Если смотреть на этот вопрос с чисто технической стороны, то AMD попросту интегрировала практически всю функциональность северного моста в центральный процессор. На блок-схемах в «даташитах» так и обозначается: вот собственно процессорное ядро, вот HT-интерфейс, а вот здесь у него Northbridge. Но «небольшая» технологическая уловка приводит к совсем иной архитектуре компьютера – SUMA, в отличие от традиционной SMP. Перечислим кратко основные преимущества SUMA над «классической» SMP.
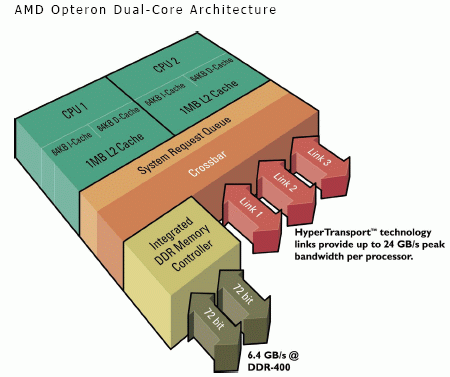
• Основа SUMA – последовательная шина HyperTransport (подробнее об этой шине можно почитать, например, на http://offline.computerra.ru/2004/547/34188). В серверных вариантах процессоров AMD может быть интегрировано до трех независимых линков HT, работающих на частотах до 1 ГГц (2 ГГц с учетом режима передачи данных DDR) и шириной по 16 бит (4 Гбайт/с) в каждом из направлений. Часть HT-линков используется для соединений точка-точка между процессорами, часть задействуется для подключения периферийных устройств (через внешний чипсет, разумеется, поскольку HT связывает один из процессоров с чипсетом тоже как точка-точка). Для программиста HT полностью совместима с традиционной программной моделью PCI; при этом с «логической» точки зрения весь компьютер, напрямую подключаются к единой шине HT, объединяющей все устройства, от центрального процессора и до «распоследней» PCI-карточки, вставленной в обычный PCI-слот.
• В каждый процессор интегрируется контроллер «локальной» оперативной памяти (собственно, по сравнению с одноядерными процессорами AMD64 контроллер памяти почти не изменился). На сегодняшний момент в зависимости от процессора это может быть одно- или двухканальный (у двухъядерников – пока только двухканальный) контроллер памяти DDR 200/266/333/400 (небуферизованной или регистровой, с поддержкой ECC и без неё). Обращения к памяти «чужих» процессоров происходят по шине HyperTransport, причем делается эта «переадресация» запросов абсолютно прозрачно для собственно вычислительного ядра процессора – ее осуществляет встроенный в Northbridge коммутатор (CrossBar), работающий на полной частоте процессора. Этот же самый CrossBar обеспечивает «автоматическую» маршрутизацию проходящих через процессор сообщений от периферийных устройств и других процессоров, включая обслуживание «чужих» запросов к оперативной памяти.
• Шина HT специально оптимизировалась для подобного режима работы со множеством «служебных» сообщений (которые возникают при использовании MOESI, о котором мы расскажем чуть позже) и обеспечивает крайне низкую латентность обращения в «чужую» память и высокую (до 4 Гбайт/с) пропускную способность при обращении к памяти «соседей». Шина является полнодуплексной, т.е. шина позволяет одновременно передавать данные на этой скорости в «обе стороны» (до 8 Гбайт/с суммарно). Модель памяти получается неоднородной (NUMA), но различия в скорости «своих» и «чужих» участков оперативной памяти получаются относительно небольшими.
• Чипсет сильно упрощается: всё, что от него требуется – это просто обеспечивать «мосты» (туннели) между HT и другими типами шин. Ну и, возможно, заодно обеспечивать какое-то количество интегрированных контроллеров. Особенно ярко этот принцип проявляется в серверном чипсете AMD 81xx, поскольку это просто набор из двух чипов – «переходников» на шины AGP и PCI-X и чипа, интегрирующего туннель на «обычную» PCI и стандартный набор периферийных контроллеров (IDE, USB, LPC и проч.). Впрочем, традиционные «большие» чипсеты тоже никто использовать не запрещает: к примеру, NVIDIA успешно выпускает Force3 и nForce4, объединяющие все необходимые туннели и контроллеры в единственном кристалле. Но зато можно, к примеру, установить на плату чип nForce Professional 2200 (решение «всё-в-одном» от NVIDIA для рабочих станций) и добавить к нему «в напарники» AMD 8132, который обеспечит материнской плате поддержку шины PCI-X, которой в nForce Pro 2200 нет. Или использовать несколько чипов nForce Pro 2200, чтобы обеспечить, к примеру, вдвое большее число линий PCI Express. Здесь всё совместимо со всем: любые современные чипсеты для микроархитектуры AMD64, теоретически, должны работать и с любыми процессорами AMD… и любыми «правильно» сделанными «напарниками». И, в частности, все двухъядерные процессоры AMD должны работать со всеми ранее выпущенными чипсетами для процессоров архитектуры K8.
