Структурные языки, подобные XBRL (Extensible Business Reporting
Language - расширяемый язык бизнес-отчетности), могут
определять структуру финансового отчета, а сами данные могут
быть сохранены как реальный XML-документ. Часто данные
подвергаются дальнейшей обработке с помощью формул,
например, для проверки балансов и получения информации для
финансового анализа. Такая обработка обычно производится в
приложениях, не имеющих отношения к XML, но у людей,
работающих с XML, возникает вопрос: а насколько хорошо язык
XSLT (Extensible Stylesheet Transformation Language -
расширяемый язык преобразования таблиц стилей) мог бы
справиться с данными вычислениями, и какие преимущества это
дает? Использование XSLT для создания данных позволяет
говорить о появлении вычислительного XSLT (Computational
XSLT); этот язык открывает возможности для распространения
финансовых формул в виде набора соответствующих функций
XSLT, которые могут быть прочитаны и выполнены на любом
процессоре XSLT. Автор статьи предлагает не новый стандарт,
а новую роль для языка XSLT любой версии (1.0 или 2.0) или
языка XQuery1.0 (XML Query Language - язык запросов XML),
при этом могут использоваться данные как в формате XBRL, так
и в любом другом XML-формате.
Финансовые отчеты: структура и данные
Элементы финансового отчета (например, оборотные фонды и
основные средства) имеют определенные наименования, смысл
которых не меняется в рамках используемого бухгалтерского
стандарта (например, US-GAAP - generally accepted accounting
principles (общепринятые принципы бухгалтерского учета)).
XBRL определяет элементы с помощью XML-схемы и баз связей,
которые опираются на спецификацию XLink (XML Linking
Language - язык связей XML). Схема определяет элементы и их
типы, а базы связей содержат дополнительную информацию.
Например, если схема определяет элемент по его
идентификационному коду (ID), то презентационная база связей
связывает этот ID с принятым наименованием для
окончательного представления. После общего определения
элементов в реальном документе передаются конкретные
значения, соответствующие той или иной компании в
определенный момент времени. В реальном документе в формате
XBRL такой момент времени и имя компании, соответствующие
значению элемента, называются контекстом значения
элемента.
Формулы
Специалисты по финансовым данным разрабатывают
определенные формулы. Они также должны задать логику работы
с пропущенными данными и другими возникающими затруднениями.
Без этой логики значения формулы не могут быть вычислены
надлежащим образом. Формулы используются для проверки
достоверности данных и их анализа. Существует множество
языков формул (разработанных самими компаниями для своих
нужд или сторонними организациями), которые используются при
работе с финансовыми данными. Но у них у всех существует
общая основа, как следует из документа XBRL Formula
Requirements (Требования к формулам XBRL). В этом
документе проведен анализ требований и на конкретных
примерах демонстрируется, как может работать предлагаемый
язык формул. Эти формулы находятся в вычислительных базах
связей.
XSLT как приложение для обработки формул
При наличии исходных данных в формате XBRL или формате,
определяемом какой-либо другой схемой, вычисления могут
осуществляться с использованием формул, определенных в базах
связей, с помощью XML или иных языков разметки. Приложение
для обработки, которое выдает вычисленные данные, обычно
работает по формулам, написанным не в скрипте XML. Но
процессор XSLT является стандартизированным приложением,
которое может преобразовать исходные данные в формате XML в
вычисленные данные, используя инструкции, доступные для
чтения и написанные на языке XSLT. Таким образом, для того,
чтобы использовать возможность XSLT, необходимо восполнить
одно пропущенное звено - преобразовать набор формул в
XSLT-файл.
Такой файл затем предоставит возможность совместного
использования реализации формул и логики их обработки,
причем эта реализация будет доступна для чтения и выполнения
на любой машине. Например, этот файл может быть предоставлен
вместе с данными (исходными и вычисленными), чтобы
продемонстрировать, как были получены результирующие данные.
Пользователь также может применить эти формулы к своим
собственным данным: в пакетном режиме на сервере или
индивидуально с помощью браузера или приложений для
персонального компьютера. Возможно, главное преимущество
такого подхода заключается в том, что он предлагает
сравнительно прямой путь для перехода от реляционных к
вычисленным данным, при условии, что он используется вместе
с поддержкой операций извлечения и трансформации
(extract-and-transform), основанных на XML (с помощью XSLT),
которую в настоящее время предлагает уже большинство
поставщиков баз данных.
Цели статьи
Обосновав необходимость использования XSLT в вычислениях
для финансовых отчетов, автор предлагает рассмотреть шаги, с
помощью которых формулы схемы превращаются в XSLT-файл, где
каждой формуле ставится в соответствие определенная
XSLT-функция. С помощью этих функций из исходных данных
вычисляются требуемые показатели. На упрощенном примере
будут показаны необходимые компоненты. Затем задача будет
усложнена, поскольку всегда существует необходимость работы
с пропущенными данными. И в заключение автор намеревается
обсудить производительность вычислительного XSLT, опираясь
на собственный опыт использования сотен формул применительно
к тысячам отчетов.
Хотя в практическом примере можно было использовать
XBRL-схемы, базы связей и реальные документы, автор
предпочел объединить и сократить XBRL-схему и базу связей
формул в единую псевдо-схему, которая включает элементы как
исходных, так и вычисленных данных (с формулами). Это было
сделано для краткости и исключения ненужных деталей, чтобы
можно было сосредоточиться на главном. Единственным
элементом контекста этого упрощенного реального
документа является период.
Первоначально эта работа была выполнена с использованием
XSLT 1.0. Затем автор переделал ее с помощью версии XSLT 2.0
для того, чтобы изучить возможности поддержки
последовательностей XPath 2.0, неограниченных структур
данных и регулярных выражений (Regular Expressions) во
второй версии XSLT. Ссылки на XSLT-функции должны
рассматриваться как функции XSLT2.0, шаблоны XSLT 1.0 (или
2.0) или функции XQuery 1.0.
Создание XSLT из формул
Ниже приводится список компонентов, необходимых для
создания XSLT-функций из формул схемы. Список состоит из
файлов с "говорящими" именами. Файлы примеров представлены в
виде исходных кодов и будут обсуждаться чуть дальше, а ниже
объясняется их роль.
- Файл Schema.xml определяет структуру
финансового отчета в терминах исходных и вычисленных
элементов. Вычисленный элемент включает использованную
формулу; эта формула ссылается на другие элементы схемы
(исходные или вычисленные).
- В файле Instance.xml исходным элементам,
определенным в файле schema.xml, присваиваются
конкретные данные. Данные элемента - это одно или более
значений, каждое со своим контекстом (периодом). Этот
файл также содержит контексты.
- Файл Compiler.xslt пишется вручную. Он
преобразует формулы файла schema.xml в XSLT-файл с
именем functions.xslt, где каждая формула становится
эквивалентной XSLT-функцией. Файл назван компилятором
(compiler), потому что можно провести аналогию с
разбором файла schema.xml и генерацией эквивалентных
вызываемых XSLT-функций. В результате, каждый файл
schema.xml будет компилирован в эквивалентный файл
functions.xslt.
Для того чтобы применить формулы, конечному пользователю
нужно, чтобы из файла schema.xml создавался
совместимый с ним файл instance.xml, а также файл
functions.xslt. Функции этих файлов будут
вызываться из их собственных XSLT. В исходных кодах файла
host.xslt показывается, как используются функции
файла functions.xslt.
Взаимодействие этих компонентов показано на рис. 1,
который демонстрирует, что XSLT имеет две четко выраженные
роли во всем процессе: он используется для компиляции при
создании файла functions.xslt, а также для
численных расчетов при последующем использовании этого
файла. Компиляция должна повторяться после любых изменений в
формуле и обычно не имеет временных ограничений. Однако,
осуществление численных расчетов, которые могут выполняться
в приложении для браузера, персонального компьютера или
сервера, должно быть максимально производительным.
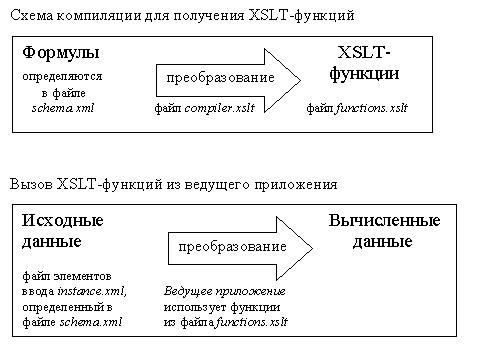
Рис.1. Две роли XSLT: создание и вызов функций
Пример: упрощенное использование вычислительного XSLT 2.0
Упрощение заключается в том, что пропущенные
(несуществующие) данные рассматриваются как данные, значение
которых равно нулю. Файл schema.xml (листинг
1) имеет три исходных элемента и четыре вычисленных.
После преобразования в файл functions.xslt (листинг
2) вычисленный элемент становится элементом <xsl:function>
с тем же именем1. В файле
functions.xslt префикс пространства имен formula
используется для этих функций, автоматически генерируемых из
формул, для того, чтобы отличать их от фиксированных
вспомогательных функций (пространство имен helper),
которые они вызывают (см. ниже). Предполагается, что
исходные данные в файле instance.xml (листинг
3) - это данные для одной компании.
Структура формульной функции в файле functions.xslt
проста: она имеет один параметр context_id, который
является индикатором того периода отчета, который
вычисляется из файла instance.xml. Она содержит
XSLT-переменную для каждого аргумента в формуле элемента и
выдает формулу, вычисленную по прописанной схеме. Например,
выражение formula:F10 - это формульная функция для
следующей операции:
<item id="F10" formula="$F1 + $F2" type="calc"/>
Выражение formula:F10 содержит переменные $F1 и $F2, созданные
следующим образом:
<xsl:variable name="F1" select="helper:get_input_value
( 'F1', $context_id)" as="xs:double"/>
Соответственно, его результатом является:
<xsl:sequence select="$F1 + $F2"/>
А вот более сложный пример:
<item id="F13" formula="if( ($F10 - $F10_prev)
gt 0.01*$F10_prev )
then ($F10 + $F3)
else ($F10)"
type="calc"/>
В соответствующей функции formula:F13 переменной вычисляемого элемента
$F10 присваивается значение путем вызова формульной функции
с идентичным именем, параметром которой является context_id:
<xsl:variable name="F10"
select="formula:F10( $context_id)"
as="xs:double"/>
В определении элемента F13 модификатор _prev в выражении $F10_prev
указывает, что значение должно относиться к предыдущему
контексту. Такие ссылки часто встречаются в финансовых
формулах. Соответствующая переменная в выражении formula:F13
создается следующим образом:
<xsl:variable name="F10_prev"
select="formula:F10(helper:get_
previous($context_id))"
as="xs:double"/>
Здесь функция helper:get_previous(context_id) просто выдает
значение context_id для периода в один год, предшествующего
тому, который был указан.
Если обратиться к исходным кодам, то файл
compiler.xslt (листинг
4) использовался для создания файла functions.xslt
из schema.xml; файл host.xslt (листинг
5) показывает, как вызываются функции в файле
functions.xslt; файл calculated_data.xml (листинг
6) показывает результат, который получается при
преобразовании instance.xml с помощью файла
host.xslt.
Все эти задачи сравнительно простые, а формулы в файле
functions.xslt обладают той же гибкостью, что и
формулы XPath 2.0.
Работа с пропущенными (несуществующими) данными
Иногда данные оказываются недоступными (несуществующими)
для исходных элементов: либо потому, что компания не
сообщила их, либо из-за того, что формуле требуются исходные
данные предыдущего периода, которых нет (такое, например,
неизбежно случается, если требуются данные для периода,
предшествующего самому раннему из тех, для которых есть
данные). Специалистам по финансовым данным необходимо
решить, как их формулы должны обращаться с отсутствующими
данными. Например, логика операций с отсутствующими данными
должна однозначно определять результат следующих выражений:
10 + null; null + null; 10 div null; null
div 10; if (null ne 10) then (null + 20)
else (30); if (25 gt null) ..; if(null = null).., и т.д...
В оставшейся части статьи автор использует бизнес-логику вычисления
формул, принятую в его организации. Бизнес-логика других
организаций может отличаться, но техническая обработка
должна быть такой же.
Практический опыт показывает, что формулы должны иметь
определенный тип (см. ниже), и для каждого типа существует
ограниченное количество допустимых выражений. Эти
ограничения необходимы, если должна применяться логика
обработки отсутствующих данных. Измененная схема -
schema_complex.xml (листинг
7) - имеет элементы следующих четырех типов:
- Тип исходных данных (Input type).
Данные присваиваются элементам этого типа в документе в
формате XBRL.
- Простой тип вычислений (Simple
calculation type). Слово "простой"
означает, что в этом типе отсутствуют операторы
сравнения, а ответом формулы должно быть число.
- Отношение (Ratio). Имеет
форму числителя (numerator) и
знаменателя (denominator), причем
числитель и знаменатель рассматриваются
как под-формулы, имеющие простой тип или тип ввода.
- Условный (Conditional).
Имеет форму если (значение теста истинно), то
вычислять результат по операции formula_if_true, иначе -
по операции formula_if_false [if (test is true) then
return result from formula_if_true else return from
formula_if_false]. Тест имеет следующую форму:
(test_left_hand test_operator test_right_hand).
Под-формулы test_left_hand, test_right_hand,
formula_if_true и formula_if_false имеют
простой тип или тип ввода.
Каждый элемент вычисляемого типа также имеет атрибут
null_eval_rule, который указывает, как вычислять
формулу или под-формулу простого типа в условном типе или
типе "отношение".
Логика работы с отсутствующими данными
Ниже перечислены основные положения этой логики, при
условии, что формулы ограничены вышеназванными типами. В
случае численных расчетов значение отсутствующего аргумента
принимается равным нулю. Читателю не обязательно
концентрироваться на деталях, но стоит обратить внимание на
возрастающую сложность.
- В случае простого типа, если любой аргумент связан с
предыдущим периодом и его значение отсутствует, формула
не выдает ответа независимо от остальных правил.
- В случае простого типа, содержащего выражение
null_eval_rule='null_if_all_null', формула выдает
численный ответ при условии, что есть хотя бы один
аргумент, значение которого известно. В противном случае
формула возвращает нулевое значение.
- В случае простого типа, содержащего выражение
null_eval_rule='null_if_any_null', формула не
выдает ответа при условии, что есть хотя бы один
аргумент, значение которого неизвестно. В противном
случае формула выдает численный ответ.
- В случае элемента типа "отношение" числитель
и знаменатель вычисляются как отдельные формулы
простого типа, имеющие общий элемент null_eval_rule.
Если любой из них выдает пустое значение, то оно
присваивается и всей формуле, в противном случае она
вычисляется.
- В случае элемента условного типа, выражения
test_left_hand и test_right_hand
вычисляются как отдельные формулы простого типа, имеющие
общий элемент null_eval_rule. Если только одно
из них имеет пустое значение, а оператором является
eq (равно) или ne (не равно), результат
теста вычисляется как true operator false (истинно
оператор ложно); в противном случае любое пустое
значение этих выражений рассматривается как равное нулю,
и они сравниваются между собой как величины. После
оценки теста как истинного или ложного общая формула
выдает выражение formula_if_true или
formula_if_false, которые рассматриваются как
формулы простого типа.
Применение логики работы с отсутствующими данными
После преобразования измененной схемы
schema_complex.xml результирующий файл
functions_complex.xslt (листинг
8) имеет много новых элементов для поддержки логики
работы с отсутствующими данными. Во-первых, тип Xschema,
выданный формульной функцией, меняется с xs:double
на xs:double?. Последний допускает пустую
последовательность - аналог пустого значения в XPath 2.0.
Во-вторых, добавляется специальный код, который помогает
присвоить "пустой" статус каждому аргументу и применять
правило(а), позволяющие получить результирующий "пустой"
статус всей функции. В файл functions_complex.xslt
добавлены соответствующие комментарии.
Все это может выглядеть слишком сложным, но любой язык
определения формул должен задавать логику их вычисления в
таком формате, который обрабатывающее приложение способно
проанализировать и применить и который должен быть доступен
для чтения. Например, документ XBRL Formula Requirements
признает необходимость гибкого кодирования такой логики и
предлагает использовать для этого подмножество ECMAScript
или XPath 1.0. Обрабатывающее приложение затем осуществит
компиляцию этого скрипта в свой выполняемый код. Но в
рассматриваемом случае чистого XSLT-подхода формульная
функция в файле functions_complex.xslt просто
использует вспомогательные функции и некоторые
дополнительные коды, находящиеся в том же файле, для
применения вычислительной логики.
Насколько успешно вычислительный XSLT справляется с
реальными финансовыми отчетами?
Как уже объяснялось, скорость стадии компиляции не
является критической, но надо иметь в виду, что даже при
правилах, более сложных, чем изложенные выше, сотни
формульных функций создаются приблизительно в течение 10
секунд. Для компилятора гораздо важнее создать быстрый XSLT.
XSLT-индексы (использующие <xsl:key>) существенно
меняют дело, как, собственно, любое кэширование вызывов
функций в XSLT-процессоре. Например, функция может
вызываться 50 раз с одними и теми же аргументами. Если
результат первого вызова кэширован, следующие 49 вызовов
считываются из кэша. Парсер Saxonica 8.1, используемый в
данном случае, поддерживает кэширование.
Пакет из 8000 реальных документов в формате XML (один
документ - одна компания), каждый из которых содержал данные
для 170 элементов ввода за 15 периодов, был преобразован в
8000 файлов с 336 вычисленными элементами для тех же
периодов. Некоторые формулы обращались к вычисленным
элементам, формулы которых, в свою очередь, также обращались
к вычисленным элементам, и так вплоть до семи уровней
обращения к исходным данным. Вычисление отсутствующих данных
и правила регулирования периодов были более сложными, чем
обсуждаемые в настоящей статье; также применялись пересчет в
годовое исчисление и форматирование. Сорок пять миллионов
вычислений были сделаны в течение семи часов, что хорошо
соответствует ожиданиям автора и сопоставимо с другими
способами обработки. Условия были следующими. Программное
обеспечение: файлы Saxonica 8.1 JAR были встроены в
облегченное приложение Java 1.4; JVM (Java Virtual Machine -
виртуальная машина Java) работала в среде Windows 2000.
Оборудование: персональный компьютер с процессором 3GHz и
тремя гигабайтами оперативной памяти.
Заключение
Вычислительный язык XSLT - это серьезная возможность для
применения формул к данным финансовых отчетов. Файл в
формате вычислительного XSLT может быть создан из
определений формул и способен использовать достаточно
сложную логику вычисления отсутствующих данных для того,
чтобы применять эти формулы. XSLT-файл дает многим
пользователям возможность использования доступных для чтения
и пригодных для любой машины формул и логики их обработки.
Например, такой файл может предоставляться вместе с данными
(исходными и вычисленными) для того, чтобы показать
пользователю, как вычисленные данные были получены, или дать
ему возможность применить эти формулы к своим собственным
данным. Хотя рассмотренный подход и не привязан к каким-либо
стандартам, кроме XSLT (или XQuery 1.0), он может работать с
XBRL-данными. Этот основанный на XML подход также предлагает
прямой путь перехода от данных, находящихся в реляционных
базах, к вычисленным данным, с помощью XML-поддержки
операций извлечения и преобразования (основанных на XSLT),
которая предоставляется основными поставщиками баз данных.
Публикации
1. Сайт XBRL:
www.xbrl.org.
2. Требования к формулам XBRL. Общедоступный рабочий
вариант, принятый 20 апреля 2004 г. (XBRL Formula
Requirements, Public Working DRAFT of Tuesday, 20 April
2004). Доступен по адресу
www.xbrl.org/technical/requirements/Formula-Req-PWD-2004-04-20.pdf.
Примечания:
1
Значение атрибута name у этих элементов
соответствует значению атрибута id в schema.xml (прим.
пер.)



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС