2004 г.
Серверные технологии: две стороны одной медали
Александр Дудкин
«Экспресс-Электроника», #12/2003
Мы стали очевидцами увлекательных событий, происходящих на рынке процессоров: сегодня настольные чипы перенимают особенности своих серверных и мобильных собратьев. В результате 64-разрядные технологии пошли в массовый сектор. Вполне справедливо, что эра 32-разрядных процессоров закончилась и будущее - за 64-разрядными системами.
Действительно, после выпуска первого 64-битного настольного процессора можно было решить, что в ближайшее время все системы перейдут на 64 бит - столь напористо и активно компании-производители процессоров продвигали новые 64-разрядные чипы. Сложилось мнение, что Barton - это последнее ядро для процессора Athlon XP, который закроет линейку 32-битных процессоров для AMD, а Pentium 4 в своей последней модификации - Prescott - станет последним 32-разрядным процессором Intel. На поверку оказалось: это и правда, и заблуждение. Да, на самом деле завершается время 32-разрядных систем, но, похоже, и Intel и AMD всеми силами хотят оттянуть этот момент, насладиться им и выжать из него все по максимуму. И неудивительно: в запасе имеются 90- и 65-нм проектные нормы производства процессоров - надо же их куда-то применить. В этом материале мы попытаемся рассмотреть аспекты внедрения, применения и текущего уровня развития 64-рзрядных процессорных систем.
64 бита - для кого?
Понятно, что 32-разрядные технологии для серверов себя практически изжили. Большие серверы работают все с большими объемами потоковой информации, с большими базами данных и системами автоматизированного проектирования. Нужны ли 64 разряда в рабочих станциях и серверах? Практика показывает, что да. 32-разрядная адресация ограничивает доступный объем памяти в 4 Гбайт. Причем только два из них можно отдать под приложения - 2 Гбайт забирает ОС на свои нужды. Долгое время компания Intel утверждала, что память свыше 4 Гбайт бесполезна в рабочих станциях и серверах. 64-разрядный Itanium рассматривался как узкоспециализированное средство для High Performance Computing (HPC). В связи с этим до сих пор многие серверы начального уровня строятся на базе Pentium 4 или Xeon DP. Сейчас отношение к Itanium 2 изменилось - он стал продвигаться на рынок как универсальное решение. Видимо, это связано с необходимостью продвигать новую версию процессора Itanium 2 Madison.
В то же время отказываться от уже отлаженных технологий производства 32-разрядных процессоров Xeon компания Intel тоже не собирается. С успехом выпускаются новые версии Intel Xeon. В ближайшем будущем их производство перейдет на новый техпроцесс. То, что серверная сфера для Intel является приоритетной, очевидно. Ведь именно от продаж серверных технологий компания получает наибольшие доходы. Причем, чем крупнее сервер, тем больше от него прибыль.
Несмотря на то что компания Intel четко дифференцирует 32- и 64-разрядные платформы и указывает на их несовместимость, ни для кого не секрет, что она при этом допускает возможную интеграцию 64-битных расширений в существующие 32-разрядные серверные процессоры. Более того, подобные разработки уже имеются. Так что, с одной стороны, Intel продвигает две независимые линейки продуктов, а с другой - делает попытки пойти по пути AMD и создать гибрид x86-совместимого 64-разрядного процессора.
В такой ситуации положение AMD кажется более выгодным: компания предлагает единственное и достаточно серьезное решение, совмещающее 32- и 64-разрядные возможности в одном. Х86-64, на котором основаны Athlon FX/64 и серверный Opteron, позиционируются как решения для HPC, рабочих станций и высокопроизводительных настольных компьютеров. Главные преимущества AMD x86-64 касаются аппаратной поддержки как существующих 16/32-битных приложений, так и 64-разрядных. Это относится и к операционным системам: на K8 можно запускать любые существующие и будущие ОС. Соответственно, не возникает привязки к программному обеспечению и отсутствует необходимость перекомпиляции существующих приложений - ведь именно это на данный момент больше всего волнует потребителя. Второе преимущество касается вышеупомянутого ограничения доступной оперативной памяти. Теперь без каких-либо архитектурных изменений поддерживается адресация 264 памяти, что позволяет обойти ограничение в 4 Гбайт памяти и 2 Гбайт на процесс. Именно поэтому изначально ядро K8 выглядит более убедительным с точки зрения своих перспектив.
Из чего выбирать:
Для начала давайте посмотрим, какие серверные технологии на данный момент мы имеем. Что касается компании AMD, на всех фронтах оборону держит Opteron, ранее известный под кодовым названием SledgeHammer. Он предназначен почти для всех серверов, имеющих от 1 до 8 процессоров. Для серверов начального уровня с 1-2 процессорами пока используется Athlon MP (Barton MP). Оба они выполнены по 0,13-мкм техпроцессу.
Ситуация с Intel более запутана. На первый взгляд, все основные требования к серверам выполняют нынешние Xeon. Причем, последний выпускается в двух версиях - Intel Xeon (DP) для двухпроцессорных конфигураций и Xeon MP для многопроцессорных систем. И только для HPC-систем предусмотрены процессоры Itanium 2, имеющие узкую сферу применения.
Современные процессоры Xeon основаны на архитектуре NetBurst. Причем Xeon DP во многом похож на своего настольного брата Northwood, в то время как Xeon MP от них сильно отличается. Фактически Intel Xeon DP не что иное, как хорошо знакомый нам Pentium 4 на ядре Northwood, но с аппаратно активизированной поддержкой двухпроцессорности (APIC). На те же мысли наводит и определение наличия APIC программами идентификации, скорее всего, эта возможность просто "залочена", как это было с Hyper-Threading. Свое начало линейка Xeon ведет от ядра Foster, выполненного по техпроцессу 0,18 мкм. Foster имел частоту до 2 ГГц, кэш второго уровня 256 кбайт и системную шину с частотой 400 МГц. Второе поколение Xeon было объявлено на IDF '2002. Новое ядро, выполненное с 0,13-мкм технормами, назвали Prestonia. На этом ядре процессоры и выпускаются до сих пор. Совсем недавно был объявлен Xeon Prestonia с частотой 3,20 ГГц и 533-МГц системной шиной. В чип интегрирована кэш-память L3 объемом 1 Мбайт (модели с частотой менее 3 ГГц имеют кэш 512 кбайт). Кэш L2 - 512 кбайт. Все модификации предназначены для использования с двухканальной памятью DDR. Для Prestonia используются наборы микросхем Intel E7501, E7505, ServerWorks GC-LE и GC-HE. В партиях от 1000 штук процессор стоит $851,что даже меньше, чем Pentium 4 Extreme Edition.
Что касается Xeon MP, он также впервые был выпущен на базе ядра Foster MP по 0,18-мкм техпроцессу. В конце 2002 года в свет вышло его второе поколение, известное под кодовым именем Gallatin. Совсем недавно была выпущена версия с частотой ядра 2,80 ГГц. Частота системной шины составляет 400 МГц, а кэш L2 традиционно 512 кбайт. Эта версия имеет кэш третьего уровня объемом 2 Мбайт (у предыдущих версий объем составлял 1 Мбайт). Переход на новый технологический процесс 0,13 мкм позволил значительно повысить частоту и увеличить кэш L3, видно, ранее это нельзя было сделать из-за сильного разогрева процессора. Xeon MP предназначен для 4-8 процессорных конфигураций. Кэш-память третьего уровня в мультипроцессорных чипах нужна, чтобы "развязать" ядро и системную шину (FSB). В отличие от кэш-памяти L2, которая является синхронной (то есть при ее заполнении процессор простаивает, ожидая тактов системной шины), кэш-память третьего уровня асинхронная, что позволяет процессору работать при ее заполнении. Для мультипроцессорных CPU наличие емкого кэша L3 важно еще и потому, что системная шина у процессоров общая (а их на ней может сидеть до восьми штук), то есть соседние процессоры не будут простаивать в вычислениях, пока один из них извлекает данные из системной памяти. Кэш-память с отслеживанием исполнения (L1, 12 кбайт микрокоманд) обеспечивает ускоренный доступ к декодированным микрокомандам и увеличивает пропускную способность конвейера, кэш-память данных L1 (8 кбайт) уменьшает задержки в работе блока быстрого исполнения благодаря применению новейших технологий доступа, кэш-память L2 с улучшенной передачей данных ускоряет доступ к данным сервера за счет точной синхронизации с кэш-памятью данных L1 и блоком быстрого исполнения. Интегрированная кэш-память L3 в сочетании с быстрой системной шиной формирует высокоскоростной канал обмена данными с системной памятью. Кэш-память L1 с отслеживанием выполнения команд хранит до 12 000 декодированных микроопераций в порядке их выполнения. Это увеличивает производительность за счет исключения декодера из системы основных команд и делает более эффективным использование кэш-памяти, так как команды, имеющие ответвления, не отсылаются в память. В результате удается передавать больший объем команд в исполнительные блоки процессора и уменьшать общее время, требуемое на возврат из неправильно предсказанных ответвлений. Кэш-память второго уровня с улучшенной передачей данных состоит из 256-битного интерфейса, передающего данные на каждый такт частоты ядра процессора. Максимальная пропускная способность подсистемы кэш-памяти этих процессоров составляет 51,2 Гбайт/с. Имеется две блока арифметической логики, работающие на удвоенной частоте, что позволяет выполнять команды за половину такта. Все Xeon заключаются в 603/604-контактный корпус FC-mPGA2P/INT-mPGA. А вот цена Xeon MP поражает. Возможно, это сделано для того, чтобы стоимость Itanium 2 выглядела более привлекательно.
Перейдем к тяжелой артиллерии. Первый 64-разрядный процессор именовался Merced, но впоследствии был наречен Itanium. Он имел частоту до 800 МГц, частоту системной шины 266 МГц и выпускался по технормам 0,18 мкм. Кэш-память была 32, 96 кбайт и 2/4 Мбайт первого, второго, и третьего уровня соответственно. Это положило начало архитектуре явного параллелизма - EPIC. Данный процессор не прижился и вскоре был сменен ядром McKinley, названным Itanium 2. Он был значительно оптимизирован, частота ядра перевалила за 1 ГГц, шина данных возросла по частоте до 400 МГц. Он все также выпускался по 0,18-мкм техпроцессу и имел форм-фактор Slot M. Летом этого года Intel представила третье поколение Itanium на ядре Madison. На данный момент выпущены версии с частотой 1,5 ГГц и кэш-памятью L3 6 Мбайт и 1,4 ГГц с кэшем 4 Мбайт. Кэш-память второго уровня невелика - 256 кбайт, а L1 - 32 кбайт на данные и команды. В сентябре выпущена версия Madison с частотой 1,4 ГГц и кэшем L3 объемом 1,5 Мбайт, что значительно снижает стоимость CPU до $1172. Используется 128-разрядная системная шина с частотой 400 МГц. Процессор выполняется по 0,13-мкм техпроцессу, напряжение ядра составляет 1,3 В. Несмотря на вдвое больший объем кэша L3, площадь кристалла уменьшилась до 374 мм2 (против 421 мм2 у McKinley). Энергопотребление осталось примерно на том же уровне - около 130 Вт. Интересно, что сам кристалл процессора содержит только 25 млн транзисторов, в то время как четыре чипа кэша L3 имеют 75 млн транзисторов каждый.
У Madison есть урезанная версия, обладающая пониженным энергопотреблением и оптимизированная для рабочих станций с высокой плотностью монтажа Itanium 2 LV. Носит она кодовое наименование Deerfield, выпускается с частотой 1 ГГц, кэшем L3 1,5 Мбайт и потребляет всего лишь 62 Вт. Его цена всего лишь $744.
Архитектура Itanium 2
Новый процессор - это нечто среднее между традиционной архитектурой RISC для рабочих станций и серверов и CISC для настойных компьютеров. В основу архитектуры положена концепция EPIC (Explicitly Parallel Instruction Computing - вычисления с явным параллелизмом команд). Проект, собственно, включает разработку принципиально новой архитектуры 64-разрядного набора команд и оптимизирующих компиляторов. Новая архитектура в основном полагается на новый вид представления команд, а также их новый принцип следования, обработки и выполнения. Аппаратное обеспечение здесь играет отнюдь не первостепенную роль. Основная нагрузка по оптимизации потока команд ложится на компилятор, который является посредником между исходным кодом выполняемого приложения и внутренними исполняемыми командами процессора. Этот компилятор очень хорошо "знает" аппаратную структуру нового CPU и формирует потоки команд, оптимизированные для их параллельного выполнения и сохранения результатов. И все это при сохранении должного уровня производительности! Но у данного подхода есть и очевидный минус: приложения, написанные для текущих моделей CPU, могут не столь эффективно распараллеливаться в будущих моделях из-за жесткой привязки компилятора к существующей архитектуре. В архитектуре EPIC команды объединяются в последовательности, называемые связками (bundles), объединяющими по три команды, которые могут быть выполнены последовательно на одном исполнительном устройстве. Таким образом, выполнение команд на одних исполнительных устройствах не зависимо от выполнения команд на других. Для этого сам процессор также "укомплектован" соответствующим образом.
В процессоре имеется шесть исполнительных конвейеров небольшой длины - по восемь стадий. Процессор может выполнять одновременно две связки команд. Каждая команда представляет собой несколько связанных с загрузкой или выгрузкой операндов, выполнением арифметических или логических действий инструкций. Itanium 2 содержит по 128 64-разрядных целочисленных и 82-разрядных регистров для инструкций с плавающей запятой. Есть еще 64 однобитных регистров для предсказания ветвлений и 8 регистров с адресами переходов. Регистры выделяются динамически, а если их не хватает, часть регистров записывается в системную память и становится адресуемыми (переназначение регистров). Исполнительных блоков в процессоре Itanium 2 тоже достаточно много: шесть блоков для целочисленной арифметики разрядностью 64 бита, шесть блоков для обработки упакованных форматов данных, два 82-разрядных FPU c поддержкой SIMD-инструкций и FMAC, четыре блока для загрузки и сохранения операндов. В общем, все сделано с учетом как можно большего параллелизма.
В процессоре есть блоки предсказания ветвлений, блоки обработки исключительных ситуаций, проверки зависимости инструкций, слежения за производительностью и т. д. Для выполнения инструкций архитектуры IA-32 имеется отдельный блок, который занимается распределением ресурсов процессора (регистров, исполнительных модулей) для поддержки старого набора команд. То есть вся основная работа происходит на уровне кэша L1, блока выборки и декодирования команд и буферов, которые формируют потоки инструкций на соответствующие исполнительные устройства. При этом определяется тип команды, ее зависимости, наличие итераций и т. д., после чего формируются потоки и связи инструкций. Таким образом, разработчикам удалось избавиться от изменения последовательности команд и их распределения. После этих операций загружается стек, и связки поступают на выполнение с учетом ветвлений.
Подсистема кэширования тоже выполнена интересно: у Itanium 2 есть два кэша первого уровня - один для целочисленных операндов объемом 16 кбайт, второй - для инструкций. Если процессор выполняет операции с плавающей запятой или не находит данных в кэше L1, он обращается к кэшу второго уровня объемом 256 кбайт. Если данных и там не найдено, производится обращение к кэшу третьего уровня, который в свою очередь "общается" с оперативной памятью. Itanium 2, имея 50-разрядную шину адреса, работает с 250 байт ОЗУ.
Теперь о системной шине. Она 128-разрядная, имеет частоту 400 МГц, построена по технологии AGTL+, рассчитана на подключение четырех процессоров, обеспечивает обнаружение и исправление ошибок по методу ECC.
В целом, процессор Itanium 2 по уровню параллелизма, объему кэша, пропускной способности шины и другим параметрам превосходит практически любой другой настольный или серверный процессор. Но проблема Itanium 2 состоит в том, что он показывает высокую производительность только в том случае, если программное обеспечение подготовлено специальным полностью 64-разрядным компилятором.
IA-64 против x86-64
Известно, что просчеты одних чаще всего становятся добычей других и, в конечном счете, плюсами последних. А серьезные, но узкоспециализированные преимущества, зачастую играют злую шутку с их хозяевами. Так получилось и с технологией IA-64, обладающей не только значительными достоинствами перед x86, но и недостатками, которые нивелируют ее достижения.
X86-64 представляет собой просто расширенное и оптимизированное до 64 разрядов ядро K7. Регистры расширены до 64 разрядов, что позволяет адресовать и работать одинаково эффективно как с 16-32-разрядными, так и с 64-раздными командами. Конвейер удлинен, а вместе с ним улучшился и блок предсказания ветвлений, и увеличено окно планировщика. Появилась поддержка набора команд SSE2. Встроенный 144-разряный контроллер памяти DDR333 поддерживает ECC (контроль ошибок). Кэш второго уровня увеличен до 1 Мбайт. Вот таким получился первый 64-битный процессор от AMD. Главный плюс Opteron в том, что вы получаете максимальную производительность 32-разрядных приложений при полной совместимости аппаратного обеспечения с 64-битным кодом. Нет необходимости перекомпилировать существующие приложения - процессор работает под любой ОС с любым ПО. Только для реализации "длинного" режима адресации требуется 64-разрядная ОС и приложения, совместимые с x86-64. Есть и минусы - приходится тянуть весь старый багаж x86 ISA, что сказывается на производительности. Отсутствуют и особые перспективы в плане развития и расширения архитектуры, ее практически невозможно оптимизировать.
Intel, понимая невозможность оптимизации микроархитектуры x86 и необходимость расширяемой архитектуры, пошла кардинально иным путем. IA-64 ISA имеет большое количество преимуществ по сравнению с x86 ISA, но у нее есть и серьезные недостатки. Главный из них - отсутствие встроенной аппаратной поддержки x86-кода и, соответственно, старых приложений. Чтобы работать с 32-битными приложениями, процессоры Itanium используют встроенный аппаратный декодер со всеми вытекающими отсюда печальными последствиями в виде низкого быстродействия при работе с этими приложениями.
Зато IA-64 ISA был сделан очень мощным. К этому Intel шла достаточно долго (EPIC начал разрабатываться в 1994 году). Давайте посмотрим, какие цели ставила компания Intel перед собой. Было решено: единственный способ увеличить производительность приложений - реализовать настоящий параллелизм. И здесь все упирается в порядок исполнения команд. Поскольку для оптимизации под конвейерную структуру раньше приходилось проверять зависимость операндов, наличие итераций, занятость регистров, от этой схемы пришлось отказаться. Настоящий параллелизм можно получить при независимости исполнения инструкций, что позволит одновременно загрузить максимальное число исполняющих устройств (ведь конвейеров в процессоре несколько).
Проблемы современных архитектур
Как правило, очень многие инструкции зависимы: будучи однажды определенными, они используются в циклах, математических операциях, условиях. Причем независимость операндов определяется только при исполнении. Часто конвейеру приходится простаивать в ожидании данных с другого исполнительного блока или из памяти - на это может уйти около 5 тактов. Получить результат за меньшее количество тактов можно - в таком случае используется предсказание ветвлений. Однако это не идеальный выход: при ошибке ветвления приходится перегружать весь конвейер заново. Чтобы инструкции были независимыми, их надо отдельно объявлять, но это, в свою очередь, увеличивает размер исполняемого кода. Современные компиляторы по умолчанию не могут реализовать параллелизм. Некоторая параллельность выполнения реализуется прямо во время компиляции, что далеко от идеала. Такой параллелизм позволяет одновременно выполнять лишь операции одного блока кода (например, одну функцию). Больше всего параллелизму мешают условные переходы, которые встречаются в современных программах очень часто. Переходы не только нарушают последовательность выполнения команд, но и требуют параллельного исполнения заранее для определения исключений.
Зависимость от обращений к памяти также значительно препятствует параллелизму. При предсказаниях необходимо часто сохранять и считывать данные, а регистров на это не хватает, поэтому их приходится перемещать, выбирать из памяти и предварительно загружать, так как загрузкой данных в кэш приложение управлять не может. Более того, зависимость компилятора от количества регистров создает дополнительные ложные зависимости. Зачастую оказывается, что даже независимые инструкции зависят от состояния процессора. Ведь регистры флагов и управления едины для всего процессора. Операции с плавающей точкой создают дополнительные ограничения, поэтому до сих пор программисты старались использовать их как можно меньше.
В современных языках программирования (C++, Java) часто применяются вызовы небольших функций и процедур, которые требуют частой передачи и возврата значений. Для вызывающей и вызываемой функций используются одни и те же регистры, соответственно, их содержание требуется сохранять в памяти. Иногда сохранение и восстановление регистров производится, даже если это и не требуется.
Циклы позволяют организовать хорошее параллельное исполнение. Но для параллельного запуска циклов каждый из них требуется запускать отдельно, а пролог и эпилог цикла сильно увеличивает размер кода, что также неблагоприятно сказывается и на эффективности кэш-памяти.
IA-64 ISA
Для решения этих проблем Intel стала действовать в разных направлениях. Первое связано с созданием архитектуры для новых приложений. Для удачной оптимизации было решено, что процессор должен обрабатывать не команды, а группы команд - связки (instruction bundles), - состоящие из нескольких инструкций определенного типа. Архитектура IA-64 предусматривает хранение трех команд в одной связке, причем каждая связка открывается шаблоном, предписывающим выполнение этой связки определенными исполнительными модулями. Это было сделано для того, чтобы избежать перегруппировки команд, на которую раньше CISC- и RISC-процессоры затрачивали достаточно много времени, чтобы параллельно выполняемые команды не влияли на результаты друг друга. В случае EPIC это делает не процессор, а компилятор: он собирает независимые друг от друга команды в блоки, и процессор может сразу же начинать параллельное выполнение, не заботясь о проверке их совместимости. Тем самым достигается существенное ускорение, но только для тех программ, которые предварительно были обработаны компилятором. Отсюда и получается, что 16- и 32-разрядные программы будут работать со значительно меньшей скоростью.
Новый набор команд сильно упрощен, из него исключены инструкции с высокой латентностью (деления, целочисленного умножения и т. п.). Безусловно, это увеличивает объем кода, поскольку необходима эмуляция сложных команд, но увеличение параллелизма, позволяющего одновременно проводить несколько вычислений, с лихвой покрывает такие потери. Имеются и расширения системы команд. Это новые команды для вычислений с плавающей точкой (команда умножения с накоплением, команды поиска максимума и минимума) и семантически совместимые с MMX мультимедийные команды, производящие параллельные вычисления над восемью 8-битными, четырьмя 16-битными или двумя 32-битными целочисленными операндами. Большинство команд - многооперандные, операции проводятся только над регистрами, а для работы с памятью существует специальная группа команд.
Инструкции имеют унифицированную длину 41 бит и упаковываются в связки по 128 бит для выравнивания. Шаблон в связке описывает, к каким исполнительным модулям направляется каждая из команд, а также границы разделения групп команд. Это сильно упрощает декодирование команд процессором. Связки могут выполняться процессором параллельно, и от того, насколько удачно удается компилятору "распараллелить" исходный код приложения, зависит эффективность выполнения приложения в целом.
Любая команда может быть выполнена задолго до ее истинного месторасположения, при этом она может вызвать исключение (exception). При выполнении такой операции исключение откладывается до точки оригинального месторасположения. В этой точке специальной командой производится проверка на удачность спекуляции. Этот механизм получил название спекулятивного ветвления. Таким образом, проблема предсказания ветвлений решается в рамках новой идеологии более эффективно. Для "отметки" ветвлений после исследования их процессором используются предикатные регистры. Затем, если процессор встречает "отмеченное" ветвление в процессе выполнения программы, он начинает одновременно выполнять все ветви. После того как будет определена "истинная" ветвь, процессор сохраняет необходимые результаты и сбрасывает остальные. Этот механизм позволяет полностью избавится от простых условных переходов, но приводит к необходимости выполнять обе ветви программы одновременно, что может снизить производительность при несбалансированных ветвях программы. Для дополнительного снижения количества ошибок на условных переходах введен ряд оригинальных механизмов: подсказки ветвлений, подсказки предвыборки, переходы по косвенным адресам с использованием регистра ветвлений, адрес в котором используется процессором как подсказка на точку ветвления, специальные команды организации цикла с хорошим предсказанием начала и завершения.
Технология спекулятивной загрузки позволяет заранее загрузить данные из памяти в один из регистров. Механизм регистрового стека позволяет не сохранять лишний раз содержимое регистров при вызове функций. Это достигается тем, что регистры с 32 по 128 являются стековыми и переименовываются при вывозе функций. Их можно использовать для передачи параметров. Механизм "вращения регистров" позволяет параллельно выполнять команды из разных итераций цикла.
Для программной поддержки всего этого Intel предлагает все необходимое ПО для разработки приложений нового типа (со старыми уже ничего не сделаешь). Практика показывает, что после оптимизации приложений можно достичь полуторного прироста производительности. В качестве исходников предлагаются библиотеки MKL и IPP. MKL (Math Kernel Library) предназначена для научных вычислений и оптимизирована как для 32-битных, так и для 64-битных многопроцессорных систем. Основаны они на C/C++ и Fortran. MKL описывает базовые функции BLAS для матриц и векторов. Имеется поддержка упакованных функций и векторых VML для больших массивов данных. Причем библиотека выпускается как под Windows, так и под Linux. Недавно вышел Intel C++ Compiler версии 6. IPP (Integrated Performance Primitives) содержит низкоуровневые программные примитивы, общие для всех процессоров и процессорозависимые функции обработки сигналов, видео, аудио и графики. Поддерживается большое количество типов и массивов данных. Компилятор Intel также создан для Windows и Linux и поддерживает кросс-платформенную компиляцию. Главной его особенностью является возможность автоматической векторизации для NetBurst и программной конвейеризации для EPIC. Он поддерживает автоматическое распараллеливание вычислений, технологию Hyper-Threading и SMP. На уровне компилятора можно организовать предвыборку команд (prefetching). При применении компилятора на различных платформах он поддерживает автоматическое определение процессора. Производительность его не очень сильно отличается от ассемблера!
Assure Thread Analyzer - это автоматический отладчик для многопоточных приложений, поставляемый Intel. Пока что он оптимизирован только под Hyper-Threading, но в будущем сможет также поддерживать кластеры. Intel VTune Performance Analyzer - очень интересная вещь, которая позволяет обнаруживать "узкие места" в приложениях и его причины. Например, он может определить наиболее часто исполняемые операции, вызываемые функции и оптимизировать их местоположение в исходном коде. Он поддерживает 32 и 64-разрядные платформы Java, C#, .NET. Ну что ж, можно сказать, IA-64 - это действительно перспективный рывок в будущее 64-битных систем.
О будущем:
Поговорим о будущем 64-разрядных платформ Intel. Позиция компании не совсем понятна: сначала она упорно утверждает, что Itanium будет широко использоваться только через некоторое время, и вообще 64-разрядные процессоры пока что не особенно нужны и будут применяться лишь в HPC-сегменте. По мнению компании, до последнего времени все серверные нужды удовлетворял Xeon MP. После долгого отрицания необходимости расширения адресуемой памяти более 4 Гбайт Intel все же ввела медленные PAE (Physical Address Extensions), которые позволяли Xeon адресовать до 64 Гбайт. Но теперь началось достаточно быстрое продвижение Itanium 2. Следующее поколение 64-битных процессоров от Intel - чипы с кодовыми названиями Madison 9M, - появятся на рынке в 2004 году. С этими чипами картина прояснилась еще прошлой осенью: Madison 9M - это версия процессора с 9 Мбайт кэша L3 и тактовыми частотами от 1,5 ГГц и выше, числом транзисторов более 500 млн.
Гораздо больше подробностей известно о линейке двухпроцессорных серверных чипов Montecito, выпуск которых перенесен с 2004 года на 2005-й. Производиться они, скорее всего, станут по 0,09-мкм техпроцессу. Как ожидается, каждое процессорное ядро чипа будет обладать своим собственным кэшем L1, L2 и L3, суммарный объем кэш-памяти составит не менее 18 Мбайт на корпус, при этом весь конструктив будет содержать порядка 1 млрд транзисторов. Интересно, каким же тогда будет у него тепловыделение?
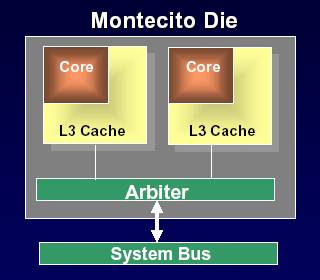
Именно в этих процессорах дебютирует новая технология внутренней "распределительной" (arbiter) шины, предназначенной для управления двумя и более процессорными ядрами в едином корпусе - что-то вроде общего процессорного системного интерфейса с пропускной способностью до 6,4 Гбайт/с и производительностью до 400 млн транзакций в секунду. По словам представителей компании, применение такой шины позволит удвоить объем кэш-памяти, поддерживаемой каждым процессором. В будущем возможно объединение до четырех ядер в одном корпусе.
В области 32-разрядных серверных процессоров, напротив, никакой сенсации не предвидится. Процессор Xeon на ядре Nocona выйдет с поддержкой шины 800 МГц, а изготовляться будет по 0,09-микронному процессу. Фактически, Nocona станет серверным аналогом настольного процессора Prescott, и ее представят во II квартале 2004 года. Для него будет выпущен чипсет Lindenhurst. Этот чипсет сможет поддерживать 800 МГц Quad Pumped Bus, работать с более скоростной памятью, а также поддерживать шину PCI Express и direct connect LAN. А процессор из серии серверных разработок, частота которых уже превысит 3,6 ГГц, под кодовым именем Jayhawk, должен появиться во второй половине следующего года. Чипсет, поддерживающий как Jayhawk, так и Nocona, носит название Tumwater.
Так что, похоже, еще рано говорить о скором вымирании 32-разрядных систем. Компания Intel будет развивать обе линейки. По крайней мере, до 2006 года.

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС

