Как быстро найти нужную информацию на избранном Web-узле.
Михаил Талантов
Поиск информации на отдельном Web-узле - это та задача, которую приходится решать каждому пользователю Интернет. Если вы связываетесь с Сетью через модем, то очевидно, что, чем больше вы тратите времени на поиски, тем дороже стоит получаемая информация. В этом случае ее изучение прямо в Сети становится непозволительной роскошью. Многие предпочитают этому ознакомительный просмотр и быстрое копирование необходимых материалов, а затем их более предметное изучение в автономном режиме. Перенос содержимого сервера целиком на локальный компьютер, а для этого существуют специальные средства, в большинстве случаев также менее предпочтителен, чем выборочное копирование. Следовательно, самым полезным навыком становится умение быстро разобраться в структуре узла и способах навигации (т. е. путей перемещения с одной Web-страницы узла на другую). Даже при подключении по выделенной линии, если вы решаете какую-либо поисковую задачу, и требуется просмотреть десятки узлов из списка отклика поисковой машины, вопрос о скорости освоения информации остается одним из определяющих. Можно ли здесь помочь пользователю? Мы предлагаем рассмотреть два важных для разрешения этой проблемы вопроса.
- Типовые структуры размещения информации на Web-узле и возможности навигации
- Логика "третьего" уровня и приемы применения автоматических поисковых средств.
Типовые структуры размещения информации на Web-узле и возможности навигации.
Структура современного Web-узла может быть различной и тесно связана со способами навигации по его страницам, которых не так уж много, а именно:
а) путем начального задания адреса вручную в строке URL или выбора документа из списка истории браузера (программы просмотра Web-страниц), если таковая уже накоплена (мы будем использовать в изложении только два основных браузера, или программы : MS Internet Explorer - сокращенно IE, и Netscape Navigator - NN);
б) по гипертекстовым ссылкам;
в) по каталогам узла с помощью обрезания строки ранее введенного адреса (URL)
Каждый раз вы теряете время, если делаете неверный выбор.
Вариант а) знаком всем и каждому по клавишам "Назад" и "Вперед" на верхней панели браузеров. Не все, тем не менее, знают что у последних поколений этих программ они несколько поумнели: при удержании на клавише нажатой кнопки мыши можно не только перейти к предыдущей или последующей странице, но и выбрать нужную из списка истории посещений за последний сеанс работы.
Вариант б) является самым неоднозначным. Именно он требует хорошего знания структуры информационного узла.
Вариант в) чаще применяется более опытными пользователями. Во многих случаях он удачно работает тогда, когда вы приходите на узел по ссылке, но указанный в ней файл не найден. Браузер выдает сообщение типа "File Not Found" или, если узел более ухожен, отрабатывает специальная программа-скрипт, приносящая извинения разработчика сайта (вместо слова "узел" часто также употребляется термин "сайт", от английского "site") и предлагающая пользователю другие возможности найти информацию самостоятельно.
Пусть вы обратились к ресурсу по URL:
http://server.citmgu.ru/internet/cources/search1.html
Искомый файл search1.html должен находиться на сервере с доменным именем server.citmgu.ru в каталоге cources, который в свою очередь является подкаталогом каталога internet, лежащего в корне сервера. Предположим, что ресурс не найден. После чтения в окне браузера надписи типа "File Not Found" многие возвращаются клавишей возврата браузера назад к предыдущей странице, полагая что информация недоступна, и это напрасно. Сервер работает, - это главное, а сам документ мог быть перемещен, переименован или заменен аналогичным по содержанию. Выход прост: попытаться выйти на головную (домашнюю) страницу узла и разыскать его самостоятельно или с помощью локальной поисковой системы. Для этого в URL следует откусить часть адреса с правой стороны и нажать на "Ввод", т.е. ввести
http://server.citmgu.ru/internet/cources
а в случае повторной неудачи
http://server.citmgu.ru/internet , и так вплоть до собственно доменного имени сервера
http://server.citmgu.ru.
При таких обращениях к каталогам сервера, о которых мы узнаем по длинному адресу, серверная программа может отобразить как список файлов указанного каталога, так и конкретную Web-страницу, относящуюся к этому каталогу и предназначенную для загрузки по умолчанию. При этом переходить сразу к имени сервера, минуя промежуточные обращения, не всегда целесообразно, поскольку, если на сервере, скажем, размещается несколько домашних страниц отдельных пользователей или компаний, то всякая логическая связь между ними, вполне вероятно, отсутствует. Корневой каталог сервера может при этом наполнять еще одна более крупная компания или организация, которая не имеет никакого отношения к документам, лежащим в глубине дерева каталогов и никаких ссылок на эти документы. Следовательно, при отсутствии дополнительной информации лучше идти мелкими шагами, последовательно поднимаясь от каталога к каталогу вверх к корню сервера.
Так как основные перемещения в Web-пространстве приходится все-таки делать по гипертекстовым ссылкам ( случай б) ), то и выбор, который стоит перед пользователем, это либо продолжить движение по ним, либо ознакомиться со структурой каталогов сервера путем усечения адреса (URL-навигации), либо использовать клавиши браузера для возврата к уже просмотренной странице.
Фактически речь идет о том, что одновременно существует два логических уровня организации информации - путем размещения ее определенным образом в иерархии каталогов, а также путем ее связывания с помощью гипертекстовых ссылок.
На качественно скроенном информационном узле, как правило, оба уровня несут смысловую нагрузку, т.е., например, перейти к просмотру предлагаемых учебных курсов по Интернет можно как по ссылке "Курсы об Интернет" на домашней странице узла, так и при обращении по URL
http://server.citmgu.ru/internet/cources
Вообще говоря, различия в базовых структурах Web-узлов во многом строятся на существовании такой двухуровневой системы навигации.
В некоторых источниках принято различать плоскую, линейную, древовидную и комбинированную структуры. Попробуем взглянуть на них глазами не Web-мастера, а пользователя-навигатора.
Плоская структура предполагает, что в центр узла ставится головной документ, с которого имеются ссылки на все остальные документы, те в свою очередь также могут ссылаться друг на друга и на головную страницу. Ясно, что точкой отсчета для очередной процедуры поиска-просмотра в этом случае является головной документ и требуется определить наиболее быстрый доступ к нему с любой страницы, например, по специальной ссылке на каждой странице, по закладке в браузере или по URL.
Структура каталогов стоит здесь на втором плане.
Линейная, или последовательная структура связывает ряд документов, в каждом из которых предусмотрены только ссылки вперед- назад. В чистом виде она встречается редко, и в этом случае перескочить сразу через несколько пунктов - но только назад, позволяет прямой выбор документа из списка просмотренных страниц из истории браузера.
Следующая - древовидная структура гипертекстовых ссылок узла полностью повторяет логическую организацию его каталогов, хотя это, разумеется, не означает, что каталоги и ссылки будут иметь совершенно одинаковые названия. При этом эффективность URL-навигации заметно возрастает.
Комбинированная структура является самой распространенной и предполагает совместное использование упомянутых выше структур. Если переходы по гипертекстовым ссылкам после двух-трех первых десятков просмотренных узлов ни у кого не вызывают затруднений, то URL-навигация редко попадает в поле зрения пользователя, хотя при наличии древовидной структуры документов она может превосходить по эффективности все другие виды перемещений (см., например, каталоги Yahoo, http://www.yahoo.com). На Yahoo, если вы получаете отклик на поисковый запрос, а затем по гиперссылке попадаете в нужный раздел, усечение адреса позволяет быстро переходить к более высоким уровням.
Чтобы воспользоваться URL- навигацией на незнакомом узле, необходимо обратить внимание на то, существует ли там какое-либо соответствие названий каталогов тематическим разделам, заявленым в ссылках на домашней странице, т.е. при очередном шаге по ссылке следует отследить изменение URL в адресном поле браузера.
Безусловно, такие исследования оказываются практичными далеко не всегда, однако готовность воспринять информационный узел в виде узнаваемой структуры помогает сэкономить десятки секунд при работе с наборами документов, что в итоге выливается в серьезное повышение производительности труда..
Логика "третьего" уровня и приемы применения автоматических поисковых средств.
Следующие наши наблюдения будут связаны с "третьим" уровнем логики - дизайном узла и типовыми названиями разделов, в которых размещается информация заданного типа, а также со средствами автоматического поиска, применяемыми на отдельной Web-странице и на узле. Все эти вопросы тесно связаны между собой.
Домашняя страница узла в большинстве случаев содержит в левой или верхней части экрана основное меню, с которого идут ссылки на информационные разделы. Желание разработчика оставлять такое меню видимым из любой точки нередко приводит к использованию фреймов - специальных прямоугольных кадров на экране, в каждом из которых может отображаться свой документ. При переходе по соответствующей ссылке новый документ может загружаться в отдельный фрейм, а меню при этом остается на экране нетронутым в своем фрейме. Если материал во фрейме не помещается целиком на экране, то по умолчанию с правой стороны от него формируется полоса прокрутки. В этом случае фрейм воспринимается как отдельное окно. Всякий раз полезно обратить внимание на размер движка этой полосы, т.к. чем он меньше, тем большая доля информации осталась за пределами экрана, а исходя из этого можно принять то или иное решение об очередном шаге.
Если информации хватает места, то полоски сбоку не возникает и выделить фрейм из экрана становится трудно. При этом у многих пользователей появляются проблемы с поиском и сохранением информации на локальный компьютер, поскольку для этого приходится использовать простые, но все-таки специальные возможности браузеров, а не те, что применяются при отсутствии фреймов, но об этом чуть позже.
Итак, на сегодняшний день широко распространены два вида домашних страниц, а именно презентационная и информационная.
Презентационная страница, как правило, насыщена графикой, имеет небольшое количество ссылок и помещается в один экран. Ее задача - представить компанию или учреждение в Интернет, которые хотят заявить о сфере своей деятельности и указать возможности контактов.
Информационная страница, напротив, сводит к минимуму присутствие графических объектов и дает максимальное текстовое наполнение, что увеличивает ее объем иногда до двух-трех и более экранов.
Оба типа страниц могут предваряться еще одной, так называемой страницей-заставкой, обычно, почти чисто графической, которая загружается перед домашней страницей. Ранее она часто использовалась для выбора кодировки на русскоязычных страницах, однако теперь, когда эта проблема решается браузером автоматически, необходимость в ней отпала, и она просто становится дополнительным препятствием на пути к информации. Задача пользователя -быстро пройти через нее, убедившись в ее минимальной смысловой нагрузке.
Один из самых эффективных способов ускорения работы с Web-страницей - это активное использование средств автоматического поиска, конечно, если вы знаете, что вам нужно. Такой подход особенно практичен для многоэкранных страниц с информационных узлов, когда визуальное ознакомление с материалом становится слишком трудоемким.
Поиск на странице можно произвести по терминам, введенным в специальный поисковый шаблон, который активизируется в браузерах клавишами CTRL-F или через главное меню "Правка- Поиск на этой странице" (MS IE) или "Edit- Find in Page" (NN).
Мало кому известно, что работа этих шаблонов несколько отличается в разных браузерах (см. рис.1) и имеет некоторые особенности.
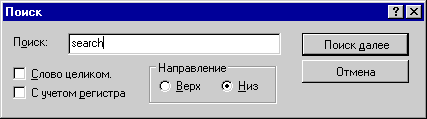
Рис.1. Шаблон для поиска на текущей странице в IE 4.0
Для того чтобы поиск по странице был успешным, к сожалению, предлагаемой справочной системой браузера инструкции, недостаточно. Сама инструкция выглядит достаточно прозаично:
Поиск текста на активной странице
- В меню Правка выберите пункт Найти на этой странице.
- Введите текст, который вы хотите найти.
- Задайте условия поиска.
- Нажмите кнопку Поиск далее.
Тем не менее автору этого материала еще не приходилось встретить новичка, у которого не возникло бы вопросов в связи с использованием этого шаблона, значимость которого по понятным причинам крайне велика - вы просто можете пройти мимо значимой информации. В чем же проблема? Необходимо помнить о следующее:
- Поиск всякий раз проводится вверх или вниз по странице в зависимости от указания направления в шаблоне (см. рис.1) , начиная с начала (если вниз), или с конца документа (если вверх), независимо от того, какая часть страницы отображается на экране на момент начала поиска. Однако это справедливо только в том случае, если на странице нет выделенных областей (на кстати это указано в справке к NN )
- Допустимо введение в шаблон не только единичного термина, но и фразы, что делается одной строкой без использования специального синтаксиса. Специальная пометка в шаблоне позволяет искать с учетом регистра символов.
- Найденное слово или фраза выделяются в тексте, и происходит автоматическое перемещение к их местоположению, однако выделенное поле не всегда можно наблюдать. Сам шаблон, остающийся на экране во время поиска может загораживать его (в этом случае надо сместить шаблон мышью), кроме того оно может быть отображено на экране не целиком, а только его кромкой (следует использовать полосу прокрутки). Другими словами, если нет сообщения о том, что поиск на странице завершен, то обязательно необходимо обнаружить выделенное в тексте поле, иначе информация будет потеряна.
- Если при старте поиска уже есть выделенная область текста, то поиск начинается именно с нее в заданном в шаблоне направлении, само содержимое выделенного поля участия в поиске уже не принимает, также как и оставшаяся часть страницы. Отметим, что всякий раз, когда поисковая процедура закончена, на странице остается выделенная область текста, соответствующая последнему совпадению. Если необходимо выполнить поиск с уже новыми терминами, то следует сначала снять уже существующее выделение кликом мыши в любой точке текста, иначе в новом поиске будет участвовать только часть страницы вверх или вниз от выделенной области в зависимости от направления, заданного в шаблоне.
- Надписи, выполненные в графике не откликаются на поисковые запросы;
- Поисковый шаблон браузера NN 4.0 не имеет возможности задать поиск термина как целого слова, как это позволяет сделать IE (см. рис.1). По умолчанию, если не выставлен нужный флаг, введенный в шаблон термин, обнаруживает совпадения со всеми словами, в которые входит указанный в шаблоне фрагмент, т.е. для термина "поиск" будут найдены совпадения со словами "поиска", "поисковый" и т.п. Таким образом, поиск по странице в IE имеет дополнительную полезную функцию.
- Если при проведении поиска экран разделен на фреймы, то обсуждаемые нами браузеры работают по-разному. Браузер IE объединяет документы из разных фреймов в единое текстовое поле, в котором и производит последовательный поиск после активизации пункта меню "Найти на этой странице", т.е. автоматически переходит из фрейма во фрейм. Браузер NN имеет специальную возможность поиска внути заданного фрейма. При этом не следует забывать о влиянии выделенных областей на работу программ (см. п.4)).
В целом для работы с фреймами NN кажется несколько удобнее. Так, например, узнать в нем о присутствии фреймов, если они не просматриваются явно, можно, заглянув в меню в меню File, где сразу же становятся доступными функции работы с фреймами (frames), также можно получить более предметную информацию о фреймовой структуре и при просмотре источника документа, однако для этого нужно знать язык HTML. ). Для операции с документом во фрейме бывает нужно активизировать соответствующий фрейм щелчком (кликом) левой кнопки мыши по любой неактивной точке фрейма (т.е. не по гипертекстовой ссылке, что спровоцирует немедленный переход). Как же это сделать, если фрейм визуально иногда не отличим от остальной части экрана? Просто следует выполнить клик где-то в области того самого материала, который вас интересует.
Основное меню узла, которое обычно расположено слева или вверху экрана, довольно часто содержит надписи, которые выполнены в виде графики, т.е. представляют собой рисованные объекты, а не алфавитно-цифровой набор символов, введенных с клавиатуры. Поэтому, как было указано выше, нельзя локализовать термины из графического меню с помощью функции поиска по странице. Однако, чтобы не лишать пользователя такой возможности, часто разработчики дублируют заголовки графического меню в самом низу домашней страницы в символьном режиме.
Обратиться к финальным ссылкам, дублирующим графическое меню, бывает полезно и тогда, когда само меню выглядит слишком вычурно и неудобно для чтения.
Глоссарий терминов, соответствующих определенному типу информации, естественно, может отличаться в зависимости от профиля изучаемых ресурсов, поэтому пользователь, постоянно решающий поисковые задачи, должен следить за обогащением своего словарного запаса специфичной сетевой лексикой.
Неординарность этой лексики, базой для которой является естественный язык, связана с тем, что в Сети доминируют авторы, имеющие техническое образование или, по крайней мере, "технократический" образ мышления, которым свойственны лаконичность, колорит и, увы, порочное тяготение к сленгу, во многих случаях совершенно неоправданному и создающему мнимый ореол элитарности вокруг тех, кто им пользуется. Разумеется, чем ближе профиль материала к техническим проблемам и чем фамильярней изложение, тем выше доля сленговой лексики. Так, например, если сайт предназначен для представления программного обеспечения, то раздел, содержащий новые поступления, скорее будет называться не "Новые программы", а "Свежий софт".
На многих серверах предусмотрена страница, которая предлагает еще более детальное изложение его содержания, чем основное меню. Такая страница называется "Карта cервера" ("Site map"). Если ссылка на нее присутствует на домашней странице и приготовлена она не в виде графики, а виде обычного текста, то бысто найти ее можно с помощью фразы-запроса "Карта cервера" ("Site map"), или иногда просто "карта" ("map"). Если ссылка на нее не текстовая, а графическая, то располагается она обычно либо в начале, либо в конце страницы, поэтому в случае нулевого отклика на текстовый запрос, следует просмотреть именно начало и конец страницы, а не приступать к немедленному чтению.
Аналогично используют функцию поиска по странице для того, чтобы найти ссылку на локальную поисковую машину, если она организована разработчиком узла. Тогда после нажатия CTRL-F следует ввести в шаблон слово "поиск" ("search"), и ссылка будет найдена в течении секунды.
Для более специализированных узлов целесообразно выработать собственную тактику выбора значимых терминов. Еще раз хочется подчеркнуть, что важно не просто знать как то, что вы разыскиваете, называется по-русски или по-английски, а как это называется в Интернет.
Хороший принцип, стараться не делать лишних движений, - предполагает продуманность каждого шага поиска и навигации.
Отдельные слова стоит сказать о специальных программах, которые могут быть внедрены прямо в загружаемую вами страницу и написаны на языках Java, JavaScript, VBScript и других. Обычно при старте таких программ в строке состояния браузера внизу экрана возникает сообщение типа "Starting Java..". Об этом должен знать пользователь, поскольку с помощью таких программных средств нередко задается основное меню узла, что , вообще говоря, является не самым лучшим тоном.
Остановимся лишь на одном аспекте меню такого типа, которое обескуражило не одного новичка. Представьте, что зайдя на сайт крупной компании вы не видите даже намека на то, чтобы познакомиться с оглавлением узла. Страница почти пустая! После минутного размышления вы случайно проводите мышью по ничем не выделенному полю экрану, даже не нажимая ее кнопки, и вдруг - вот оно, меню с названиями разделов, плавающими по экрану. Мораль очень проста: указанные программы могут активизироваться по некоторому событию, происходящему на экране, например, по движению мыши (даже без щелчка ее кнопки), так что на многих "молчаливых" поначалу страницах не лишено смысла исследовать поля мышечувствительности, заглянув в каждый уголок.
Другой неприятностью, которую они могут доставить, является возможность автоматического открытия еще одного или нескольких окон браузера, например, в случае, клика по какой-либо гиперссылке, когда документ начинает загружаться в новое окно. Его появление может остаться незаметным, если не обращать внимание на панель задач, если вы работаете в Windows 95/98/NT, которая немедленно реагирует на открытие нового окна. Его пугающей многих особенностью является неактивность клавиши "Назад". Но это вполне объяснимо, т. к. у новорожденного окна еще нет истории, которая сохраняется по-прежнему в спрятанном теперь родительском окне. Не следует допускать большого количества одновременно открытых окон, поскольку они быстро поглощают ресурсы оперативной памяти системы и приводят к некорректной работе браузеров, вплоть до ошибок, делающих необходимой перезагрузку системы.
Известно, что при обращение к Web-серверу по протоколу http, если загрузка происходит слишком долго, можно попытаться клавишей браузера "Останов", или "Stop" прекратить загрузку, а затем снова возобновить ее и добиться от сервера более быстрого обслуживания. Если до остановки загрузки часть информации с узла отобразилась, все гиперссылки в этом случае оказываются работающими. Если вы не дождались окончания загрузки и нажали на появившуюся гиперссылку, то текущая загрузка прерывается автоматически, но только в случае если новый документ открывается в том же окне. Если же он открывается в новом, то происходит одновременная загрузка двух документов: нового и старого, что замедляет передачу каждого из них. Поэтому если старый документ перестал вам быть интересен, необходимо нажать на "Останов" ("Stop") до активизации очередного перехода.
Еще одно замечание сделаем относительно возможности еще до нажатия на гиперссылку отследить адрес (URL), по которому она осуществит переход. Когда указатель мыши встает на ссылку (без нажатия), то в строке состояния браузера появляется соответствующий адрес. Эту информацию можно использовать для предварительной оценки целесообразности такого перехода, она также полезна и в случае применения разработчиком специальной графической карты гипертекстовых ссылок (UsemapClient Side), когда отдельные фрагменты сомкнутой воедино картинки, могут являться ссылками на различные ресурсы.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС