В те времена, когда компьютеры были большими, это выражение было в ходу. Быть может, и мой опыт кому-то покажется небесполезным.
Предполагается, что читатели сего немного ориентируются в предмете обсуждения: этапах разработки ПО, объектно-ориентированной терминологии, а также в методах проектирования реляционных БД.
К статье прилагается архив, содержащий: модель данных, а также её графическое изображение - для читателей, не имеющих возможности запустить для анализа модели ERwin. Также прилагаются две подпапки: SQL - со сгенерированными скриптами, и BPL - со сгенерированными исходниками компонентов. А также, для полноты представления, - скрипт для создания БД.
Многим программистам время от времени приходится разрабатывать вполне тривиальные отчётно-учётные приложения, "заточенные" под нужды конкретных заказчиков. Системы учёта CD и кассет, складские, зарплатные, и прочие подобные проекты… Разработка их отнимает уйму времени, и можно впасть в отчаяние от осознания того факта, что все они слишком похожи по сути, чтобы тратить на них жизнь! Но и подработать хочется…
На просторах Интернета живёт статья Алексея Вторникова "Как выжить программисту-одиночке" на вечно живую для нашего человека тему "Кто виноват, и что делать?". В ней приведено красочное описание проблем, встающих перед мастером самоделкиным, а также организационные методы их (проблем) решения.
Следование простым, но эффективным правилам, описанным во второй части статьи, помогает справиться с ворохом проблем. Но от подкрепления орг.мер техническими средствами ещё никому не поплохело.
Здесь я опишу технологию разработки учётно-отчётных приложений, которая выкристаллизовалась у меня в процессе разработки многих проектов, а также - инструментальное средство, которое является "последним штрихом", завершающим стройную систему производства софта средней степени сложности размером в десятки и сотни тысяч строк исходного кода.
Это средство - генератор программного кода (тем более, что некоторый подобный опыт у меня уже был), который, имея "на входе" модель данных, спроектированную в ERwin, "на выходе" генерирует SQL-скрипты, содержащие триггеры и хранимые процедуры, а также файлы компонентов (.H, .CPP) для Borland C++ Builder. Для каждой сущности предметной области будет сформирован свой класс, имеющий все поля описанных типов, а также умеющий отображать себя на БД: сохраняться в базе и читать значения своих полей из БД, и "понимающий" связи между сущностями. Эти компоненты включаются в Package, который устанавливается на палитру компонентов, - и вот вам "строительные кубики", из которых можно складывать приложение!
Преимущества такого подхода очевидны: большой пласт тривиального программного кода, который и так пришлось бы писать, греша ошибками и теряя драгоценное время, генерируется за долю секунды и абсолютно безошибочно. Действительно, писать вручную для каждой сущности похожий код, различающийся только в деталях, - непозволительная роскошь.
И хотя платформа, которой я пользуюсь ("Firebird 1.5" + "Borland C++ Builder 6.0"), не находится на острие прогресса, данный подход позволяет поиметь некоторые дивиденды от тех знаний и умений, которыми я овладел ранее. То есть, окупить прежние капиталовложения.
Совокупность навыков, наработок и толики везения позволяет мне очень быстро выпускать первую версию продукта, а значит, становится рентабельной разработка приложений даже для однократной продажи.
И последнее. Не надо, спеша, вещать о том, что существуют-де системы проектирования приложений типа Rational Rose, и т.д. На рынке, наряду с магазинами готового платья, существуют также пошивочные ателье - и, как ни странно, не разоряются.
Поэтому я решил свою уже устоявшуюся технологию разработки БД-приложений (со всеми наворотами, реализующими парадигму повторного использования кода и ресурсов) дополнить последним мазком художника - кодогенератором, дающим "быстрый старт" процессу разработки.
То, что генератор программного кода "заточен" именно под мои наработки, позволяет ему генерировать весьма эффективный код, из которого чрезвычайно легко получается готовое приложение.
Маленький пример: моим последним заказом была разработка системы учёта контрагентов/договоров/поставленного оборудования, и т.д. для ЗАО "…" (пока не получил их согласия на оглашение). Общий объём исходников первой версии приложения составил более 13.500 строк, из них около 3.500 строк было сгенерировано. По-моему, 25% программного кода, которые принесены вам "на блюдечке с голубой каёмочкой" - это совсем неплохо.
Итак, опишу вкратце этапы разработки, которые приходится выполнять каждый раз, когда затевается новый проект.
Как уже упоминалось, я привык разрабатывать свои приложения в двухзвенной архитектуре "клиент-сервер", с использованием СУБД "Firebird 1.5". Не буду расписывать преимущества клиент-серверной модели по сравнению с "настольными" реализациями; просто перечислю их: эффективность, скорость, масштабируемость, возможность многопользовательской работы, и т.д.
Вначале анализируется предметная область - из бесед с представителями заказчика, или путём высасывания из пальца. При этом выделяются сущности и взаимосвязи между ними; простой пример: сущность "Регион" имеет поле "Наименование"; сущность "Населённый пункт" также имеет поле "Наименование", ссылку на "Регион", в котором расположен нас. пункт (кажется, город Каменка есть в любом регионе России), а также, возможно, ссылку на тип населённого пункта (типы должны быть прописаны в справочнике). Между сущностями "Регион" и "Населённый пункт" существует отношение "один-ко-многим".
Уф, это только словами долго расписывать, а при проектировании модели данных, например, в ERwin, - это всего несколько манипуляций мышкой. В-общем, хорошо представляя себе предметную область, разрабатываем модель данных. К счастью, ERwin позволяет сгенерировать SQL-скрипт для создания БД.
Понятия предметной области на уровне абстракции приложения мы оформляем в виде "сущностей", которые в БД представляют собою таблицы и взаимосвязи между ними. Один из стандартов проектирования, которых я придерживаюсь: уникальный идентификатор каждой записи каждой таблицы (primary key) должен быть целым автоинкрементируемым полем, никак не связанным со смысловым наполнением: просто ID. Такой подход многое упрощает. Настолько многое, что это просто праздник какой-то!..
На уровне клиентской части сущности представляются, как классы с набором полей (полностью соответствующим полям в таблицах БД), методами очистки, чтения из БД и записи в БД. Хорошо бы ещё, чтобы классы как-то отслеживали межсущностные связи.
Для каждой сущности генерируется её отображение на платформу разработки. Для серверной части - это генератор, триггеры и процедуры; для клиентской - класс, который умеет обращаться к соответствующим сгенерированным процедурам. Генераторы и триггеры обеспечивают работу автоинкрементных идентификаторов средствами InterBase/Firebird.
Рассмотрим, например, сущность "Город". В скрипте "AutoGen.SQL" мы увидим строчки, создающие генератор для таблицы "CITY":
create generator GEN_ID_CITY;
set generator GEN_ID_CITY to 0;
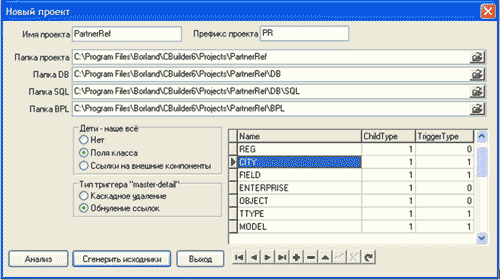
А в скрипте "AutoTrig.SQL" - триггер "BEF_ADD_CITY", срабатывающий при добавлении записи в эту таблицу, и автоматически задающий значение полю "ID_CITY". Генератор кода - это видно на скриншоте - позволяет задать тип каскадного воздействия для таблиц "Master-Detail" индивидуально для каждой сущности: при удалении записи в master-таблице все зависимые записи в detail-таблицах можно либо удалить, либо обNULLить в них ссылки на master-запись. Эта функциональность достигается генерацией соответствующих триггеров для каждой таблицы.
При удалении города из справочной таблицы CITY триггер "BEF_DEL_CITY" обнуляет ссылки на город в таблице "ENTERPRISE".
А для сущности "Предприятие" (ENTERPRISE) метод каскадного воздействия был указан другой: в случае удаления предприятия будут удалены все данные, связанные с ним: документы, договора, контакты, представители, и т.д. (триггер "BEF_DEL_ENTERPRISE").
В скрипте "AutoProc.SQL" находятся сгенерированные процедуры чтения/записи для каждой сущности; в частности, для "Города" - это "GET_CITY" и "PUT_CITY". Причём каждая сущность знает, каким способом себя записать в БД: если экземпляр сущности уже существовал (ID_<сущность> IS NOT NULL), при сохранении будет выбран оператор "update", иначе - если в БД записывается новый экземпляр - будет использован "insert". Здесь-то и пригодилось нам абстрагирование идентификатора записи от смыслового значения: простой целый автоинкрементный ID - это просто подарок судьбы!
Ещё стоит заметить, что все параметры PUT-функции, представляющие собой ID'ы, автоматически нормализуются (им присваивается значение NULL, если оно было равно числовому нулю), что имеет значение для соблюдения ссылочной целостности.
Продолжим рассмотрение сущности "Город", но теперь уже на уровне клиентской части приложения. В папке "BPL" находятся исходники классов - "обёрток" для сущностей; вернее, компонентов. Во первых, в заголовочном файле описаны все поля нашей сущности, но теперь уже в терминах языка С++, а не языка описания данных.
Во вторых, генерируются методы "Clear", "Get" и "Put"; два последних обращаются к уже сгенерированным серверным GET- и PUT-процедурам.
В-третьих, для сущностей, находящихся в отношении "master-detail" (например, "Регион" - "Город"), реализовано "понимание" классами этих связей. Так, класс TPRCity ("Город") является контейнером для объекта класса TPRReg ("Регион"). Это позволяет в методах TPRCity->Get() и TPRCity->Clear() автоматически вызывать соответствующие методы экземпляра класса TPRReg.
Такой подход позволяет, вызвав метод Get() класса "Город", получить сразу и данные о регионе, в котором он расположен. А вызвав метод Enterprise->Get(), мы узнаем всё не только о предприятии, но и о городе (а значит, и регионе!), в котором расположено предприятие, а также наименование отрасли промышленности, к которой оно относится (см. модель данных и приведённые исходники).
Если в какой-либо сущности зависимостей больше, для всех из них будет сгенерирован соответствующий код.
"Имплантировать" классы "master-сущностей" в код классов "detail-сущностей" можно двумя способами (см. скриншот программы): в первом варианте (как в приведённых исходниках) объекты "master-сущностей" будут создаваться в объектах "detail-сущностей", как в контейнере.
Во втором варианте в коде компонента "detail-сущности" будут сгенерированы свойства-указатели на компоненты "master-сущностей". Использоваться это может следующим образом: в процессе проектирования формы на неё помещаются все нужные компоненты ("Город", "Регион", "Предприятие"), и между ними "наводятся мосты" с помощью свойств, указывающих на нужные компоненты. Выбор метода представления связей остаётся за разработчиком.
Вот и всё. Как говорил Высоцкий, "что я хотел сказать своими песнями, то я и сказал". То есть, исходники представлены; в вашей воле их рассматривать и оценивать.
Итак, у нас в руках оказался инструмент (работающий в рамках принятой концепции разработки БД-приложений), который позволяет, имея спроектированную модель данных, в один миг получить "строительные кубики", из которых легко складывается приложение, потребное заказчику.
Те программы, которые не слишком сильно отражают индивидуальность заказчика, представлены на сайте http://goldenask.narod.ru
Часть II
Описание генератора кода было бы неполным без объяснения, на какие вспомогательные классы опирается получающийся программный код.
Сгенерированные исходники компонентов так лаконичны и красивы по той причине, что все компоненты, описывающие сущности, происходят (наследуются) от компонента TAIEssence, код которого приведён в "прицепе".
Этот компонент инкапсулирует некоторые понятия и методы, общие для всех сущностей. Во-первых, мы приняли, что каждый объект сущности обладает целым уникальным идентификатором; поэтому в классе TAIEssence есть public-поле ID, и каждая сущность наследует его.
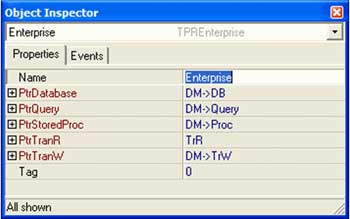
Во-вторых (см. рисунок), каждый компонент имеет свойства-указатели на:
- БД
- TIBQuery
- TIBStoredProc
- транзакции для чтения и записи (TrR, TrW)
Естественно, что каждый объект должен знать, какими манипуляторами ему пользоваться при работе с БД. Метод Notification обслуживает корректное функционирование этих свойств-манипуляторов.
Далее. Объект каждого класса должен знать, как называются серверные GET- и PUT-процедуры, а также их параметры. Для этого заведёны поля ENTITY_ID, PutProc, GetProc, P_ID, R_ID, которые инициализируются правильными значениями в момент присвоения имени сущности свойству ENTITY_NAME. А этот код создаётся генератором кода; в этом можно убедиться, взглянув на исходники предыдущей статьи. В конструкторе каждого компонента обязательно присутствует строка типа «ENTITY_NAME="USER";».
Компонент TAIEssence реализует метод InheritProperties, который устанавливает упомянутые свойства-манипуляторы для всех объектов, динамически создаваемых в текущем классе, как в контейнере (см. исходники к предыдущей статье).
Следующий полезный метод, который позволяет лаконично выражать свои действия классам-потомкам, - это Prepare(). Этот метод подготавливает к исполнению хранимую процедуру с заданным именем. Предварительно процедуре "подсовывается" транзакция, "заточенная" под задачи процедуры: чтение или запись в БД.
Мы плавно подошли к рассмотрению "хитрых" свойств TrR, TrW (типа TAskIBTransaction, который рассмотрим ниже), которые также наследуются сущностями. Эти свойства возвращают наиболее подходящую транзакцию для выполнения какого-либо запроса/процедуры.
Кроме того, каждый экземпляр любой сущности обладает унаследованным от TAIEssence методом с приятным названием Del(). Его функциональность очевидна: каждая сущность должна уметь удалить себя из БД (помимо умений прочитать и записать себя в БД).
Теперь опишем тип TAskIBTransaction, производный от TIBTransaction. Он позволяет более свободно работать с БД, и писать меньше кода; свойства PtrTranR, PtrTranW каждого компонента указывают именно на транзакцию этого типа.
Исходный код класса TAskIBTransaction совсем простенький, и позволяет организовать - нет, не вложенные транзакции, - а "вложенное" к ним обращение.
Мы можем в клиентском приложении написать следующий код:
try {
DM->TrW->StartTransaction();
ScreenToEnterprise(); Enterprise->Put();
PutContacts(); PutPersons(); PutPersContactsToDB();
PutContracts(); PutOffers(); PutDocs();
DM->TrW->Commit();
}
catch(EIBInterBaseError &E) {
DM->TrW->Rollback(); throw;
}
А внутри метода Put() каждого компонента-сущности уже сгенерирован код:
try {
TranW->StartTransaction();
Prepare(PutProc, ettWrite);
PtrStoredProc->ParamByName(P_ID)->AsInteger = ID;
<…>
PtrStoredProc->ExecProc();
ID = PtrStoredProc->ParamByName("R_ID_ENTERPRISE")->AsInteger;
PtrStoredProc->Close();
TranW->Commit();
}
catch(EIBInterBaseError &E) {
TranW->Rollback(); throw;
}
То есть, если PtrTranW компонента указывает на DM->TrW (а обычно так оно и есть), мы можем не писать код, анализирующий, активна ли транзакция, и предпринимающий в соответствии с её состоянием, какие-либо действия.
Соответственно, подобный код не нужен и при завершении транзакции (Commit или Rollback).
Эта возможность обеспечивается отслеживанием глубины вызовов "старта" и окончания транзакции, и выполнением соответствующих методов (StartTransaction() и Commit() или Rollback()) только при первом (последнем) вызове.
Таким образом, этот простенький механизм позволяет не заморачиваться техническими вопросами, а спокойно ваять приложение, справедливо полагая, что механизм "вложенного" вызова транзакция сам во всём разберётся.
Вообще-то, осталось ещё несколько компонентов, облегчающих работу с БД InterBase/Firebird, но их описание отложим "на потом".
Программы, разработанные с использованием описанной методики, "живут" на сайте http://goldenask.narod.ru
К материалу прилагаются файлы:
Исходные коды, sql-скрипты и схемы. (182 K)
Исходный код модулей (2 K)

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС