8. Системы хранения и поиска данных
В основе всех современных информационных приложений находятся системы хранения данных во внешней памяти и их эффективного поиска. В зависимости от специфики приложений используются разные технологии хранения и поиска данных. Если проводить грубую классификацию таких технологий, то можно выделить два основных направления - системы управления базами данных (СУБД) и информационно-поисковые системы (ИПС). Эти направления взаимно дополняют друг друга и в совокупности обеспечивают возможность построения приложений в разных архитектурах, с разной функциональной ориентированностью, с разными требованиями к доступу к данным и т.д.
Основными характеристиками среды хранения данных, управляемой СУБД, являются:
- структурированная природа хранимых данных, причем описание структуры является частью самой базы данных, т.е. известна СУБД (соответствующую часть базы данных иногда называют метабазой данных);
- существенно частое обновление данных, эффективно поддерживаемое СУБД и производимое многими пользователями, одновременно подключенными к базе данных;
- автоматическое поддержание целостного состояния базы данных на основе механизма управления транзакциями и хранимого в метабазе данных набора ограничений целостности и/или триггеров;
- поддержка структурированных языков доступа к базе данных, в которых условие поиска представляет собой логическую связку разнообразных простых условий, накладываемых на содержимое требуемых записей.
Среду хранения данных, управляемую ИПС, характеризует в основном следующее:
- отсутствие структуризации данных, известной ИПС; как правило, в таких системах хранятся полнотекстовые документы, структура которых (если речь идет о структурированных документах) известна соответствующим приложениям;
- редкое обновление данных, уже включенных в среду хранения; в частности, во многих ИПС обновление среды хранения данных (изменение, удаление, добавление документов) производится только в специальном режиме, не допускающем одновременную выборку информации;
- отсутствие встроенного в систему механизма поддержания целостности данных; необходимые механизмы контроля вводимой информации должны являться частью приложения;
- наличие развитых механизмов выборки информации, основанных на логических связках простых условий, накладываемых на содержание искомых документов; примерами простых условий является указание ключевых слов, характеризующих документ, или контекста, относящегося к содержимому документа.
ИПС по естественным причинам никогда не претендовали на роль СУБД. Однако обратное неверно, и многие производители СУБД пытаются ввести в состав своих продуктов возможности, позволяющие использовать их в качестве систем информационного поиска. Нужно заметить, что особых успехов в этой деятельности не видно. Главным образом, это связано с реляционной спецификой современных серверов баз данных, с их ориентацией на обеспечение эффективного доступа к структурированной информации. С другой стороны, многие возможности серверов баз данных в действительности не требуются для поддержки полнотекстовой информации. К таким возможностям можно отнести развитые средства управления транзакциями, организацию развитых средств динамического обновления данных, реализацию структурированных языков запросов и т.д.
В дальнейшем в этом разделе курса мы не будем затрагивать специфические свойства ИПС. Это связано не с тем, что мы считаем это направление недостаточно существенным для организации информационных систем. Все дело в том, что в настоящее время основной областью применения ИПС являются распределенные информационные системы, базирующиеся на Web-технологии. Естественно, имеются смежные вопросы, касающиеся, например, возможностей доступа к традиционным базам данных в среде Internet. Тем не менее, однако, обе эти области достаточно широки по отдельности, чтобы можно было рассматривать их независимо.
8.1. Новые веяния в области серверов реляционных баз данных
Начнем с того, что текущее поколение программных продуктов, предназначенных для управления базами данных, практически полностью базируется на классической реляционной модели данных, которая в той или иной степени развивается и модифицируется в разных системах. Реляционная модель данных обладает большим числом достоинств и, конечно, многими недостатками. К числу достоинств можно отнести простую и вместе с тем мощную математическую основу модели, базирующейся на наиболее прочных аппаратах теории множеств и формальной логике первого порядка. Пожалуй, реляционная модель является исключительным примером соразмерности используемых математических средств и получаемых от этого преимуществ. Достоинством реляционного подхода является и его интуитивная ясность. Для того, чтобы начать грамотно использовать реляционную СУБД, совсем не требуется глубокое погружение в формальную математику. Достаточно понять житейский смысл объектов реляционных баз данных и научиться ими пользоваться. Проводятся интуитивные аналогии, не нарушающие смысл понятий, между отношениями-таблицами-файлами, атрибутами-столбцами-полями записей, кортежами-строками-записями файла и т.д.
Как всегда бывает в жизни, отрицательные качества реляционного подхода представляют обратную сторону его достоинств. Очень просто представлять информацию в виде регулярных плоских таблиц, в которых каждая строка имеет одну и ту же структуру, а в столбцах могут храниться только простые данные атомарной структуры. Но одновременно, при использовании реляционных баз данных для хранения сложной информации возникают сложности. Известный консультант и аналитик Эстер Дайсон сравнивает использование реляционных баз данных для хранения сложных объектов (объектов, для представления которых недостаточно использовать плоские таблицы) с необычным использованием гаража, когда каждый раз, устанавливая автомобиль в гараж, шофер полностью его разбирает, а утром выполняет полную процедуру сборки. На самом деле, соответствующие процедуры сборки (соединения нескольких таблиц) являются наиболее трудоемкими в реляционных СУБД. Другая проблема состоит в том, что упрощенная структура реляционных баз данных не позволяет сохранить в базе данных ту семантическую информацию (знания), которыми располагал ее создатель при проектировании. Реально ситуация выглядит следующим образом. На первой, наиболее интеллектуальной фазе проектирования базы данных имеется существенный запас данных, почерпнутых проектировщиком в процессе анализа предметной области. Однако по мере перехода к определению реально хранимых структур эти знания теряются, оставаясь в лучшем случае в виде бумажной или не привязанной к базе данных электронной информации, использование которой необходимо в жизненном цикле базы данных и соответствующей информационной системы, но сильно затруднено.
Перечисленные положительные и отрицательные качества реляционных баз данных в большой степени влияли на развитие индустрии баз данных в последние годы. Несколько лет тому назад казалось, что перевешивают отрицательные качества. В результате появилось несколько новых направлений архитектур баз данных, каждое из которых принесло новые методы и алгоритмы, а также экспериментальные реализации. Мы не будем глубоко вдаваться в обсуждение этих подходов, но все же приведем их краткую характеристику.
В классической реляционной модели данных содержимым столбцов могут быть только значения базовых типов данных (целые и плавающие числа, строки символов и т.д.). Не допускается хранение в столбце таблицы массивов, множеств, записей и т.п. Собственно, это и означает, что таблицы классической реляционной модели являются абсолютно плоскими (по-другому это называется представлением таблиц в первой нормальной форме). Вся сложность структур предметной области уходит в динамику; требуется непрерывная сборка сложных объектов из их элементарных составляющих. Один из подходов к расширению возможностей реляционной модели данных заключается в отказе от требования первой нормальной формы. Значением столбца таблицы может быть любой объект, представляемый в виде строки, массива, списка и даже таблицы. Понятно, что при использовании таким образом расширенной модели, в качестве строки таблицы может храниться уже собранный объект с произвольно сложной (иерархической) структурой. Причиной того, что реляционные системы с отказом от требования первой нормальной формы не вошли в широкую практику, является прежде всего необходимость полного пересмотра внутренней организации СУБД (начиная со структур хранения). Кроме того, если для классических реляционных баз данных давно и тщательно отработана технология и методология проектирования, то проектирование ненормализованных реляционных баз данных недостаточно хорошо изучено даже на уровне теории. Тем не менее, на рынке СУБД имеется продукт UniVerse компании VMark, в которой в ограниченных масштабах поддерживается хранение ненормализованными реляционными данными.
Понятно, что ограничением ненормализованных реляционных баз данных является обязательность иерархической организации хранимой информации. Конечно, это совсем другой уровень построения информации, чем тот, который поддерживался в дореляционных иерархических системах. Между элементами данных отсутствуют явно проводимые физические ссылки. Упрощена процедура реструктуризации данных (в частности, в ненормализованной реляционной модели предполагается наличие пары операций nest/unnest, позволяющих сделать существующую таблицу элементом, хранимым в столбце другой таблицы, или "вытянуть" на верхний уровень некоторую вложенную таблицу). Тем не менее, общая структура остается иерархической. Во многих случаях этого достаточно (в частности, для решения проблемы, упоминавшегося выше примера Эстер Дайсон).
Однако существуют потребности, выходящие за пределы возможностей иерархических организаций данных. Стандартным примером является необходимость в моделировании сложных объектов, в которые входит один и тот же подобъект. Например, объект "человек" может являться подобъектом объекта "отдел", подобъектом объекта "семья" и т.д. Для определения требуемых структур недостаточна чисто иерархическая организация, требуется возможность построения сетевых структур. Соответствующее направление получило название "базы данных сложных объектов". Поскольку трудно сказать, насколько сложные структуры потребуются при реальном моделировании предметных областей, должен поддерживаться механизм произвольно сложной структуризации с поддержкой возможности определения структурных типов данных, типов массивов, списков и множеств, а также развитыми средствами использования указателей. Конечно, с учетом опыта реляционных баз данных в базах данных сложных объектов никогда не предполагалось использование адресных указателей физического уровня. Одним из естественных требований было наличие возможности взятия из базы данных произвольно сложного объекта с возможностью его перемещения в другую область внешней памяти или вообще в память другого компьютера. Основной проблемой баз сложных объектов являлось отсутствие простого и мощного интерфейса доступа к данным, хотя бы частично сравнимого с простотой и естественностью реляционных интерфейсов.
Возникновение направления объектно-ориентированных баз данных (ООБД) определялось прежде всего потребностями практики: необходимостью разработки сложных информационных прикладных систем, для которых технология предшествующих систем баз данных не была вполне удовлетворительной. Как мы видели, определенными недостатками обладали и классические реляционные системы, и системы, основанные на ненормализованной реляционной модели, и базы данных сложных объектов.
Конечно, ООБД возникли не на пустом месте. Соответствующий базис обеспечивался как предыдущими работами в области баз данных, так и давно развивающимися направлениями языков программирования с абстрактными типами данных и объектно-ориентированных языков программирования.
Что касается связи с предыдущими работами в области баз данных, то наиболее сильное влияние на работы в области ООБД оказали проработки реляционных СУБД и следующего хронологически за ними семейства БД, в которых поддерживалось управление сложными объектами. Эти работы обеспечили структурную основу организации OOБД.
Среди языков и систем программирования наибольшее первичное влияние на ООБД оказал Smalltalk. Этот язык сам по себе не являлся полностью пионерским, хотя в нем была введена новая терминология, являющаяся теперь наиболее распространенной в объектно-ориентированном программировании. На самом деле, Smalltalk основан на ряде ранее выдвинутых концепций.
В наиболее общей и классической постановке объектно-ориентированный подход базируется на следующих концепциях:
- объекта и идентификатора объекта;
- атрибутов и методов;
- классов;
- иерархии и наследования классов.
Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта. Любой объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с объектом во все время его существования и не меняется при изменении состояния объекта.
Каждый объект имеет состояние и поведение. Состояние объекта - набор значений его атрибутов. Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта. Значение атрибута объекта - это тоже некоторый объект или множество объектов. Состояние и поведение объекта инкапсулированы в объекте; взаимодействие объектов производится на основе передачи сообщений и выполнении соответствующих методов.
Множество объектов с одним и тем же набором атрибутов и методов образует класс объектов. Объект должен принадлежать только одному классу (если не учитывать возможности наследования). Допускается наличие примитивных предопределенных классов, объекты-экземпляры которых не имеют атрибутов: целые, строки и т.д. Класс, объекты которого могут служить значениями атрибута объектов другого класса, называется доменом этого атрибута.
Допускается порождение нового класса на основе уже существующего класса - наследование. В этом случае новый класс, называемый подклассом существующего класса (суперкласса) наследует все атрибуты и методы суперкласса. В подклассе, кроме того, могут быть определены дополнительные атрибуты и методы. Различаются случаи простого и множественного наследования. В первом случае подкласс может определяться только на основе одного суперкласса, во втором случае суперклассов может быть несколько. Если в языке или системе поддерживается единичное наследование классов, набор классов образует древовидную иерархию. При поддержании множественного наследования классы связаны в ориентированный граф с корнем, называемый решеткой классов. Объект подкласса считается принадлежащим любому суперклассу этого класса.
Одной из более поздних идей объектно-ориентированного подхода является идея возможного переопределения атрибутов и методов суперкласса в подклассе (перегрузки методов). Эта возможность увеличивает гибкость, но порождает дополнительную проблему: при компиляции объектно-ориентированной программы могут быть неизвестны структура и программный код методов объекта, хотя его класс (в общем случае - суперкласс) известен. Для разрешения этой проблемы применяется, так называемый, метод позднего связывания, означающий, по сути дела, интерпретационный режим выполнения программы с распознаванием деталей реализации объекта во время выполнения посылки сообщения к нему. Введение некоторых ограничений на способ определения подклассов позволяет добиться эффективной реализации без потребностей в интерпретации.
Видимо, наиболее важным новым качеством ООБД, которое позволяет достичь объектно-ориентированный подход, является поведенческий аспект объектов. В прикладных информационных системах, основывавшихся на БД с традиционной организацией (вплоть до тех, которые базировались на семантических моделях данных), существовал принципиальный разрыв между структурной и поведенческой частями. Структурная часть системы поддерживалась всем аппаратом БД, ее можно было моделировать, верифицировать и т.д., а поведенческая часть создавалась изолированно. В частности, отсутствовали формальный аппарат и системная поддержка совместного моделирования и гарантирования согласованности этих структурной (статической) и поведенческой (динамической) частей. В среде ООБД проектирование, разработка и сопровождение прикладной системы становится процессом, в котором интегрируются структурный и поведенческий аспекты. Конечно, для этого нужны специальные языки, позволяющие определять объекты и создавать на их основе прикладную систему.
С точки зрения разработчиков информационных систем подход OOБД кажется очень заманчивым. Более того, на рынке программных продуктов управления базами данных сегодня существует около двух десятков коммерческих систем, которые более или менее успешно продаются (примерами таких систем являются O2 компании O2 Technology (www.o2tech.com), ObjectStore компании ObjectDesignInc., (www.odi.com), Objectivity/DB компании Objectivity, Inc., Versant компании VersantObjectTechnology (www.versant.com), ONTOSDB компании ONTOS, Inc., (www.ontos.com) и т.д.). Во всех этих системах поддерживается возможность распределенного хранения баз данных; имеется возможность написания приложений и/или методов объектов на одном или нескольких языках объектно-ориентированного программирования (как правило, в минимальный набор языков входят Си++ и Java); обеспечиваются удобные средства доступа к базам данных в среде Internet и т.д. Тем не менее, объектно-ориентированные системы оказались не в состоянии конкурировать с реляционными системами, поставляемыми ведущей шестеркой поставщиков программных средств управления базами данных.
Прежде чем перейти к краткому обзору современных продуктов ведущих компаний, попробуем понять, почему же большинство заказчиков предпочитает использовать именно эти продукты, а не объектно-ориентированные СУБД. Мы можем привести несколько соображений, некоторые из которых являются в большей степени эмоциональными, а другие - чисто техническими. Во-первых, компьютерное сообщество уже пережило техническую революцию при переходе от дореляционных СУБД к реляционным. Как и любая революция, эта техническая революция была пережита непросто. Хотя и очень простые, идеи реляционного подхода воспринимались широкими массами пользователей и разработчиков информационных систем на протяжении нескольких лет. Переход к новым технологиям вызвал необходимость в реинжиниринге, а иногда и полной переделке существующих и используемых практически информационных систем. В результате, конечно, были получены более качественные продукты, но одновременно с этим обострилась известная проблема "унаследованных" ("legacy") систем, которые являются морально устаревшими, плохо сопровождаемыми, но необходимыми для успешного функционирования предприятия. Переход к объектно-ориентированной технологии баз данных означал бы новую революцию. Потребовалась бы качественная, основанная на иных понятиях переделка прикладного программного обеспечения. Естественно, это отпугнуло пользователей и разработчиков от объектно-ориентированных баз данных.
Во-вторых, любая развитая система управления базами данных является предельно сложным программным продуктом, для эффективной реализации которого требуется привлечение правильным образом разработанного или выбранного из числа готовых набора методов, алгоритмов, протоколов и структур данных. Кроме того, для достижения должного уровня эффективности СУБД должна пройти длительный процесс отладки, обкатки и настройки. Ведущие производители реляционных СУБД в той или иной степени успешно решили эти проблемы за счет больших денежных и временных затрат. Конечно, сегодня невозможно говорить о какой-либо объектно-ориентированной СУБД, которая была бы настолько же хорошо отлажена и настроена, которая могла настолько же эффективно обрабатывать большие объемы данных, как продукты ведущей шестерки.
В-третьих, одним из основных преимуществ реляционного подхода по отношению к дореляционным системам является наличие ненавигационного интерфейса доступа к базам данных. Отсутствие явной навигации в базе данных позволяет освободить прикладную программу от технических деталей ассемблерного уровня (можно проводить аналогию между явным переходом по ссылке в структуре внешних данных и безусловным переходом в языках уровня ассемблера), а также дает возможность более эффективного по сравнению с ручным выполнения операций доступа к данным (когда способ выполнения непроцедурно заданного оператора выбирается в компиляторе соответствующего языка, то используется гораздо больший объем знаний, чем тот, которым располагает отдельно взятый человек). Отрицательным свойством ненавигационного, основанного на манипуляциях с таблицами способа доступа к базам данных является так называемая потеря соответствия (impedancemismatch) языков программирования и языков баз данных. Классические, наиболее используемые на практике языки программирования ориентированы на работу с атомарными значениями встроенных типов данных. Даже если в языке содержатся средства определения массивных типов данных (структур, массивов, множеств, списков и т.д.), то перед выполнением любой обрабатывающей операции необходимо выбрать атомарный элемент соответствующего массивного типа. Языки реляционных баз данных ориентированы на работу с таблицами: операндами любой операции являются таблицы, и в результате выполнения операции формируется новая таблица. Фактически, языки программирования и языки реляционных баз данных ортогональны:
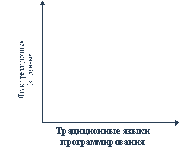
Рис. 8.1. Ортогональность языков программирования и языков баз данных
То, что предлагается в языке SQL относительно возможности встраивания его конструкций в традиционный язык программирования - это попытка сгладить эту ортогональность. (Имеются в виду средства встраиваемого SQL для развертывания операций обработки результата запроса к базе данных в последовательность или цикл обработки ее строк.)
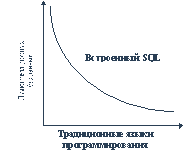
Рис. 8.2. Сглаживание ортогональности средствами языка SQL
Одной из задач, которую ставили перед собой разработчики подхода ООБД, состояла в том, чтобы добиться отсутствия потери соответствия между языками объектно-ориентированного программирования и языками объектно-ориентированных баз данных. Идеалом представлялось то, чтобы один и тот же язык использовался и для программирования приложений (и написания методов объектов), и для обеспечения доступа к базе данных. Поскольку природа объектно-ориентированных языков не изменилась по сравнению с их предшественниками, средства доступа к базе данных естественно стали снова навигационными. Конечно, это другой уровень навигации с использованием логических ссылок, но навигация есть навигация - за одно обращение к базе данных можно получить возможность работы с одним объектом. Естественно, и это отпугнуло разработчиков и пользователей.
Заметим, что в последнее время ситуация изменилась. В результате деятельности международного консорциума ObjectDatabaseManagementGroup (ODMG) был выработан стандарт языка запросов (OQL - ObjectQueryLanguage) к ООБД (в июле 1997 г. опубликована его вторая версия). Этот язык ненавигационный и синтаксически близок к языку SQL. Но для текущего поколения объектно-ориентированных СУБД язык OQL появился слишком поздно, и с этим связана вторая причина неудачи объектно-ориентированных СУБД на рынке.
До возникновения стандартов ODMG существовало столько же разных представлений о природе ООБД, сколько разных соответствующих продуктов. Если реляционные системы с самого начала основывались на одной и достаточно точной модели, то для ООБД такой общей модели не было вообще. Все попытки создать такую модель требовали привлечения весьма трудного математического аппарата, обычно непонятного даже профессиональным математикам. Группа ODMG, включающая всех основных поставщиков объектно-ориентированных СУБД, смогла предложить общую объектную модель баз данных, но и эта модель появилась слишком поздно, а кроме того, она слишком неточна и является результатом многочисленных компромиссов. Естественно, необоснованные теоретически объектно-ориентированные СУБД не могли вызвать слишком большого доверия.
Повторим, что ситуация меняется. Если раньше между ODMG и сообществом реляционных баз данных (в частности, комитетом по стандартизации языка SQL) существовали принципиальные разногласия, то сегодня обе стороны стремятся к сближению позиций. Тем не менее, на сегодняшний день рынок объектно-ориентированных систем по крайней мере на порядок уже рынка реляционных систем и, возможно, еще более сузится в связи с возникновением нового сектора коммерческих объектно-реляционных систем, поставку которых начинают ведущие компании.
Назад |
Содержание |
Вперед

