Оптимизация работы протокола ТСР в распределенных сетях. Часть 2
Максим КУЛЬГИН
СЕТИ #11/99
В первой части статьи были рассмотрены основы протокола ТСР, прежде всего — механизм плавающего окна. Вторая часть посвящена основным методам и алгоритмам оптимизации работы протокола, а также способам предотвращения перегрузок в сети.
Стратегии отправления и приема данных
При отсутствии данных, помеченных флагом PSH, протокол TCP на стороне отправителя имеет возможность самостоятельно назначать время передачи. Когда данные передаются модулю протокола ТСР пользовательским приложением, они записываются в передающий буфер. Протокол TCP может создавать отдельные сегменты для каждой группы данных, поступивших от приложения, либо дожидаться накопления большого объема данных и только после этого формировать и отправлять сегменты. Выбор конкретной политики отправки данных всецело зависит от требований к производительности. Если передачи сегментов происходят редко, но при этом пересылаются большие объемы данных, то накладные расходы, связанные с созданием сегмента и его обработкой, оказываются небольшими. Если же передачи осуществляются часто, а объем транспортируемых данных невелик, то система способна обеспечить быструю реакцию на изменения состояния сети.
Когда отсутствуют данные, помеченные флагом PSH, протокол TCP на стороне получателя также может самостоятельно определять время доставки данных пользовательскому приложению. Так, возможны доставка данных при получении сегментов в их исходной последовательности или занесение данных из нескольких сегментов в буфер приема. Как и в предыдущем случае, реальная схема определяется требованиями к производительности. Если данные приходят редко и имеют большие объемы, то приложение получит их не сразу. Если данные поступают часто и малыми порциями, может возникнуть избыточная и обременительная обработка информации протоколом TCP и приложением.
В том случае, когда сегменты поступают в порядке их отсылки по установленному соединению, протокол TCP помещает данные в буфер получения для доставки пользовательскому приложению. Но вполне возможно, что какие-либо сегменты будут поступать c нарушением первоначального порядка следования. Тогда протокол TCP на приемной стороне сможет принимать только те сегменты, которые приходят в порядке отправления (а остальные просто отбрасывать), либо все сегменты, чьи номера зафиксированы в окне получения (вне зависимости от порядка их поступления).
Первый из этих вариантов упрощает реализацию протокола, однако создает дополнительную нагрузку на сеть, так как отправитель, подождав некоторое время, начнет повторно передавать сегменты, которые были успешно получены, но затем отброшены из-за некорректного порядка поступления. Более того, если хотя бы один сегмент потерялся при передаче, приходится повторно посылать все последующие сегменты. При втором варианте количество повторных передач может быть снижено, но зато требуются более сложные алгоритм приема и схема буферизации данных и отслеживания порядка их поступления.
Протокол TCP поддерживает очередь отправленных сегментов, подтверждения о приеме которых еще не поступили. Согласно спецификации протокола сегмент будет передан повторно, если подтверждение не поступит в течение определенного периода. Разные реализации протокола TCP могут поддерживать три стратегии повторной передачи.
«Только первый». Поддерживается один таймер повторной передачи для всей очереди. При получении подтверждения первый сегмент удаляется из очереди повторной передачи и таймер сбрасывается. Если время таймера истекает, повторно передается сегмент из начала очереди и таймер обнуляется.
Пакетная. Также поддерживается один таймер повторной передачи для всей очереди. Когда приходит подтверждение, из очереди повторной передачи удаляются все сегменты и таймер сбрасывается. Если время таймера истекает, повторно передаются все сегменты из очереди и таймер обнуляется.
Индивидуальная. Для каждого сегмента в очереди существует отдельный таймер. При получении подтверждения из очереди повторной передачи удаляется первый сегмент, а соответствующий таймер обнуляется. По истечении времени какого-либо таймера повторно передается только соответствующий сегмент и его таймер сбрасывается.
Первая стратегия повышает эффективность передачи трафика, поскольку повторно передается лишь потерянный сегмент (или тот, чье подтверждение о приеме было потеряно). Однако из-за того, что таймер для второго сегмента в очереди не устанавливается, пока не подтвержден прием первого сегмента, могут возникать некоторые задержки. Индивидуальная стратегия решает эти проблемы ценой более сложной реализации. Использование пакетного режима также снижает вероятность длительных задержек, но способно привести к ненужным повторным передачам.
Реальная эффективность политики повторной передачи зависит от реализуемой схемы приема сегментов на стороне получателя. Если избран подход, при котором принимаются только сегменты, следующие в порядке отправления, то сегменты, поступившие после потерянного, будут отброшены. Такая схема хорошо подходит для пакетной стратегии. Если же получатель принимает все сегменты, независимо от порядка их прибытия, то оптимальными являются стратегии «только первый» и индивидуальная.
При поступлении сегмента протокол TCP на приемной стороне имеет два варианта выбора времени отправки подтверждения.
«Немедленно». Сразу после принятия данных с определенным номером последовательности передается пустой (без данных) сегмент, содержащий соответствующий номер подтверждения.
«С накоплением». Когда данные успешно приняты, отмечается необходимость в подтверждении, но последнее отправляется с очередным исходящим сегментом данных, в котором устанавливается флаг АСК. Во избежание длительных задержек устанавливается таймер окна. Если время таймера истекает до момента отсылки очередного сегмента данных, то отправителю посылается пустой сегмент, содержащий соответствующий номер подтверждения.
Пример реализации механизма SACK
...
TCP: Source Port = 0x04DA
TCP: Destination Port = NETBIOS Session Service
TCP: Sequence Number = 925104 (0xE1DB0)
TCP: Acknowledgement Number = 54857341 (0x3450E7D)
{Подтверждение получения данных до номера в последовательности 54857341}
...
TCP: Options
TCP: Option Nop = 1 (0x1)
TCP: Option Nop = 1 (0x1)
TCP: Timestamps Option
TCP: Option Nop = 1 (0x1)
TCP: Option Nop = 1 (0x1)
TCP: SACK Option
TCP: Option Type = 0x05
TCP: Option Length = 10 (0xA)
TCP: Left Edge of Block = 54858789 (0x3451425)
TCP: Right Edge of Block = 54861685 (0x3451F75)
{Указание на успешно принятые номера в последовательности данных 54858789 — 54861685}
...
Алгоритм немедленной отправки подтверждений проще в реализации и позволяет поддерживать полную информированность протокола TCP на отправляющей стороне, что минимизирует ненужные повторные передачи. В то же время его использование приводит к появлению дополнительных пустых сегментов, служащих исключительно для подтверждения успешного приема. Более того, такой подход повышает загруженность сети. Вполне возможна, например, ситуация, в которой протокол ТСР на приемной стороне получает сегмент и немедленно посылает подтверждение, а приложение вдруг расширяет свое приемное окно, инициируя тем самым передачу пустого сегмента для предоставления дополнительного лимита отправляющей стороне.
Так как описанная стратегия выдачи подтверждений сопряжена с высокими накладными расходами, обычно используется режим работы с накоплением. Следует отметить, что применение этого режима приводит к увеличению нагрузки на получающей стороне и усложняет задачу отправителя по оценке времени обращения сегментов.
Рассмотрим два расширения протокола TCP, используемых в среде Windows NT.
Выборочное подтверждение (TCP Selective Acknowledgement — SACK, RFC 2018). Это расширение сравнительно недавно одобрил консорциум IETF. Оно позволяет подтверждать прием данных не в порядке их поступления, как это было раньше, а выборочно. Подобный подход имеет два главных преимущества.
Во-первых, повышается эффективность повторной передачи сегментов ТСР благодаря сокращению времени выполнения этой процедуры. Обычно протокол TCP использует алгоритм повторной передачи, опираясь на информацию, которую он получает на основе упорядоченных подтверждений. Такой вариант вполне приемлем, однако в случае его применения для восстановления каждого потерянного сегмента требуется примерно один цикл обращения. SACK же позволяет осуществлять в одном цикле повторную передачу сразу нескольких потерянных сегментов.
| Показатель | SackOpts | TcpDelAckTicks | TcpMaxDupAcks |
| Ключ в реестре | Tcpip\Parameters | Tcpip\Parameters\Interfaces\<interface> | Tcpip\Parameters |
| Тип записи | REG_DWORD-Boolean | REG_DWORD-Number | REG_DWORD-Number |
| Границы значений | 0, 1 (False, True) | 0-6 | 1-3 |
| Значение по умолчанию | 1 (True) | 2 (200 мс) | 2 |
Во-вторых, благодаря выборочным подтверждениям протокол TCP точнее оценивает доступную ширину полосы пропускания в условиях нескольких последовательных потерь сегментов и способен обойтись без алгоритма «Медленный старт». SACK играет важную роль в соединениях, в которых используется окно TCP большого размера. Когда работает SACK (а в Windows NT это расширение включено по умолчанию), при потере сегмента или серии сегментов получатель имеет возможность точно проинформировать отправителя о том, какие данные были приняты успешно, и указать на образовавшуюся «прореху» в потоке сегментов. Отправитель может повторно передавать только потерянные данные, а не весь их блок, в состав которого входят и успешно принятые пакеты. Для управления алгоритмом SACK служит параметр SackOpts (столбец 2 табл. 2), определенный в реестре операционной системы Windows NT 5.0.
Врезка иллюстрирует процедуру перехвата сегментов сетевым монитором (Microsoft Network Monitor). В этом примере подтверждено получение данных до номера 54857341, а также данных с номерами от 54858789 до 54861685. Данные с номерами от 54857341 до 54858789 не подтверждены. Таким образом, SACK указывает на то, что данные с номерами от 54857341 до 54858789 были пропущены и отправителю следует повторить их передачу.
Задержанное подтверждение (Delayed Acknowledgement, RFC 1122). В соответствии с этим алгоритмом подтверждения высылаются при условии, что подтверждение приема предыдущего сегмента не отправлялось и после принятия данного сегмента в течение 200 мс не поступил следующий. Значение таймера задержанного подтверждения можно устанавливать с помощью параметра TcpDelAckTicks реестра операционной системы Windows NT 5.0 (столбец 3 табл. 2); впервые он был введен в пакете обновлений Service Pack 4 для версии Windows NT 4.0.
Значения данного параметра могут меняться в диапазоне от 0 до 6, где единица соответствует 100 мс; другими словами, максимальное значение таймера равно 600 мс. Обнуление таймера запрещает использование задержанных подтверждений, что приводит к немедленным отправлениям подтверждений для каждого полученного сегмента.
Таймер повторной передачи
Протокол TCP не формирует явных негативных подтверждений, непосредственно указывающих на нарушение процедуры передачи. Вместо этого он «полагается» исключительно на положительные подтверждения и повторную передачу в тех случаях, когда подтверждение не поступает в течение определенного интервала времени. К повторной передаче сегмента приводит любое из двух событий:
- сегмент был испорчен при передаче, но доставлен получателю. Контрольная сумма, включенная в сегмент, позволяет получателю обнаружить ошибку и отбросить такой сегмент;
- сегмент просто не поступил к получателю.
В обоих случаях посылающая сторона не знает о том, что передача сегмента оказалась неудачной.
Когда сегмент принимается с ошибками либо не поступает вовсе, подтверждение ACK просто не формируется, что однозначно указывает на необходимость повторной передачи. Для принятия решения о повторной передаче используется таймер, работающий с каждым посланным сегментом. Если время таймера истекает до получения ACK для данного сегмента, отправитель должен выполнить повторную передачу.
Регулируемое время этого таймера является важным параметром протокола TCP. Если его значение будет слишком малым, то заметно участятся ненужные повторные передачи, уменьшающие полезную полосу пропускания сети, что вызовет дополнительные повторные передачи и т. д. При очень большом значении реакция протокола на потерю сегмента станет слишком медленной. Таймер должен быть установлен так, чтобы его значение немного превышало время обращения сегмента (Round Trip Time, RTT). Естественно, эта задержка зависит от множества факторов, влияние которых ощутимо даже при постоянной загрузке сети.
Существуют два способа, позволяющих установить время таймера повторной передачи. В первом случае используется фиксированное значение таймера, величина которого основывается на статистических данных, отражающих обычное поведение распределенной сети (т. е. таймер выставляется с небольшим превышением среднего значения RTT). Понятно, что такая стратегия исключает гибкое реагирование на резкие изменения условий работы сети.
Пример реализации алгоритма «Временная метка»
...
TCP: Timestamps Option
TCP: Option Type = Timestamps
TCP: Option Length = 10 (0xA)
TCP: Timestamp = 2525186 (0x268802)
TCP: Reply Timestamp = 1823192 (0x1BD1D8)
...
Второй подход опирается на адаптивную схему, которая также имеет достоинства и недостатки. Предположим, что протокол TCP постоянно отслеживает время получения подтверждений, свидетельствующих о приеме сегментов, и устанавливает значение таймера, основываясь на наблюдаемой задержке. Это значение не может полностью удовлетворять всей совокупности требований к транспортному протоколу по следующим причинам: получение сегмента иногда не подтверждается немедленно (напомним, что привилегия дается задержанным подтверждениям), при повторной передаче сегмента отправитель не знает, относится ли полученный ACK к начальному сегменту или его копии, а кроме того, условия в сети порой меняются внезапно. Эта проблема не имеет исчерпывающего решения: всегда существует некоторая неуверенность в правильности установки значения таймера повторной передачи.
Если в поведении сети произойдут какие-либо изменения, велика вероятность того, что статический таймер повторной передачи неадекватно отреагирует на них: его значение окажется либо слишком малым, либо слишком большим. Поэтому все реализации протокола TCP пытаются оценить текущее время передачи в процессе наблюдения за характером изменения задержек последних посланных сегментов. На основании этой оценки устанавливается значение таймера, которое имеет небольшое превышение над оцененным временем передачи.
| Время | Отправитель | Получатель | Протокол | Флаги | Описание |
| 0.000 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
| 0.521 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
| 1.001 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
| 2.003 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
| 4.007 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
| 8.130 | 10.57.10.32 | 10.57.9.138 | TCP | .A.., | len: 1460, seq: 8043781, ack: 8153124, win: 8760 |
Рассмотрим один из подходов, который учитывает среднее наблюдаемое время для некоторого количества посланных сегментов. Если это время достаточно точно предсказывает будущие задержки, то полученное значение таймера повторной передачи обеспечит очень хорошую производительность сети. Усредненное время можно определить, используя следующее выражение:
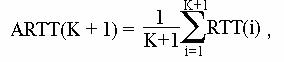
где RTT(i) — наблюдаемое время обращения i-го переданного сегмента, а ARTT(K) — среднее время обращения для первых K сегментов. Для удобства последующего изложения представим приведенное выражение в виде
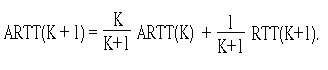
Следует учесть, что каждый параметр в последней формуле имеет равный вес. Однако, как правило, больший вес, или большая степень доверия, присваивается самым последним замерам, поскольку они точнее всего отражают будущее поведение сети. Общий метод предсказания очередного усредненного значения времени обращения на основе предыдущей серии измерений приведен в документе RFC 793. В его основе лежит выражение
![]()
где SRTT(K) — так называемое сглаженное оцененное время обращения (Smoothed Round Trip Time). Нетрудно сравнить это выражение с предыдущим. Используя константу a (0 < a < 1), не зависящую от числа последних наблюдений, можно сформулировать условия, при которых учитываются все последние значения наблюдений, но более ранние наблюдения имеют меньший вес. Эту константу называют фактором сглаживания.
Наименьшее значение константы a придает больший вес самым последним наблюдениям. При a = 0,5 самыми весомыми становятся четыре или пять последних наблюдений, в то время как при a = 0,875 средний вес распределяется между десятью последними наблюдениями (и даже большим их числом). Достоинством использования малого значения константы a является то, что оно позволяет учесть быстрые изменения в наблюдаемых величинах. Недостаток же такого выбора состоит в следующем: при возникновении короткого волнообразного изменения наблюдаемых времен обращения с последующим возвратом к среднему значению происходят резкие изменения вычисляемого усредненного времени обращения.
Как уже упоминалось, таймер повторной передачи должен быть установлен так, чтобы его значение слегка превосходило оцененное время обращения. Для вычисления этого превышения можно использовать формулу
![]()
где RTO (Retransmission Time Оut) — контрольное время повторной передачи (его иногда называют тайм-аутом повторной передачи), а D — некоторая константа. Недостаток этого способа состоит в том, что значение D не пропорционально значению SRTT. Для больших значений SRTT величина константы D относительно невелика. В этом случае флуктуации фактического значения RTT будут приводить к ненужным повторным передачам. При малых значениях SRTT величина D, напротив, начинает доминировать и может вызвать ненужные задержки при повторных передачах потерянных сегментов.
В этой связи документ RFC 793 определяет значение таймера, пропорциональное SRTT, со следующими ограничениями:
![]()
где UBOUND и LBOUND — фиксированные верхняя и нижняя границы значения таймера, а b — константа, называемая фактором изменения задержки. Документ RFC 793 не рекомендует применять фиксированные значения, в нем приводятся следующие диапазоны изменений параметров: a — между 0,8 и 0,9; b— между 1,3 и 2,0.
Временные метки
Для соединений, в которых используются окна большого размера, применяется алгоритм временных меток (TCP Timestamps), описанный в документе RFC 1323. Временные метки помогают проводить точное измерение времени обращения RTT для последующей корректировки значения таймера повторной передачи.
В упомянутом алгоритме определяются два дополнительных поля: Timestamp Value и Timestamp Echo Reply. Первое может быть включено протоколом TCP в любой отправляемый сегмент. При подтверждении успешного приема этого сегмента получатель включает в ответный сегмент поле Timestamp Echo Reply с тем же значением, что было в Timestamp Value. Это позволяет протоколу TCP осуществлять постоянный мониторинг времени обращения сегментов.
Во врезке приведен фрагмент процедуры перехвата сегментов сетевым монитором с полями алгоритма временных меток. В операционной системе Windows NT 5.0 использование временных меток разрешено по умолчанию.
В ОС Windows NT версий 4 и 5 число повторных передач устанавливается алгоритмом, определяющим поведение протокола TCP. Протокол TCP запускает таймер в момент передачи сегмента протоколу IP. Для новых соединений таймер инициируется со значением 3 с. При каждой повторной отправке сегмента начальное значение таймера увеличивается на величину, указанную в параметре TcpMaxConnect Retransmissions реестра ОС Windows NT (значение по умолчанию для NT 5.0 равно двум, а для NT 4.0 — трем). Для действующих соединений управление числом попыток повторной передачи осуществляется при помощи параметра TcpMaxDataRetransmissions (значение по умолчанию равно пяти), описанного в реестре Windows NT.
В целях оптимизации параметров соединения таймер повторной передачи может корректироваться «на лету» с использованием величины SRTT. В результате протокол TCP самонастраивается с учетом задержек на данном соединении и других факторов работы сети. Соединения TCP, устанавливаемые в каналах с большой задержкой, требуют большего начального значения таймера повторной передачи, чем соединения в быстрых каналах связи.
Приведем пример работы сетевого монитора, использующего алгоритм повторной передачи в сети Ethernet (см. врезку). В середине процесса передачи большого файла по протоколу FTP получатель был отключен от сети. Так как значение SRTT для данного соединения крайне мало, то первая повторная передача произойдет примерно через 0,5 с. Затем значение таймера будет удваиваться после каждой повторной передачи. Если после пяти повторных передач подтверждения не поступают, то соединение разрывается.
Контрольное время RTO, которое используется отправителем для повторной передачи потерянного сегмента, на практике может заметно превосходить реальное время обращения RTT. На величину этого превышения влияют следующие причины.
- RTO вычисляется на основе предсказания RTT, которое было спрогнозировано, исходя из значения предыдущего RTT. Но если задержки в сети флуктуируют, то спрогнозированное RTT может значительно превзойти реальное.
- Если задержки на стороне получателя изменяются, то и в этом случае точность оценки RTT невысока.
- Получатель подтверждает получение не каждого сегмента, а их множества, причем подтверждение посылается при передаче ответных данных. При таком поведении получателя невозможно точно определить RTT, не прибегая к специальным методам.
Понятно, что в случае завышенного RTO и потери сегментов протокол TCP становится инертным при осуществлении повторной передачи. Если протокол на стороне получателя использует правило «прием в порядке отправления», это может привести к потере множества сегментов. Даже в более благоприятном случае, когда получатель принимает все указанные в окне отправления сегменты, медленная повторная передача также способна вызвать проблемы.
Поясним сказанное на примере. Предположим, что станция А передала последовательность сегментов, первый из которых был потерян. До тех пор, пока окно отправления станции А не обнулится и RTO не закончится, эта станция будет продолжать передавать сегменты, не дожидаясь получения подтверждений на ранее отосланные. Станция Б получила все сегменты за исключением первого. Ей надлежит помещать все принимаемые сегменты в буфер, пока не поступит копия потерянного сегмента. Более того, станция Б не может отправить данные приложению и тем самым очистить свой буфер до поступления этой копии. Если повторная передача потерянного сегмента по каким-то причинам сильно задержится, то после заполнения буфера станция Б начнет отбрасывать новые входящие сегменты.
Чтобы уменьшить негативные последствия описанной выше ситуации, был предложен алгоритм быстрой повторной передачи (Fast Retransmission), который повышает производительность сети при неоптимальном выборе RTO. Этот алгоритм определяет следующие правила работы протокола TCP. Когда сегмент поступает на приемную сторону не в порядке отправления, немедленно формируются подтверждения о приеме последнего сегмента, пришедшего в порядке отправления, и всех последующих. Подтверждения будут отсылаться до тех пор, пока не поступит копия пропущенного сегмента. После этого протокол перейдет в режим отсылки накопленных подтверждений о приеме всех сегментов, полученных в порядке отправления.
Когда отправитель получает двойное подтверждение о получении одного из сегментов (поступившего последним в порядке отправления), он способен интерпретировать это событие двояко: либо нарушена последовательность получения (по разным причинам), либо произошла потеря сегмента. В первом случае сегмент все же может поступить к получателю, и без повторной передачи удастся обойтись. Во втором случае двойное подтверждение указывает на то, что, возможно, понадобится отослать копию сегмента. Для окончательного принятия решения об отсылке копии отправитель должен получить три дополнительных подтверждения о получении одного и того же сегмента (т. е. всего четыре подтверждения). В этом случае, не дожидаясь срабатывания таймера повторной передачи, он передает в сеть копию потерянного сегмента.

Рис.9 Быстрая повторная передача
На рис. 9 показано, как реализуется алгоритм быстрой повторной передачи. Станция А отсылает последовательность сегментов с 200 байтами данных в каждом. Предположим, что сегмент 1201 был потерян, но станция А не реагирует на это событие до истечения времени RTO. Она будет посылать новые сегменты до тех пор, пока не закроется ее окно отсылки. Станция Б получает сегмент 1001 (с байтами от 1001 до 1200) и высылает подтверждение с номером 1201. Затем к ней поступает сегмент 1401 (байты от 1401 до 1600). Поскольку он нарушает последовательность отсылки, станция Б повторяет отправку подтверждения с номером 1201 и затем станет высылать подтверждение с этим номером при поступлении каждого нового сегмента. Процесс будет продолжаться до получения копии сегмента 1201. За время, прошедшее между отправкой сегмента 1201 и получением четвертого подтверждения с тем же номером, станция А успеет отправить семь сегментов. Получив четвертое подтверждение с номером 1201, она немедленно повторит последовательность сегментов, начиная с данного номера.
По умолчанию в Windows NT 5.0 сегмент посылается повторно, если поступают три подтверждения с одинаковым номером, который в последовательности отстает от текущего. Управление осуществляется с помощью параметра TcpMaxDupAcks, описанного в реестре операционной системы (столбец 4 табл. 2). Этот параметр определяет число двойных подтверждений с одним номером, которые должны быть получены, прежде чем начнет выполняться алгоритм быстрой повторной передачи.
Контроль за перегрузками
В сетях IP контроль за перегрузками реализовать достаточно сложно.
Во-первых, протокол IP не ориентирован на установление соединения. Он не обеспечивает обнаружение состояний перегрузки, поэтому не может быть использован для контроля за ними.
Во-вторых, хотя протокол TCP и осуществляет управление потоком, он обнаруживает перегрузку в сети лишь по косвенным признакам. Более того, поскольку задержки в распределенных сетях постоянно изменяются и могут быть очень большими, то информация, полученная на основании косвенных признаков, не является достоверной.
В-третьих, не существует распределенного алгоритма для связывания различных реализаций протокола TCP: ПО протоколов TCP, запущенное на разных компьютерах, не способно взаимодействовать для поддержания определенных характеристик общего потока. На практике приложения ведут себя весьма «эгоистично» по отношению к свободным ресурсам канала.
Сообщение «Подавление источника» (Source Quench) протокола ICMP можно рассматривать как грубый инструмент сдерживания потоков, генерируемых отправителем, но его нельзя причислить к эффективным методам контроля за перегрузками. На протокол RSVP удается возложить функции контроля за перегрузками, однако его широкого распространения стоит ожидать только в будущем (пусть и не очень отдаленном).
Протокол TCP может влиять на загрузку сети, управляя потоками данных с помощью рассмотренных выше методов, но без принятия специальных мер ему сложно поддерживать загрузку каналов связи на оптимальном уровне. Практически во всех современных реализациях протокола применяются алгоритмы, предотвращающие возникновение перегрузок в сети. К ним относятся алгоритмы «Медленный старт» (Slow Start) и предотвращения перегрузок (Congestion Avoidance, RFC 1122), динамическое изменение окна при перегрузке, быстрая повторная передача и быстрое восстановление.
«Медленный старт»
Казалось бы, чем больший размер окна определен отправителем, тем больше сегментов он успеет отослать до момента получения очередного подтверждения. Но на практике все происходит совсем иначе. В установившемся режиме передачи данных скорость отправки сегментов регулируется за счет автосинхронизации протокола. Гораздо сложнее выбрать такие начальную скорость передачи данных (сразу же после создания соединения) и алгоритм ее повышения, которые позволяют в одночасье не заполнить своими сегментами весь канал связи. Решить задачу можно двумя способами.
Первый состоит в том, что отправитель начинает посылать данные, имея окно отсылки относительно большого размера, и постепенно увеличивает этот размер до такого значения, которое оптимально для стационарного режима передачи. Однако всегда существует определенный риск заполнения распределенной сети множеством сегментов до того момента, когда отправитель поймет, что он посылает данные со слишком большой скоростью. Очевидно, что основной недостаток этого способа — возможность изначального выбора слишком большого окна отсылки.
Второй способ заключается в использовании сразу после формирования соединения минимального размера окна отсылки, который ни при каких обстоятельствах не вызовет перегрузку сети. «Изюминка» этого подхода — наращивание размера окна отсылки с помощью алгоритма «Медленный старт».
В протоколе TCP применяется новое окно, окно перегрузки, размер которого измеряется не в байтах, а в количестве сегментов. В любой момент скорость передачи данных протоколом TCP определяется следующим образом:
AWND = min[CREDIT, CWND].
Здесь AWND — разрешенный размер окна передачи в сегментах, иначе говоря — число сегментов, которое протоколу TCP разрешено отправить в данный момент без получения подтверждений об их успешном приеме; CWND — размер окна перегрузки в сегментах, используемого протоколом TCP в начальный период работы и позволяющего снизить скорость передачи данных при возникновении перегрузки; CREDIT — неиспользуемый на данный момент лимит отсылки сегментов, который был выдан в самых последних подтверждениях.
При создании нового соединения TCP устанавливает окно перегрузки CWND равным единице. Это означает, что отправитель может послать только один сегмент и должен дождаться подтверждения о его успешном приеме, прежде чем отправить следующий сегмент. Каждый раз, когда поступает подтверждение, значение окна CWND увеличивается на единицу. Так происходит до тех пор, пока размер данного окна не достигнет максимального значения.
Поскольку отправитель расширяет свое окно отсылки только по мере прибытия подтверждений, процедура «Медленный старт» гарантирует, что в распределенной сети, даже если она работает на пределе своих возможностей, не окажется слишком много сегментов. Таким образом, протокол ТСР учитывает текущую загруженность канала связи.
Описанный алгоритм правильнее было бы назвать «Экспоненциальным стартом», так как на самом деле размер окна CWND увеличивается в соответствии с показательной функцией. Получив первое подтверждение, протокол TCP увеличивает размер окна CWND в два раза и посылает сразу два сегмента. После этого окно CWND увеличивается на единицу для каждого приходящего подтверждения. Следовательно, получив подтверждение о получении двух последних отосланных сегментов, отправитель может послать уже четыре сегмента, а дождавшись подтверждений об их приеме, отправить восемь сегментов и т. д.
Рис.10 Динамическое изменение окна перегрузки
Сказанное иллюстрирует рис. 10. В этом примере станция А посылает сегмент размером 100 байт и по истечении приблизительно четырехкратного времени обращения RTT получает возможность заполнить канал связи непрерывным потоком своих сегментов.
Алгоритм «Медленный старт» достаточно эффективен при установлении соединения. Он позволяет протоколу TCP на стороне отправителя быстро определить оптимальный размер окна для данного соединения. Но что делать, если, несмотря на принятые меры, перегрузка все-таки возникла?
Предположим, что устанавливается соединение с «Медленным стартом» и прежде чем увеличивающийся размер окна перегрузки CWND достигает лимита, выделенного отправителю другой стороной, происходит потеря сегмента. Этот факт может свидетельствовать о перегруженности сети, однако данных, позволяющих оценить серьезность возникшей ситуации, практически не существует. А раз так, то самым очевидным решением будет сброс размера окна перегрузки CWND до первоначального единичного значения и повторный запуск процедуры «Медленный старт».
Подобная стратегия может показаться вполне приемлемой, но, к сожалению, только на первый взгляд. Давно не требует доказательств тот факт, что перегрузить сеть легко, но восстановить ее нормальное функционирование сложно. Иными словами, после возникновения перегрузки для восстановления рабочих параметров сети могут потребоваться достаточно длительное время и значительные усилия администратора и участников сетевого обмена. Следовательно, при экспоненциальном росте размера окна перегрузки CWND (после восстановления единичного значения) его величина способна довольно быстро снова достичь максимума, хотя к этому времени нормальные параметры сети еще не будут восстановлены. Поэтому повторный «Медленный старт» не облегчит, а, наоборот, усложнит процесс восстановления.
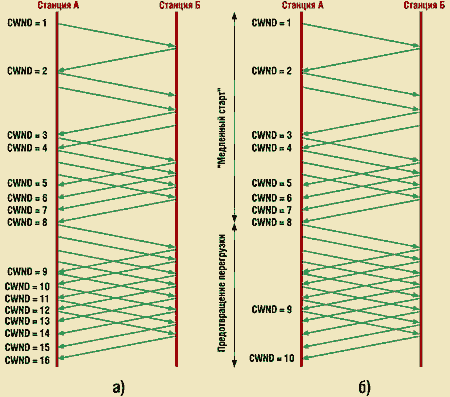
Рис.11 «Медленный старт» с линейным ростом окна перегрузки: а — заканчивающийся потерей сегмента; б — с предотвращением перегрузки
Для разрешения указанной проблемы был предложен алгоритм «Медленный старт» с линейным ростом размера окна перегрузки CWND. В случае его применения при возникновении перегрузки в сети выполняются следующие действия.
- Значение переменной SSTHREST (граница «Медленного старта») устанавливается равным половине текущего размера окна перегрузки: SSTHREST = CWND/2.
- Размер окна перегрузки CWND определяется равным единице, и процедура «Медленного старта» выполняется до тех пор, пока размер окна CWND не сравняется с установленным значением переменной SSTHREST (шаг 1). В этой фазе размер окна CWND будет увеличиваться на единицу после получения подтверждения о приеме каждого посланного сегмента.
- Если размер окна CWND превысил значение переменной SSTHREST, то его следует увеличивать на единицу каждый раз по истечении времени обращения сегмента RTT.
Рис.12 Временная диаграмма для алгоритмов «Медленный старт» и предотвращения перегрузок
Модифицированный вариант процедуры «Медленный старт» показан на рис. 11. При этом на рис. 11,а отображена динамика роста размера окна перегрузки, аналогичная представленной на рис. 10, только в данном случае последний сегмент потерян. Рис. 11,б иллюстрирует реакцию протокола на потерю сегмента. Значение переменной SSTHREST устанавливается равным восьми. До тех пор, пока размер окна перегрузки не достигнет этой величины, оно растет по экспоненте, а после прохождения указанного рубежа увеличивается линейно.
На рис. 12 окно CWND шириной восемь сегментов задает граничное значение. И если для достижения тайм-аута здесь понадобилось четыре времени обращения RTT, то для повторного вхождения в этот режим потребуется уже одиннадцатикратное время RTT.
* * *
Мы рассмотрели далеко не все алгоритмы и технологии, позволяющие оптимизировать протокол ТСР. Тем не менее автор надеется, что использование даже указанных методов будет способствовать более уверенной работе сетевых администраторов.
<<< ЧАСТЬ 1
ОБ АВТОРЕ
С Максимом Кульгиным можно связаться по электронной почте: mk@mail.admiral.ru.