Хорошие идеи: взгляд из Зазеркалья
Никлаус ВиртПеревод: Сергей Кузнецов
Оригинал: Good Ideas, through the Looking Glass by Niklaus Wirth, Computer, V. 39, No 1, January 2006
История вычислительной техники и программирования развивалась под влиянием многих хороших и оригинальных идей, но некоторые из них оказались менее блестящими, чем выглядели при своем появлении. Во многих случаях важность идей уменьшилась по причине изменений технологической среды. Часто на важность хорошей идеи влияли коммерческие факторы. Некоторые идеи просто оказывались менее эффективными и яркими при их ретроспективном рассмотрении или после тщательного анализа. Другие идеи являлись реинкарнацией идей, появившихся ранее и впоследствии забытых, возможно, потому что они опередили свое время, возможно, потому что они не отвечали текущим моде и тенденциям. А некоторые идеи появлялись заново, хотя они были востребованы уже в своей первой инкарнации.
Это навело меня на мысль собрать хорошие идеи, выглядящие менее привлекательными в ретроспективе. Эту работу мотивировало недавнее выступление Чарльза Тэкера (Charles Daniel Thacker) об устаревших идеях - тех, которые с возрастом деградировали. Я также вновь открыл для себя статью Дона Кнута (Donald Ervin Knuth), называемую "Опасности теории компьютерной науки" ("The Dangers of Computer Science Theory"). Тэкер представил свое выступление в далеком Китае, Кнут - за Железным занавесом в Румынии в 1970 г., оба эти места находятся в безопасности от разрушительной "западной критики". Документ Кнута, его ироническая позиция в особенности подвигли меня к написанию этих заметок.*
ТЕХНОЛОГИЯ АППАРАТУРЫ
Основной заботой компьютерных инженеров всегда была скорость. Одним из путей достижения этой цели является совершенствование существующих методов, другим путем служит поиск альтернативных решений. Следующие подходы, казавшиеся при своем появлении наиболее обещающими, оказались в конечном счете неуспешными.Память на цилиндрических магнитных доменах
Идея памяти на цилиндрических магнитных доменах появилась в то время, когда доминировали запоминающие устройства на магнитных сердечниках. Как обычно, сторонники этой идеи возлагали на нее большие надежды, планируя заменить соответствующими устройствами все виды устройств с механическим вращением, основным источником неприятностей и ненадежностей. Хотя цилиндрические магнитные домены все равно должны были вращаться в магнитном поле внутри ферритового материала, устройство не содержало механически движущихся частей. Подобно дискам, они представляли собой последовательные устройства, но быстрое развитие технологии дисков лишило привлекательности объем и скорость устройств на магнитных доменах, так что разработчики после нескольких лет исследований тихо похоронили эту идею.Криогеника
Криогенные устройства представляли собой новую технологию, высокие надежды на которую были живы в течение десятилетий, в особенности, в области суперкомпьютеров. Эти устройства обещали обеспечить сверхвысокие скорости переключений, но для обеспечения работоспособности крупных компьютерных систем при температуре, близкой к абсолютному нулю, потребовались непомерные усилия. Появление персональных компьютеров заморозило или развеяло криогенные мечты.Туннельные диоды
Некоторые разработчики предлагали использовать туннельные диоды - названные так по той причине, что они основывались на квантовом эффекте прохода электронов через энергетический барьер без наличия необходимой энергии - вместо транзисторов как элементов переключения и хранения.У туннельного диода имеется особая характеристика с отрицательным участком. Это позволяет ему принимать два стабильных состояния. Туннельный диод является германиевым устройством и не содержит кремниевых составляющих. Это позволяет ему работать только в относительно узком диапазоне температур. Кремниевые транзисторы стали быстрее и дешевле, что заставило исследователей забыть туннельных диодах.
АРХИТЕКТУРА КОМПЬЮТЕРОВ
Эта тема обеспечивает благодатную область для поиска хороших идей. Фундаментальной проблемой является представление чисел, в особенности целых.Представление чисел
Здесь ключевым вопросом является выбор основания числа. Практически все ранние компьютеры характеризовались основанием 10 - представление на основе десятичных цифр, как каждого из нас учат в школе.Однако двоичное представление с использованием двоичных цифр является, очевидно, более экономичным. Для представления целого числа n требуется log10(n) десятичных цифр, но всего лишь log2(n) двоичных цифр (бит). Поскольку для представления десятичной цифры требуется четыре бита, для десятичного представления требуется примерно на 20% больше памяти, чем для двоичного, что показывает очевидное преимущество двоичной формы. Тем не менее, разработчики долгое время сохраняли десятичное представление, и оно присутствует и сегодня в форме библиотечного модуля. Это связано с тем, что разработчики продолжали верить в необходимость точности всех вычислений.
Однако ошибки возникают при округлении, например, после выполнения операции деления. Эффекты округления могут различаться в зависимости от способа представления чисел, и двоичный компьютер может выдать результаты, отличающиеся от результатов десятичного компьютера. Поскольку финансовые транзакции - где более всего существенна точность - традиционно выполнялись вручную с использованием десятичной арифметики, разработчики полагали, что компьютеры должны производить во всех случаях те же результаты - и, следовательно, фиксировать те же ошибки.
Двоичная форма в общем случае приводит к более точные результатам, но десятичная форма остается предпочтительным вариантом в финансовых приложениях, поскольку десятичный результат в случае потребности легко проверить вручную.
Эта понятная идея, очевидно, являлась консервативной. Заметим, что до пришествия в 1964 г. IBM System/360, в которой поддерживалась как двоичная, так и десятичная арифметика, производители крупных компьютеров предлагали две линейки продуктов: двоичные компьютеры для научных потребителей и десятичные компьютеры для коммерческих потребителей - дорогостоящий подход.
В ранних компьютерах целые числа представлялись своим модулем и отдельным знаковым битом. В машинах, основанных на последовательном сложении, бит за битом, по порядку чтения, система размещала знак в младшем разряде. Когда стала возможной параллельная обработка, знак переместился в старший разряд, снова аналогично общепринятой бумажной нотации. Однако использование представления "знак-модуль" было плохой идеей, поскольку для положительных и отрицательных чисел требовались разные схемы.
Очевидно, что намного лучшее решение обеспечило представление отрицательных чисел в виде дополнения, поскольку одна и та же схема могла выполнять и сложение, и вычитание. Некоторые разработчики выбирали дополнение до единицы, когда -n получалось из n путем простого инвертирования всех бит. Некоторые выбирали дополнение до двойки, когда -n получалось путем инвертирования всех бит и прибавлением единицы. Недостатком первого способа было наличие двух форм нуля (0...0 и 1...1). Это неприятно, особенно, если доступные инструкции сравнения являются неадекватными.
Например, в компьютерах CDC 6000 имелась инструкция для проверки значения на ноль, корректно распознающая обе формы, но также присутствовала и инструкция, проверяющая только знаковый бит и относящая 1...1 к отрицательным числам, что неоправданно усложняло сравнения. Это пример неадекватной разработки раскрывает ущербность идеи дополнения до единицы. Сегодня во всех компьютерах используется арифметика с дополнением до двойки. Эти разные формы показаны в таблице 1.
Таблица 1. Использование арифметики с дополнением до двойки во избежание двусмысленных результатов
| Десятичное представление | Представление с дополнением до двойки | Представление с дополнением до единицы |
| 2 | 010 | 010 |
| 1 | 001 | 001 |
| 0 | 000 | 000 или 111 |
| -1 | 111 | 110 |
| -2 | 110 | 101 |
Числа с дробной частью можно представлять в формах с фиксированной и плавающей точкой. Сегодня в аппаратуре обычно поддерживается арифметика с плавающей точкой, т.е. число x представляется двумя целыми числами - порядком e и мантиссой m, так что x=Bem.
Некоторое время разработчики спорили о том, какое следует выбрать основание B для представления порядка. Вместо традиционного B=2 в Burroughs B5000 использовалось B=8, а в IBM 360 - B=16. Намерение состояло в том, чтобы сэкономить место за счет меньшего диапазона значений порядка и ускорить нормализацию, поскольку сдвиги происходили только на более крупных шагах в позициях 3-го или 4-го битов.
Однако это оказалось плохой идеей, поскольку усугубляло эффекты округления. В результате для IBM 360 можно было найти такие значения x и y, что для некоторого малого положительного ε выполнялось соотношение (x+ε)*(y+ε)<(x * y). Умножение утрачивало свойство монотонности. Такое умножение является ненадежным и потенциально опасным.
Адресация данных
В ранних компьютерах инструкции состояли просто из кода операции и абсолютного адреса параметра или его литерального значения. Это делало неизбежной самомодификацию программ. Например, если требовалось сложить в цикле числа, хранимые в последовательных ячейках памяти, программа должна была на каждом шаге модифицировать адрес в инструкции сложения, прибавляя к нему единицу.Хотя разработчики объявляли возможность модификации программ одним из важных следствий глубокой идеи Джона фон Неймана (John von Neumann) о хранении программы и данных в одной и той же памяти, этот подход оказался опасным и неограниченным источником ошибок. Программный код должен оставаться неприкосновенным; в противном случае поиск ошибок становится ночным кошмаром. Разработчики быстро поняли, что самомодификация программ является плохой идеей.
Чтобы избежать этих ошибок, они ввели новый режим адресации, в котором адрес трактовался как часть изменяемых данных, а не как часть программной инструкции, которую было бы лучше оставить неприкосновенной. Решение вовлекало косвенную адресацию и модификацию только непосредственно адресуемого адреса, слова данных.
Хотя этот подход устранял опасность самомодификации программ и использовался в большинстве компьютеров до середины 1970-х, в ретроспективе его следует рассматривать как сомнительную идею. В конце концов, для обеспечения каждого доступа к данным требовалось произвести два обращения к памяти, что вызывало замедление вычислений.
"Остроумная" идея многоуровневой косвенности еще более ухудшила ситуацию. Данные, к которым производился доступ, должны были содержать бит, показывающий, содержит ли данное слово желаемые данные или же еще один - возможно, снова косвенный - адрес. При задании цикла косвенных адресов такие машины могли войти в состояние полного бездействия.
Решение состояло во введении индексных регистров. Значение, хранимое в индексном регистре, могло прибавляться к константному адресу, который содержался в инструкции. Для этого требовалось добавить в состав аппаратуры несколько индексов и внедрить сложитель в сумматор арифметического устройства. В IBM 360 все регистры были объединены в единую группу регистров, что теперь является привычным.
Своеобразный механизм использовался в компьюторах CDC 6000. Команды непосредственно обращались только к регистрам, которые делились на три группы: 60-битные регистры (X), 18-битные регистры (A) и 18-битные регистры (B). Каждое обращение к A-регистру, значение которого модифицировалось путем прибавления значения B-регистра, неявно вызывало доступ к памяти. Странным было то, что обращения к регистрам A0-A5 приводили к чтению из адресуемой ячейки памяти в регистры X0-X5 соответственно, а обращения к A6 или A7 приводили к сохранению X6 или X7 соответственно.
Хотя этот механизим не вызывал каких-либо серьезных проблем, мы можем ретроспективно отнести его к категории заурядных идей, потому что номер регистра определяет выполняемую операцию и, тем самым, направление пересылки данных. Не считая этого, CDC 6000 отличалась замечательными идеями, прежде всего, своей простотой. Хотя Сигмур Крей (Seymour Roger Cray) спроектировал ее в 1962 г., задолго до появления термина "reduced-instruction-set computer", CDC 6000 можно несомненно назвать первым RISC-компьютером.
В машине Burroughs B5000 появилась более сложная схема адресации - дескрипторная схема, использовавшаяся в основном для указания массивов. Так называемый дескриптор данных являлся, по существу, косвенным адресом, но он также содержал граничные значения индексов, проверяемые во время доступа. Хотя автоматическая проверка индексов являлась отличной и почти фантастической возможностью, дескрипторная схема оказалась сомнительной идеей, поскольку для матриц (многомерных массивов) требовался массив дескрипторов, по одному на строку или столбец матрицы. Для каждого доступа к n-мерной матрице требовалась n-кратная косвенность. Очевидно, что схема не только замедляла доступ из-за косвенности, но также требовала наличия дополнительных строк дескрипторов. Тем не менее, в 1995 г. эту идею переняли разработчики Java, а за ними в 2000 г. и разработчики C#.
Стеки выражений
Язык Algol 60 оказал сильное влияние на разработку последующих языков программирования и, в меньшей степени, архитектур компьютеров. Это не удивительно, поскольку язык, компилятор и компьютер образуют неразрывный комплекс.В Algol можно было вычислять выражения произвольной сложности с подвыражениями, заключенными в скобки, и операциями с индивидуальной связующей способностью. Результаты подвыражений временно сохранялись. Фридрих Бауер (Friedrich Ludwig Bauer) и Эдсгер Дийкстра (Edsger Wybe Dijkstra) независимо предложили схему вычисления произвольных выражений. Они заметили, что при вычислении выражения слева направо с учетом правил приоритетов операций и скобок первым всегда потребуется последний сохраненный элемент. Поэтому его можно помещать в список с проталкиванием вниз, или стек.
Эта простая стратегия очевидным образом реализовывалась с использованием группы регистров путем добавления неявного реверсивного счетчика, сохраняющего верхний индекс регистра. Применение такого стека сокращало число обращений к памяти и позволяло избежать явного указания в инструкциях конкретных регистров. Коротко говоря, стековые компьютеры казались отличной идеей, и эта схема была реализована в компьютерах English Electric KDF-9 и Burroughs B5000, хотя это, очевидно, повысило сложность аппаратуры.
Поскольку регистры являлись дорогостоящими ресурсами, возникал вопрос о требуемой глубине стека. В итоге в B5000 использовались всего два регистра и автоматическое проталкивание в память, если требовалось сохранить более двух промежуточных результатов. Это казалось разумным. Как показал Кнут в результате анализа многих программ на языке Fortran, для подавляющего большинства выражений требуются один или два регистра.
Тем не менее, идея стека выражений оказалась сомнительной, в особенности после пришествия в середине 1960-х гг. архитектур с группами регистров. Стековая организация ограничивала использование дефицитного ресурса фиксированной стратегией. Усложненные же алгоритмы компиляции позволяли использовать регистры более экономно путем гибкого указания конкретных регистров в каждой инструкции.
Сохранение адреса возврата в коде
Инструкция перехода на подпрограмму, предложенная Дэвидом Уилером (David John Wheeler), сохраняет значение счетчика команд, которое должно быть восстановлено при завершении подпрограммы. Проблема состоит в выборе места для сохранения этого значения. В нескольких компьютерах, в основном, в миникомпьютерах, но также и в мейнфрейме CDC 6000, инструкция такого перехода на ячейку с адресомd сохраняла адрес возврата в этой ячейке и продолжала выполнение с адреса d+1:
mem[d] := PC+1; PC := d+1.Эта идея была плохой, по крайней мере, по двум причинам. Во-первых, это не давало возможности вызывать подпрограммы рекурсивно. В языке Algol была введена рекурсия, и это вызвало многочисленные споры по причине невозможности обрабатывать рекурсивные вызовы процедур таким простым образом, поскольку рекурсивный вызов затирал адрес возврата предыдущего вызова. Поэтому приходилось считывать адрес возврата из фиксированного места и помещать в место, уникальное для конкретного воплощения рекурсивной процедуры. Эти накладные расходы были неприемлемы для многих разработчиков и пользователей компьютеров, заставляя их объявлять рекурсию нежелательной, бесполезной и запретной. Они отказывались признать, что эти трудности порождались неадекватностью инструкции вызова.
Во-вторых, это решение оказалось плохой идеей, потому что не допускало мультипроцессирования. Поскольку код програмы и данные не хранились раздельно, у каждого параллельного процесса должна была иметься собственная копия кода.
В нескольких более поздних разработках аппаратуры, в особенности в архитектуре RISC в 1990-х, для обработки рекурсивных вызовов процедур были введены особые регистры, предназначеные для адреса стека, и адреса возврата сохранялись в стеке в соответствии со значениями этих регистров. Наилучшим оказалось сохранение адресов в регистре общего назначения (при наличии группы регистров), поскольку это решение оставляет свободу выбора разработчикам компиляторов, сохраняя основную инструкцию вызова подпрограммы настолько эффективной, насколько это возможно.
Виртуальная адресация
Как и у разработчиков компиляторов, у разработчиков операционных систем имелись собственные любимые идеи, которые им хотелось реализовать. Подобные желания появились после пришествия концепций мультипроцессирования и разделения времени, которые вообще породили операционные системы.Руководящая идея состояла в оптимальном использовании процессора, в его переключении на другую программу, как только текущая выполняемая программа блокируется, например, операцией ввода или вывода. Тем самым, разные программы выполнялись перекрывающимися частями, квазипараллельно. Вследствие этого, запросы на выделение и освобождение памяти поступали в непредсказуемой, случайной последовательности. Хуже того, физическая память обычно была недостаточно большой для размещения процессов в количестве, достаточным для того, чтобы мультипрограммирование приносило пользу.
Разработчики нашли остроумное решение этой дилеммы - косвенную адресацию, скрытую на этот раз от программиста. Память подразделялась на блоки, или страницы фиксированной длины, равной степени двойки. В системе использовалась таблица страниц, отображавшая виртуальный адрес в физический. В результате индивидуальные страницы могли располагаться в памяти где угодно, и даже будучи разбросанными, они создавали видимость непрерывного пространства. Более того, страницы, для которых не находились слоты в памяти, могли сохраняться на больших дисках. Бит в соответствующем элементе таблицы страниц показывал, находится ли страница в данное время на диске или же в основной памяти.
Эта остроумная и сложная схема, полезная в свое время, породила некоторые проблемы. Практически во всей современной компьютерной аппаратуре требуется подерживать таблицы страниц и отображение адресов и скрывать расходы на косвенную адресацию - не говоря уже про сохранение страниц на диске и восстановление их в памяти в непредсказуемые моменты времени - от ничего не подозревающего пользователя.
Даже сегодня в большинстве процессоров используется отображение страниц, и большинство операционных систем работает в многопользовательском режиме. Но эта идея стала сомнительной, поскольку полупроводниковая память достигла таких больших размеров, что отображение и замещение страниц перестали приносить пользу. Тем не менее, накладные расходы на поддержание сложного механизма косвенной адресации остаются с нами.
По иронии судьбы виртуальная адресация используется и для того, для чего никогда не предназначалась. Для отслеживания ссылок на несуществующие объекты используется значение указателя NIL. NIL представляется как 0, и поэтому страница с адресом 0 никогда не выделяется. Эта уловка основана на неправильном использовании виртуальной адресации, и от нее следует отказаться.
Сложные наборы инструкций
В ранних компьютерах поддерживались небольшие наборы инструкций, поскольку они основывались на минимальном числе дорогостоящих схем. По мере удешевления аппаратных средств появилось искушение введения более сложных инструкций, таких как инструкция условного перехода; инструкция, увеличивающая значение операнда, сравнивающая его со значением другого операнда и осуществляющая условный переход; сложные операции пересылки с преобразованием.После появления языков высокого уровня разработчики стали пытаться поддерживать некоторые языковые конструкции машинными инструкциями, соответствующим образом приспособленными, например, для поддержки оператора for или рекурсивных вызовов процедур языка Algol. Специализированные инструкции представляли собой разумную идею, поскольку способствовали повышению плотности кода, важному фактору в то время, когда память была скудным ресурсом с размером не более чем 64 Кб.
Эта тенденция установилась в 1963 г. В машине Burroughs B5000 не только поддерживались многие усложненные конструкции языка Algol; она сочетала особенности научного компьютера с возможностями машины обработки символов и строк и включала в себя два компьютера с разными наборами инструкций. Такая экстравагантность стала возможной за счет использования техники микропрограмм, которые сохранялись в быстрой памяти, доступной только по чтению. Этот подход сделал жизнеспособной и идею семейства машин. Семейство IBM Series 360 состояло из набора компьютеров, которые все обладали одним и тем же набором инструкций и одной и той же архитектурой, по крайней мере, с точки зрения программиста. Однако внутренняя организация индивидуальных представителей семейства чрезвычайно различалась. Машины низшего класса были микропрограммными; аппаратура выполняла короткие микропрограммы, интерпретируя код инструкций. Однако в машинах высшего класса все инструкции реализовывались напрямую. Эта технология продолжала использоваться в однокристальных микропроцессорах 8086 компании Intel, 68000 компании Motorola и 32000 компании National Semiconductor (NS).
Процессор NS представляет собой хороший пример компьютера со сложной системой команд (complex instruction-set computer, CISC). Сжатие часто встречающихся паттернов инструкций в одну инструкцию существенно улучшало плотность кода и сокращало число обращений к памяти, что повышало скорость выполнения.
В процессоре NS поддерживалась, например, новая концепция модулей и раздельной компиляции на основе использования соответствующей инструкции вызова. Сегменты кода связывались при загрузке, а компилятор обеспечивал таблицы со связующей информацией. Минимизация числа операций связывания, которые заменяют ссылки на таблицу связей абсолютными адресами, безусловно, является хорошей идеей. Схема, упрощающая задачу редактора связей, приводит к специальной организации хранения каждого модуля, как показывает рис. 1.
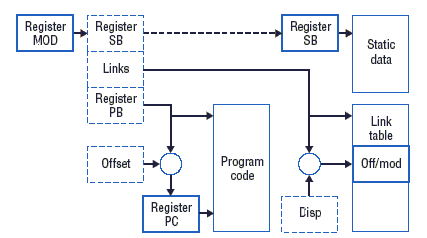
Рис. 1. Организация хранения модуля.
