Making Internet Servers Fault-Tolerant - A Comprehensive Overview
Volker Hamann, Tandem Computers GmbH
Handelskai 388-4-6-2, A-1020 Wien, Austria
Email: hamann_volker@tandem.com
Abstract: In this paper, an overview over current trends in the Internet towards fault-tolerant services is given. It is shown that fail-safe services are a need becoming more and more a demand in future. Having a clear motivation for the issue, some principles are presented how to introduce fault-tolerance into the hardware, the operating system and the software of Internet servers.
Introduction
Since its introduction in the late 1960s, the Internet has evolved constantly from an originally small-size, military and education-only network to the network as we know it now.
Currently, over 35 million users and 5 millions hosts are connected with each other, and this number is constantly increasing. Also, over time the services offered has been subject to evolution.
Whereas at the very beginning - after adoption of TCP/IP as standard protocol - only character-based services were available (ftp, telnet, mail) this has become more user friendly in the last several years due to the employment of graphical user interfaces.
Nowadays, World Wide Web (WWW) plays the one major role among all Internet services. Separated but not so clearly distinguishable from WWW anymore are the very popular services Usenet News and E-mail.
More and more companies go for the Internet either as passive or as active participants. With this development, a demand for making Internet connections reliable and safe has shown as a natural consequence.
Security versus Fault-Tolerance
In common speech, security and safety are very closely related issues. Here, however, a clear distinction between these two terms has to be made. Security in the context of data transmissions means providing means of preventing non-authorized persons from getting access to confidential data. This is particularly true for monetary transactions, password-only services (personalized and usually liable to pay costs). Security is usually accomplished by data encryption techniques such as private/public key systems like RSA [1] or PGP [2]. For WWW, a protocol called S-HTTP (secure hypertext transfer protocol) has been developed [3]. There are also several products available doing this encryption and decryption of messages on a hardware basis, e.g. the CyberWeb Security Processor by Atalla [4]. Another implementation of protocol-level security is SSL (secure socket layer) providing for application-transparent data encryption on IP level [5].
On the other hand, safety is a term originally coming from systems theory. In this context it means that systems will behave exactly as they are specified, i.e. they will not show unpredictable behavior. System failures normally do not comply with safety expectations although one could argue that a stopped system still stays within its specification because it does nothing not covered in the specification. In practical life, however, this does not make sense. Users expect their systems to work and on top of that to work well. This is also and especially true for Internet servers. Psychological studies say that the average Web surfer only tries to connect to a host two times. If he cannot reach the desired system both times he will stop to look there at all. In the context of this paper, safety will mean all measures that can be taken to guarantee a non-stop service free of interruptions due to hardware or also operating system or software errors. Also, fault-tolerance and safetiness will be regarded as equivalent.
Technical Issues
In this section which forms the central part of the paper, technical means will be discussed how one can achieve safetiness in Internet Services. After giving a short overview how the basic Internet services work the fallacies and pitfalls of running them on non fault-tolerant hardware and operating systems will be outlined. As a capability to ease these problems, fault-tolerant hardware and software with non-stop Internet services on top will be presented.
The Classic Non-Fault-Tolerant Solution
This type of architecture is the one employed in most single-processor systems like PCs, entry-level workstations and servers but also can be found in multi-processor hardware without a fault-tolerant operating system. Figure 1 below shows the principle. A CPU is sitting on top of the memory which itself is connected via a system bus to peripheral devices like disks and communication lines.
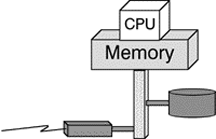
Fig. 1: Basic System Architecture (Non-Fault-Tolerant)
The obvious disadvantages of this architecture are its proneness to bottleneck situations. As all internal data flow takes its way over a single system bus its speed puts a unavoidable strict limit on overall system speed.
Most entry-level to midrange systems nowadays still follow this architecture in one way or the other. This is mainly due to the reason that these systems are easier to manufacture and cheaper, impacting their marketability to the broad mass of end users. Life-expectancy is low to medium, mean time between failures quite high. These figures strongly depend on the quality of the hardware which itself is again correlated to its price.
Virtually any hardware and every operating system which is available on the market nowadays is able to run Internet services in one way or the other. Being overly-simplistic, one could say that it suffices to be able to run the TCP/IP protocol to make a machine qualified for the Internet. In fact, most of the current Internet servers, whether they are Web servers, mail servers or whatsoever, are running on a non fault-tolerant platform. Typical operating systems in this context are UNIX and Windows-NT which offer enough stability for non-critical Internet service programs.
Fault-Tolerant Hardware
When the question of making hardware fault-tolerant arises, this is usually answered by adding redundant components. This can either be done by replicating standard architectures as mentioned above and have them run on a standby basis or - which is more elegant - using specially developed architectures. In the following, several design principles of fault-tolerant computer architectures are outlined.
Figure 2 shows a multiple CPU configuration sharing a single memory. Depending on the detailed configuration and the operating system, the CPUs can work in three modes. In the first mode (called parallel independent mode), each processor executes different code resulting in high speed but also in zero fault-tolerance. If one of the CPUs fails the processes being executed on it dies and cannot be recovered easily. The second mode (virtual processor) is a fail-safe one: each processor executes the same code at the same time and the results of each processor are compared against each other. A so-called voting mechanism decides if a CPU is faulty which is then switched off automatically. As the other(s) continue their work, this flaw is unobservable to the user, he will not even notice a performance degradation.
This architecture, however, contains single points of failure, that is components that once they fail lead to a complete standstill of the system. The shared memory in this example is such a single failure point.
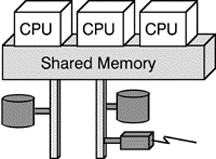
Fig. 2: Shared-memory Multiprocessing
This problem is addressed by the architecture schematized in Figure 3 below. Two systems are connected via their I/O channels to obtain a kind of coarse-grained full redundancy. For preserving data integrity and giving all participating systems in a cluster equal access to a common data resort, typically multiported RAID-systems [6] are used for mass-storage. Typically, one of the two systems is working as primary server and the other as backup server. Using a failover software, the systems check each other permanently ("are you still alive?") and the backup takes completely the role of the primary as soon as the primary fails.
To overcome the pitfalls of shared-memory architectures (single points of failure), shared-nothing multiprocessor systems have been developed. As displayed in Figure 4, fully equipped CPUs, each with their own memory and peripheral devices communicate with each other over a highspeed local bus. In this example, this bus is also twofold, so that a failure of one of them would not result in a total system crash. Failure of one or several of these modules will also leave the whole system intact. Again, it is the responsibility of some high-availability software to ensure that processes running on a failing CPU will be restarted appropriately on a different CPU.
A logical and useful further evolution of the shared-nothing multiprocessing architecture is a recently developed new interconnection technology: the ServerNet [7]. Being an implementation of a so-called system-area network, it provides a high-speed facility for connecting CPU-memory modules and peripheral devices in a many-to-many relationship. The network is fully dynamically configurable and almost unlimited in its expandability. Making use of its flexibility it can be configured for computation-intensive, data-intensive or communication-intensive applications or for a combination of them.
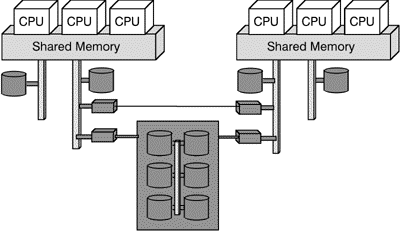
Fig. 3: Clustering multiprocessor systems
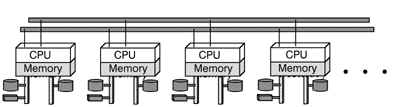
Fig. 4: Shared-nothing Multiprocessing
Data integrity can be obtained by a combination of shared-memory multiprocessing (voting) and cluster multiprocessing (failover) methods. For full fault-tolerance it is possible to build the ServerNet itself redundantly by doubling it and connecting all devices to both planes in parallel.
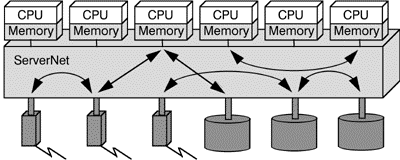
Fig. 5: ServerNet Architecture
Internet servers typically do not need much computing power but huge amounts of data storage and communication lines as well as a high-throughput connection between them. Figure 6 shows a typical ServerNet configuration which meets the needs of a fault-tolerant Web-Server.
Fig. 6: ServerNet based Internet server configuration
Fault-Tolerant Operating Systems
Having fault-tolerant hardware without running an appropriate fault-tolerant operating system on it, is like driving a sportscar without appropriate motorization. So in fact neither hardware nor operating systems are self-sufficient in any respect.
Historically, hardware and operating systems have always been developed in close connection with each other. Sometimes operating system design influences hardware design, but most of the time an operating system will fit an existing hardware.
Modern operating systems are built in a layered way. On the lowest level, the hardware dependent parts like device drivers etc. can be found. The uppermost layers rely on an abstract model of the machine without taking to much concern about the hardware any more. Similarly, also fault-tolerant operating systems are structured hierarchically. The structuring of Tandem's NonStop UX being an example for a fault-tolerant UNIX implementation can be seen in Figure 7.
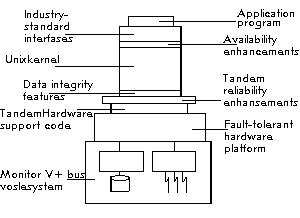
Fig. 7: NonStop UX System Architecture
The layers closest to hardware deal with things like:
- checking CPU working conditions (keepalive, voting)
- switching off faulty CPUs
- failover on CPU level with all consequences like cache and memory consistency
- handling fault-tolerant periphery (e.g. RAID disk systems)
Higher levels will have to handle tasks like restarting failed processes, reconfiguring network interfaces on protocol level (e.g. reassigning a TCP/IP address to a secondary network interface being activated after a failover) and bringing up newly configured network services and much more.
To application processes a typical UNIX system interface is presented. Functional enhancements to the operating system can be accessed via a clearly defined API (application program interface) which in a UNIX environment is typically implemented as system calls or library functions. Application can make use of these services or run without them in non fault tolerant mode.
Non-Stop Internet Services
Now that we have a fault-tolerant hardware and also a fail-safe operating system running on it, the focus of attention can be brought to fault tolerant applications. Typically applications which have to grant a continuous service to their users will be implemented with a high emphasis of fault-tolerance. Among them can be found: database systems, transaction-oriented software, critical process control systems, systems critical to external visibility and a lot more.
Internet servers are not clearly categorizable into one of the above mentioned classes. They are transaction oriented, often make use of database functionality and are clearly a front to the outside and thus critical to their owner's reputation. In our context we restrict ourselves to Internet service specific applications.
- FTP, telnet etc.: these "old" connection oriented (TCP-) services and protocols can hardly be made fault-tolerant. Their inherent end-to-end connectivity does not allow for a smooth transition of a server instance to a newly generated one. In most cases, a client will lose connection and the user will have to reinitiate the session.
- Email: whereas the most common email protocol SMTP (simple mail transfer protocol) is also connection oriented, no end user communication is involved. Thus broken connections can be restarted without the user getting notice of it. Delivery confirmation protocols help in maintaining an additional end-to-end safety.
- Web Servers: the HTTP protocol is connectionless. Reconnection after a failover is effortless. However, if on-line transactions running over the Web are interrupted they must be recovered using similar techniques as known from database oriented transaction systems.
- Network File Services: NFS - the most often used network file system - is connectionless and thus insensitive to service interruptions. If, however, for speedup purposes caching is employed, cached data will be lost. For shared-memory architectures there are solutions to this problem (write-through cache).
Interest Groups for a Fault-Tolerant Internet
Now that we have discussed how to achieve nonstop Internet services from a technical point of view, let's have a look at the question who ought really to care about this type of service.
First of all, there is the rapidly growing group of those who want to use the Internet for business purposes. Especially anytime when monetary transactions are in place the reliability of data transmission from end-to-end is necessary. Imagine a situation where somebody places an order via the Internet that includes automatic transfer of money from his bank account to the company receiving the order. If the Internet server crashes in the critical moment where the first transaction has not yet finished but the second is already completed, this customer will have to pay for something he could not even order. Using fault-tolerant services would reduce this risk to almost zero and thus increase the trust of customers in Internet-based order processing.
A similar scenario is the upcoming of commercial applets: users don't buy software copies on media anymore but load applications on-demand onto their client to be immediately deleted when their services are not needed anymore. Billing is made on a per-download basis instead of a per-copy basis. This implies that customers are very interested in an error and interruption free download process.
Second example: the number of Internet service providers is increasing almost in the same speed as the number of Internet users. Consequently, they will face an increase in competition in the next couple of years. Competing only by low prices is not desirable for them as this will decrease their revenues and thus their profits. So it is a much better idea to compete with improved services. Being able to offer non-stop and fail-safe connectivity without additional maintenance costs is a very strong argument for prospective customers.
These are just two possible scenarios serving as typical target audience for fault-tolerant services. There are of course many more many of which we don't even know yet nor can imagine.
Conclusion
In this paper, some aspects of fault-tolerant computing in the area of Internet services have been presented. Basically there are three levels which all have to incorporate fail-safe features to make the whole system fault-tolerant: hardware, operating system, and server / application software. Hardware can be made fault-tolerant by several means all of which introduce redundancy in some way or the other. Operating systems like UNIX are built in a modular way so that they can be enhanced with high availability features by adding functionality on the levels close to hardware and without having to touch the upper levels too much.
Internet server software can be seen like usual applications and thus be made fault-tolerant by much the same measures. Connectionless services are easier to modify than connection-oriented ones.
There is a need for fault tolerant Internet services in the marketplace and more and more products will be there over time to meet these demands. Cooperation and partnerships between companies that have a long tradition in the area of fault-tolerant computing and such that traditionally deal with networks and the Internet in general will help to push such products forward.
References
[1] R. L. Rivest, A. Shamir, L. Adleman. A method for obtaining digital signatures and public-key cryptosystems. Communications of the ACM, 21(2):120--126, February 1978.
[2] Simson Garfinkel. PGP: Pretty Good Privacy. O'Reilly and Associates, 1st Edition December 1994. ISBN: 1-56592-098-8.
[3]E. Rescorla, A. Schiffman. The Secure Hypertext Transfer Protocol. Internet-Draft, December 1994.http://www.commerce.net/information/standards/drafts/shttp.txt.
[4] Atalla. WebSafe Internet Security Processor. Product Announcement, August 1995.
http://www.atalla.com/at_wsisp.html.
[5] Alan O. Freier, Philip Karlton, Paul C. Kocher. SSL Version 3.0. Internet Draft, December 1994. ftp://ietf.cnri.reston.va.us/internet-drafts/draft-freier-ssl-version3-00.txt.
[6] ITC. Raid Guide. 1995. http://www.invincible.com/rguide.htm.
[7] W. E. Baker, R. W. Horst, D. P. Sonnier, W. J. Watson. A Flexible Servernet-based Fault-Tolerant Architecture. Proc. of 25th Intl. Symposium on Fault-Tolerant Computing, Pasadena, California. June 1995.
[Назад]
[Содержание]
[Вперед]

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
