ЗУ - один из источников машинного "интелекта" - вынуждено постоянно следовать в "кильватерной струе" быстродействия
микропроцессора. Баланс производительности между этими центральными элементами системы в последнее время несколько
выровнялся и не вызывает уже недоуменного вопроса: а точно ли мы подсчитали такты ожидания?
История динамической памяти с произвольным доступом (DRAM, Dynamic Random Access Memory) - один из примеров
отличной проработки удачной идеи, однажды осенившей исследователей.
Как DRAM задерживает работу ПК
Ячейка – базовый элемент памяти
Парадоксально, но динамическая память способна запоминать нолики и единички благодаря паразитной емкости, с
которой электронщики ведут долголетнюю борьбу. Это — квинтэссенция конструкции, смонтированной на базе структуры
комплиментарной технологии металл-оксид-полупроводник (CMOS, Complimentary Metal Oxide Semiconductor ).
По CMOS технологии, благодаря ее несомненным техническим достоинствам, строятся современные чипы быстродействующих электронных элементов с высокой
плотностью упаковки.
Микросхема DRAM содержит множество элементарных ячеек, одна из которых изображена на рис. 1.
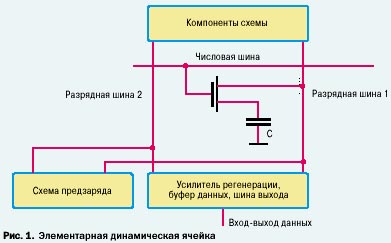
Транзистор в динамической ячейке работает как ключ, управляющий передачей заряда. При записи в конденсатор бита
информации ключ открывается, заряжая конденсатор до определенной величины.
Считывание информации — процесс длительный, включающий подготовительные операции. Вначале специальная схема предзаряда сообщает
потенциал (опорное напряжение) обеим разрядным шинам. Схема также модифицирует ячейку, восстанавливая информационную емкость после
чтения (откуда и название режима работы — чтение с модификацией)).
Далее для доступа к микросхеме памяти из контроллера ОЗУ поступают сигналы управления, которые переводят числовую шину в активное состояние.
При этом на числовой шине ячейки также повышается потенциал, транзистор открывается и замыкает цепь: корпус — числовая шина 1.
Если емкость заряжена, она разряжается на числовую шину, повышая ее потенциал. Между числовыми шинами 1 и 2 возникает напряжение.
Циркулирующий при этом ток создает на выходной шине заряд (единица). Если емкость не была заряжена, то на выходе формируется ток
противоположного направления и с шины данных снимается ноль.
Процесс записи обратен считыванию.
Временных характеристик динамической памяти очень много, но важнейших — три:
время предзаряда памяти — представляет собой задержку, связанную с предварительным зарядом разрядных шин опорным напряжением;
время доступа к памяти — активизация числовой шины, в результате чего на выходную шину данных памяти выкладывается информация;
время цикла — состоит из задержек времени предзаряда и доступа.
Время задержки вывода данных DRAM измеряется величинами от десятков до сотен наносекунд.
Когда процессор "гуляет"
Систему притормаживают не только задержки в «недрах» памяти. Любое обращение к ОЗУ сопровождается передачей в контроллер памяти большой группы сигналов,
осложняющих схемотехнику. Громоздкость сигнального аппарата повышает латентность подготовительного периода цикла обмена данными. О чем идет речь?
В DRAM каждую ячейку можно отыскать по ее адресным координатам, оформленным в строки и столбцы (рис. 2 ).
Все ячейки выводятся на общую числовую шину. Выбор соответствующего адреса строки и столбца позволяет определить место ячейки.
Содержимое нескольких ячеек, объединенных на выходе, образует информационную группу — байт, или слово, и следует на шину данных памяти.
Разрядность внешней шины данных памяти позволяет повысить ее пропускную способность.
Вместе с тем рост быстродействия памяти не возымеет никакого эффекта, если она не способна работать с малыми временными задержками.

Адрес памяти содержит сведения для выбора: байта, банка, строки и столбца. Он поступает в один из портов контроллера ОЗУ,
трансформируется в два адреса — строки и столбца, которые по шине MA попадают в DRAM (рис. 3) с некоторым промежутком времени (ΔT1 на рис. 4).

Контроллер памяти оснащен портом для обмена данными с процессором и еще одним портом — для обмена с устройствами ввода вывода на системной шине.
В современных чипсетах первый порт называется «северным», а другой «южным». С таким же успехом порт AGP может быть назван «западным»…
Поскольку «соискателей» для обмена много, на входе подсистемы имеется арбитр. Этот «строгий привратник» подключает к памяти устройства в соответствии
с приоритетами. На этот процесс также уходит время.
Шина между процессором и контроллером ОЗУ — FSB (Front Side Bus) — тактируется системными синхроимпульсами.
При отсутствии данных в кэш, доступ к ОЗУ можно представить следующим образом.
За время первого и второго тактов синхронизации с шины FSB в контроллер ОЗУ направляются управляющие и адресные сигналы
(# у сигнала свидетельствует о том, что его активный уровень — низкий). Сигналы анализируются и управляют логикой ОЗУ.
Два-три (в зависимости от качества DRAM) синхроимпульса расходуется на запуск схемы дешифрации и выбор соответствующей строки.
Каждый из элементов адресной группы стробируется импульсами сигналов управления RAS# (Row AddressStrobe)и
CAS# (Column Address Strobe) (рис. 4).
При доступе к шинам строк активизируется числовая шина, и все ячейки в данной строке считываются. На разрядные шины поступают
соответствующие потенциалы от конденсаторов. На активизацию шин столбцов, подключение разрядных шин к буферу данных и извлечение
из ячейки памяти данных также требуется два-три такта синхронизации. Еще один такт уходит на доставку данных в буфер данных DRAM.
По такту затрачивается на доставку данных в контроллер ОЗУ и далее — в процессор.
Таким образом, за один цикл обращения к памяти система генерирует, в общей сложности 9–11 тактов синхронизации.
При считывании данных следует учесть еще два такта, расходуемых на восстановление заряда ячеек.
ОЗУ подвержено «склерозу»
После отключения питания ОЗУ, оно напрочь забывает о том, какой оперативной работой занималось до того, как вы нажали на кнопку Power.
Более того, если бы не специально предпринимаемые меры, ОЗУ «умудрилось» бы позабыть, что хранило в своих ячейках с десяток миллисекунд назад.
Это связано с естественным процессом утечки тока с емкости.
В отличие от Statics RAM, динамическая память энергозависима и требует периодического восполнения энергии в паразитных емкостях, что реализуется
стандартной процедурой регенерации. Эта аппаратная процедура инициируется интервальным таймером каждые 15,6 мкс (рис. 5) и выполняется через канал ПДП.
Для регенерации используются только стробы RAS#, а стробы CAS# в процессе не участвуют.
На протяжении этого времени, называемого шагом регенерации, в DRAM перезаписывается целая строка ячеек. Так, на протяжении 8–64 мс обновляются все строки памяти.
Для перезаписи ячеек ОЗУ достаточно перебирать строку за строкой и выполнять «фиктивную» (без вывода данных на магистраль данных памяти) команду чтения.
В этом случае каждая ячейка строки перезапишется через схему предзаряда, а данные не попадут в буферы выхода данных. Шина данных — в высокоимпедансном
состоянии. На модификацию ячейки при считывании расходуется два такта синхронизации.
Очевидно, что процедура регенерации памяти (в классическом варианте) «тормозит» работу системы, поскольку в это время обмен данными с ОЗУ невозможен.
Регенерация, основанная на обычном переборе строк (независимо в какой последовательности) в современных типах DRAM не применяется.
Существует несколько экономичных вариантов этой процедуры — расширенный, пакетный, распределенный и пр.
Регенерация с циклом CBR (CAS Before RAS) более практична. Начало процесса инициируется контроллером ОЗУ и индицируется синхростробами.
Срез строба RAS# помещается в промежуток времени низкого уровня CAS#. Внутренний счетчик перебирает адреса строк для регенерации.
Для выполнения регенерации типа CBR также используется прием «фиктивного» чтения.
Наиболее экономична скрытая регенерация. Каждый рабочий цикл чтения или записи сопровождается удержанием строба CAS# в низкоуровневом состоянии.
На протяжении этого периода времени, уровень строба RAS# нарастает и падает — и микро схема, в соответствии с показанием внутреннего счетчика,
выполняет цикл регенерации. Регенерация протекает не при фиктивном, а при реальном считывании данных из буфера, что не вызывает потерь времени.
Из новых технологий регенерации выделим PASR (Partial Array Self Refresh), применяемую Samsung Electronics в чипах памяти SDRAM с низким уровнем
энергопотребления. Регенерация ячеек выполняется только в период ожидания в тех банках памяти, в которых имеются данные.
Параллельно с этой технологией реализуется и метод TCSR (Temperature Compensated Self Refresh), предназначенный для регулировки скорости регенерации в
зависимости от рабочей температуры.

Как DRAM избавлялась от «вредных привычек»
Архитектурные и технологические решения позволяют минимизировать в DRAM временные задержки (латентность).
Страничная память в интерлив
Не ищите в ОЗУ страницу. Это — логическая категория, существующая для удобства обращения. Память разбивается на четное количество банков,
состоящих из страниц малого объема.
При каждом обращении контроллерпамяти генерирует адресные элементы для доступа к строкам и к столбцам. Между этими операциями существует временной «зазор» (ΔТ1), который, накапливаясь, приводит к высокой латентности. Доступ к памяти в режиме быстрого страничного обмена (FPM, Fast Page Mode) позволяет минимизировать эти потери.
Временной выигрыш при доступе к ОЗУ в режиме FPM состоит в том, что задержки (ΔТ1) возникают лишь при первом доступе к ячейкам страницы. Потери времени на первое обращение к ОЗУ, вне зависимости оттипа DRAM, — «ахиллесова пята» динамической памяти.
Все последующие обращения к столбцам страницы выполняются на уже выбранном адресе строки (открытой строке). Таким образом, адрес строки активен на протяжении всех циклов доступа к строке памяти, а адреса столбцов стробируются импульсами CAS# каждый раз, когда в этом есть необходимость (рис. 6).
Интерлив, или чередование банков, — режим работы, используется всеми модулями динамической памяти. Как известно, каждое последующее обращение к DRAM возможно лишь по завершению переходных процессов в ячейках.
В памяти с интерливом каждая последующая строка выбирается в новом банке, что позволяет ячейкам строки из предыдущего банка восстановить свои кондиции. Увеличение количества последовательно выбираемых банков памяти способствует снижению временных потерь, связанных с перезарядкой емкостей.
Память DRAM FPM и ее модификации — EDO (Extended Data Out) и BEDO (Burst EDO) применялись для группового обмена с ОЗУ. В EDO совмещены по времени операция передачи в ОЗУ адреса и выборка текущих данных. Благодаря этому и удается выиграть пару тактов.

В таблице 1 рассмотрены характеристики некоторых типов памятиDRAM.
Сильные стороны синхронизма
Наиболее радикальные изменения коснулись DRAM с внедрением технологии синхронной динамической памяти (SDRAM, Synchronous DRAM). Для того чтобы синхронизировать память извне, в чип была вмонтирована логика управления. Таким образом, узлы памяти перебрали ряд функций контроллера ОЗУ. В память поступают команды, которые обрабатываются непосредственно в чипе (рис. 7). Синхронизм позволяет микросхеме SDRAM выполнять операции независимо от задержек внешних сигналов управления. Внедрение в чип механизма управления и упрощение схемотехники сократили накладные расходы времени доступа к ОЗУ.
Следовательно, чип SDRAM представляет некое подобие микроконтроллера со встроенными элементами динамической памяти. Микросхема содержит скоростную синхронную шину данных. Для доступа к данным используется трехступенная конвейерная архитектура с интерливом. SDRAM содержит защелки и счетчик адреса столбцов (рис. 8). На открытой строке счетчик последовательно перебирает адреса столбцов, и за каждый такт из защелок данных шлюза ввода вывода в выходной буфер перемещается по восемь байтов данных.
Таким образом, за четыре обращения к памяти считывается полная строка (32 байта). Первое обращение к восьми байтам (при промахе кэш) занимает 9–11 тактов. На каждое последующее расходуется по такту.
Команды загружаются в память SDRAM через программируемый регистр режима. Регистр позволяет запрограммировать память для выбора режима регенерации, автоматической выборки расположенных смежно ячеек памяти в пределах банка, а также применение интерлива. Может быть запрограммирована длина пакета и изменено время задержки стробов CAS#. Настройка этой задержки сказывается на производительности системы.
Конвейерная обработка пакетов данных позволяет исключить из списка временных потерь весьма существенные позиции. Внутреннее выполнение команд снимает с системных шин часть нагрузки и ускоряет процесс доступа к данным.
Выполнение команд обеспечивает оперативную регенерацию в наиболее благоприятные для памяти моменты времени. В SRAM применяется авторегенерация и саморегенерация.
Авторегенерация осуществляется на том банке памяти, к которому на текущий момент обращений нет.
Саморегенерация производится постоянно в любой области памяти за исключениям тех блоков, к которым обращается система с текущим запросом.
Архитектура синхронной памяти имеет модификации.
DDR SDRAM (Double Data Rate SDRAM) — тип памяти, который «роднит» с SDR SDRAM (Single Data Rate SDRAM) общий тракт обработки адресов и сигналов управления, одинако вая конструкция банков памяти и общие методы регенерации (см. рис. 8).
Основные отличия этих технологий (см. табл. 2) — в организации интерфейса данных и системе синхронизации. DDR работает на удвоенной частоте.

SL DRAM (Synchronous Link DRAM) — это также синхронная память. Как и DDR, она синхронизирует данные фронтом и срезом тактового импульса. Управляющая информация, как и данные, передается в память пакета ми, что уменьшает латентность. Память SL содержит расширенный файл программируемых регистров и справляется с большим числом команд.
Что может быть лучше «простой» SDRAM
Новые технологии синхронной памяти, многобитные модули ОЗУ, а также оптимизированные циклы группового обмена данными и пакетная передача сигналов управления действительно позволили повысить производительность системы. Хотя на
доступ к ОЗУ расходуется и меньше тактов синхронизации, процент тактов ожидания процессора по-прежнему велик (рис. 9).
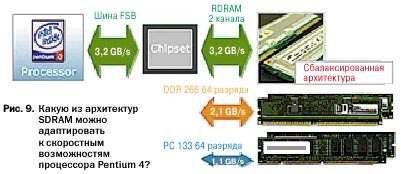
Преодолеть ограничения, присущие архитектуре традиционной DRAM, стало возможно благодаря технологии DR DRAM (Direct Rambus DRAM). Идейными вдохновителями движения Rambus стали корпорации Intel Corporation и Rambus Inc., заключившие в 1996 г. договор о сотрудничестве. Усилия альянса по созданию быстродействующего ОЗУ поддерживаются ведущими фирмами отрасли, такими как Micron, Samsung, Toshiba и др. (рис. 10).

DR — разновидность быстрой динамической памяти с произвольным доступом. Основа архитектуры Rambus — банки памяти, «пронизанные» скоростным каналом. Канал представляет собой электрическую шину, подключающую элементы памяти к контроллеру и разъемам (рис. 11). Канал входит в модуль на одном его конце, проходит через все чипы и выходит на другом конце модуля.
Шина данных синхронизируется отвнешнего источника 400 МГц, как и DDR SDRAM, фронтом и срезом, благодаря чему тактовая частота синхронизации памяти — 800 МГц.
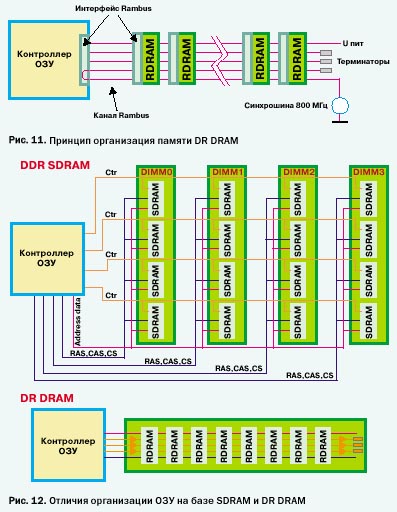
Структурные отличия модулей SDRAM и DR DRAM иллюстрирует рисунок 12.
Значительные усовершенствования в DR DRAM коснулись структуры и организации банков памяти. Если модуль DIMM SDRAM содержит всего лишь 4 банка, то 128 Мбит чип DR DRAM располагает 32 банками. Современные RIMM (Rambus In line Memory Module) могут содержать до 128 банков памяти.
Благодаря конвейеру, поток данных малыми порциями распределяется между банками таким образом, что потери времени при обращении к памяти минимальны. Распределение данных зависит от скорости заполнения каждого банка. Большое число банков позволяет эффективно использовать синхронную внутреннюю высокоскоростную магистраль данных.
Два канала данных (каждый шириной по байту) позволяют получить пиковую пропускную способность выходной шины данных до 3, 2 Гб/с. В дальнейшем для работы DR DRAM с процессором Pentium 4 планируется использовать ускоренную системную шину (533 МГц), разрабатываемую Intel. В планах альянса: к 2002 г. адаптировать DR DRAM для работы в соответствии со спецификацией PC1066, а к 2005 г. — PC1200. Таким образом, в 2005 г. планируется на базе 0,12 мкм технологии выпустить 32/64 разрядные модули ОЗУ с пропускной способностью памяти DR DRAM 9, 6 Гб/с.
На что способноОЗУ вашего ПК?
Быстродействие ОЗУ зависит не только от архитектурных и конструктивных особенностей модулей памяти, но также и от режимов обмена, показателей центрального процессора, чипсета и прочих системных устройств, влияющих на синхронизм обмена и латентность.
Что следует учесть для определения быстродействия SDRAM в следующих режимах:
кэш попадание;
кэш промах с выборкой из текущей строки;
кэш промах с выборкой из другой строки.
В третьем, наиболее жестком, режиме требуется восстановление заряда ячеек предыдущей строки и выбор новой, текущей. На этот процесс (precharge time) расходуется два дополнительных такта.
В таблице 3 рассмотрены некоторые задержки, характерные для отмеченных режимов и определено быстродействие памяти на шине PC133.
Таблицы 3,4
Быстродействие ОЗУ повышается, если чипсет работает с ОЗУ и процессором синхронно и согласованно (см. табл. 4). Синхронизм между шинами памяти и процессора обеспечивает оптимальный, скоростной режим работы системы. Если частоты на шинах отличаются, данные, пересылаемые через чипсет, буферизируются. Для согласования скоростей на шинах требуются дополнительные такты ожидания.
Таким образом, недостаточно оценивать быстродействие ОЗУ, руководствуясь только конструктивными и технологическими достоинствами микросхем и модулей памяти. Немалое влияние на показатели производительности оказывают характеристики системных устройств — центрального процессора и компонентов подсистемы памяти. Скорей всего, оптимальным решением может стать интеграция в одном модуле компонентов, изображенных на рис. 3.




 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС