2004 г.
XML: свобода, ограниченная только фантазией
Арсений Чеботарев, Издательский Дом "КОМИЗДАТ"
Неважно, какую платформу для своих веб-приложений вы выбираете - Sun, Linux или Microsoft, в любом случае ваши веб-сервисы будут общаться на XML
Технология XML продолжает свое наступление на системы хранения, выборки и передачи данных. На сегодня существует несколько хороших парсеров - в том числе для Java (от IMB, Apache и Sun).
Термины
XML (eXtensible Markup Language) - расширяемый язык разметки. Язык, в котором текст чередуется с элементами разметки, маркерами.
DTD (Document Type Definition) - язык описания схемы данных, применяемый в первой версии XML.
XSDL (XML Schema Definition Language). Новый и рекомендуемый способ формального описания структуры XML-документа. Для описания структуры, естественно, применяется нормальный XML. Структура может быть применена дважды - как шаблон для порождения документа и как правило валидации, то есть проверки документа на предмет соответствия схеме.
DOM (Document Object Model). Спецификация высокого уровня, представляющая документы
в виде структуры агрегированных объектов. Реализация DOM представляет собой парсер высокого
уровня.
SAX (Simple API for XML). Базовый парсер XML. Набор функций низкого уровня, основанных
на вызове пользовательского кода в момент возникновения событий - таких как "получено
начало/конец элемента", "получен текст" и так далее.
Microsoft, как ни странно, тоже не стала изобретать "полностью свой XML", а в соответствии
с рекомендациями предлагает Parser & SDK. Ввиду возможности использования готового
и бесплатного кода, применение XML, с точки зрения разработчика, является привлекательным
способом хранения и доступа к данным.
Дилемма 0.
Применять ли XML вообще?
XML предназначен для тех приложений, в которых текст (документ) должен быть легко доступен
как программно, так и в читабельном формате. Это своего рода компромисс между бинарным
кодом, отражающим встроенные типы языков программирования, и текстовым форматом, предназначенным
для восприятия человеком. Примером представления первого типа служит встроенная база данных
Berkeley db. Примером данных второго сорта может быть документ в формате RTF или Microsoft
Word.
XML полезен также в случаях, когда данные представляются скорее в виде древовидных
структур, а не плоских двумерных таблиц отношений, характерных для RDBS ("скорее" - потому
что, приложив достаточно усилий, древовидную структуру можно представить в виде набора
плоских представлений). Другое ограничение, снимаемое XML,- это фиксированная схема данных.
Конечно, RDBS тоже могут манипулировать структурами отношений в процессе работы приложения,
но, вообще говоря, это не то, для чего они созданы.
Третье преимущество XML - это гарантированная доставка методами Сети, в частности HTTP.
Особенно это касается методов использования, когда вы взаимодействуете со стандартизированными
протоколами по SOAP. Все это распространяется также и на веб-сервисы, WSDL и так далее.
В таких случаях - поскольку вы должны в конце концов представить данные в виде XML - вы,
возможно, сочтете удобным хранить и обрабатывать данные тоже в этом формате. На самом
деле подробности реализации не входят в компетенцию веб-сервисов, так что последнее решение
зависит от вас.
Частным случаем является доступ к базам данных в сети посредством метода доступа XML,
поскольку многие производители RDBS предусматривают такую возможность. Естественно, представление
отношений в виде XML унаследует все ограничения отношений, то есть все они будут иметь
фиксированную схему.
Дилемма 1.
Атрибуты или элементы?
Это один из тех простых вопросов, на которые нет простого ответа. Предположим, у нас
есть запись о служащем, состоящая всего из двух элементов:
<worker>
<id>48709</id>
<name>John Smith</name>
</worker>
То же самое можно записать и другим способом:
<worker id=48709>
<name>John Smith</name>
</worker>
Или даже так:
<worker id="48709" name="John Smith"/>
Какая запись является предпочтительной? Это зависит от нескольких соображений. Атрибуты доступны непосредственно при выборе элемента, так что можно сэкономить пару строк кода для выбора значения. Задание атрибута фиксирует также его арность - то есть атрибут может быть указан или не указан - но не более одного раза.
С другой стороны, атрибут - это всегда простое значение, которое не может стать сложным
ни при каких условиях. Это ограничение можно рассматривать и как положительное - то есть
таким образом можно принудительно ограничить фантазию пользователей.
Кроме того, следует иметь в виду два отличия атрибутов и элементов.
Первое из них касается старых типов данных XML 1.0 - таких как ID, IDREF, NMTOKEN и
других. В целях совместимости их использование ограничено только атрибутами.
Вторая особенность - это то, как обрабатываются значения по умолчанию. Значение атрибута
по умолчанию будет подставлено в том случае, если этот атрибут не указан совсем. Можно
задействовать значение элемента по умолчанию - для этого сам элемент должен быть указан,
но не должен содержать значения - отсутствие элемента не породит элемент со значением
по умолчанию.
Третья особенность - элементы могут адресоваться из других мест того же или другого
документа (ссылки). Адресовать подобным образом атрибуты невозможно.
Дилемма 2.
Как обеспечить устойчивость?
Устойчивость - это свойство структур данных сохранять свое состояние в промежутках
между сеансами, например между запусками программы или между подключениями пользователя
к удаленному серверу. Чаще всего XML хранится в виде текстового файла, но для хранения
зачастую используются также и табличные базы данных.
Третий вариант - так называемые объектные базы данных - представляют собой некоторые
прикладные пакеты ограниченного хождения. Фактически "объектная БД" - это промежуточный
программный уровень, который скрывает от пользователя метод хранения XML, то есть именно
то, что вы и должны реализовать.
Вопрос хранения в таблицах DB (с методом доступа SQL или не-SQL - не суть важно) носит
характер компромисса. На одном полюсе - метод представления всего документа одним полем
базы данных, например в таблице с двумя полями: DOCNAME, DOCXML. Преимущества такого подхода
очевидны - не нужно разрабатывать никакой логики на уровне DB, все операции ограничиваются
тремя действиями: добавить, удалить, выбрать. При этом можно использовать простые и эффективные
хранилища: устойчивые хеш-таблицы, Беркли db или ldap. Скорость выборки документа будет
максимальной - но поиск и разбор такого документа потребует времени.
Другим полюсом является хранение с высокой степенью детализации. При этом все элементы,
текст, атрибуты, ребра и так далее нумеруются уникальными идентификаторами. В таблицу
заносится полный перечень узлов и связей. По такой таблице проще искать узел с конкретным
значением, связями, типом используя индексированный поиск и запросы, например SQL, но
восстановление DOM-представления по такой таблице - задача не для слабонервных.
Конечно, многие попытаются совместить оба варианта. Можно предложить несколько комбинированных
подходов, основанных на избыточности и предварительном анализе задачи. Так, если нас интересуют,
в основном, только ребра (связи) определеного типа (например, поиск e-mail по нику), то
можно составить таблицу отношений для этого типа связей. При этом в другом месте можно
хранить полный XML текст для менее частых запросов.
Недостаток комбинирования методов - ваша программа сможет работать только с документами
определенного типа, а это не совсем то, для чего создан XML. Кроме того, в условиях избыточности
вам придется гарантировать согласованность параллельных вхождений. То есть, если изменяется
документ, то должны измениться и все производные отношения. Или, напротив, при изменении
отношения должен измениться и документ XML (возможно, такое поведение вообще следует запретить).
Иными словами - вам придется скрывать используемый метод доступа (например, SQL) и реализовать
свою версию "объектной базы данных", отслеживая целостность данных вручную.
Дилемма 3.
Нужна ли схема?
На самом деле существует, по крайней мере, три способа определения схемы документа
XML, в том числе DTD, Documet Type Definition и XMLShcema. Последняя является новейшей
разработкой, находящейся на стадии стандартизации, и всем разработчикам рекомендовано
придерживаться именно этого синтаксиса. Учебник для начинающих можно найти по адресу: www.w3.org/TR/xmlschema-0/.
Самое главное - это то, как вы собираетесь в будущем использовать свои документы и
схемы. Возможны три варианта:
1. Структура документа жестко зафиксирована в программе. Например, если вы разбираете
XML, полученный как результат запроса к известной базе данных, то ваша программа может
выбирать совершенно определенные элементы.
2. Вторая версия происходящего - ссылка на схему приводится в самом документе - например
так, как HTML-документ ссылается на CSS. Выглядит это следующим образом:
<article xmlns:xsi=
"http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="article.xsd">
В таком случае вы можете верифицировать документ относительно такой схемы стандартными
средствами SAX и DOM. Другое дело: что делать, если документ не проходит валидацию? Но,
тем не менее, это уже что-то.
3. Вариант третий - вы получаете документы из внешнего источника, ничего не зная об
их схеме. Простой пример - HTML-документ произвольной структуры. В таком случае вы можете
только проверить, удовлетворяет ли документ условиям валидности.
Фактически по отношению к схеме возможна только одна операция - верификация документа
с простым вопросом: "удовлетворяет ли документ схеме?". Кроме того, приложение на основании
схемы может распределять память - то есть создавать иерархию объектов для документа определенного
типа. Учитывая тот факт, что схема является моделью данных, можно рекомендовать всегда
строить схему для случаев, когда XML-данные первичны, и опираться на UML-представление
структуры БД, когда XML-данные экспортируются из БД.
Дилемма 4.
DOM или SAX?
И тот, и другой метод позволяют разбирать и работать с одними и теми же XML-документами
- но на разном уровне.
DOM - это общий способ представления иерархических документов, рекомендация W3C к представлению
и методу доступа (фактически сокращение Document Object Model совершенно не ссылается
на XML). Архитектурно DOM основан на узловом представлении, то есть объектами представляются
элементы, а не связи между ними. В основе иерархии стоит класс Узла - в его функции входит
двусторонняя связь по вертикали (с родительским узлом) и по горизонтали (с сестринскими
узлами). У каждого узла не более одного сестринского элемента, предшествующего и следующего
за ним.
От узла происходят Элементы - это такие узлы, которые дополнительно содержат два списка:
список дочерних элементов и список атрибутов. Атрибуты - это пары ключ-значение. Имена
ключей должны быть уникальными, но их порядок не имеет значения.
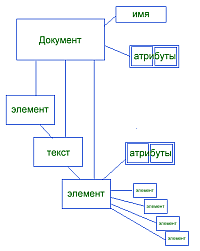
Особый случай элемента - Документ, который всегда является корневым элементом. Документ имеет уникальное имя и не имеет родительского элемента. Все остальные узлы имеют родительский документ, причем только один.
От узла происходят также два листовых (не имеющих дочерних) типа узла - Текст и Комментарий. В списке дочерних элементов элемента могут чередоваться узлы других элементов, текста и комментарии в любом порядке.
Помимо классов, над ними определены методы - типично "добавить узел", "удалить узел", "добавить атрибут", "удалить атрибут" и так далее.
Недостаток DOM - достаточно большие накладные расходы на обработку каждого элемента; они могут составлять даже 1000% и более от нетто данных. При обработке больших документов это может стать критическим параметром. Кроме того, некоторые операции с DOM-представлением (такие как поиск) будут связаны со сложным обходом дерева, и в общем случае они медленнее линейного поиска.
Метод доступа через DOM удобен, когда структура документа должна (или может) быть доступна в целом и легко модифицироваться - например так, как это происходит в документе Word или при формировании страницы DHTML.
SAX, Simple API for XML - это де-факто стандартный метод разбора, завязанный конкретно на XML. В основе лежит обработка событий - то есть при открытии и закрытии каждого элемента, получении текста и так далее ваша программа получает управление, сопровождаемое параметрами события. Для своей работы этот метод не требует использования больших хранилищ данных
или иерархий объектов в памяти, так что можно обрабатывать очень большие объемы данных
на ограниченных ресурсах (как пример практически бесконечного XML-потока представьте датчик
сигналов, генерирующий бесконечную последовательность XML-элементов).
Кроме того, SAX-разбор происходит асинхронно, то есть программа не должна ждать завершающего тега для отработки уже полученных. Последнее может пригодиться, например, для отображения записей SQL-запроса еще до того, как все они будут получены. Другое применение - обрыв сеанса, допустим при нахождении одной нужной записи из миллиона.
Недостаток SAX - необходимость хранения состояния в процессе разбора XML-потока, то есть в случае со сложной и/или недетерминированной структурой придется частично реконструировать узловую модель для отслеживания уровней вложения.
SAX и DOM подходы иногда сочетают между собой. Так, веб-браузер отображает элементы в процессе получения по методу SAX, но после получения документа строит его DOM-модель
для DHTML-доступа в терминах иерархии объектов.
Дилемма 5.
Узлы или ребра?
DOM представляет собой модель, которая в качестве сущностей использует узлы. Этот метод хорош для хранения документа в виде объектов в памяти, но может стать значительной проблемой при хранении иерархических данных в таблицах SQL. Для хранения, напротив, более подходящим будет метод представления, в котором сущностью являются связи между узлами. Дополнительным условием является наличие у всех узлов однозначных идентификаторов, так чтобы было возможно идентифицировать два одинаковых сестринских узла. Поскольку все связи возможно представить в виде простой таблицы, то реберное представление позволяет просто (с учетом наличия идентификаторов) хранить XML в SQL базе данных с максимальной степенью детализации.
Рассмотрим простой пример, иллюстрирующий сказанное. Допустим, у нас есть простая XML-схема
(модель статьи):
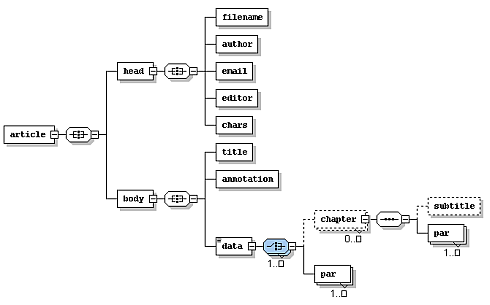
На основе этой модели можно создать такой валидный документ:
<?xml version="1.0" encoding="UTF-8"?>
<article codename="XML">
<head>
<filename>Text</filename>
<author>Vasia Pupkin</author>
<email>ya_vasia@bigmir.net</email>
<editor>Chebotarjov A.</editor>
<chars>456</chars>
</head>
<body>
<title>XML parsing</title>
<annotation>It's just an example.</annotation>
<data>
<par>
Body text of article.
</par>
</data>
</body>
</article>
Добавим к каждому элементу идентификатор для введения определенности в случаях, когда есть последовательность однотипных элементов (вообразите, что у вас есть отношение "первый параграф раздела", но сам-то раздел должен быть идентифицирован). Поскольку у текста и
комментариев не может быть дочерних узлов, то для них можно не вводить идентификаторов.
Можно ввести культуру (правило) присвоения имен узлам, можно их просто вынимать из "черного
ящика" - главное, что они должны быть уникальными. Для автоматизации такой операции нам,
очевидно, пригодится SAX. Условно такой документ может выглядеть так (на самом деле его
нет необходимости явно генерировать):
<?xml version="1.0" encoding="UTF-8"?>
<article ID="1" codename="XML">
<head ID="2">
<filename ID="3">file.rtf</filename>
<author ID="4">Vasia Pupkin</author>
<email ID="5">ya_vasia@bigmir.net</email>
<editor ID="6">Chebotarjov A.</editor>
<chars ID="7">456</chars>
</head>
<body ID="8">
<title ID="9">XML parsing</title>
<annotation ID="10">It's just an example.</annotation>
<data ID="11">
<par ID="12">
Body text of article.
</par>
</data>
</body>
</article>
В результате мы можем составить такую таблицу ребер (убедитесь, что по этой таблице можно восстановить исходный документ).
| ORDER |
Источник |
Тип ребра |
Приемник |
Значение |
| 0 |
|
подэлемент |
article.1 |
статья про XML |
| 1 |
article.1 |
атрибут |
codename |
XML |
| 2 |
article.1 |
подэлемент |
head.2 |
|
| 3 |
head.2 |
подэлемент |
filename.3 |
|
| 4 |
filename.3 |
текст |
|
file.rtf |
| 5 |
head.2 |
подэлемент |
author.4 |
|
| 6 |
author.4 |
текст |
|
Vasia Pupkin |
Может быть несколько способов реберного представления - в зависимости от терминологии и предполагаемого использования. Значение текста, например, можно считать и значением, и "приемником" (поскольку это все-таки узел). У нас не показаны также "сестринские" связи - а это может оказаться полезным, если важно искать соседние подэлементы. Иногда будет
выгодно указывать только первый дочерний элемент и потом - связи типа "следующий".
Можно также нумеровать атрибуты и исключить еще один столбец, но поскольку событие "прибыл атрибут" не предусмотрено в SAX, то сам процесс такой нумерации потребует дополнительного кодирования в духе foreach.
Кроме того, не показана алгебра документов - то есть способ учета документов как атомарных величин. Возможно, для этого будет создана отдельная таблица традиционного формата с полями DOC_ID, DOC_NAME, DOC_DESСRIPTION, DOC_LASTMOD и в том же духе.
Как видно, это представление легко укладывается в одну SQL-таблицу и может быть сравнительно прямолинейно восстановлено с использованием SAX. Фактически многие "объектные" базы данных работают именно таким образом, сохраняя документы в виде реберного представления и восстанавливая их в момент загрузки.
Реберное представление позволяет также оптимизировать поиск - особенно если таблица индексирована по искомому полю. Например, очень легко найти элемент (ы) с заданным индексом, именем, значением атрибута, связью и так далее.
Итог
Как можно заключить из вышесказанного - XML не только предоставляет выгоды и удобства, но и требует особого внимания к продуманной архитектуре вашего приложения. При разработке XML-приложений уделяйте больше времени моделированию и меньше кодированию - и тогда у
ваших приложений будет будущее. Чем мощнее технология, тем более серьезные ошибки вы можете
допустить - в этом смысле XML не исключение и не представляет собой ничего нового.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
