно это следует делать, руководствуясь значением дискриминанта sex.
Более слабый, но эквивалентный по возможностям механизм поддерживается в языках семейства Си. В этих языках существует специальная разновидность типов данных, называемая смесью (union). Фактически, смесь - это запись с вариантами, но без явно поддерживаемого дискриминанта. По нашему мнению, решение о применении такого "облегченного" механизма было принято потому, что использование явно задаваемого дискриминанта в языках линии Паскаль все равно является необязательным, а раз так, то при желании можно просто включить дополнительное поле, значение которого будет характеризовать применимый вариант. Приведенный выше пример можно было бы переписать на языке Си следующим образом:
struct person { char lname[10], fname[10];
integer birthday;
enum { single, married } marstatus;
enum { male, female } sex;
union {
struct { float weight;
integer bearded } male;
integer female[3];
} pers;
}
1.5.4. Множества
Еще одной разновидностью конструируемых типов являются типы множеств. Такие типы поддерживаются только в развитых сильно типизированных языках. В языке Паскаль тип множества определяется конструкцией type T = set of T0, где T0 - встроенный или ранее определенный тип данных (базовый тип). Значениями переменных типа T являются множества элементов типа T0 (в частности, пустые множества).
Для любого типа множества определены следующие операции: "?" - пересечение множеств, "+" - объединение множеств, "-" - вычитание множеств и "in" - проверка принадлежности к множеству элемента базового типа.
С использованием механизма множеств можно писать лаконичные и красивые программы, но нужно отдавать себе отчет в том, что для эффективной реализации множеств требуются серьезные ограничения их мощности. Обычно в реализациях языков допускаются множества, мощность базового типа которых не превосходит длину машинного слова. Это связано с тем, что перечисленные выше операции допускают эффективную реализацию только в том случае, когда значение множества представляется битовой шкалой, длина которой равна мощности базового типа. "1" означает, что соответствующий элемент базового типа входит в множество, "0" - не входит. Чтобы для выполнения операций над множествами можно было прямо использовать машинные команды, нужно ограничить длину шкалы машинным словом.
1.6. Указатели
Понятие указателя в языках программирования является абстракцией понятия машинного адреса. Подобно тому, как зная машинный адрес можно обратиться к нужному элементу памяти, имея значение указателя, можно обратиться к соответствующей переменной. Различие между механизмами указателей в разных языках состоит главным образом в том, откуда берется значение указателя. Чем больше возможностей по работе с указателями, тем более эффективную программу можно написать и тем "опаснее" становится программирование. Обычно возможности оперирования указателями ограничиваются по мере повышения уровня языка и усиления его типизации.
В любом случае для объявления указательных переменных служат так называемые указательные, или ссылочные типы. Для определения указательного типа, значениями которого являются указатели на переменные встроенного или ранее определенного типа T0, в языке Паскаль используется конструкция type T = T0. В языке Си отсутствуют отдельные возможности определения указательного типа, и, чтобы объявить переменную var, которая будет содержать указатели на переменные типа T0, используется конструкция T0 *var. Но конечно, это чисто поверхностное отличие, а суть гораздо глубже.
В языках линии Паскаль переменной указательного типа можно присваивать только значения, вырабатываемые встроенной процедурой динамического выделения памяти new, значения переменных того же самого указательного типа и специальное "пустое" ссылочное значение nil, которое входит в любой указательный тип. Не допускаются преобразования типов указателей и какие-либо арифметические действия над их значениями. С переменной-указателем var можно выполнять только операцию var, обеспечивающую доступ к значению переменной типа T0, на которую указывает значение переменной var.
Напротив, в языках Си и Си++ имеется полная свобода работы с указателями. С помощью операции "&" можно получить значение указателя для любой переменной, над указателями определены арифметические действия, возможно явное преобразование указательных типов и даже преобразование целых типов к указательным типам. В этих языках не фиксируется значение "пустых" (ни на что не ссылающихся) указательных переменных. Имеется лишь рекомендация использовать в качестве такого значения константу с символическим именем NULL, определяемую в библиотечном файле включения. По сути дела, понятие указателя в этих языках очень близко к понятию машинного адреса.
Отмеченные свойства механизма указателей существенно повлияли на особенности реализации в языках Си и Си++ работы с массивами. Имя массива в этих языках интерпретируется как имя константного указателя на первый элемент массива. Операция доступа к i-тому элементу массива arr хотя и обозначается как и в языках линии Паскаль arr[i], имеет низкоуровневую интерпретацию *(arr+i). Поэтому было логично допустить подобную запись для любой переменной var с указательным типом: var[i] интерпретируется как *(var+i). По этой причине понятие массива в Си/Си++ существенно отличается от соответствующего понятия в Паскале. Размер массива существенен только при его определении и используется для выделения соответствующего объема памяти. При работе программы используется только имя массива как константный указатель соответствующего типа. Нет операций над "массивными переменными" целиком; в частности, невозможно присваивание. Фактически отсутствует поддержка массивов как параметров вызова функций - передаются именно значения указателей (в связи с этим, при описании формального параметра-массива его размер не указывается). Функции не могут вырабатывать "массивные" значения.
Как отмечалось выше, особенности работы с указателями в некоторой степени повлияли и на организацию структур. Хотя в описаниях языков Си и Си++ и рекомендациях по программированию присутствует настоятельный совет обращаться к полям структурных переменныхтолько по их именам, известно, что каждое имя на самом деле интерпретируется как смещение от начала структуры. Поэтому, имея значение указателя на начало структурной переменной и манипулируя известными длинами полей структуры, технически можно добраться до любого поля, не используя его имя.
Подводя итоги этого краткого обсуждения механизма указателей в Си/Си++, заметим, что позволяя программировать с очень большой эффективностью, этот механизм делает языки очень опасными для использования и требует от программистов большой аккуратности и сдержанности. При разработке получающего все большее распространение языка Java (одним из основных предков которого был Си++) для повышения уровня безопасности были резко ограничены именно средства работы с указателями в языке Си++.
1.7. Динамическое распределение памяти и списки
При решении ряда задач становится неудобно, неэффективно, а иногда и просто невозможно обойтись использованием памяти, выделяемой компилятором и системой поддержки времени выполнения в соответствии с явными описаниями переменных в программе. Во всех языках, более или менее приспособленных к практическому применению, имеется возможность явно запрашивать и использовать области так называемой динамической памяти. Такие области принято называть "динамическими переменными". Возможности создания и использования динамических переменных тесно связаны с механизмами указателей, поскольку динамическая переменная не имеет статически заданного имени, и доступ к такой переменной возможен только через указатель.
Как и во многих обсуждавшихся ранее случаях, механизмы работы с динамической памятью в языках с сильной типизацией существенно отличаются от соответствующих механизмов языков со слабой типизацией. В языках линии Паскаль для запроса динамических переменных используется встроенная процедура new(var), где var - переменная некоторого ссылочного типа T. Если тип T определялся конструкцией type T = T0, то при выполнении этой процедуры подсистема поддержки времени выполнения выделяет динамическую область памяти с размером, достаточным для размещения переменных типа T0, и переменной var присваивается ссылочное значение, обеспечивающее доступ к выделенной динамической переменной.
Понятно, что размеры области памяти, используемой для динамического выделения переменных, в любой реализации языка ограничены. Кроме того, обычно время полезного существования динамической переменной меньше времени выполнения программы, в которой эта переменная была создана. Поэтому наряду со средствами образования динамических переменных должны существовать средства освобождения памяти, занятой ставшими бесполезными динамическими переменными. В сильно типизированных языках для этого применяются два разных механизма.
Первый - это явное использование встроенной процедуры dispose(var), где var - переменная ссылочного типа, значение которой указывает на ранее выделенную и еще не освобожденную динамическую переменную. Строго говоря, при выполнении процедуры dispose должно быть не только произведено действие по освобождению памяти, но также переменной var и всем переменным того же ссылочного типа с тем же значением должно быть присвоено значение nil. Это гарантировало бы, что после вызова dispose в программе были бы невозможны некорректные обращения к освобожденной области памяти. К сожалению, обычно из соображений эффективности такая глобальная очистка не производится, и программирование с использованием динамической памяти становится достаточно опасным.
Второй механизм, обеспечивающий более безопасное программирование, состоит в том, что подсистема поддержки времени выполнения хранит ссылки на все выделенные динамические переменные и время от времени (обычно, когда объем свободной динамической памяти достигает некоторого нижнего предела) автоматически запускает процедуру "сборки мусора". Процедура просматривает содержимое всех существующих к этому моменту ссылочных переменных, и если оказывается что некоторые ссылки не являются значением ни одной ссылочной переменной, освобождает соответствующие области динамической памяти. Заметим, что это является возможным в силу наличия строгой типизации ссылочных переменных и отсутствия явных или неявных преобразований их типов.
Работа с динамической памятью в языках Си/Си++ гораздо проще и опаснее. Правильнее сказать, что в самих языках средства динамического выделения и освобождения памяти вообще отсутствуют. При программировании на языке Си для этих целей используются несколько функций из стандартной библиотеки stdlib, специфицированной в стандарте ANSI C. При реализации языка Си в среде ОС UNIX используются соответствующие функции из системной библиотеки stdlib.
Базовой функцией для выделения памяти является malloc(), входным параметром которой является размер требуемой области динамической памяти в байтах, а выходным - значение типа *void, указывающее на первый байт выделенной области. Гарантируется, что размер выделенной области будет не меньше запрашиваемого и что область будет выравнена так, чтобы в ней можно было корректно разместить значение любого типа данных. Тем самым, чтобы использовать значение, возвращаемое функцией malloc(), необходимо явно преобразовать его тип к нужному указательному типу.
Для освобождения ранее выделенной области динамической памяти используется функция free(). Ее входным параметром является значение типа *void, которое должно указывать на начало ранее выделенной динамической области. Поведение программы непредсказуемо при использовании указателей на ранее освобожденную память и при задании в качестве параметра функции free() некорректного значения.
Заметим, что по причине наличия возможности получить значение указателя на любую статически объявленную переменную, работа с указателями на статические и динамические переменные производится полностью единообразно. Единообразная работа с массивами и указателями естественным образом позволяет создавать и использовать динамические массивы.
Как видно, с динамической памятью в языках Си/Си++ работать можно очень эффективно, но программирование является опасным.
Используя структурные типы, указатели и динамические переменные, можно создавать разнообразные динамические структуры памяти - списки, деревья, графы и т.д. (Особенности указателей в языках Си/Си++ позволяют, вообще говоря, строить динамические структуры памяти на основе статически объявленных переменных или на смеси статических и динамических переменных.) Идея организации всех динамических структур одна и та же. Определяется некоторый структурный тип T, одно или несколько полей которого объявлены указателями на тот же или некоторый другой структурный тип. В программе объявляется переменная var типа T (или переменная типа указателя на T в случае полностью динамического создания структуры). Имя этой переменной при выполнении программы используется как имя "корня" динамической структуры. При выполнении программы по мере построения динамической структуры запрашиваются динамические переменные соответствующих типов и связываются ссылками, начиная с переменной var (или первой динамической переменной, указатель на которую содержится в переменной var). Понятно, что этот подход позволяет создать динамическую структуру с любой топологией.
Наиболее простой динамической структурой является однонаправленный список (рисунок 1.1). Для создания списка определяется структурный тип T, у которого имеется одно поле next, объявленное как указатель на T. Другие поля структуры содержат информацию, характеризующую элемент списка. При образовании первого элемента ("корня") списка в поле next заносится пустой указатель (nil или NULL). При дальнейшем построении списка это значение будет присутствовать в последнем элементе списка

Рис. 1.1.
Над списком, построенном в такой манере, можно выполнять операции поиска элемента, удаления элемента и занесение нового элемента в начало, конец или середину списка. Понятно, что все эти операции будут выполняться путем манипуляций над содержимым поля next существующих элементов списка. Для оптимизации операций над списком иногда создают вспомогательную переменную-структуру (заголовок списка), состоящую из двух полей - указателей на первый и последний элементы списка (рисунок 1.2). Для этих же целей создают двунаправленные списки, элементы которых, помимо поля next, включают поле previous, содержащее указатель на предыдущий элемент списка (рисунок 1.3) и, возможно, ссылки на заголовок списка (рисунок 1.4).
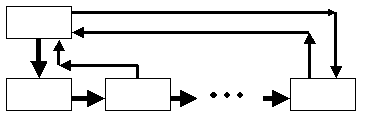
Рис. 1.2.
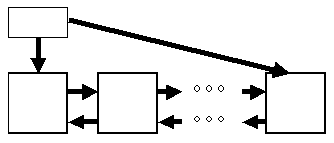
Рис. 1.3.
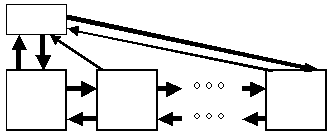
Рис. 1.4.
1.8. Абстрактные (определяемые пользователями) типы данных
На самом деле, оба термина, употребленные в названии раздела, плохо отражают суть соответствующего понятия. Термин "абстрактные типы" плох тем, что реально ничего абстрактного в этой категории типов нет. Термин "определяемые пользователями типы" не точно отражает специфику, поскольку все типы, обсуждавшиеся выше, кроме встроенных в языки программирования, так или иначе определяются пользователями. Тем не менее, в силу привычки, мы будем использовать в этом разделе словосочетание "абстрактные типы данных" (АТД).
Не обращая больше внимания на ущербность терминологии, займемся содержанием понятия АТД. Как мы видели, наличие перечисляемых, уточняемых и конструируемых типов данных в сочетании со средствами выделения динамической памяти позволяет конструировать и использовать структуры данных, достаточные для создания произвольно сложных программ. Ограниченность этих средств состоит в том, что при определении типов и создании структур невозможно зафиксировать правила их использования. Например, если определен структурный тип с полями salary, commissions и total в предположении, что для любой переменной этого типа поле total всегда будет содержать общую сумму выплат, то ничто не мешает по ошибке нарушить это условие (с точки зрения компилятора никакой ошибки нет) и получить неверные результаты работы программы.
Основной идеей АТД является то, что при его определении специфицируется не только структура значений типа, но и набор допустимых операций над переменными и значениями этого типа. В наиболее сильном случае доступ к внутренней структуре типа доступен только через его операции. В число операций обязаны входить один или несколько конструкторов значений типа.
Имеется много разновидностей языков с АТД, языковые средства которых весьма различаются. Кроме того, к этому семейству языков примыкают языки объектно-ориентированного программирования. По поводу них одни авторы (к числу которых относится и автор этой книги) полагают, что для них термин "язык объектно-ориентированного программирования" является модной заменой старого термина "язык с АТД". Другие находят между этими языковыми семействами много тонких отличий, часть которых считают серьезными. Мы не будем глубоко анализировать эти дискуссии, а обсудим некоторые базовые концепции, общие для обоих семейств.
1.8.1. Представление типа
При программировании с использованием АТД возможны три подхода (они могут быть смешаны): (1) перед началом написания основной программы полностью определить все требуемые типы данных; (2) определить только те характеристики АТД, которые требуются для написания программы и проверки ее синтаксической корректности; (3) воспользоваться готовыми библиотечными определениями. В каждом из этих подходов имеются свои достоинства и недостатки, но их объединяет то, что при написании программы известны по меньшей мере внешние характеристики всех типов данных. В некотором смысле это означает, что расширен язык программирования.
Подобная внешняя характеристика АТД называется его представлением или спецификацией. Представление включает имя АТД и набор спецификаций доступных пользователю операций со значениями этого типа. Со своей стороны, спецификация операции состоит из имени и типов параметров (в последнее время такие спецификации принято называть сигнатурами операций). Для однозначного определения компилятором того, какая реально функция или процедура должна быть вызвана при обращении к операции, обычно требуют, чтобы сигнатуры всех операций всех АТД, используемых в программе, были различны (мы еще вернемся к этой теме ниже при обсуждении возможностей полиморфизма).
Переменные, используемые для внутреннего представления значений типа называются переменными состояния, а их совокупность состоянием значений.
Иногда исходя из соображений эффективности допускается прямой доступ к некоторым переменным состояния значений типа (путем использования обычных предопределенных операций чтения и записи). В этом случае переменные состояния, доступные в таком режиме, также специфицируются во внешнем представлении типа.
1.8.2. Реализация типа
Реализация типа представляет собой многовходовой программный модуль, точки входа которого соответствуют набору операций реализуемого типа. Естественно, должно иметься полное соответствие реализации типа его спецификации. Набор статических переменных (в смысле языков Си/Си++) этого модуля образует структуру данных, используемую для представления значений типа. Такой же структурой обладает любая переменная данного абстрактного типа.
Иногда для целей реализации типа бывает полезно иметь в составе его операций такие, которые недоступны для внешнего использования и носят служебный характер. Такие функции и/или процедуры специальным образом помечаются в реализации типа (например, как приватные), и их сигнатуры не включаются во внешнюю спецификацию типа. Переменные состояния, которые должны быть прямо доступны для внешнего использования, также помечаются специальным образом.
1.8.3. Инкапсуляция
Существуют разные точки зрения относительно того, для чего наиболее полезно применять абстрактные типы данных. Многие считают, например, что основной смысл этого подхода состоит в развитии методов модульного структурного программирования. Это, конечно, верно, но с точки зрения автора наибольшее преимущество подхода абстрактных типов данных состоит в принципиальном разделении спецификации и реализации типа. Для правильного написания (а иногда и отладки) программы достаточно иметь набор спецификаций требуемых типов. Для каждой спецификации, вообще говоря, может существовать несколько реализаций, и при их корректном создании эти реализации могут быть взаимозаменяемыми.
В строго типизированных языках с абстрактными типами данных спецификация типа скрывает его реализацию. Внешнее представление типа инкапсулирует особенности его структурной и операционной реализации. До сих пор продолжаются споры о том, что является идеальной инкапсуляцией типа. В частности, многие полагают, что разрешение прямого доступа к переменным состояния нарушает принципы инкапсуляции. По всей видимости, это неверно. Если все возможные операции со значениями типа строго специфицированы в его внешнем представлении, то в любом случае могут допускаться различные реализации типа. Но, естественно, чем более высоким уровнем обладает спецификация, тем больше свобода при выборе реализации.
1.8.4. Наследование типов
Под наследованием типов понимается возможность дисциплинированного создания новых типов на основе уже определенных. Мы подчеркиваем слово "дисциплинированного", потому что, конечно, можно определять новые типы и произвольным образом, используя в качестве заготовок куски существующих программных текстов.
В отличие от этого, при использовании механизма наследования типов требуется, чтобы спецификация нового типа (подтипа) полностью включала спецификацию наследуемого типа (супертипа). Но эта спецификация может быть расширена сигнатурами дополнительных операций, вводимых для подтипа. Соответственно в реализации подтипа должны присутствовать коды функций и/или процедур дополнительных операций, а структуры данных, функции и процедуры супертипа могут быть переопределены.
В разных языках с абстрактными типами данных допускается либо только простое наследование типов (для каждого подтипа существует только один супертип), либо множественное наследование (для подтипа может существовать несколько супертипов). Множественное наследование порождает проблему согласования сигнатур операций супертипов. Общего решения этой проблемы не существует, в каждом из языков с множественным наследованием используются свои приемы. Мы не будем более подробно останавливаться на этих деталях.
Имеются два основных соображения по поводу пользы механизма наследования типов. Во-первых, этот механизм обеспечивает возможность контролируемого и дисциплинированного повторного использования программных кодов. Во-вторых (и может быть, это даже более важно), во многих языках используется так называемая семантика включения: считается, что значение любого подтипа одновременно является значением любого своего супертипа. Семантика включения хорошо соответствует смыслу механизма наследования как средства уточненной классификации объектов предметной области.
На рисунке 1.5 показана простая схема образования типов на основе одиночного наследования. Естественно, что в подтипах типа "Человек" появляются дополнительные операции, например, "размер пособия" для безработных и "должностной оклад" для служащих. Можно предположить, что операция "знание языков", вводимая для типа "Служащий", по-разному переопределяется для его подтипов "Программист" и "Преподаватель".
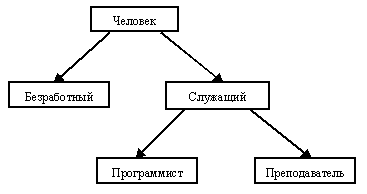
Рис. 1.5.
С другой стороны, очевидно, что из соображений здравого смысла и безработные, и служащие обладают общими свойствами, характерными для типа "Человек", а программисты и преподаватели относятся к категории "Служащие". Эти соображения приводят нас к рисунку 1.6, на котором показана иерархия включения значений этих типов данных. Это означает, что, в частности, должна иметься возможность единообразной работы со значениями типа "Человек" независимо от того, сформировано ли соответствующее значение конструктором этого типа или же конструктором любого из его подтипов. Конечно, при этом можно использовать только те операции, которые специфицированы во внешнем представлении типа "Человек".
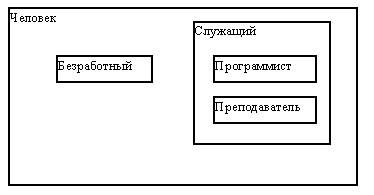
Рис. 1.6.
Поскольку в подтипе может быть переопределена реализация операций, специфицированных в супертипе, то во время компиляции программы иногда невозможно установить, какую функцию или процедуру требуется вызывать при выполнении операции над значением типа. По этой причине в системах программирования, поддерживающих развитый механизм наследования, для обеспечения корректного вызова функций и/или процедур, которые реализуют операции типа, приходится применять так называемый метод позднего связывания (late binding).
Суть этого метода состоит в том, что во время выполнения программы при каждом значении (или объекте в языках объектно-ориентированного программирования) содержится информация о типе, с помощью конструктора которого было создано это значение. На основе этой информации на стадии выполнения удается обнаружить требуемые реализации операций. Понятно, что применение метода позднего связывания вносит в процесс выполнения программы существенный элемент интерпретации, что приводит к снижению эффективности. Поэтому, по мере возможности, стремятся снизить накладные расходы даже за счет понижения универсальности механизма наследования. Примером может служить аппарат виртуальных функций в языке Си++.
1.8.5. Разновидности полиморфизма
Полиморфизм в языках программирования - это очень широкое и собирательное понятие, включающее разные аспекты. Мы остановимся только на полиморфизме операций типов в контексте приведенного выше материала. Можно выделить две разновидности полиморфных операций: (1) одноименные операции одного или нескольких типов, различающиеся сигнатурами, и (2) операции с общей сигнатурой, определяемые и переопределяемые в иерархии наследования типов.
Как кажется, основной причиной появления полиморфизма первого типа является желание использовать для обозначения операций абстрактных типов привычные знаки операций, принятые во встроенных типах данных. Например, если определяется абстрактный тип данных "комплексные числа", то было бы естественно использовать знак "+" для обозначения сложения, "-" - для обозначения вычитания и т.д. Кроме того, для того же типа хотелось бы использовать один и тот же знак "+" для обозначения операций сложения двух комплексных чисел, сложения комплексного числа с вещественным и вещественного с комплексным.
Технику, обеспечивающую возможность ввести новую интерпретацию уже используемых знаков операций и/или имен функций и процедур, принято называть "перегрузкой". Перегрузка существует и в языках, не поддерживающих абстрактные типы данных, в частности, в языке программирования Ада. Но, с нашей точки зрения, особенно существенны возможности перегрузки именно в языках с абстрактными типами данных.
Преимуществом полиморфизма на основе перегрузки является то, что для его поддержки требуется не слишком существенное усложнение компилятора и не возникают дополнительные накладные расходы во время выполнения программы. Обычно реализация основывается на использовании сигнатур функций и процедур. При соблюдении обязательного требования различия сигнатур всех одноименных функций и процедур достаточно просто придумать правила формирования расширенных имен на основе основного имени функции или процедуры и имен типов ее параметров. Если язык достаточно строго типизирован, и сигнатура любой доступной функции или процедуры находится в области видимости компилятора, то по имени и составу фактических параметров вызова можно определить расширенное имя требуемой подпрограммы. (Заметим, что если бы в программах на языке Си использование прототипов функций было бы обязательным, то можно было бы реализовать перегрузку имен функций и соответствующий полиморфизм даже в компиляторах чистого Си.)
Второй род полиморфизма операций типов и реализующих их функций и процедур возникает при переопределении в подтипе реализации операций супертипа. Как мы отмечали в предыдущем разделе, в этом случае сигнатуры операций изменяться не должны, и мы получаем разные реализации операции с одной сигнатурой. В этом случае возникающие неоднозначности невозможно разрешить во время компиляции программы, и приходится использовать упоминавшийся в предыдущем разделе метод позднего связывания.
Тем самым, хотя отмеченные виды полиморфизма на первый взгляд кажутся очень близкими, они существенно по-разному реализуются и порождают существенно разные накладные расходы. При всей привлекательности возможности переопределения операций в подтипах ими следует пользоваться осмотрительно.
1.9. Типы и структуры данных, применяемые в реляционных базах данных
В конце этой части книги мы коротко рассмотрим особенности использования типов и структур данных в системах управления базами данных (СУБД). Начнем с наиболее распространенных сегодня традиционных баз данных, основанных на чистой, классической реляционной модели данных. Одним из базовых свойств этой модели является атомарность значений в каждом из столбцов таблиц, составляющих базу данных. Другими словами, эти значения должны принадлежать к одному из встроенных типов, поддерживаемых СУБД.
Практически все современные реляционные СУБД опираются на стандартный язык баз данных SQL и поддерживают встроенные типы данных, специфицированные в этом языке. Если не вдаваться в синтаксические детали, то типы данных в стандарте языка SQL/92 определяются следующим образом:
Тип данных определяется как множество представляющих его значений. Логическим представлением значения является литерал. Физическое представление зависит от реализации.
Значение любого типа является примитивным в том смысле, что в соответствии со стандартом оно не может быть логически разбито на другие значения. Значения могут быть определенными или неопределенными. Неопределенное значение - это зависящее от реализации значение, которое гарантированно отлично от любого определенного значения соответствующего типа. Можно считать, что имеется всего одно неопределенное значение, входящее в любой тип данных языка SQL. Для неопределенного значения отсутствует представляющий его литерал, хотя в некоторых случаях используется ключевое слово NULL для выражения того, что желательно именно неопределенное значение.
SQL/92 определяются типы данных, обозначаемые следующими ключевыми словами: CHARACTER, CHARACTER VARYING, BIT, BIT VARYING, NUMERIC, DECIMAL, INTEGER, SMALLINT, FLOAT, REAL, DOUBLE PRECISION, DATE, TIME, TIMESTAMP и INTERVAL.
Типы данных CHARACTER и CHARACTER VARYING совместно называются типами данных символьных строк; типы данных BIT и BIT VARYING - типами данных битовых строк. Типы данных символьных строк и типы данных битовых строк совместно называются строчными типами данных, а значения строчных типов называются строками.
Типы данных NUMERIC, DECIMAL, INTEGER и SMALLINT совместно называются типами данных точных чисел. Типы данных FLOAT, REAL и DOUBLE PRECISION совместно называются типами данных приблизительных чисел. Типы данных точных чисел и типы данных приблизительных чисел совместно называются числовыми типами. Значения числовых типов называются числами.
Типы данных DATE, TIME и TIMESTAMP совместно называются типами даты-времени. Значения типов даты-времени называются "дата-время". Тип данных INTERVAL называется интервальным типом.
Поскольку основным способом использования языка SQL при создании прикладных информационных систем является встраивание операторов SQL в программы, написанные на традиционных языках программирования, необходимо для всех потенциально используемых языков программирования иметь правила соответствия встроенных типов SQL встроенным типам соответствующих языков. Стандарт обеспечивает такие соответствия. В частности, для языка Си установлены следующие соответствия: CHARACTER соответствует строкам Си (массивам символов, завершающимся "пустым" символом); INTEGER соответствует long; SMALLINT соответствует short; REAL соответствует float; DOUBLE PRECISION соответствует double. Естественно, это не означает, что в базах данных числа хранятся именно в той форме, в которой они представляются в Си-программе. Необходимые преобразования представлений обеспечиваются на интерфейсе прикладной программы и СУБД.
Важным понятием реляционных баз данных, зафиксированным в стандарте языка SQL, является понятие домена. Домен - это именованное множество значений некоторого встроенного типа, ограниченное условием, задаваемым при определении домена. Условие определяет вхождение значения базового типа во множество значений домена. В некотором смысле можно считать понятие домена расширением понятия ограниченного типа в языках программирования. В частности, если столбец C некоторой таблицы определен на домене D, то система гарантирует, что в этом столбце будут присутствовать только значения домена D. Кроме того, считается допустимым соединять таблицы T1 и T2 по значениям столбцов C1 и C2 только в том случае, когда C1 и C2 определены на общем домене D.
Значения всех упомянутых типов (и определенных на них доменов) имеют фиксированную или, по крайней мере, ограниченную длину. Даже для типов CHARACTER VARYING и BIT VARYING длина допустимого значения обычно ограничена размером страниц внешней памяти, используемых СУБД для хранения баз данных. В связи с потребностями современных приложений (географических, мультимедийных, категории CAD/CAM и т.д.) в большинстве СУБД поддерживается дополнительный, не специфицированный в стандарте SQL псевдотип данных с собирательным названием BLOB (Binary Large Object). Значения этого типа представляют собой последовательности байт, на которые на уровне СУБД не накладывается никакая более сложная структура и длина которых практически не ограничена (в 32-разрядных архитектурах - до 2 Гбт). Необходимая структуризация значений типа BLOB производится на прикладном уровне. Традиционные СУБД обеспечивают очень примитивный набор операций со столбцами типа BLOB - выбрать значение столбца в основную память или в файл и занести в столбец значение из основной памяти или файла.
1.10. Типы и структуры данных, применяемые в объектно-реляционных базах данных
Чисто реляционные базы данных обладают рядом ограничений, которые затрудняют их использование в приложениях, требующих богатого типового окружения. Это относится и к категорическому требованию использовать в столбцах таблиц только атомарные значения встроенных типов, и к невозможности определить новые типы данных (возможно, с атомарными значениями) с дополнительными или переопределенными операциями. Понятно, что ослабление этих ограничений приводит к потребности существенного пересмотра архитектуры серверных продуктов баз данных. В этой книге не рассматриваются требуемые архитектурные расширения и переделки. Мы остановимся только на расширениях системы типов и связанных с этим структурах данных.
В настоящее время отсутствует общая точка зрения относительно того, что должна обеспечивать объектно-реляционная СУБД по части обеспечения типовой среды (похоже, что до принятия следующего стандарта - SQL-3 - окончательной ясности так и не будет). Однако наличие на рынке по крайней мере трех развитых систем с объектно-реляционными расширениями дает возможность сделать небольшой предварительный обзор обязательных возможностей.
1.10.1. Строчные типы данных
Одним из недостатков классического реляционного подхода к построению баз данных является то, что при определении схемы таблицы ее имя одновременно становится именем самой таблицы. Т.е. отсутствует возможность отдельно определить именованную схему таблицы, а затем - одну или несколько таблиц с той же самой схемой. Для устранения этого недостатка (а также получения некоторых дополнительных преимуществ; см. ниже) в объектно-реляционных системах появилось понятие строчного типа.
Фактически, строчный тип - это именованная спецификация одного или более столбцов (для каждого столбца указывается имя, а также его тип или домен). После определения строчного типа можно специфицировать таблицы, заголовок которых соответствует этому типу или включает его как свою часть.
1.10.2. Наследование таблиц и семантика включения
Если таблица определена на одном строчном типе (без добавления столбцов), то разрешается использовать ее как супертаблицу и производить на ее основе подтаблицы с добавлением столбцов. При этом используется семантика включения.
Считается, что любая супертаблица включает строки всех своих подтаблиц, спроецированных на заголовок супертаблицы (кроме того, при работе с супертаблицей можно явно указать, что пользователя или прикладную программу интересуют только "собственные" строки супертаблицы). В ряде случаев использование механизма наследования таблиц с использованием семантики включения позволяет более правильно (без излишеств) спроектировать базу данных и обойтись без привлечения операторов объединения при формулировке сводных запросов.
1.10.3. Типы коллекций
Типы коллекций находятся ближе всего к конструируемым типам языков программирования и внедряются в объектно-реляционные базы данных, чтобы ликвидировать или, по крайней мере, смягчить ограничение первой нормальной формы (атомарности значений столбцов), накладываемое классической реляционной моделью данных. К типам коллекций относятся типы массива, списка и множества. Заметим, что в данном случае (в отличие от языков программирования) не устанавливаются ограничения на мощность базового типа множества (в силу специфики расположения данных во внешней памяти).
Для каждой разновидности типа коллекции имеется предопределенный набор операций (например, доступ к элементу массива по индексу). После определения любого типа коллекции его можно использовать как любой встроенный тип. В частности, типом столбца таблицы может быть тип множества, базовым типом которого является строчный тип. Понятно, что с использованием типов коллекций можно организовывать базы данных с произвольно сложной иерархической структурой.
1.10.4. Объектные типы данных
Эта разновидность типов ближе всего к абстрактным типам данных в языках программирования. Идея состоит в том, что сначала специфицируется определяемый пользователем тип данных (переименовывается некоторый встроенный тип, определяется строчный тип или тип коллекции). Затем для этого типа можно специфицировать (конечно, предварительно написав соответствующие программы) ряд определяемых пользователем функций. Строго говоря, после этого можно считать, что тип инкапсулирован этим набором функций, хотя не все разработчики считают строгую инкапсуляцию необходимой.
После полной спецификации объектного типа его можно использовать как встроенный или любой ранее определенный тип. Видимо, в будущих реализациях объектно-реляционных СУБД появится и полная возможность наследования объектных типов.
2. Методы внутренней сортировки
В этой и следующей частях книги мы будем обсуждать методы сортировки информации. В общей постановке задача ставится следующим образом. Имеется последовательность однотипных записей, одно из полей которых выбрано в качестве ключевого (далее мы будем называть его ключом сортировки). Тип данных ключа должен включать операции сравнения ("=", ">", "<", ">=" и "<="). Задачей сортировки является преобразование исходной последовательности в последовательность, содержащую те же записи, но в порядке возрастания (или убывания) значений ключа. Метод сортировки называется устойчивым, если при его применении не изменяется относительное положение записей с равными значениями ключа.
Различают сортировку массивов записей, целиком расположенных в основной памяти (внутреннюю сортировку), и сортировку файлов, хранящихся во внешней памяти и не помещающихся полностью в основной памяти (внешнюю сортировку). Для внутренней и внешней сортировки требуются существенно разные методы. В этой части мы рассмотрим наиболее известные методы внутренней сортировки, начиная с простых и понятных, но не слишком быстрых, и заканчивая не столь просто понимаемыми усложненными методами.
Естественным условием, предъявляемым к любому методу внутренней сортировки является то, что эти методы не должны требовать дополнительной памяти: все перестановки с целью упорядочения элементов массива должны производиться в пределах того же массива. Мерой эффективности алгоритма внутренней сортировки являются число требуемых сравнений значений ключа (C) и число перестановок элементов (M).
Заметим, что поскольку сортировка основана только на значениях ключа и никак не затрагивает оставшиеся поля записей, можно говорить о сортировке массивов ключей. В следующих разделах, чтобы не привязываться к конкретному языку программирования и его синтаксическим особенностям, мы будем описывать алгоритмы словами и иллюстрировать их на простых примерах.
2.1. Сортировка включением
Одним из наиболее простых и естественных методов внутренней сортировки является сортировка с простыми включениями. Идея алгоритма очень проста. Пусть имеется массив ключей a[1], a[2], ..., a[n]. Для каждого элемента массива, начиная со второго, производится сравнение с элементами с меньшим индексом (элемент a[i] последовательно сравнивается с элементами a[i-1], a[i-2] ...) и до тех пор, пока для очередного элемента a[j] выполняется соотношение a[j] > a[i], a[i] и a[j] меняются местами. Если удается встретить такой элемент a[j], что a[j] <= a[i], или если достигнута нижняя граница массива, производится переход к обработке элемента a[i+1] (пока не будет достигнута верхняя граница массива).
Легко видеть, что в лучшем случае (когда массив уже упорядочен) для выполнения алгоритма с массивом из n элементов потребуется n-1 сравнение и 0 пересылок. В худшем случае (когда массив упорядочен в обратном порядке) потребуется n?(n-1)/2 сравнений и столько же пересылок. Таким образом, можно оценивать сложность метода простых включений как O(n2).
Можно сократить число сравнений, применяемых в методе простых включений, если воспользоваться тем фактом, что при обработке элемента a[i] массива элементы a[1], a[2], ..., a[i-1] уже упорядочены, и воспользоваться для поиска элемента, с которым должна быть произведена перестановка, методом двоичного деления. В этом случае оценка числа требуемых сравнений становится O(n?log n). Заметим, что поскольку при выполнении перестановки требуется сдвижка на один элемент нескольких элементов, то оценка числа пересылок остается O(n2).
Таблица 2.1 Пример сортировки методом простого включения
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Шаг 1 |
8 23 5 65 44 33 1 6
|
| Шаг 2 |
8 5 23 65 44 33 1 6
5 8 23 65 44 33 1 6
|
| Шаг 3 |
5 8 23 65 44 33 1 6
|
| Шаг 4 |
5 8 23 44 65 33 1 6
|
| Шаг 5 |
5 8 23 44 33 65 1 6
5 8 23 33 44 65 1 6
|
| Шаг 6 |
5 8 23 33 44 1 65 6
5 8 23 33 1 44 65 6
5 8 23 1 33 44 65 6
5 8 1 23 33 44 65 6
5 1 8 23 33 44 65 6
1 5 8 23 33 44 65 6
|
| Шаг 7 |
1 5 8 23 33 44 6 65
1 5 8 23 33 6 44 65
1 5 8 23 6 33 44 65
1 5 8 6 23 33 44 65
1 5 6 8 23 33 44 65
|
Дальнейшим развитием метода сортировки с включениями является сортировка методом Шелла, называемая по-другому сортировкой включениями с уменьшающимся расстоянием. Мы не будем описывать алгоритм в общем виде, а ограничимся случаем, когда число элементов в сортируемом массиве является степенью числа 2. Для массива с 2n элементами алгоритм работает следующим образом. На первой фазе производится сортировка включением всех пар элементов массива, расстояние между которыми есть 2(n-1). На второй фазе производится сортировка включением элементов полученного массива, расстояние между которыми есть 2(n-2). И так далее, пока мы не дойдем до фазы с расстоянием между элементами, равным единице, и не выполним завершающую сортировку с включениями. Применение метода Шелла к массиву, используемому в наших примерах, показано в таблице 2.2.
Таблица 2.2. Пример сортировки методом Шелл
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Фаза 1 (сортируются элементы, расстояние между которыми четыре) |
8 23 5 65 44 33 1 6
8 23 5 65 44 33 1 6
8 23 1 65 44 33 5 6
8 23 1 6 44 33 5 65
|
| Фаза 2 (сортируются элементы, расстояние между которыми два) |
1 23 8 6 44 33 5 65
1 23 8 6 44 33 5 65
1 23 8 6 5 33 44 65
1 23 5 6 8 33 44 65
1 6 5 23 8 33 44 65
1 6 5 23 8 33 44 65
1 6 5 23 8 33 44 65
|
| Фаза 3 (сортируются элементы, расстояние между которыми один) |
1 6 5 23 8 33 44 65
1 5 6 23 8 33 44 65
1 5 6 23 8 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
В общем случае алгоритм Шелла естественно переформулируется для заданной последовательности из t расстояний между элементами h1, h2, ..., ht, для которых выполняются условия h1 = 1 и h(i+1) < hi. Дональд Кнут показал, что при правильно подобранных t и h сложность алгоритма Шелла является O(n(1.2)), что существенно меньше сложности простых алгоритмов сортировки.
2.2. Обменная сортировка
Простая обменная сортировка (в просторечии называемая "методом пузырька") для массива a[1], a[2], ..., a[n] работает следующим образом. Начиная с конца массива сравниваются два соседних элемента (a[n] и a[n-1]). Если выполняется условие a[n-1] > a[n], то значения элементов меняются местами. Процесс продолжается для a[n-1] и a[n-2] и т.д., пока не будет произведено сравнение a[2] и a[1]. Понятно, что после этого на месте a[1] окажется элемент массива с наименьшим значением. На втором шаге процесс повторяется, но последними сравниваются a[3] и a[2]. И так далее. На последнем шаге будут сравниваться только текущие значения a[n] и a[n-1]. Понятна аналогия с пузырьком, поскольку наименьшие элементы (самые "легкие") постепенно "всплывают" к верхней границе массива. Пример сортировки методом пузырька показан в таблице 2.3.
Таблица 2.3. Пример сортировки методом пузырька
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Шаг 1 |
8 23 5 65 44 33 1 6
8 23 5 65 44 1 33 6
8 23 5 65 1 44 33 6
8 23 5 1 65 44 33 6
8 23 1 5 65 44 33 6
8 1 23 5 65 44 33 6
1 8 23 5 65 44 33 6
|
| Шаг 2 |
1 8 23 5 65 44 6 33
1 8 23 5 65 6 44 33
1 8 23 5 6 65 44 33
1 8 23 5 6 65 44 33
1 8 5 23 6 65 44 33
1 5 8 23 6 65 44 33
|
| Шаг 3 |
1 5 8 23 6 65 33 44
1 5 8 23 6 33 65 44
1 5 8 23 6 33 65 44
1 5 8 6 23 33 65 44
1 5 6 8 23 33 65 44
|
| Шаг 4 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 5 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 6 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
| Шаг 7 |
1 5 6 8 23 33 44 65
|
Для метода простой обменной сортировки требуется число сравнений n?(n-1)/2, минимальное число пересылок 0, а среднее и максимальное число пересылок - O(n2).
Метод пузырька допускает три простых усовершенствования. Во-первых, как показывает таблица 2.3, на четырех последних шагах расположение значений элементов не менялось (массив оказался уже упорядоченным). Поэтому, если на некотором шаге не было произведено ни одного обмена, то выполнение алгоритма можно прекращать. Во-вторых, можно запоминать наименьшее значение индекса массива, для которого на текущем шаге выполнялись перестановки. Очевидно, что верхняя часть массива до элемента с этим индексом уже отсортирована, и на следующем шаге можно прекращать сравнения значений соседних элементов при достижении такого значения индекса. В-третьих, метод пузырька работает неравноправно для "легких" и "тяжелых" значений. Легкое значение попадает на нужное место за один шаг, а тяжелое на каждом шаге опускается по направлению к нужному месту на одну позицию.
На этих наблюдениях основан метод шейкерной сортировки (ShakerSort). При его применении на каждом следующем шаге меняется направление последовательного просмотра. В результате на одном шаге "всплывает" очередной наиболее легкий элемент, а на другом "тонет" очередной самый тяжелый. Пример шейкерной сортировки приведен в таблице 2.4.
Таблица 2.4. Пример шейкерной сортировки
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Шаг 1 |
8 23 5 65 44 33 1 6
8 23 5 65 44 1 33 6
8 23 5 65 1 44 33 6
8 23 5 1 65 44 33 6
8 23 1 5 65 44 33 6
8 1 23 5 65 44 33 6
1 8 23 5 65 44 33 6
|
| Шаг 2 |
1 8 23 5 65 44 33 6
1 8 5 23 65 44 33 6
1 8 5 23 65 44 33 6
1 8 5 23 44 65 33 6
1 8 5 23 44 33 65 6
1 8 5 23 44 33 6 65
|
| Шаг 3 |
1 8 5 23 44 6 33 65
1 8 5 23 6 44 33 65
1 8 5 6 23 44 33 65
1 8 5 6 23 44 33 65
1 5 8 6 23 44 33 65
|
| Шаг 4 |
1 5 6 8 23 44 33 65
1 5 6 8 23 44 33 65
1 5 6 8 23 44 33 65
1 5 6 8 23 33 44 65
|
| Шаг 5 |
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
1 5 6 8 23 33 44 65
|
Шейкерная сортировка позволяет сократить число сравнений (по оценке Кнута средним числом сравнений является (n2 - n?(const + ln n)), хотя порядком оценки по-прежнему остается n2. Число же пересылок, вообще говоря, не меняется. Шейкерную сортировку рекомендуется использовать в тех случаях, когда известно, что массив "почти упорядочен".
2.3. Сортировка выбором
При сортировке массива a[1], a[2], ..., a[n] методом простого выбора среди всех элементов находится элемент с наименьшим значением a[i], и a[1] и a[i] обмениваются значениями. Затем этот процесс повторяется для получаемых подмассивов a[2], a[3], ..., a[n], ... a[j], a[j+1], ..., a[n] до тех пор, пока мы не дойдем до подмассива a[n], содержащего к этому моменту наибольшее значение. Работа алгоритма иллюстрируется примером в таблице 2.5.
Таблица 2.5. Пример сортировки простым выбором
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Шаг 1 |
1 23 5 65 44 33 8 6
|
| Шаг 2 |
1 5 23 65 44 33 8 6
|
| Шаг 3 |
1 5 6 65 44 33 8 23
|
| Шаг 4 |
1 5 6 8 44 33 65 23
|
| Шаг 5 |
1 5 6 8 33 44 65 23
|
| Шаг 6 |
1 5 6 8 23 44 65 33
|
| Шаг 7 |
1 5 6 8 23 33 65 44
|
| Шаг 8 |
1 5 6 8 23 33 44 65
|
Для метода сортировки простым выбором требуемое число сравнений - n?(n-1)/2. Порядок требуемого числа пересылок (включая те, которые требуются для выбора минимального элемента) в худшем случае составляет O(n2). Однако порядок среднего числа пересылок есть O(n?ln n), что в ряде случаев делает этот метод предпочтительным.
2.4. Сортировка разделением (Quicksort)
Метод сортировки разделением был предложен Чарльзом Хоаром (он любит называть себя Тони) в 1962 г. Этот метод является развитием метода простого обмена и настолько эффективен, что его стали называть "методом быстрой сортировки - Quicksort".
Основная идея алгоритма состоит в том, что случайным образом выбирается некоторый элемент массива x, после чего массив просматривается слева, пока не встретится элемент a[i] такой, что a[i] > x, а затем массив просматривается справа, пока не встретится элемент a[j] такой, что a[j] < x. Эти два элемента меняются местами, и процесс просмотра, сравнения и обмена продолжается, пока мы не дойдем до элемента x. В результате массив окажется разбитым на две части - левую, в которой значения ключей будут меньше x, и правую со значениями ключей, большими x. Далее процесс рекурсивно продолжается для левой и правой частей массива до тех пор, пока каждая часть не будет содержать в точности один элемент. Понятно, что как обычно, рекурсию можно заменить итерациями, если запоминать соответствующие индексы массива. Проследим этот процесс на примере нашего стандартного массива (таблица 2.6).
Таблица 2.6. Пример быстрой сортировки
| Начальное состояние массива |
8 23 5 65 |44| 33 1 6
|
| Шаг 1 (в качестве x выбирается a[5]) |
|--------|
8 23 5 6 44 33 1 65
|---|
8 23 5 6 1 33 44 65
|
| Шаг 2 (в подмассиве a[1], a[5] в качестве x выбирается a[3]) |
8 23 |5| 6 1 33 44 65
|--------|
1 23 5 6 8 33 44 65
|--|
1 5 23 6 8 33 44 65
|
| Шаг 3 (в подмассиве a[3], a[5] в качестве x выбирается a[4]) |
1 5 23 |6| 8 33 44 65
|----|
1 5 8 6 23 33 44 65
|
| Шаг 4 (в подмассиве a[3], a[4] выбирается a[4]) |
1 5 8 |6| 23 33 44 65
|--|
1 5 6 8 23 33 44 65
|
Алгоритм недаром называется быстрой сортировкой, поскольку для него оценкой числа сравнений и обменов является O(n?log n). На самом деле, в большинстве утилит, выполняющих сортировку массивов, используется именно этот алгоритм.
2.5. Сортировка с помощью дерева (Heapsort)
Начнем с простого метода сортировки с помощью дерева, при использовании которого явно строится двоичное дерево сравнения ключей. Построение дерева начинается с листьев, которые содержат все элементы массива. Из каждой соседней пары выбирается наименьший элемент, и эти элементы образуют следующий (ближе к корню уровень дерева). Из каждой соседней пары выбирается наименьший элемент и т.д., пока не будет построен корень, содержащий наименьший элемент массива. Двоичное дерево сравнения для массива, используемого в наших примерах, показано на рисунке 2.1. Итак, мы уже имеем наименьшее значение элементов массива. Для того, чтобы получить следующий по величине элемент, спустимся от корня по пути, ведущему к листу с наименьшим значением. В этой листовой вершине проставляется фиктивный ключ с "бесконечно большим" значением, а во все промежуточные узлы, занимавшиеся наименьшим элементом, заносится наименьшее значение из узлов - непосредственных потомков (рис. 2.2). Процесс продолжается до тех пор, пока все узлы дерева не будут заполнены фиктивными ключами (рисунки 2.3 - 2.8).
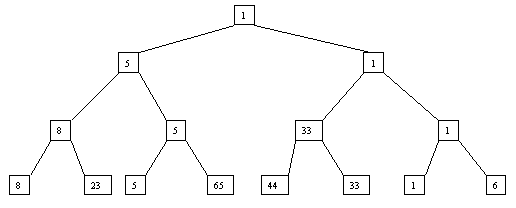
Рис. 2.1.
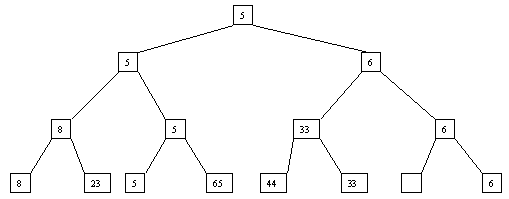
Рис. 2.2. Второй шаг
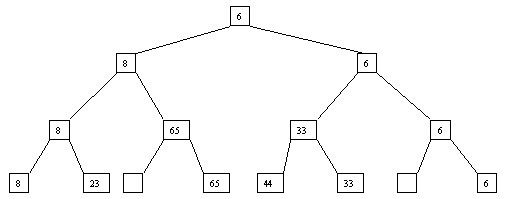
Рис. 2.3. Третий шаг
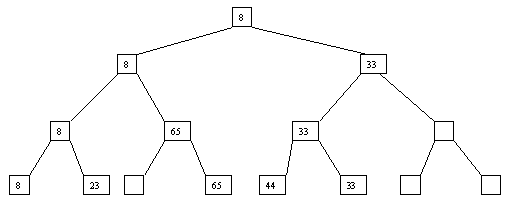
Рис. 2.4. четвертый шаг
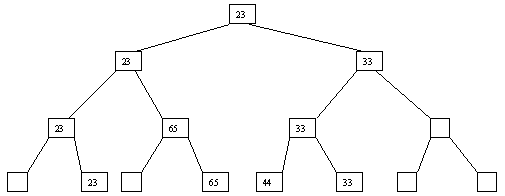
Рис. 2.5. Пятый шаг
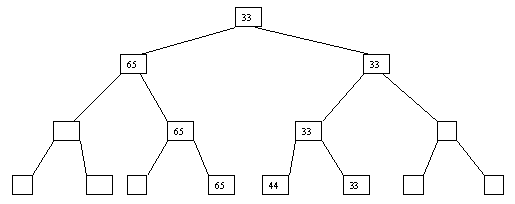
Рис. 2.6. Шестой шаг
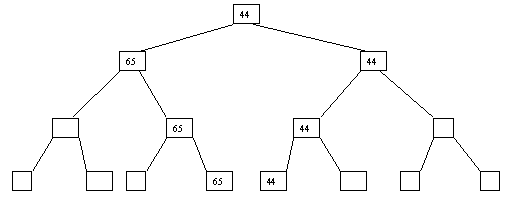
Рис. 2.7. Седьмой шаг
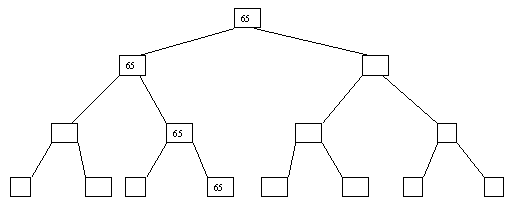
Рис. 2.8. Восьмой шаг
На каждом из n шагов, требуемых для сортировки массива, нужно log n (двоичный) сравнений. Следовательно, всего потребуется n?log n сравнений, но для представления дерева понадобится 2n - 1 дополнительных единиц памяти.
Имеется более совершенный алгоритм, который принято называть пирамидальной сортировкой (Heapsort). Его идея состоит в том, что вместо полного дерева сравнения исходный массив a[1], a[2], ..., a[n] преобразуется в пирамиду, обладающую тем свойством, что для каждого a[i] выполняются условия a[i] <= a[2i] и a[i] <= a[2i+1]. Затем пирамида используется для сортировки.
Наиболее наглядно метод построения пирамиды выглядит при древовидном представлении массива, показанном на рисунке 2.9. Массив представляется в виде двоичного дерева, корень которого соответствует элементу массива a[1]. На втором ярусе находятся элементы a[2] и a[3]. На третьем - a[4], a[5], a[6], a[7] и т.д. Как видно, для массива с нечетным количеством элементов соответствующее дерево будет сбалансированным, а для массива с четным количеством элементов n элемент a[n] будет единственным (самым левым) листом "почти" сбалансированного дерева.
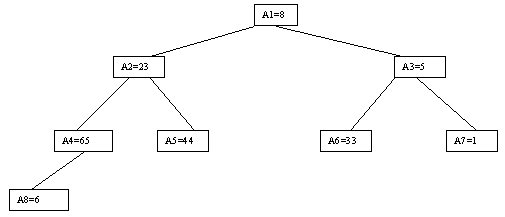
Рис. 2.9.
Очевидно, что при построении пирамиды нас будут интересовать элементы a[n/2], a[n/2-1], ..., a[1] для массивов с четным числом элементов и элементы a[(n-1)/2], a[(n-1)/2-1], ..., a[1] для массивов с нечетным числом элементов (поскольку только для таких элементов существенны ограничения пирамиды). Пусть i - наибольший индекс из числа индексов элементов, для которых существенны ограничения пирамиды. Тогда берется элемент a[i] в построенном дереве и для него выполняется процедура просеивания, состоящая в том, что выбирается ветвь дерева, соответствующая min(a[2?i], a[2?i+1]), и значение a[i] меняется местами со значением соответствующего элемента. Если этот элемент не является листом дерева, для него выполняется аналогичная процедура и т.д. Такие действия выполняются последовательно для a[i], a[i-1], ..., a[1]. Легко видеть, что в результате мы получим древовидное представление пирамиды для исходного массива (последовательность шагов для используемого в наших примерах массива показана на рисунках 2.10-2.13).
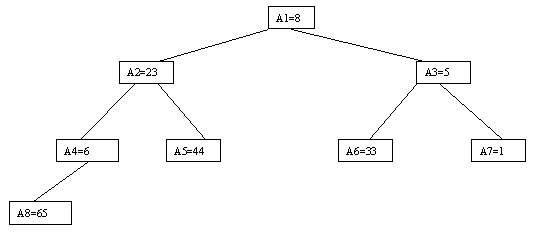
Рис. 2.10.
Рис. 2.11.
Рис. 2.12.
Рис. 2.13.
В 1964 г. Флойд предложил метод построения пирамиды без явного построения дерева (хотя метод основан на тех же идеях). Построение пирамиды методом Флойда для нашего стандартного массива показано в таблице 2.7.
Таблица 2.7 Пример построения пирамиды
| Начальное состояние массива |
8 23 5 |65| 44 33 1 6
|
| Шаг 1 |
8 23 |5| 6 44 33 1 65
|
| Шаг 2 |
8 |23| 1 6 44 33 5 65
|
| Шаг 3 |
|8| 6 1 23 44 33 5 65
|
| Шаг 4 |
1 6 8 23 44 33 5 65
1 6 5 23 44 33 8 65
|
В таблице 2.8 показано, как производится сортировка с использованием построенной пирамиды. Суть алгоритма заключается в следующем. Пусть i - наибольший индекс массива, для которого существенны условия пирамиды. Тогда начиная с a[1] до a[i] выполняются следующие действия. На каждом шаге выбирается последний элемент пирамиды (в нашем случае первым будет выбран элемент a[8]). Его значение меняется со значением a[1], после чего для a[1] выполняется просеивание. При этом на каждом шаге число элементов в пирамиде уменьшается на 1 (после первого шага в качестве элементов пирамиды рассматриваются a[1], a[2], ..., a[n-1]; после второго - a[1], a[2], ..., a[n-2] и т.д., пока в пирамиде не останется один элемент). Легко видеть (это иллюстрируется в таблице 2.8), что в результате мы получим массив, упорядоченный в порядке убывания. Можно модифицировать метод построения пирамиды и сортировки, чтобы получить упорядочение в порядке возрастания, если изменить условие пирамиды на a[i] >= a[2?i] и a[1] >= a[2?i+1] для всех осмысленных значений индекса i.
Таблица 2.8 Сортировка с помощью пирамиды
| Исходная пирамида |
1 6 5 23 44 33 8 65
|
| Шаг 1 |
65 6 5 23 44 33 8 1
5 6 65 23 44 33 8 1
5 6 8 23 44 33 65 1
|
| Шаг 2 |
65 6 8 23 44 33 5 1
6 65 8 23 44 33 5 1
6 23 8 65 44 33 5 1
|
| Шаг 3 |
33 23 8 65 44 6 5 1
8 23 33 65 44 6 5 1
|
| Шаг 4 |
44 23 33 65 8 6 5 1
23 44 33 65 8 6 5 1
|
| Шаг 5 |
65 44 33 23 8 6 5 1
33 44 65 23 8 6 5 1
|
| Шаг 6 |
65 44 33 23 8 6 5 1
44 65 33 23 8 6 5 1
|
| Шаг 7 |
65 44 33 23 8 6 5 1
|
Процедура сортировки с использованием пирамиды требует выполнения порядка n?log n шагов (логарифм - двоичный) в худшем случае, что делает ее особо привлекательной для сортировки больших массивов.
2.6. Сортировка со слиянием
Сортировки со слиянием, как правило, применяются в тех случаях, когда требуется отсортировать последовательный файл, не помещающийся целиком в основной памяти. Методам внешней сортировки посвящается следующая часть книги, в которой основное внимание будет уделяться методам минимизации числа обменов с внешней памятью. Однако существуют и эффективные методы внутренней сортировки, основанные на разбиениях и слияниях.
Один из популярных алгоритмов внутренней сортировки со слияниями основан на следующих идеях (для простоты будем считать, что число элементов в массиве, как и в нашем примере, является степенью числа 2). Сначала поясним, что такое слияние. Пусть имеются два отсортированных в порядке возрастания массива p[1], p[2], ..., p[n] и q[1], q[2], ..., q[n] и имеется пустой массив r[1], r[2], ..., r[2?n], который мы хотим заполнить значениями массивов p и q в порядке возрастания. Для слияния выполняются следующие действия: сравниваются p[1] и q[1], и меньшее из значений записывается в r[1]. Предположим, что это значение p[1]. Тогда p[2] сравнивается с q[1] и меньшее из значений заносится в r[2]. Предположим, что это значение q[1]. Тогда на следующем шаге сравниваются значения p[2] и q[2] и т.д., пока мы не достигнем границ одного из массивов. Тогда остаток другого массива просто дописывается в "хвост" массива r.
Пример слияния двух массивов показан на рисунке 2.14.
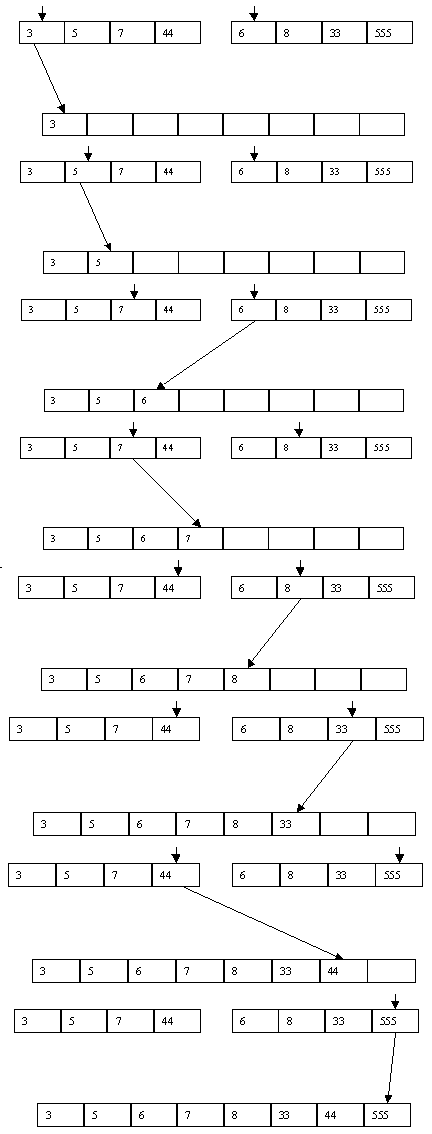
Рис. 2.14.
Для сортировки со слиянием массива a[1], a[2], ..., a[n] заводится парный массив b[1], b[2], ..., b[n]. На первом шаге производится слияние a[1] и a[n] с размещением результата в b[1], b[2], слияние a[2] и a[n-1] с размещением результата в b[3], b[4], ..., слияние a[n/2] и a[n/2+1] с помещением результата в b[n-1], b[n]. На втором шаге производится слияние пар b[1], b[2] и b[n-1], b[n] с помещением результата в a[1], a[2], a[3], a[4], слияние пар b[3], b[4] и b[n-3], b[n-2] с помещением результата в a[5], a[6], a[7], a[8], ..., слияние пар b[n/2-1], b[n/2] и b[n/2+1], b[n/2+2] с помещением результата в a[n-3], a[n-2], a[n-1], a[n]. И т.д. На последнем шаге, например (в зависимости от значения n), производится слияние последовательностей элементов массива длиной n/2 a[1], a[2], ..., a[n/2] и a[n/2+1], a[n/2+2], ..., a[n] с помещением результата в b[1], b[2], ..., b[n].
Для случая массива, используемого в наших примерах, последовательность шагов показана в таблице 2.9.
Таблица 2.9. Пример сортировки со слиянием
| Начальное состояние массива |
8 23 5 65 44 33 1 6
|
| Шаг 1 |
6 8 1 23 5 33 44 65
|
| Шаг 2 |
6 8 44 65 1 5 23 33
|
| Шаг 3 |
1 5 6 8 23 33 44 65
|
При применении сортировки со слиянием число сравнений ключей и число пересылок оценивается как O(n?log n). Но следует учитывать, что для выполнения алгоритма для сортировки массива размера n требуется 2?n элементов памяти.
2.7. Сравнение методов внутренней сортировки
Для рассмотренных в начале этой части простых методов сортировки существуют точные формулы, вычисление которых дает минимальное, максимальное и среднее число сравнений ключей (C) и пересылок элементов массива (M). Таблица 2.10 содержит данные, приводимые в книге Никласа Вирта.
Таблица 2.10. Характеристики простых методов сортировки
| | Min | Avg | Max |
| Прямое включение |
C = n-1
M = 2x(n-1)
|
(n2 + n - 2)/4
(n2 - 9n - 10)/4
|
(n2 -n)/2 - 1
(n2 -3n - 4)/2
|
| Прямой выбор |
C = (n2 - n)/2
M = 3x(n-1)
|
(n2 - n)/2
nx(ln n + 0.57)
|
(n2 - n)/2
n2/4 + 3x(n-1)
|
| Прямой обмен |
C = (n2 - n)/2
M = 0
|
(n2 - n)/2
(n2 - n)x0.75
|
(n2 - n)/2
(n2 - n)x1.5
|
Для оценок сложности усовершенствованных методов сортировки точных формул нет. Известно лишь, что для сортировки методом Шелла порядок C и M есть O(n(1.2)), а для методов Quicksort, Heapsort и сортировки со слиянием - O(n?log n). Однако результаты экспериментов показывают, что Quicksort показывает результаты в 2-3 раза лучшие, чем Heapsort (в таблице 2.11 приводится выборка результатов из таблицы, опубликованной в книге Вирта; результаты получены при прогоне программ, написанных на языке Модула-2). Видимо, по этой причине именно Quicksort обычно используется в стандартных утилитах сортировки (в частности, в утилите sort, поставляемой с операционной системой UNIX).
Таблица 2.11. Время работы программ сортировк
| |
Упорядоченный массив |
Случайный массив |
В обратном порядке |
|
|
n = 256
|
Heapsort
Quicksort
Сортировка со слиянием
|
0.20
0.20
0.20
|
0.08
0.12
0.08
|
0.18
0.18
0.18
|
|
|
n = 2048
|
Heapsort
Quicksort
Сортировка со слиянием
|
2.32
2.22
2.12
|
0.72
1.22
0.76
|
1.98
2.06
1.98
|
3. Методы внешней сортировки
Принято называть "внешней" сортировкой сортировку последовательных файлов, располагающихся во внешней памяти и слишком больших, чтобы можно было целиком переместить их в основную память и применить один из рассмотренных в предыдущем разделе методов внутренней сортировки. Наиболее часто внешняя сортировка применяется в системах управления базами данных при выполнении запросов, и от эффективности применяемых методов существенно зависит производительность СУБД.
Следует пояснить, почему речь идет именно о последовательных файлах, т.е. о файлах, которые можно читать запись за записью в последовательном режиме, а писать можно только после последней записи. Методы внешней сортировки появились, когда наиболее распространенными устройствами внешней памяти были магнитные ленты. Для лент чисто последовательный доступ был абсолютно естественным. Когда произошел переход к запоминающим устройствам с магнитными дисками, обеспечивающими "прямой" доступ к любому блоку информации, казалось, что чисто последовательные файлы потеряли свою актуальность. Однако это ощущение было ошибочным.
Все дело в том, что практически все используемые в настоящее время дисковые устройства снабжены подвижными магнитными головками. При выполнении обмена с дисковым накопителем выполняется подвод головок к нужному цилиндру, выбор нужной головки (дорожки), прокрутка дискового пакета до начала требуемого блока и, наконец, чтение или запись блока. Среди всех этих действий самое большое время занимает подвод головок. Именно это время определяет общее время выполнения операции. Единственным доступным приемом оптимизации доступа к магнитным дискам является как можно более "близкое" расположение на накопителе последовательно адресуемых блоков файла. Но и в этом случае движение головок будет минимизировано только в том случае, когда файл читается или пишется в чисто последовательном режиме. Именно с такими файлами при потребности сортировки работают современные СУБД.
Следует также заметить, что на самом деле скорость выполнения внешней сортировки зависит от размера буфера (или буферов) основной памяти, которая может быть использована для этих целей. Мы остановимся на этом в конце этой части книги. Сначала же мы рассмотрим основные методы внешней сортировки, работающие при минимальных расходах основной памяти.
3.1. Прямое слияние
Начнем с того, как можно использовать в качестве метода внешней сортировки алгоритм простого слияния, обсуждавшийся в конце предыдущей части. Предположим, что имеется последовательный файл A, состоящий из записей a1, a2, ..., an (снова для простоты предположим, что n представляет собой степень числа 2). Будем считать, что каждая запись состоит ровно из одного элемента, представляющего собой ключ сортировки. Для сортировки используются два вспомогательных файла B и C (размер каждого из них будет n/2).
Сортировка состоит из последовательности шагов, в каждом из которых выполняется распределение состояния файла A в файлы B и C, а затем слияние файлов B и C в файл A. (Заметим, что процедура слияния для файлов полностью иллюстрируется рисунком 2.14.) На первом шаге для распределения последовательно читается файл A, и записи a1, a3, ..., a(n-1) пишутся в файл B, а записи a2, a4, ..., an - в файл C (начальное распределение). Начальное слияние производится над парами (a1, a2), (a3, a4), ..., (a(n-1), an), и результат записывается в файл A. На втором шаге снова последовательно читается файл A, и в файл B записываются последовательные пары с нечетными номерами, а в файл C - с четными. При слиянии образуются и пишутся в файл A упорядоченные четверки записей. И так далее. Перед выполнением последнего шага файл A будет содержать две упорядоченные подпоследовательности размером n/2 каждая. При распределении первая из них попадет в файл B, а вторая - в файл C. После слияния файл A будет содержать полностью упорядоченную последовательность записей. В таблице 3.1 показан пример внешней сортировки простым слиянием.
Таблица 3.1. Пример внешней сортировки прямым слиянием
|
Начальное состояние файла A
|
8 23 5 65 44 33 1 6
|
Первый шаг
Распределение
Файл B
Файл C
Слияние: файл A
|
8 5 44 1
23 65 33 6
8 23 5 65 33 44 1 6
|
Второй шаг
Распределение
Файл B
Файл C
Слияние: файл A
|
8 23 33 44
5 65 1 6
5 8 23 65 1 6 33 44
|
Третий шаг
Распределение
Файл B
Файл C
Слияние: файл A
|
5 8 23 65
1 6 33 44
1 5 6 8 23 33 44 65
|
Заметим, что для выполнения внешней сортировки методом прямого слияния в основной памяти требуется расположить всего лишь две переменные - для размещения очередных записей из файлов B и C. Файлы A, B и C будут O(log n) раз прочитаны и столько же раз записаны.
3.2. Естественное слияние
При использовании метода прямого слияния не принимается во внимание то, что исходный файл может быть частично отсортированным, т.е. содержать упорядоченные подпоследовательности записей. Серией называется подпоследовательность записей ai, a(i+1), ..., aj такая, что ak <= a(k+1) для всех i <= k < j, ai < a(i-1) и aj > a(j+1). Метод естественного слияния основывается на распознавании серий при распределении и их использовании при последующем слиянии.
Как и в случае прямого слияния, сортировка выполняется за несколько шагов, в каждом из которых сначала выполняется распределение файла A по файлам B и C, а потом слияние B и C в файл A. При распределении распознается первая серия записей и переписывается в файл B, вторая - в файл C и т.д. При слиянии первая серия записей файла B сливается с первой серией файла C, вторая серия B со второй серией C и т.д. Если просмотр одного файла заканчивается раньше, чем просмотр другого (по причине разного числа серий), то остаток недопросмотренного файла целиком копируется в конец файла A. Процесс завершается, когда в файле A остается только одна серия. Пример сортировки файла показан на рисунках 3.1 и 3.2.
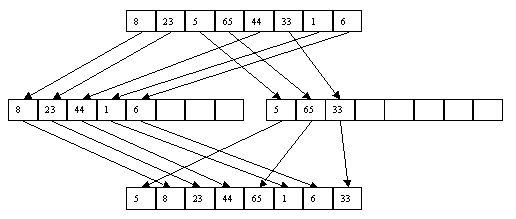
Рис. 3.1. Первый шаг
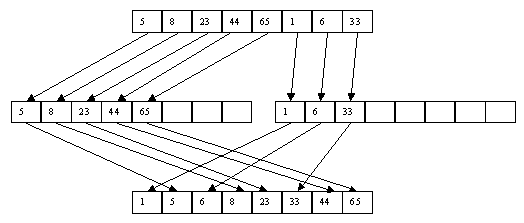
Рис. 3.2. Второй шаг
Очевидно, что число чтений/перезаписей файлов при использовании этого метода будет не хуже, чем при применении метода прямого слияния, а в среднем - лучше. С другой стороны, увеличивается число сравнений за счет тех, которые требуются для распознавания концов серий. Кроме того, поскольку длина серий может быть произвольной, то максимальный размер файлов B и C может быть близок к размеру файла A.
3.3. Сбалансированное многопутевое слияние
В основе метода внешней сортировки сбалансированным многопутевым слиянием является распределение серий исходного файла по m вспомогательным файлам B1, B2, ..., Bm и их слияние в m вспомогательных файлов C1, C2, ..., Cm. На следующем шаге производится слияние файлов C1, C2, ..., Cm в файлы B1, B2, ..., Bm и т.д., пока в B1 или C1 не образуется одна серия.
Многопутевое слияние является естественным развитием идеи обычного (двухпутевого) слияния, иллюстрируемого рисунком 2.14. Пример трехпутевого слияния показан на рисунке 3.3.
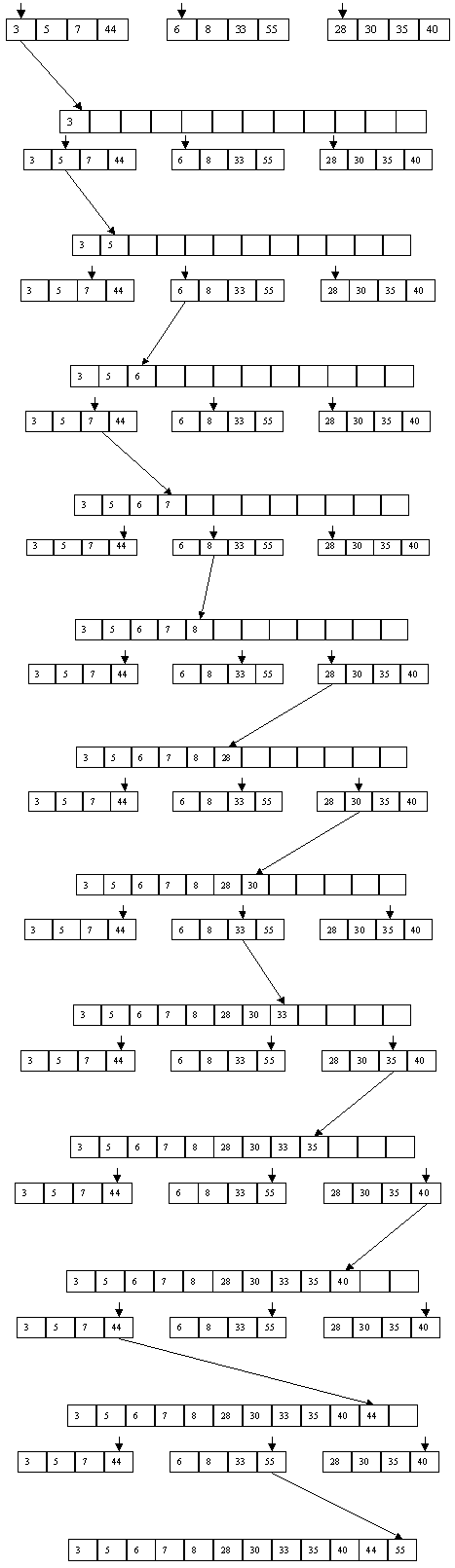
Рис. 3.3.
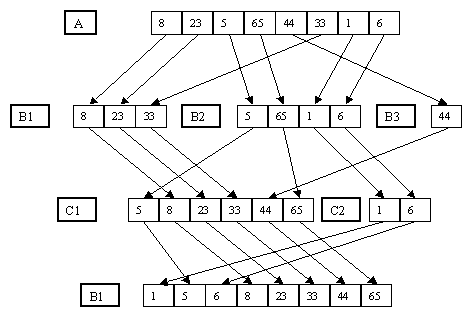
Рис. 3.4.
На рисунке 3.4 показан простой пример применения сортировки многопутевым слиянием. Он, конечно, слишком тривиален, чтобы продемонстрировать несколько шагов выполнения алгоритма, однако достаточен в качестве иллюстрации общей идеи метода. Заметим, что, как показывает этот пример, по мере увеличения длины серий вспомогательные файлы с большими номерами (начиная с номера n) перестают использоваться, поскольку им "не достается" ни одной серии. Преимуществом сортировки сбалансированным многопутевым слиянием является то, что число проходов алгоритма оценивается как O(log n) (n - число записей в исходном файле), где логарифм берется по основанию n. Порядок числа копирований записей - O(log n). Конечно, число сравнений не будет меньше, чем при применении метода простого слияния.
3.4. Многофазная сортировка
При использовании рассмотренного выше метода сбалансированной многопутевой внешней сортировки на каждом шаге примерно половина вспомогательных файлов используется для ввода данных и примерно столько же для вывода сливаемых серий. Идея многофазной сортировки состоит в том, что из имеющихся m вспомогательных файлов (m-1) файл служит для ввода сливаемых последовательностей, а один - для вывода образуемых серий. Как только один из файлов ввода становится пустым, его начинают использовать для вывода серий, получаемых при слиянии серий нового набора (m-1) файлов. Таким образом, имеется первый шаг, при котором серии исходного файла распределяются по m-1 вспомогательному файлу, а затем выполняется многопутевое слияние серий из (m-1) файла, пока в одном из них не образуется одна серия.
Очевидно, что при произвольном начальном распределении серий по вспомогательным файлам алгоритм может не сойтись, поскольку в единственном непустом файле будет существовать более, чем одна серия. Предположим, например, что используется три файла B1, B2 и B3, и при начальном распределении в файл B1 помещены 10 серий, а в файл B2 - 6. При слиянии B1 и B2 к моменту, когда мы дойдем до конца B2, в B1 останутся 4 серии, а в B3 попадут 6 серий. Продолжится слияние B1 и B3, и при завершении просмотра B1 в B2 будут содержаться 4 серии, а в B3 останутся 2 серии. После слияния B2 и B3 в каждом из файлов B1 и B2 будет содержаться по 2 серии, которые будут слиты и образуют 2 серии в B3 при том, что B1 и B2 - пусты. Тем самым, алгоритм не сошелся (таблица 3.2).
Таблица 3.2. Пример начального распределения серий, при котором трехфазная внешняя сортировка не приводит к нужному результату
| Число серий в файле B1 | Число серий в файле B2 | Число серий в файле B3 |
| 10 | 6 | 0 |
| 4 | 0 | 6 |
| 0 | 4 | 2 |
| 2 | 2 | 0 |
| 0 | 0 | 2 |
Попробуем понять, каким должно быть начальное распределение серий, чтобы алгоритм трехфазной сортировки благополучно завершал работу и выполнялся максимально эффективно. Для этого рассмотрим работу алгоритма в обратном порядке, начиная от желательного конечного состояния вспомогательных файлов. Нас устраивает любая комбинация конечного числа серий в файлах B1, B2 и B3 из (1,0,0), (0,1,0) и (0,0,1). Для определенности выберем первую комбинацию. Для того, чтобы она сложилась, необходимо, чтобы на непосредственно предыдущем этапе слияний существовало распределение серий (0,1,1). Чтобы получить такое распределение, необходимо, чтобы на непосредственно предыдущем этапе слияний распределение выглядело как (1,2,0) или (1,0,2). Опять для определенности остановимся на первом варианте. Чтобы его получить, на предыдущем этапе годились бы следующие распределения: (3,0,2) и (0,3,1). Но второй вариант хуже, поскольку он приводится к слиянию только одной серии из файлов B2 и B3, в то время как при наличии первого варианта распределения будут слиты две серии из файлов B1 и B3. Пожеланием к предыдущему этапу было бы наличие распределения (0,3,5), еще раньше - (5,0,8), еще раньше - (13,8,0) и т.д.
Это рассмотрение показывает, что метод трехфазной внешней сортировки дает желаемый результат и работает максимально эффективно (на каждом этапе сливается максимальное число серий), если начальное распределение серий между вспомогательными файлами описывается соседними числами Фибоначчи. Напомним, что последовательность чисел Фибоначчи начинается с 0, 1, а каждое следующее число образуется как сумма двух предыдущих:
(0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ....)
Аналогичные (хотя и более громоздкие) рассуждения показывают, что в общем виде при использовании m вспомогательных файлов условием успешного завершения и эффективной работы метода многофазной внешней сортировки является то, чтобы начальное распределение серий между m-1 файлами описывалось суммами соседних (m-1), (m-2), ..., 1 чисел Фибоначчи порядка m-2. Последовательность чисел Фибоначчи порядка p начинается с p нулей, (p+1)-й элемент равен 1, а каждый следующий равняется сумме предыдущих p+1 элементов. Ниже показано начало последовательности чисел Фибоначчи порядка 4:
(0, 0, 0, 0, 1, 1, 2, 4, 8, 16, 31, 61, ...)
При использовании шести вспомогательных файлов идеальными распределениями серий являются следующие:
1 0 0 0 0
1 1 1 1 1
2 2 2 2 1
4 4 4 3 2
8 8 7 6 4
16 15 14 12 8
........
Понятно, что если распределение основано на числе Фибоначчи fi, то минимальное число серий во вспомогательных файлах будет равно fi, а максимальное - f(i+1). Поэтому после выполнения слияния мы получим максимальное число серий - fi, а минимальное - f(i-1). На каждом этапе будет выполняться максимально возможное число слияний, и процесс сойдется к наличию всего одной серии.
Поскольку число серий в исходном файле может не обеспечивать возможность такого распределения серий, применяется метод добавления пустых серий, которые в дальнейшем как можно более равномерного распределяются между промежуточными файлами и опознаются при последующих слияниях. Понятно, что чем меньше таких пустых серий, т.е. чем ближе число начальных серий к требованиям Фибоначчи, тем более эффективно работает алгоритм.
3.5. Улучшение эффективности внешней сортировки за счет использования основной памяти
Понятно, что чем более длинные серии содержит файл перед началом применения внешней сортировки, тем меньше потребуется слияний и тем быстрее закончится сортировка. Поэтому до начала применения любого из методов внешней сортировки, основанных на применении серий, начальный файл частями считывается в основную память, к каждой части применяется один из наиболее эффективных алгоритмов внутренней сортировки (обычно Quicksort или Heapsort) и отсортированные части (образующие серии) записываются в новый файл (в старый нельзя, потому что он чисто последовательный).
Кроме того, конечно, при выполнении распределений и слияний используется буферизация блоков файла(ов) в основной памяти. Возможный выигрыш в производительности зависит от наличия достаточного числа буферов достаточного размера.

