Одной из основных проблем построения вычислительных систем во все времена остается задача обеспечения их продолжительного функционирования. Эта задача имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющих предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Единицей измерения надежности является среднее время наработки на отказ (MTBF - Mean Time Between Failure).
Повышение готовности предполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности - есть способ борьбы за снижение времени простоя системы. Единицей измерения здесь является коэффициент готовности, который определяет вероятность пребывания системы в работоспособном состоянии в любой произвольный момент времени. Статистически коэффициент готовности определяется как MTBF/(MTBF+MTTR), где MTTR (Mean Time To Repair) - среднее время восстановления (ремонта), т.е. среднее время между моментом обнаружения неисправности и моментом возврата системы к полноценному функционированию.
Таким образом, основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности от ремонтопригодности, контролепригодности и т.д.
В последние годы в литературе по вычислительной технике все чаще употребляется термин "системы высокой готовности", "системы высокой степени готовности", "системы с высоким коэффициентом готовности". Все эти термины по существу являются синонимами, однако как и многие термины в области вычислительной техники, термин "высокая готовность" понимается по-разному отдельными поставщиками и потребителями вычислительных систем. Совершенно аналогично, некоторые слова, связанные с термином "высокая готовность", такие, например, как "кластеризация", также употребляются в различных значениях. Важно иметь стандартный набор определений для того, чтобы предложения различных поставщиков можно было сравнивать между собой на основе одинаковых терминов.
Ниже приведены общепринятые в настоящее время определения, которые мы будем использовать для различных типов систем, свойством которых является та или иная форма снижения планового и непланового времени простоя:
- Высокая Готовность (High Availability). Настоящие конструкции с высоким коэффициентом готовности для минимизации планового и непланового времени простоя используют обычную компьютерную технологию. При этом конфигурация системы обеспечивает ее быстрое восстановление после обнаружения неисправности, для чего в ряде мест используются избыточные аппаратные и программные средства. Длительность задержки, в течение которой программа, отдельный компонент или система простаивает, может находиться в диапазоне от нескольких секунд до нескольких часов, но более часто в диапазоне от 2 до 20 минут. Обычно системы высокой готовности хорошо масштабируются, предлагая пользователям большую гибкость, чем другие типы избыточности.
- Эластичность к отказам (Fault Resiliency). Ряд поставщиков компьютерного оборудования делит весь диапазон систем высокой готовности на две части, при этом в верхней его части оказываются системы эластичные к отказам. Ключевым моментом в определении эластичности к отказам является более короткое время восстановления, которое позволяет системе быстро откатиться назад после обнаружения неисправности.
- Устойчивость к отказам (Fault Tolerance). Отказоустойчивые системы имеют в своем составе избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода и подсистемы дисковой памяти. Если соответствующий функциональный блок неправильно функционирует, всегда имеется горячий резерв. В наиболее продвинутых отказоустойчивых системах избыточные аппаратные средства можно использовать для распараллеливания обычных работ. Время восстановления после обнаружения неисправности для переключения отказавших компонентов на избыточные для таких систем обычно меньше одной секунды.
- Непрерывная готовность (Continuous Availability). Вершиной линии отказоустойчивых систем являются системы, обеспечивающие непрерывную готовность. Продукт с непрерывной готовностью, если он работает корректно, устраняет любое время простоя как плановое, так и неплановое. Разработка такой системы охватывает как аппаратные средства, так и программное обеспечение и позволяет проводить модернизацию (upgrade) и обслуживание в режиме on-line. Дополнительным требованием к таким системам является отсутствие деградации в случае отказа. Время восстановления после отказа не превышает одной секунды.
- Устойчивость к стихийным бедствияи (Disaster Tolerance). Широкий ряд продуктов и услуг связан с обеспечением устойчивости к стихийным бедствиям. Иногда устойчивость к стихийным бедствиям рассматривается в контексте систем высокой готовности. Смысл этого термина в действительности означает возможность рестарта или продолжения операций на другой площадке, если основное месторасположение системы оказывается в нерабочем состоянии из-за наводнения, пожара или землетрясения. В простейшем случае, продукты, устойчивые к стихийным бедствиям, могут просто представлять собой резервные компьютеры, расположенные вне основного местоположения системы, сконфигурированные по спецификациям пользователя и доступные для использования в случае стихийного бедствия на основной площадке. В более сложных случаях устойчивость к стихийным бедствиям может означать полное (зеркальное) дублирование системы вне основного местоположения, позволяющее принять на себя работу немедленно после отказа системы на основной площадке.
Все упомянутые типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Имеется два типа времени простоя компьютера: плановое и неплановое. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, принятое руководством, для проведения работ по модернизации системы и для ее обслуживания. Неплановое время простоя является результатом отказа системы или компонента. Хотя системы высокой готовности возможно больше ассоциируются с минимизацией неплановых простоев, они оказываются также полезными для уменьшения планового времени простоя.
Возможно наибольшим виновником планового времени простоя является резервное копирование данных. Некоторые конфигурации дисковых подсистем высокой готовности, особенно системы с зеркальными дисками, позволяют производить резервное копирование данных в режиме on-line. Следующим источником снижения планового времени простоя является организация работ по обновлению (модернизации) программного обеспечения. Сегодня некоторые отказоустойчивые системы и все системы с непрерывной готовностью позволяют производить модернизацию программного обеспечения в режиме on-line. Некоторые поставщики систем высокой готовности также обещают такие же возможности в течение ближайших нескольких лет.
В общем случае, неплановое время простоя прежде всего снижается за счет использования надежных частей, резервных магистралей или избыточного оборудования. Однако даже в этом случае система может требовать достаточно большого планового времени простоя.
Специальное программное обеспечение является существенной частью систем высокой готовности. При обнаружении неисправности системы оно обеспечивает управление конфигурацией аппаратных средств и программного обеспечения, а также в случае необходимости процедурами начальной установки, и перестраивает где надо структуры данных.
Высокая готовность не дается бесплатно. Общая стоимость подобных систем складывается из трех составляющих: начальной стоимости системы, издержек планирования и реализации, а также системных накладных расходов.
Для реализации системы высокой готовности пользователи должны в начале закупить собственно систему (или системы), включающую один или несколько процессоров в зависимости от требуемой вычислительной мощности и предполагаемой конфигурации, дополнительное программное обеспечение и дополнительное дисковое пространство.
Чтобы реализовать конфигурацию системы высокой готовности наиболее эффективным способом, особенно при использовании кластерных схем, требуется достаточно большое предварительное планирование. Например, чтобы иметь возможность переброски критичного приложения в случае отказа одного процессора на другой, пользователи должны определить, какие приложения являются наиболее критичными, проанализировать все возможные отказы и составить подробные планы восстановления на все случаи отказов.