Выделенный регистр MOD указывает на дескриптор модуля M, который содержит процедуру, выполняемую в настоящее время. Регистр PC - это обычный счетчик команд. Регистр SB указывает на сегмент данных модуля M, включающего статические, глобальные переменные M. Значения всех этих регистров изменяются при выполнении системного вызова внешней процедуры. Для ускорения этого процесса в процессоре наряду с инструкцией обычного перехода на подпрограмму (BSR) поддерживалась инструкция вызова внешней процедуры (CXP). Соответственно, поддерживались и две инструкции возврата - RTS и RXP.
Предположим теперь, что требуется активизировать процедуру P в модуле M. Параметр d инструкции CXP указывает на элемент таблицы связей. На основе этого система получает адрес дескриптора M и смещение точки входа в P в сегменте кода. Затем система получает из дескриптора адрес сегмента данных M и загружает его в SB - все это делается при выполнении одной короткой инструкции. Однако за получаемые простоту связывания и плотность кода нужно было чем-то платить, и платить приходилось увеличенным числом косвенных ссылок и, между прочим, дополнительной аппаратурой - регистрами MOD и SB.
Аналогичным примером является инструкция проверки границ массива. Она сравнивала индекс массива с нижней и верхней границами массива и вызывала системное прерывание, если значение индекса не находилось в этом диапазоне, объединяя, тем самым, две инструкции сравнения и две инструкции ветвления.
Несколько лет спустя, после того, как был разработан и выпущен компилятор языка Oberon, появились новые, более быстрые версии процессора. Разработчики стремились реализовывать прямо в аппаратуре часто используемые, простые инструкции и интерпретировать сложные инструкции на внутреннем микрокоде. В результате этого инструкции, ориентированные на поддержку языка, становились существенно медленнее простых операций. Поэтому при программировании новой версии компилятора я не использовал усложненные инструкции.
Это привело к удивительным результатам. Новый код выполнялся существенно быстрее, из чего следовало, что разработчики архитектуры компьютера и компилятора оптимизировали не то, что требовалось.
И действительно, в начале 1980-х развитые микропроцессоры начали конкурировать со старыми мейнфреймами, обладающими сложными и необычными наборами инструкций. Эти наборы становились настолько сложными, что большинство программистов использовало только их небольшие части. Да и в компиляторах использовалось только подмножество доступных инструкций, что ясно показывало, что разработчики аппаратных архитектур зашли слишком далеко.
В районе 1990 г. реакция проявилась в форме RISC-машин - прежде всего, архитектур ARM, MIPS и Sparc. В них поддерживались небольшой набор простых инструкций, каждая из которых выполнялась за один такт, единственный режим адресации и довольно большой набор коротких регистров единой структуры. Появление этих архитектур показало, что идея CISC было плохой.
ОСОБЕННОСТИ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
Языки программирования обеспечивают плодородную почву для спорных идей. Про некоторые из них с самого начала было ясно, что они не только сомнительны, но и просто являются плохими. Отличный пример представляют средства, предложенные в 1960 г. для языка Algol и позже для его преемников [1].Большая часть людей считает, что язык программирования - это всего лишь код, единственное назначение которого состоит в конструировании программного обеспечения, выполняемого на компьютерах. Однако язык программирования - это модель вычислений, а программы - это формальные тексты, к которым применимы математические рассуждения. Модель должна определяться таким образом, чтобы ее семантика описывалась без отсылок на какой-либо нижележащий механизм, физический или абстрактный.
Поэтому явно плохой идеей является объяснение сложного набора особенностей и возможностей языка в толстых томах руководства. В действительности язык характеризуется не столько тем, что дает нам возможность программировать, сколько тем, что удерживает нас от использования недопустимых конструкций. Как заметил Дийкстра, наиболее трудной, ежедневной задачей программиста является недопущение беспорядка. Первичная и наиболее благородная обязанность языка состоит в том, чтобы помогать программистам в этой нескончаемой борьбе.
Нотация и синтаксис
Стало модным относиться к нотации как ко вторичному аспекту, целиком зависящему от личных вкусов. Это отчасти верно, хотя выбор нотации не должен быть случайным. У этого выбора имеются последствия, обнаруживаемые в общем облике языка.Общеизвестным плохим примером является выбор знака равенства для обозначения присваивания, восходящий к языку Fortran в 1957 г. и слепо повторяемый до сих пор массой разработчиков языков. Эта плохая идея низвергает вековую традицию использования знака "=" для обозначения сравнения на равенство, предиката, принимающего значения true или false. Но в Fortran этот символ стал обозначать присваивание, принуждение к равенству. В этом случае операнды находятся в неравном положении: левый операнд, переменная, должен быть сделан равным правому операнду, выражению. Поэтому x = y не означает то же самое, что y = x. В языке Algol эта ошибка была исправлена путем простого решения: присваивание обозначили через ":=".
Программистам, привыкшим к использованию знака равенства для обозначения присваивания, это может показаться придиркой. Но смешивание присваивания и сравнения действительно является плохой идеей, поскольку в этом случае требуется другой символ для того, что традиционно выражает знак равенства. Сравнение на равенство стали обозначать двумя символами "==" (впервые в языке C). Это является отвратительным последствием, приведшим к аналогичным плохим идеям использования "++", "--", "&&" и т.д.
В языках C, C++, Java и C# некоторые из этих операций вызывают побочные эффекты, известный источник ошибок программирования. Например, можно было бы принять "++" для обозначения увеличения значения на единицу, если бы то же самое не обозначало само увеличенное значение, что позволяет писать выражения с побочными эффектами. Неприятность состоит в удалении фундаментального различия между оператором и выражением. Оператор - это инструкция, подлежащая выполнению, выражение - это значение, которое надлежит вычислить.
Уродство конструкции обычно проявляется в комбинации с другими средствами языка. На языке C программист может написать конструкцию x+++++y, загадку, а не выражение, представляющую проблему даже для сложного синтаксического анализатора. Равняется ли значение этого "выражения" значению ++x+++y+1? Верны ли следующие соотношения?
x+++++y+1==++x+++y x+++y++==x+++++y+1
Так можно было бы постулировать новую алгебру. Я нахожу совершенно удивительной невозмутимость, с которой мировое сообщество программистов приняло этого нотационного монстра. В 1962 г. установившиеся традиции аналогичным образом подорвало постулирование правой ассоциативности операций в языке APL. Тогда x+y+z неожиданно стало обозначать x+(y+z), а x-y-z - x-y+z.
У условного оператора языка Algol, представляющего пример неудачного синтаксиса, а не только плохого выбора символов, имелось две формы (S0 и S1 обозначают некоторые операторы):
if b then S0 if b then S0 else S1
Это определение порождает очевидную двусмысленность, получившую название проблемы "висящего else". Например, оператор
if b0 then if b1 then S0 else S1можно интерпретировать двумя способами, а именно,
if b0 then (if b1 then S0 else S1) и if b0 then (if b1 then S0) else S1,возможно, приводящими к совершенно разным результатам. Следующий пример еще более серьезен:
if b0 then for i := 1 step 1 until 100 do if b1 then S0 else S1,поскольку он может быть синтаксически разобран двумя способами, приводящими к совершенно разным вычислениям:
if b0 then [for i := 1 step 1 until 100 do if b1 then S0 else S1]и
if b0 then [for i := 1 step 1 until 100 do if b1 then S0] else S1
Однако выйти из положения здесь достаточно просто: нужно использовать явный символ end в каждой конструкции, являющейся рекурсивной, и начинать с явного стартового символа, такого как if, while, for или case:
if b then S0 end if b then S0 else S1 end
Оператор goto
Среди многих плохих идей, представленных на доске позора, идея оператора goto подвергалась наибольшей критике. В языках программирования этот оператор является непосредственным двойником машинной инструкции перехода и может использоваться для конструирования условных и повторяющихся операторов. Но он также дает возможность программистам конструировать запутанный или беспорядочный поток выполнения программы, игнорировать какую-либо регулярную структуру. Это затрудняет, если не делает невозможными, структурные рассуждения о таких программах.Нашими основными средствами для понимания сложных объектов и управления ими являются структура и абстракция. Мы разбиваем чрезмерно сложный объект на части. Спецификация целого основывается на спецификации его частей. Оператор goto стал прототипом плохой идеи языка программирования, поскольку он может разрушить границы между частями и сделать недействительными их спецификации.
Из этого следует, что язык должен допускать, стимулировать и даже навязывать формулирование программ в виде должным образом вложенных структур, в которых свойства целого могут быть выведены из свойств частей. Рассмотрим, например, спецификацию повторения R оператора S. В этом случае S является частью R. Покажем две возможные формы:
R0: while b do S end R1: repeat S until bКлючом к надлежащей вложенности является возможность вывода свойств
R из свойств S. Например, если условие (утверждение) P остается справедливым (является инвариантом) при выполнении S, то мы заключаем, что P останется инвариантом, когда выполнение S будет повторяться.
Правила Хоара (Sir Charles Antony Richard Hoare) выражают это формально следующим образом:
{P & b} S {P} влечет {P} R0 {P & b}
{P} S {P} влечет {P} R1 {P & b}
Однако если S содержит оператор goto, то по поводу S невозможно сформулировать какое-либо подобное утверждение, и, следовательно, невозможен какой-либо дедуктивный вывод относительно действия R. Это очень значительная потеря. И действительно, практика показывает, что большие програмы без goto гораздо проще понимаются, и гораздо проще обеспечить какие-либо гарантии относительно их свойств.
Об операторе goto говорилось и писалось достаточно, чтобы убедить почти каждого, что это основной пример плохой идеи. Тем не менее, создатель языка Pascal (Напомним, что автором языка Pascal является сам Никлаус Вирт. - С. Кузнецов) оставил в языке оператор goto, а также оператор if без закрывающего символа end. Очевидно, ему не хватило смелости нарушить традицию, и он пошел на ошибочные уступки традиционалистам. Но это было в 1968 г. Теперь почти все понимают суть проблемы, за исключением разработчиков позднейших коммерческих языков программирования, таких как C#.
Переключатели
Если некоторое средство представляет собой плохую идею, то средства, построенные поверх его, оказываются еще хуже. Это правило можно продемонстрировать на переключателе, который, по существу, представляет собой массив меток. Например, в предположении наличия метокL1, : L5 объявление переключателя в языке Algol могло бы выглядеть следующим образом:
switch S := L1, L2, if x < 5 then L3 else L4, L5Тогда несомненно простой оператор
goto S[i] является эквивалентным следующему:
if i = 1 then goto L1 else if i = 2 then goto L2 else if i = 3 then if x < 5 then goto L3 else goto L4 else if i = 4 then goto L5Если
goto стимулирует беспорядок в программировании, то переключатель делает его неизбежным.
В 1965 г. Хоар предложил наиболее подходящую замену переключателя - оператор case. Эта конструкция представляет собой правильную структуру, в которой операторы-компоненты выбираются в соответствии со значением i:
case i of 1: S1 | 2: S2 | ........... | n: Sn endОднако разработчики современных языков программирования решили игнорировать это элегантное решение в пользу гибрида переключателя языка Algol и структурного оператора
case:
case statement:
switch (i) {
case 1: S1; break;
case 2: S2; break;
: ;
case n: Sn; break; }
Символ break либо обозначает разделитель между последовательными операторами Si, либо действует как goto на конец конструкции переключателя. В первом случае он является избыточным, а во втором - это замаскированный goto. Этот пример происходит из языка C - плохая концепция в плохой нотации,
Сложный оператор for в языке Algol
Разработчики языка понимали, что некоторые часто встречающиеся случаи повторения лучше было бы выражать в более точной форме, чем в комбинации в операторамиgoto. Они ввели оператор for, особенно удобный при работе с массивами, как в следующем примере:
for i := 1 step 1 until n do a[i] := 0
Если не обращать внимание на довольно неудачный выбор слов step и until, идея кажется замечательной. К несчастью, она была заражена плохой идеей мнимой общности. Последовательность значений, которые могла принимать управляющая переменная i, можно было задавать в виде списка:
for i := 2, 3, 5, 7, 11 do a[i] := 0
Более того, элементы списка могли быть выражениями общего вида:
for i := x, x+1, y-5, x*(y+z) do a[i] := 0
Кроме того, допускались различные формы элементов списка:
for i := x-3, x step 1 until y, y+7, z while z < 20 do a[i] := 0
Естественно, светлые головы быстро придумали патологические случаи, демонстрирующие абсурдность конструкции:
for i := 1 step 1 until i+1 do a[i] := 0 for i := 1 step i until i do i := -i
Общность оператора for в языке Algol должна служить предупреждающим сигналом для всех будущих разработчиков о том, что следует помнить об основном назначении конструкции и относиться с настороженностью к излишним общности и сложности, которые могут легко оказаться непродуктивными.
Передача параметров по имени в языке Algol
Процедуры и параметры в языке Algol обладали намного большей общностью, чем в более ранних языках, таких как Fortran. В частности, параметры выглядили так, как полагается в традиционной математике функций, где действительный параметр текстуально замещает формальный параметр [2]. Например, при наличии объявленияreal procedure square(x); real x; square := x * xвызов
square(a) должен точно интерпретироваться как a*a, а вызов square(sin(a)*cos(b)) - как sin(a)*cos(b) * sin(a)* cos(b). Для этого требуется вычислять синус и косинус дважды, что, весьма вероятно, не соответствует желанию программиста.
Для предотвращения этого часто встречающегося, вводящего в заблуждение случая разработчики языка Algol постулировали вторую разновидность параметра - параметр-значение. Это означало, что должна была выделяться локальная переменная x' и инициализироваться значением действительного параметра x. При наличии объявления
real procedure square(x); value x; real x; square := x * xприведенный выше вызов интерпретировался бы как
x' := sin(a) * cos(b); square := x' * x',что позволяло избежать двойного вычисления действительного параметра. В действительности передача параметров по имени является наиболее гибким средством, что показывает следующий пример.
Пусть имеется объявление
real procedure sum(k, x, n); integer k, n; real x; begin real s; s := 0; for k := 1 step 1 until n do s := x + s; sum := s endТогда сумма
a1 + a2 + : + a100 записывается просто как sum(i, a[i], 100), внутреннее произведение векторов a и b - как sum(i, a[i]*b[i], 100), а гармоническая функция - как sum(i, 1/i, n).
Но за общность, которая может оборачиваться элегантностью и усложненностью, нужно платить. Рефлексия показывает, что каждый параметр, передаваемый по имени, должен реализовываться как безымянная процедура без параметров. Чтобы избежать скрытых накладных расходов, в искусно разработанных компиляторах некоторые случаи можно оптимизировать. Но обычно возникает неэффективность, которую можно было бы легко избежать.
Мы могли бы просто удалить из языка параметры, передаваемые по имени. Однако эта мера была бы слишком решительной и поэтому является неприемлемой. Например, это препятствовало бы присваиванию параметрам для возврата результатов вызвавшей процедуре. Однако это соображение привело к замене в более поздних языках Algol W, Pascal и Ada средства передачи параметров по имени на средство передачи параметров по ссылке. Сегодня идея звучит следующим образом: относитесь скептически к чрезмерно сложным средствам и возможностям. В самом крайнем случае их стоимость должна быть известна пользователям до выпуска, публикации и распространения языка. Эта стоимость должна быть соразмерна преимуществам, получаемым при включении в язык данного средства.
Лазейки (loopholes)
Я рассматриваю лазейки как одно из наихудших средств, хотя сам заразил этим убийственным вирусом Pascal, Modula и даже Oberon. Лазейка позволяет программисту взломать проверку типов компилятора и сказать: "Не вмешивайтесь. Я умнее правил". У лазеек имеется много форм. Наиболее распространены функции явного изменения типа, такие какMesa: x := LOOPHOLE[i, REAL] Modula: x := REAL(i) Oberon: x := SYSTEM.VAL (REAL, i)Но они могут маскироваться под спецификации абсолютных адресов или под записи с вариантами, как в языке Pascal. В предшествующих примерах внутреннее представление целого значения
i должно интерпретироваться как число с плавающей точкой x. Это можно делать только при наличии знания о представлении чисел, что не должно требоваться при работе на уровне абстракции, обеспечиваемом языком. В Pascal и Modula [3] лазейки, по крайней мере, демонстрируются открытым образом. В языке Oberon они представлены только через небольшое число функций, инкапсулированных в псевдокод, называемый SYSTEM, который должен импортироваться и, таким образом, становиться видимым в заголовке любого модуля, в котором используются такие низкоуровневые возможности.
Это может звучать как попытка оправдания, но, тем не менее, лазейки являются плохой идеей. Они были введены для обеспечения возможности реализации законченных систем с использованием единственного языка программирования. Например, у менеджера памяти должна иметься возможность представления памяти как плоского массива байт без типов данных. У него должна иметься возможность выделять и освобождать блоки независимо от ограничений типов. Другим примером потребности в лазейках является драйвер устройства. В ранних компьютерах имелись специальные инструкции для доступа к устройствам. Позже программисты присвоили устройствам специальные адреса памяти, отобразили их в память. Поэтому появилась идея разрешить задавать для некоторых переменных абсолютные адреса, как в языке Modula. Но этой возможностью можно злоупотреблять многими нерегальными способами.
Очевидно, что нормальный пользователь никогда не нуждается в программировании менеджера памяти или драйвера устройства, и, следовательно, ему не нужны эти лазейки. Однако - и именно это делает лазейки плохой идеей - лазейки по-прежнему находятся в распоряжении программистов. Опыт показал, что нормальные пользователи не будут избегать использования лазеек, а скорее с энтузиазмом ухватятся за них, как за замечательное средство, которое будет ими использоваться при всякой возможности. Это особенно проявляется, если в руководстве программирования содержатся предостережения по поводу использования лазеек.
Наличие возможности лазеек обычно указывает на недостаточное совершенство языка, показывая, что на языке невозможно выразить некоторые вещи, которые могут оказаться важными. Например, тип ADDRESS в Modula приходилось использовать для программирования структур данных с элементами разных типов. Строгая стратегия статической типизации, которая требовала, чтобы каждый указатель был статически ассоциирован с фиксированным типом и мог ссылаться только на такие объекты, делала это невозможным. Зная, что указатели являются адресами, лазейка в форме невинно выглядящей функции изменения типа обеспечивала эту возможность, позволяя указательным переменным указывать на объект любого типа. Недостаток состоял в том, что никакой компилятор не мог проверить корректность таких присваиваний. Система проверки типов блокировалась и с таким же успехом могла бы вовсе отсутствовать. В языке Oberon [4] было применено чистое решение проблемы расширения типа, называемое в объектно-ориентированных языках наследованием. Теперь стало возможным объявить указатель как ссылающийся на данный тип, и этот указатель мог указывать на любой тип, являющийся расширением данного типа. Это позволяло конструировать неоднородные структуры данных и безопасно использовать их при поддержке надежной системы проверки типов. Реализация требовала проверки во время выполнения только в тех случаях, когда было невозможно произвести проверку во время компиляции.
Программы, представленные на языках 1960-х, были полны лазейками, что делало их весьма подверженными ошибкам. Но тогда отсутствовала какая-либо альтернатива. Тот факт, что разработчики могут использовать язык, подобный Oberon, для программирования без использования лазеек систем целиком, за исключением менеджера памяти и драйверов устройств, характеризует наиболее существенный прогресс в разработке языков за последние 40 лет.
СМЕШАННЫЕ МЕТОДЫ
Плохие идеи, рассматриваемые в этой части статьи, произрастают из широкой области софтверной практики, или, вернее, из более узкой области, охватываемой личным опытом автора сорокалетней давности. Тем не менее, полученные уроки остаются справедливыми и сегодня. Некоторые из них отражают более современные методы и тенденции, поддерживаемые, главным образом, обильным наличием мощности аппаратуры.Синтаксический анализ
В 1960-е гг. наблюдалось развитие методов синтаксического анализа. Использование формального синтаксиса для определения языка Algol обеспечило необходимые основы для превращения направлений определения языков и конструирования компиляторов в научную область. Сформировалась концепция синтаксически управляемого компилятора, и возникло много активностей в направлении автоматического синтаксического анализа на математически строгой основе. В этих работах появились идеи нисходящих и восходящих принципов, методов рекурсивного спуска и критериев для упреждающего поиска символов и поиска с возвратом. Это сопровождалось усилиями по более строгому определению семантики языков путем размещения семантических правил поверх соответствующих синтаксических правил.Как часто происходит в новых областях деятельности, исследования вышли за пределы текущих потребностей. Разработчики создавали все более мощные генераторы синтаксических анализаторов, которые могли работать со все более общими и сложными грамматиками. Хотя результаты этой работы представляли интеллектуальное достижения, их последствия были не столь позитивны. Они побудили разработчиков языков верить в том, что независимо от вида постулируемой ими синтаксической конструкции, автоматические инструментальные средства смогут уверенно определить двусмысленности, а некоторый мощный синтаксический анализатор несомненно сможет справиться с этой конструкцией. При этом ни одно такое средство не могло обеспечить какое-либо указание на то, как можно было бы улучшить синтаксис. Разработчики игнорировали как проблему эффективности, так и то, что язык служит целям не только автоматического парсера, но и читателя-человека. Если язык ставит в затруднение анализаторы, то он определенно затруднит и человека. Многие языки были бы более понятными и чистыми, если бы разработчики вынуждались использовать более простой метод синтаксического анализа.
Мой собственный опыт полностью подтверждает справедливость этого утверждения. После участия в 1960-е гг. в разработке синтаксических анализаторов для грамматик предшествования и их использования при реализации языков Euler и Algol W я решил переключиться на простейшие методы синтаксического анализа для языка Pascal. Опыт оказался в основном ободряющим, и я с большим удовлетворением придерживаюсь его по сей день.
Отрицательной стороной является потребность в существенно более тщательном продумывании синтаксиса до его публикации и каких-либо попыток реализации. Эти дополнительные усилия с лихвой компенсируются последующим использованием как языка, так и компилятора.
Расширяемые языки
Фантазии компьютерных ученых в 1960-е гг. не знали границ. Вдохновленные успехом в направлениях автоматического синтаксического анализа и генерации анализаторов, некоторые исследователи предложили идею гибких или, по крайней мере, расширяемых языков, представляя, что программе будут предшествовать синтаксические правила, которыми будет руководствоваться общий синтаксический анализатор при ее анализе. Более того, синтаксические правила можно было рассыпать повсюду в тексте. Например, можно было бы использовать какую-нибудь причудливую форму оператора for, специфицируя даже разные варианты одного и того же понятия в разных частях одной программы.Полностью затиралась та идея, что языки служат общению людей, поскольку теперь, очевидно, можно было определять язык "на лету". Однако трудности, возникающие при попытке определить смысл приватных конструкций, быстро разрушили эти большие ожидания. Вследствие этого, быстро увяла и занимательная идея расширяемых языков.
Древовидные таблицы символов
Компиляторы конструируют таблицы символов. Компилятор наращивает таблицы при обработке объявлений и производит в них поиск при обработке операторов. Для языков, допускающих вложенные области видимости, каждая область видимости представляется собственной таблицей.Традиционно эти таблицы являются двоичными деревьями, обеспечивающими быстрый поиск. Изменяя этой давнишней традиции, при реализации компилятора языка Oberon я осмелился усомниться в премуществах древовидных структур. Когда возникли сомнения, я быстро убедился в том, что древовидные структуры не имеют смысла для локальных областей видимости. В большинстве случаев процедуры содержат не более дюжины локальных переменных. Использование связанного линейного списка оказывается и проще, и эффективнее.
В программах, написанных 30-40 лет назад, большинство переменных объявлялось на глобальном уровне. Поскольку их было много, было оправданным и применение древовидной структуры. Однако, тем временем, возрастал спептицизм по отношению к практике использования глобальных переменных. В современных программах не используется много глобальных переменных, и в этом случае древовидные таблицы вряд ли являются подходящими.
Современные программные системы состоят из многих модулей, каждый из которых, вероятно, содержит несколько глобальных переменных, но не сотни. В ранних программах многие глобальные переменные распределялись по многочисленным модулям, и доступ к ним производился не по одиночному идентификатору, а по комбинации имен M.x, определяющей исходный путь поиска.
Использование усложненных структур данных для организации таблиц символов несомненно являлось плохой идеей. Однажды мы даже обсуждали возможность использования сбалансированных деревьев.
Использование неподходящих инструментальных средств
Хотя очевидно, что использование неподходящих инструментов является плохой идеей, часто мы обнаруживаем неадекватность инструментального средства только после затраты существенных усилий на его построение и понимание. К сожалению, затрачивание этих усилий придает инструменту воспринимаемую ценность (perceived value) независимо от его функциональной ценности. Это произошло с моей группой, когда мы реализовывали в 1969 г. первый компилятор языка Pascal.Инструментальными средствами, доступными для написания программ, являлись ассеблер и компиляторы языков Fortran и Algol. Компилятор Algol был настолько плохо реализован, что мы опасались на него полагаться, а использовать для работы язык ассемблера нам было стыдно. Оставался только Fortran.
Наш наивный план состоял в том, чтобы использовать Fortran для конструирования компилятора основного подмножества языка Pascal, который после завершении работы был бы оттранслирован на Pascal. Затем мы собирались использовать классическую технику раскрутки (bootstrapping) для завершения и совершенствования компилятора.
Перед лицом действительности наш план потерпел крах. Когда мы завершили первый шаг - затратив около одного человекогода труда, - оказалось, что трансляция Fortran-кода на Pascal является невозможной. Эта программа настолько определялась возможностями языка Fortran (вернее, отсутствием каких-либо возможностей), что единственным доступным для нас выходом было написание компилятора заново. Поскольку в языке Fortran не поддерживались указатели и записи, нам пришлось втискивать таблицы символов в неестественную форму массивов. В языке Fortran не было и рекурсивных подпрограмм. Поэтому нам пришлось использовать сложный таблично-управляемый, восходящий метод синтаксического анализа с использованием синтаксиса, представленного массивами и матрицами. Коротко говоря, для использования преимуществ языка Pascal требовалось полностью переписать и реструктурировать компилятор.
Этот случай показал, что простейший способ не всегда является правильным. Но у затруднений имеются и свои премущества: поскольку компилятор языка Pascal все-таки стал доступным, нам потребовалось переписать всю программу компиляции основного подмножества языка Pascal без тестирования обратной связи. Это оказалось исключительно полезным опытом, и такой подход был бы еще полезнее сегодня, в эпоху быстрых испытаний и интерактивного исправления ошибок.
После того, как мы убедились в завершенности компилятора, мы отправили одного из членов нашей группы к себе домой, чтобы он оттранслировал программу на синтаксически правильный низкоуровневый язык, для которого имелся компилятор. Он вернулся через две недели интенсивной работы, и еще через несколько дней компилятор, написанный на языке Pascal, откомпилировал первые тестовые программы.
Опыт добросовестного программирования оказался исключительно ценным. Никогда программы не содержат так мало ошибок, как при отсутствии каких-либо средств отладки. Впоследствии мы смогли воспользоваться раскруткой для получения новых версий компилятора, которые справлялись с большим числом языковых конструкций и производили все более качественный код. Сразу после первой раскрутки мы отказались от варианта компилятора, написанного на вспомогательном языке. Его облик очень напоминал зловещий облик низкоуровневого языка C, опубликованного год спустя.
После этого эксперимента у нас появилось смутное понимание причин, по которым сообщество инженерии программного обеспечения не признает преимуществ применения высокоуровневого, типизированного языка вместо языка C.
ПАРАДИГМЫ ПРОГРАММИРОВАНИЯ
За последние несколько десятков лет входило в моду и выходило из моды несколько парадигм программирования, внося в развитие этой области вклад разного уровня важности.Функциональное программирование
Функциональные языки происходят от языка Lisp [5]. Они подверглись большому числу расширений и изменений и используются для реализации как небольших, так и крупных программных систем. Я всегда сохранял скептическую позицию по отношению к этому направлению.Что характеризует функциональные языки? Всегда оказывалось, что они характеризуются своей формой, что вся программа состоит из вычислений функций - вложенных, рекурсивных, параметрических и т.д. Отсюда происходит термин функциональный. Однако ключевая идея состоит в том, что функции по своему существу не имеют состояний. Отсюда следует отсутствие переменных и присваиваний. Вместо переменных используются неизменяемые параметры функций - переменные в математическом смысле. Вследствие этого, только что вычисленные значения невозможно присвоить той же переменной, затирая ее старое значение. Это объясняет, почему повторение должно выражаться через рекурсию. Структуру данных, в лучшем случае, можно расширить, но невозможно изменить ее существующую часть. Это приводит к очень высокому уровню рециркуляции памяти - необходимым компонентом является "сборщик мусора" (garbage collector). Реализация без автоматической сборки мусора является немыслимой.
Постулирование модели вычислений без состояний поверх машины, наиболее значительной характеристикой которой является состояние, кажется, по крайней мере, странной идеей. Между моделью и машиной существует широкая пропасть, возведение моста через которую обходится дорого. Это невозможно исправить с помощью какой-либо аппаратной поддержки: идея остается плохой и на практике.
Сторонники функциональных языков также со временем поняли это. С помощью разнообразных хитрых приемов они ввели состояние и переменные. Тем самым, чисто функциональный облик языков был дискредитирован и принесен в жертву. Старая терминология стала обманчивой.
Если оглянуться на прошлое функциональных языков, то оказывается, что их действительно важным вкладом было, конечно, не отсутствие состояний, а требование понятных вложенных структур и использование строго локальных объектов. Эта дисциплина может практиковаться и с использованием традиционных, императивных языков, которые со временем позаимствовали идеи вложенных структур, функций и рекурсии.
Однако функциональные языки подразумевают гораздо большее, чем отказ от операторов goto. Они также подразумевают ограничение на локальные переменные, за исключением, возможно, нескольких глобальных переменных состояния. В них, возможно, считается нежелательной вложенность процедур. По-видимому, были правы разработчики компьютера B5000, ограничая доступ к строго локальным и глобальным переменным.
Много лет спустя некоторые разработчики все чаще стали утверждать, что функциональные языки являются наилучшим средством для введения параллелизма - хотя было бы более уместно сказать "для облегчения работы компиляторов по определению возможностей распараллеливания программ". Вообще-то относительно несложно определить, какие части выражения могут вычисляться параллельно. Более важно то, что параллельно могут вычисляться параметры вызываемой функции, если запрещены побочные эффекты - которые не могут возникать в истинно функциональном языке. В то время, как это обстоятельство может быть истинным и, возможно, минимальным преимуществом функциональных языков, объектно-ориентированный подход предлагает более эффективный способ хорошего использования параллелизма, когда поведение каждого объекта представляется в виде отдельного процесса.
Логическое программирование
Хотя логическое программирование также привлекло широкое внимание, эта парадигма представлена всего одним языком - Prolog. Основной особенностью языка Prolog является то, что спецификации действий, таких как присваивания переменным, заменяются в нем спецификациями предикатов на состояниях. Если один или несколько параметров предиката остаются неопределенными, система производит поиск всех возможных значений аргументов, удовлетворяющих данный предикат. Из этого следует потребность в механизме поиска, находящем решения логических операторов. Этот механизм является сложным, часто потребляющим много времени; иногда он оказывается не в состоянии продолжать поиск без дополнительных указаний. Однако для этого требуется, чтобы систему поддерживал пользователь, обеспечивая требуемые "подсказки", а для этого он должен понимать, что происходит в системе, и в чем состоит процесс логического вывода. А ведь именно возможность игнорирования пользователем этого процесса обещали сторонники парадигмы.Мы должны допускать, что разработчики программного обеспечения были рады услышать о возможности подобной панацеи, поскольку их сообщество отчаянно нуждалось в способах производства более качественного, более надежного программного обеспечения. Но обещанные достижения так и не материализовались. Я с сожалением напомню надежды, возлагавшиеся на японский проект компьютера пятого поколения, Prolog-машины вывода. Организаторы потратили огромные объемы ресурсов на реализацию этой неблагоразумной и почти уже забытой идеи.
Объектно-ориенированное программирование
В отличие от функционального и логического программирования, объектно-ориентированное программирование (ООП) основывается на тех же принципах, что и традиционное, процедурное программирование. ООП обладает императивным обликом. Процесс описывается как последовательность преобразований состояния. Новшество состоит в разбиении глобального состояния на отдельные объекты и связывании с объектом преобразователей состояния, называемых методами. Объекты представляются как акторы, которые посылают другим объектам сообщения, побуждая их изменять свое состояние. Описание шаблона объекта называется определением класса.Эта парадигма непосредственно отражает структуру систем реального мира и поэтому хорошо подходит для моделирования сложных систем со сложным поведением. Не удивительно, что истоки ОПП лежат в области имитационного моделирования систем. Успех ООП в области разработки программных систем говорит сам за себя, начиная с языка Smalltalk [6] и продолжая линией Object Pascal, C++, Eiffel, Oberon, Java, и C#.
Первая реализация Smalltalk обеспечила убедительный пример применимости языка. Будучи первым языком, в котором поддерживались окна, меню, кнопки и пиктограммы, Smalltalk предоставил совершенный пример видимых объектов. Прямое моделирование акторов снижало значимость аналитического доказательства корректности программы, поскольку прежде всего специфицровалось поведение, а не статические связи по вводу-выводу.
Тем не менее, нас может заинтересовать, где сокрыто ядро новой парадигмы, и чем оно по существу отличается от традиционного представления о программировании. В конце концов, старые краеугольные камни процедурного программирования проявляются снова и снова, хотя и встроенными в новую терминологию. Объекты - это записи, классы - это типы, методы - это процедуры, а посылка сообщения эквивалентна вызову процедуры. Да, записи теперь могут состоять из полей данных и, впридачу к ним, методов; да, средство, называемое наследованием, позволяет конструировать разнородные структуры данных, но все это полезно и вне объектной ориентированности. Выражает ли это изменение терминологии существенное изменение парадигмы, или же это всего лишь маркетинговая уловка? Этот вопрос остается открытым.
Многое можно узнать из анализа не только плохих идей и прошлых ошибок, но и хороших идей. Хотя представленная здесь коллекция тем может показаться случайной, и конечно, она неполна, я писал ее с той точки зрения, что компьютерная наука может выиграть при наличии более частых проявлений анализа и критики, в частности, самокритики. В конце концов, самокритика - это признак любой дисциплины, претендующей на именование наукой.
Литература
- P. Naur, "Report on the Algorithmic Language ALGOL 60," Comm. ACM, May 1960, pp. 299-314.
- D.E. Knuth, "The Remaining Trouble Spots in ALGOL 60," Comm. ACM, Oct. 1967, pp. 611-618.
- N. Wirth, Programming in Modula-2, Springer-Verlag, 1982.
- N. Wirth, "The Programming Language Oberon," Software - Practice and Experience, Wiley, 1988, pp. 671-691.
- J. McCarthy, "Recursive Functions of Symbolic Expressions and their Computation by Machine," Comm. ACM, May 1962, pp. 184-195.
- A. Goldberg and D. Robson, Smalltalk-80: The Language and Its Implementation, Addison-Wesley, 1983.
* К сожалению, мне не удалось найти в Internet какие-либо следы публикации выступления Тэкера. Статья Кнута также недоступна в Internet. Она была опубликована сначала в журнале Logic, Methodology and Philosophy of Science (N 4, 1973), а затем перепечатана в книге Кнута Selected Papers on the Analysis of Algorithms (Center for the Study of Language and Inf, 2000). (Прим. С.Кузнецова)