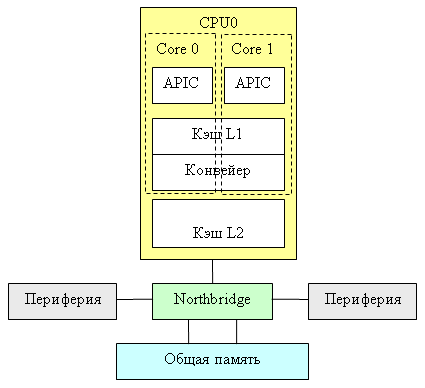
AMD сейчас любит подчеркивать, что её процессоры «специально проектировались в расчёте на двухядерность», но, строго говоря, правильнее было бы говорить, что двухядерность очень удачно ложится на её архитектуру. Каждый процессор K8 является «системой в миниатюре», со своим «процессором» и Northbridge; а двухядерный K8 – «двухпроцессорная SMP-система в миниатюре».
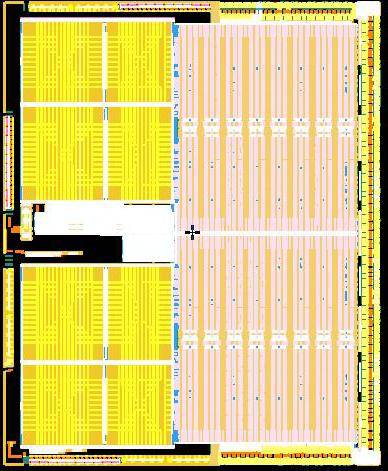
Кристалл двухъядерного процессора AMD
Второе ядро подключается к кросс-бару через общую шину SRI; оба ядра идентичны и, фактически, являются полноценными процессорами; общего кэша L2 нет. То есть если мы, скажем, рассматриваем однопроцессорную двухядерную систему, то вся разница между реализациями AMD и Intel с «технологической» точки зрения заключается в том, что у Intel Northbridge реализован отдельным кристаллом, а у AMD он просто интегрирован в центральный процессор. Но…
…Но интеграция Northbridge в процессор и SUMA-архитектура K8 не просто обеспечивает «более быстрый контроллер оперативной памяти», - она заодно позволяет очень эффективно решать и ряд свойственных многопроцессорным системам проблем.
Мы рассматриваем особенности и различия реализации двухъядерности у недавно вышедших настольных процессоров AMD и Intel. Напомним, что Intel в данном случае пошла по наиболее простому пути, механически объединив два независимых микропроцессора на одном кристалле, тогда как AMD использовала преимущества разработанной ранее для серверов микроархитектуры ядра, в основу которого положено использование встроенного контроллера памяти и линков HyperTransport. И это еще не всё…
Dual-Core AMD vs. Dual-Core Intel: подробности реализации
Интеграция Northbridge в процессор и SUMA-архитектура K8 не просто обеспечивает «более быстрый контроллер оперативной памяти», - она заодно позволяет очень эффективно решать и ряд свойственных многопроцессорным системам проблем.
Во-первых, SUMA решает «проблему общей памяти». Если сравнивать сегодняшние системы (а это, как минимум, двухканальная DDR400) с системами трехлетней давности (одноканальная SDRAM PC133), то прогресс здесь, конечно, достигнут впечатляющий: пропускная способность оперативной памяти увеличилась более чем в 8-10 раз, в то время, как вычислительная мощность центральных процессоров – несколько меньше (в ряде тестов - только в 3-4 раза). Правда, латентность оперативной памяти по меркам процессора остается по-прежнему огромной, но и с этой напастью научились эффективно бороться, используя кэш-память внушительных размеров и механизмы аппаратной и программной предвыборки из памяти. Однако стоит поставить в систему не одно, а два, четыре, а то и восемь процессорных ядер, как проблема «медленной памяти» всплывает с прежней силой – особенно в архитектуре SMP с контроллером памяти в чипсепте:
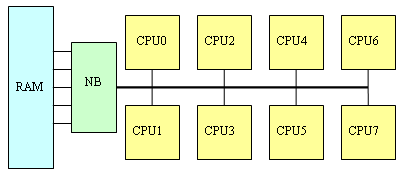
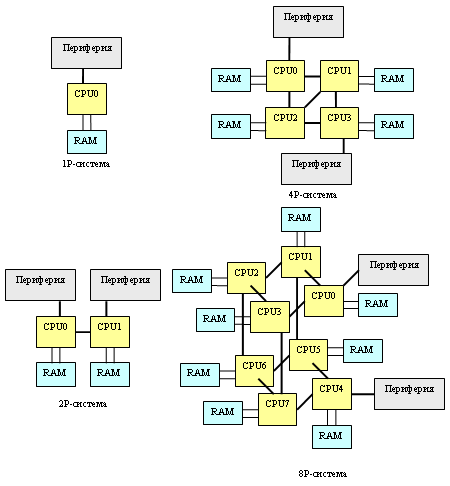
На практике это выливается в «проблему масштабируемости» - когда использование нескольких процессоров не приводит к ожидаемому приросту производительности. Считайте сами: если, например, одиночный процессор 20% своего времени простаивал, ожидая данных из оперативной памяти, то «двушка» будет простаивать 33% времени, а «четверка» - 50%. В пересчёте на общую производительность, 1P-система работает со скоростью 100%, 2P-система – со скоростью 167% (вместо расчётных 200%), а 4P-система – со скоростью 250% (вместо 400%). Более того: получить даже пятикратный прирост производительности в данном случае невозможно в принципе (см. график ниже)! И ничего с этим поделать невозможно. Интересно, кстати, что этот эффект свойственен исключительно многопроцессорным системам: если в примере выше заменить оперативную память на вдвое более быструю, то производительность однопроцессорной системы возрастет лишь на жалкие 11%. (Такие «ужасы» получаются в программах, которые много времени проводят в ожидании данных от памяти (не из кэша, а именно из ОЗУ: если у нас программа почти всегда работает с кэшем – никаких проблем не возникает). То есть если на одном процессоре 80% времени вычислений и 20% ожидания данных из памяти, то на двух получаем «40%» вычислений и «20%» ожидания данных из памяти (в пересчёте к «старым» процентам); выигрыш составляет 100/60 = 167%. И так далее. Ставим вдвое более быструю память – получаем на двухпроцессорной системе «80%» вычислений и «10%» ожидания данных из памяти; выигрыш – 100/90=111%).
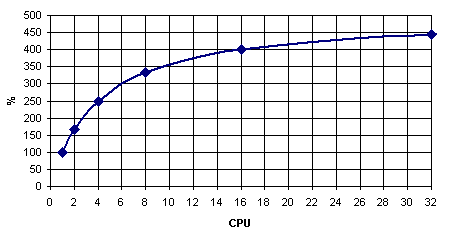
В идеале любая многопроцессорная система должна быть хорошо сбалансирована – слишком быстрая память обходится слишком дорого; слишком медленная – сводит эффект от установки нескольких процессоров к минимуму. То есть если для однопроцессорной системы вполне достаточно двухканальной оперативной памяти DDR (а практика показывает, что это, скорее всего, так), то в «двушку» желательно установить четырехканальный, а в «квад» - восьмиканальный контроллер памяти DDR. Но на практике даже четырехканальный контроллер пока обходится слишком дорого: заикаться же о чем-то большем в «классических» SMP даже не приходится. Правда, четыре канала в следующем поколении чипсетов Intel мы всё-таки увидим (причем контроллеры памяти в них вынесены за пределы Northbridge в виде отдельных микросхем); а через два года, к 2008му, на рынке должна появиться серверная оперативная память FB-DIMM с последовательным интерфейсом доступа к памяти, которая позволит создавать шести- и восьмиканальные- контроллеры памяти.
Но это всё - в SMP: а вот в NUMA (типа AMD-шной), где двухканальный контроллер памяти интегрирован в каждый процессор, суммарная производительность подсистемы памяти как раз и возрастает пропорционально количеству процессоров. Правда, у NUMA, как уже было сказано, «свои тараканы» - неоднородность скорости работы различных участков памяти. В случае новых AMD Opteron можно подсчитать, что «в среднем» пропускная способность памяти в пересчёте на один процессор составляет для 2P-систем порядка 81% (100% в лучшем, 62% в худшем), для 4P – где-то между 62% и 53% (31% в худшем случае). Для 8P-систем всё гораздо неприятнее – без учета особенностей NUMA там не получится «выжать» из подсистемы памяти и 30% её пропускной способности (большинство обращений будут к чужой памяти, причем в среднем каждый линк HT будут занимать по три процессора одновременно). (Суть этих оценок в том, чтобы посчитать устоявшиеся потоки данных, полагая, что они равномерно распределяются по кратчайшим путям между процессорами. Считается, сколько каждому CPU достанется «процентов» от общей пропускной способности линков HT; считаются доли запросов в «свою» память и запросов, проходящих через линки HT. Например, для двухпроцессорной системы линк HT процессору ни с кем делить не требуется, 50% запросов идет в оперативную память, 50% - по линку HT. Всего (6,4 * 0,5 + 4,0 * 0,5) = 5,2 Гбайт/c, т.е. 5,2/6,4 = 81%.)
Впрочем, если сравнивать с аналогичными цифрами для SMP (50, 25 и 12% соответственно), то нельзя не признать, что даже неоптимизированные программы должны работать с памятью на Opteron-ах в несколько раз быстрее, чем на «традиционных» SMP. А если еще вспомнить, что кросс-бар и контроллер памяти AMD K8 работают с поразительно низкой латентностью1, то эффективности работы Opteron с оперативной памятью можно только позавидовать.
Увеличить
Решение «проблемы общей памяти» - далеко не единственное преимущество подхода AMD. Обычные SMP страдают еще и от «проблемы общей шины»: мало сделать быстрый контроллер памяти – нужно еще и обеспечить достаточно быструю передачу полученных из памяти данных к процессору. Что толку с того, что новейший чипсет Intel 955X Express, поддерживает двухканальную оперативную память DDR2 667 МГц с пиковой пропускной способностью 10,7 Гбайт/с, если 800-мегагерцовая процессорная шина не позволяет «прокачивать» более 6,4 Гбайт/с? И ведь это еще не всё: чем больше процессоров мы помещаем на системную шину, тем сложнее обеспечить безошибочную передачу по ней данных (возрастает электрическая нагрузка, усложняется разводка). В итоге если один процессор свободно работает с шиной 800 и даже 1066 МГц, то два процессора уже вынуждены ограничиться шиной не выше 800 МГц, а четыре – так и вовсе работают только с шиной 667 МГц и ниже. Вот так всё неидеально получается для SMP. Мегабайты и даже десятки мегабайт кэш-памяти третьего уровня для них не роскошь, а жестокая необходимость.
Intel, правда, нашла достаточно успешный способ отчасти обойти эту проблему, используя в новейших многопроцессорных системах сразу две независимых процессорных шины. Но в неоднородной AMD-шной SUMA-архитектуре этой проблемы-то вообще нет! И хотя два ядра в двухядерниках AMD разделяют общую шину SRI, работает эта шина все же, как и кросс-бар, на полной частоте процессора, как и вообще все его «внутренние» шины. То есть ничем не отличается, скажем, от шины, соединяющий между собой его кэш-память различных уровней. В итоге эта «общая» шина у AMD получается настолько быстродействующая, что ядра друг другу практически не мешают – их ограничивает только пропускная способность оперативной памяти, да ведущих во «внешний мир» линков HyperTransport.
Когерентность кэш-памяти
Да, текущие двухъядерные процессоры AMD и Intel не имеют «общей» кэш-памяти, используя которую одно ядро могло бы увеличивать свою производительность за счёт другого. Можно даже встретить мнение, что, мол, ничего принципиально интересного поэтому в двухъядерниках AMD нету. Но процессоры архитектуры K8 способны эффективно «лазить» в кэш-память своих соседей, не обращая внимания на то, что кэши у них раздельные! Просто нужно обратить внимание на скромную строчку в перечне характеристик кэша – где в графе «протокол поддержания когерентности кэшей» у процессоров AMD записано «MOESI».
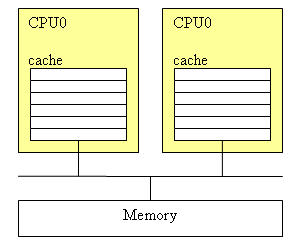
Что вообще такое «протокол поддержания когерентности кэшей»? Пусть, например, у нас процессор CPU0 произвел какие-то вычисления и записал полученный результат в оперативную память. Поскольку у CPU0, разумеется, есть «своя», персональная кэш-память (хотя бы первого уровня), то запись данных производится не в «тормозную» оперативную память, а в кэш. В случае однопроцессорных систем эта схема замечательно работает… но что будет, если в многопроцессорной системе та же самая ячейка памяти, которую изменил процессор CPU0, для каких-то целей понадобится и процессору CPU1? В «лучшем» случае CPU1 прочитает эту ячейку из оперативной памяти, куда, если повезет, процессор CPU0 уже успеет сохранить её новое значение. В худшем – эта ячейка (с устаревшими данными) окажется в его кэше и CPU1 даже не будет пытаться выяснить, изменилось ли что-нибудь с тех пор, как он в последний раз эту ячейку из оперативной памяти прочитал. Всё вместе называется «проблемой когерентности кэшей», а методы её решения – как раз и называют соответствующими «протоколами».
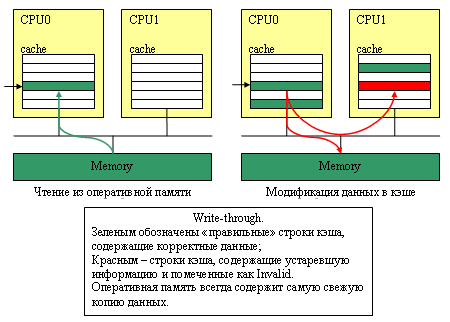
Как эту проблему решают? Простейший протокол поддержания когерентности – это так называемый Write-Through, когда любые изменения сразу же записываются (write through cache) не только в кэш-память, но и в оперативную память компьютера; причем остальные процессоры как-то об этом знаменательном событии информируются. Например, если используется общая шина, то другие процессоры просто «подслушивают» (snoop), что текущий «владелец» шины по ней пересылает и, зарегистрировав, что CPU0 выполняет операцию записи в память, обновляют «свои» записи в кэше. Обычно, чтобы сэкономить время - просто помечают, что соответствующие строки в кэше отныне «неправильные» (Invalid) и при обращении к ним данные необходимо брать не из кэша, а из оперативной памяти. Схема достаточно простая... но неэффективная: запись данных в оперативную память – далеко не быстрый процесс.
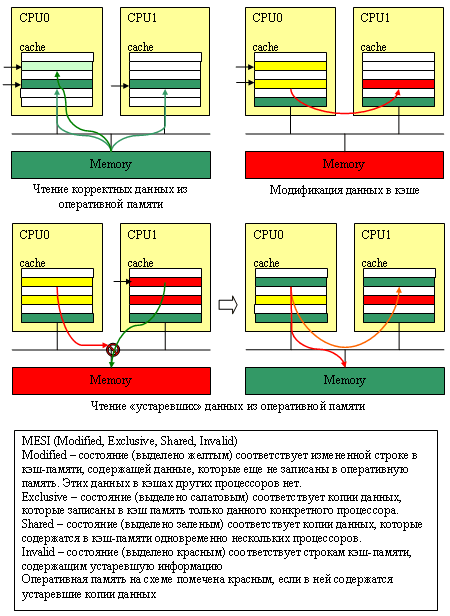
Но зачем разбазаривать зря ресурсы компьютера (пропускную способность шины и оперативной памяти), сохраняя малейшие изменения в медленной оперативной памяти, если вся эта «обновленная» информация может еще десять раз обновиться, прежде чем она понадобится кому-то кроме «владеющего» этой информацией процессора? А ведь если поразмыслить, то работа нескольких процессоров одновременно с одним и тем же участком оперативной памяти – явление исключительное: в подавляющем большинстве случаев каждый процессор занимается обработкой «своего» участка и лишь изредка – обращается к участку «чужому»2. Именно эта идея положена в основу протокола MESI. Использующий его процессор, четко различает кэш-строки, которых заведомо нет в кэшах других процессоров (они помечаются как Exclusive) и «общие», присутствующие более чем в одном кэше (они помечаются как Shared). Если изменяется Shared-строка, то «соседям» по компьютеру передается сигнал-требование проверить свои кэши и, если что, сделать напротив своих записей в кэшах пометку «неправильно» (Invalid); если изменяется Exclusive-строка (а как уже говорилось, вероятность этого события очень велика), то делать эту достаточно трудоемкую операцию нет необходимости. В любом случае строка помечается как Modified, но попыток эту самую строку немедленно записать в оперативную память не предпринимается. Зато все процессоры бдительно наблюдают за всеми операциями чтения данных из памяти и если один из процессоров замечает, что его сосед пытается прочитать строчку памяти, которая в его кэше помечена, как «Modified», то он прерывает эту операцию, сохраняет изменения в оперативной памяти, снимает со «своей» кэш-строки «галочку» Modified и только после этого разрешает вызвавшему «проблему» процессору завершить операцию чтения. В итоге «типовые» операции с кэш-памятью в MESI происходят практически с той же скоростью, что и в single-системе.
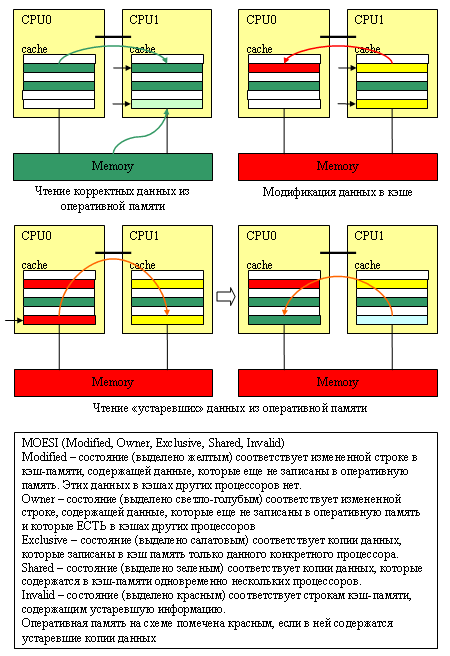
А что же AMD? AMD использует всё тот же MESI, но только доработанный таким образом, чтобы процессоры могли эффективно использовать данные из кэш-памяти друг друга. В MESI процессоры почти не используют кэши своих соседей: в лучшем случае, чтение обновленных данных из памяти производится при выгрузке этих данных в память «соседом». В протоколе же MOESI любая операция чтения сопровождается проверкой кэшей соседей – если нужные данные находятся в одном из них, то и читаются они прямо оттуда; причем сохранение этих данных в оперативную память при этом не производится. Просто «владелец» этой памяти делает у себя «зарубку» Owner3 напротив соответствующей строки кэш-памяти. Мы убиваем двух зайцев одним выстрелом: не производим ненужных записей в оперативную память и эффективно используем память «соседа». В итоге в двухядерных процессорах кэш-память первого и второго уровней «соседнего ядра» может работать как кэш-память третьего уровня (L3); а кэш-память «чужих» процессоров в многопроцессорной системе – как кэши четвертого уровня. Конечно, это не «полноценный» кэш L3/L4 и уж точно – не полноценный разделяемый L2 (поскольку самостоятельно загрузить «соседа» своими данными ядро процессора не может – оно может только надеяться, что «сосед» тоже эти данные будет использовать), однако свою прибавку к производительности, безусловно, MOESI должен обеспечивать. Только не следует думать, что в Intel не могут реализовать аналог протокола, предложенного еще аж в 1986 году (и определенные варианты таки присутствует в Itanium-системах и некоторых других ядрах) – просто для систем с общей системной шиной никаких преимуществ по сравнению с MESI он не предоставляет. Что просто перебросить по этой медленной общей шине данные от одного процессора к другому, что эти данные заодно и в оперативную память записать – разницы почти никакой. А вот для процессоров AMD, у которых ядра и процессоры связаны между собой интерфейсами, работающими гораздо быстрее обычной оперативной памяти, разница есть и порой она становится весьма ощутимой.
Система на основе Pentium 4 supporting Hyper-Threading
Чтобы всё не выглядело настолько неприглядно для Intel, заметим, что у этой корпорации тоже есть очень сильный козырь в кармане – и называется он Hyper-Threading. Технология виртуальной многопоточности (когда одно физическое ядро изображает из себя несколько «виртуальных») позволяет гораздо эффективнее загрузить исполнительные блоки этих процессоров работой. Мало кто знает, что IPC (количество инструкций, которые можно выполнить за один такт) для этих процессоров в устоявшемся режиме может доходить до четырех. Это не просто много: это очень много даже по современным меркам. Для сравнения, процессоры AMD архитектур K7 и K8 выполняют по 3 (в пике – до 6) инструкций за такт, то есть теоретическая эффективность в пересчете на один мегагерц у Pentium 4 должна быть выше, чем у Athlon 64 и Opteron. Почему КПД архитектуры NetBurst в ряде приложений получается «очень скромным» - вопрос для немаленькой отдельной статьи (да и написано по этому поводу уже очень много), отметим только, что сверхвысокие IPC для Pentium 4 вполне можно увидеть на практике – на тщательно оптимизированных приложениях и тестах типа Linpack-а или Prime 95. Главное – это то, что Hyper-Threading позволяет существующий КПД процессора на 10-25% увеличить: подобная прибавка вполне способна перекрыть и выигрыш от более быстрой подсистемы памяти, и от более быстрой шины и от «более продвинутого» протокола MOESI.
Впрочем, по утверждениям самой Intel, двухъядерность будет значительно эффективнее на тех же задачах, где имеется прирост от использования Hyper-Threading. И это легко понять, если взглянуть на следующие блок-схемы протекания процессов в двуядерной системе и одноядерной системе с Hyper-Threading.
Блок-схемы Hyper-Threading vs Dual Core
Блок-схема 1. Pentium4 With HT. Two Floating Point Threads
Блок-схема 2. Pentium D. Two Floating Point Threads
Блок-схема 3. Pentium4 With HT. Integer and Floating Point Threads
Блок-схема 4. Dual Core Pentium Processor. Multiple Integer and Floating Point Threads
Тем не менее, для процессора Intel Pentium Extreme Edition, имеющего обе эти «фичи» и видимого в операционной системе как четыре логических процессора, определенные сомнения в эффективности совместного использования двухъядерности и Hyper-Threading могут возникнуть, хотя профессиональные приложения, показывающие мощный прирост и в этом случае, все же существуют (например, Cinema 4D и другой 3D-рендеринг).
Технологические подробности
Разобравшись с тем, почему «двухядерность» (и многопроцессорность вообще) лучше или хуже ложится на архитектуры AMD K8 и Intel NetBurst, перейдем к рассмотрению, скажем так, сугубо технологических деталей. Начнем, пожалуй, снова с более простого случая Intel.
На сегодняшний момент все двухъядерные процессоры Intel выпускает на основе ядра Smithfield, которое, как уже упоминалось, является просто парой обыкновенных одноядерных процессоров Pentium 4 Prescott (наследников степпинга E0), объединенных в виде единого кристалла. Поддерживаются SSE/SSE2/SSE3, 64-битные расширения EM64T, энергосберегающая технология EIST, технология защиты от вирусов XD-bit, объем кэш-памяти второго уровня (каждого ядра) составляет 1 Мбайт. Использовать новое ядро Prescott-2M с двухмегабайтным кэшем, видимо, показалось технологам пока слишком большим расточительством (хотя от себя добавим, и проведенные нами тесты это подтверждают, что он бы там не повредил). Площадь ядра Smithfield – 203 мм2, количество транзисторов – более 230 миллионов; однако благодаря отлично отлаженному за полтора года 90-нм технологическому процессу особых затруднений для Intel массовый выпуск подобных кристаллов не представляет.
А вот с энергопотреблением и тепловыделением у этих процессоров проблемы предвидятся: задачку о том, какой ток будут потреблять два одинаковых ядра и сколько тепла эти два ядра рассеют в пространство (при условии, что одно ядро потребляет ток в 78 ампер и рассеивает 89 Вт тепла) решит любой школьник (хотя, безусловно, в реальных двухпроцессорных системах просто удваивать эти показатели было бы неправильно). Вдобавок тактовые частоты для новых процессоров пришлось значительно понизить: вместо максимальных для Pentium 4 3,8 ГГц выпущенные двухядерники Intel работают на частотах не превосходящих 3,2 ГГц. Но даже с учетом этого старшие модели новых Smithfield рассеивают не менее 130 Вт (зато младшие – 95 ватт) и требуют для своей работы схем питания VRM соответствующих новому, пятому стандарту питания для процессоров Intel (05A и 05B). Работать в ранее выпущенных системах (за исключением появившегося незадолго до выпуска Pentium Extreme Edition чипсета nForce 4 SLI Intel Edition) они тоже не будут – в них даже предусмотрен специальный механизм защиты, который не позволит «жадному» до тока Smithfield-у сжечь не рассчитанную на его установку материнскую плату.
По маркетинговым соображениям на основе одних и тех же Smithfield выпускается сразу две линейки процессоров: относительно недорогие Pentium D (от 281 до 530$ за модели 820, 830 и 840 с частотами 2,8; 3,0 и 3,2 ГГц соответственно) и «экстремальный» Pentium Extreme Edition 840 (3,2 ГГц, 999$). Отличаются же они только тем, что в Pentium D отключена технология Hyper-Threading и множитель заблокирован для изменения в большую сторону, а в Extreme Edition его можно повышать хоть до 60. ;)
AMD также выпустила на рынок четыре двухядерных десктопных процессора (и тоже предпочла выделить их в отдельный бренд – Athlon 64 X2). Однако, в отличие от процессоров Intel, основываются они на двух различных процессорных кристаллах – с 512 и с 1024 Кбайт кэш-памяти второго уровня. Кроме того, еще несколько раньше были анонсировано девять двухъядерных Opteron (на основе ядер с 1024-Кбайтного кэша L2) для одно-, двух-, и многопроцессорных систем. Но вот с производством двухядерников у AMD сейчас должно возникнуть немало проблем: компания принципиально вынуждена выпускать однокристальные двухядерники, а кристалл Toledo (с 1Мбайт кэша L2) получился довольно громоздким (хотя и не столь здоровенным, как Smithfield): 199мм2 и те же самые 230 миллионов транзисторов – сказывается интегрированный Northbridge, пусть даже и общий для обоих ядер. Выпускается Toledo по 90-нм технологическому процессу второго поколения (с использованием напряженного кремния, т.н. Dual Stress Liner) на основе нового степпинга E0/E3 (поддержка SSE/SSE2/SSE3/3D now! Professional, AMD64, NX-bit, Cool`n`Quiet и усовершенствованный контроллер памяти). Интересно, что CPUID для этих процессоров показывает то, что данные процессоры… поддерживают технологию Hyper-Threading :). Скорее всего, это просто перестраховка – чтобы «оптимизированные для Гипер-Трейдинга» программы не решили вдруг, что использовать на этом «обычном» процессоре несколько потоков исполнения – только время зря терять и заведомо корректно заработали на новых Athlon 64 X2. Проблем с потребляемым током и тепловыделением у двухядерников AMD поменьше (тепловой пакет составляет 95 Вт для новых Opteron и 110 Вт – для Athlon 64 X2), работать эти процессоры должны в любых Socket – 939 – системах4, достаточно мощных, чтобы на них можно было запустить Athlon 64 FX-55. Не забудьте только обновить BIOS: без этого новые процессоры будут работать в «одноядерном» режиме.
|
Таблица 1. Двухъядерные десктопные процессоры Intel |
|
Процессор |
Pentium D 820 |
Pentium D 830 |
Pentium D 840 |
Pentium Extreme Edition 840 |
|
Тактовая частота |
2,80 ГГц |
3,00 ГГц |
3,20 ГГц |
3,20 ГГц |
|
Системная шина |
800 МГц |
800 МГц |
800 МГц |
800 МГц |
|
Кэш-память L2 |
2 x 1 Мбайт |
2 x 1 Мбайт |
2 x 1 Мбайт |
2 x 1 Мбайт |
|
Hyper-Threading |
- |
- |
- |
+ |
|
Разблокированный (вверх) множитель |
- |
- |
- |
+ |
|
Поддержка EIST |
Нет |
Есть |
Есть |
Нет |
|
Thermal Design Power |
95 Вт |
95 Вт |
130 Вт |
130 Вт |
|
Цена |
$241 |
$316 |
$530 |
$999 |
|
Таблица 2. Двухъядерные десктопные процессоры AMD |
|
Процессор |
Athlon 64 X2 4200+ |
Athlon 64 X2 4400+ |
Athlon 64 X2 4600+ |
Athlon 64 X2 4800+ |
|
Тактовая частота |
2,2 ГГц |
2,2 ГГц |
2,4 ГГц |
2,4 ГГц |
|
Кэш-память L2 |
2 x 512 Кбайт |
2 x 1 Мбайт |
2 x 512 Кбайт |
2 x 1 Мбайт |
|
Шина HyperTransport |
1000 МГц |
1000 МГц |
1000 МГц |
1000 МГц |
|
Контроллер памяти |
Двухканальный контроллер памяти Unbuffered DDR SDRAM. Поддерживаются модули DDR200, DDR266, DDR333, DDR400 |
|
Thermal Design Power |
110 Вт |
|
Цена |
$531 |
$581 |
$803 |
$1001 |
|
Таблица 3. Двухъядерные серверные процессоры AMD Opteron |
|
Процессор |
865 |
870 |
875 |
265 |
270 |
275 |
165 |
170 |
175 |
|
Кол-во процессоров в системе |
4-8 |
2 |
1 |
|
Тактовая частота, ГГц |
1.8 |
2.0 |
2.2 |
1.8 |
2.0 |
2.2 |
1.8 |
2.0 |
2.2 |
|
Кэш-память L2 |
2 x 1 Мбайт |
2 x 1 Мбайт |
2 x 1 Мбайт |
|
Шина HyperTransport |
HT 2.0 1000 ГГц, 3 линка |
HT 2.0 1000 ГГц, 2линка |
HT 2.0 1000 ГГц, 1 линк |
|
Контроллер памяти |
Двухканальный контроллер памяти Registered DDR SDRAM. Поддерживается DDR200-DDR400; поддерживается ECC |
|
Thermal Design Power |
95 Вт |
|
Цена |
$1514 |
$2149 |
$2649 |
$851* |
$1051* |
$1299* |
Пока не продаются |
|
* - ограниченная доступность (в официальном прайсе AMD пока их нет, но в Японии они продаются) |
| 1(обратно к тексту) | Именно что поразительной: простой перенос контроллера памяти в процессор отнюдь не объясняет, почему латентность памяти на AMD K8 оказывается ниже почти вдвое по сравнению с альтернативными системами. Более быстрая шина между контроллером памяти и ядром процессора способна дать выигрыш эдак 12-15%, но никак не в 50-100. |
| 2(обратно к тексту) | Хотя бы потому, что каждая такая операция «передоверения» оперативной памяти требует выполнения весьма неторопливой процедуры синхронизации. |
| 3(обратно к тексту) | Owner-данные почти во всём ведут себя так-же, как и Shared-строки: любое изменение Owner-строки приводит к автоматическому «устареванию» аналогичных строк в кэшах других процессоров; любое изменение такой же Shared-строки в кэше чужого процессора приводит к устареванию конкретной кэш-строки. Но в отличие от Shared-строк, Owner-строки, как и Modified-строки, при их вытеснении из кэша (то есть когда требуется строку из кэша по каким-то причинам убрать) предварительно сохраняются в оперативную память. Выполнять эту операцию для Exclusive, Invalid и Shared-строк, естественно, не требуется. |
| 4(обратно к тексту) | Правда, есть и неприятные исключения: скажем, по непонятным причинам с двухядерниками не работает VIA K8T890. |


 Виртуальные VPS серверы в РФ и ЕС
Виртуальные VPS серверы в РФ и ЕС