Накладные расходы систем высокой готовности связаны с необходимостью поддержки довольно сложных программных продуктов, обеспечивающих высокую готовность. Для обеспечения дублирования записей на зеркальные диски в случае отсутствия специальных, предназначенных для этих целей процессоров, требуется поддержка дополнительной внешней памяти.
Стоимость системы высокой готовности в значительной степени зависит от выбранной конфигурации и ее возможностей. Ниже приведена некоторая информация, позволяющая грубо оценить различные типы избыточности.
Высокая Готовность. Дополнительная стоимость систем высокой готовности меняется в пределах от 10 до 100 процентов, обычно стремясь к середине этого диапазона. Дополнительная стоимость системы высокой готовности зависит от той степени, с которой пользователь способен использовать резервную систему для обработки своих приложений. Стоимость системы высокой готовности может реально превысить 100 процентов за счет программного обеспечения и необходимой начальной установки в случае применения резервной системы, которая не используется ни для чего другого. Однако обычно резервная система может быть использована для решения некритичных задач, значительно снижая стоимость.
Высокая эластичность. Дополнительная стоимость систем высокой эластичности к отказам, принадлежащих к верхнему уровню диапазона систем высокой готовности, лежит в пределах от 20 до 100 процентов, снова обычно стремясь к середине этого диапазона. Схемы высокой эластичности более сложны и предполагают более высокую стоимость планирования и большие накладные расходы, чем системы, принадлежащие нижнему уровню диапазона систем высокой готовности. В некоторых случаях однако, пользователь может в большей степени использовать общие процессорные ресурсы, тем самым уменьшая общую стоимость.
Непрерывная готовность. Надбавка к стоимости для систем с непрерывной готовностью находится в диапазоне от 20 до 100 или более процентов и обычно приближается к верхнему пределу этого диапазона. Программное обеспечение для обеспечения режима непрерывной готовности более сложное, чем для систем, обеспечивающих высокую эластичность к отказам. Большинство компонентов системы, такие как процессоры, источники питания, контроллеры и кабели, должны дублироваться, а иногда и троироваться. Пользователи систем непрерывной готовности, как и пользователи высоко эластичных к отказам систем, имеют возможность использовать весь набор ресурсов системы большую часть времени, по сравнению с пользователями более простых систем, принадлежащих нижнему уровню диапазона систем высокой готовности.
Устойчивость к стихийным бедствиям. Надбавка к стоимости для систем, устойчивым к стихийным бедствиям, может сильно варьироваться. С одной стороны, она может составлять, например, только несколько процентов стоимости системы при резервировании времени запасного компьютера, находящегося вне основной площадки. С другой стороны, стоимость системы может увеличиться в несколько раз, если необходимо обеспечить действительно быстрое переключение на другую систему, находящуюся на удаленной площадке с помощью высокоскоростных сетевых средств. Большинство предложений по системам, устойчивым к стихийным бедствиям, требуют существенного объема планирования.
Для того, чтобы снизить стоимость системы, следует тщательно оценивать действительно необходимый уровень готовности (т.е. осуществлять выбор между высокой готовностью, устойчивостью к отказам и/или устойчивостью к стихийным бедствиям) и вкладывать деньги только за обеспечение безопасности наиболее критичных для деятельности компании приложений и данных.
Первым шагом на пути обеспечения высокой готовности является защита наиболее важной части системы, а именно - данных. Разные типы конфигураций избыточной внешней памяти обеспечивают разную степень защиты данных и имеют разную стоимость.
Имеются три основных типа подсистем внешней памяти с высокой готовностью. Для своей реализации они используют технологию Избыточных Массивов Дешевых Дисков (RAID - Redundant Arrays of Inexpensive Disks). Наиболее часто используются следующий решения (более подробно об уровнях RAID см. разд. 9.3.2): RAID уровня 1 или зеркальные диски, RAID уровня 3 с четностью и RAID уровня 5 с распределенной четностью. Эти три типа внешней памяти в общем случае имеют практически почти мгновенное время восстановления в случае отказа. Кроме того, подобные устройства иногда позволяют пользователям смешивать и подбирать типы RAID в пределах одного дискового массива. В общем случае дисковые массивы представляются прикладной задаче как один диск.
Технология RAID уровня 1 (или зеркалирования дисков) основана на применении двух дисков так, что в случае отказа одного из них, для работы может быть использована копия, находящаяся на дополнительном диске. Программные средства поддержки зеркальных дисков обеспечивают запись всех данных на оба диска. Недостатком организации зеркальных дисков является удвоение стоимости аппаратных средств и незначительное увеличение времени записи, поскольку данные должны быть записаны на оба диска. Положительные стороны этого подхода включают возможность обеспечения резервного копирования в режиме on-line, а также замену дисков в режиме on-line, что существенно снижает плановое время простоя. Как правило, структура устройств с зеркальными дисками устраняет также единственность точки отказа, поскольку для подключения обоих дисков обычно предусматриваются два отдельных кабеля, а также два отдельных контроллера ввода/вывода.
В массивах RAID уровня 3 предусматривается использование одного дополнительного дискового накопителя, обеспечивающего хранение информации о четности (контрольной суммы) данных, записываемых на каждые два или четыре диска. Если один из дисков в массиве отказывает, информация о четности вместе с данными, находящимися на других оставшихся дисках, позволяет реконструировать данные, находившиеся на отказавшем накопителе.
Массив RAID уровня 5 является комбинацией RAID уровня 0, в котором данные расщепляются для записи на несколько дисков, и RAID уровня 3, в которых имеется один дополнительный диск. В RAID уровня 5 полезная информация четырех дисков и контрольная информация распределяется по всем пяти дискам так, что при отказе одного из них, оставшиеся четыре обеспечивают считывание необходимых данных. Методика расщепления данных позволяет также существенно увеличить скорость ввода/вывода при передаче больших объемов данных.
Диапазон возможных конструкций современных дисковых массивов достаточно широк. Он простираются от простых подсистем без многих дополнительных возможностей до весьма изощренных дисковых подсистем, которые позволяют пользователям смешивать и подбирать уровни RAID внутри одного устройства. Наиболее мощные дисковые подсистемы могут также содержать в своем составе процессоры, которые разгружают основную систему от выполнения рутинных операций ввода/вывода, форматирования дисков, защиты от ошибок и выполнения алгоритмов RAID. Большинство дисковых массивов снабжаются двумя портами, что позволяет пользователям подключать их к двум различным системам.
Добавка к стоимости дисковой подсистемы для организации зеркальных дисков стремится к 100%, поскольку требуемые диски должны дублироваться в избыточной конфигурации 1:1. Дополнительная стоимость дисков для RAID уровней 3 и 5 составляет либо 33% при наличии диска четности для каждых двух дисков, либо более часто 20% при наличии диска четности для каждых четырех накопителей. Кроме того, следует учитывать стоимость специального программного обеспечения, а также стоимость организации самого массива. Некоторые компании предлагают программные средства для организации зеркальных дисков при использовании обычных дисковых подсистем. Другие предлагают возможности зеркальной организации в подсистемах RAID, специально изготовленных для этих целей. Подсистемы, использующие RAID уровней 3 и 5, отличаются по стоимости в зависимости от своих возможностей.
Реализация внешней памяти высокой готовности может приводить также к увеличению системных накладных расходов. Например, основной процессор системы вынужден обрабатывать две операции при каждой записи информации на зеркальные диски, если эти диски не являются частью зеркального дискового массива, который имеет свои собственные средства обработки. Однако наиболее сложные дисковые массивы позволяют снизить накладные расходы за счет использования процессоров ввода/вывода, являющихся частью аппаратуры дискового массива.
В настоящее время для устройств внешней памяти характерна тенденция уменьшения соотношения стоимости на единицу емкости памяти (1, 0.5 и менее долларов за мегабайт). Эта тенденция делает сегодняшние избыточные решения по внешней памяти даже менее дорогими, по сравнению со стоимостью подсистем с обычными дисками, выпускавшимися только год назад. Поэтому использование подсистемы RAID очень быстро становится одним из базовых требований обычных систем, а не специальным свойством систем высокой готовности.
В настоящее время одним из ключевых требований пользователей UNIX-систем является возможность их наращивания с целью обеспечения более высокой степени готовности. Главными характеристиками систем высокой готовности по сравнению со стандартными системами являются пониженная частота отказов и более быстрый переход к нормальному режиму функционирования после возникновения неисправности посредством быстрого восстановления приложений и сетевых сессий до того состояния, в котором они находились в момент отказа системы. Следует отметить, что во многих случаях пользователей вполне может устроить даже небольшое время простоя в обмен на меньшую стоимость системы высокой готовности по сравнению со значительно более высокой стоимостью обеспечения режима непрерывной готовности.
Конфигурации систем высокой готовности, предлагаемые современной компьютерной промышленностью, простираются в широком диапазоне от "простейших" жестких схем, обеспечивающих дублирование основной системы отдельно стоящим горячим резервом в соотношении 1:1, до весьма свободных кластерных схем, позволяющих одной системе подхватить работу любой из нескольких систем в кластере в случае их неисправности.
Термин "кластеризация" на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: "реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей". Машины, кластеризованные вместе таким способом могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности. Имеются несколько поставщиков, которые называют свои системы высокой готовности "кластерами" или "простыми кластерами", однако на сегодняшний день реально доступны только несколько кластеров, которые подпадают под строгое определение (см. ниже).
Современные конструкции систем высокой готовности предполагают использование горячего резерва (Fail-Over), включая переключение прикладных программ и пользователей на другую машину с гарантией отсутствия потерь или искажений данных во время отказа и переключения. В зависимости от свойств системы, некоторые или все эти процессы могут быть автоматизированы.
Системы высокой готовности связаны со своими резервными системами посредством очень небольшого программного демона "сердечный пульс", который позволяет резервной системе управлять основной системой или системами, которые она резервирует. Когда "пульс" пропадает, кластер переходит в режим переключения на резервную систему.
Такое переключение может выполняться вручную или автоматически, и имеется несколько уровней автоматизации этого процесса. Например, в некоторых случаях пользователи инструктируются о том, что они должны выйти и снова войти в систему. В других случаях переключение осуществляется более прозрачным для пользователя способом: он только должен подождать в течение короткого периода времени. Иногда пользователь может делать выбор между ручным и автоматическим переключением. В некоторых системах пользователи могут продолжить работу после переключения именно с той точки, где они находились во время отказа. В других случаях их просят повторить последнюю транзакцию.
Резервная система не обязательно должна полностью повторять систему, которую она резервирует (конфигурации систем могут отличаться). Это позволяет в ряде случаев сэкономить деньги за счет резервирования большой системы или систем с помощью системы меньшего размера и предполагает либо снижение производительности в случае отказа основной системы, либо переключение на резервную систему только критичных для жизнедеятельности организации приложений.
Следует добавить, что одни пользователи предпочитают не выполнять никаких приложений на резервной машине, хотя другие наоборот стараются немного нагрузить резервный сервер в кластере. Возможность выбора конфигурации системы с помощью процедур начальной установки дает пользователям большую гибкость, позволяя постепенно использовать весь заложенный в системе потенциал.
Большинство систем высокой готовности требуют включения в свой состав процедур начальной установки (System Setup), обеспечивающих конфигурацию кластера для подобающего выполнения процедур переключения, необходимых в случае отказа. Пользователи могут запрограммировать "скрипты" начальной установки самостоятельно или попросить системного интегратора или поставщика проделать эту работу. В зависимости от того, насколько сложна начальная установка системы, и в зависимости от типа системы, с которой мигрирует пользователь, написание "скриптов", которые управляют действиями системы высокой готовности в случае отказа, может занять от одного - двух дней до нескольких недель или даже месяцев для опытных программистов. Многие поставщики обеспечивают несколько стандартных "скриптов" начальной установки. Кроме того, некоторые из них предоставляют сервисные услуги по начальной установке конфигурации, которые включают программирование сценариев переключения на горячий резерв в случае отказа, а также осуществляют работу с заказчиком по написанию или модификации "скриптов". Пользователи могут самостоятельно создавать "скрипты", однако для реализации подобающей конфигурации требуется высококвалифицированный программист - знаток UNIX и C.
Время простоя при переключении системы на резервную для систем высокой готовности может меняться в диапазоне от нескольких секунд до 20-40 и более минут. Процедура переключения на резерв включает в себя следующие этапы: резервная машина обнаруживает отказ основной и затем следует предписаниям скрипта, который вероятнее всего включает перезапуск системы, передачу адресов пользователей, получение и запуск необходимых приложений, а также выполнение определенных шагов по обеспечению корректного состояния данных. Время восстановления зависит главным образом от того, насколько быстро вторая машина сможет получить и запустить приложения, а также от того, насколько быстро операционная система и приложения, такие как базы данных или мониторы транзакций, смогут получить приведенные в порядок данные.
В общем случае аппаратное переключение на резерв занимает по порядку величины одну - две минуты, а система перезагружается за следующие одну - две минуты. В большинстве случаев от 5 до 20 минут требуется на то, чтобы получить и запустить приложение с полностью восстановленными данными. В противном случае пользователи инструктируются о необходимости заново ввести последнюю транзакцию.
Накладные системные расходы зависят от типа используемой системы и от сложности процедур ее начальной установки. Для простых процедур начальной установки при переходе на резерв они очень небольшие: от долей процента до 1.5%. Однако, чтобы получить истинную стоимость накладных расходов к этим накладным расходам необходимо добавить еще потери, связанные с недоиспользованием процессорной мощности резервной системы. Хотя покупатели стремятся использовать резервную систему для некритических приложений, она оказывается менее загруженной по сравнению с основной системой. Истинно кластерные системы, такие как VAXclasters компании DEC или кластер LifeKeeper Claster отделения NCR компании AT&T, являются примерами намного более сложного управления по сравнению с простыми процедурами начальной установки при переключении на резерв, и полностью используют все доступные процессоры. Однако организация таких систем влечет за собой и большие накладные расходы, которые увеличиваются с ростом числа узлов в кластере.
Поставщики, предлагающие системы с горячим резервом, обычно в своих версиях системы UNIX предоставляют также некоторые дополнительные свойства высокой готовности, обеспечивающие быструю загрузку и/или перезагрузку резервной системы в случае переключения при возникновении неисправности.
Журнализация файловой системы
Следствием журнализации изменений файловой системы является то, что файлы всегда находятся в готовом для использования состоянии. Когда система отказывает, журнализованная файловая система гарантирует, что файлы сохранены в последнем согласованном состоянии. Это позволяет осуществлять переключение на резервную систему без какой-либо порчи данных, а также либо вообще без каких-либо потерь данных, либо с потерей только одной последней транзакции. Такой подход отличается от систем, которые осуществляют журнализацию только метаданных файловой системы - процедура, которая помогает управлять целостностью файловой системы, но не целостностью данных.
Изоляция неисправного процесса
Для активно используемых компонентов программного обеспечения, таких как файловая система, часто применяется технология изоляции неисправных процессов, гарантирующая изоляцию ошибок в одной системе и невозможность их распространения за пределы этой системы.
Мониторы обработки транзакций
Иногда для управления переключением на резерв используются мониторы транзакций, гарантирующие отсутствие потерь данных. При этом для незавершенных транзакций может быть произведен откат назад и базы данных возвращаются к известному согласованному состоянию. Для системы UNIX наиболее известными мониторами транзакций являются Tuxedo компании USL, Encina компании Transarc, CICS/6000 компании IBM и Top End компании NCR.
Другие функции программного обеспечения
В современных системах все возрастающую роль играет диагностика в режиме on-line, позволяющая предвосхищать проблемы, которые могут привести к простою системы. В настоящее время она специфична для каждой системы. В будущем, возможно, диагностика станет частью распределенного управления системой.
Первыми открытыми системами, построенными в расчете на высокую готовность, были приложения баз данных и систем коммуникаций. Базы данных высокой готовности гарантируют непрерывный доступ к информации, которая является жизненно важной для функционирования многих корпораций и стержнем сегодняшней информационной экономики. Программное обеспечение систем коммуникаций высокой готовности усиливает средства горячего резервирования систем и составляет основу для распределенных систем высокой готовности и систем, устойчивых к стихийным бедствиям.
Высокая готовность баз данных. Несколько компаний, поставляющих базы данных, такие как Oracle, Sybase, Informix имеют в составе своих продуктов программное обеспечение, позволяющее выполнять быструю реконструкцию файлов в случае отказа системы. Это снижает время простоя для зеркальных серверов и кластерных решений.
Продукт Oracle7 Parallel Server позволяет нескольким системам одновременно работать с единым представлением базы данных Oracle. Балансировка нагрузки и распределенный менеджер блокировок, которые позволяют множеству систем обращаться к базе данных в одно и то же время, увеличивают потенциальную готовность базы данных.
Первоначально модель вычислительного кластера была разработана компанией DEC в конце 80-х годов. Она известна под названием VMS-кластеров (или VAX-кластеров), которые представляли собой объединенные в кластер миникомпьютеры VAX, работающие под управлением операционной системы VMS. Компания DEC была первым поставщиком Oracle Parallel Server на VMS-кластерах в 1991 году. После появления версии Oracle 7, у компании Oracle появился интерес к концепции базы данных на UNIX-кластерах и в 1991 году она опубликовала программный интерфейс приложений (API) для своего менеджера блокировок. Публикация этого API означала открытое приглашение всех поставщиков вычислительных систем для организации поддержки на их платформах Oracle 7 Parallel Server. В результате основные поставщики UNIX-кластеров в настоящее время поддерживают этот продукт.
Кроме того, существуют продукты третьих фирм, дополняющие возможности баз данных известных производителей и обеспечивающие увеличение степени высокой готовности. Например, компания Afic Computer Incorporated (New York) продает продукт под названием Multi Server Option (MSO), который позволяет пользователям осуществлять через сеть TCP/IP одновременную запись в любое количество распределенных зеркальных баз данных Sybase. Информация распространяется широковещательным способом одновременно ко всем базам данных. MSO обеспечивает также балансировку нагрузки по множеству серверов. Если один из серверов отказывает, программное обеспечение перенаправит запрос на дублирующую базу данных в течение не более 30 секунд.
Системы высокой готовности требуют также высокой готовности коммуникаций. Чем быстрее коммуникации между машинами, тем быстрее происходит восстановление после отказа. Некоторые конфигурации систем высокой готовности имеют дублированные коммуникационные связи. В результате связь перестает быть точкой, отказ которой может привести к выходу из строя всей системы. Существующая в настоящее время тенденция в направлении сетей LAN и WAN с повышенной пропускной способностью обеспечивает как локальные, так и удаленные компьютеры более быстрыми коммуникациями, что приводит в итоге к более быстрому восстановлению в распределенных системах.
Современная сетевая технология сама по себе требует устранения таких точек, выход из строя которых, может привести к отказу всей сети. Сегодня при создании сетей характерно использование более сложных сетевых устройств от различных поставщиков, таких как маршрутизаторы и сетевые хабы. Маршрутизаторы, которые определяют путь данных в сетях, могут вычислить новый путь в случае отказа связи. Хабы могут иметь конфигурации с избыточными устройствами и могут изолировать отказы в физической сети для предотвращения отказа всей сети. Важную роль в поддержании оптимального функционирования систем играют также сетевые анализаторы, позволяющие вызвать системного менеджера по любому симптому, который может потенциально привести к простою.
Высокая готовность сетевой организации всегда очень зависит от размера сети. По мере своего разрастания сеть стремится приобрести свойства встроенной надежности: чем больше сеть, тем более желательно использование альтернативных маршрутов, чтобы отказ одного компонента блокировал только какую-то небольшую ее часть.
В настоящее время ведутся активные разработки в направлении создания высокоскоростных сетей ATM. Широкое внедрение этой технологии позволит достаточно быстро передавать большие объемы информации через WAN и обеспечит высокоскоростное переключение в случае отказа между удаленными системами.
Цены на сети высокой готовности в значительной степени зависят от их конфигурации. Ниже даны несколько примеров для одноранговых сетей высокой готовности.
Для небольшой сети, расположенной на одной площадке и имеющей менее 500 узлов, пользователь должен ожидать примерно 50-процентного увеличения стоимости за обеспечение высокой готовности.
Средняя по размеру сеть, предполагающая размещение на нескольких площадках и имеющая до 5000 узлов потребует от 30 до 40 процентов надбавки к стоимости обычной сети.
Для очень большой сети с более 5000 узлов, расположенных на одной площадке надбавка к стоимости за обеспечение высокой готовности уменьшается примерно до 20 - 30%.
В отказоустойчивых системах стоимость сети еще больше увеличивается. Надбавка к стоимости за базовую отказоустойчивую сеть обычно находится в пределах 80-100 и более процентов, и связана скорее не с размером сети, а с платой за высокую готовность.
Компания DEC первой анонсировала концепцию кластерной системы в 1983 году, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования.
VAX-кластер обладает следующими свойствами:
Разделение ресурсов. Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным.
Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров HSC и один из них отказывает, другие контроллеры HSC автоматически подхватывают его работу.
Высокая пропускная способность. Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера.
Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера.
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер.
Работа VAX-кластера определяется двумя главными компонентами. Первым компонентом является высокоскоростной механизм связи, а вторым - системное программное обеспечение, которое обеспечивает клиентам прозрачный доступ к системному сервису. Физически связи внутри кластера реализуются с помощью трех различных шинных технологий с различными характеристиками производительности.
Основные методы связи в VAX-кластере представлены на рис. 11.1.
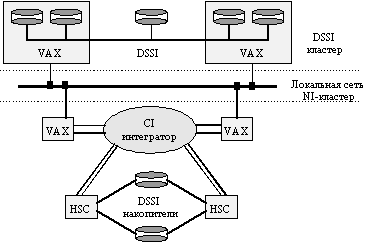
Рис. 11.1. VAX/VMS-кластер
Шина связи компьютеров CI (Computer Interconnect) работает со скоростью 70 Мбит/с и используется для соединения компьютеров VAX и контроллеров HSC с помощью коммутатора Star Coupler. Каждая связь CI имеет двойные избыточные линии, две для передачи и две для приема, используя базовую технологию CSMA, которая для устранения коллизий использует специфические для данного узла задержки. Максимальная длина связи CI составляет 45 метров. Звездообразный коммутатор Star Coupler может поддерживать подключение до 32 шин CI, каждая из которых предназначена для подсоединения компьютера VAX или контроллера HSC. Контроллер HSC представляет собой интеллектуальное устройство, которое управляет работой дисковых и ленточных накопителей.
Компьютеры VAX могут объединяться в кластер также посредством локальной сети
Ethernet, используя NI - Network Interconnect (так называемые локальные VAX-кластеры), однако производительность таких систем сравнительно низкая из-за необходимости делить пропускную способность сети Ethernet между компьютерами кластера и другими клиентами сети.
В начале 1992 года компания DEC анонсировала поддержку построения кластера на основе шины DSSI (Digital Storage System Interconnect). На шине DSSI могут объединяться до четырех компьютеров VAX нижнего и среднего класса. Каждый компьютер может поддерживать несколько адаптеров DSSI. Отдельная шина DSSI работает со скоростью 4 Мбайт/с (32 Мбит/с) и допускает подсоединение до 8 устройств. Поддерживаются следующие типы устройств: системный адаптер DSSI, дисковый контроллер серии RF и ленточный контроллер серии TF. DSSI ограничивает расстояние между узлами в кластере 25 метрами.
Во всем мире насчитывалось более 20000 установок VAX-кластеров. Почти все из них построены с использованием шинного интерфейса CI.
Системное программное обеспечение VAX-кластеров
Для гарантии правильного взаимодействия процессоров друг с другом при обращениях к общим ресурсам, таким, например, как диски, компания DEC использует распределенный менеджер блокировок DLM (Distributed Lock Manager). Очень важной функцией DLM является обеспечение когерентного состояния дисковых кэшей для операций ввода/вывода операционной системы и прикладных программ. Например, в приложениях реляционных СУБД DLM несет ответственность за поддержание согласованного состояния между буферами базы данных на различных компьютерах кластера.
Задача поддержания когерентности кэш-памяти ввода/вывода между процессорами в кластере подобна задаче поддержания когерентности кэш-памяти в сильно связанной многопроцессорной системе, построенной на базе некоторой шины. Блоки данных могут одновременно появляться в нескольких кэшах и если один процессор модифицирует одну из этих копий, другие существующие копии не отражают уже текущее состояние блока данных. Концепция захвата блока (владения блоком) является одним из способов управления такими ситуациями. Прежде чем блок может быть модифицирован должно быть обеспечено владение блоком.
Работа с DLM связана со значительными накладными расходами. Накладные расходы в среде VAX/VMS могут быть большими, требующими передачи до шести сообщений по шине CI для одной операции ввода/вывода. Накладные расходы могут достигать величины 20% для каждого процессора в кластере. Поставщики баз данных при использовании двухпроцессорного VAX-кластера обычно рассчитывают получить увеличение пропускной способности в 1.8 раза для транзакций выбора и в 1.3 раза для транзакций обновления базы данных.
Различные группы промышленных аналитиков считают VAX-кластеры образцом, по которому должны реализовываться другие кластерные системы, и примером свойств, которыми они должны обладать. VAX-кластеры являются очень надежными и высокопроизводительными вычислительными системами, основанными на миникомпьютерах. Хотя они базируются на патентованной операционной среде (VMS), опыт их эксплуатации показал, что основные свойства, которыми они обладают очень хорошо соответствуют потребностям коммерческих учреждений.
В настоящее время на смену VAX-кластерам приходят UNIX-кластеры. При этом VAX-кластеры предлагают проверенный набор решений, который устанавливает критерии для оценки подобных систем. Одна из известных аналитических групп (Gartner Group) опубликовала модель для сравнения, которая получила название "Критерии оценки кластеров" (MCS Research Note T-470-1411, November 22, 1993). Эта модель базируется на наборе свойств VAX-кластера и используется для сравнения UNIX-кластеров. Критерии этой модели представлены в табл. 11.1.
Таблица 11.1
| Архитектурная модель | VAX-кластер
|
Масштабируемость
Масштабируемость (>6 узлов)
Смешанный размер
Смешанные поколения
Единственное представление данных
Балансировка нагрузки
Общий планировщик работ
Общий менеджер систем
Надежность на уровне кластера
Готовность
Подавление одиночного отказа или сбоя
Симметричный резерв аппаратных средств
Симметричный резерв программных средств
Автоматическая реконфигурация
Автоматическое восстановление клиента
Размещение на нескольких площадках |
да
да
да
да
да
да
да
да
да
да
да
да
да
да
|
В настоящее время UNIX-кластеры все еще отстают от VAX-кластеров по функциональным возможностям. Одно из наибольших отличий связано с реализацией восстановления клиентов в случае отказа. В VAX-кластерах такое восстановление осуществляется средствами программного обеспечения самого VAX-кластера. В UNIX-кластерах эти возможности обычно реализуются отдельным уровнем программного обеспечения, называемым монитором транзакций. В UNIX-кластерах мониторы транзакций кроме того используются также для целей балансировки нагрузки, в то время как VAX-кластеры имеют встроенную в программное обеспечение утилиту балансировки загрузки.
Ожидается, что UNIX-кластеры подойдут и обгонят по функциональным возможностям VAX-кластеры в период 1996-1997 года.
Стратегическая линия новых продуктов компании DEC основана на новой аппаратной платформе Alpha AXP, которая поддерживает несколько операционных систем (в их числе OpenVMS, DEC OSF/1 и Windows NT). Компания объявила о создании UNIX-кластеров на своей новой платформе Alpha/OSF в 1993 году. Главной задачей при этом считается достижение тех же функциональных возможностей, которыми обладали VAX/VMS-кластеры.
В основу нового кластерного решения положен высокоскоростной коммутатор
GigaSwitch, максимальная пропускная способность которого достигает 3.6 Гбайт/с.
GigaSwitch представляет собой протокольно независимое устройство коммутации пакетов, которое может иметь 36 портов и поддерживать протоколы Ethernet, FDDI и ATM. Поддержка различных протоколов реализована с помощью набора специальных сменных карт. Предполагается, что к GigaSwitch помимо рабочих станций Alpha смогут подключаться и UNIX-станции других производителей.
В апреле 1994 года компания DEC анонсировала продукт под названием Integrated Cluster Server, который по своим функциональным характеристикам должен соответствовать стандарту VAX/VMS-кластеров. Основу этого решения составляет новая технология так называемой рефлективной памяти, имеющейся в каждом узле кластера. Устройства рефлективной памяти разных узлов кластера объединяются с помощью высокоскоростных каналов на основе интерфейса PCI (см. рис. 11.2). Обмен информацией между узлами типа "память-память" по этим каналам может производиться со скоростью 100 Мбайт/с, что на порядок превышает скорость обмена по обычным каналам ввода/вывода. Появление этого продукта ожидается в конце 1995 года.
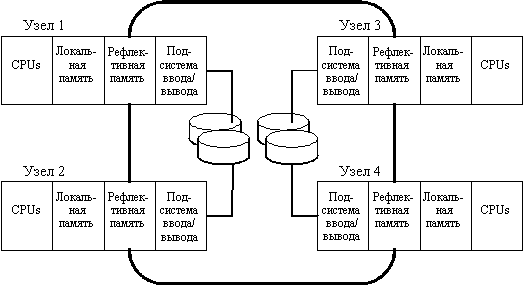
Рис. 11.2. Архитектура кластера компании DEC на базе рефлективной
памяти и каналов "память-память"
Компания DEC выпускает RAID массивы StorageWorks, которые поддерживают RAID уровней 0, 1 и 5 и обеспечивают замену компонентов без выключения питания. В стоечной конфигурации поддерживается до 70 накопителей и дополнительные источники питания. Они могут выполнять до 400 операций ввода/вывода в секунду и подключаются к основным компьютерам через интерфейс Differential Fast SCSI-2. Скоростью интерфейса составляет 10 Мбайт/с, максимальная длина связи - 25 м.
Компания IBM предлагает несколько типов слабо связанных систем на базе RS/6000, объединенных в кластеры и работающих под управлением программного продукта High-Availability Clastered Multiprocessor/6000 (HACMP/6000). В этих системах поддерживаются три режима автоматического восстановления системы после отказа:
Режим 1 - в конфигурации с двумя системами, одна из которых является основной, а другая находится в горячем резерве, в случае отказа обеспечивает автоматическое переключение с основной системы на резервную.
Режим 2 - в той же двухмашинной конфигурации позволяет резервному процессору обрабатывать некритичные приложения, выполнение которых в случае отказа основной системы можно либо прекратить совсем, либо продолжать их обработку в режиме деградации.
Режим 3 - можно действительно назвать кластерным решением, поскольку системы в этом режиме работают параллельно, разделяя доступ к логическим и физическим ресурсам пользуясь возможностями менеджера блокировок, входящего в состав HACMP/6000.
Начиная с объявления в 1991 году продукт HACMP/6000 постоянно развивался. В его состав были включены параллельный менеджер ресурсов, распределенный менеджер блокировок и параллельный менеджер логических томов, причем последний обеспечил возможность балансировки загрузки на уровне всего кластера. Максимальное количество узлов в кластере возросло до восьми. В настоящее время в составе кластера появились узлы с симметричной многопроцессорной обработкой, построенные по технологии Data Crossbar Switch, обеспечивающей линейный рост производительности с увеличением числа процессоров.
Первоначально обязательным требованием режима 3 было использование высокопроизводительной дисковой подсистемы IBM 9333, которая использовала последовательный дисковый интерфейс с поддержкой 17.6 Гбайт дискового пространства, а также дисковой подсистемы IBM 9334 с интерфейсом SCSI, обеспечивающим дисковое пространство в 8.2 Гбайт. В августе 1993 года была анонсирована первая подсистема RAID: две модели 7135 RAIDiant Array могут поддерживать до 768 Гбайт дискового пространства в стоечной конструкции серии 900 и 96 Гбайт в напольных тумбовых конструкциях, при этом реализуют RAID уровней 1, 3 и 5.
Кластеры RS/6000 строятся на базе локальных сетей Ethernet, Token Ring или FDDI и могут быть сконфигурированы различными способами с точки зрения обеспечения повышенной надежности:
- Горячий резерв или простое переключение в случае отказа. В этом режиме активный узел выполняет прикладные задачи, а резервный может выполнять некритичные задачи, которые могут быть остановлены в случае необходимости переключения при отказе активного узла.
- Симметричный резерв. Аналогичен горячему резерву, но роли главного и резервного узлов не фиксированы.
- Взаимный подхват или режим с распределением нагрузки. В этом режиме каждый узел в кластере может "подхватывать" задачи, которые выполняются на любом другом узле кластера.
Отделение GIS (Global Information Systems) образовалось после покупки AT&T компании NCR, успешно работавшей в направлении создания систем с симметричной многопроцессорной обработкой (SMP) и систем с массовым параллелизмом (MPP) на базе микропроцессоров Intel. В 1993 году NCR анонсировала программное обеспечение для поддержки высокой готовности, получившее название LifeKeeper FRS (Fault Recilient Systems) Clastering Software, которое вместе с дисковыми массивами NCR позволяло строить высоконадежные кластерные решения. В состав кластеров NCR могут входить многопроцессорные системы серий 3400 и 3500, каждая из которых включает от 1 до 8 процессоров 486DX2 или Pentium (рис. 11.3).
Disk Array Subsystem 6298 включает до 20 дисковых накопителей емкостью 1 Гбайт и поддерживает RAID уровней 0, 1, 3 и 5 в любой комбинации. Подсистема обеспечивает замену дисковых накопителей, вентиляторов и источников питания в режиме on-line, т.е. без приостановки работы системы. В ней предусмотрено три порта и возможна поставка с избыточными контроллерами.
Программное обеспечение LifeKeeper допускает построение кластеров высокой готовности с четырьмя узлами, причем любой из узлов кластера может служить в качестве резервного для других узлов. Плановое время простоя для инсталляции программного обеспечения может быть значительно снижено, поскольку переключение на резерв можно инициировать вручную, затем модифицировать программное обеспечение и произвести обратное переключение с резерва. LifeKeeper обеспечивает также восстановление системы после обнаружения ошибок в системных, прикладных программах и периферийном оборудовании. Он обеспечивает автоматическое переключение при обнаружении отказа и инициируемое оператором обратное переключение. Все связи узлов кластера с помощью Ethernet, Token Ring и FDDI дублированы, а дисковые подсистемы, как уже отмечалось, могут подключаться сразу к нескольким узлам кластера. Все это обеспечивает построение системы, устойчивой к одиночным отказам, причем программное обеспечение выполняет автоматическое обнаружение отказов и восстановление системы.
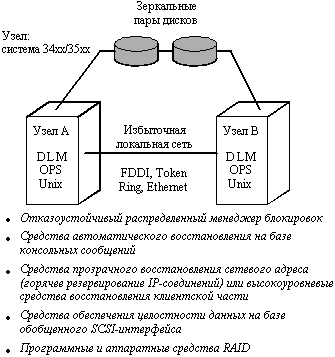
Рис. 11.3. Архитектура двухмашинного кластера AT&T GIS LifeKeeper FRS
При использовании Oracle Parallel Server распределенный менеджер блокировок, входящий в состав LifeKeeper, позволяет параллельной базе данных работать с системой высокой готовности.
В планы компании входит построение крупномасштабных кластеров для университетских кампусов, а также глобальных кластеров, способных продолжать работу в случае стихийных бедствий.
Sequent была, по-видимому, второй после IBM компанией, осуществившей поставки UNIX-кластеров баз данных в середине 1993 года. Она предлагает решения, соответствующие среднему и высокому уровню готовности своих систем. Первоначально Sequent Hi-Av Systems обеспечивали дублирование систем, которые разделяли общие диски. Пользователи могли выбирать ручной или автоматический режим переключения на резерв в случае отказа. Программный продукт ptx/CLASTERS, который может использоваться совместно с продуктом Hi-Av Systems, включает ядро, отказоустойчивый распределенный менеджер блокировок, обеспечивающий разделение данных между приложениями. Продукт ptx/NQS предназначен для балансировки пакетных заданий между узлами кластера, а ptx/LAT расширяет возможности управления пользовательскими приложениями в режиме on-line. Продукт ptx/ARGUS обеспечивает централизованное управление узлами кластера, а ptx/SVM (распределенный менеджер томов) представляет собой инструментальное средство управления внешней памятью системы. Hi-Av Systems обеспечивает также горячее резервирование IP адресов и позволяет кластеру, в состав которого входят до четырех узлов, иметь единственный сетевой адрес (рис. 11.4).
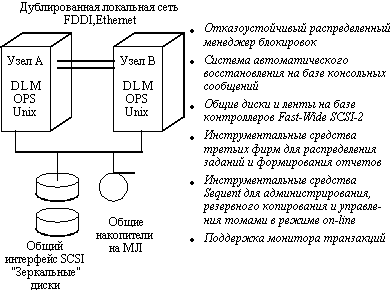
Рис. 11.4. Архитектура двухмашинного кластера SE90 компании Sequent
Компания Sequent одной из первых освоила технологию Fast-Wide SCSI, что позволило ей добиться значительного увеличения производительности систем при обработке транзакций. Компания поддерживает дисковые подсистемы RAID уровней 1, 3 и 5. Кроме того она предлагает в качестве разделяемого ресурса ленточные накопители SCSI. Модель SE90 поддерживает кластеры, в состав которых могут входить два, три или четыре узла, представляющих собой многопроцессорные системы Symmetry 2000 или Symmetry 5000 в любой комбинации. Это достаточно мощные системы. Например, Sequent Symmetry 5000 Series 790 может иметь от 2 до 30 процессоров Pentium 66 МГц, оперативную память емкостью до 2 Гбайт и дисковую память емкостью до 840 Гбайт.
При работе с Oracle Parallel Server все узлы кластера работают с единственной копией базы данных, расположенной на общих разделяемых дисках.
Продукты высокой готовности HP включают дисковые массивы, программное обеспечение Switchover/UX и SharePlex, а также заказные услуги по организации систем, устойчивых к стихийным бедствиям. HP до настоящего времени не поддерживает Oracle Parallel Server, хотя имеются планы по организации такой поддержки. Схема "слабо связанного" кластера HP включает до 8 серверов HP 9000 Series 800, причем семь из них являются основными системами, а восьмая находится в горячем резерве и готова заменить любую из основных систем в случае отказа (рис. 11.5). Для этого в нормальном режиме работы основные системы посылают резервной сообщения (так называемый "пульс"), подтверждающие их работоспособное состояние. Если резервная система обнаруживает потерю "пульса" какой-либо основной системой, она прекращает выполнение своих процессов, берет на себя управление дисками отказавшей системы, осуществляет перезагрузку, переключает на себя сетевой адрес отказавшей системы и затем перезапускает приложения. Весь процесс переключения может занимать от 10 до 20 или более минут в зависимости от приложения.
Продукты Switchover и Shareplex могут использоваться совместно. При этом Switchover обеспечивает высокую готовность, а Shareplex расширяет возможности кластерной системы, предоставляя поддержку общего управления системами, отказоустойчивости при стихийных бедствиях и разделяемого доступа к распределенным ресурсам систем.
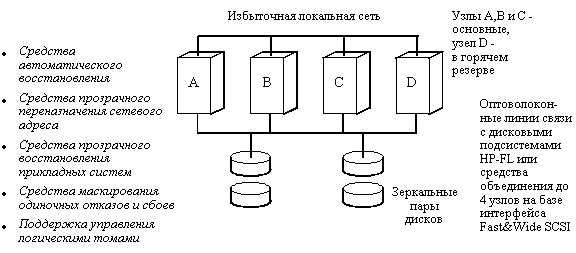
Рис. 11.5. Отказоустойчивая архитектура Switchover/UX компании Hewlett Packard
Хотя Oracle Parallel Server еще не поставлялся в составе кластерных систем HP, компания проводит активные работы в этом направлении. В частности, в последнее время появились новые программные продукты: MC/LockManager - менеджер блокировок, обеспечивающий связь между экземплярами Oracle, функционирующими в кластере, и MC/ServiceGuard - продукт, заменяющий ранее поставлявшийся Switchover.
Продукты HP известны своей высокой надежностью и хорошими показателями наработки на отказ. Дисковые массивы HP-FL поддерживают RAID уровней 0, 3 и 5, а также замену без выключения питания. В настоящее время в системах HP используются устройства Fast/Wide SCSI Disk Array, поддерживающие RAID уровней 0, 1, 3 и 5 с 50 Гбайт общего дискового пространства. В отличие от устройств HP-FL, подсоединение которых осуществлялось с помощью оптоволоконного кабеля, SCSI Disk Array подключается посредством обычных медных кабелей, длина которых может достигать 25 метров.
Новая версия ОС Version 10.0 HP-UX обеспечивает журнализацию файлов и распределенное управление блокировками, что позволяет HP активно конкурировать с продукцией высокой готовности других поставщиков.
Sun Microsystems предлагает кластерные решения на основе своего продукта SPARCclaster PDB Server, в котором в качестве узлов используются многопроцессорные SMP-серверы SPARCserver 1000 и SPARCcenter 2000. Максимально в состав SPARCserver 1000 могут входить до восьми процессоров, а в SPARCcenter 2000 до 20 процессоров SuperSPARC. В комплект базовой поставки входят следующие компоненты: два кластерных узла на основе SPARCserver 1000/1000E или SPARCcenter 2000/2000E, два дисковых массива SPARCstorage Array, а также пакет средств для построения кластера, включающий дублированное оборудование для осуществления связи, консоль управления кластером Claster Management Console, программное обеспечение SPARCclaster PDB Software и пакет сервисной поддержки кластера.
Для обеспечения высокой производительности и готовности коммуникаций кластер поддерживает полное дублирование всех магистралей данных. Узлы кластера объединяются с помощью каналов SunFastEthernet с пропускной способностью 100 Мбит/с. Для подключения дисковых подсистем используется оптоволоконный интерфейс Fibre Channel с пропускной способностью 25 Мбит/с, допускающий удаление накопителей и узлов друг от друга на расстояние до 2 км. Все связи между узлами, узлами и дисковыми подсистемами дублированы на аппаратном уровне. Аппаратные, программные и сетевые средства кластера обеспечивают отсутствие такого места в системе, одиночный отказ или сбой которого выводил бы всю систему из строя.
SPARCclaster PDB Server поддерживает полностью автоматическое обнаружение отказов, их изоляцию и восстановление после отказа, причем обнаружение и изоляция отказа выполняются на разных уровнях в зависимости от отказавшего компонента (системы связи между узлами, дисковой подсистемы, сетевого подключения или целиком узла). При этом процесс восстановления осуществляется достаточно быстро, поскольку в случае подобных отказов не требуется полной перезагрузки системы.
В состав программного обеспечения кластера входят четыре основных компонента: отказоустойчивый распределенный менеджер блокировок, распределенный менеджер томов, программные средства управления обнаружением отказов и управления восстановлением, программное обеспечение управления кластером.
Sun Microsystems выпускает дисковые массивы, обеспечивающие RAID уровней 0 и 1. Ожидается появление поддержки RAID уровня 5. Максимальная емкость дискового массива для SPARCserver 1000 составляет 63 Гбайт при использовании SPARCstorage Array Model 100 и 324 Гбайт при использовании SPARCstorage Array Model 200. Для SPARCcenter 2000 эти цифры составляют соответственно 105 Гбайт и 324 Гбайт.
Линия продуктов высокой готовности компании Data General включает системы, основными свойствами которых являются: полностью автоматическое восстановление без потери данных, конфигурируемые дисковые и ленточные массивы и средства поддержания высокой готовности, встроенные в системное программное обеспечение.
Data General поставляет многопроцессорные SMP-серверы серий AV 5500, AV 8500 и AV 9500. Эти серверы поддерживают работу с отказоустойчивыми дисковыми и ленточными подсистемами CLARiiON, средства автоматической диагностики AV/Alert, инициируемые оператором или автоматически средства переключения на резервную систему, управление внешней памятью в режиме on-line, управление вводом/выводом и быстрое восстановление файлов.
При обнаружении отказа процессора, памяти или компоненты ввода/вывода система автоматически начинает процесс выключения и затем осуществляет собственную перезагрузку с исключением отказавших компонент. Стандартным средством указанных систем является наличие избыточных источников питания.
Максимальная степень готовности достигается при подключении двух серверов к высоконадежному дисковому массиву CLARiiON. Дисковые массивы CLARiiON Series C2000 Disk Array обеспечивают RAID уровней 0, 1, 3 и 5 в любых сочетаниях, до 20 накопителей в одном шасси общей емкостью до 80 Гбайт и возможность замены накопителя без выключения питания. В конструкции дискового массива используются избыточные интеллектуальные контроллеры с дублированными связями, обеспечивающие отказоустойчивость. Ленточный массив CLARiiON Series 4000 поддерживает отказоустойчивое резервное копирование и восстановление. В составе массива используется специальный процессор, реализующий схему расщепления данных, подобную RAID уровня 5. Ленточный массив обеспечивает не только высокую пропускную способность, но и реализует защиту от отказов носителя и накопителя. В действительности, даже при отказе накопителя или картриджа, операции по резервному копированию или восстановлению данных продолжаются без потери данных. В массив можно устанавливать 3, 5 или 7 накопителей. При двухкратной компрессии данных общая емкость ленточного массива может достигать 48 Гбайт.
[Предыдущая глава] [Оглавление]

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
