Выражаем
благодарность компании ASBIS за предоставленные для обзора
процессоры.
В апреле 2005 года корпорация
Intel объявила о выходе двухъядерной платформы, включающей
семейство двухъядерных процессоров Intel Pentium D 8xx и набор
микросхем Intel 955X Express. На сегодняшний день в модельном
ряде двухъядерных процессоров Intel для ПК насчитывается
четыре модели, которые отличаются друг от друга тактовой
частотой, набором поддерживаемых технологий и, конечно же,
стоимостью. В этой статье мы сравним производительность всех
двухъядерных процессоров Intel и выберем самый оптимальный по
соотношению цена/производительность процессор.
Способы увеличения производительности процессора
Гонка тактовых частот, продолжавшаяся на протяжении многих
лет, похоже, окончательно ушла в прошлое. За эти годы в умах
пользователей укоренилось мнение, что именно тактовая частота
процессора является показателем его производительности, однако планы
компании Intel по наращиванию тактовых частот так и остались
планами, и, скорее всего, увидеть процессор с тактовой частотой 10
ГГц нам предстоит весьма не скоро. По всей видимости,
масштабирование процессоров по тактовой частоте оказалось не столь
простой задачей, как предполагалось, и потому при сегодняшних
технологических нормах производства процессоров и малоэффективных
воздушных системах охлаждения добиться линейного масштабирования
тактовой частоты процессоров не удаётся. Осознав, что увеличение
прежними темпами тактовых частот процессоров не представляется
невозможным, нужно было искать принципиально иные технологии
увеличения производительности процессоров. Одновременно с этим
необходимо было (по маркетинговым соображениям) убедить
пользователей в том, что производительность процессора определяется
не только и не столько его тактовой частотой. И первым шагом на пути
к такому «перевоспитанию» пользователей стал отказ компании Intel от
указания в названии процессора его тактовой частоты — на смену
процессорам Intel Pentium 4 3,0 ГГц пришли загадочные обозначения
вроде Intel Pentium 4 560 и т.п.
Давайте разберемся, от чего же в действительности зависит
производительность процессора. Общепринято отождествлять
производительность процессора со скоростью выполнения им инструкций
программного кода. Производительность (Performance) — это отношение
общего числа выполненных инструкций программного кода ко времени их
выполнения:
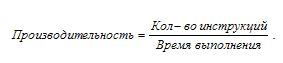
В этом смысле производительность процессора отождествляется с
количеством инструкций, выполняемых за секунду (Instructions rate).
А поскольку одной из важных характеристик процессора является его
тактовая частота, то желательно именно с ней связать
производительность процессора. Это можно сделать, если количество
инструкций, выполняемых за единицу времени, рассматривать как
произведение количества инструкций, выполняемых за один такт
процессора (Instruction Per Clock, IPC), на количество тактов
процессора в единицу времени (тактовая частота процессора):
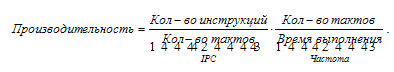
Количество тактов процессора в единицу времени – это и есть
его тактовая частота (Frequency). Таким образом, производительность
процессора зависит в равной степени и от его тактовой частоты, и от
количества инструкций, выполняемых за такт (IPC):
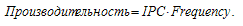
Последняя формула, по сути, определяет два разных подхода к
увеличению производительности процессора, первый из которых связан с
увеличением тактовой частоты процессора, а второй – с
увеличением количества инструкций программного кода, выполняемых за
один такт процессора. Вполне очевидно, что увеличение тактовой
частоты не может быть бесконечным и определяется технологией
изготовления процессора. При этом рост производительности не
является прямо пропорциональным росту тактовой частоты, то есть
наблюдается тенденция насыщаемости, когда дальнейшее увеличение
тактовой частоты становится нерентабельным. Количество инструкций,
выполняемых за время одного такта, зависит от микроархитектуры
процессора: от количества исполняемых блоков, от длины конвейера и
эффективности его заполнения, от блока предвыборки и т.д., а кроме
того, естественно, от оптимизации программного кода к данной
микроархитектуре процессора. Итак, в общих чертах мы выяснили,
почему вполне корректным является сравнение производительности
процессоров на основании их тактовой частоты в пределах одной и той
же микроархитектуры (при одинаковом значении IPC процессоров) и
почему некорректно сравнение производительности процессоров с
различной микроархитектурой исключительно на основе тактовой
частоты. К примеру, основываясь на тактовой частоте, некорректно
сравнивать производительность процессоров с разным размером L2-кэша
или производительность процессоров, поддерживающих и не
поддерживающих технологию Hyper-Threading.
Другим подходом к увеличению производительности процессорной
подсистемы, типичным для серверных решений, является использование
многопроцессорных SMP-конфигураций. В этом случае достигается
параллельное (Thread Level Parallelism, TLP) и в какой-то мере
независимое решение нескольких разных задач или нескольких потоков
одной задачи на нескольких процессорах, что, естественно,
сопровождается приростом общей производительности вычислительной
подсистемы сервера. Впрочем, ожидать адекватного количеству
процессоров роста производительности и в данном случае не приходится
— многое зависит от типа решаемых задач, от реализации в серверной
операционной системе поддержки SMP. Всегда можно найти такое
приложение, которое в двухпроцессорной конфигурации будет показывать
результаты ниже, чем в однопроцессорной, и потому любой
«талантливый» программист вполне сможет свести на нет все
преимущества многопроцессорной архитектуры.
Между тем, кроме перечисленных способов увеличения общей
производительности процессорной подсистемы, существуют технологии,
позволяющие реализовать параллельное выполнение нескольких задач на
одном процессоре. Такая многозадачность реализована в том или ином
виде во всех современных процессорах. Отход от последовательного
исполнения команд и использование нескольких исполняющих блоков в
одном процессоре позволяют одновременно обрабатывать несколько
процессорных микрокоманд, то есть организовывать параллелизм на
уровне инструкций (Instruction Level Parallelism, ILP), что,
разумеется, увеличивает общую производительность.
Технология Hyper-Threading – первый шаг к
многоядерности
Анонсированная в 2002 году компанией Intel технология
Hyper-Threading – пример многопоточной обработки команд. Данная
технология является чем-то средним между многопоточной обработкой,
реализованной в мультипроцессорных системах, и параллелизмом на
уровне инструкций, реализованном в однопроцессорных системах.
Фактически технология Hyper-Threading позволяет организовать два
логических процессора в одном физическом. Таким образом, с точки
зрения операционной системы и запущенного приложения в системе
существует два процессора, что даёт возможность распределять
загрузку задач между ними точно так же, как при
SMP-мультипроцессорной конфигурации.
Посредством реализованного в технологии Hyper-Threading принципа
параллельности можно обрабатывать инструкции в параллельном (а не в
последовательном) режиме, то есть для обработки все инструкции
разделяются на два параллельных потока. Это позволяет одновременно
обрабатывать два различных приложения или два различных потока
одного приложения и тем самым увеличить IPC процессора, что
сказывается на росте его производительности.
В конструктивном плане процессор с поддержкой технологии
Hyper-Threading состоит из двух логических процессоров, каждый из
которых имеет свои регистры и контроллер прерываний (Architecture
State, AS), а значит, две параллельно исполняемые задачи работают со
своими собственными независимыми регистрами и прерываниями, но при
этом используют одни и те же ресурсы процессора для выполнения своих
задач. После активации каждый из логических процессоров может
самостоятельно и независимо от другого процессора выполнять свою
задачу, обрабатывать прерывания либо блокироваться. Таким образом,
от реальной двухпроцессорной конфигурации новая технология
отличается только тем, что оба логических процессора используют одни
и те же исполняющие ресурсы, одну и ту же разделяемую между двумя
потоками кэш-память и одну и ту же системную шину. Использование
двух логических процессоров позволяет усилить процесс параллелизма
на уровне потока, реализованный в современных операционных системах
и высокоэффективных приложениях. Команды от обоих исполняемых
параллельно потоков одновременно посылаются для обработки ядру
процессора. Используя технологию out-of-order (исполнение командных
инструкций не в порядке их поступления), ядро процессора тоже
способно параллельно обрабатывать оба потока за счёт использования
нескольких исполнительных модулей.
Идея технологии Hyper-Threading тесно связана с микроархитектурой
NetBurst процессора Pentium 4 и является в каком-то смысле её
логическим продолжением. Микроархитектура Intel NetBurst позволяет
получить максимальный выигрыш в производительности при выполнении
одиночного потока инструкций, то есть при выполнении одной задачи.
Однако даже в случае специальной оптимизации программы не все
исполнительные модули процессора оказываются задействованными на
протяжении каждого тактового цикла. В среднем при выполнении кода,
типичного для набора команд IA-32, реально используется только 35%
исполнительных ресурсов процессора, а 65% исполнительных ресурсов
процессора простаивают, что означает неэффективное использование
возможностей процессора. Было бы вполне логично реализовать работу
процессора таким образом, чтобы в каждом тактовом цикле максимально
использовать его возможности. Именно эту идею и реализует технология
Hyper-Threading, подключая незадействованные ресурсы процессора к
выполнению параллельной задачи.
Поясним всё вышесказанное на примере. Представьте себе
гипотетический процессор, в котором имеется четыре исполнительных
блока: два блока для работы с целыми числами (арифметико-логическое
устройство, ALU), блок для работы с числами с плавающей точкой (FPU)
и блок для записи и чтения данных из памяти (Store/Load, S/L).
Пусть, кроме того, каждая операция осуществляется за один такт
процессора. Далее предположим, что выполняется программа, состоящая
из трёх инструкций: первые две — арифметические действия с целыми
числами, а последняя — сохранение результата. В этом случае вся
программа будет выполнена за два такта процессора: в первом такте
задействуются два блока ALU процессора (красный квадрат на рис. 1),
во втором — блок записи и чтения данных из памяти S/L.
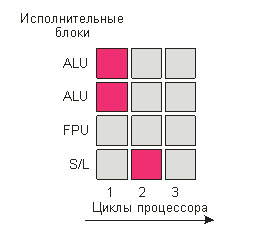
Рисунок 1. Реализация параллелизма на уровне инструкций
(Instruction Level Parallelism, ILP)
В современных приложениях в любой момент времени, как правило,
выполняется не одна, а несколько задач или несколько потоков
(threads) одной задачи, называемых также нитями. Давайте посмотрим,
как будет вести себя наш гипотетический процессор при выполнении
двух разных потоков задач (рис. 2). Красные квадраты соответствуют
использованию исполнительных блоков процессора одного потока, а
синие квадраты — другого. Если бы оба потока исполнялись
изолированно, то для выполнения первого и второго потока
потребовалось бы по пять тактов процессора. При одновременном
исполнении обоих потоков процессор будет постоянно переключаться
между обоими потоками, следовательно, за один такт процессора
выполняются только инструкции какого-либо одного из потоков. Для
исполнения обоих потоков всего потребуется десять процессорных
тактов.
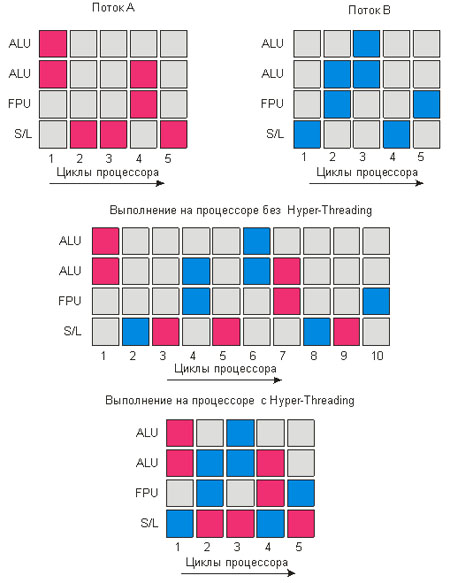
Рисунок 2. Выполнение двух потоков на процессоре без
реализации и с реализацией технологии Hyper-Threading
Теперь давайте подумаем над тем, как можно повысить скорость
выполнения задачи в рассмотренном примере. Как видно из рис. 2, на
каждом такте процессора используются далеко не все исполнительные
блоки процессора, поэтому имеется возможность частично совместить
выполнение инструкций отдельных потоков на каждом такте процессора.
В нашем примере выполнение двух арифметических операций с целыми
числами первого потока можно совместить с загрузкой данных из памяти
второго потока и выполнить все три операции за один такт процессора.
Аналогично на втором такте процессора можно совместить операцию
сохранения результатов первого потока с двумя операциями второго
потока и т.д. Собственно, в таком параллельном выполнении двух
потоков и заключается основная идея технологии Hyper-Threading.
Конечно, описанная ситуация является довольно идеализированной, и
на практике выигрыш от использования технологии Hyper-Threading куда
более скромен. Дело в том, что возможность одновременного выполнения
на одном такте процессора инструкций от разных потоков
ограничивается тем, что эти инструкции могут задействовать одни и те
же исполнительные блоки процессора.
Рассмотрим ещё один типичный пример работы нашего гипотетического
процессора. Пусть имеется два потока команд, каждый из которых по
отдельности выполняется за пять тактов процессора. Без использования
технологии Hyper-Threading для выполнения обоих потоков
потребовалось бы десять тактов процессора. А теперь выясним, что
произойдет при использовании технологии Hyper-Threading (рис. 3). На
первом такте процессора каждый из потоков задействует различные
блоки процессора, поэтому выполнение инструкций легко совместить.
Аналогичное положение вещей наличествует и на втором такте, а вот на
третьем такте инструкции обоих потоков пытаются задействовать один и
тот же исполнительный блок процессора, а именно блок S/L. В
результате возникает конфликтная ситуация, и один из потоков должен
ждать освобождения требуемого ресурса процессора. То же самое
происходит и на пятом такте. В итоге оба потока выполняются не за
пять тактов (как в идеале), а за семь.
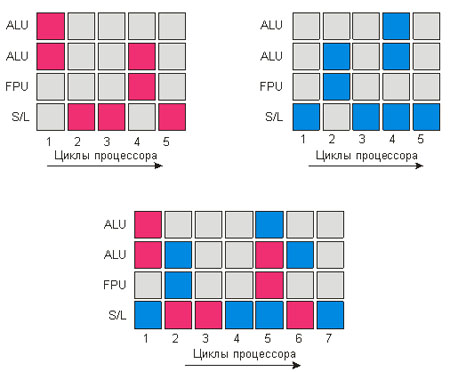
Рисунок 3. Возникновение конфликтных ситуаций при
использовании технологии Hyper-Threading
Продолжение

 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС
