1. Введение
Современные микропроцессоры обладают достаточными ресурсами для выполнения нескольких инструкций за один такт. Для того чтобы достичь хорошей производительности на таких процессорах, нужно уметь находить в программе инструкции, которые могут выполняться независимо. Обычно эту задачу называют обнаружением параллелизма на уровне команд (ILP, instruction level parallelism).
Суперскалярные процессоры решают задачу нахождения ILP динамически в процессе выполнения программы. Программа для этих процессоров не содержит сведений о том, какие инструкции могут выполняться независимо, и вся нагрузка по нахождению оптимального "плана" выполнения ложится на аппаратуру. Чем больше команд процессор может выдать за такт, тем сложнее в реальном времени обнаружить оптимальную последовательность выполнения команд.
Для того чтобы преодолеть эти ограничения, фирмой Intel была предложена архитектура EPIC (Explicitly Parallel Instruction Computing [1]) с очень длинным командным словом, реализованная в процессорах семейства Itanium. Идея EPIC состоит в том, чтобы переложить задачу по поиску ILP на компилятор. EPIC-программа содержит явные указания на то, какие инструкции можно выполнять параллельно, а EPIC-процессор в точности следует тому плану выполнения, который задает программа. При этом его основной задачей становится обеспечение работы конвейера, и необходимость в аппаратной реализации сложной логики поиска независимых инструкций отпадает.
С другой стороны, отдавая компилятору задачу определения наилучшего плана выполнения программы, архитектура должна предоставить компилятору широкие возможности по управлению ходом выполнения программы. EPIC дает возможность компилятору (помимо явного указания на независимость определенных команд) предсказывать ветвления, влиять на работу кэша, избавляться от коротких ветвлений, выполнять команды с опережением и некоторые другие. Кроме того, предоставляется значительный объем ресурсов - большой регистровый файл и много параллельно работающих функциональных устройств.
Из перечисленного списка особенностей архитектуры видно, что создание оптимизирующего компилятора для EPIC является принципиально иной задачей, чем оптимизация под традиционные последовательные архитектуры. Компилятор для EPIC должен уметь выразить как можно больше параллелизма на уровне команд, создавая эффективный план выполнения программы с учетом всех возможностей архитектуры, и упаковать эти команды в длинные слова. При этом задачи, возникающие при использовании свойств архитектуры, ранее в компиляторах не ставились, и методы их решения до сих пор в полной мере не разработаны.
Целью нашей работы является разработка и реализация алгоритма эффективной генерации команд раннего выполнения (speculative execution). Технология раннего выполнения - это одна из особенностей EPIC, заключающаяся в возможности опережающего выполнения команд, использующих данные из памяти, что помогает "скрывать" задержки чтения данных и лучше переупорядочивать поток команд. В данной статье мы описываем предлагаемый нами алгоритм генерации инструкций раннего выполнения, а также приводим методы, которые используются нами для улучшения эффективности раннего выполнения на основании данных анализа указателей. Кроме того, мы обсуждаем результаты тестирования реализации алгоритма для компилятора GCC [2] на пакете SPEC CPU 2000.
2. Реализация раннего выполнения на Intel Itanium
В этом разделе мы описываем технику раннего выполнения, а также ее реализацию в процессорах Itanium. Далее под инструкцией (или командой) мы понимаем одну операцию, выполняемую процессором.
Процессоры семейства Intel Itanium [3] являются реализацией архитектуры EPIC с очень длинным командным словом (VLIW - Very Long Instruction Word). Каждое такое командное слово представляет собой пакет инструкций, который включает в себя 3 инструкции, и задает шаблон, который указывает процессору, на каком функциональном устройстве следует выполнять каждую из инструкций. Itanium 2 имеет более 20 функциональных устройств, которые могут работать параллельно.
Пакеты инструкций объединяются в группы инструкций (далее - просто группы), каждая из которых может быть выполнена за 1 такт работы процессора (всего до двух групп за 1 такт). Группы разделяются между собой стоп-битами, которые являются частью кода шаблона; в текущей реализации в одной группе может быть до двух пакетов. Задача компилятора по выявлению ILP состоит в явном указании шаблонов пакетов и границ групп инструкций (с помощью стоп-битов). Шаблоны указывают процессору, куда требуется распределить инструкции, а группы явно указывают, какие инструкции можно выполнять независимо.
Для того чтобы эффективно использовать параллелизм на уровне команд, имеющийся в программе, необходимо иметь как можно большую свободу перемещения инструкций между группами с тем, чтобы максимально использовать все функциональные устройства, доступные во время выполнения каждой группы. Возможности по перемещению инструкций компилятором ограничиваются зависимостями инструкций по данным и по управлению. Тем не менее, часто бывает, что точно определить наличие зависимости в момент компиляции нельзя, но можно с большой вероятностью утверждать, что зависимости нет. При обычном планировании компилятор в таких случаях обязан предполагать наличие зависимости, чтобы сохранить корректность программы. Архитектура EPIC позволяет компилятору игнорировать такие зависимости, поддерживая технику раннего выполнения (speculative execution). Компилятор может выдать инструкции раньше, чем позволило бы наличие зависимости, но должен сгенерировать код восстановления (recovery code), который обеспечит корректное выполнение программы, если зависимость окажется реальной. В случае отсутствия зависимости использование раннего выполнения позволяет скрыть задержки операций загрузки из памяти и уменьшить время выполнения программы.
Существует два вида раннего выполнения: один направлен на устранение зависимостей по данным (data speculation), другой - зависимостей по управлению (control speculation). Первый состоит в перемещении операции загрузки из ячейки памяти выше операции записи в некоторую ячейку, адрес которой может пересекаться с адресом загрузки. Второй состоит в перемещении операции загрузки из памяти выше операции ветвления. Инструкции, в которых используется результат операции загрузки, также могут быть перемещены. Перед использованием результатов перемещенных команд должна быть выполнена проверочная инструкция, определяющая, действительно ли была зависимость. Если результат проверки положителен, то проверочная инструкция выполняет переход на код восстановления (см. примеры на рисунках 1 и 2).
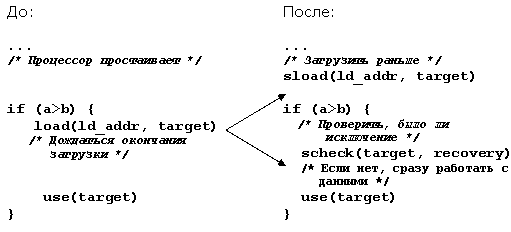
Рис. 1. Пример раннего выполнения (устраняется зависимость по управлению)
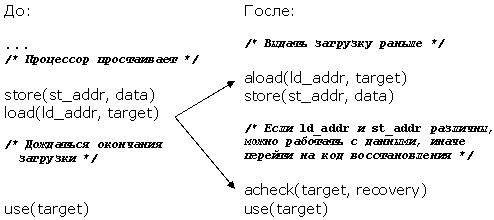
Рис. 2. Пример раннего выполнения (устраняется зависимость по данным)
В системе команд Itanium раннее выполнение поддерживается двумя группами инструкций, для преодоления зависимостей по данным и по управлению. К первой группе относятся инструкции ld.a (расширенная команда загрузки), а также ld.c и chk.a (проверка выполненной ранней загрузки), ко второй - соответственно ld.s и chk.s.
При устранении зависимости по данным необходимо убедиться, что адреса ячеек памяти, указатели на которые создают эту зависимость, не совпадают в момент выполнения программы. Для этого инструкция ld.a, выполняя раннюю загрузку операнда из памяти, сохраняет фактический адрес ячейки памяти, из которой загружалось значение, в специальной таблице адресов - ALAT (Advanced Load Address Table - таблица адресов ранней загрузки). Эта таблица индексируется по номеру регистра, в который выполнялась загрузка. Операции записи по адресу, перекрывающемуся со значением одной из ячеек в таблице ALAT, а также выполнение ранней загрузки в тот же регистр удаляет предыдущее значение соответствующей ячейки.
При выполнении инструкции проверки ранней загрузки ld.c с тем же номером регистра назначения, в таблице адресов ранней загрузки выполняется поиск значения с индексом, равным номеру этого регистра. Если такого значения не найдено, то считается, что была выполнена конфликтующая операция записи. Следовательно, раннее выполнение не удалось, и инструкция загрузки выполняется еще раз. В случае команды chk.a происходит переход на ранее сгенерированный компилятором код восстановления.
При устранении зависимости по управлению достаточно гарантировать, что в случае возникновения исключительной ситуации при выполнении ранней загрузки она будет возбуждена в корректном месте программы. Для этого инструкция ld.s, выполняя раннюю загрузку в некоторый регистр, при возникновении исключительной ситуации устанавливает для него специальный флаг NaT (Not a Thing), который свидетельствует о наличии отложенного исключения. Этот флаг может быть установлен для любого регистра общего назначения. Если этот флаг был установлен для какого-либо регистра, то он также будет установлен для всех регистров, значения которых были получены с помощью вычислений, использовавших значение первого регистра.
Если впоследствии проверочная инструкция chk.s обнаруживает, что для ее операнда регистра установлен флаг NaT, то она передает управление на код восстановления, который должен устранить последствия неудачной попытки раннего выполнения. Примеры ассемблерного кода с использованием раннего выполнения приведены на рис. 3.
| Исходная программа | Программа с инструкциями раннего выполнения | | Исходная программа | Программа с инструкциями раннего выполнения |
|---|
adds r15=r16,r14
st8 r14=[r14]
nop.i
ld8 r18=[r19];;
st4 r15=[r33]
nop.i
ld8 r14=[r18];; |
ld8.a r18=[r19];;
adds r15=r16,r14
nop.i
st8 r14=[r14]
ld8.c.clr r18=[r19]
nop.i;;
ld8 r14=[r18];;
st4 [r15]=r33
| |
mov r1=r42
adds r14=1,r8;;
cmp4.ltu p6, r14
(p6) br.cond bd0
ld4 r14=[r33];;
add r14=r14,r8
|
adds r14=1,r8
ld4.s r15=[r33]
mov r1=r42;;
cmp4.ltu p6,r14
(p6) br.cond bf0
chk.s.m r15,b40;;
add r15=r15,r8
|
| а) | | б) |
Рис. 3. Примеры ассемблерного кода с командами раннего выполнения
| а) преодоление зависимостей по данным, |
| б) преодоление зависимостей по управлению |
Избыточная генерация инструкций раннего выполнения зачастую может не только не дать выигрыша в производительности, но и наоборот, привести к ухудшению производительности программы, т.к. в случае неудачного раннего выполнения необходимо будет выполнять загрузку из памяти повторно, или выполнять дополнительный код восстановления. Использование информации, полученной с помощью анализа указателей, во многих случаях дает возможность оценить целесообразность генерации инструкций раннего выполнения, что позволяет генерировать такие инструкции только в тех местах, где это действительно необходимо.
3. Алгоритм генерации инструкций раннего выполнения
Инструкции раннего выполнения порождаются компилятором в процессе планирования. В этом разделе описывается, как нужно изменить планировщик, чтобы он мог поддерживать раннее выполнение. Предполагается, что планировщик может оперировать регионами из нескольких базовых блоков (иначе не появляется зависимостей по управлению и раннего выполнения для них). При описании того, как меняется собственно алгоритм планирования, мы предполагаем, что планировщик принадлежит к классу алгоритмов списочного планирования (list scheduling [4]).
Для моделирования раннего выполнения в планировщике инструкций введем понятие блока раннего выполнения. Некоторые инструкции могут порождать начало таких блоков (например, загрузки из памяти). Затем могут следовать несколько инструкций, использующих результат загрузки (первой инструкции блока). Блок завершается специальными инструкциями проверки (такими как ld.c и chk.s). Таким образом, блок раннего выполнения формируется из операций ранней загрузки и проверки, и может включать несколько использований результата ранней загрузки.
Алгоритм поддержки раннего выполнения в планировщике имеет своей целью корректное создание и наполнение блоков раннего выполнения наравне с планированием обычных инструкций. Для этого необходимо решить следующие подзадачи:
- Расширение структур данных планировщика, хранящих сведения об инструкциях и зависимостях, данными раннего выполнения.
- Инициализация новых структур данных.
- Планирование инструкций раннего выполнения.
- Поддержка планирования машинно-зависимой частью компилятора.
Далее мы подробно описываем решение каждой из этих задач.
3.1. Расширение и инициализация структур данных
Для отражения свойств инструкций и зависимостей, связанных с ранним выполнением, в структуры данных планировщика, представляющие инструкции и зависимости между ними, включены флаги раннего выполнения (см. таблицу 1). Наличие флага раннего выполнения для зависимости означает, что для преодоления данной зависимости можно использовать раннее выполнение. Аналогично, такой флаг для инструкции означает, что она может быть запланирована альтернативным способом - с использованием раннего выполнения. Также специальными флагами помечаются инструкции, которые более предпочтительны для раннего выполнения, либо, наоборот, не должны в нем участвовать.
Таблица 1. Флаги раннего выполнения
| Флаг | Зависимость может быть устранена с помощью: | Инструкция может быть: |
|---|
| BEGIN_DATA | ранняя загрузка с помощью ld.a | ld.a |
| BEGIN_CONTROL | ранняя загрузка с помощью ld.s | ld.s |
| BE_IN_DATA
BE_IN_CONTROL | использование результата ранней загрузки | использование результата ранней загрузки |
| FINISH_DATA | - | ld.c |
| FINISH_CONTROL | - | chk.s |
| HARD_DEP | невозможно устранить | ранняя загрузка не может быть использована |
| WEAK_DEP | ранняя загрузка предпочтительна | ранняя загрузка предпочтительна |
Инициализация флагов происходит перед началом планирования, когда работает анализ зависимостей по данным. Все так называемые истинные зависимости по памяти (команда, читающая данные из памяти, зависит от ранее выполняемой команды записи этих данных) помечаются анализом зависимостей флагом BEGIN_DATA. Некоторые зависимости при этом помечаются флагом HARD_DEP (например, зависимости, возникающие при волатильных обращениях в память). Флаг зависимости по управлению BEGIN_CONTROL, BE_IN- и FINISH- флаги, а также флаги раннего выполнения для инструкций устанавливаются в процессе планирования при анализе их зависимостей.
3.2. Планирование инструкций раннего выполнения
Планировщиком семейства list scheduling непосредственно для планирования используется список готовых инструкций. Инструкция может быть помещена в этот список при начале планирования, либо после того, как запланирована предыдущая инструкция и удовлетворены зависимости по данным. Из списка выбирается (обычно руководствуясь набором эвристик) наилучшая для планирования в данный момент инструкция, которая выдается на планирование и удаляется из списка, а зависимые от нее инструкции добавляются в список. Процесс повторяется до тех пор, пока не будут запланированы все инструкции.
С точки зрения планировщика, все истинные зависимости по памяти могут быть потенциально устранены с помощью раннего выполнения по данным. Дополнительное ограничение накладывает архитектура машины, которая может поддерживать раннюю выдачу лишь некоторых инструкций (в Itanium это команды загрузки из памяти). За проверку этого ограничения отвечает машинно-зависимая часть компилятора. Аналогично, любая инструкция из последующих базовых блоков может быть выполнена в планируемом блоке с помощью раннего выполнения по управлению, если это поддерживается целевой машиной. Это ограничение проверяется при каждом перемещении инструкции в список для планирования и далее в этом разделе не упоминается.
Помещение в список планирования.
Рассмотрим, как изменяется процесс добавления инструкций в список готовых к планированию. Пусть инструкция находится в том же базовом блоке, который сейчас планируется. Тогда она может быть добавлена в список, если у нее нет зависимостей, либо все ее зависимости помечены флагами
BEGIN_DATA либо
BE_IN_DATA. Такая инструкция при помещении в список также помечается одним из этих флагов.
Если же инструкция находится в другом базовом блоке, то возможны три случая. В первом случае у инструкции нет зависимостей по данным, и она не может возбудить исключение - перемещение такой инструкции не нарушает корректность программы, и она сразу помещается в список. Во втором случае инструкция может создать исключение, но не имеет зависимостей. Эта инструкция может быть помещена в список для раннего выполнения по управлению, если вероятность выполнения ее базового блока относительно текущего высока, и в этом случае она помечается флагом BEGIN_CONTROL. В третьем случае у инструкции есть зависимости по данным. Если все такие зависимости помечены флагами BEGIN_DATA либо BE_IN_DATA, тогда, аналогично двум предыдущим случаям, в зависимости от того, может или нет инструкция возбудить исключение, она может быть помещена в список с флагом (либо без флага) BEGIN_CONTROL и с флагами, соответствующими флагам ее зависимостей. Если же зависимости инструкции устранить невозможно (флаг HARD_DEP), то она не может быть помещена в список планирования.
Сортировка списка планирования.
После формирования списка готовых инструкций он сортируется в соответствии с эвристиками планировщика. Затем из списка выбирается инструкция, планирование которой позволит выдать наибольшее число инструкций в текущем цикле. Для определения приоритетов среди инструкций раннего выполнения при планировании используются следующие эвристики:
- Обычная инструкция всегда предпочитается инструкции раннего выполнения;
- Инструкция раннего выполнения по данным предпочитается инструкциям раннего выполнения по управлению;
- Если обе инструкции раннего выполнения устраняют зависимости по данным, то вычисляется оценка того, какие из зависимостей наименее вероятны. Эта оценка является суммой оценок вероятностей каждой зависимости инструкции. Вероятность зависимости в свою очередь является степенью "слабости" зависимости (понятие слабых зависимостей подробнее рассматривается в следующем разделе);
- Если обе инструкции являются инструкциями раннего выполнения по управлению, то предпочитается инструкция с наибольшей вероятностью выполнения.
Выдача инструкций раннего выполнения.
Выдача инструкций раннего выполнения происходит следующим образом. Инструкция, помеченная одним из флагов
BEGIN_* (загрузка из памяти в случае Itanium) разбивается на две части: инструкцию раннего выполнения и инструкцию проверки. Все зависимости исходной инструкции (как прямые, так и обратные), переносятся на инструкцию проверки, а также добавляется зависимость между инструкциями раннего выполнения и проверки. При этом обратные зависимости с флагом
HARD_DEP изменяются на зависимости
BE_IN_*. Инструкция раннего выполнения планируется на текущем цикле, а инструкция проверки помечается как последняя инструкция блока раннего выполнения (
FINISH_*), и планируется позже, как обычная инструкция. Кроме того, при планировании инструкций, создающих новый блок раннего выполнения, также создается новый блок, который будет содержать код восстановления, и в него помещается копия спланированной инструкции. Для данной копии создается зависимость от инструкции проверки типа
HARD_DEP, которая обеспечивает планирование кода восстановления после проверочной инструкции.
При выдаче инструкции, содержащейся внутри блока раннего выполнения (помеченной флагами BE_IN_*), аналогично ее зависимости также изменяют свой тип с BEGIN_* на BE_IN_*, и копия инструкции помещается в уже созданный блок восстановления. При этом BE_IN_* зависимости инструкции, которые были устранены при планировании, перемещаются на копию инструкции, чтобы указать планировщику зависимость копии инструкции от уже содержащихся в блоке восстановления инструкций.
При выдаче инструкции проверки, завершающей блок раннего выполнения, соответствующий блок восстановления закрывается и добавляется к текущему региону для последующего планирования аналогично обычным базовым блокам. Если блок выполнения состоит из одной инструкции, то возможна ситуация, когда задачу восстановления выполнит сама инструкция проверки (в случае Itanium это возможно для ld.c). Тогда блок восстановления уничтожается.
3.3. Машинно-зависимая поддержка раннего выполнения
При разработке алгоритма раннего выполнения мы ориентировались на мультиплатформенный компилятор, подобный GCC. Для этого машинно-зависимые части поддержки раннего выполнения были выделены отдельно. Если необходимо реализовать поддержку для определенной платформы, то модуль компилятора, реализующий кодогенерацию для этой платформы, должен предоставить следующие возможности (реализованные в виде процедур):
- Запрос о том, какие типы раннего выполнения (в терминах введенных нами флагов) поддерживает архитектура;
- Запрос о том, поддерживает ли архитектура раннее выполнение данной инструкции;
- Запрос на преобразование инструкции, подготавливаемой к раннему выполнению определенного типа, к виду (во внутреннем представлении), который она примет при раннем выполнении. Для Itanium, например, при передаче инструкции загрузки из памяти в качестве параметра необходимо вернуть инструкцию во внутреннем представлении, соответствующую
ld.s или ld.a;
- Запрос на создание инструкции проверки для данного типа раннего выполнения;
- Запрос на то, нужен ли блок восстановления для данной инструкции данного типа раннего выполнения, или же можно обойтись инструкцией проверки;
- Запрос на расширение структур данных при создании новых инструкций (нового базового блока).
Кроме того, для всех типов инструкций раннего выполнения необходимо задать их вид в ассемблере целевой машины для кодогенератора, а также время выполнения (латентность) и занимаемые функциональные устройства для того, чтобы планировщик мог оценивать состояние конвейера целевой машины в процессе планирования.
3.4. Использование анализа указателей для улучшения эффективности раннего выполнения
Данные анализа указателей могут значительно повысить эффективность планирования инструкций с поддержкой раннего выполнения, указывая планировщику, в каких случаях генерация инструкций раннего выполнения является наиболее эффективной. На основе данных анализа указателей с помощью приведенных ниже эвристик оценивается степень истинной зависимости между инструкциями. Будем говорить, что между двумя инструкциями существует слабая зависимость, если между ними с помощью консервативного статического анализа диагностируется истинная зависимость по данным, но фактически вероятность возникновения такой зависимости мала. Аналогично, будем считать, что сильной зависимостью между двумя инструкциями является такая истинная зависимость по данным, которая с достаточно большой вероятностью имеет место и во время выполнения программы.
Для определения степени зависимости вычисляется эвристическая оценка, показывающая вероятность ее существования с точки зрения статического анализа. Используются следующие эвристики:
- Два указателя, ссылающиеся на ячейки, степень зависимости которых определяется, имеют непересекающиеся множества значений, на которые они могут указывать (множества points-to), но вследствие консервативности анализа для одного из указателей известно, что он мог ссылаться по неопределенному адресу;
- Один из указателей является прямой ссылкой, а другой - непрямой. Эта эвристика используется при ссылках на поля структуры (
s.a или p->b);
- Указатели являются различными параметрами одной функции;
- Указатели имеют различные базовые значения, т.е. значения, относительно которых выполнялись операции над указателями, и эти базовые значения являются различными параметрами функций. Другими словами, указатели
p и q имеют вид
p = arg1 + offset1, q = arg2 + offset2,
где arg1 и arg2 - различные аргументы функции.
Аналогично, зависимость является сильной, и мы не должны пытаться «разорвать» зависимость по данным, если множества points-to соответствующих указателей пересекаются. В этом случае, как было установлено экспериментально, высока вероятность того, что раннее выполнение окажется неудачным.
4. Реализация алгоритма раннего выполнения в компиляторе GCC
Данный подход был реализован в компиляторе GCC на основе серии 4.х (в настоящий момент еще не вышедшей). Логика планирования инструкций раннего выполнения и расширение структур данных планировщика были реализованы так, как описано в разделе 3. В кодогенераторе GCC для процессоров Itanium были описаны ассемблерные формы инструкций раннего выполнения. Кроме того, был исправлен ряд недочетов и сделано несколько улучшений планировщика, не связанных непосредственно с основным алгоритмом:
- Структуры данных планировщика не были рассчитаны на то, что в процессе планирования могут появиться новые инструкции. Нами был предусмотрен ряд процедур, осуществляющих расширение этих структур на лету;
- Планировщик не поддерживал граф потока управления в консистентном состоянии, что не позволяло добавлять блоки восстановления к планируемым регионам;
- Планировщик также не поддерживал консистентность информации о времени жизни регистров, так как дальнейшим оптимизациям она не была нужна. Это мешало обрабатывать инструкции раннего выполнения во время второго запуска планировщика;
- Приоритет инструкций на стыках базовых блоков вычислялся неправильно, что не являлось проблемой до появления команд раннего выполнения. После реализации алгоритма оказалось, что при переходе к планированию следующего базового блока из-за неверного вычисления приоритета в длинное командное слово, не полностью заполненное инструкциями из предыдущего базового блока, могли попасть новые инструкции раннего выполнения, причем корректность программы нарушалась;
- Планировщик не сохранял все типы зависимостей, а только сильнейшую зависимость между двумя инструкциями. Это может помешать корректно выдать команду раннего выполнения. Рассмотрим следующий пример:
<точка планирования>
add r3 = r3, r4
st [r6] = r4
ld r4 = [r5]
Загрузка в регистр r4 не может быть перемещена для раннего выполнения в текущую точку планирования, поскольку такое перемещение нарушит обратную зависимость (anti-dependence) между инструкциями ld и add. Между тем, эта зависимость может быть опущена из-за наличия прямой (истинной) зависимости у инструкции ld. Мы исправили анализ зависимостей так, чтобы сохранялись все типы зависимостей;
- Было улучшено формирование регионов планирования. За счет нескольких дополнительных итераций (в 95% достаточно двух, а в 99% - трех итераций) по графу потока управления стало возможным формировать бóльшие регионы, позволяет иметь лучший выбор при раннем планировании.
5. Экспериментальные результаты
Мы провели тестирование раннего выполнения на наборе тестов SPEC 2000 [5]. Использовались серверы HP rx1600 с двумя процессорами Intel Itanium 2 1.8 ГГЦ и 2 ГБ оперативной памяти. В таблице 2 приведены результаты тестирования для пакета SPEC FP c уровнем оптимизации -O3. Для сравнения приведены также данные ускорений, получаемые при включении отдельных оптимизаций. При уровне оптимизации -O3, помимо раннего выполнения, работает также и широкий набор стандартных оптимизаций компилятора GCC.
Результаты тестирования показывают, что ранее выполнение наиболее полезно для вычислительных задач, где применение этой техники может дать большое ускорение (до 20% и выше). Для целочисленных задач применение техники должно быть более консервативным, и стандартного анализа указателей (компилятора GCC) может не хватать. Вообще говоря, чем более консервативные настройки раннего выполнения, тем меньше ускорение для отдельных тестов, но при этом и меньше тестов, показывающих худшие результаты.
Таблица 2. Результаты тестирования на SPEC FP 2000.
| Тесты | Только по данным | Только по управ- лению | По данным и по управ- лению | Только анализ указа- телей | Все вместе | Оптимизация
-O3 |
|---|
| 168.wupwise | 0,71% | 1,43% | 1,43% | 1,66% | 0,95% | -0,47% |
| 171.swim | -0,30% | -0,30% | 0,30% | -0,44% | -0,15% | -0,15% |
| 172.mgrid | 0,00% | 0,00% | 0,30% | 4,79% | 5,09% | -4,84% |
| 173.applu | 0,24% | 0,00% | 1,18% | -0,71% | -0,24% | 0,95% |
| 177.mesa | -1,09% | 0,00% | 2,89% | 0,14% | 0,82% | 1,73% |
| 178.galgel | 2,51% | -5,75% | 2,51% | -5,92% | -3,41% | 8,76% |
| 179.art | 1,05% | 0,06% | -0,17% | -0,06% | 0,58% | -0,23% |
| 183.equake | -0,90% | -0,23% | -1,13% | -0,23% | -0,45% | -2,24% |
| 187.facerec | 0,19% | 0,00% | -1,12% | -3,16% | -2,99% | 2,87% |
| 188.ammp | 18,84% | 0,15% | 18,84% | -1,52% | 16,87% | 20,68% |
| 189.lucas | 0,12% | -0,12% | -0,36% | -0,12% | 0,00% | 0,00% |
| 191.fma3d | 0,73% | -0,36% | 0,36% | 0,73% | 2,93% | -0,72% |
| 200.sixtrack | 2,43% | 0,00% | 2,08% | -1,04% | 1,04% | 3,16% |
| 301.apsi | 1,12% | -0,67% | 0,45% | -4,45% | -3,13% | 5,57% |
SPEC
FP 2000 | 1,71% | -0,57% | 1,89% | -0,76% | 1,14% | 2,46% |
6. Заключение
В этой статье мы описали проблемы, возникающие при компиляции для архитектур с явно выраженным параллелизмом на уровне команд, на примере задачи поддержки раннего выполнения для Intel Itanium. Разработанный нами алгоритм реализован в компиляторе GCC и протестирован на пакете SPEC CPU 2000. Алгоритм показывает ускорение примерно в 2,5% на пакете вычислительных программ SPEC FP 2000, причем отдельное ускорение достигает 20% (для теста ammp).
В наших дальнейших планах тонкая настройка алгоритма раннего выполнения, а также тестирование этого алгоритма с улучшенным анализом указателей, разработанным нами в рамках предыдущих исследований. Мы планируем включить нашу реализацию алгоритма раннего выполнения в компилятор GCC версии 4.2.
Литература



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС