|

2003 г
Iptables Tutorial 1.1.19
Oskar Andreasson
Перевод: Андрей Киселев
http://www.linuxshare.ru
Последнюю версию документа можно получить по адресу: http://iptables-tutorial.frozentux.net/ .
Допускается копирование и/или модификация данного документа или его части, в
соответствии с соглашениями, принятыми в GNU Free Documentation License, версии
1.1. Неизменяемыми разделами являются раздел "Введение" и все подразделы этого
раздела, а так же разделы, начинающиеся словами "Original Author: Oskar
Andreasson", Копия GNU Free Documentation License включена в данный документ и
находится в секции "GNU Free Documentation License".
Все сценарии в данном руководстве подпадают под действие GNU General Public
License. Они являются свободно распространяемыми и могут копироваться и/или
модифицироваться в соответствии с условиями GNU General Public License версии
2.
Сценарии распространяются в надежде на то, что они будут полезны вам, но БЕЗ
КАКИХ ЛИБО ГАРАНТИЙ. За дополнительной информацией обращайтесь к тексту GNU
General Public License.
С данным документом должна распространяться копия GNU General Public License,
в секции "GNU General Public License"; в случае ее отсутствия вы можете написать
по адресу Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA
02111-1307 USA
Прежде всего, я хотел бы посвятить данный документ моей замечательной подруге
Нинель (Ninel). Она поддерживает меня больше, чем я когда-либо смогу поддержать
ее.
Во-вторых - всем разработчикам Linux сделавшим эту замечательную операционную
систему, за их невероятно напряженный труд.
Я человек, который имеет на своем попечении достаточно много стареньких
компьютеров, объединенных мною в локальную сеть с выходом в Интернет, и
обеспечивающий их безопасность. И в этом отношении переход от ipchains к
iptables является оправданным. Ранее для повышения безопасности своей сети, вы
могли отсекать все пакеты, закрывая определенные порты, однако это порождало
проблемы с пассивным FTP (passive FTP) или исходящим DCC в IRC (outgoing DCC in IRC), для
которых порты на сервере назначаются динамически и потом сообщаются клиенту для
выполнения соединения. В самом начале я столкнулся с некоторыми 'болезнями',
перекочевавшими из ipchains, и считал код iptables не совсем готовым к
окончательному выпуску. Сегодня же я мог бы порекомендовать всем, кто использует
в своей работе ipchains и ipfwadm 'пересесть' на iptables!
Этот документ написан, так чтобы облегчить читателям понимание замечательного
мира iptables. Здесь вы не найдете информации об ошибках в iptables или в
netfilter. Если вы столкнетесь с ними, то можете связяться с командой
разработчиков, а они в ответ могут сообщить вам, действительно ли существует
такая ошибка. На сегодняшний день iptables и netfilter практически не содержат
ошибок, хотя изредка одна - две "проскакивают". Информация о таких ошибках
обязательно появляется на главной странице проекта Netfilter.
Вышесказанное также означает, что при написании наборов правил, прилагаемых к
данному руководству, не учитывалось возможное наличие каких-либо ошибок внутри
netfilter. Основная цель примеров - показать порядок написания набора правил и
проблемы, с которыми вы можете столкнуться. Например, в этом документе не
поясняется, как закрыть уязвимость Apache 1.2.12 на HTTP порту (фактически в
примерах вы найдете, как закрыть этот порт, но по другой причине).
Этот документ был написан с целью дать начинающим хороший, простой и в то же
время достаточно полный учебник по iptables. Он не содержит информации по
действиям и критериям из patch-o-matic по той простой причине, что потребовалось
бы слишком много усилий, чтобы запомнить весь список изменений. Если у вас
возникнет необходимость в получении информации по модификациям patch-o-matic, то
вам следует обращаться к документации, которая сопровождает конкретный
patch-o-matic, она доступна на главной странице проекта Netfilter.
Данное руководство предполагает наличие у читателя начальных сведений о
Linux/Unix, языке сценариев командной оболочки. Кроме того, вы должны знать -
как пересобрать ядро операционной системы и иметь некоторое представление о его
внутреннем устройстве.
Я постарался, насколько это возможно, сделать документ доступным для
понимания как можно более широкому кругу читателей, однако я не всесилен, и
поэтому от вас все-таки потребуется наличие некоторых познаний.
В данном документе приняты следующие соглашения по выделению информации
различного рода:
-
Команды, вводимые пользователем, и вывод, получаемый в результате работы
команд, отображаются моноширинным шрифтом, кроме того, ввод пользователя
отображается жирным шрифтом: [blueflux@work1 neigh]$ ls
default eth0 lo
[blueflux@work1 neigh]$
-
Все команды и имена программ отображаются жирным
шрифтом .
-
Все упоминания об аппаратном обеспечении, а так же о внутренних механизмах
ядра или абстрактных понятиях системы (например: петлевой (loopback)
интерфейс), отображаются курсивом.
-
Имена файлов и пути к файлам отображаются таким образом: /usr/local/bin/iptables.
Скажем так, я посчитал, что существует досадный пробел в HOWTO по части
информации об iptables и функциях сетевого фильтра (netfilter), реализованных в
новой серии ядер 2.4.x Linux. Кроме всего прочего, я попытался ответить на
некоторые вопросы по поводу новых возможностей, например проверки состояния
пакетов (state matching). Большинство из них проиллюстрированы в файле скрипта
rc.firewall.txt,
который вы можете вставить в /etc/rc.d/. Для тех, кому
интересно, готов сообщить, что этот файл первоначально был основан на
masquerading HOWTO.
Там же вы найдете небольшой сценарий rc.flush-iptables.txt,
написанный мною, который вы можете использовать, для своих нужд, при
необходимости расширяя под свою конфигурацию.
Я консультировался с Марком Бучером (Marc Boucher) и другими членами команды
разработчиков netfilter. Пользуясь случаем, выражаю огромную признательность за
их помощь в создании данного руководства, которое изначально было написано для
boingworld.com, а теперь доступно на моем персональном сайте frozentux.net. С
помощью этого документа вы пройдете процесс настройки шаг за шагом и, надеюсь,
что к концу изучения его вы будете знать о пакете iptables значительно больше.
Большая часть материала базируется на файле rc.firewall.txt, так как я считаю,
что рассмотрение примера -- лучший способ изучения iptables. Я пройду по
основным цепочкам правил в порядке их следования. Это несколько усложняет
изучение, зато изложение становится логичнее. И, всякий раз, когда у вас
возникнут затруднения, вы можете обращаться к этому руководству.
Этот документ содержит несколько терминов, которые следует пояснить прежде,
чем вы столкнетесь с ними.
DNAT - от англ. Destination Network Address Translation -- Изменение Сетевого
Адреса Получателя. DNAT - это изменение адреса назначения в заголовке пакета.
Зачастую используется в паре с SNAT. Основное применение -- использование
единственного реального IP-адреса несколькими компьютерами для выхода в Интернет
и предоставления дополнительных сетевых услуг внешним клиентам.
"Поток" (Stream) - под этим термином подразумевается соединение, через
которое передаются и принимаются пакеты. Я использовал этот термин для
обозначения соединений, через которые передается по меньшей мере 2 пакета в
обеих направлениях. В случае TCP это может означать соединение, через которое
передается SYN пакет и затем принимается SYN/ACK пакет. Но это так же может
подразумевать и передачу SYN пакета и прием сообщения ICMP Host unreachable.
Другими словами, я использую этот термин в достаточно широком диапазоне
применений.
SNAT - от англ. Source Network Address Translation -- Изменение Сетевого
Адреса Отправителя. SNAT - это изменение исходного адреса в заголовке пакета.
Основное применение -- использование единственного реального IP-адреса
несколькими компьютерами для выхода в Интернет. В натоящее время диапазон
реальных IP-адресов, по стандарту IPv4, недостаточно широк, и его не хватает на
всех (переход на IPv6 разрешит эту проблему).
"Состояние" (State) - под этим термином подразумевается состояние, в котором
находится пакет, согласно RFC 793 -
RFC
793 - Transmission Control Protocol, а также трактовкам, используемым в
netfilter/iptables. Хочу обратить ваше внимание на тот факт, что определения
состояний пакетов, как для внутренних так и для внешних состояний, используемые
Netfilter, не полностью соответствуют указанному выше RFC 793.
"Пространство пользователя" (User space) - под этим термином я подразумеваю
все, что расположено за пределами ядра, например: коменда iptables -h выполняется за пределами ядра, в то время как
команда iptables -A FORWARD -p tcp -j ACCEPT
выполняется (частично) в пространстве ядра, поскольку она добавляет новое
правило к имеющемуся набору.
"Пространство ядра" (Kernel space) - в большей или меньшей степени является
утверждением, обратным термину "Пространство пользователя". Подразумевает место
исполнения - в пределах ядра.
"Userland" - см. "Пространство пользователя".
Целью данной главы является оказание помощи в понимании той роли, которую
netfilter и iptables играют в Linux сегодня. Так
же она должна помочь вам установить и настроить межсетевой экран (firewall).
Пакеты iptables могут быть загружены с
домашней страницы проекта
Netfilter. Кроме того, для работы iptables соответствующим образом должно
быть сконфигурировано ядро вашей Linux-системы. Настройка ядра будет обсуждаться
ниже.
Для обеспечения базовых возможностей iptables,
с помощью утилиты make config или ей подобных
(make menuconfig или make
xconfig прим. перев.), в ядро должны быть включены следующие опции:
CONFIG_PACKET - Эта опция необходима для
приложений, работающих непосредственно с сетевыми устройствами, например:
tcpdump или snort.
 |
Строго говоря, опция CONFIG_PACKET не требуетсядля работы iptables, но,
поскольку она используется довольно часто, я включил ее в список. Если вам
эта опция не нужна, то можете ее не
включать. |
CONFIG_NETFILTER - Эта опция необходима, если
вы собираетесь использовать компьютер в качестве сетевого экрана (firewall) или
шлюза (gateway) в Интернет. Другими словами, вам она определенно понадобится,
иначе зачем тогда читать это руководство!
И конечно нужно добавить драйверы для ваших устройств, т.е. для карты
Ethernet, PPP и SLIP. Эти опции
необходимы для обеспечения базовых возможностей iptables, для получения дополнительных возможностей
придется включить в ядро некоторые дополнительные опции. Ниже приводится список
опций для ядра 2.4.9 и их краткое описание:
CONFIG_IP_NF_CONNTRACK - Трассировка
соединений. Трассировка соединений, среди всего прочего, используется при
трансляции сетевых адресов и маскарадинге (NAT и Masquerading). Если вы собираетесь строить сетевой экран
(firewall) для локальной сети, то вам определенно потребуется эта опция. К
примеру, этот модуль необходим для работы rc.firewall.txt.
CONFIG_IP_NF_FTP - Трассировка FTP соединений.
Обмен по FTP идет слишком интенсивно, чтобы использовать обычные методы
трассировки. Если не добавить этот модуль, то вы столкнетесь с трудностями при
передаче протокола FTP через сетевой экран (firewall).
CONFIG_IP_NF_IPTABLES - Эта опция необходима
для выполнения операций фильтрации, преобразования сетевых адресов (NAT) и
маскарадинга (masquerading). Без нее вы вообще ничего не сможете делать с
iptables.
CONFIG_IP_NF_MATCH_LIMIT - Этот модуль
необязателен, однако он используется в примерах rc.firewall.txt.
Он предоставляет возможность ограничения количества проверок для некоторого
правила. Например, -m limit --limit 3/minute
указывает, что заданное правило может пропустить не более 3-х пакетов в минуту.
Таким образом, данный модуль может использоваться для защиты от нападений типа
"Отказ в обслуживании".
CONFIG_IP_NF_MATCH_MAC - Этот модуль позволит
строить правила, основанные на MAC-адресации. Как
известно, каждая сетевая карта имеет свой собственный уникальный Ethernet-адрес,
таким образом, существует возможность блокировать пакеты, поступающие с
определенных MAC-адресов (т.е. с определенных сетевых
карт). Следует, однако, отметить что данный модуль не используется в rc.firewall.txt
или где либо еще в данном руководстве.
CONFIG_IP_NF_MATCH_MARK - Функция маркировки
пакетов MARK. Например, при использовании функции
MARK мы получаем возможность пометить требуемые
пакеты, а затем, в других таблицах, в зависимости от значения метки, принимать
решение о маршрутизации помеченного пакета. Более подробное описание функции
MARK приводится ниже в данном документе.
CONFIG_IP_NF_MATCH_MULTIPORT - Этот модуль
позволит строить правила с проверкой на принадлежность пакета к диапазону
номеров портов источника/приемника.
CONFIG_IP_NF_MATCH_TOS - Этот модуль позволит
строить правила, отталкиваясь от состояния поля TOS в
пакете. Поле TOS устанавливается для Type Of Service.
Так же становится возможным устанавливать и сбрасывать биты этого поля в
собственных правилах в таблице mangle или командами
ip/tc.
CONFIG_IP_NF_MATCH_TCPMSS - Эта опция добавляет
возможность проверки поля MSS в TCP-пакетах.
CONFIG_IP_NF_MATCH_STATE - Это одно из самых
серьезных усовершенствований по сравнению с ipchains. Этот модуль предоставляет возможность
управления TCP пакетами, основываясь на их состоянии
(state). К примеру, допустим, что мы имеем установленное TCP соединение, с
траффиком в оба конца, тогда пакет полученный по такому соединению будет
считаться ESTABLISHED (установленное соединение
-- прим. ред). Эта возможность широко используется в примере rc.firewall.txt.
CONFIG_IP_NF_MATCH_UNCLEAN - Этот модуль
реализует возможность дополнительной проверки IP, TCP, UDP и ICMP пакетов на предмет наличия в них несоответствий,
"странностей", ошибок. Установив его мы, к примеру, получим возможность
"отсекать" подобного рода пакеты. Однако хочется отметить, что данный модуль
пока находится на экспериментальной стадии и не во всех случаях будет работать
одинаково, поэтому никогда нельзя будет быть уверенным, что мы не "сбросили"
вполне правильные пакеты.
CONFIG_IP_NF_MATCH_OWNER - Проверка "владельца"
соединения (socket). Для примера, мы можем позволить только пользователю root
выходить в Internet. Этот модуль был написан как пример работы с iptables. Следует заметить, что данный модуль имеет
статус экспериментального и может не всегда выполнять свои функции.
CONFIG_IP_NF_FILTER - Реализация таблицы filter в которой в основном и осуществляется фильтрация. В
данной таблице находятся цепочки INPUT, FORWARD и OUTPUT. Этот модуль
обязателен, если вы планируете осуществлять фильтрацию пакетов.
CONFIG_IP_NF_TARGET_REJECT - Добавляется
действие REJECT, которое производит передачу ICMP-сообщения об ошибке в ответ на входящий пакет, который
отвергается заданным правилом. Запомните, что TCP
соединения, в отличие от UDP и ICMP, всегда завершаются или отвергаются пакетом TCP RST.
CONFIG_IP_NF_TARGET_MIRROR - Возможность
отправки полученного пакета обратно (отражение). Например, если назначить
действие MIRROR для пакетов, идущих в порт HTTP через нашу цепочку INPUT (т.е.
на наш WEB-сервер прим. перев.), то пакет будет отправлен обратно (отражен) и, в
результате, отправитель увидит свою собственную домашнюю страничку. (Тут одни
сплошные "если": Если у отправителя стоит WEB-сервер, если он работает на том же
порту, если у отправителя есть домашняя страничка, и т.д. . Суть-то собственно
сводится к тому, что с точки зрения отправителя все выглядит так, как будто бы
пакет он отправил на свою собственную машину, а проще говоря, действие MIRROR меняет местами адрес отправителя и получателя и
выдает измененный пекет в сеть прим. перев.)
CONFIG_IP_NF_NAT - Трансляция сетевых адресов в
различных ее видах. С помощью этой опции вы сможете дать выход в Интернет всем
компьютерам вашей локальной сети, имея лишь один уникальный IP-адрес. Эта опция
необходима для работы примера rc.firewall.txt.
CONFIG_IP_NF_TARGET_MASQUERADE - Маскарадинг. В
отличие от NAT, маскарадинг используется в тех случаях, когда заранее неизвестен
наш IP-адрес в Интернете, т.е. для случаев DHCP, PPP, SLIP или какого-либо другого
способа подключения, подразумевающего динамическое получение IP-адреса.
Маскарадинг дает несколько более высокую нагрузку на компьютер, по сравнению с
NAT, однако он работает в ситуациях, когда невозможно заранее указать
собственный внешний IP-адрес.
CONFIG_IP_NF_TARGET_REDIRECT - Перенаправление.
Обычно это действие используется совместно с проксированием. Вместо того, чтобы просто пропустить пакет
дальше, это действие перенаправляет пакет на другой порт сетевого экрана
(прокси-серверу прим. перев.). Другими словами, таким способом мы можем
выполнять "прозрачное проксирование".
CONFIG_IP_NF_TARGET_LOG - Добавляет действие
LOG в iptables. Мы
можем использовать этот модуль для фиксации отдельных пакетов в системном
журнале (syslog). Эта возможность может оказаться весьма полезной при отладке
ваших сценариев.
CONFIG_IP_NF_TARGET_TCPMSS - Эта опция может
использоваться для преодоления ограничений, накладываемых некоторыми
провайдерами (Internet Service Providers), которые блокируют ICMP Fragmentation Needed пакеты. В результате таких
ограничений серверы провайдеров могут не передавать web-страницы, ssh может
работать, в то время как scp обрывается после установления соединения и пр. Для
преодоления подобного рода ограничений мы можем использовать действие TCPMSS ограничивая значение MSS
(Maximum Segment Size) (обычно MSS ограничивается размером MTU исходящего
интерфейса минус 40 байт прим. перев.). Таким образом мы получаем возможность
преодолеть то, что авторы netfilter называют "преступной безмозглостью
провайдеров или серверов" ("criminally braindead ISPs or servers") в справке по
конфигурации ядра.
CONFIG_IP_NF_COMPAT_IPCHAINS - Добавляет
совместимость с более старой технологией ipchains. Вполне возможно, что подобного рода
совместимость будет сохранена и в ядрах серии 2.6.x.
CONFIG_IP_NF_COMPAT_IPFWADM - Добавляет
совместимость с ipfwadm, не смотря на то что это
очень старое средство построения брандмауэров.
Как вы можете видеть, я дал краткую характеристику каждому модулю. Данные
опции доступны в ядре версии 2.4.9. Если вам потребуются дополнительные
возможности - советую обратить внимание на расширения patch-o-matic, которые добавляют достаточно большое
количество дополнительных функций к Netfilter. Patch-o-matic - это набор дополнений, которые, как
предполагается, в будущем будут включены в состав ядра.
Для работы сценария rc.firewall.txt
вам необходимо будет добавить в ядро следующие опции или собрать соответствующие
подгружаемые модули. За информацией по опциям, необходимым для работы других
сценариев, обращайтесь к приложению с примерами этих сценариев.
Выше приведен список минимально необходимых опций ядра для сценария rc.firewall.txt
Перечень опций, необходимых для других примеров сценариев вы сможете найти в
соответствующих разделах ниже. Сейчас же мы остановимся на главном сценарии и
начнем его изучение.
В первую очередь посмотрим как собрать (скомпилировать) пакет iptables. Сборка пакета в значительной степени зависит от
конфигурации ядра и вы должны это понимать. Некоторые дистрибутивы предполагают
предустановку пакета iptables, один из них -- Red
Hat. Однако, в RedHat этот пакет по умолчанию выключен, поэтому ниже мы
рассмотрим как его включить в данном и в других дистрибутивах.
Для начала пакет с исходными текстами iptables
нужно распаковать. Мы будем рассматривать пакет iptables
1.2.6a и ядро серии 2.4. Распакуем как обычно, командой bzip2 -cd iptables-1.2.6a.tar.bz2 | tar -xvf -
(распаковку можно выполнить такжк командой tar -xjvf
iptables-1.2.6a.tar.bz2). Если распаковка прошла удачно, то пакет будет
размещен в каталоге iptables-1.2.6a. За
дополнительной информацией вы можете обратиться к файлу iptables-1.2.6a/INSTALL, который содержит подробную
информацию по сборке и установке пакета.
Далее необходимо проверить включение в ядро дополнительных модулей и опций.
Шаги, описываемые здесь, будут касаться только наложения "заплат" (patches) на
ядро. На этом шаге мы установим обновления, которые, как ожидается, будут
включены в ядро в будущем.
|
Некоторые из них находятся пока на экспериментальной стадии и наложение
этих заплат может оказаться не всегда оправданной, однако среди них есть
чрезвычайно интересные функции и действия.
Выполним этот шаг, набрав команду (естественно, обладая правами
пользователя root) |
make pending-patches
KERNEL_DIR=/usr/src/linux/
Переменная KERNEL_DIR должна содержать путь к исходным
текстам вашего ядра. Обычно это /usr/src/linux/. Если
исходные тексты у вас расположены в другом месте, то, соответственно, вы должны
указать свой путь.
|
Здесь предполагается выполнить несколько обновлений и дополнений,
которые определенно войдут в состав ядра, но несколько позднее, сейчас же
мы возьмем их отсюда выполнив команду: |
make most-of-pom
KERNEL_DIR=/usr/src/linux/
В процессе выполнения вышеприведенной команды у вас будет запрашиваться
подтверждение на обновление каждого раздела из того, что в мире netfilter
называется patch-o-matic. Чтобы установить все "заплатки" из patch-o-matic, вам
нужно выполнить следующую команду:
make patch-o-matic
KERNEL_DIR=/usr/src/linux/
Не забудьте внимательно и до конца прочитать справку по каждой "заплатке" до
того как вы будете устанавливать что-либо, поскольку одни "заплатки" могут
оказаться несовместимы с другими, а некоторые -- при совместном наложении даже
разрушить ядро.
|
Вы можете вообще пропустить обновление ядра, другими словами особой
нужды в таком обновлении нет, однако patch-o-matic
содержит действительно интересные обновления, и у вас вполне может
возникнуть желание посмотреть на них. Ничего страшного не случится, если
вы запустите эти команды и посмотрите какие обновления
имеются. |
После завершения обновления, вам необходимо будет пересобрать ядро, добавив в
него только что установленные обновления. Не забудьте сначала выполнить
конфигурирование ядра, поскольку установленные обновления скорее всего окажутся
выключенными. В принципе, можно подождать с компиляцией ядра до тех пор пока вы
не закончите установку iptables.
Продолжая сборку iptables, запустите
команду:
make KERNEL_DIR=/usr/src/linux/
Если в процессе сборки возникли какие либо проблемы, то можете попытаться
разрешить их самостоятельно, либо обратиться на Netfilter
mailing list, где вам смогут помочь. Там вы найдете пояснения, что могло
быть сделано вами неправильно при установке, так что сразу не паникуйте. Если
это не помогло -- постарайтесь поразмыслить логически, возможно это поможет. Или
обратитесь к знакомому "гуру".
Если все прошло гладко, то следовательно вы готовы к установке исполняемых
модулей (binaries), для чего запустите следующую команду:
make install KERNEL_DIR=/usr/src/linux/
Надеюсь, что здесь-то проблем не возникло! Теперь для использования пакета
iptables вам определенно потребуется пересобрать
и переустановить ядро, если вы до сих пор этого не сделали. Дополнительную
информацию по установке пакета вы найдете в файле INSTALL.
RedHAt 7.1, с установленным ядром 2.4.x уже включает предустановленные netfilter и iptables. Однако,
для сохранения обратной совместимости с предыдущими дистрибутивами, по умолчанию
работает пакет ipchains. Сейчас мы коротко
разберем - как удалить ipchains и запустить вместо него iptables.
|
Версия iptables в Red Hat 7.1 сильно
устарела и, наверное неплохим решением будет установить более новую
версию. |
Для начала нужно отключить ipchains, чтобы
предотвратить загрузку соответствующих модулей в будущем. Чтобы добиться этого,
нам потребуется изменить имена некоторых файлов в дереве каталогов /etc/rc.d/. Следующая команда, выполнит требуемые
действия:
chkconfig --level 0123456 ipchains off
В результате выполнения этой команды, в некоторых именах ссылок, указывающих
на файлы в каталоге /etc/rc.d/init.d/ipchains, символ S
(который сообщает, что данный сценарий отрабатывает на запуске системы) будет
заменен символом K (от слова Kill, который указывает на то, что сценарий
отрабатывает, при завершении работы системы. Таким образом мы предотвратим
запуск ненужного сервиса в будущем.
Однако ipchains по-прежнему остаются в работе.
Теперь надо выполнить команду, которая остановит этот сервис:
service ipchains stop
И в заключение необходимо запустить сервис iptables. Для этого, во-первых, надо определиться с
уровнями запуска операционной системы, на которых нужно стартовать этот сервис.
Обычно это уровни 2, 3 и 5. Об этих уровнях мы знаем:
-
2. Многопользовательский режим без поддержки NFS или то же самое, что и 3,
но без сетевой поддержки.
-
3. Полнофункциональный многопользовательский режим.
-
5. X11. Данный уровень используется для автоматической загрузки
Xwindows.
Чтобы запустить iptables на этих уровнях нужно
выполнить команду:
chkconfig --level 235 iptables on
Хочется упомянуть об уровнях, на которых не требуется запуска iptables: Уровень 1 -- однопользовательский режим работы,
как правило используется в экстренных случаях, когда мы "поднимаем" "упавшую"
систему. Уровень 4 -- вообще не должен использоваться. Уровень выполнения 6 --
это уровень остановки системы при выключении или перезагрузке компьютера.
Для активации сервиса iptables подадим
команду:
service iptables start
Итак, мы запустили iptables, но у нас пока еще
нет ни одного правила. Чтобы добавить новые правила в Red Hat 7.1 можно пойти
двумя путями, во-первых: подправить файл /etc/rc.d/init.d/iptables, но этот способ имеет одно
негативное свойство -- при обновлении iptables из RPM-пакетов все ваши правила
будут утеряны, а во-вторых: занести правила и сохранить их командой iptables-save, сохраненные таким образом правила будут
автоматически восстанавливаться при загрузке системы.
В случае, если вы избрали первый вариант установки правил в iptables, то вам необходимо занести их в секцию start
сценария /etc/rc.d/init.d/iptables (для установки правил при загрузке системы)
или в функцию start(). Для выполнения действий при остановке системы -- внесите
соответствующие изменения в секцию stop) или в функцию stop(). Так же не
забудьте про секции restart и condrestart. Хочется еще раз напомнить, что в
случае обновления iptables из RPM-пакетов или
через автоматическое обновление по сети, вы можете утерять все изменения,
внесенные в файл /etc/rc.d/init.d/iptables.
Второй способ загрузки правил предпочтительнее. Он предполагает следующие
шаги. Для начала -- запишите правила в файл или непосредственно, через команду
iptables, смотря что для вас предпочтительнее.
Затем исполните команду iptables-save. Эта
команда эквивалентна команде iptables-save >
/etc/sysconfig/iptables. В результате, весь набор правил будет сохранен
в файле /etc/sysconfig/iptables, который автоматически
подгружается при запуске сервиса iptables. Другим способом сохранить набор
правил будет подача команды service iptables
save, которая полностью идентична вышеприведенной команде.
Впоследствии, при перезагрузке компьютера, сценарий iptables из rc.d будет
выполнять команду iptables-restore для загрузки
набора правил из файла /etc/sysconfig/iptables.
И наконец, в завершение установки, неплохо было бы удалить старые версии
ipchains и iptables. Это необходимо сделать для того, чтобы система
не "перепутала" старый пакет iptables с вновь
установленным. Удаление старого пакета iptables
необходимо произвести только в том случае, если вы производили установку из
исходных текстов. Дело в том, что RPM пакеты устанавливаются в несколько иное
место нежели пакеты, собранные из исходных текстов, а поэтому новый пакет не
"затирает" старый. Чтобы выполнить деинсталляцию предыдущей версии iptables выполните следующую команду:
rpm -e iptables
Аналогичным образом удалим и ipchains,
поскольку оставлять этот пакет в системе более нет никакого смысла.
rpm -e ipchains
В этой главе мы рассмотрим порядок прохождения таблиц и цепочек в каждой
таблице. Эта информация будет очень важна для вас позднее, когда вы начнете
строить свои наборы правил, особенно когда в наборы правил будут включаться
такие действия как DNAT, SNAT и конечно же TOS.
Когда пакет приходит на наш брандмауэр, то он сперва попадает на сетевое
устройство, перехватывается соответствующим драйвером и далее передается в ядро.
Далее пакет проходит ряд таблиц и затем передается либо локальному приложению,
либо переправляется на другую машину. Порядок следования пакета приводится
ниже:
Таблица 3-1. Порядок движения транзитных пакетов
| Шаг |
Таблица |
Цепочка |
Примечание |
| 1 |
|
|
Кабель (т.е. Интернет) |
| 2 |
|
|
Сетевой интерфейс (например,
eth0) |
| 3 |
mangle |
PREROUTING |
Обычно эта цепочка используется для
внесения изменений в заголовок пакета, например для изменения битов TOS и пр.. |
| 4 |
nat |
PREROUTING |
Эта цепочка используется для
трансляции сетевых адресов (Destination Network Address
Translation). Source Network Address
Translation выполняется позднее, в другой цепочке. Любого рода
фильтрация в этой цепочке может производиться только в исключительных
случаях |
| 5 |
|
|
Принятие решения о дальнейшей
маршрутизации, т.е. в этой точке решается куда пойдет пакет -- локальному
приложению или на другой узел сети. |
| 6 |
mangle |
FORWARD |
Далее пакет попадает в цепочку FORWARD таблицы mangle, которая должна использоваться
только в исключительных случаях, когда необходимо внести некоторые
изменения в заголовок пакета между двумя точками принятия решения о
маршрутизации. |
| 7 |
Filter |
FORWARD |
В цепочку FORWARD попадают только те пакеты, которые идут на
другой хост Вся фильтрация транзитного трафика должна выполняться здесь.
Не забывайте, что через эту цепочку проходит траффик в обоих направлениях,
обязательно учитывайте это обстоятельство при написании правил
фильтрации. |
| 8 |
mangle |
POSTROUTING |
Эта цепочка предназначена для
внесения изменений в заголовок пакета уже после того как принято последнее
решение о маршрутизации. |
| 9 |
nat |
POSTROUTING |
Эта цепочка предназначена в первую
очередь для Source Network Address Translation. Не
используйте ее для фильтрации без особой на то необходимости. Здесь же
выполняется и маскарадинг (Masquerading). |
| 10 |
|
|
Выходной сетевой интерфейс
(например, eth1). |
| 11 |
|
|
Кабель (пусть будет
LAN). |
Как вы можете видеть, пакет проходит несколько этапов, прежде чем он будет
передан далее. На каждом из них пакет может быть остановлен, будь то цепочка
iptables или что либо еще, но нас главным образом
интересует iptables. Заметьте, что нет каких либо
цепочек, специфичных для отдельных интерфейсов или чего либо подобного. Цепочку
FORWARD проходят ВСЕ пакеты, которые движутся через наш
брандмауэр/ роутер. Не используйте цепочку INPUT для фильтрации транзитных
пакетов, они туда просто не попадают! Через эту цепочку движутся только те
пакеты, которые предназначены данному хосту!
А теперь рассмотрим порядок движения пакета, предназначенного локальному
процессу/приложению:
Таблица 3-2. Для локального приложения
| Шаг |
Таблица |
Цепочка |
Примечание |
| 1 |
|
|
Кабель (т.е. Интернет) |
| 2 |
|
|
Входной сетевой интерфейс (например,
eth0) |
| 3 |
mangle |
PREROUTING |
Обычно используется для внесения
изменений в заголовок пакета, например для установки битов TOS и пр. |
| 4 |
nat |
PREROUTING |
Преобразование адресов (Destination Network Address Translation). Фильтрация
пакетов здесь допускается только в исключительных случаях. |
| 5 |
|
|
Принятие решения о
маршрутизации. |
| 6 |
mangle |
INPUT |
Пакет попадает в цепочку INPUT таблицы mangle. Здесь внесятся изменения в
заголовок пакета перед тем как он будет передан локальному
приложению. |
| 7 |
filter |
INPUT |
Здесь производится фильтрация
входящего трафика. Помните, что все входящие пакеты, адресованные нам,
проходят через эту цепочку, независимо от того с какого интерфейса они
поступили. |
| 8 |
|
|
Локальный процесс/приложение (т.е.,
программа-сервер или программа-клиент) |
Важно помнить, что на этот раз пакеты идут через цепочку INPUT, а не через FORWARD.
И в заключение мы рассмотрим порядок движения пакетов, созданных локальными
процессами.
Таблица 3-3. От локальных процессов
| Шаг |
Таблица |
Цепочка |
Примечание |
| 1 |
|
|
Локальный процесс (т.е.,
программа-сервер или программа-клиент). |
| 2 |
|
|
Принятие решения о маршрутизации.
Здесь решается куда пойдет пакет дальше -- на какой адрес, через какой
сетевой интерфейс и пр. |
| 3 |
mangle |
OUTPUT |
Здесь производится внесение
изменений в заголовок пакета. Выполнение фильтрации в этой цепочке может
иметь негативные последствия. |
| 4 |
nat |
OUTPUT |
Эта цепочка используется для
трансляции сетевых адресов (NAT) в пакетах, исходящих от локальных
процессов брандмауэра. |
| 5 |
Filter |
OUTPUT |
Здесь фильтруется исходящий
траффик. |
| 6 |
mangle |
POSTROUTING |
Цепочка POSTROUTING таблицы mangle в основном используется для
правил, которые должны вносить изменения в заголовок пакета перед тем, как
он покинет брандмауэр, но уже после принятия решения о маршрутизации. В
эту цепочку попадают все пакеты, как транзитные, так и созданные
локальными процессами брандмауэра. |
| 7 |
nat |
POSTROUTING |
Здесь выполняется Source Network Address Translation. Не следует в этой
цепочке производить фильтрацию пакетов во избежание нежелательных побочных
эффектов. Однако и здесь можно останавливать пакеты, применяя политику
по-умолчанию DROP. |
| 8 |
|
|
Сетевой интерфейс (например,
eth0) |
| 9 |
|
|
Кабель (т.е.,
Internet) |
Теперь мы знаем, что есть три различных варианта прохождения пакетов. Рисунок
ниже более наглядно демонстрирует это:
Этот рисунок дает довольно ясное представление о порядке прохождения пакетов
через различные цепочки. В первой точке принятия решения о маршрутизации
(routing decision) все пакеты, предназначенные данному хосту направляются в
цепочку INPUT, остальные - в цепочку FORWARD.
Обратите внимание также на тот факт, что пакеты, с адресом назначения на
брандмауэр, могут претерпеть изменение сетевого адреса назначения (DNAT) в
цепочке PREROUTING таблицы nat и соответственно
дальнейшая маршрутизация в первой точке будет выполняться в зависимости от
произведенных изменений. Запомните -- все пакеты
проходят через таблицы и цепочки по тому или иному маршруту. Даже если
выполняется DNAT в ту же сеть, откуда пакет пришел, то
он все равно продолжит движение по цепочкам.
 |
В сценарии rc.test-iptables.txt
вы сможете найти дополнительную информацию о порядке прохождения
пакетов. |
Как уже упоминалось выше, эта таблица предназначена, главным образом для
внесения изменений в заголовки пакетов (mangle - искажать, изменять. прим.
перев.). Т.е. в этой таблице вы можете устанавливать биты TOS (Type Of Service) и т.д.
 |
Еще раз напоминаю вам, что в этой таблице не следует производить любого
рода фильтрацию, маскировку или преобразование адресов (DNAT, SNAT,
MASQUERADE). |
В этой таблице допускается выполнять только нижеперечисленные действия:
Действие TOS выполняет установку битов поля
Type of Service в пакете. Это поле используется для
назначения сетевой политики обслуживания пакета, т.е. задает желаемый вариант
маршрутизации. Однако, следует заметить, что данное свойство в действительности
используется на незначительном количестве маршрутизаторов в Интернете. Другими
словами, не следует изменять состояние этого поля для пакетов, уходящих в
Интернет, потому что на роутерах, которые таки обслуживают это поле, может быть
принято неправильное решение при выборе маршрута.
Действие TTL используется для установки
значения поля TTL (Time To Live) пакета. Есть одно
неплохое применение этому действию. Мы можем присваивать определенное значение
этому полю, чтобы скрыть наш брандмауэр от чересчур любопытных провайдеров
(Internet Service Providers). Дело в том, что отдельные провайдеры очень не
любят когда одно подключение разделяется несколькими компьютерами. и тогда они
начинают проверять значение TTL приходящих пакетов и
используют его как один из критериев определения того, один компьютер "сидит" на
подключении или несколько.
Действие MARK устанавливает специальную метку
на пакет, которая затем может быть проверена другими правилами в iptables или
другими программами, например iproute2. С помощью
"меток" можно управлять маршрутизацией пакетов, ограничивать траффик и
т.п.
Эта таблица используется для выполнения преобразований сетевых адресов NAT (Network Address Translation). Как уже упоминалось
ранее, только первый пакет из потока проходит через цепочки этой таблицы,
трансляция адресов или маскировка применяются ко всем последующим пакетам в
потоке автоматически. Для этой таблицы характерны действия:
Действие DNAT (Destination Network Address
Translation) производит преобразование адресов назначения в заголовках пакетов.
Другими словами, этим действием производится перенаправление пакетов на другие
адреса, отличные от указанных в заголовках пакетов.
SNAT (Source Network Address Translation)
используется для изменения исходных адресов пакетов. С помощью этого действия
можно скрыть структуру локальной сети, а заодно и разделить единственный внешний
IP адрес между компьютерами локальной сети для выхода в Интернет. В этом случае
брандмауэр, с помощью SNAT, автоматически
производит прямое и обратное преобразование адресов, тем самым давая возможность
выполнять подключение к серверам в Интернете с компьютеров в локальной сети.
Маскировка (MASQUERADE) применяется в тех же
целях, что и SNAT, но в отличие от последней,
MASQUERADE дает более сильную нагрузку на
систему. Происходит это потому, что каждый раз, когда требуется выполнение этого
действия - производится запрос IP адреса для указанного в действии сетевого
интерфейса, в то время как для SNAT IP адрес
указывается непосредственно. Однако, благодаря такому отличию, MASQUERADE может работать в случаях с динамическим IP
адресом, т.е. когда вы подключаетесь к Интернет, скажем через PPP, SLIP или DHCP.
Как следует из названия, в этой таблице должны содержаться наборы правил для
выполнения фильтрации пакетов. Пакеты могут пропускаться далее, либо отвергаться
(действия ACCEPT и DROP соответственно), в зависимости от их содержимого.
Конечно же, мы можем отфильтровывать пакеты и в других таблицах, но эта таблица
существует именно для нужд фильтрации. В этой таблице допускается использование
большинства из существующих действий, однако ряд действий, которые мы
рассмотрели выше в этой главе, должны выполняться только в присущих им
таблицах.
В данной главе все внимание будет уделено механизму определения состояний
пакетов (state machine). По прочтении ее у вас должно сложиться достаточно
четкое представление о работе механизма, а способствовать этому должен
значительный объем поясняющих примеров.
Механизм определения состояния (state machine) является отдельной частью
iptables и в действительности не должен бы так называться, поскольку фактически
является механизмом трассировки соединений. Однако значительному количеству
людей он известен именно как "механизм определения состояния" (state machine). В
данной главе эти названия будут использоваться как синонимы. Трассировщик
соединений создан для того, чтобы netfilter мог постоянно иметь информацию о
состоянии каждого конкретного соединения. Наличие трассировщика позволяет
создавать более надежные наборы правил по сравнению с брандмауэрами, которые не
имеют поддержки такого механизма.
В пределах iptables, соединение может иметь одно из 4-х базовых состояний:
NEW, ESTABLISHED,
RELATED и INVALID.
Позднее мы остановимся на каждом из них более подробно. Для управления
прохождением пакетов, основываясь на их состоянии, используется критерий --state.
Трассировка соединений производится специальным кодом в пространстве ядра --
трассировщиком (conntrack). Код трассировщика может быть скомпилирован как
подгружаемый модуль ядра, так и статически связан с ядром. В большинстве случаев
нам потребна более специфичная информация о соединении, чем та, которую
поставляет трассировщик по-умолчанию. Поэтому трассировщик включает в себя
обработчики различных протоколов, например TCP, UDP или ICMP. Собранная ими
информация затем используется для идентификации и определения текущего состояния
соединения. Например -- соединение по протоколу UDP
однозначно идентифицируется по IP-адресам и портам источника и приемника.
В предыдущих версиях ядра имелась возможность включения/выключения поддержки
дефрагментации пакетов. Однако, после того как трассировка соединений была
включена в состав iptables/netfilter, надобность в этом отпала. Причина в том,
что трассировщик не в состоянии выполнять возложенные на него функции без
поддержки дефрагментации и поэтому она включена постоянно. Ее нельзя отключить
иначе как отключив трассировку соединений. Дефрагментация выполняется всегда,
если трассировщик включен.
Трассировка соединений производится в цепочке PREROUTING, исключая случаи, когда пакеты создаются
локальными процессами на брандмауэре, в этом случае трассировка производится в
цепочке OUTPUT. Это означает, что iptables производит
все вычисления, связанные с определением состояния, в пределах этих цепочек.
Когда локальный процесс на брандмауэре отправляет первый пакет из потока, то в
цепочке OUTPUT ему присваивается состояние NEW, а когда возвращается пакет ответа, то состояние
соединения в цепочке PREROUTING изменяется на ESTABLISHED, и так далее. Если же соединение
устанавливается извне, то состояние NEW
присваивается первому пакету из потока в цепочке PREROUTING. Таким образом, определение состояния пакетов
производится в пределах цепочек PREROUTING и OUTPUT таблицы nat.
Кратко рассмотрим таблицу трассировщика, которую можно найти в файле /proc/net/ip_conntrack. Здесь содержится список всех
активных соединений. Если модуль ip_conntrack загружен,
то команда cat /proc/net/ip_conntrak должна
вывести нечто, подобное: tcp 6 117 SYN_SENT src=192.168.1.6
dst=192.168.1.9 sport=32775 \
dport=22 [UNREPLIED] src=192.168.1.9
dst=192.168.1.6 sport=22 \
dport=32775 use=2
В этом примере содержится вся информация, которая известна трассировщику, по
конкретному соединению. Первое, что можно увидеть - это название протокола, в
данном случае - tcp. Далее следует некоторое число в обычном десятичном
представлении. После него следует число, определяющее "время жизни" записи в
таблице (т.е. количество секунд, через которое информация о соединении будет
удалена из таблицы). Для нашего случая, запись в таблице будет храниться еще 117
секунд, если конечно через это соединение более не проследует ни одного пакета.
При прохождении каждого последующего пакета через данное соединение, это
значение будет устанавливаться в значение по-умолчанию для заданного состояния.
Это число уменьшается на 1 каждую секунду. Далее следует фактическое состояние
соединения. Для нашего примера состояние имеет значение SYN_SENT. Внутреннее представление состояния несколько
отличается от внешнего. Значение SYN_SENT говорит
о том, что через данное соединение проследовал единственный пакет TCP SYN. Далее расположены адреса отправителя и получателя,
порт отправителя и получателя. Здесь же видно ключевое слово [UNREPLIED], которое сообщает о том, что ответного
трафика через это соединение еще не было. И наконец приводится дополнительная
информация по ожидаемому пакету, это IP адреса отправителя/получателя (те же
самые, только поменявшиеся местами, поскольку ожидается ответный пакет), то же
касается и портов.
Записи в таблице могут принимать ряд значений, все они определены в
заголовочных файлах linux/include/netfilter-ipv4/ip_conntrack*.h. Значения
по-умолчанию зависят от типа протокола. Каждый из IP-протоколов -- TCP, UDP или ICMP имеют собственные значения по-умолчанию, которые
определены в заголовочном файле linux/include/netfilter-ipv4/ip_conntrack.h. Более подробно
мы остановимся на этих значениях, когда будем рассматривать каждый из протоколов
в отдельности.
|
Совсем недавно, в patch-o-matic, появилась заплата tcp-window-tracking,
которая предоставляет возможность передачи значений всех таймаутов через
специальные переменные, т.е. позволяет изменять их "на лету". Таким
образом появляется возможность изменения таймаутов без необходимости
пересборки ядра.
Изменения вносятся с помощью определенных системных вызовов, через
каталог
/proc/sys/net/ipv4/netfilter.
Особое
внимание обратите на ряд переменных
/proc/sys/net/ipv4/netfilter/ip_ct_*
. |
После получения пакета ответа трассировщик снимет флаг [UNREPLIED] и заменит его флагом [ASSURED]. Этот флаг сообщает о том, что соединение
установлено уверенно и эта запись не будет стерта по достижении максимально
возможного количества трассируемых соединений. Максимальное количество записей,
которое может содержаться в таблице зависит от значения по-умолчанию, которое
может быть установлено вызовом функции ipsysctl в последних версиях ядра. Для
объема ОЗУ 128 Мб это значение соответствует 8192 записям, для 256 Мб - 16376.
Вы можете посмотреть и изменить это значение установкой переменной /proc/sys/net/ipv4/ip_conntrack_max.
Как вы уже наверняка заметили, в пространстве ядра, в зависимости от типа
протокола, пакеты могут иметь несколько различных состояний. Однако, вне ядра
пакеты могут иметь только 4 состояния. В основном состояние пакета используется
критерием --state. Допустимыми являются состояния
NEW, ESTABLISHED,
RELATED и INVALID.
В таблице, приводимой ниже, рассмтриваются каждое из возможных состояний.
Таблица 4-1. Перечень состояний в пространстве
пользователя
| Состояние |
Описание |
| NEW |
Признак NEW сообщает о том, что пакет является первым для
данного соединения. Это означает, что это первый пакет в данном
соединении, который увидел модуль трассировщика. Например если получен SYN пакет являющийся первым пакетом для данного
соединения, то он получит статус NEW.
Однако, пакет может и не быть SYN пакетом и тем не
менее получить статус NEW. Это может
породить определенные проблемы в отдельных случаях, но может оказаться и
весьма полезным, например когда желательно "подхватить" соединения,
"потерянные" другими брандмауэрами или в случаях, когда таймаут соединения
уже истек, но само соединение не было закрыто. |
| RELATED |
Состояние RELATED одно из самых "хитрых". Соединение получает
статус RELATED если оно связано с другим
соединением, имеющим признак ESTABLISHED.
Это означает, что соединение получает признак RELATED тогда, когда оно инициировано из уже
установленного соединения, имеющего признак ESTABLISHED. Хорошим примером соединения, которое
может рассматриваться как RELATED, является
соединение FTP-data, которое является связанным с
портом FTP control, а так же DCC соединение, запущенное из IRC. Обратите внимание на то, что большинство
протоколов TCP и некоторые из протоколов UDP весьма сложны и передают информацию о соединении
через область данных TCP или UDP пакетов и поэтому требуют наличия специальных
вспомогательных модулей для корректной работы. |
| ESTABLISHED |
Состояние ESTABLISHED говорит о том, что это не первый пакет
в соединении. Схема установки состояния ESTABLISHED достаточна проста для понимания.
Единственное требование, предъявляемое к соединению, заключается в том,
что для перехода в состояние ESTABLISHED
необходимо чтобы узел сети передал пакет и получил на него ответ от
другого узла (хоста). После получения ответа состояние соединения NEW или RELATEDбудет
изаменено на ESTABLISHED. |
| INVALID |
Признак INVALID говорит о том, что пакет не может быть
идентифицирован и поэтому не может иметь определенного статуса. Это может
происходить по разным причинам, например при нехватке памяти или при
получении ICMP-сообщения об ошибке, которое не
соответствует какому либо известному соединению. Наверное наилучшим
вариантом было бы применение действия DROP
к таким пакетам. |
Эти четыре состояния могут использоваться в критерии --state. Механизм определения состояния позволяет строить
чрезвычайно мощную и эффективную защиту. Раньше приходилось открывать все порты
выше 1024, чтобы пропустить обратный трафик в локальную сеть, теперь же, при
наличии механизма определения состояния, необходимость в этом отпала, поскольку
появилась возможность "открывать" доступ только для обратного (ответного)
трафика, пресекая попытки установления соединений извне.
В этом и в последующих разделах мы поближе рассмотрим признаки состояний и
порядок их обработки каждым из трех базовых протоколов TCP, UDP и ICMP, а так же коснемся случая, когда протокол соединения не
может быть классифицирован на принадлежность к трем, вышеуказанным, протоколам.
Начнем рассмотрение с протокола TCP, поскольку он имеет множество интереснейших
особенностей в отношении механизма определения состояния в iptables.
TCP соединение всегда устанавливается передачей трех
пакетов, которые инициализируют и устанавливают соединение, через которое в
дальнейшем будут передаваться данные. Сессия начинается с передачи SYN пакета, в ответ на который передается SYN/ACK пакет и подтверждает установление соединения пакет
ACK. После этого соединение считается установленным и
готовым к передаче данных. Может возникнуть вопрос: "А как же трассируется
соединение?". В действительности все довольно просто.
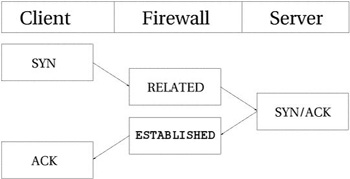
Для всех типов соединений, трассировка проходит практически одинаково.
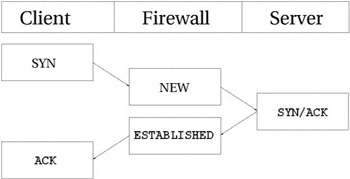
Взгляните на рисунок ниже, где показаны все стадии установления соединения. Как
видите, трассировщик, с точки зрения пользователя, фактически не следит за ходом
установления соединения. Просто, как только трассировщик "увидел" первый (SYN) пакет, то присваивает ему статус NEW. Как только через трассировщика проходит второй пакет
(SYN/ACK), то соединению присваивается статус ESTABLISHED. Почму именно второй пакет? Сейчас
разберемся. Строя свой набор правил, вы можете позволить покидать локальную сеть
пакетам со статусом NEW и ESTABLISHED, а во входящем трафике пропускать пакеты
только со статусом ESTABLISHED и все будет
работать прекрасно. И наоборот, если бы трассировщик продолжал считать
соединение как NEW, то фактически вам никогда не
удалось бы установить соединение с "внешним миром", либо пришлось бы позволить
прохождение NEW пакетов в локальную сеть. С точки
зрения ядра все выглядит более сложным, поскольку в пространстве ядра TCP соединения имеют ряд промежуточных состояний,
недоступных в пространстве пользователя. В общих чертах они соответствуют
спецификации RFC
793 - Transmission Control Protocol на странице 21-23. Более подробно
эта тема будет рассматриваться чуть ниже.
С точки зрения пользователя все выглядит достаточно просто, однако если
посмотреть с точки зрения ядра, то все выглядит несколько сложнее. Рассмотрим
порядок изменения состояния соединения в таблице /proc/net/ip_conntrack. После передачи первого пакета
SYN. tcp 6 117 SYN_SENT src=192.168.1.5
dst=192.168.1.35 sport=1031 \
dport=23 [UNREPLIED] src=192.168.1.35
dst=192.168.1.5 sport=23 \
dport=1031 use=1
Как видите, запись в таблице отражает точное состояние соединения -- был
отмечен факт передачи пакета SYN (флаг SYN_SENT),
на который ответа пока не было (флаг [UNREPLIED]).
После получения пакета-ответа, соединение переводится в следующее внутреннее
состояние: tcp 6 57 SYN_RECV src=192.168.1.5
dst=192.168.1.35 sport=1031 \
dport=23 src=192.168.1.35
dst=192.168.1.5 sport=23 dport=1031 \
use=1
Теперь запись сообщает о том, что обратно прошел пакет SYN/ACK. На этот раз соединение переводится в состояние SYN_RECV. Это состояние говорит о том, что пакет SYN был благополучно доставлен получателю и в ответ на него
пришел пакет-подтверждение (SYN/ACK). Кроме того,
механизм определения состояния "увидев" пакеты, следующие в обеих направлениях,
снимает флаг [UNREPLIED]. И наконец после передачи
заключительного ACK-пакета, в процедуре установления
соединения tcp 6 431999 ESTABLISHED src=192.168.1.5
dst=192.168.1.35 \
sport=1031 dport=23 src=192.168.1.35
dst=192.168.1.5 \
sport=23 dport=1031 use=1
соединение переходит в состояние ESTABLISHED
(установленное). После приема нескольких пакетов через это соединение, к нему
добавится флаг [ASSURED] (уверенное).
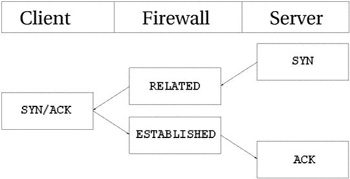
При закрытии, TCP соединение проходит через следующие
состояния.
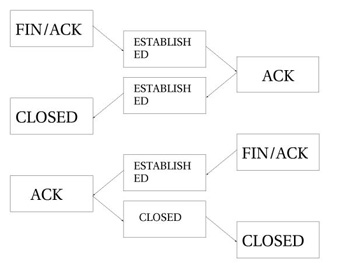
Как видно из рисунка, соединение не закрывается до тех пор пока не будет
передан последний пакет ACK. Обратите внимание -- эта
картинка описывает нормальный процесс закрытия соединения. Кроме того, если
соединение отвергается, то оно может быть закрыто передачей пакета RST (сброс). В этом случае соединение будет закрыто по
истечение предопределенного времени.
При закрытии, соединение переводится в состояние TIME_WAIT, продолжительность которого по-умолчанию
соответствует 2 минутам, в течение которого еще возможно прохождение пакетов
через брандмауэр. Это является своего рода "буферным временем", которое дает
возможность пройти пакетам, "увязшим" на том или ином маршрутизаторе
(роутере).
Если соединение закрывается по получении пакета RST,
то оно переводится в состояние CLOSE. Время
ожидания до фактического закрытия соединения по-умолчанию устанавливается равным
10 секунд. Подтверждение на пакеты RST не передается и
соединение закрывается сразу же. Кроме того имеется ряд других внутренних
состояний. В таблице ниже приводится список возможных внутренних состояний
соединения и соответствующие им размеры таймаутов.
Таблица 4-2. Internal states
| Состояние |
Время ожидания |
| NONE |
30 минут |
| ESTABLISHED |
5 дней |
| SYN_SENT |
2 минуты |
| SYN_RECV |
60 секунд |
| FIN_WAIT |
2 минуты |
| TIME_WAIT |
2 минуты |
| CLOSE |
10 секунд |
| CLOSE_WAIT |
12 часов |
| LAST_ACK |
30 секунд |
| LISTEN> |
2 минуты |
Эти значения могут несколько изменяться от версии к версии ядра, кроме того,
они могут быть изменены через интерфейс файловой системы /proc (переменные proc/sys/net/ipv4/netfilter/ip_ct_tcp_*). Значения
устанавливаются в сотых долях секунды, так что число 3000 означает 30
секунд.
|
Обратите внимание на то, что со стороны пользователя, механизм
определения состояния никак не отображает состояние флагов TCP пакетов. Как правило - это не всегда хорошо,
поскольку состояние NEW присваивается, не
только пакетам SYN.
Это качество трассировщика может быть использовано для избыточного
файерволлинга (firewalling), но для случая домашней локальной сети, в
которой используется только один брандмауэр это очень плохо. Эта проблема
более подробно обсуждается в разделе Пакеты
со статусом NEW и со сброшенным битом SYN приложения Общие
проблемы и вопросы. Альтернативным вариантом решения этой
проблемы может служить установка заплаты tcp-window-tracking из patch-o-matic, которая сделает возможным принятие
решений в зависимости от значения TCP
window. |
По сути своей, UDP соединения не имеют признака
состояния. Этому имеется несколько причин, основная из них состоит в том, что
этот протокол не предусматривает установления и закрытия соединения, но самый
большой недостаток -- отсутствие информации об очередности поступления пакетов.
Приняв две датаграммы UDP, невозможно сказать точно в
каком порядке они были отправлены. Однако, даже в этой ситуации все еще возможно
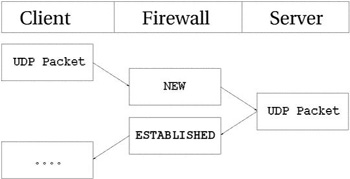
определить состояние соединения. Ниже приводится рисунок того, как выглядит
установление соединения с точки зрения трассировщика.
Из рисунка видно, что состояние UDP соединения
определяется почти так же как и состояние TCP
соединения, с точки зрения из пользовательского пространства. Изнутри же это
выглядит несколько иначе, хотя во многом похоже. Для начала посмотрим на запись,
появившуюся после передачи первого пакета UDP. udp 17 20 src=192.168.1.2
dst=192.168.1.5 sport=137 dport=1025 \
[UNREPLIED] src=192.168.1.5
dst=192.168.1.2 sport=1025 \
dport=137 use=1
Первое, что мы видим -- это название протокола (udp) и его номер (см.
/etc/protocols прим. перев.). Третье значение -- оставшееся "время жизни" записи
в секундах. Далее следуют характеристики пакета, прошедшего через брандмауэр --
это адреса и порты отправителя и получателя. Здесь же видно, что это первый
пакет в сессии (флаг [UNREPLIED]). И завершают
запись адреса и порты отправителя и получателя ожидаемого пакета. Таймаут такой
записи по умолчанию составляет 30 секунд. udp 17 170 src=192.168.1.2
dst=192.168.1.5 sport=137 \
dport=1025 src=192.168.1.5
dst=192.168.1.2 sport=1025 \
dport=137 use=1
После того как сервер "увидел" ответ на первый пакет, соединение считается
ESTABLISHED (установленным), единственное отличие
от предыдущей записи состоит в отсутствии флага [UNRREPLIED] и, кроме того, таймаут для записи стал
равным 180 секундам. После этого может только добавиться флаг [ASSURED] (уверенное соединение), который был описан
выше. Флаг [ASSURED] устанавливается только после
прохождения некоторого количества пакетов через соединение. udp 17 175 src=192.168.1.5
dst=195.22.79.2 sport=1025 \
dport=53 src=195.22.79.2
dst=192.168.1.5 sport=53 \
dport=1025 [ASSURED] use=1
Теперь соединение стало "уверенным". Запись в таблице выглядит практически
так же как и в предыдущем примере, за исключением флага [ASSURED]. Если в течение 180 секунд через соединение
не пройдет хотя бы один пакет, то запись будет удалена из таблицы. Это
достаточно маленький промежуток времени, но его вполне достаточно для
большинства применений. "Время жизни" отсчитывается от момента прохождения
последнего пакета и при появлении нового, время переустанавливается в свое
начальное значение, это справедливо и для всех остальных типов внутренних
состояний.
ICMP пакеты используются только для передачи
управляющих сообщений и не организуют постоянного соединения. Однако, существует
4 типа ICMP пакетов, которые вызывают передачу ответа,
поэтому они могут иметь два состояния: NEW и
ESTABLISHED. К этим пакетам относятся ICMP Echo Request/Echo Reply, ICMP
Timestamp Request/Timestamp Reply, ICMP Information
Request/Information Reply и ICMP Address Mask
Request/Address Mask Reply. Из них -- ICMP Timestamp
Request/Timestamp Reply и ICMP Information
Request/Information Reply считаются устаревшими и поэтому, в большинстве
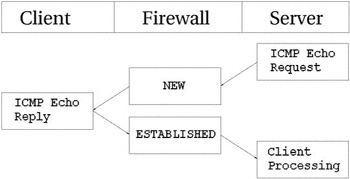
случаев, могут быть безболезненно сброшены (DROP). Взгляните на рисунок ниже.
Как видно из этого рисунка, сервер выполняет Echo
Request (эхо-запрос) к клиенту, который (запрос) распознается брандмауэром
как NEW. На этот запрос клиент отвечает пакетом
Echo Reply, и теперь пакет распознается как имеющий
состояние ESTABLISHED. После прохождения первого
пакета (Echo Request) в ip_conntrack появляется запись: icmp 1 25 src=192.168.1.6
dst=192.168.1.10 type=8 code=0 \
id=33029 [UNREPLIED] src=192.168.1.10
dst=192.168.1.6 \
type=0 code=0 id=33029 use=1
Эта запись несколько отличается от записей, свойственных протоколам TCP и UDP, хотя точно так же
присутствуют и название протокола и время таймаута и адреса передатчика и
приемника, но далее появляются три новых поля - type, code и id. Поле type содержит
тип ICMP, поле code - код
ICMP. Значения типов и кодов ICMP приводятся в приложении Типы
ICMP. И последнее поле id содержит
идентификатор пакета. Каждый ICMP-пакет имеет свой
идентификатор. Когда приемник, в ответ на ICMP-запрос
посылает ответ, он подставляет в пакет ответа этот идентификатор, благодаря
чему, передатчик может корректно распознать в ответ на какой запрос пришел
ответ.
Следующее поле -- флаг [UNREPLIED], который
встречался нам ранее. Он означает, что прибыл первый пакет в соединении.
Завершается запись характеристиками ожидаемого пакета ответа. Сюда включаются
адреса отправителя и получателя. Что касается типа и кода ICMP пакета, то они соответствуют правильным значениям
ожидаемого пакета ICMP Echo Reply. Идентификатор
пакета-ответа тот же, что и в пакете запроса.
Пакет ответа распознается уже как ESTABLISHED.
Однако, мы знаем, что после передачи пакета ответа, через это соединение уже
ничего не ожидается, поэтому после прохождения ответа через netfilter, запись в
таблице трассировщика уничтожается.
В любом случае запрос рассматривается как NEW,
а ответ как ESTABLISHED.
|
Заметьте при этом, что пакет ответа должен совпадать по своим
характеристикам (адреса отправителя и получателя, тип, код и
идентификатор) с указанными в записи в таблице трассировщика, это
справедливо и для всех остальных типов
трафика. |
ICMP запросы имеют таймаут, по-умолчанию, 30 секунд. Этого времени, в
большинстве случаев, вполне достаточно. Время таймаута можно изменить в /proc/sys/net/ipv4/netfilter/ip_ct_icmp_timeout. (
Напоминаю, что переменные типа /proc/sys/net/ipv4/netfilter/ip_ct_* становятся доступны
только после установки "заплаты" tcp-window-tracking из patch-o-matic прим.
перев.).
Значительная часть ICMP используется для передачи
сообщений о том, что происходит с тем или иным UDP или
TCP соединением. Всвязи с этим они очень часто
распознаются как связанные (RELATED) с
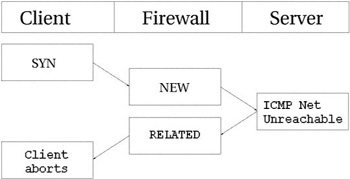
существующим соединением. Простым примером могут служить сообщения ICMP Host Unreachable или ICMP Network
Unreachable. Они всегда порождаются при попытке соединиться с узлом сети
когда этот узел или сеть недоступны, в этом случае последний маршрутизатор
вернет соответствующий ICMP пакет, который будет
распознан как RELATED. На рисунке ниже показано
как это происходит.
В этом примере некоторому узлу передается запрос на соединение (SYN пакет). Он приобретает статус NEW на брандмауэре. Однако, в этот момент времени, сеть
оказывается недоступной, поэтому роутер возвращает пакет ICMP
Network Unreachable. Трассировщик соединений распознает этот пакет как
RELATED, благодаря уже имеющейся записи в
таблице, так что пакет благополучно будет передан клиенту, который затем оборвет
неудачное соединение. Тем временем, брандмауэр уничтожит запись в таблице,
поскольку для данного соединения было получено сообщение об ошибке.
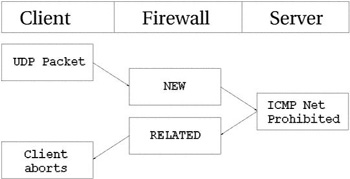
То же самое происходит и с UDP соединениями -- если
обнаруживаются подобные проблемы. Все сообщения ICMP,
передаваемые в ответ на UDP соединение, рассматриваются
как RELATED. Взгляните на следующий рисунок.
Датаграмма UDP передается на сервер. Соединению
присваивается статус NEW. Однако доступ к сети
запрещен (брандмауэром или роутером), поэтому обратно возвращается сообщение ICMP Network Prohibited. Брандмауэр распознает это сообщение
как связанное с открытым UDP соединением, присваивает
ему статус RELATED и передает клиенту. После чего
запись в таблице трассировщика уничтожается, а клиент благополучно обрывает
соединение.
В некоторых случаях механизм определения состояния не может распознать
протокол обмена и, соответственно, не может выбрать стратегию обработки этого
соединения. В этом случае он переходит к заданному по-умолчанию поведению.
Поведение по-умолчанию используется, например при обслуживании протоколов NETBLT, MUX и EGP. Поведение по-молчанию во многом схоже с трассировкой
UDP соединений. Первому пакету присваивается статус
NEW, а всем последующим - статус ESTABLISHED.
При использовании поведения по-умолчанию, для всех пакетов используется одно
и то же значение таймаута, которое можно изменить в
/proc/sys/net/ipv4/netfilter/ip_ct_generic_timeout.
По-умолчанию это значение равно 600 секундам, или 10 минутам В зависимости от
типа трафика, это время может меняться, особенно когда соединение
устанавливается по спутниковому каналу.
Имеется ряд комплексных протоколов, корректная трассировка которых более
сложна. Прмером могут служить протоколы ICQ, IRC и FTP. Каждый из этих протоколов
несет дополнительную информацию о соединении в области данных пакета.
Соответственно корректная трассировка таких соединений требует подключения
дополнительных вспомогательных модулей.
В качестве первого примера рассмотрим протокол FTP.
Протокол FTP сначала открывает одиночное соединение,
которое называется "сеансом управления FTP" (FTP control
session). При выполнении команд в пределах этого сеанса, для передачи
сопутствующих данных открываются дополнительные порты. Эти соединения могут быть
активными или пассивными. При создании активного соединения клент передает FTP серверу номер порта и IP адрес
для соединения. Затем клент открывает порт, сервер подключает к заданному порту
клиента свой порт с номером 20 (известный как FTP-Data)
и передает данные через установленное соединение.
Проблема состоит в том, что брандмауэр ничего не знает об этих дополнительных
подключениях, поскольку вся информация о них передается через область данных
пакета. Из-за этого брандмауэр не позволит серверу соединиться с указанным
портом клиента.
Решение проблемы состоит в добавлении специального вспомогательного модуля
трассировки, который отслеживает, специфичную для данного протокола, информацию
в области данных пакетов, передаваемых в рамках сеанса управления. При создании
такого соединения, вспомогательный модуль корректно воспримет передаваемую
информацию и создаст соответствующую запись в таблице трассировщика со статусом
RELATED, благодаря чему соединение будет
установлено. Рисунок ниже поясняет порядок выполнения подобного соединения.
Пассивный FTP действует противоположным образом.
Клиент посылает запрос серверу на получение данных, а сервер возвращает клиенту
IP адрес и номер порта для подключения. Клиент
подключает свой 20-й порт (FTP-data) к указанному порту
сервера и получает запрошенные данные. Если ваш FTP сервер находится за
брандмауэром, то вам потребуется этот вспомогательный модуль для того, чтобы
сервер смог обслуживать клиентов из Интернет. То же самое касается случая, когда
вы хотите ограничить своих пользователей только возможностью подключения к HTTP и FTP серверам в Интернет и
закрыть все остальные порты. Рисунок ниже показывает как выполняется пассивное
соединение FTP.
Некоторые вспомогательные модули уже включены в состав ядра. Если быть более
точным, то в состав ядра включены вспомогательные модули для протоколов FTP и IRC. Если в вашем распоряжении
нет необходимого вспомогательного модуля, то вам следует обратиться к patch-o-matic, который содержит большое количество
вспомогательных модулей для трассировки таких протоколов, как ntalk или H.323. Если и здесь вы не
нашли то, что вам нужно, то у вас есть еще варианты: вы можете обратиться к CVS
iptables, если искомый вспомогательный модуль еще не был включен в patch-o-matic, либо можете войти в контакт с разработчиками
netfilter и узнать у них -- имеется ли подобный модуль и планируется ли он к
выпуску. Если и тут вы потерпели неудачу, то наверное вам следует прочитать Rusty
Russell's Unreliable Netfilter Hacking HOW-TO.
Вспомогательные модули могут быть скомпилированы как в виде подгружаемых
модулей ядра, так и статически связаны с ядром. Если они скомпилированы как
модули, то вы можете загрузить их командой: modprobe ip_conntrack_*
Обратите внимание на то, что механизм определения состояния не имеет никакого
отношения к трансляции сетевых адресов (NAT), поэтому
вам может потребоваться большее количество дополнительных модулей, если вы
выполняете такую трансляцию. Допустим, что вы выполняете трансляцию адресов и
трассировку FTP соединений, тогда вам необходим так же и
соответствующий вспомогательный модуль NAT. Имена
вспомогательных модулей NAT начинаются с ip_nat_, в
соответствии с соглашением об именах. В данном случае модуль называется ip_nat_ftp. Для протокола IRC такой
модуль будет называться ip_nat_irc. Тому же самому
соглашению следуют и названия вспомогательных модулей трассировщика, например:
ip_conntrack_ftp и ip_conntrack_irc.
|
|