2009 г.
Обеспечение высокопродуктивного программирования для современных параллельных платформ
А.И. Аветисян, В.В. Бабкова, А.В. Монаков, http://www.ispras.ru/groups/ctt/parjava.html
Труды Института системного программирования РАН
Назад Содержание Вперёд
2. Средства разработки параллельных приложений в среде Java
Среда ParJava позволяет выполнять большую часть разработки параллельной Java-программы на инструментальном компьютере. Для этого используется модель параллельной Java-программы [19], интерпретируя которую на инструментальном компьютере можно получить оценки времени выполнения программы на заданном кластере (кластер определяется числом узлов, параметрами платформы, используемой в качестве его узлов, и параметрами его коммуникационной сети), а также оценки других динамических атрибутов программы, построить модели ее профилей и трасс. Полученная информация о динамических свойствах параллельной программы позволяет оценить границы ее области масштабируемости, помогает прикладному программисту вручную оптимизировать программу, проверяя на интерпретаторе, как отразились произведенные изменения на ее масштабируемости. Возможность использования инструментального компьютера для оптимизации и доводки параллельной программы избавляет программиста от большей части отладочных запусков программы на целевой вычислительной системе, сокращая период отладки и доводки программы.
2.1. Модель параллельной Java-программы и ее интерпретация
Модель SPMD-программы представляет собой совокупность моделей всех классов, входящих в состав моделируемой программы. Модель каждого класса – это множество моделей всех методов этого класса; кроме того, в модель класса включается модель еще одного дополнительного метода, описывающего поля класса, его статические переменные, а также инициализацию полей и статических переменных. Модель метода (функции) состоит из списка описаний локальных и глобальных переменных метода и модифицированного абстрактного синтаксического дерева метода: внутренние вершины модели соответствуют операторам языка Java, а листовые – базовым блокам. В качестве базовых блоков рассматриваются не только линейные последовательности вычислений (вычислительные базовые блоки), но также и вызовы библиотечных функций, вызовы пользовательских методов и функций и вызовы коммуникационных функций. Для обеспечения возможности интерпретации модели по частям введено понятие редуцированного блока, который представляет значения динамических атрибутов уже проинтерпретированных частей метода.
Каждый MPI-процесс моделируемой программы представляется в ее модели с помощью логического процесса, который определен как последовательность действий (примеры действий: выполнение базового блока, выполнение операции обмена и т.п.). Каждое действие имеет определенную продолжительность. В логическом процессе определено понятие модельных часов. Начальное показание модельных часов каждого логического процесса равно нулю. После интерпретации очередного действия к модельным часам соответствующего логического процесса добавляется значение времени, затраченного на выполнение этого действия (продолжительности). Продолжительность каждого действия, а также значения исследуемых динамических параметров базовых блоков, измеряются заранее на целевой платформе.
Для идентификации логических процессов используются номера моделируемых процессов, использованные в моделируемой программе при описании коммуникатора MPI (будем называть их пользовательскими номерами процессов). Как известно, для удобства программирования приложений в стандарте MPI реализована возможность задавать коммуникаторы, позволяющие задавать виртуальные топологии сети процессоров, описывая группы процессов. В среде ParJava коммуникаторы, заданные программистом, отображаются на MPI_COMM_WORLD, получая, тем самым, наряду с пользовательскими номерами внутренние номера. Все инструменты среды ParJava работают с внутренними номерами процессов, но при выдаче сообщений пользователю эти номера переводятся в пользовательские. В дальнейшем, при упоминании номера логического процесса будет подразумеваться его внутренний (системный) номер. Внутренний номер используется для доступа к логическому процессу при моделировании коммуникационных функций.
Для сокращения времени интерпретации и обеспечения возможности выполнения интерпретации на инструментальном компьютере в среде ParJava моделируются только потоки управления процессов моделируемой программы и операции обмена данными между процессами. Это допустимо, так как значения времени выполнения и других исследуемых динамических атрибутов базовых блоков определяются на целевой вычислительной системе до начала интерпретации модели. Интерпретация модели лишь распространяет значения указанных динамических атрибутов на остальные узлы модели. Такой подход позволяет исключить из моделей базовых блоков переменные, значения которых не влияют на поток управления моделируемой программы. В результате часть вычислений, в которых определяются и используются указанные переменные, становится «мертвым кодом» и тоже исключается, что ведет к сокращению, как объема обрабатываемых данных, так и общего объема вычислений во время интерпретации. В некоторых базовых блоках описанный процесс может привести к исключению всех вычислений, такие базовые блоки заменяются редуцированными блоками.
Внутреннее представление модели SPMD-программы разрабатывалось таким образом, чтобы обеспечить возможность возложить как можно большую часть функций интерпретатора на JavaVM. Такое решение позволило существенно упростить реализацию интерпретатора и обеспечить достаточно высокую скорость интерпретации, однако для его реализации потребовалось внести некоторые структурные изменения в модель параллельной программы.
Внутреннее представление модели базового блока B представляет собой пару <DescrB, BodyB>, где DescrB – дескриптор блока B (т.е. семерка <id, τ, P, IC, OC, Time, A>, где id – уникальный идентификатор базового блока, присваиваемый ему при построении модели, τ – тип базового блока, P – ссылка на модель его тела, IC – множество входных управляющих переменных, OC – множество выходных управляющих переменных, Time – время выполнения базового блока, A – ссылка на список остальных его атрибутов), а BodyB – модель тела блока B (список выражений на байт-коде, вычисляемых в блоке B).
Внутреннее представление модели метода определяется как тройка <дескриптор метода, модель потока управления, модель вычислений>. Дескриптор метода содержит сигнатуру метода, список генерируемых методом исключений, список дескрипторов формальных параметров и ссылки на модель потока управления и модель вычислений. Модель потока управления – это модифицированное АСД, описанное в [19], в котором базовые блоки представлены своими дескрипторами. Модель вычислений – это преобразованный байт-код интерпретируемой Java-программы: все базовые блоки модели вычислений включены в состав переключателя, значение управляющей переменной которого определяет номер очередного интерпретируемого базового блока.
Интерпретация модели состоит в выполнении Java-программы, определяющей модель вычислений на JavaVM: в интерпретаторе модели потока управления определяется очередное значение управляющей переменной переключателя модели вычислений, после чего интерпретируется модель соответствующего базового блока. Интерпретация модели базового блока определяется его типом. Для блоков типа «вычислительный блок» (время выполнения таких базовых блоков определяется заранее на целевой платформе) вносится соответствующее изменение во временной профиль метода, и управление возвращается в модель вычислений. Для блоков типа «вызов пользовательской функции», управление возвращается в модель вычислений, где вызывается модель вычислений этого метода. Во время выполнения вызванной модели вычислений в стек помещается текущее состояние, и подгружаются необходимые структуры данных. После интерпретации метода из стека извлекается состояние на момент вызова пользовательской функции и продолжается выполнение модели вычислений первой функции. Для блоков типа «вызов коммуникационной функции», управление возвращается в модель вычислений, где вызывается модель соответствующей коммуникационной функции, которая помимо выполнения передачи данных между логическими процессами обеспечивает вычисление оценки времени выполнения коммуникации и внесение соответствующих изменений во временной профиль. При интерпретации блоков типа «редуцированный блок» (динами-ческие атрибуты таких блоков уже определены и они не интерпретируются), возврат в модель вычислений не происходит; вносятся изменения во временной профиль, и выполняется поиск следующего базового блока.
2.2. Технологический процесс разработки параллельных программ в среде ParJava
В рамках среды ParJava разработан и реализован ряд инструментальных средств, которые интегрированы с открытой средой разработки Java-программ Eclipse [20]. После подключения этих инструментальных средств к Eclipse, получилась единая среда разработки SPMD-программ, включающая как инструменты среды ParJava, так и инструменты среды Eclipse: текстовый редактор, возможность создания и ведения проектов, возможность инкрементальной трансляции исходной программы во внутреннее представление. Интеграция в среду Eclipse осуществлена с помощью механизма «подключаемых модулей».
При разработке параллельной программы по последовательной программе сначала оценивается доля последовательных вычислений, что позволяет (с помощью инструмента “Speed-up”) получить оценку максимального потенциально достижимого ускорения в предположении, что все циклы, отмеченные прикладным программистом, могут быть распараллелены. Затем с использованием инструмента “Loop Analyzer” среды ParJava циклы исследуются на возможность их распараллелить.
Для распараллеленных циклов с помощью инструмента “DataDistr” подбирается оптимальное распределение данных по узлам вычислительной сети. В частности, для гнезд циклов, в которых все индексные выражения и все границы циклов заданы аффинными формами, инструмент “DataDistr” позволяет с помощью алгоритма [21] найти такое распределение итераций циклов по процессорам, при котором не требуется синхронизаций (обменов данными), если, конечно, требуемое распределение существует (см. ниже пример 1). В этом случае инструмент “DataDistr” выясняет, можно ли так распределить итерации цикла по узлам, чтобы любые два обращения к одному и тому же элементу массива попали на один и тот же процессор. Для этого методом ветвей и сечений находится решение задачи целочисленного линейного программирования, в которую входят ограничения на переменные циклов, связанные с необходимостью оставаться внутри границ циклов, и условия попадания на один и тот же процессор для всех пар обращений к одинаковым элементам массива. Задача решается относительно номеров процессоров, причем для удобства процессоры нумеруются с помощью аффинных форм (т.е. рассматривается многомерный массив процессоров).
Если оказывается, что для обеспечения сформулированных условий все данные должны попасть на один процессор, это означает, что цикл не может выполняться параллельно без синхронизации. В последнем случае инструмент “DataDistr” может в диалоговом режиме найти распределение данных по узлам, требующее минимального числа синхронизаций при обменах данными. Для этого к условиям сформулированной задачи линейного программирования добавляются условия на время обращений к одним и тем же элементам массива: например, в случае прямой зависимости, требуется, чтобы обращение по записи выполнялось раньше, чем обращение по чтению. В частности, при решении дополнительных временных ограничений, может оказаться, что они могут быть выполнены, если обрабатываемые в программе массивы будут разбиты на блоки. При этом смежные блоки должны быть распределены по процессорам «с перекрытием», чтобы все необходимые данные были на каждом из процессоров. При этом возникают так называемые теневые грани (т.е. части массива, используемые на данном процессоре, а вычисляемые на соседнем процессоре). Ширина теневых граней определяется алгоритмом решения задачи и определяет фактический объем передаваемых в сети сообщений. Количество теневых граней зависит выбора способа нумерации процессоров: априорно выгоднее всего, чтобы размерность массива процессоров совпадала с размерностью обрабатываемых массивов данных. Однако в некоторых случаях оказывается более выгодным, чтобы размерность массива процессоров была меньше, чем размерность обрабатываемых массивов данных.
Пример 1. В качестве примера работы инструмента “DataDistr” рассмотрим цикл:
for (i = 1; i <= 100; i++)
for(j = 1; j <=100; j++){
X[i,j] = X[i,j] + Y[i – 1,j]; /*s1*/
Y[i,j] = Y[i,j] + X[i,j - 1]; /*s2*/
}
Для приведенного примера инструмент “DataDistr” выдаст следующее распределение:
X[1,100] = X[1,100] + Y[0,100]; /*s1*/
for (p = -99; p <= 98; p++){
if (p >= 0)
Y[p+l,l] = X[p+l,0] + Y[p+l,l]; /*s2*/
for (i = max(l,p+2); i <= min(100,100+p); i++) {
X[i,i-p-l] = X[i,i-p-l] + Y[i-l,i-p-l]; /*s1*/
Y[i,i-p] = X[i,i-p-l] + Y[i,i-p]; /*s2*/
}
if (p <= -1)
X[101+p,100]=X[101+p,100]+Y[101+p-l,100];/*s1*/
}
Y[100,l] = X[100,0] + Y[100,l]; /*s2*/
где p – номер вычислителя, а цикл по p определяет распределение данных по вычислителям. Таким образом, исходный цикл расщепился на 200 цепочек вычислений, каждая из которых может выполняться независимо.
После того, как данные распределены по вычислителям, прикладному программисту необходимо выбрать такие операции обмена данными и так трансформировать свою программу, чтобы добиться максимально возможного перекрытия вычислений и обменов данными. Среда ParJava позволяет решать этот вопрос в диалоговом режиме, используя интерпретатор параллельных программ (инструмент “Interpreter”).
В тривиальных случаях даже использование стандартных коммуникационных функций (MPI_send, MPI_receive) позволяет достичь достаточного уровня масштабируемости. Однако, в большинстве случаев это невозможно, так как приводит к большим накладным расходам на коммуникации, а это в соответствии с законом Амдаля существенно урезает масштабируемость. Достичь перекрытия вычислений и обменов для некоторых классов задач позволяет использование коммуникационных функций MPI_Isend, MPI_Ireceive совместно с функциями MPI_Wait и MPI_Test. Это поясняется примером 2.
Пример 2. Как видно из схемы на рис. 1, необходимо добиться, чтобы во время передачи данных сетевым процессором (промежуток между моментами времени 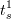 и
и 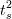 ) вычислитель был занят обработкой данных, а не простаивал в ожидании окончания пересылки.
) вычислитель был занят обработкой данных, а не простаивал в ожидании окончания пересылки.
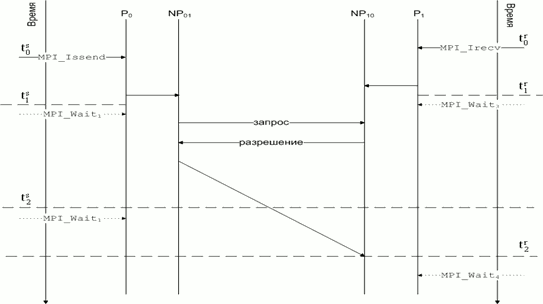
Рис. 1. Схема передачи данных MPI
Подбор оптимальных коммуникационных функций требует многочисленных интерпретаций различных версий разрабатываемой программы. Для ускорения этого процесса строится «скелет» программы и все преобразования делаются над ним. После достижения необходимых параметров параллельной программы автоматически генерируется вариант программы в соответствии с полученным коммуникационным шаблоном.
Проиллюстрировать важность оптимального выбора операций пересылок можно на следующем «скелете» реальной программы моделирования торнадо (рис. 2а). Если в рассматриваемом «скелете» заменить блокирующие операции Send и Recv на неблокирующие и установить соответствующую операцию Wait после гнезда циклов получится «скелет», представленный на рис. 2б. На рис. 3 приведены графики ускорения «скелетов» программы представленного на рис. 2а и 2б. Как видно, такая замена существенно расширила область масштабируемости программы.
При этом окончательная версия «скелета», удовлетворяющая требованиям прикладного программиста, используется для построения трансформированной исходной программы.

Рис. 2. Схематичное изображение алгоритмов с блокирующими и неблокирующими пересылками
К сожалению, в большинстве реальных программ такими простыми преобразованиями не удается достичь необходимого уровня перекрытия, либо такое преобразование невозможно. Использование предлагаемой технологии обеспечивает возможность применения различных преобразований программы, и достигать необходимых параметров программы в приемлемое время.
Этот процесс отладки и оптимизации параллельной программы показывает, что задача сама по себе неформализована. На сегодняшний день не может быть реализован компилятор, делающий оптимизацию автоматически, т.к. в некоторых точках процесса программист обязан принимать волевые решения.
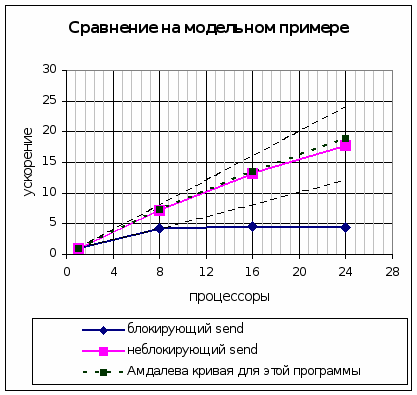
Рис. 3. Сравнение масштабируемости параллельных программ, использующих блокирующие и неблокирующие пересылки
На следующем этапе, необходимо проинтерпретировать полученную программу на реальных данных, для того чтобы оценить, какое количество вычислителей будет оптимальным для счета. Для этого снова используется инструмент «Inerpreter». Поскольку интерпретатор использует смешанную технику, включающую в себя элементы прямого выполнения, довольно остро стоит проблема нехватки памяти на инструментальной машине. Моделирование некоторых серьёзных программ требует использования довольно больших массивов данных, которые не могут быть размещены в памяти одного вычислительного узла. Для решения этой проблемы проводится преобразование модели, представляющее собой удаление выражений программы, значение которых не влияет на поток управления. Это позволяет качественно изменить требования по памяти, в том числе существенно сократив время интерпретации.
Таким образом, инструментальные средства среды ParJava позволяют реализовать технологический процесс, обеспечивающий итеративную разработку параллельной программы. Отметим, что итеративная разработка предполагает достаточно большое число итераций, что может привести к большим накладным расходам по времени разработки и ресурсам. Итеративная разработка реальных программ, предлагаемая в рамках ParJava, возможна благодаря тому, что большая часть процесса выполняется на инструментальном компьютере, в том числе за счет использования инструментов, базирующихся на интерпретаторе параллельных программ.
Применение интерпретатора позволяет достаточно точно оценивать ускорение программы. Ошибка на реальных приложениях не превосходила 10%, и в среднем составила ~5% [36-44]. Окончательные значения параметров параллельной программы можно уточнить при помощи отладочных запусков на целевой аппаратуре.
Назад Содержание Вперёд

