1999 г
Профессиональный поиск в Интернете: полнота, достоверность, скорость.
Опубликовано в журнале КомпьютерПресс (www.cpress.ru) N 7(1999)
Михаил Талантов
Этой статьей мы начинаем небольшую серию публикаций, связанных с вопросом поиска информации в Интернете. Интерес к нему не ослабевает на протяжении всего времени существования Сети. Однако наш угол зрения на проблему будет несколько нетрадиционным - речь пойдет о профессиональном поиске. Хотелось бы избежать пафосного звучания слова "профессиональный". Оно лишь подчеркивает тот факт, что люди, для которых поиск информации стал частью служебных обязанностей, сталкиваются с проблемами, не свойственными эпизодическому, "любительскому" поиску. Их естественным желанием становится преодолеть эти проблемы и выработать новые результативные подходы к решению поисковых задач.
За последние годы развития Интернет-технологий в мире и в России произошло немало положительных перемен. Формирование позитивного общественного мнения о полезности Сети, расширение ее технических возможностей и географии подключения пользователей стимулировали стремительный рост информационной базы Интернета и, как следствие, становление новых и развитие старых поисковых сервисов. Тем не менее эти события явились лишь фоном, на котором произошел главный перелом - в сознании руководителей среднего и высшего звена как коммерческих организаций, так и государственных учреждений. Стало понятно, что своевременное получение информации из Сети способно приносить авторитет, деньги и стабильность положения ее потребителям. Автору этой статьи, которому в течение нескольких лет приходилось читать и поддерживать на современном уровне курс по поиску информации в Интернете, судьба предоставила уникальную возможность. Немало учебного времени ему пришлось провести с десятками людей, для которых решение поисковых задач стало профессиональной деятельностью. Общение с ними, безусловно, обогатило личный опыт автора, и до какой-то степени уполномочило говорить о самой проблеме от их имени.
Черты, присущие профессиональному поиску
Итак, в отличие от ситуации, когда вы что-либо ищите для себя, профессиональный поиск предполагает исполнение некоторого заказа, с вытекающими отсюда обязательствами перед заказчиком. Эти обязательства и являются источником трех основных требований:
- контроль полноты охвата ресурсов;
- контроль достоверности информации, полученной из Сети;
- высокая скорость проведения поиска;
Так, если вы выступаете в роли заказчика, то вправе потребовать от поисковика помимо собственно результатов, еще и некоторых гарантий по указанным выше пунктам. Такие гарантии, безусловно, может дать лишь человек, неплохо осведомленный о тонкостях распределения и движения информационных потоков в Интернете.
Целью настоящей и ближайших публикаций станет обсуждение тех возможностей, которыми располагает поисковик, чтобы добиться оптимальных показателей по полноте, достоверности и скорости выполнения поисковых работ. Попробуем теперь более предметно обозначить существующие проблемы
Контроль полноты охвата ресурсов является закономерным требованием, если вы решаете задачу, противоположную той, что звучит как "найти хоть что-нибудь".
Полномасштабный сбор информации из Интернета по какому-либо вопросу во многих случаях выводит поисковика за пределы широко освоенного Web-пространства, в лоно telnet-доступных баз данных, региональных телеконференций и других хранилищ информации. Знание всех основных существующих на сегодняшний день типов ресурсов Сети, понимание технической и тематической специфики их информационного наполнения и особенностей доступа становится необходимым условием успешного планирования и проведения поисковых работ.
Контроль достоверности информации, полученной из Сети в результате поиска, разумеется, может производиться разными средствами. Кратко остановимся здесь на возможностях, которые предоставляет сама Сеть. Так, традиционными способами проверки являются локализация источников информации, альтернативных данному; сверка фактического материала, установление частоты его использования другими источниками; выяснение статуса документа и рейтинга узла, на котором он находится средствами поисковых систем; получение информации о компетентности и статусе автора материала с помощью специальных поисковых сервисов; анализ отдельных элементов организации узла с целью оценки квалификации специалистов, его поддерживающих и другие.
Скорость проведения поиска в Сети, если не принимать во внимание технические характеристики подключения пользователя, зависит в основном от двух факторов. Это грамотное планирование поисковой процедуры и навыки работы с ресурсом выбранного типа. Под составлением плана поисковых работ понимается выбор поисковых сервисов и инструментов, отвечающих специфике задачи и, что крайне важно, последовательности их применения в зависимости от ожидаемой результативности. После получения доступа к соответствующему ресурсу на передний край выдвигается умение быстро разобраться в его структуре и способах навигации. Моторика выполнения действий, умелое совмещение поисковых средств и возможностей обработки информации локальной клиентской программы и сервера для поисковика являются необходимыми навыками.
Материал этой статьи будет посвящен в основном вопросу полноты проводимого поиска.
Контроль полноты охвата ресурсов. Типы ресурсов Интернет.
Большинство пользователей, пришедших в Интернет за последние один-два года отождествляют его со Всемирной Паутиной WWW. И дело даже не в том, что им ничего неизвестно о существовании в мультипротокольной среде Сети ресурсов других типов. Как правило, эти сведения воспринимаются ими скорее как признак эрудиции, чем как практически полезная вещь. Действительно, информационный объем Web-пространства удовлетворяет многих пользователей. Однако, как только поиск ставится на профессиональную основу и заставляет нести ответственность за выполненную работу контроль за полнотой охвата ресурсов выдвигается на передний план. Можете ли вы гарантировать, что эксперт, выполнивший поисковые работы после вас, не обнаружит в Сети ничего реально значимого по заданному вопросу, что уже находилось там на момент ваших действий? Автору известен случай, когда сведения, найденные в нужный момент в группах новостей телеконференций до какой-то степени изменили судьбу целой компании, увеличив на порядок доход от планируемой накануне сделки.
Так или иначе, сегодня информация в Интернете оказывается доступной из источников разного типа. Планировать поиск без полного представления об их спектре и особенностях функционирования невозможно. Перечень основных типов ресурсов, который можно использовать как карту при планировании поисковой процедуры, приведен на рис.1. Фактически вопрос ставится более широко - об основных способах представления, передачи и обработки информации в Сети.
| Основные информационные и коммуникационные ресурсы Интернета |
|---|
- электронная почта и почтовые роботы;
- глобальная система телеконференций Usenet, региональные и специализированные телеконференции;
- списки рассылки;
- он-лайновые средства коммуникации пользователей;
- системы поиска людей и организаций;
- базы данных Hytelnet;
- система файловых архивов FTP, системы поиска в FTP-архивах глобального и регионального охвата;
- базы данных Gopher и поисковая система Veronica;
- гипертекстовая информационная система World Wide Web (WWW);
- каталоги ресурсов - глобальные, локальные, специализированные (в среде WWW);
- поисковые машины, или автоматические индексы - глобальные, локальные, специализированные (в среде WWW);
- баннерные системы (в среде WWW);
- активные информационные каналы (в среде WWW);
|
Рис.1. Основные информационные и коммуникационные ресурсы Интернета
Особенности доступа к ресурсам указанного типа обсуждаются во многих руководствах. Полезный материал на этот счет содержится также во втором номере журнала КомпьютерПресс за этот год. Ограничимся здесь краткой характеристикой каждого типа, акцентируя внимание на той нагрузке, которую может нести на себе ресурс при проведении поиска в Сети.
Электронная почта и почтовые роботы. Адрес электронной почты отдельного лица или организации традиционно используются для идентификации владельца. В коммуникационных ресурсах Сети - он-лайновых средствах коммуникации пользователей и системе телеконференций нередко он оказывается необходимым атрибутом каждого участника. Специальная URL-схема mailto позволяет вставлять в Web-страницу гиперссылку на е-mail, автоматически открывающую почтового клиента. В этом виде она широко применяется в Паутине. Сами адреса при этом свободно индексируются поисковыми системами и доступны для поиска через поисковые машины общего назначения. AltaVista, например, показывает, что адреса электронной почты встречаются почти на 100 миллионах Web-страниц из 150 миллионов заиндексированных ей документов.
Адреса е-mail активно накапливаются и в специальных системах поиска людей и организаций, о которых пойдет речь ниже. Серьезное неудобство для поиска по e-mail составляет то, что при получении адреса допускается регистрации пользователя под псевдонимом. Эта практика особенно широко распространена на серверах, предоствляющих бесплатные почтовые ящики.
Почтовые роботы - это специальные программы, способные отвечать определенными действиями на команды, поступающие им по электронной почте. Их основное назначение -пересылка данных по запросу в случае, когда те не доступны иным способом, а также как альтернатива работы в режиме on-line с каким-либо из известных ресурсов, например, ftp-архивами. Адрес почтового робота имеет обычный формат, например, mailserv@turbo.nsk.su (файловый сервер Новосибирского узла TURBO). Справка о перечне допустимых команд обычно высылается роботами на адрес пользователя в ответ на сообщение с пустым полем subject и единственным словом help, набранном в теле сообщения с первой позиции. При поиске почтовые роботы обычно используются лишь как посредники при получении информации. Иногда приходится сталкиваться с тем, что они оказываются единственным средством получения нужных сведений.
Глобальная система телеконференций Usenet, региональные и специализированные телеконференции. Система построена по принципу электронных досок объявлений, когда пользователь может разместить свою информацию в одной из тематических групп новостей. Затем эта информация передается пользователям, которые подписаны на данную группу. Полное число групп новостей Usenet превышает 20 тысяч и сведения о них можно найти, например, на Yahoo. Все они одновременно не поддерживаются ни одним сервером, так что труднее бывает отыскать не название соответствующей группы, а сервер телеконференций, с которого ее можно загрузить. Usenet - ключевое слово именно для глобальной системы телеконференций. Региональные и специализированные системы также имеют распространение. Ресурс наиболее значим для быстрого накопления информации по узкому вопросу, а при поиске - чаще для получения частной, неофициальной информации.
Несколько примеров из практики. Один из референтов получил задание обеспечить "техническую" сторону пребывания делегации российской компании в Лондоне. Стандартный набор сведений, необходимых в этом случае - транспорт, отель, погода, последние городские новости, а также личные пожелания участников командировки. Большая часть информации была взята с Web-узлов, локализованных с помощью поисковых систем Yahoo и AltaVista. Тем не менее на ряд частных вопросов, таких как рента автомобиля и отдельные маршруты городского транспорта Лондона, ответов в Web-пространстве не существовало. С помощью сервера Deja News (http://wmod.dejanews.com), являющимся Web-шлюзом к системе телеконференций, референт разыскал две британские региональные группы новостей - uk.transport.london и uk.local.london. Благодаря обаянию, с которым он изложил свою просьбу, вся необходимая информация была получена в течение одного дня.
Еще один поисковик столкнулся с проблемами, возникшими у офис-менеджера при конвертировании документов в текстовом процессоре Microsoft Word97. Автор посоветовал ему обратиться на сервер телеконференций msnews.microsoft.com компании Microsoft и задать при организации подписки поиск русскоязычной группы новостей по ключевому слову "word"в ее названии. Ответ на все вопросы был получен в течение двух дней.
Списки рассылки подразумевают более или менее систематическую рассылку собщений информации по электронной почте. Если пользователь сам может поместить информацию в список рассылки, то это начинает напоминать систему телеконференции, однако не требует специального клиента. Небольших по охвату адресов узкоспециальных или рекламных списков рассылки в Сети насчитывается огромное количество. Здесь стоит обратить внимание на те, авторитет которых получил международное признание. Внушительная коллекция почтовых списков, где их несколько тысяч, собрана на узле http://www.NeoSoft.com/internet/paml/. Там же присутствуют указатели на другие списки списков. По адресу http://www.relc.com/tech/all/list.html.ru можно найти страницу, содержащую перечень наиболее известных российских списков рассылки. Если не говорить о каких-то специальных интересах, то они необходимы поисковику, главным образом, для того, чтобы быть к курсе последних событий, происходящих в жизни Интернета,. Владение сетевой лексикой по широкому спектру тем и осведомленность о крупнейших проектах, реализуемых в Сети, которые можно почерпнуть из списков рассылки, позволяют более результативно строить поисковые запросы.
Он-лайновые средства коммуникации пользователей (chat, ICQ и другие) предполагают возможность обмена информацией между двумя или большим количеством пользователей Сети в режиме реального времени через посредство специального чат-сервера . Частью такого обмена может становиться текстовый диалог, передача графики прямо в процессе ее создания, голосовая и видео связь, обмен файлами. Долгое время ресурсы этого типа крайне редко использовались в решении поиковых задач, однако ситуацию изменило появление в 1996 году нового сервиса этого типа, а именно службы ICQ, известной среди российских пользователей как "Аська" (http://www.icq.com). В отличие от существовавших ранее чатов, где регистрация участников, как правило, носила анонимный характер и действовала лишь на протяжении сеанса связи, разработчики ICQ предложили каждому пользователю регистрационный номер-идентификатор, который сохранялся бы за ним постоянно. Это решение имело грандиозные последствия в области компьютерного общения людей. Уникальный ICQ-номер грозит появиться на визитных карточках рядом с телефоном, адресом электронной почты и домашней страницей. При поиске людей и организаций можно с успехом использовать поисковую службу ICQ, которая становится доступной сразу после установки ICQ-клиента на компьютер.
Еще несколько слов о чат-серверах. Как правило, некоторый их перечень уже зашит в используемую клиентскую программу, как, например, в программе Microsoft NetMeeting.
В регистрационных списках чатов обычно присутсвуют сведения о месте проживания участников, и они редко указываются неверно. Автора этой статьи чат-ресурсы даже в своем анонимном варианте не раз привлекали тем, что позволяли получить информацию из первых рук от представителей конкретного государства, региона и города планеты.
Системы поиска людей и организаций в современной Сети характеризуются двумя важными моментами: большинство этих ресурсов уже перенесено на Web-сервера и все более широкое присутствие получает в них информация о людях и организациях, которые не имеют прямого или вообще никакого отношения к Интернету. С последним утверждением связаны известные факты появления в Сети телефонных, адресных и других баз данных как отдельных организаций, так и целых регионов. Тем не менее такой чисто сетевой идентификатор пользователя как адрес e-mail остается доминирующим поисковым атрибутом для многих сервисов этого типа. Источником пополнения их баз данных становятся материалы телеконференций, Web-сервера, а также самостоятельная регистрация пользователей. К ним добавляются системы, специализирующиеся на поиске, например, по номеру ICQ (см. выше) или домашних страниц пользователей (служба Ahoy!, URL http://www.cs.washington.edu/research/ahoy/). Наряду c переориентированием сервисов под WWW в Сети продолжает работать одна из самых старых поисковых служб подобного типа- Whois, доступная по протоколу telnet с сервера whois.internic.net после входа по login: whois.
Часто возникают попытки выяснить рейтинг поисковых сервисов этого назначения. Так, по результатам исследований журнала PC Magazin (http://www.zdnet.com/pcmag) наибольшей популярностью в Сети среди пользователей Европы и Северной Америки пользуется служба поиска адресов электронной почты Four11 (http://www.four11.com), расположенная в портале Yahoo. Однако практика показывает, что начало поиска именно с нее совершенно не гарантирует успеха. Все эти службы имеют один серьезный недостаток - они не представляют собой единую кем-либо администрируемую систему, а являются лишь хаотически с точки зрения стороннего наблюдателя пополняемым набором информационных узлов. Следствием этого является то, что грамотно спланировать поисковую процедуру и расставить приоритеты в поиске отдельного лица становится крайне сложно. В некоторых случаях намного эффективней прибегнуть к поиску человека по его следам в Сети - публикациям, месту службы и т.п. с использованием поисковых систем общего назначения.
Базы данных Hytelnet, с доступные по протоколу telnet в ряде случаев представляют собой совершенно уникальную информацию, прежде всего по библиотечным каталогам европейских и американских университетов, а также государственных учреждений. Наиболее внушительный перечень баз данных этого типа, превышающий 1600 единиц можно найти на Web-сервере по адресу http://www.lights.com/hytelnet/. Каждая из них обладает оригинальной системой навигации и поиска, реализуемой через команды, которые вводятся с клавиатуры в алфавитно-цифровом режиме. Пример подобного интерфейса, с которым не знакомо большинство нынешних пользователей Сети приведен на рис.2.
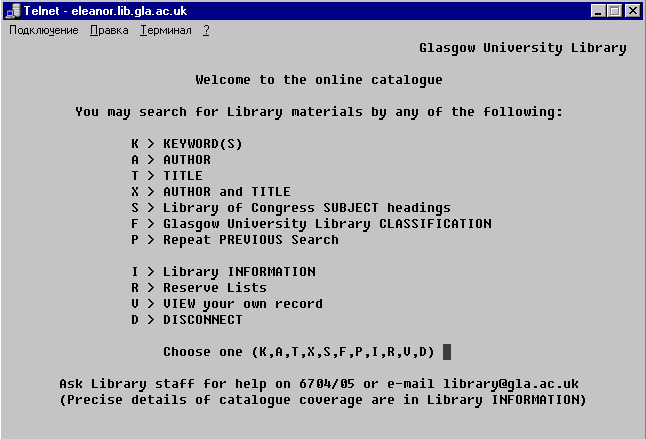
Рис.2. Пример интерфейса, доступной по протоколу telnet базы данных библиотеки Glasgow University (UK).
Система файловых архивов FTP, системы поиска в FTP-архивах глобального и регионального охвата. Ресурсы этого типа не отступили так безоговорочно под натиском Web-технологий, как большинство остальных. Одна из причин в огромном количестве информации, накопленной в ftp-архивах за десятилетия эксплуатации компьютерных систем, которая по-прежнему ценна для специалистов. Социального заказа на ее перенос в Web-пространство в полном объеме не существует. Другая причина кроется в простоте доступа, навигации и передачи файлов по ftp. Так или иначе сегодня ftp-ресурсы востребованы и даже характеризуются развитием не только своей единственной глобальной поисковой системы Archie (адрес одного из стабильно доступных Web-шлюзов к ней - http://ftpsearch.ntnu.no), но и региональных систем, в частности российской - http://ftpsearch.city.ru , охватывающей более 2000 серверов.
Ftp-архивы - это в первую очередь источники программного обеспечения, успешно конкурирующие с Web-узлами, которые специализируются на продаже и представлении коллекций программ. В отличие от Web-узлов на них гораздо чаще можно столкнуться с нарушением авторских прав в виде пиратских копий программ и отдельных материалов, продаваемых на других узлах за деньги. Как следствие теневых сторон ftp-сервиса- опасность заражения вирусом из непроверенного источника. Поиски какой же информации стоит начинать с поисковой системы ftp? Универсальный ответ прост: поскольку ключевым словом при оформлении запроса является текст, входящий в название файла или каталога на ftp-сервере, то наибольшего успеха можно добиться в поиске информации, которая, будучи оформлена в виде файла, либо уже имеет определенное кем-либо имя, либо существует реальная возможность его угадать. Известных автору случаев делового применения ftp-поиска немало. Один из них следующий. Поисковик , разыскивающий один из американских стандартов ASTM по материаловедению с помощью поисковой системы HotBot быстро локализовал головной Web-сервер. Там ему удалось выяснить точное название стандарта. Полное описание стандарта предоставлялось за плату, а краткая аннотация - бесплатно. По техническим причинам аннотация на сервере была не доступна. Человек принял решение исследовать ftp-архивы с помощью поисковой системы и использовать алфавитно-цифровую последовательность, кодирующую название материала. Вскоре была найдена версия стандарта, близкая к полной, что исчерпало проблему. Достоверность информации вызывала у поисковика некоторые сомнения, однако была легко установлена специалистами.
Базы данных Gopher и поисковая система Veronica, сканирующая ресурсы Gopher-пространства на текущий момент перестали играть сколько-нибудь существенную роль в информационном поле Интернета. Тем не менее мать Гоферов всего мира -сервер, на котором зарегистрировано большинство gopher-серверов Сети (gopher://gopher2.tc.umn.edu), остается в рабочем состоянии и по сей день. Выйти на тот или иной gopher-сервер случается и через коллекции ссылок на Web-страницах, и через "бумажные" Желтые страницы. Как правило, если gopher-сервер еще работает, то в одном из файлов на нем указан адрес Web-узла, на который перенесена информация.
Гипертекстовая информационная система World Wide Web (WWW) и ее технологии на сегодняшний день наиболее значительны в Сети и продолжают свой подъем. По своей навигационной картине WWW фактически скопировала Gopher-ресурсы, но следствия одной мелкой детали, мало кто мог предугадать. Эта деталь - использование Web-страницы как легко создаваемого составного объекта, в тело которого монтируется более простые объекты, предназначенные для одновременного отображения. То, что сегодня в списке последних присутствуют текст, гиперссылки, графика, мультимедиа, программный код, диалоговые формы и многое другое в конечном итоге и предопределило широкое коммерческое использование WWW. Паутина заставила поисковые системы Web-пространства тонко подстроиться под себя и фактически обозначила ключевую тендецию их развития. Речь идет с одной стороны о том, что при индексировании ресурсов все более детальной проработке поисковыми системами подвергаются поля Web-страниц, формируемые контейнерами языка HTML. С другой стороны интенсивно развиваются те элементы информационно-поисковых языков, которые поддерживают поиск внутри этих полей. Сегодня можно констатировать глубокую интеграцию поисковых систем и ресурсов WWW на базе единой технологии. Кроме того чудовищный объем информационной базы WWW впервые с особой остротой поставил вопрос о необходимости параллельного существования целого ряда идентичных поисковых сервисов, обслуживающих интересы пользователей.
Каталоги ресурсов - глобальные, локальные, специализированные (в среде WWW); представляют собой размещаемые в Сети базы данных с адресами ресурсов и самым разным масштабом накопленной информации и охватом тематики. Обычно они имеют иерархическую структуру, перемещаясь по которой, можно локализовать нужный объект. Скорость накопления информации такими системами оказывается сравнительно низкой, поскольку в классификации ресурсов предполагается непосредственное участие человека. Для поисковика получение информации о ресурсе из известного каталога всегда является некоторой гарантией достоверности. При решении более или менее стандартной поисковой задачи именно каталог, а не поисковая машина оказываются стартовой площадкой для начала поиска.
Поисковые машины, или автоматические индексы - глобальные, локальные, специализированные (в среде WWW) представляют собой мощные информационно-поисковые системы, размещаемые на серверах свободного доступа. Их специальные программы-роботы, или пауки, в автоматическом режиме непрерывно сканируют информацию Сети на основе заданных алгоритмов, проводя индексацию документов. В последующем на основе созданных индексных баз данных поисковые машины предоставляют пользователю доступ к распределенной на узлах Сети информации. Это реализуется через выполнение поисковых запросов в рамках соответсвующего интерфейса. Последние исследования возможностей поисковых машин, даже самых мощных из них, таких как AltaVista, или HotBot, показывают, что реальная полнота охвата ресурсов Всемирной Паутины отдельной такой системой не превышает 30%. Планирование поисковой процедуры в пространстве WWW является нетривиальным, и его,безусловно, следует рассмотреть отдельно.
Баннерные системы (в среде WWW) предполагают различные варианты размещения специальных объектов - баннеров, обычно небольших графических изображений с рекламной целью на Web-узле , принимающем рекламу. Баннеры отсылают пользователя по гиперссылке на сервер рекламодателя и зачастую могут не иметь вообще никакого отношения к основному содержимому страницы. Баннеры не используются напрямую при проведении поиска, но являются неплохими индикаторами состояния информационного рынка Сети.
Активные информационные каналы (в среде WWW) представляют собой специализированные Web-сервера, предназначенные для поступления данных прямо на рабочее место пользователя. Ресурсы этого типа принято связывать с push-технологией (технология проталкивания информации). Фактически активный Web-канал является информационным источником периодически обновляемых данных. Можно как подписаться на канал, так и остановить подписку, что многим напоминает работу со списками рассылки. Методика поддержки каналов основными на сегодняшний день браузерами Netscape Communicator и Internet Explorer оказывается различной. С информацией каналов после ее обновления можно позднее ознакомиться в автономном режиме. Сама технология не получила ожидаемого широкого распространения и в контексте проблемы поиска не играет заметной роли.
Ресурсы Интернета через призму поисковых сервисов.
Среди пользователей Интернета легко очертить две категории. С одной стороны - это разработчики ресурсов в самом широком смысле этого слова от технического персонала до авторов-журналистов, поставляющих информацию в Сеть. С другой стороны - активные потребители информационного потока. Деятельность по поиску информации становится неотъемлемой надстройкой потребительской сферы.
Стремление разработчиков осмыслить интересы потребителя выглядит более чем естественно. Однако эффективные подходы к решению поисковых задач кроются как раз в обратном проникновении - детальном осмыслении поисковиком интересов, намерений и технических решений, культивируемых разработчиком. В этом смысле при рассмотрении основных типов ресурсов Сети мы стремились упомянуть и те, которые пока привлекательны в большей степени для поставщиков информации. Роль некоторых из них для задач поиска не кажется, на первый взгляд, существенной, но такое положение может измениться.
История развития Интернет-технологий показывает, что состояние поисковых сервисов, обслуживающих информационный ресурс определенного типа, напрямую связано с фазой его жизненного цикла (см. рис. 3).
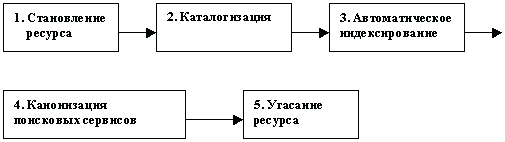
Рис.3. Связь жизненного цикла информационного ресурса Сети с динамикой развития сопутствующих поисковых сервисов.
Кратко поясним основные элементы схемы жизненного цикла. Каталогизация как оформление и укрупнение коллекций ссылок на ресурсы данного типа следует немедленно за становлением ресурса. Сервис автоматического индексирования начинает обычно формироваться лишь в случае достижения информационной массой ресурса некоторого критического объема. После этого течет фаза конкуренции идентичных поисковых сервисов - каталогов и индексов, обслуживающих ресурс. Канонизация фактически приостанавливает этот процесс, отдавая пальму первенства одному или нескольким поисковым системам. Заключительная стадия - угасания ресурса - характеризуется активной утечкой информационной массы в поле функционирования ресурсов другого типа вплоть до полного исчезновения.
Попробуем рассмотреть в свете схемы рис.3 такие информационные системы как Telnet, FTP, Gopher и WWW. Так, очевидно, что ресурсы WWW переживают в настоящий момент пик жизненного цикла между 3 и 4 фазами. Поисковые работы в информационном поле ресурса, переживающего период бурного развития автоматических индексов являются самыми многообещающими и самыми проблематичными одновременно. Архивы FTP находятся в фазе канонизации. Базы данных Gopher и Telnet характеризуются стадией угасания. Тем не менее какую бы жизненную фазу не переживал ресурс, и это основной тезис, проводимый автором, он всегда может содержать уникальную информацию и поэтому требует бережного обращения при организации поиска информации в Сети.



 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС