2010 г.
Система моделирования Grid: реализация и возможности применения
Грушин Д.А., Поспелов А.И.
Институт системного программирования РАН (ИСП РАН), Москва
Содержание
- 1. Введение
- 2. Система моделирования Grid
- 2.1. Модель представления Grid системы
- 3. Эксперименты
- 4. Заключение
- Литература
Аннотация
В статье описывается разработанная в ИСП РАН система моделирования распределенных вычислительных сред Grid. С помощью этой системы проведен анализ реальной вычислительной среды Sharcnet. На основе анализа были выявлены возможные способы существенного увеличения эффективности работы среды.
1. Введение
В последнее время к вычислительным кластерам проявляется повышенный интерес со стороны науки, образования и промышленности. С доступностью кластерных технологий связан рост числа установок, которые строятся, устанавливаются, и которые специалисты пытаются применять для решения своих производственных задач. Кластерные вычислительные системы становятся повседневным инструментом исследователя и инженера. Однако, любая организация, становясь обладателем вычислительного кластера, не использует его постоянно, в режиме “24/7”, более того, очень часто такой дорогостоящий вычислительный ресурс простаивает.
В связи с увеличением количества кластеров набирает все большую популярность концепция Grid [12, 16]. Grid позволяет совместно использовать вычислительные ресурсы, которые принадлежат различным организациям и которые могут быть расположены в различных административных областях. В Grid могут объединяться разнородные вычислительные ресурсы: персональные компьютеры, рабочие станции, кластеры и супер-компьютеры.
Одним из наиболее распространенных в настоящее время программных средств для реализации Grid является пакет Globus Toolkit [7]. Пакет Globus Toolkit разрабатывается, поддерживается и продвигается международным альянсом разработчиков из университетов США и Великобритании, а также научных лабораторий и вычислительных центров. Globus Toolkit является свободно распространяемым с открытым исходным кодом программным пакетом и предлагает базовые средства для создания Grid инфраструктуры: средства обеспечения безопасности в распределенной среде, средства надежной передачи больших объемов данных, средства запуска и получения результатов выполнения задач на удаленных вычислительных ресурсах. На базе пакета Globus Toolkit создаются промышленные версии реализаций Grid инфраструктуры, например, такие как Univa [19] и Platform Globus Toolkit [17].
Однако, несмотря на то, что уже сейчас предлагаются ставшие “де-факто” стандартными средства создания Grid-инфраструктур, существует ряд важных научных задач, в том числе и теоретических, без решения которых полномасштабное использования возможностей Grid технологий в промышленности невозможно. Одной из актуальных задач в настоящее время является эффективное управление вычислительными ресурсами в распределенной среде. С ростом числа ресурсных центров, входящих в распределенную инфраструктуру, отсутствие хорошего планировщика, обеспечивающего управление потоком задач, не только значительно снижает эффективность использования всей Grid-инфраструктуры, но может сделать бессмысленным ее создание. При этом следует отметить, что для таких распределенных систем характерным является динамичное развитие, что делает невозможным решение задачи эффективного управления “в статике” – один раз и навсегда.
С другой стороны, оптимизация алгоритмов управления распределенной средой на непосредственно уже существующей Grid-инфраструктуре затруднено и связано со значительными издержками и простоями ресурсных центров, а часто в силу масштабности распределенной среды вообще невозможно. В связи с этим актуальной задачей является создание системы моделирования Grid-инфраструктуры, которая позволит адекватно оценивать ее поведение при изменяющихся условиях и на основе этого оптимизировать стратегии управления потоками задач.
Система моделирования может быть использована для оценки эффективности распределенной вычислительной среды в различных ситуациях, например:
- при изменении нагрузки: количества поступающих задач, их размерности, приоритета, периода поступления и т.д.;
- при отключении части вычислительных ресурсов или добавлении новых ресурсов;
- при увеличении количества передаваемых данных;
- при выходе из строя части коммуникационных каналов
При этом оценка эффективности управления может проводиться по следующим наиболее популярным критериям [4]:
- минимизация среднего времени ожидания задачи в очереди;
- минимизация максимального времени выполнения группы задач (makespan);
- максимизация пропускной способности – числа завершенных задач в единицу времени;
- минимизация простоев процессоров
- и т.д.
В настоящее время существует несколько проектов по разработке систем моделирования Grid. Среди них наиболее известны: Bricks [14], MicroGrid [11], OptorSim [13], SimGrid [10] и GridSim [1]. Данные системы обладают как достоинствами, так и недостатками. Среди недостатков можно отметить узкую специализацию систем, отсутствие публично доступных версий, а также ограниченность моделируемых архитектур Grid систем. Особенности реализации некоторых из них накладывают ограничения на количество одновременно существующих элементов в Grid системе и требуют от пользователя знания специальных языков программирования, что значительно снижает эффективность работы с такими системами.
2. Система моделирования Grid
С 2007 года в ИСП РАН разрабатывается система моделирования Grid. При разработке мы старались избежать недостатков, присущих существующим системам, а также реализовать некоторые новые интересные идеи.
В частности, система проектировалась так, чтобы сделать работу пользователя максимально удобной и быстрой. В отличие от перечисленных выше систем в разработанной системе не нужно вручную писать программу моделирования. Пользователь работает в специальном редакторе, задавая топологию Grid системы и свойства отдельных элементов. При этом автоматически проверяются различные виды ошибок: значения параметров, выходящие за область допустимых значений, несовместимость различных элементов, соединенных между собой, и т.п.
Сценарий работы с системой изображен на рисунке 1(a). Пользователь задает описание моделируемой среды и указывает различные параметры. Система автоматически генерирует код программы моделирования и компилирует его. Программа-симулятор запускается и создает в результате своей работы профиль выполнения. Полученный профиль анализируется и представляется пользователю в виде HTML документа.
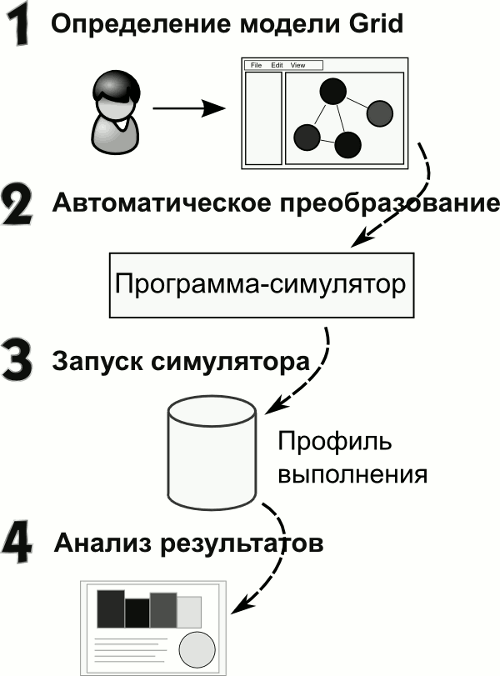
(a) Сценарий работы системы моделирования Grid
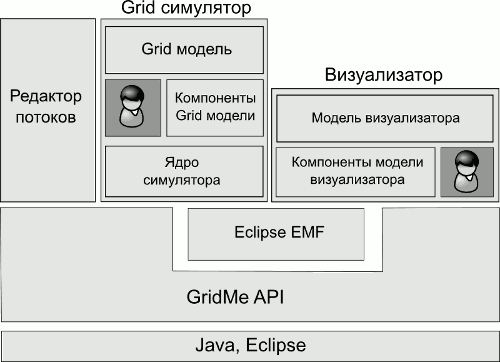
(b) Основные компоненты системы моделирования Grid
Рисунок 1: Система моделирования Grid
Система моделирования реализована на основе платформы Eclipse [2], с использованием только языка Java. Это дает возможность интеграции с другими Eclipse приложениями, например, средой разработки Java, системами контроля версий, и т.п. и позволяет использовать систему моделирования под различными операционными системами – Linux, Windows, Solaris и др.
Система расширяема и рассчитана на гибкое использование. Система позволяет моделировать различные Grid архитектуры: одно и двух-уровневые системы с одним или несколькими брокерами, добавлять хранилища данных, определять топологию сетевых соединений и т.д. Система включает в себя множество реализованных компонент, таких как брокер, кластер, поток задач и т.д. Кроме того, пользователи могут расширять систему, реализовывая свои собственные компоненты.
Поведение отдельных элементов моделируется с помощью конечных автоматов, что позволяет работать с моделями больших систем – порядка тысяч процессоров и более миллиона задач.
Система предоставляет возможность для быстрого описания алгоритмов распределения задач с помощью набора правил. При моделировании распределения задач в Grid очень часто требуется проверить несколько алгоритмов, незначительно отличающихся друг от друга, например, сортировкой входного потока задач, способом выбора очередной задачи или ресурса и т.п. Описание алгоритма с помощью набора правил в такой ситуации позволяет гораздо быстрее проверить работу алгоритма, чем в случае реализации его в виде, например, Java класса, с последующей отладкой и тестированием.
В системе поддерживается возможность проведения серии экспериментов, состоящей из последовательных запусков выполняемой модели с изменением некоторых параметров при каждом следующем запуске. Например, может изменяться поток задач, конфигурация кластеров, сетевых соединений и т.п. Это позволяет в рамках одного эксперимента посмотреть динамику изменения эффективности системы и определить узкие места.
В системе реализован удобный механизм обработки результатов моделирования. Результат выполнения модели хранится в отдельном профиле и может обрабатываться независимо. Пользователь может использовать свой шаблон для выбора и визуализации только необходимой в данный момент информации. Это позволяет нескольким исследователям провести моделирование один раз, а затем независимо анализировать полученную информацию.
Система также включает в себя редактор и анализатор записей потоков задач (workload) [15, 8]. Запись потока представляет собой текстовый файл, каждая строка которого содержит характеристики отдельной задачи: время порождения, время запуска, общее время выполнения, количество занимаемых процессоров и т.д. Анализатор позволяет отобразить различные характеристики потока – количество задач, соотношение однопроцессорных и параллельных задач, график порождения задач во времени и т.п. С помощью редактора можно изменять поток – копировать и перемещать части потока, соединять несколько потоков в один, изменять характеристики группы задач и т.п. Также, редактор позволяет создавать синтетический поток по заданным параметрам.
Основные компоненты системы изображены на рисунке 1(b). Это – редактор и анализатор потоков, симулятор Grid системы, визуализатор.
2.1. Модель представления Grid системы
Модель для представления Grid инфраструктуры (мета-модель Grid) в нашей системе изображена на рисунке 2.
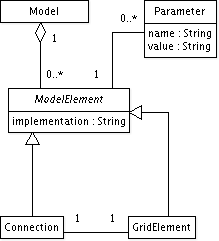
Рисунок 2: Мета-модель Grid
Модель Grid состоит из множества элементов (ModelElement), связанных между собой. Доступно два вида элементов – соединение (Connection) и Grid-элемент (GridElement). Grid-элементом может быть кластер, брокер, пользователь, хранилище данных и т.п. Соединения предназначены для передачи данных между Grid-элементами. У каждого элемента есть строковый атрибут реализация (implementation). Значение данного атрибута указывает на имя Java-класса, определяющего поведение элемента. Каждый элемент может быть параметризован. Параметр представляет собой пару строк (имя, значение) и может иметь дочерние параметры. Дочерние параметры используются, например, при задании свойств алгоритмов распределения задач. Предположим, для элемента мы выбираем реализацию “кластер” и для кластера определяем значение параметра “schedulerClass” как “BackfillLocal”. В данном случае реализация “BackfillLocal” может также требовать задания значений параметров. В этом случае параметр “schedulerClass” будет иметь дочерние параметры.
Таким образом, модель Grid-системы определяется в несколько этапов (рисунок 3). Сначала мы создаем Grid элементы, из которых будет состоять Grid система. Затем задаем топологию сети путем создания связей между элементами и сетевыми соединениями. И на последнем этапе выбираем реализацию каждого элемента и определяем значения параметров для конкретной реализации.
Рисунок 3: Этапы определения модели Grid-системы
В системе представлены основные элементы, необходимые для создания моделей Grid. Это – кластер, брокер, поток задач, сетевое соединение. Базовый набор реализованных алгоритмов распределения для кластера и брокера включают:
| BackfillLocal
| реализация алгоритма Backfill (алгоритм обратного заполнения) для кластера. Задание с меньшим приоритетом может быть запущено вне очереди, но только в том случае, если оно не будет мешать запуску более приоритетных заданий
|
| BestFitLocal
| реализация алгоритма “наилучший подходящий” для кластера. Для данного текущего количества свободных узлов подбирается задача, наиболее близкая по ширине
|
| FirstFitLocal
| реализация алгоритма “первый подходящий” для кластера. Размещается задача из начала очереди. Если узлов для запуска задачи не достаточно, то размещения не происходит
|
| RandomFitGlobal
| “случайный подходящий” для брокера. Для текущей задачи случайным образом выбирается кластер из множества подходящих
|
и другие.
В качестве примера рассмотрим, каким образом в системе моделирования будет определяться архитектура, изображенная на рисунке 4(a).
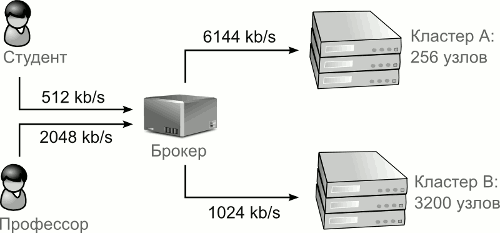
(а) Система
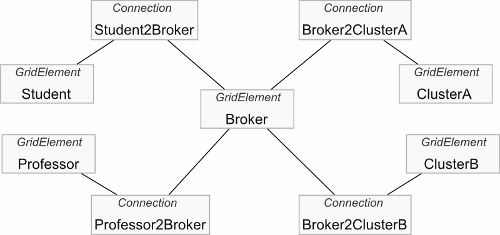
(b) Модель
Рисунок 4: Пример определения Grid системы
Пользователи, брокер и кластеры представляются с помощью Grid-элементов, с именами Student, Professor, Broker, ClusterA, ClusterB соответственно – рисунок 4(b). Для задания соединений используются элементы Connection с именами Student2Broker, Professor2Broker, Broker2ClusterA, и Broker2ClusterB. В таблице 1 перечислены параметры и имена классов, реализующих поведение элементов.
| Имя | Реализация | Параметр | Значение
|
| ClusterA | SimpleCluster |
|
| | Nodes | 256
|
| | Speedup | 1
|
| | schedulerClass | ”BackfillLocal“
|
| ClusterB | SimpleCluster |
|
| | Nodes | 3200
|
| | Speedup | 1
|
| | schedulerClass | ”BackfillLocal“
|
| Student | WorkloadTaskFlow |
|
| | Wfile | ”student.sfw.zip“
|
| | startDelay | 0
|
| Professor | WorkloadTaskFlow |
|
| | Wfile | ”professor.sfw.zip“
|
| | startDelay | 0
|
| Broker | SimpleBroker |
|
| | schedulerClass | ”RandomFitGlobal“
|
| Student2Broker | DelayedConstantConnection |
|
| | Count | 512000
|
| | Period | 1
|
| Professor2Broker | DelayedConstantConnection |
|
| | Count | 2048000
|
| | Period | 1
|
| Broker2ClusterA | DelayedConstantConnection |
|
| | Count | 6144000
|
| | Period | 1
|
| Broker2ClusterB | DelayedConstantConnection |
|
| | Count | 1024000
|
| | Period | 1
|
Таблица 1: Параметры элементов
Для кластеров мы используем реализацию SimpleCluster. В качестве параметров необходимо указать количество узлов – параметр nodes и коэффициент ускорения – параметр speedup. Ускорение определяет, насколько быстрее, по сравнению с некоторым эталонным кластером, задачи будут выполняться на данном кластере. В нашем примере мы предполагаем, что задачи выполняются с одинаковой скоростью на обоих кластерах. Параметр schedulerClass определяет алгоритм распределения задач локальным планировщиком. В примере мы задаем алгоритм BackfillLocal, представляющий собой реализацию алгоритма Backfill [6].
Для пользователей ”студент“ и ”профессор“ мы используем реализацию WorkloadTaskFlow. Данная реализация позволяет порождать задачи в моделируемой системе на основе собранных статистических данных использования реально существующей среды Grid. В качестве параметров задается имя файла в формате ”workload“ – параметр wfile и время до начала порождения первой задачи – параметр startDelay. Период позволяет активизировать различные потоки задач в различное время.
Брокер задается реализацией SimpleBroker. Единственным параметром является алгоритм распределения задач глобальным планировщиком – параметр schedulerClass. Мы указываем значение RandomFitGlobal. Это реализация алгоритма ”случайный из подходящих“ – для очередной задачи брокер выбирает множество кластеров, которые могут выполнить данную задачу, и затем случайным образом выбирает один кластер из данного множества.
Для сетевых соединений Student2Broker, Professor2Broker, Broker2ClusterA и Broker2ClusterB мы используем реализацию DelayedConstantConnection. Это простая реализация сетевого соединения позволяет передавать заданное количество данных с некоторой задержкой. В нашем примере это 512, 2048, 6144 и 1024 kb/sec соответственно.
После того, как описание модели завершено, трансляция данного описания, и последующая компиляция исходного кода происходит автоматически. На выходе получается выполняемая программа-симулятор, которую можно запустить и получить результат в виде профиля выполнения.
Для визуализации результатов система предоставляет готовые шаблоны, отображающие:
- загруженность системы – общую и с разбивкой по отдельным кластерам
- время ожидания задач в очереди – среднее и пиковое с разбивкой по классам задач и по отдельным кластерам
- пропускной способности – как по количеству задач, так и используя интегральную оценку
Содержание Вперёд

