Прозрачный механизм удаленного обслуживания системных вызовов
Яковенко П.Н.
Институт системного программирования РАН (ИСП РАН), Москва
3. Прозрачное обслуживание системных вызовов
Механизм системных вызовов в процессорах семейства x86 может быть реализован различными способами. Исторически для этого использовались программные прерывания (инструкция INTn), в частности, в ОС Linux для выполнения системного вызова используется вектор 128. Возврат из системного вызова производился при помощи инструкции IRET. При выполнении инструкций INTn и IRET процессор проводит ряд проверок контекста выполнения инструкции и ее параметров. Частое выполнение процессом системных вызовов может оказывать существенное влияние на производительность системы. Как решение, производители процессоров предложили дополнительную пару инструкций, специально предназначенных для быстрого перехода в режим ядра на заданный адрес и обратно: SYENTER/SYSEXIT от Intel и SYSCALL/SYSRET от AMD. Использование этих инструкций является предпочтительным, однако оригинальный механизм выполнения системных вызовов на базе программных прерываний по-прежнему поддерживается из соображений обратной совместимости приложений.
В рассматриваемой в этой работе системе удаленного обслуживания системных вызовов требуется, чтобы доверенные программы использовали для выполнения системных вызовов механизм программных прерываний. Это обусловлено возможностью перехвата инструкции программного прерывания и возврата из прерывания непосредственно при помощи аппаратуры виртуализации. Остальные процессы в вычислительной ВМ могут использовать произвольные механизмы системных вызовов. Из соображений повышения производительности перехват программного прерывания (инструкция INTn) устанавливается, только когда управление передается доверенному процессу, что позволяет предотвратить выход из ВМ, если эта инструкция выполнялась любым другим (недоверенным) процессом.
Флаг перехвата инструкции IRET, в свою очередь, устанавливается при каждом возврате управления ВМ, если в системе выполняется хотя бы один доверенный процесс. Лишь перехватывая все такие инструкции, гипервизор может отследить момент, когда ОС передает управление доверенному процессу. Это необходимо для корректного возобновления процесса после получения результатов из сервисной ВМ. Если результаты готовы, и возврат управления происходит на следующую инструкцию после запроса на системный вызов, то гипервизор записывает результаты, полученные из сервисной ВМ, на регистры и в память процесса, и процесс продолжает выполнение.
При перехвате программного прерывания гипервизор проверяет, что оно было выполнено из контекста доверенного процесса, и что вектор прерывания соответствует вектору запросов на обслуживание системных вызовов (128 в ОС Linux). Далее гипервизор проверяет, требуется ли обслуживать данный системный вызов удаленно в сервисной ВМ или локально в вычислительной ВМ. Правила такого анализа системных вызовов будут рассмотрены в следующем разделе. Если вызов локальный, то гипервизор просто возобновляет управление ВМ, передавая управление ядру ОС. Если вызов удаленный, то гипервизор копирует параметры системного вызова из регистров и, возможно, из адресного пространства процесса в собственную область памяти, формирует запрос и отправляет его в сервисную ВМ. Схема механизма прозрачного обслуживания системных вызовов приведена на рисунке 4.
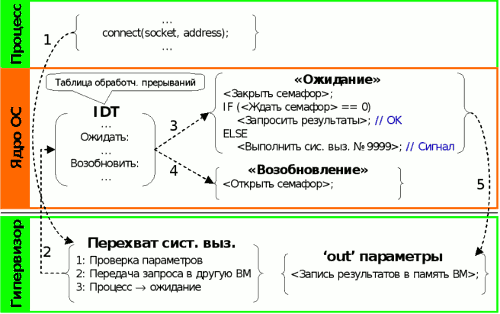
Рисунок 4. Прозрачное обслуживание системного вызова в вычислительной ВМ.
Для определения адреса параметров системного вызова в физической памяти гипервизор программным образом обходит таблицы приписки процесса и вычисляет условно физический адрес в контексте ВМ. Далее, зная отображение памяти ВМ на машинную память, гипервизор вычисляет точное размещение параметров вызова в физической памяти. В процессе чтения параметров, расположенных в памяти процесса (например, в случае системного вызова write), возможна ситуация, когда данные расположены в странице памяти, откачанной ОС на внешнее устройство.
Гипервизор, обнаружив откачанную страницу, вбрасывает в ВМ исключение «ошибка страницы» с адресом, соответствующим отсутствующей странице, и возобновляет управление ВМ. ОС подкачивает страницу в память и возвращает управление процессу по адресу инструкции выполнения системного вызова. Процесс повторно выполняет системный вызов, и гипервизор заново начинает копирование параметров. Такой процесс будет повторяться до тех пор, пока все страницы памяти, занятые входными параметрами системного вызова, не окажутся в физической памяти.
После копирования входных параметров системного вызова гипервизор возобновляет выполнение вычислительной ВМ и переводит процесс в состояние ожидания. Для этого в точке выполнения системного вызова он вбрасывает синхронное прерывание, для которого модуль ядра в вычислительной ВМ зарегистрировал обработчик. В результате, вместо прерывания 128, соответствующего системным вызовам, аппаратура доставляет другое прерывание.
Получив управление, обработчик осуществляет доступ к закрытому семафору, что переводит процесс в состояние ожидания штатными средствами ОС. Процесс ожидает открытия семафора в режиме, допускающем обработку внешних событий. В случае поступления сигнала для процесса ОС прерывает ожидание семафора. Модуль ядра при этом имитирует запрос на выполнение несуществующего системного вызова (например, с номером 9999). Ядро ОС, разумеется, не будет выполнять этот запрос, однако до того, как вернуть управление процессу, оно выполнит обработку поступивших сигналов.
После обслуживания сигнала ОС возвращает управление процессу на исходную инструкцию системного вызова, и процесс повторно выполняет запрос на системный вызов. Гипервизор перехватывает его, определяет, что в данное время системный вызов находится в процессе удаленного обслуживания, снова подменяет прерывание, и процесс во второй раз переходит в состояние ожидания. Такой циклический процесс будет повторяться до тех пор, пока из сервисной ВМ не поступят результаты выполнения системного вызова.
При получении результатов из сервисной ВМ гипервизору необходимо возобновить выполнение доверенного процесса со следующей инструкции, причем в регистр r/eax должен быть записан результат выполнения вызова, а в память процесса (например, в случае системного вызова read) по заданным адресам должны быть записаны выходные данные, если они имеются.
Гипервизор выводит процесс из состояния ожидания посредством вброса другого синхронного прерывания в вычислительную ВМ, обработчик которого освобождает семафор и, тем самым, возобновляет выполнение процесса. Процесс далее выполняет гипервызов на запрос результатов системного вызова. Заметим, что хотя гипервызов производится из контекста ядра, в точке гипервызова на аппаратуре загружены собственные таблицы приписки доверенного процесса. Гипервизор просматривает таблицы и проверяет, что виртуальные адреса, по которым должны быть записаны результаты, отображены на физическую память, и доступ к этим адресам открыт по записи. Наличие доступа только по чтению может означать, что данная область памяти является «копируемой при операции записи». При наличии доступа по записи ко всему необходимому диапазону адресов гипервизор копирует результаты выполнения системного вызова из хранилища в адресное пространство процесса и возобновляет выполнение ВМ. В противном случае гипервизор для всех необходимых виртуальных страниц вбрасывает в ВМ исключение «ошибка страницы», дающее ОС указание выделить память для соответствующей виртуальной страницы и отобразить ее на физическую память.
При удаленном обслуживании системного вызова делегат может получить сигнал от ОС в сервисной ВМ, например, сигнал SIGPIPE о разрыве сетевого соединения. В этом случае делегат извещает гипервизор о полученном сигнале, и гипервизор доставляет сигнал доверенному процессу. Для этого он информирует о сигнале модуль ядра ОС, который, в свою очередь, доставляет сигнал процессу средствами API ядра ОС Linux. Доставка процессу сигнала может привести к его аварийному завершению. В этом случае монитор известит гипервизор об окончании выполнения процесса, и гипервизор освободит память, отведенную под служебные структуры данных.
3.1. Точка обслуживания системного вызова
В подавляющем большинстве случаев системный вызов может быть ассоциирован с ресурсами какой-либо одной из виртуальных машин либо на основании номера системного вызова, либо на основании его параметров. В частности, системный вызов socket, создающий конечную точку для сетевого взаимодействия и возвращающий файловый дескриптор для работы с ней, должен обслуживаться в сервисной ВМ. Системный вызов write требует дополнительного анализа файлового дескриптора, передаваемого в параметрах вызова. Если дескриптор ассоциирован с сокетом, то он должен обслуживаться в сервисной ВМ, в противном случае — в вычислительной ВМ.
ОС в обеих ВМ поддерживают наборы файловых дескрипторов для доверенного процесса и его делегата независимо друг от друга. Если гипервизор после удаленного обслуживания системного вызова вернет доверенному процессу идентификатор файлового дескриптора, полученного от делегата, без каких-либо изменений, то это может привести к наличию в памяти доверенного процесса двух идентичных дескрипторов, которые на самом деле соответствуют разным ресурсам в той и другой ВМ. В дальнейшем при выполнении доверенным процессом системного вызова для такого дескриптора гипервизор не сможет различить, относится ли вызов к локальному ресурсу в вычислительной ВМ или удаленному в сервисной ВМ.
Для решения этой проблемы гипервизор реализует дополнительный уровень абстракции файловых дескрипторов для доверенных процессов. Файловые дескрипторы, хранимые в памяти доверенного процесса (в каких-то переменных), представляют собой не реальные дескрипторы, назначенные ядром ОС в вычислительной или сервисной ВМ, а индексы в таблице удаленных ресурсов, поддерживаемой гипервизором. Гипервизор перехватывает и обрабатывает все системные вызовы доверенного процесса, у которых входные или выходные параметры содержать файловые дескрипторы. Если параметр входной, то гипервизор извлекает из таблицы удаленных ресурсов фактический файловый дескриптор, модифицирует параметры системного вызова и передает его на обслуживание той ВМ, которая является владельцем ресурса с этим дескриптором. Если параметр выходной, то гипервизор создает новую запись в таблице удаленных ресурсов, помечая, какая из виртуальных машин является владельцем ресурса, и модифицирует выходные параметры процесса, подставляя индекс созданной записи вместо фактического значения дескриптора. Компонента гипервизора, отвечающая за обработку файловых дескрипторов, учитывает особенности выделения свободных дескрипторов ОС Linux, включая нюансы работы системных вызовов dup2 и fcntl. Таким образом, по значению, передаваемому доверенным процессом, всегда можно определить виртуальную машину — владельца ресурса и номер файлового дескриптора в ее контексте.
В ряде случаев выполнение системного вызова может задействовать ресурсы обеих ВМ. В частности, параметры системного вызова select и его аналогов, а именно, наборы файловых дескрипторов, для которых процесс ожидает возникновения соответствующих событий, могут одновременно относиться к ресурсам как вычислительной, так и сервисной ВМ. Такой вызов должен обслуживаться одновременно в обеих ВМ, иначе программа может перестать выполняться корректно. При этом системный вызов в каждой виртуальной машине должен обслуживаться только с теми параметрами (файловыми дескрипторами), которые относятся к ресурсам данной ВМ.
При перехвате запроса на выполнение системного вызова, требующего одновременного выполнения в обеих ВМ, гипервизор, используя таблицу удаленных ресурсов, расшивает фактические параметры на два непересекающихся набора (по одному для каждой из ВМ) и выполняет вызов одновременно в обеих ВМ с соответствующими наборами параметров. Модифицированный набор параметров записывается в память доверенного процесса поверх оригинального. Перед возвратом управления процессу (после обслуживания системного вызова) гипервизор восстанавливает исходный набор параметров, возможно, корректируя его с учетом результатов системного вызова, полученных из сервисной ВМ. Итоговым результатом выполнения системного вызова является результат той ВМ, которая хронологически первой закончила выполнение своей части вызова, результаты другой ВМ отбрасываются.
По получении результатов от одной из ВМ гипервизор производит отмену выполнения системного вызова в другой ВМ. Механизм отмены выполнения системного вызова реализован в обеих виртуальных машинах по-разному. В случае вычислительной ВМ модуль ядра посылает доверенному процессу определенный сигнал (не используемый процессом). При этом модуль системы защиты непосредственно перед посылкой сигнала регистрирует для процесса специальный «пустой» обработчик сигнала, представляющий собой адрес RET инструкции в коде доверенной программы. Адрес инструкции указывается в паспорте задачи. Регистрация обработчика гарантирует, что посылка сигнала не приведет к аварийному останову процесса. В сервисной ВМ все системные вызовы, которые могут выполняться одновременно в обеих ВМ, выполняются в отдельном потоке (нити) делегата. Отмена выполнения системного вызова производится посредством принудительного завершения этого потока.
4. Производительность системы
Описанная в этой работе система реализована на базе монитора виртуальных машин KVM [9]. KVM включен в основную ветку разработки ядра ОС Linux и представляет собой модуль, динамически загружаемый в ядро базовой (хост) операционной системы Linux. Управление выполнением ВМ реализуется совместно ядром хост системы, модулем KVM и пользовательской программой QEMU. QEMU виртуализирует периферийные устройства и обеспечивает совместный доступ виртуальных машин к оборудованию, установленному на компьютере и управляемому базовой системой.
Реализация, представленная в этой работе, построена на базовой операционной системе Linux с ядром версии 2.6.31.6 и мониторе виртуальных машин KVM версии 88. Суммарный объем кода компонент системы составляет порядка 16 тыс. строк. Виртуальные машины выполняются под управлением ОС Linux из дистрибутива Fedora версии 9 со штатным ядром версии 2.6.27.12-78.2.8.fc9.i686. На компьютере установлен четырехядерный процессор Phenom 9750 компании AMD с тактовой частотой 2.4 Ггц и 2 Гбайта оперативной памяти. Данный процессор поддерживает технологию аппаратной виртуализации, включая виртуализацию памяти на базе вложенных (NPT) таблиц приписки виртуальной машины. Базовая операционная система использует все четыре ядра процессора (ядро базовой ОС собрано в SMP-конфигурации). Каждой виртуальной машине выделяется по одному виртуальному процессору и по 512 Мбайт оперативной памяти.
Для проведения ряда тестов используется второй компьютер такой же конфигурации. В обоих компьютерах установлены 100 Мбит-ные сетевые адаптеры, связанные друг с другом через сетевой концентратор (хаб). К концентратору подключены только данные две машины.
Доступ виртуальной машины к сети осуществляется посредством создания в базовой ОС штатными средствами ядра ОС программного сетевого интерфейса (TAP0). Этот интерфейс является образом сетевого интерфейса (ETH0) виртуальной машины в базовой системе. Привязка интерфейса TAP0 к физической среде производится через программный Ethernet-мост (bridge) в ядре базовой ОС, также организуемый штатными средствами ОС Linux. Такая конфигурация (рис. 1) позволяет открыть ВМ для других машин в сети, в отличие от конфигурации QEMU по умолчанию, скрывающей ВМ от других машин в сети посредством механизма трансляции сетевых адресов (NAT) и разрешающей только исходящие соединения в ВМ.
Для тестирования производительности мы использовали четыре специально разработанных синтетических теста, моделирующих «тяжелые» для системы сценарии использования, и три типовых программы: утилиту тестирования производительности сети TTCP, программу удаленного доступа SSH и веб-сервер Apache.
Синтетические тесты основаны на выполнении системного вызова select() с одним или двумя файловыми дескрипторами. Один из дескрипторов (локальный), обозначим его LocalFD, представляет собой файл, открытый в контексте вычислительной ВМ, другой (удаленный), обозначим его RemoteFD, — сокет, созданный в сервисной ВМ. Во всех тестах, кроме первого, выполнение системного вызова требует взаимодействия между ВМ. Тесты запускаются из контекста вычислительной ВМ.
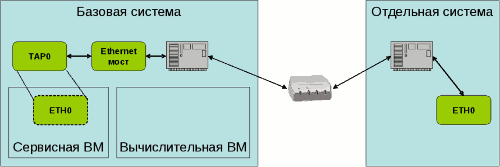
Рисунок 5. Конфигурация сети для тестирования производительности.
Обрамление дескриптора квадратными скобками означает, что запрашиваемая операция не может быть выполнена для данного ресурса, и системный вызов заблокирует выполнение соответствующего пользовательского процесса в одной из ВМ. Отсутствие квадратных скобок означает возможность выполнения операции и немедленный возврат управления пользовательскому процессу. Тогда синтетические тесты проверяют следующие сценарии выполнения системного вызова:
- select(LocalFD);
- select(RemoteFD);
- select(LocalFD, [RemoteFD]);
- select([LocalFD], RemoteFD).
Выполнение системного вызова select(LocalFD) не требует взаимодействия между виртуальными машинами и характеризует «вычислительные» накладные расходы внутри вычислительной ВМ на перехват системных вызовов, анализ фактических параметров и пр. Выполнение системного вызова select(RemoteFD) показывает суммарное время, необходимое на доставку запроса делегату в сервисную ВМ, выполнение системного вызова в ней и возврат результатов процессу, пребывающему все это время в состоянии ожидания.
Выполнение системного вызова select с двумя дескрипторами включает в себя взаимодействие между виртуальными машинами и, кроме того, требует выполнения отмены системного вызова в той ВМ, в которой процесс был заблокирован, а именно, в той ВМ, дескриптор ресурса которой обрамлен квадратными скобками. Следует отметить принципиальное отличие третьего и четвертого теста. В тесте select(LocalFD, [RemoteFD]) отмена системного вызова, выполняемого делегатом в сервисной ВМ, производится асинхронно для процесса в вычислительной ВМ, и он может продолжить свое выполнение, не дожидаясь подтверждения от сетевой ВМ. Такая оптимизация возможна, поскольку для нормального продолжения выполнения процесса достаточно результатов, получаемых локально от ядра вычислительной ВМ. В свою очередь, в тесте select([LocalFD], RemoteFD) процесс не может продолжить выполнение, пока выполнение системного вызова не будет прервано, что приводит к дополнительным накладным расходам.
В таблице 1 указано время выполнения тестов (в секундах) в цикле из 100 тысяч итераций. Первая строка таблицы характеризуют выполнение теста select(LocalFD) в базовой системе. Вторая строка показывает время выполнения теста select(LocalFD) в ВМ со включенным механизмом отслеживания выполнения процесса. Возрастание времени выполнения на один порядок обусловлено затратами на перехват инструкции INTn, инициирующей системный вызов и, главное, инструкции IRET, реализующей возврат в пользовательский режим как из системного вызова, так из обработчиков прерываний. Мы ожидаем, что за счет адаптации предлагаемой системы под механизм быстрого выполнения системных вызовов (SYSCALL/SYSRET), поддерживаемый современными процессорами семейства x86, данный показатель может быть улучшен.
Показатель в третьей строке таблицы говорит о том, что собственно вычислительные затраты системы (за исключением перехвата двух инструкций) составляют порядка 20%. Четвертая строка характеризует накладных расходы на асинхронную отмену части системного вызова, выполняемой делегатом в сервисной ВМ. Отметим, что несколько последовательных операций отмены также выполняются асинхронно, и синхронизация производится только при последующем выполнении «существенного» (не отменяемого) удаленного системного вызова. Кроме того, делегат не будет исполнять системный вызов, если обнаружит, что для него уже поступила команда на отмену. Такое возможно в силу асинхронности выполнения виртуальных машин.
В тесте select(LocalFD, [RemoteFD]) синхронизация производится только после выходе из цикла при закрытии «удаленного» сокета (системный вызов close). При наличии большого количества последовательно отмененных системных вызовов (100 тысяч в данном случае) такая операция синхронизации может занимать продолжительное время, что и отражено в таблице. Непосредственно при выходе из основного цикла время выполнения теста составляет всего 15 секунд. Последующая операция закрытия сокета, требующая синхронизации операций отмены, требует дополнительных 16 секунд.
Последние две строки таблицы характеризуют полноценное удаленное обслуживание системного вызова. Шестая строка таблицы показывает накладные расходы на отмену локальной части системного вызова в вычислительной ВМ, которая всегда выполняется синхронно для процесса.
| Тест | Время (сек.) |
|---|---|
| Базовая система | 1 |
| Виртуальная машина | 9 |
| select(LocalFD) | 11 |
| select(LocalFD, [RemoteFD]) | 15 (31) |
| select(RemoteFD) | 189 |
| select([LocalFD], RemoteFD) | 253 |
Таблица 1. Время выполнения синтетических тестов.
Синтетические тесты показывают, что при худшем сценарии время выполнения системного вызова может возрастать до 250 раз. Однако на практике это не оказывает существенного влияния на время выполнения программы в целом. Во-первых, большинство системных вызовов, требующих удаленного выполнения, включает в себя передачу данных через периферийное устройство (в частности, по сети). Во-вторых, приложение, как правило, выполняет также другие действия, которые нивелируют данные накладные расходы, например, оно может часто находится в состоянии ожидания открытия семафора.
На рисунке 6 приведены результаты тестирования системы на утилите TTCP, выполняющей в цикле передачу пакетов между двумя машинами в сети. Первая диаграмма соответствует оригинальной TTCP утилите, вторая — модифицированной, в которую мы добавили выполнение системного вызова select перед каждой посылкой пакета. Системный вызов select в данном случае выполняется удаленно, т.е. соответствует синтетическому тесту select(RemoteFD). При выполнении оригинальной утилиты накладные расходы на удаленное обслуживание системных вызовов составили всего 2% от суммарного времени выполнения программы. Добавление системного вызова select увеличило накладные расходы до 31%, однако даже в этом случае они значительно меньше издержек в синтетическом тесте select(RemoteFD), где время выполнения увеличилось в 189 раз.
Мы также тестировали предлагаемую систему на утилите удаленного доступа SSH посредством копирования файла между двумя машинами в сети, а также на веб-сервере Apache, запуская для него пакет тестов нагрузочного тестирования Flood. В обоих случаях время выполнения тестов варьировалось в пределах 1% от их выполнения на базовой системе. Таким образом, мы считаем, что предлагаемый механизм удаленного обслуживания системных вызовов является достаточно эффективным для его использования в промышленных задачах.
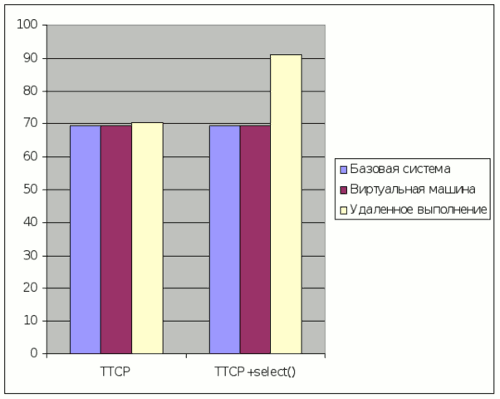
Рисунок 6. Время выполнения утилиты TTCP (сек.).
5. Заключение
В данной работе представлен подход к удаленному выполнению системных вызовов пользовательского процесса, не требующий внесения каких-либо изменений (в том числе, перекомпиляции) ни в код процесса, ни в код операционной системы. Особенностью рассматриваемого подхода является то, что процессу может быть предоставлен контролируемый доступ к таким ресурсам, к которым операционная система, под управлением которой выполняется процесс, ни прямого, ни опосредованного доступа не имеет. Это позволяет предоставлять селективный доступ к ресурсам, требующим контроля (например, сети Интернет), отдельным доверенным пользовательским процессам, оставляя в то же время эти ресурсы недоступными другим процессам и даже ядру операционной системы.
Предлагаемый подход основан на выполнении операционной системы (и управляемых ею процессов) внутри аппаратной виртуальной машины. Монитор виртуальных машин (гипервизор) перехватывает системные вызовы отдельных доверенных процессов и при необходимости передает их на обслуживание сервисной машине. Сервисная машина может быть другой виртуальной машиной, выполняющейся параллельно, или другой физической машиной, с которой у гипервизора есть канал связи.
Рассматриваемый подход реализован на базе монитора виртуальных машин KVM. В качестве сервисной машины использовалась параллельно выполняющаяся виртуальная машина, а в качестве контролируемых ресурсов было выбраны сетевые ресурсы (в т.ч. ресурсы Интернета). Тестирование производительности системы показало, что на реальных приложениях накладные расходы на удаленное обслуживание системных вызовов укладываются в пределы 3 процентов.