Записки исследователя NTFS
Атрибуты
После нахождения записи mft, самой важной задачей является поиск необходимого атрибута, например с данными. Атрибуты бывают двух видов: резидентные (resident) и нерезидентные (nonresident). Резидентный атрибут умещается в записи MFT, а нерезидентный нет. У обоих атрибутов есть общий заголовок, куда входят поля типа, длины, и пр. и далее свой собственный заголовок (либо для резидентного либо для нерезидентного). Атрибуты идентифицируются типом, но также могут быть и именованными, если поле name_length не нулевое. В общем, заголовок обоих атрибутов описывается структурой.
typedef struct _ATTR_RECORD
{
/*0x00*/ ATTR_TYPES type; //тип атрибута
/*0x04*/ USHORT length; //длина заголовка; используется для перехода к //следующему атрибуту
/*0x06*/ USHORT Reserved;
/*0x08*/ UCHAR non_resident; //1 если атрибут нерезидентный, 0 - резидентный
/*0x09*/ UCHAR name_length; //длина имени атрибута, в символах
/*0x0A*/ USHORT name_offset; //смещение имени атрибута, относительно заголовка
//атрибута
/*0x0C*/ USHORT flags; //флаги, перечислены в ATTR_FLAGS
/*0x0E*/ USHORT instance;
union
{
//Резидентный атрибут
struct
{
/*0x10*/ ULONG value_length; //размер, в байтах, тела атрибута
/*0x14*/ USHORT value_offset; //байтовое смещение тела, относительно заголовка
//атрибута
/*0x16*/ UCHAR resident_flags; //флаги, перечислены в RESIDENT_ATTR_FLAGS
/*0x17*/ UCHAR reserved;
} r;
//Нерезидентный атрибут
struct
{
/*0x10*/ ULARGE_INTEGER lowest_vcn;
/*0x18*/ ULARGE_INTEGER highest_vcn;
/*0x20*/ USHORT mapping_pairs_offset;//смещение списка отрезков
/*0x22*/ UCHAR compression_unit;
/*0x23*/ UCHAR reserved1[5];
/*0x28*/ ULARGE_INTEGER allocated_size; //размер дискового пространства,
//которое было выделено под тело
//атрибута
/*0x30*/ ULARGE_INTEGER data_size; //реальный размер атрибута
/*0x38*/ ULARGE_INTEGER initialized_size;
} nr;
} u;
} ATTR_RECORD, *PATTR_RECORD;
Флаги атрибута описываются структурой.
typedef enum {
ATTR_IS_COMPRESSED = 0x1, //атрибут сжат (compressed)
ATTR_IS_ENCRYPTED = 0x4000, //атрибут зашифрован (encrypted)
ATTR_IS_SPARSE = 0x8000 //атрибут разрежен (sparse)
} ATTR_FLAGS;
Важные типы атрибутов.
typedef enum
{
AT_STANDARD_INFORMATION = 0x10,
AT_ATTRIBUTE_LIST = 0x20,
AT_FILE_NAME = 0x30,
AT_OBJECT_ID = 0x40,
AT_SECURITY_DESCRIPTOR = 0x50,
AT_VOLUME_NAME = 0x60,
AT_VOLUME_INFORMATION = 0x70,
AT_DATA = 0x80,
AT_INDEX_ROOT = 0x90,
AT_INDEX_ALLOCATION = 0xa0,
AT_BITMAP = 0xb0,
AT_REPARSE_POINT = 0xc0,
AT_END = 0xffffffff
} ATTR_TYPES;
В заголовке MFT записи хранится байтовое смещение первого атрибута, относительно самой записи. Прибавляя это смещение к смещению записи, мы получим смещение первого атрибута. Для перехода к следующему элементу нужно прибавить к этому смещению значение поля length заголовка и так для всех последующих заголовков. Концом списка считается значение AT_END, считанное с начала атрибута. Важное замечание: в исходниках Linux NTFS, поле length имеет тип ULONG, однако при исследовании выяснилось, что для корректного обхода атрибутов следует сделать это поле как USHORT, а следующее за ним просто зарезервировать; бывают ситуации, когда в этих старших байтах хранился «мусор». К тому же этих двух байт вполне хватит для адресации смещения внутри MFT записи, размер которой обычно составляет 1 или 4 КБ.
Важное значение имеют флаги атрибутов, которые перечислены в ATTR_FLAGS. Они содержат информацию о характеристиках данного атрибута, например, является ли он зашифрованным или сжатым.
Если все атрибуты для файла не вмещаются в одну MFT запись, тогда для файла создаются расширенные записи (extra records). В таком случае основная (первичная) запись называется базовой и хранит атрибут $ATTRIBUTE_LIST, в котором хранятся ссылки на расширенные файловые записи.
Пользовательский файл обычно содержит атрибуты: $STANDART_INFORMATION – информация о файле (время создания, атрибуты), $FILE_NAME – имя файла, $SECURITY_DESCRIPTOR – дескриптор защиты, $DATA – данные. Описание этих атрибутов, а также их структуры можно найти у Кэрриэ в «Криминалистическом анализе файловых систем».
Для исследования NTFS на диске лучше всего использовать Runtime DiskExplorer for NTFS, поскольку она показывает очень много полезной информации и подробно структуры самой ФС.
Рис. 1. Список атрибутов и файлов у корневого каталога.
Резидентные атрибуты. Как уже упоминалось, такие атрибуты хранят свое тело в записи MFT и для них флаг non_resident в заголовке установлен в ноль. Для считывания данных такого атрибута достаточно определить смещение тела как сумму смещений заголовка атрибута и поля r.value_offset, а затем считать r.value_length байт в память.
Нерезидентные атрибуты. Для таких атрибутов флаг non_resident установлен в 1 и их тела хранятся в отдельных кластерах, на которые указывают отрезки. Отрезок (run) хранит цепочки кластеров, в которых находится содержимое атрибута. Массив отрезков называется списком отрезков (run list). Если атрибут имеет один отрезок, то он не фрагментирован и, соответственно, все кластеры, которые содержат данные являются смежными. Смещение списка отрезков определяется суммой смещения заголовка атрибута и поля nr.mapping_pairs_offset.
Отрезки находятся в сжатом виде и содержат сопоставления LCN-VCN для кластеров. Набор отрезков, описывающих кластеры для атрибута называется списком отрезков (run list). Поле mapping_pairs_offset в заголовке нерезидентного атрибута содержит смещение списка отрезков от начала заголовка атрибута. Фактически, список отрезков это массив структур переменного размера. Размер каждого из полей структуры указывается в предыдущем байте. Первый элемент структуры содержит размер отрезка в кластерах, а второй номер кластера. Байт, описывающий размеры полей размера и номера кластеров условимся называть байтом длин. Младший полубайт байта длин содержит длину поля размера, а старший длину поля номера кластера. Данные в полях структуры хранятся в формате Intel, т. е. младший байт по младшему адресу.
Рассмотрим пример. Нерезидентный атрибут имеет список отрезков вида.
32 90 3A 00 00 0C | 32 30 0F DA A7 1B | 32 A0 36 5E 89 05 | 00
Первый байт – байт длин описывает длины полей первого отрезка. Младший полубайт равен 2, значит на поле длины приходится два байта и длина отрезка равна 0x3A90. Далее, старший полубайт байта длин равен трем и стартовый кластер равен 0xC0000. Получаем первый отрезок начинается с кластера 0xC0000 и заканчивается границей 0xC0000 + 0x3A90 = C3A90. Для перехода к следующему элементу следует прибавить размеры полей, и единицу для байта длин, т. е. 3 + 2 + 1. Для второго отрезка по байту длин видим, что размер полей такой же как в предыдущем отрезке, т. е. младший полубайт равен двойке, значит размер поля длины два и равен 0xF30, старший полубайт равен трем и стартовый VCN равен 0x1BA7DA. Для преобразования VCN в LCN, складываем первый LCN - 0xC0000 и VCN - 0x1BA7DA. Получаем 0xC0000 + 0x1BA7DA = 0x27A7DA. Получаем, второй отрезок начинается с кластера 0x27A7DA и продолжается до 0x27A7DA+0xF30 = 0x27B70A. Для перехода к следующему отрезку добавляем размеры полей плюс единицу для самого байта длин. Третий отрезок начинается с байта длин - 32 и размер в кластерах отрезка равен 0x36A0, VCN равен 0x5895E. Для преобразования VCN-LCN складываем предыдущий стартовый LCN с данным VCN, т. е. 0x27A7DA + 0x5895E = 0x2D3138. Получаем третий отрезок 0x2D3138 - 2D67D8. Следующий байт за отрезком нулевой, следовательно список отрезков закончен. Итак исходный атрибут размещается в кластерах 0xC0000 – 0xC3A90, 0x27A7DA - 0x27B70A, 0x2D3138 – 0x2D67D8 (не включая последний кластеры).
На практике возможны «нестандартные» цепочки кластеров, когда вышеприведенное правило сопоставления относительных смещений в LCN работать не будет, поэтому следует после распаковки списка отрезков сверять полученный из отрезков размер файла с тем, который указывается в заголовке нерезидентного атрибута. В «нормальном» случае эти значения должны совпадать. Кроме того следует выполнять проверку не является ли значение длины этого отрезка больше самого смещения этого отрезка. Если это так, то от распаковки такого отрезка лучше отказаться. Также таким способом нельзя распаковать отрезки разряженного файла.
Например, следующая функция из загрузчика ReactOS для NTFS распаковывает отрезок.
PUCHAR //возвращает указатель на следующий отрезок в списке
NtfsDecodeRun(
PUCHAR DataRun, //на входе, указатель на отрезок для распаковки
LONGLONG *DataRunOffset, //на выходе, распакованное значение кластерного смещения
ULONGLONG *DataRunLength //на выходе, распакованное значение числа кластеров
)
{
UCHAR DataRunOffsetSize; //размер поля смещения
UCHAR DataRunLengthSize; //размер поля длины
CHAR i;
//из старшего полубайта считаем размер поля смещения
DataRunOffsetSize = (*DataRun >> 4) & 0xF;
//из младшего размер поля смещения
DataRunLengthSize = *DataRun & 0xF;
*DataRunOffset = 0;
*DataRunLength = 0;
//указатель на сами данные
DataRun++;
//цикл распаковки длины отрезка, с каждой итерацией значение сдвигается на i-байт и
//прибавляется с длиной
for (i = 0; i < DataRunLengthSize; i++)
{
*DataRunLength += *DataRun << (i << 3);
DataRun++;
}
/* NTFS 3+ sparse files, если файл разряжен */
if (DataRunOffsetSize == 0)
{
*DataRunOffset = -1;
}
else
{
//цикл распаковки смещения
for (i = 0; i < DataRunOffsetSize - 1; i++)
{
*DataRunOffset += *DataRun << (i << 3);
DataRun++;
}
//последний байт может быть знаковым, поэтому он обрабатывается отдельно
*DataRunOffset = ((CHAR)(*(DataRun++)) << (i << 3)) + *DataRunOffset;
}
//возвращаем указатель на следующий отрезок
return DataRun;
}
Каталоги
Каталог представляется записью MFT и содержит ссылки на файлы и другие каталоги. NTFS умеет быстро находить определенный файл в каталоге, потому что каталог хранит информацию о содержащихся в нем файлах в формате дерева. Поиск файла по упорядоченному дереву занимает намного меньше времени, чем при линейном поиске. В свою очередь, это накладывает дополнительные, незначительные временные издержки, при добавлении файлов/каталогов в дерево, на поддержании дерева в упорядоченном виде.
В NTFS используется понятие индекса, которое пришло из баз данных. Индекс - это коллекция элементов (атрибутов), хранящихся в отсортированном порядке. NTFS использует B+ деревья для организации индекса. Для таких деревьев в одном узле дерева может содержаться несколько значений. В NTFS эти значения называются индексными элементами. В качестве индексного элемента может выступать любой атрибут, по которому будет производиться индексация. Для индексов каталогов это всегда атрибут $FILE_NAME, для каждого файла/каталога, содержащегося в нем. Т. о. на каждый файл/каталог приходится как минимум две структуры FILE_NAME, первый как атрибут у файла, а второй, используемый для индекса. Узел дерева хранит последовательность атрибутов $FILE_NAME. Для хранения узлов дерева используются два типа атрибутов $INDEX_ROOT, который присутствует всегда для любой директории и $INDEX_ALLOCATION, который может и не присутствовать для небольших каталогов.
Индексы также используются для метафайла $Secure, который содержит дескрипторы защиты для файлов.
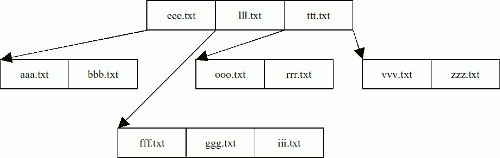
Рис. 4. Дерево каталога NTFS.
Индексный узел наделен заголовком INDEX_HEADER.
typedef struct _INDEX_HEADER //заголовок узла
{
/*0x00*/ ULONG entries_offset; //байтовое смещение первого индексного элемента,
//относительно заголовка узла
/*0x04*/ ULONG index_length; //размер узла в байтах
/*0x08*/ ULONG allocated_size; //выделенный размер узла
/*0x0C*/ ULONG flags;
} INDEX_HEADER, *PINDEX_HEADER;
Индексные узлы хранятся в атрибутах $INDEX_ROOT и $INDEX_ALLOCATION. Первый является резидентным и, следовательно, может хранить только один индексный узел, а второй является нерезидентным и хранить неограниченное число узлов.
Индексный элемент каталога наделен заголовком INDEX_ENTRY_HEADER_DIR.
typedef enum _INDEX_ENTRY_FLAGS
{
INDEX_ENTRY_NODE = 1,
INDEX_ENTRY_END = 2 //последний элемент в узле
} INDEX_ENTRY_FLAGS;
typedef struct _INDEX_ENTRY_HEADER_DIR //заголовок индексного элемента
{
/*0x00*/ MFT_REF indexed_file; //адрес MFT файла
/*0x08*/ USHORT length; //смещение следующего элемента, относительно текущего
/*0x0A*/ USHORT key_length; //длина атрибута $FILE_NAME
/*0x0C*/ INDEX_ENTRY_FLAGS flags; //флаги
/*0x10*/ FILE_NAME_ATTR file_name;//сам атрибут $FILE_NAME, если key_length
//больше нуля.
} INDEX_ENTRY_HEADER_DIR, *PINDEX_ENTRY_HEADER_DIR;
Теперь рассмотрим атрибут $INDEX_ROOT. В самом начале его тела располагается заголовок INDEX_ROOT.
typedef struct _INDEX_ROOT //заголовок $INDEX_ROOT
{
/*0x00*/ ATTR_TYPES type; //тип индексируемого атрибута
/*0x04*/ ULONG collation_rule; //правило упорядочения в дереве
/*0x08*/ ULONG index_block_size; //размер индексной записи в байтах
/*0x0C*/ UCHAR clusters_per_index_block; //size of each index block (record) in clusters
//либо логарифм размера
/*0x0D*/ UCHAR reserved[3]; //unused
/*0x10*/ INDEX_HEADER index; //заголовок индексного узла
} INDEX_ROOT, *PINDEX_ROOT;
Наглядно, INDEX_ROOT представляется следующим образом.
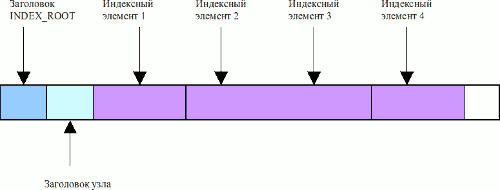
Рис. 5. Тело атрибута $INDEX_ROOT.
Для перечисления всех индексных элементов в узле, необходимо вычислить адрес начального индексного элемента как сумму смещения заголовка INDEX_HEADER, и значения поля entries_offset заголовка узла, а затем перебрать все индексные элементы, пока в очередном элементе не будет встречен флаг INDEX_ENTRY_END. Для перехода от одного элемента к другому следует к адресу индексного элемента добавлять поле length.
Если индексные элементы не вмещаются в атрибуте $INDEX_ROOT, то для их хранения выделяется атрибут $INDEX_ALLOCATION, который по своему строению отличается от $INDEX_ROOT.
Тело атрибута $INDEX_ALLOCATION хранит индексные элементы в индексных записях, каждая из которых обладает заголовком. Индексная запись имеет статический размер и представляет один узел дерева. Ее размер указывается либо в поле index_block_size в INDEX_ROOT либо в поле загрузочного сектора, где может быть байтовый размер записи или двоичный логарифм размера.
Каждая индексная запись обладает заголовком INDEX_ALLOCATION.
typedef struct _INDEX_ALLOCATION //заголовок индексной записи
{
/*0x00*/ ULONG magic; //сигнатура "INDX"
/*0x04*/ USHORT usa_ofs;
/*0x06*/ USHORT usa_count;
/*0x08*/ ULARGE_INTEGER lsn;
/*0x10*/ ULARGE_INTEGER index_block_vcn; //VCN индексной записи
/*0x18*/ INDEX_HEADER index; //заголовок узла
} INDEX_ALLOCATION, *PINDEX_ALLOCATION;
Атрибут $INDEX_ALLOCATION представляет собой последовательность индексных записей, количество которых может быть вычислено делением размера атрибута на размер индексной записи (AttrRec->u.nr.data_size.QuadPart / IndexRootAttr->index_block_size). Зная количество индексных записей, мы можем их обойти как линейный массив элементов.
Индексные записи могут быть выделены для хранения узлов, а могут и нет. Для определения статуса выделения нужно при проходе учитывать атрибут $BITMAP, который хранит в своем теле последовательность бит, каждый из которых соответствует номеру индексной записи (начиная с нуля). Атрибут $BITMAP делится на байты и хранит состояние выделения индексных записей по следующей схеме: если старший бит байта N содержал состояние выделения индексной записи X, тогда младший бит следующего байта N+1 содержит состояние выделения записи X + 1. Рассмотрим пример.
ff 5f 70 ff 05 11111111 01011111 01110000 11111111 00000101
Все индексные записи, начиная с нуля и заканчивая номером 12 выделены, т. к. первый байт содержит все единицы (анализ байтов происходит слева направо, а битов справа налево), следовательно, индексные записи с номерами 0-7 выделены. Переходим к следующему байту, видим, что первые пять бит равны единице, следовательно записи 8-12 выделены для использования. Следующая запись, 13 не выделена.
Для определения байта, в котором хранится бит, характеризующий выделение, нужно индекс записи разделить нацело на восемь. Чтобы рассчитать позицию бита в байте, нужно взять остаток от этого деления.
Если PUCHAR StartBitmap – содержит адрес считанного в память битмапа, тогда
Пусть для примера N = 20. Разделим целочисленно 20 на 8, 20/8 = 2. Получаем второй байт - 01110000. Возьмем остаток 20 % 8 = 4. Сдвигая байт на 4 и обнуляя все байты, кроме первого получаем 1. Следовательно, индексная запись N выделена.
Как показывает практика, свободная индексная запись будет содержать нормальный заголовок индекса, но в первом индексном элементе будет установлен флаг INDEX_ENTRY_END и поле key_length будет обнулено.
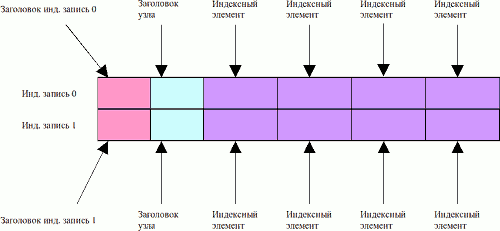
Рис. 6. Организация индексных записей в атрибуте INDEX_ALLOCATION.
Мы рассмотрели механизм, с помощью которого NTFS проходится по дереву каталогов, например, когда нужно открыть конкретный файл. В начале просматривается содержимое первого каталога как дерева и там ищется имя следующего каталога, затем для него выполняется та же операция, пока не будет найден искомый файл.
Индексные записи удобно просматривать с помощью той же DiskExplorer. Для этого нужно выбрать каталог и поставить внизу галочку на пункте Details. В таком случае для директории отобразятся все ее атрибуты. Чтобы просмотреть содержимое атрибута $INDEX_ALLOCATION в бинарном виде, нужно перейти по кластеру с которого начинаются его данные и нажать F3 для просмотра их в бинарном виде.
Тема индексов очень хорошо рассмотрена у того же Кэрриэ в «Криминалистическом анализе».