Спецификация и форматы обмена данными в разнородных информационных системах на базе XML-технологий
Старых Владимир Александрович
Российский государственный университет инновационных технологий и предпринимательства
Дунаев Сергей Борисович
Коровкин Сергей Дмитриевич
Иваново, Ивановский государственный энергетический университет
1.Постановка проблемы
В задачах построения сложных информационных систем одной из главных проблем является обмен данными между различными подсистемами. Нередко самая простая задача импорта/экспорта данных из одной системы в другую приводит к необходимости серьезных разработок модулей на стыке подсистем. Задача существенно облегчается, если данные определенного класса будут перемещаться между подсистемами, при условии, что в этих подсистемах будет заложена технологически реализованная возможность воспринимать извне и отдавать наружу данные в стандартном формате импорта/экспорта. Данный подход является основой для разработки метаданных и интерфейсов для обмена регулярными данными для различных унаследованных разноформатных систем. На этапе построения инфологических моделей документарного обеспечения управления и создания спецификаций протокола взаимодействия разноформатных систем используются технологии XML.
Данный подход прошёл апробацию в проекте интеграции функциональных подсистем, базирующихся на разнородных программных платформах ERP-класса с системой автоматизированного документооборота и делопроизводства, построенной на технологиях платформы Lotus Notes Domino, DominoDoc.
Для решения этой задачи необходимо:
- разработать формат документа обмена, основанный на языке XML, и спецификации на создание программных средств обмена между различными информационными системами и/или подсистемами, как уже созданными, так и, по возможности, теми, что будут созданы в будущем .
- разработать спецификации на различные слои метаданных, которые будут описывать данные в каждой из подсистем, вовлеченные в процессы информационного обмена. Сам по себе стандарт XML является обобщенным форматом данных, он создан консорциумом, состоящим из многих компаний, и необходимо дополнить язык XML семантикой, которая существует в области разработки информационных систем, основанных на понятии "документ", таких как: электронные архивы, системы документооборота и делопроизводства, генераторы отчетов из различных ERP-систем и т.д..
- разработать сценарии информационного обмена, которые будут включать в себя и использовать подмножество XML-схем, что обеспечивает с одной стороны возможность работы с файлами в едином универсальном формате стандартным XML-инструментарием, а с другой стороны упрощает разрабатываемые программы для импорта/экспорта структурированных данных в XML-формате.
2.Два основных варианта использования сценариев обмена между разноформатными системами
Прежде чем перечислить предполагаемые сценарии использования универсального формата XML-обмена, отметим, что существует два взгляда на эти сценарии. Представим, что имеются 3 системы различного класса, обозначенные, как: X-система, Y-система, Z-система (см. Рис. 1)
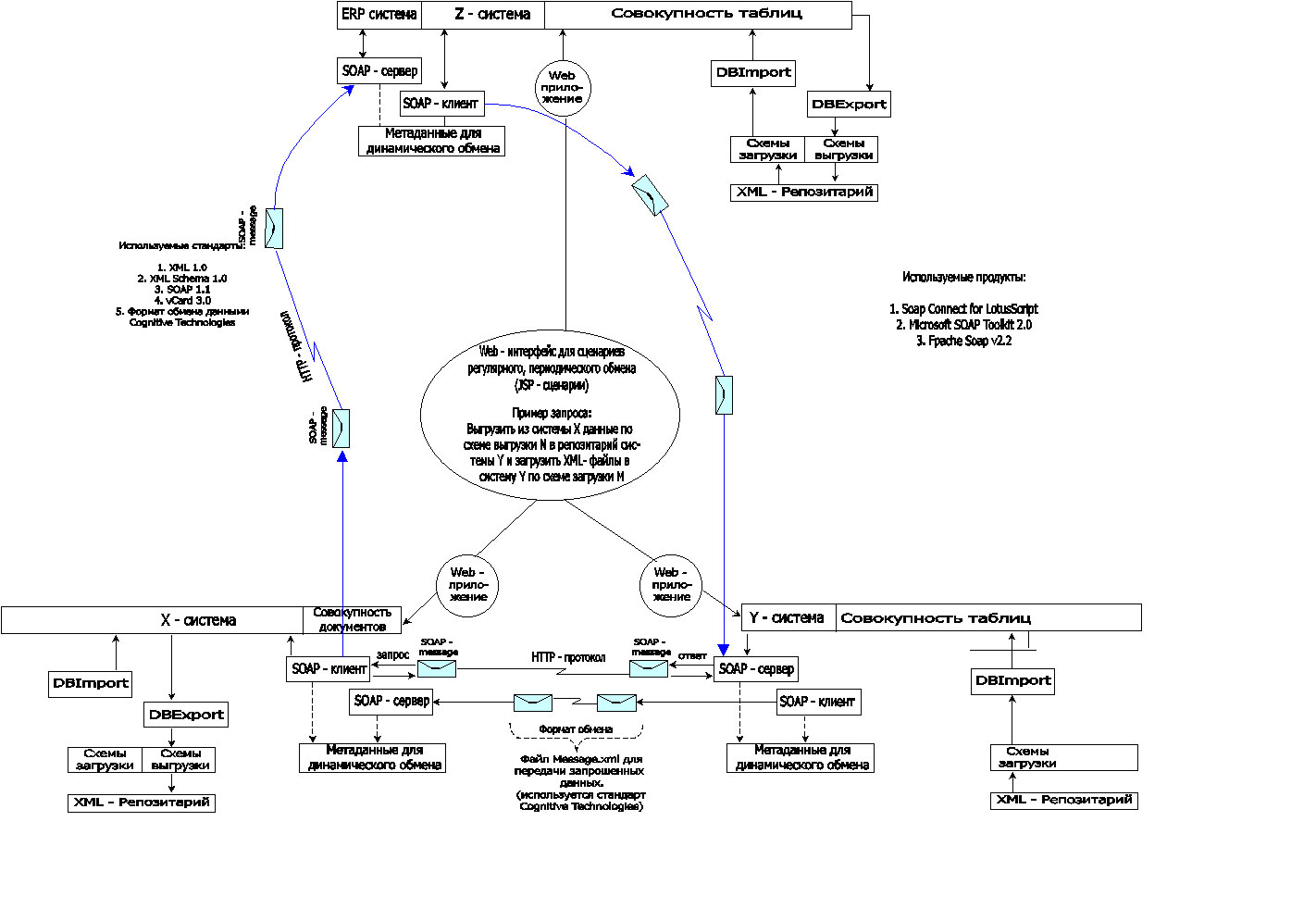
Рис.1 Схема взаимодействия трех разноформатных систем
2.1 Вариант регулярного периодического обмена данными
В каждой системе имеется XML-Репозитарий, где хранятся XML-файлы, содержащие схемы загрузки и выгрузки информации из собственного Хранилища (1-й слой метаданных). Со схемами загрузки/выгрузки работают универсальные Java-приложения DBImport и DBExport, доступ к которым может быть осуществлен через Web-интерфейс (см. на схеме Web-приложение). Они не модифицирутся при переносе из системы в систему (или при добавлении новых систем), а настраиваются на работу со схемами данных (XML-схемы). Достоинством этих модулей является то обстоятельство, что они не нуждаются в перепрограммировании. Они обеспечивают возможности экспорта/импорта через гибкие, универсальные интерфейсы:
- уровень XML-схемы (XML-парсер, обеспечивающий разбор XML-файлов из Репозитария и безошибочное извлечение данных);
- уровень доступа к Хранилищу (JDBC или Сonnector), обеспечивающий извлечение и запись данных в Хранилище c использованием XML-конвертора и валидации данных по схеме.
В общем случае процесс обмена осуществляется с использованием сценариев загрузки/выгрузки автоматически, или с возможностью административного интерфейса через Web-приложение, так как это обозначено на схеме:
"Выгрузить из системы X данные по схеме выгрузки N и загрузить в систему Y по схеме загрузки M ".
Способы организации административного интерфейса в варианте регулярного периодического обмена.
Таких способов в этом варианте также может существовать два:
1. Централизованное администрирование репозитария сценариев загрузки/выгрузки данных. Этот вариант предполагает создание единого репозитария схем загрузки/выгрузки для всех систем участвующих в обмене данными и средства его администрирования.
2. Распределенное администрирование локальных репозитариев для каждой системы в отдельности. Этот вариант предполагает создание отдельных репозитариев схем загрузки/выгрузки для каждой из систем и развертывания локальных средств их администрирования.
2.2 Вариант динамического обмена
Формат обмена данными
В этом варианте ключевым звеном является единый универсальный формат документа обмена и протокол SOAP, по которому передаются динамически запрашиваемые данные. Этот формат представляет собой подмножество XML-схем, дополненный XML семантикой, существующей в области разработки информационных систем.
Предполагается, что каждая из информационных систем имеет внутреннее хранилище (например, базу данных). Связь между системами осуществляется по принципу "точка-точка" через канал передачи: отправитель экспортирует внутренние данные в формат, а получатель импортирует данные из формата в свое внутреннее хранилище. В этом случае данные находятся в родном формате системы, к которой обращаются по запросу и каждая из запрашивающих клиентских SOAP-программ имеет доступ только к метаданным, но не к методам извлечения этих данных. Методы извлечения нужных данных, определяемых в метаописаниях, реализуют специальные программные компоненты Plug-Ins, написанные средствами той системы, к которой обращаются по запросу. Plug-Ins должны уметь извлекать данные и формировать документ в соответствии с форматом передачи данных. Для этого plug-ins должны реализовывать в полном объеме интерфейсы взаимодействия с SOAP-сервером обмена и снабжаться необходимыми библиотеками для непосредственного доступа к источнику данных. В свою очередь SOAP-сервер должен реализовывать механизм взаимодействия с клиентами посредством SOAP-сообщений, в соответствии с разрабатываемой спецификацией.
SOAP-сообщение выглядит следующим образом:
<Envelope xmlns="http://schemas.xmlsoap.org/soap/envelope/" <Header> <!-- заголовки --> </Header> <Body> <!-- документы --> </Body> </Envelope>
Заголовки пакета (содержимое элемента <Header>) могут быть любыми. Прикладные программы должны формировать их с учетом потребностей конкретной среды передачи данных в соответствии со стандартом SOAP.
Тело пакета <Body> состоит из одного или более документов. Документами считаются все элементы, непосредственным родителем которых является <Body>.
В соответствии с разрабатываемой спецификацией , в состав SOAP-сообщения могут входить один или более XML - документов, являющиеся уни версальными документами обмена между системами. Спецификация предусматривает один стандартный тип документа обмена, прикладные программы могут вводить свои.
Вместе с этим, спецификация определяет четыре стандартных подтипа передаваемых сообщений:
1. Команды для управления действиями систем;
2. Метаданные (описания) предоставляемых ресурсов;
3. Передаваемые данные;
4. Результат обработки запроса системой.
При этом спецификация никак не ограничивает возможности передачи нескольких документов в одном SOAP-сообщении.
Процесс обмена
Процесс обмена динамическими данными между разноформатными системами представляет собой взаимодействие SOAP-клиента и SOAP-сервера, обменивающихся SOAP-сообщениями. После процесса установления соединения, SOAP-клиент запрашивает у удаленного SOAP-сервера блок метаданных, где описана структура предоставляемой для экпорта информации. На данном этапе происходит SOAP-обмен управляющими блоками (пакеты данных еще не передаются). После получения метаданных, клиент формирует специальный запрос на получение определенного пакета данных в едином универсальном формате. SOAP-сервер принимает запрос клиента, вызывает необходимый модуль выгрузки (plug-in), который выгружает нужные данные из источника данных в единый формат передачи. SOAP-сервер формирует SOAP-сообщение, проверяет его на целостность и передает по линии связи (протокол HTTP) в принимающую систему. На принимающей стороне начинает работу импортирующая программа (соответствующий plug-in), который обеспечивает импорт данных, конвертируя XML-представление во внутреннее представление источника данных. Для различных ERP-систем существуют готовые XML конверторы, которые могут быть использованы при необходимости.
3. Разработка спецификации
В данном проекте предложено унифицированное решение, которое базируется на едином представлении документа. Необходимое требование - на всех этапах жизненного цикла работа с документом ведётся единообразно. Это позволяет выделить часто встречающиеся преобразования для повторного использования в других информационных системах.
Спецификация документов
В системе существует несколько типов документов. В процессе жизненного цикла документ создается, преобразуется из одного типа в другой, становится основой для создания новых документов и, в конце концов, уничтожается, или сохраняется в архиве долговременного хранения. Над каждым документом в системе производятся операции, иначе называемые преобразованиями.
Входные преобразования
Можно выделить несколько источников для входных преобразований:
1. Неэлектронный документ. В этом случае происходит распознавание в том или ином виде: распознавание текста отсканированных бумажных документов, распознавание речи, введенной с микрофона и т.д.
2. Неструктурированный документ. Необходимо выделение информации из такого документа. Примерами могут служить рубрикация, авторефирирование, автовыделение информации определенного типа: дат, географических названий, номеров телефонов и т.д.
3. Структурированный документ. Это самый простой случай. Здесь необходимо лишь преобразование данных из одного формата в другой, например из DBF в XML.
Выходные преобразования
Выходное преобразование переводит структурированную информацию в неструктурированную. Результатом являются, как правило, текстовые форматы, предназначенные для печати - HTML, RTF, TEX, PDF и другие.
Преобразование может предваряться подготовкой данных и, возможно, их агрегацией. Это делают программы, называемые обычно генераторами отчетов.
Унифицированная модель документа
Любой документ можно представить в виде модифицированной модели "сущность-связь"
Объекты:
1.1. Тип объектов обязательно имеет имя.
- 1.2. Объекты могут иметь метаданные (не путать со свойствами).
- 2.1. Только простые, нет составных (структур).
2.2. Есть ключевые свойства, уникальные в контексте отношения.
2.3. Возможны однозначные и многозначные свойства. Под многозначными свойствами понимается неупорядоченное множество попарно различных элементов (т.е. порядок элементов не сохраняется).
2.4. Нет производных свойств (таких, как сумма чего-нибудь).
2.5. Свойства (как и объекты) могут иметь метаданные.
4. Подтипы отсутствуют.
Единственным серьезным дополнением модели сущность/связь в данной концепции является введение понятия метаданных. Метаданные документа - это некоторая дополнительная информация, которая семантически не может быть отнесена к свойствам документа. Например, идентификатор документа является внутренней информацией, которая актуальна для хранилища, но ее бессмысленно делать свойством. Метаданные свойства - это дополнительная информация о свойстве, которая отражает его представление в прикладной программе и влияет на его обработку. Метаданные могут быть только простых типов или являться ссылками на другие типы).
Документ - это множество объектов, связанных отношениями, с одним выделенным объектом - корневым. Коллекция документов - это множество, элементами которого являются Документы и Коллекции документов.
Хранение документов в базах данных
Самым важным моментом в любой информационной системе является хранение документов в базе данных. Основными характеристиками являются скорость выполнения запросов и занимаемый объем.
Соответствие между формальной моделью документа и представлением в реляционной СУБД:
1. Каждой сущности соответствует кортеж.
2. Однозначным свойствам соответствуют атрибуты кортежа.
3. Многозначные свойства представляются повторяющимися кортежами.
4. Ключевым свойствам соответствует ограничение на уникальность атрибутов.
5. Отсутствующим свойствам соответствуют NULL-значения.
6. Бинарному отношению типа "один ко многим" и "один к одному" соответствует дополнительное поле в кортеже, соответствующему сущности на стороне "многие". Атрибутам отношения соответствуют поля в этом же кортеже.
7. Бинарному отношению типа "многие ко многим" и отношениям со степенью более двух соответствуют кортежи с полями - внешними ключами, указывающими на кортежи - участники отношения. Атрибутам отношения соответствуют поля в этом же кортеже.
8. Метаданные представляются дополнительными полями в кортежах, соответствующих сущностям и свойствам.
Соответствие между формальной моделью документа и представлением в реляционной СУБД:
1. Каждой сущности соответствует структура.
2. Однозначным свойствам соответствуют вершины в структуре.
3. Многозначные свойства представляются вершинами типа "массив структур" со структурами, имеющими единственное ключевое поле, соответствующее свойству.
4. Ключевым свойствам соответствуют ключевые вершины в структуре.
5. Отсутствующим свойствам соответствуют отсутствующие вершины.
6. Бинарному отношению типа "один ко многим" и "один к одному" соответствует вершина в структуре, соответствующей сущности на стороне "один". Тип этой вершины - массив структур, соответствующих сущности на стороне "многие". Атрибутам отношения соответствуют дополнительные вершины в дочерней структуре. Ключом в этой структуре является либо вершина, являющаяся естественным уникальным идентификатором, либо, в отсутствие таковой, искусственно добавленная вершина целого типа со случайным значением.
7. Безатрибутному бинарному отношению типа "многие ко многим" соответствует вершина в одной из структур. Тип вершины - ссылка на значение, указывающая на другую структуру.
8. Атрибутному бинарному отношению типа "многие ко многим" и отношениям со степенью более двух соответствует вершина в одной из структур. Тип вершины - структура. Поля этой структуры - ссылки на значения, указывающие на структуры - участники отношения. Атрибутам отношения соответствуют поля в этой структуре.
9. Метаданные сущностей и свойств представляются дополнительными вершинами в структурах, соответствующих сущностям.
Модель документа в документоориентированных базах данных, типа Lotus Notes, позволяющих хранить информацию достаточно произвольного формата, включая форматированные тексты, графику и видеоизображения, представляется обычно набором полей самого разнообразного содержания и описывается в произвольных формах, по модели которой создается документ и коллекции документов, созданных по одной форме. В таких базах, которые ближе всего к объектно-иерархическим возможен единственный вид отношений между сущностями ("родительский" документ - ответные документы), который поддерживается на системном уровне. В таких базах возможны составные форматируемые поля, которые сами по себе могут представлять коллекции объектов.
XML-представление документов очень похоже на представление в иерархических СУБД. Только вместо дерева описания данных фигурирует XML-схема. Фактически, она позволяет описать все те же самые понятия в других терминах - терминах стандарта XML.
Спецификация описания документов при помощи XML-схем
При передаче разнообразных данных между разноформатными подсистемами необходимо разработать унифицированный доступ к документам, основанный на их XML-описаниях. В настоящее время существует несколько идеологий построения форматов, близких по назначению к тем требованиям, которые сформулированы для данной работы. А именно:
1. Документ описывает сам себя. На этом принципе построен формат OIFML (кандидат на стандарт консорциума ODMG - Object Database Management Group. Объект, записанный в этом формате, выглядит следующим образом:
<odmg_object oid="Jane"> <class>Engineer</class> <contents> <attribute name="Name"> <value><string val="Sally"/></value> </attribute> <attribute name="Age"> <value><unsignedshort val="11"/></value> </attribute> <attribute name="PersonID"> <value> <array size="3"> <element index="0"> <value><unsignedshort val="450"/></value> </element> <element index="2"> <value><unsignedshort val="270"/></value> </element> </array> </value> </attribute> </contents> </odmg_object>
2. Информация о структуре документа хранится отдельно от документа, но в том же файле и с использованием собственных описательных средств.
3. Информация о структуре хранится в отдельной схеме.
Следует отметить, что для описания схемы XML-файлов уже сейчас существует с десяток форматов. Однако стандартными из них являются лишь два: DTD (старый формат, являющийся частью XML 1.0) и XML Schema (утвержден в мае 2001 года). Далее под XML-схемой будет подразумеваться файл в формате XML Schema (.xsd).
Стандарт XML-схема является наиболее предпочтительным.
1. Он предоставляет значительную часть информации, которая хранится обычно в схеме базы данных (реляционной, иерархической и т.д.).
2. В файл со схемой можно внести дополнительную информацию, так что стандартные валидаторы будут ее игнорировать, а специализированные программы будут её использовать.
При разработке XML-схем, описывающих структуры данных и документы, участвующие в процессе информационного взаимодействия разноформатных систем настоящей спецификацией учитываются следующие основные положения:
Требования к унифицированной XML-схеме, описывающей документы обмена.
Схема может рассматриваться как коллекция (словарь) определений типов и объявлений элементов, имена которых принадлежат определенному пространству имен, которое называется целевым пространством имен. Целевые пространства имен дают возможность видеть различия между определениями и объявлениями из различных словарей. Например, целевое пространство имен дает возможность различить между объявлением для element в словаре языка XML Schema, и объявлением для element в гипотетическом словаре языка по химии. Первый - часть целевого пространства имен http://www.w3.org/2001/XMLSchema, а второй - часть другого целевого пространства имен.
Если нужно проверить документ примера на соответствие одной или нескольким схемам (посредством процесса, называемого проверкой правильности схемы), то для проверки элементов и атрибутов в документе примера, необходимо определить нужные объявления элементов и атрибутов и определения типов в схемах. Целевое пространство имен играет важную роль в процессе идентификации.
Все разрабатываемые схемы должны удовлетворять требованиям комитета W3C в соответствии с XML Schema Requirements, описанными в документе http://www.w3.org/TR/2003/WD-xmlschema-11-req-20030121/
1. Схема не должна иметь ориентации на конкретное предприятие или фрагментов, ориентированных на конкретного потребителя.
2. Схема должна быть документирована. Программные продукты, работающие со схемой не должны использовать недокументированные возможности схемы.
3. Объекты метаданных должны иметь осмысленные идентификаторы, а в случае, если они длинные или сложные, еще и синонимы. Объекты метаданных, идентификаторы которых могут использоваться при работе схемы (например, параметры подключения к источнику данных), должны иметь комментарии
XML схема должна определять:
1. Механизмы для разграничения структуры (пространства имен, элементы, атрибуты) и содержания (типы данных, сущности(объекты), примечания);
2. Механизмы, обеспечивающие возможности наследования для элементов, атрибутов и типов данных;
3. Механизмы для встраивания документов;
XML схема должна:
1. Обеспечивать набор примитивных типов, включая: byte, date, integer, sequence, SQL & Java primitive data types, etc.;
2. Определять тип системы, которая адекватна операциям импорта/экспорта из СУБД (к примеру, реляционная, объектная, OLAP);
3. Различать требования по отношению к лексическому представлению данных и управлению основным информационным набором;
4. Позволять создание пользовательских типов данных, которые могут быть получены из существующих типов данных и ограничивать некоторые их свойства (например, диапазон значений, точность, длина, маски и т.д.) .
XML схема должна:
1. Определять отношения между схемами и XML документами;
2. Определять отношения между достоверностью (validity) схемы и достоверностью XML;
3. Определять отношения между схемами, XML DTDs, и их информационными наборами;
Описание сущности представляет собой вложение complexType ' sequence, в котором перечислены элементы, соответствующие свойствам, связанным элементам и связям. Метаданные элементов представляются также, как и метаданные свойств. Дополнения представляются квалифицированными атрибутами у элемента xsd:complexType.
Реквизиты представляются элементами (тегами), являющимися экземплярами сложных типов (complex type) с простым содержимым (simple content) или простых типов (simple type). Название тега - название реквизита с точностью до преобразования недопустимых символов (см. далее). Многозначные реквизиты представляются повторяющимися тегами. Метаданные представляются атрибутами встроенных типов.
Подробнее:
1. Описание типа реквизита всегда представляет собой вложение complexType ' simpleContent ' restriction.
2. Возможны как варианты "один реквизит Ф один тип реквизита", так и "много реквизитов Ф один тип реквизита".
4. Метаданные
Метаданные в процессе обмена данными между разноформатными системами также могут быть описаны на двух уровнях:
- 1. Схемы метаданных для регулярного периодического обмена
2. Схемы метаданных для динамического обмена данными по запросам через протокол SOAP
4.1 Схемы метаданных для регулярного периодического обмена
Загружаемые документы XML могут поступать из другого приложения, из внешнего источника данных (база данных или файл) или из формы ввода данных. Для загрузки/выгрузки данных XML в реляционные БД и документальные БД типа Lotus Notes разработаны специальные программные средства. Данные программные средства представляют собой набор библиотек, позволяющих осуществлять загрузку и выгрузку данных в формате XML произвольной структуры. Настройка под конкретную структуру осуществляется при помощи т.н. карт загрузки/выгрузки, которые представляют из себя XML-документы, описывающие сценарий преобразования данных. В свою очередь описание работы с источником данных содержится в XML-документах, включающих в себя информацию о метаданных источника (информация о типах, параметры подключения и т. д.).
Общие схемы загрузки/выгрузки представлены на рис. 2 и рис. 3
Схема загрузки
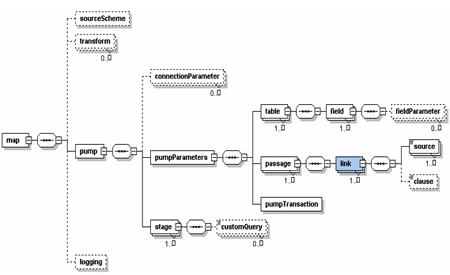
Рис. 2 Схема карты загрузки
Одним из самых мощных интерфейсов доступа к содержимому XML документов является Document Object Model - DOM.
Объектная модель XML документов является представлением его внутренней структуры в виде совокупности определенных объектов. Для удобства эти объекты организуются в некоторую древообразную структуру данных - каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое, в виде набора вложенных элементов, комментариев, секций CDATA и т.д. представляется в этой структуре поддеревьями. Так как в любом правильно составленном XML-документе обязательно определен главный элемент, то все содержимое можно рассматривать как поддеревья этого основного элемента, называемого в таком случае корнем дерева документа.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов и является просто своеобразным API для их обработчиков. DOM является стандартным способом построения объектной модели любого HTML или XML документа, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать его элементы.
Для описания интерфейсов доступа к содержимому XML документов в спецификации DOM применяется платформо-независимый язык IDL и для использования их необходимо "перевести" на какой-то конкретный язык программирования. Однако этим занимаются создатели самих анализаторов, и разработчику можно ничего не знать о способе реализации интерфейсов - с точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами.
Достоинством модели DOM является тот факт, что загрузчик получает произвольный доступ к элементам документа. Однако обработка документов большого объема потребует значительных вычислительных ресурсов.
Другим подходом при обработке XML-документов является модель SAX. Он построен на механизме обратных вызовов. Пользователь должен предоставить класс, который будет реагировать на события разбора XML (или игнорировать их). Примерами таких событий являются начало документа, начало тэга и т. п.
Использование модель SAX для обработки XML-документов в данном случает представляется более разумным при реализации загрузчика, поскольку не требует значительных ресурсов памяти. Однако, при использовании модели SAX обработка документа будет происходить последовательно. Элементы документа будут обрабатываться в том порядке, в каком они встречаются в документе.
Данное обстоятельство не позволяет обрабатывать элементы документа в произвольном порядке, что может понадобиться при загрузке, в случае, если например таблицы должны быть связаны по уникальным идентификаторам со справочниками, а данные справочника расположены в документе после основных данных.
Для разрешения таких ситуаций в спецификации на карту загрузки существует элемент <passage></passage> , который позволяет задавать несколько проходов обработки входного документа со своими настройками связок обработки данных. Таким образом, можно определить первый проход, который будет обрабатывать данные справочников, а вторым проходом определить обработку данных таблицы с установлением идентификаторов из справочников.
Схема выгрузки
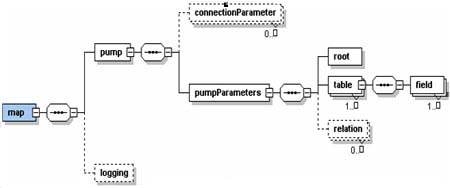
Рис.3 Схема выгрузки
Для создания документов XML на основе выгрузки реляционных данных может применяться целый ряд методов. Ниже перечисляются основные из них:
- Документ XML может быть создан на основе данных таблицы базы данных. Таблица форматируется как документ XML, а ограничения внешнего ключа используются для создания иерархии элементов документа. Имена типов элементов формируются из имени таблицы и имен столбцов;
- Документы формируются с учетом структур, представленных в схеме базы данных, но могут также использоваться реляционные представления. Каждое представление преобразуется в отдельный документ XML. Иерархия элементов может быть определена на основе внешних ключей и/или отношения, которое явно указывает, какие значения должны быть развернуты в иерархию и как именно это должно быть сделано;
- Для создания документов XML могут применяться произвольные запросы, что характерно и для предыдущих методов. Однако иерархия элементов все еще зависит от структуры схемы базы данных (и/или представлений);
- Может применяться шаблон документа, в котором части документа определены в терминах запросов. Эти запросы выполняются и результаты их форматируются, а затем объединяются в один документ;
- Формируется запрос с подзапросами и структура запроса определяет структуру документа. Такой метод может применяться, если средства вывода данных в коде XML встроены в машину запросов базы данных (например, Oracle и MS SQL Server).
В настоящей спецификации выбран вариант в соответствии с которым выгрузка производится по предопределенным картам выгрузки. Карты выгрузки должны обеспечивать возможности определения:
- 1. Произвольных имен элементов и атрибутов элементов в выходном XML-документе;
2. Отношений между таблицами источника данных для правильного построения дерева экспорта;
3. Вариантов выгрузки данных из таблиц.
4.2 Схемы метаданных для динамического обмена
Для того, чтобы разнородные системы могли динамически обмениваться информацией, спецификация предусматривает разработку форматов двух типов универсальных документов:
- 1. Формат документа, являющегося сообщением, передаваемым от одной системы к другой (Схема описания сообщений message.xsd).
2. Формат документа, описывающий хранящиеся на данной системе ресурсы (Схема описания метаданных resources.xsd);
При этом в схему документа, описывающего сообщения обмена импортирована схема описывающая хранящимися в данной системе ресурсы.
Это обосновывается тем, что желательно:
- Избежать дублирования при хранении схем;
- Хранить метаописания каждого из предоставляемых ресурсов совместно со списком всех ресурсов системы, для более эффективного управления списком.
4.2.1 Схема описания сообщений
Разрабатываемая спецификация предусматривает использование команд для управления системами. На каждой из систем, команды обрабатываются SOAP-сервером, принявшим SOAP-сообщение. SOAP - сервер, получивший команду, вызывает методы соответствующего native plug-in, в соответствии с разрабатываемыми интерфейсами взаимодействия между SOAP - сервером и native plug-ins. Структура схемы сообщений приведена на рис.4
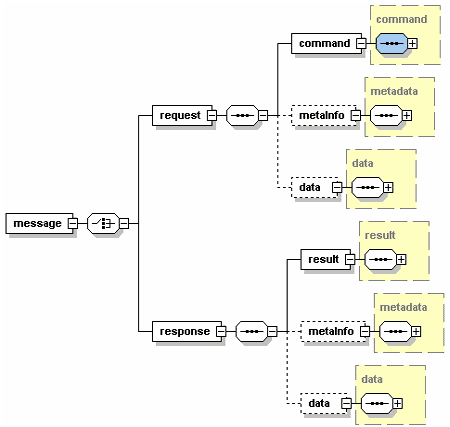
Рис.4 Схема единого документа обмена между системами.
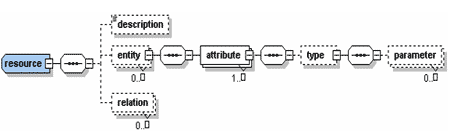
4.2.2 Схема описания метаданных предоставляемого ресурса
Схема описывает предоставляемый для обмена ресурс. При передаче данных между системами необходимо передавать также и метаописания сущностей и атрибутов, которым соответствуют данные, для того чтобы соответствующий plug-in на принимающей системе мог загрузить принятые данные в источник данных и, при необходимости обновить данные в списке предоставляемых ресурсов. На текущий момент спецификация не предусматривает создания средств для автоматической генерации метаописания конкретного ресурса.
Данная схема (см. Рис.5) описывает документ, хранящий список имеющихся в системе ресурсов.
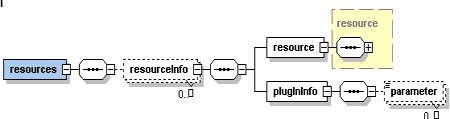
Рис. 5. Схема списка имеющихся в системе ресурсов для обмена.
5.Требования к программным модулям и API
Для ERP - систем, участвующих в процессе обмена предъявляется требование обеспечения WEB-интерфейса к своим данным. Почти все современные системы уже имеют такие интерфейсы:
1. WEB-расширения 1C: предприятие.
2. WEB-расширения Парус On-line
3. Web-расширение SAP/R3
Любое WEB-расширение обеспечивает доступ к данным с помощью собственных встроенных методов (V7Script 1C, ASP, JSP и т. д.). Например, в Парус взаимодействие WEB-клиента с базой данных осуществляется через WEB-сервер (IIS), на котором хранятся asp-сценарии (active server pages), обеспечивающие механизм ADO доступа к БД Oracle. (см. asp.parus.ru).
В 1С WEB-расширение также обеспечивает ASP-разработку через собственную библиотеку связи с V7Script.
В любом случае SOAP-сервер, обеспечивающий вызовы native-plug-ins ДОЛЖЕН быть реализован как WEB-приложение:
1. для DOMINO - как WEB-приложение DOMINO с использованием библиотеки SOAP-поддержки;
2. для 1С и ПАРУС как WEB-приложение IIS с использованием MS SOAP Toolkit;
3. для систем, базирующихся на СУБД Oracle, как внешнее приложение на базе WEB - сервера APACHE с использованием библиотеки поддержки APACHE AXIS и APACHE SOAP.
5.1. Требования к SOAP-серверу
Программный продукт типа Soap-сервер, должен соответствовать стандарту обмена данными, в соответствии с данной спецификацией. Любой SOAP-сервер в любой информационной системе должен обеспечивать:
1. Доступ по протоколу HTTP;
2. Обработку сообщений, описываемых в спецификации на сообщения обмена между системами;
3. Хранение и предоставление в формате, определенном в данной спецификации, метаописаний предоставляемых ресурсов;
4. Механизм взаимодействия с native plug-ins при необходимости получения или загрузки данных.
Данная спецификация определяет использование программных средств, реализующих SOAP-спецификацию (любая реализация SOAP Implementation, основанная на спецификации SOAP 1.1, например Apache Soap, или Мicrosoft Soap Toolkit);
SOAP-сервер должен обеспечивать работу с plug-in, соответствующим требуемому метаописанию ресурса. Для этого в списке метаописаний ресурсов включен элемент pluginInfo, описывающий параметры работы с plug-in. Логику обработки параметров должен реализовывать SOAP-сервер. Например, если SOAP-сервер и plug-in взаимодействуют в соответствии с технологией COM (Component Object Model), то параметры должны содержать уникальный идентификатор COM-объекта, реализующего plug-in и другую необходимую информацию.
5. 2 Требования к Plug-Ins
В настоящей спецификации Plug-Ins определены как специальные программные компоненты, написанные средствами той системы, к которой обращаются по запросу. Plug-Ins должны уметь извлекать данные и формировать документ в соответствии с форматом передачи данных. Для этого plug-ins должны реализовывать в полном объеме интерфейсы взаимодействия с SOAP-сервером обмена и снабжаться необходимыми библиотеками для непосредственного доступа к источнику данных. Интерфейсы взаимодействия Plug-Ins c SOAP-сервером должны определяться в терминах любой объектной реализации COM, DCOM, EJB, CORBA. Возможны несколько реализаций SOAP-серверов, отвечающих данной спецификации, для различных программно-технологических платформ.
Разрабатываемые plug-ins должны удовлетворять следующим требованиям:
- 1. Учитывать особенности источника данных, с которым он работает (параметры подключения, синтаксис языка общения с источником и др.);
2. Уметь работать с метаописаниями ресурсов (создавать структуры в источнике данных по метаописаниям, загружать данные;
3. Формировать XML-документ с данными, содержащий метаописания данных ресурса, в соответствии с разрабатываемой спецификацией;
4. Полностью реализовывать интерфейс взаимодействия с SOAP-сервером.
Литература
- 1. Дейт К. Дж. Введение в системы баз данных / Пер. с англ. 6-е изд. К.: Диалектика, 1998)
2. Д.С. Порай "Обработка документов как основа построения информационных систем"
3. Башмаков А.И., Старых В.А. Систематизация информационных ресурсов для сферы образования: классификация и метаданные. - М.: "Европейский центр по качеству", 2003. - 384 с.
4. Дунаев С.Б. "Технология Интернет-программирования" BHV Cпб 2001